
1. Antes de começar
Muitos apps que você usa armazenam dados diretamente no dispositivo. O app Relógio armazena seus alarmes recorrentes, o Google Maps salva uma lista das pesquisas recentes e o app Contatos permite adicionar, editar e remover as informações dos contatos.
A persistência de dados (o armazenamento ou a retenção de dados no dispositivo) é uma parte importante do desenvolvimento para Android. Os dados persistentes garantem que o conteúdo gerado pelo usuário não seja perdido quando o app for fechado ou que os dados transferidos por download da Internet sejam salvos e não seja necessário fazer o download novamente.
O SQLite é uma forma comum de armazenar os dados fornecida pelo SDK para apps Android. Ele oferece um banco de dados relacional que permite representar dados de maneira semelhante à estruturação de dados com classes do Kotlin. Este codelab ensina os princípios básicos da linguagem de consulta estruturada (SQL) que, embora não seja uma linguagem de programação real, oferece uma maneira simples e flexível de ler e modificar um banco de dados SQLite com apenas algumas linhas de código.
Depois de adquirir um conhecimento básico de SQL, você vai poder usar a biblioteca do Room para adicionar persistência aos seus apps mais adiante nesta unidade.
2. Principais conceitos dos bancos de dados relacionais
O que é um banco de dados?
Se você usa um editor de planilhas como o Google Planilhas, já conhece a analogia básica de um banco de dados.
Uma planilha consiste em tabelas de dados separadas ou planilhas individuais na mesma pasta de trabalho.

Cada tabela é formada por colunas que definem o que os dados significam e linhas que representam itens individuais com valores em cada coluna. Por exemplo, você pode definir colunas para o ID, o nome, o curso e a nota de um estudante.

Cada linha contém dados de um único estudante, com valores para cada uma das colunas.
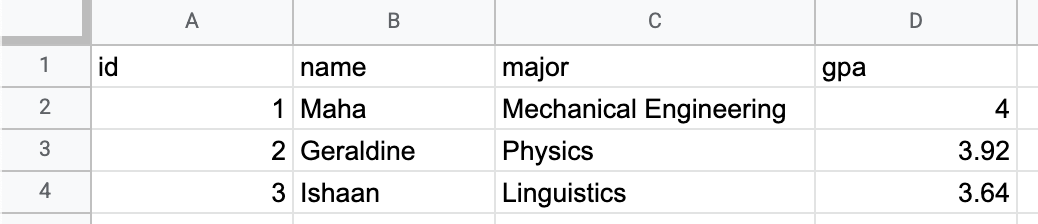
Um banco de dados relacional funciona da mesma forma.
- As tabelas definem agrupamentos de dados de alto nível que você quer representar, como estudantes e professores.
- As colunas definem os dados que cada linha da tabela contém.
- As linhas contêm os dados reais que consistem em valores para cada coluna na tabela.
A estrutura de um banco de dados relacional também é semelhante ao que você já sabe sobre classes e objetos no Kotlin.
data class Student(
id: Int,
name: String,
major: String,
gpa: Double
)
- As classes, como as tabelas, modelam os dados que você quer representar no seu app.
- As propriedades, como as colunas, definem os dados específicos que cada instância da classe precisa conter.
- Os objetos, como as linhas, são os dados reais. Os objetos contêm valores para cada propriedade definida na classe, assim como as linhas contêm valores para cada coluna definida na tabela de dados.
Da mesma forma que uma planilha pode ter várias páginas e um app várias classes, um banco de dados pode ter várias tabelas. Um banco de dados é chamado de relacional quando consegue modelar relações entre tabelas. Por exemplo, um estudante universitário pode ter um único professor como orientador, enquanto esse professor pode ser orientador de vários outros estudantes.

Cada tabela em um banco de dados relacional contém um identificador exclusivo para linhas, como uma coluna em que o valor em cada linha é um número inteiro incrementado automaticamente. Esse identificador é conhecido como chave primária.
Quando uma tabela se refere à chave primária de outra, ela é conhecida como chave externa. A presença de uma chave externa indica que há uma relação entre as tabelas.
O que é SQLite?
SQLite é um banco de dados relacional usado com frequência. Especificamente, SQLite se refere a uma biblioteca C leve para gerenciamento de bancos de dados relacionais com linguagem de consulta estruturada, conhecida como SQL, e, às vezes, pronunciada como "sequel".
Você não vai precisar aprender sobre C ou qualquer linguagem de programação totalmente nova para trabalhar com um banco de dados relacional. SQL é apenas uma maneira de adicionar e extrair dados de um banco de dados relacional com apenas algumas linhas de código.
Como representar dados com SQLite
No Kotlin, você já conhece os tipos de dados, como Int e Boolean. Os bancos de dados SQLite também usam tipos de dados. As colunas da tabela de dados precisam ter um tipo de dados específico. A tabela abaixo mapeia tipos de dados comuns do Kotlin para os equivalentes do SQLite.
Tipo de dado de Kotlin | Tipo de dados SQLite |
| INTEGER |
| VARCHAR ou TEXTO |
| BOOLEANO |
| REAL |
As tabelas em um banco de dados e as colunas em cada tabela são conhecidas coletivamente como esquema. Na próxima seção, você vai baixar o conjunto de dados inicial e aprender mais sobre o esquema.
3. Baixar o conjunto de dados inicial
O banco de dados deste codelab serve para um app de e-mails hipotético. Este codelab usa exemplos conhecidos, como classificar e filtrar e-mails ou pesquisar por assunto ou remetente, para demonstrar todos os recursos avançados de SQL. Esse exemplo também garante que você tenha experiência com os tipos de cenários que pode encontrar em um app antes de trabalhar com o Room no próximo módulo.
Faça o download do projeto inicial na ramificação compose do repositório de noções básicas do SQL do GitHub neste link (em inglês).
Usar o Database Inspector
Para usar o Database Inspector, siga estas etapas:
- Execute o app SQL Basics no Android Studio. Quando o app for iniciado, a tela abaixo vai aparecer.
- No Android Studio, clique em View > Tool Windows > App Inspection.
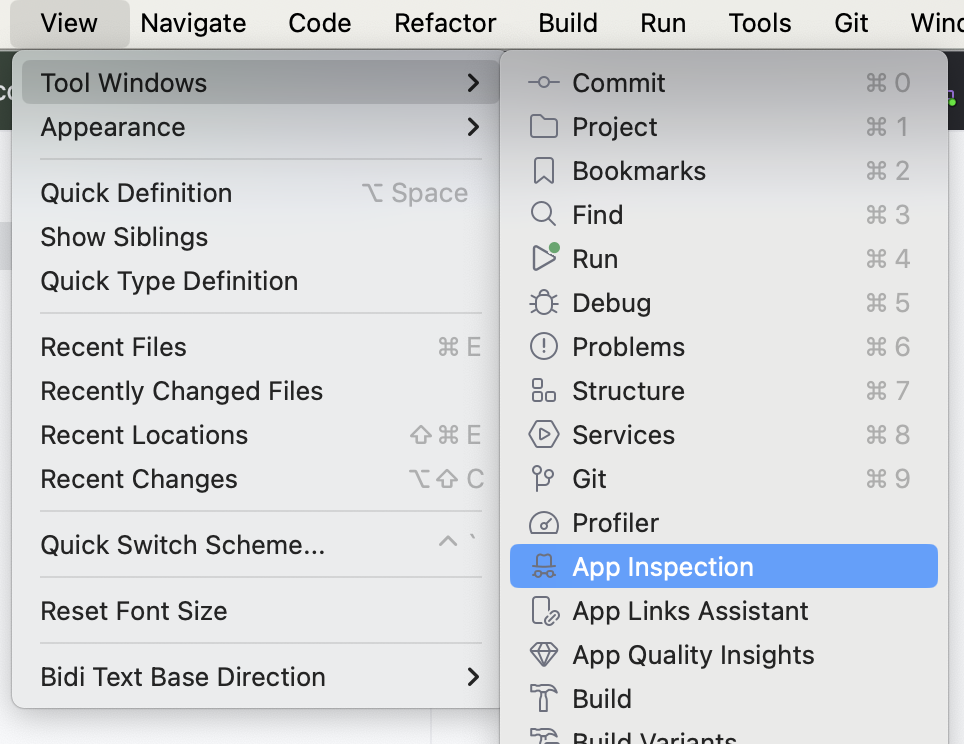
Agora você vai encontrar uma nova guia na parte de baixo com o rótulo App Inspection com a guia Database Inspector selecionada. Há outras duas guias, mas você não precisa usá-las. Pode demorar alguns segundos para carregar, mas você vai ter uma lista à esquerda com as tabelas de dados, que podem ser selecionadas para fazer consultas.
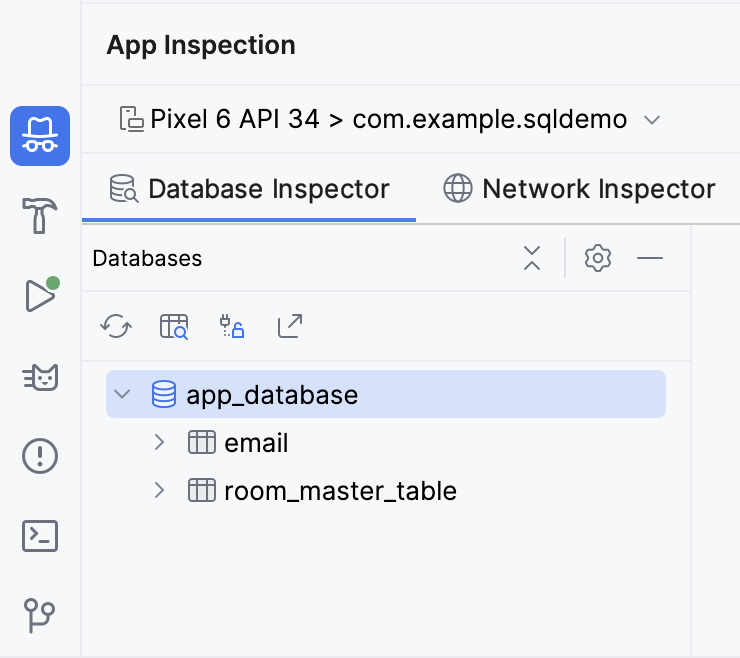
- Clique no botão Open New Query Tab para abrir um painel e executar uma consulta no banco de dados.
A tabela email tem 7 colunas:
id: a chave primária.subject: a linha de assunto do e-mail.sender: o endereço de origem do e-mail.folder: a pasta em que a mensagem pode ser encontrada, como Caixa de entrada ou Spam.starred: se o usuário marcou ou não o e-mail com estrela.read: se o usuário leu ou não o e-mail.received: o carimbo de data/hora em que o e-mail foi recebido.
4. Ler dados com uma instrução SELECT
Instrução SQL SELECT
Uma instrução SQL, às vezes chamada de consulta, é usada para ler ou manipular um banco de dados.
Você lê dados de um banco de dados SQLite com uma instrução SELECT. Uma instrução SELECT simples consiste na palavra-chave SELECT, seguida do nome da coluna, da palavra-chave FROM e do nome da tabela. Todas as instruções SQL terminam com ponto e vírgula (;).

Uma instrução SELECT também pode retornar dados de várias colunas. Os nomes das colunas precisam ser separados por vírgula.

Se você quiser selecionar todas as colunas na tabela, use o caractere curinga (*) no lugar dos nomes das colunas.

Em ambos os casos, uma instrução SELECT simples como essa retorna todas as linhas na tabela. Basta especificar os nomes das colunas que você quer que sejam retornadas.
Ler dados de e-mail usando uma instrução SELECT
Uma das principais tarefas de um app de e-mails é mostrar uma lista de mensagens. Com um banco de dados SQL, é possível acessar essas informações com uma instrução SELECT.
- Confira se a tabela email está selecionada no Database Inspector.
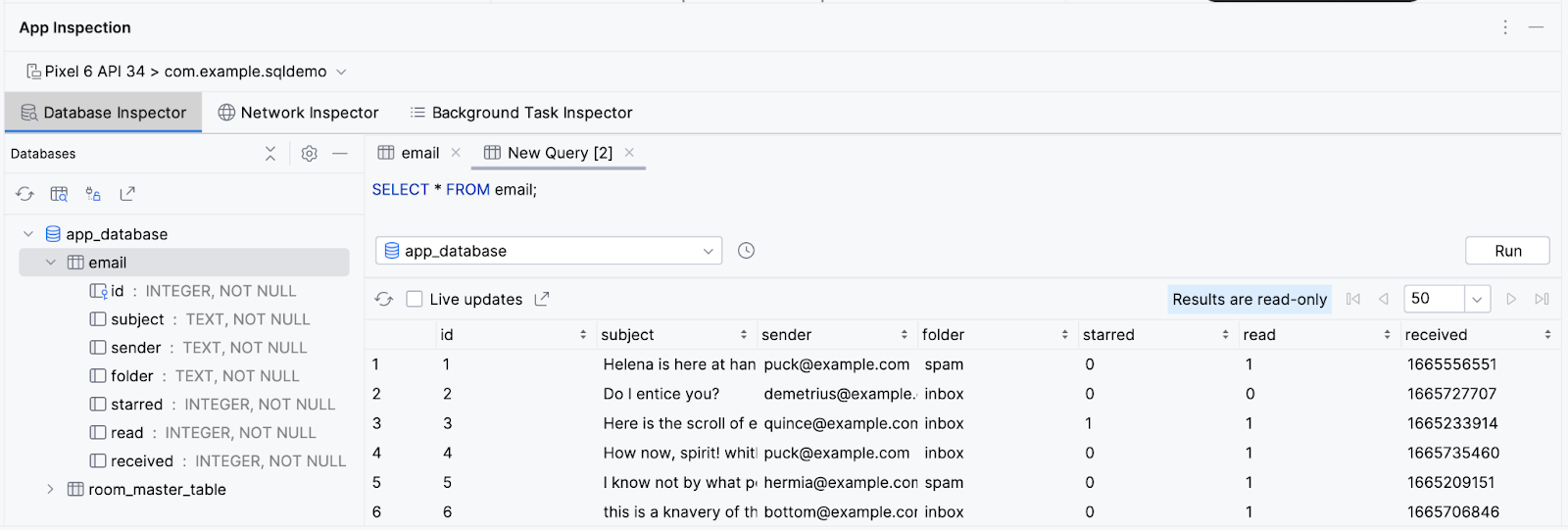
- Primeiro, tente selecionar todas as colunas de cada linha na tabela
email.
SELECT * FROM email;
- Clique no botão Run no canto inferior direito da caixa de texto. Observe que toda a tabela
emailé retornada.
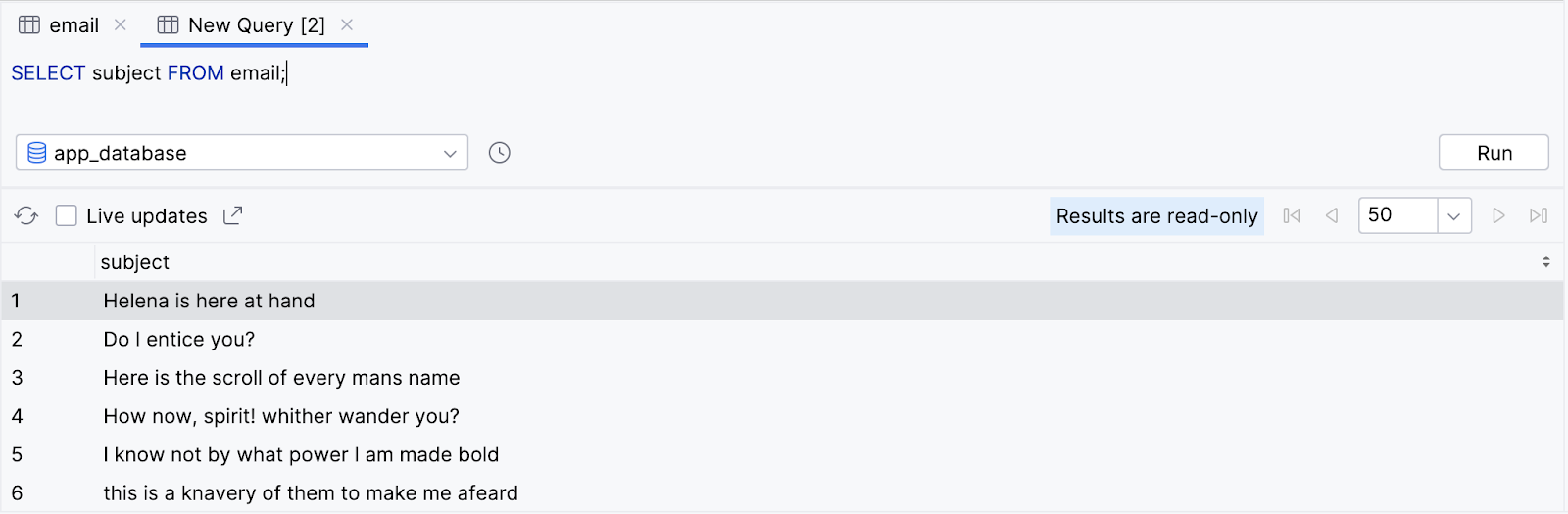
- Agora, selecione apenas o assunto de cada linha.
SELECT subject FROM email;
- Mais uma vez, a consulta retorna todas as linhas, mas somente para essa coluna.
- Também é possível selecionar várias colunas. Tente selecionar o assunto e o remetente.
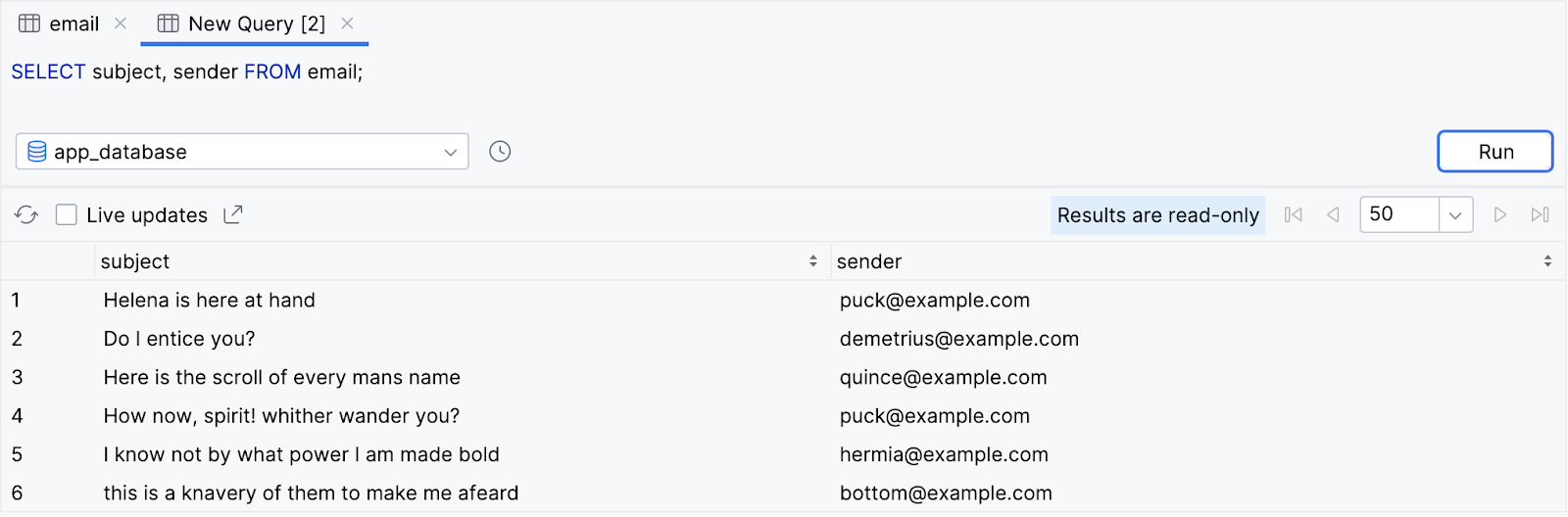
SELECT subject, sender FROM email;
- A consulta retorna todas as linhas da tabela de
email, mas apenas os valores do assunto e da coluna do remetente.
Parabéns! Você acabou de executar sua primeira consulta. Nada mal, mas foi só o começo. Praticamente um tutorial "Hello World" do SQL.
É possível ser muito mais específico com instruções SELECT, adicionando cláusulas para especificar um subconjunto dos dados e até mesmo mudar a formatação da saída. Nas próximas seções, você vai aprender sobre as cláusulas mais usadas das instruções SELECT e como formatar dados.
5. Usar instruções SELECT com funções de agregação e valores distintos
Reduzir colunas com funções de agregação
As instruções SQL não se limitam a linhas de retorno. O SQL oferece várias funções que podem executar uma operação ou um cálculo em uma coluna específica, como encontrar o valor máximo ou contar o número de valores exclusivos possíveis para uma determinada coluna. Elas são chamadas de funções de agregação. Em vez de retornar todos os dados de uma coluna específica, você pode retornar um único valor de uma coluna específica.
Confira alguns exemplos de funções de agregação SQL:
COUNT(): retorna o número total de linhas que correspondem à consulta.SUM(): retorna a soma dos valores de todas as linhas na coluna selecionada.AVG(): retorna o valor médio (a média) de todos os valores na coluna selecionada.MIN(): retorna o menor valor na coluna selecionada.MAX(): retorna o maior valor na coluna selecionada.
Em vez de um nome de coluna, chame uma função agregada e transmita um nome de coluna como argumento entre parênteses.

Em vez de retornar o valor dessa coluna para cada linha na tabela, um único valor vai ser retornado ao chamar a função agregada.
As funções de agregação podem ser uma forma eficiente de realizar cálculos de valor quando você não precisa ler todos os dados em um banco de dados. Por exemplo, você talvez queira descobrir manualmente a média dos valores em uma coluna sem carregar todo o banco de dados em uma lista.
Vamos conferir algumas das funções de agregação em ação com a tabela email:
- Um app pode querer saber o número total de e-mails recebidos. Para fazer isso, use a função
COUNT()e o caractere curinga (*).
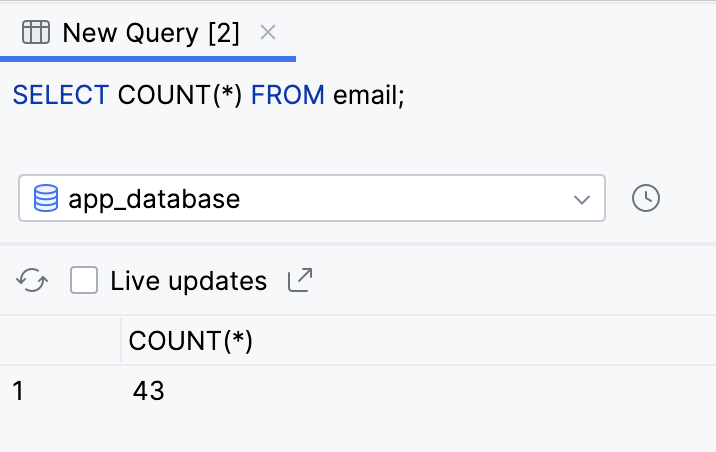
SELECT COUNT(*) FROM email;
- A consulta retorna um único valor. É possível fazer isso inteiramente com uma consulta SQL, sem nenhum código Kotlin para contar as linhas manualmente.
- Para conferir o horário da mensagem mais recente, use a função
MAX()na coluna recebida porque o carimbo de data/hora Unix mais recente é o número mais alto.
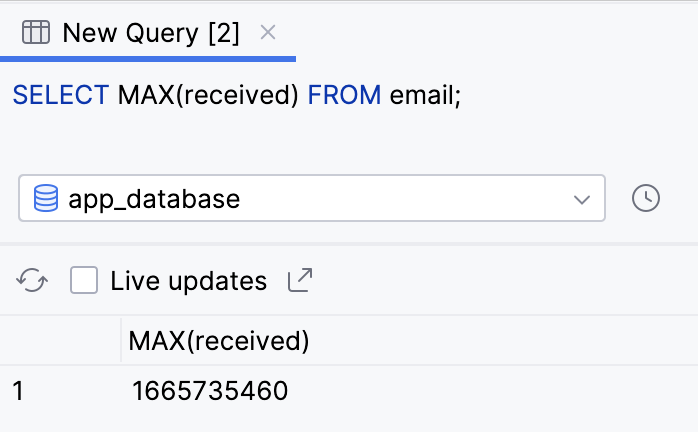
SELECT MAX(received) FROM email;
- A consulta retorna um único resultado, o maior carimbo de data/hora (o mais recente) na coluna recebida.
Filtrar resultados duplicados com DISTINCT
Ao selecionar uma coluna, é possível usar a palavra-chave DISTINCT antes da instrução. Essa abordagem pode ser útil quando você quer remover cópias do resultado da consulta.

Por exemplo, muitos apps de e-mail têm um recurso de preenchimento automático para endereços. É recomendável incluir todos os endereços de que você já recebeu um e-mail e mostrá-los em uma lista.
- Execute a consulta abaixo para retornar a coluna
senderpara cada linha.
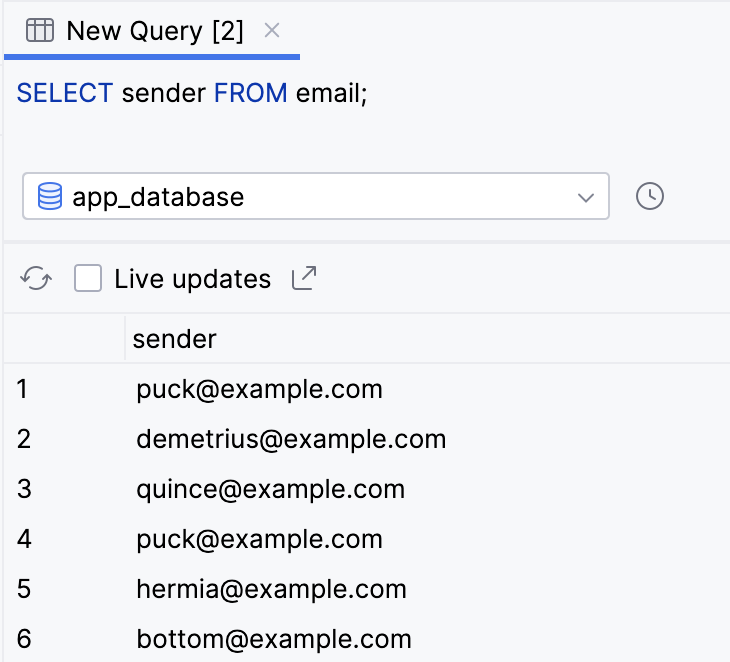
SELECT sender FROM email;
- O resultado contém muitas cópias. Essa não é uma experiência ideal.
- Adicione a palavra-chave
DISTINCTantes da coluna do remetente e execute a consulta de novo.
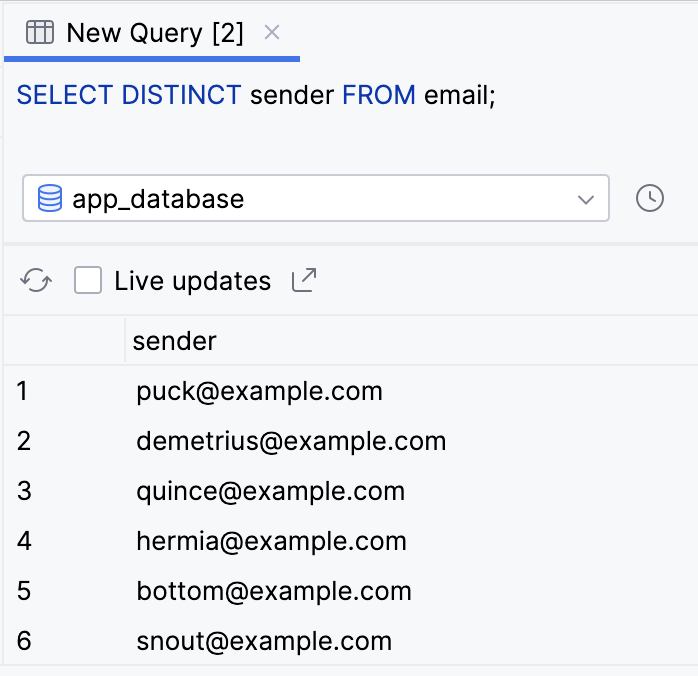
SELECT DISTINCT sender FROM email;
- O resultado é muito menor, e cada valor é único.
Também é possível usar a palavra-chave DISTINCT antes do nome da coluna em uma função agregada.

Digamos que você queira saber o número de remetentes únicos no banco de dados. É possível contar o número de remetentes únicos com a função agregada COUNT() e a palavra-chave DISTINCT na coluna sender.
- Execute uma instrução
SELECT, transmitindoDISTINCT senderpara a funçãoCOUNT().
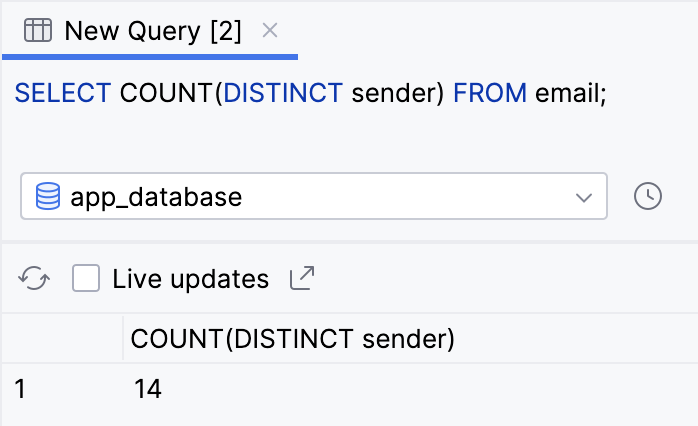
SELECT COUNT(DISTINCT sender) FROM email;
- A consulta informa que há 14 remetentes únicos.
6. Filtrar consultas com uma cláusula WHERE
Muitos apps de e-mail oferecem o recurso de filtrar as mensagens mostradas com base em determinados critérios, como dados, termo de pesquisa, pasta, remetente etc. Para esses tipos de casos de uso, é possível adicionar uma cláusula WHERE na consulta SELECT.
Após o nome da tabela, em uma nova linha, adicione a palavra-chave WHERE seguida por uma expressão. Ao escrever consultas SQL mais complexas, é comum colocar cada cláusula em uma nova linha para facilitar a leitura.

Essa consulta executa uma verificação booleana para cada linha selecionada. Se a verificação retornar "true", ela vai incluir a linha no resultado da consulta. As linhas em que a consulta retorna "false" não são incluídas no resultado.
Por exemplo, um app de e-mails pode ter filtros de spam, lixeira, rascunhos ou outros criados pelo usuário. As instruções abaixo fazem isso com uma cláusula WHERE:
- Execute uma instrução
SELECTpara retornar todas as colunas (*) da tabelaemail, incluindo uma cláusulaWHEREpara verificar a condiçãofolder = 'inbox'. Não, isso não é um erro de digitação: você usa um único sinal de igual para conferir a igualdade no SQL e aspas simples em vez de duplas para representar um valor de string.
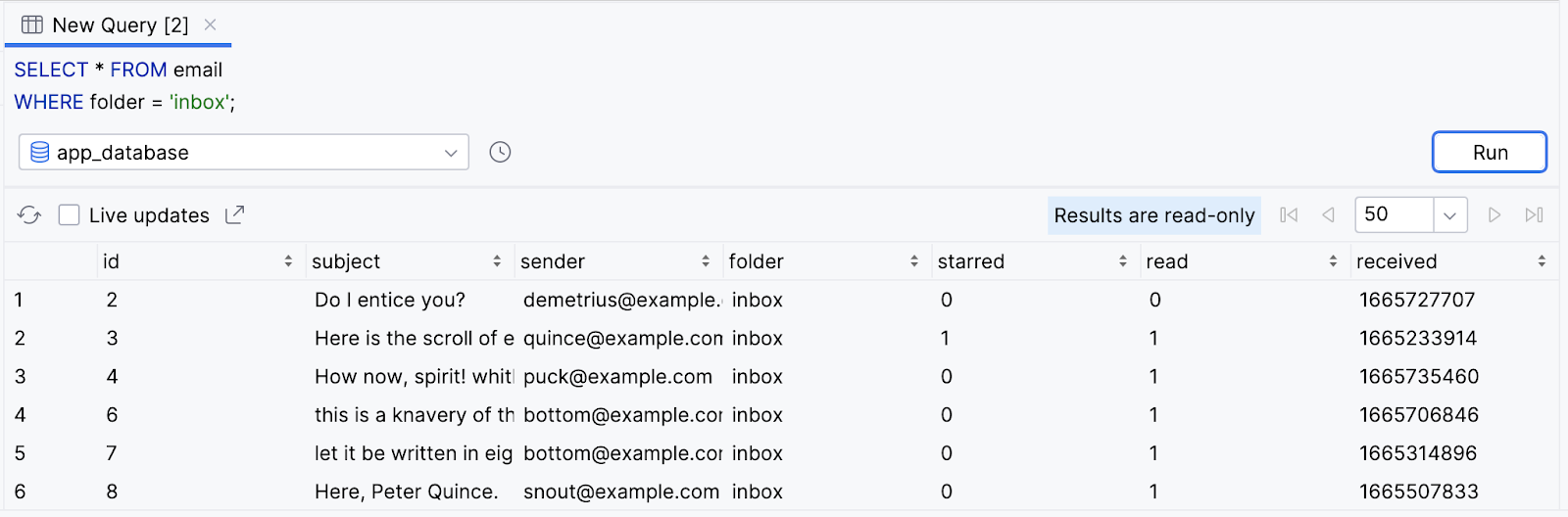
SELECT * FROM email
WHERE folder = 'inbox';
- O resultado retorna apenas linhas para mensagens na caixa de entrada do usuário.
Operadores lógicos com cláusulas WHERE
As cláusulas SQL WHERE não se limitam a uma única expressão. Você pode usar a palavra-chave AND, equivalente ao operador e (&&) do Kotlin, para incluir apenas resultados que atendam às duas condições.

Como alternativa, você pode usar a palavra-chave OR, equivalente ao operador ou (||) do Kotlin, para incluir linhas nos resultados que atendam a alguma das condições.

Para facilitar a leitura, você também pode negar uma expressão usando a palavra-chave NOT.

Muitos apps de e-mail permitem vários filtros, por exemplo, mostrando apenas e-mails não lidos.
Teste as cláusulas WHERE mais complicadas abaixo na tabela email:
- Além de retornar apenas mensagens na caixa de entrada do usuário, tente também limitar os resultados a mensagens não lidas. Nesse caso, o valor da coluna de leitura é "false".
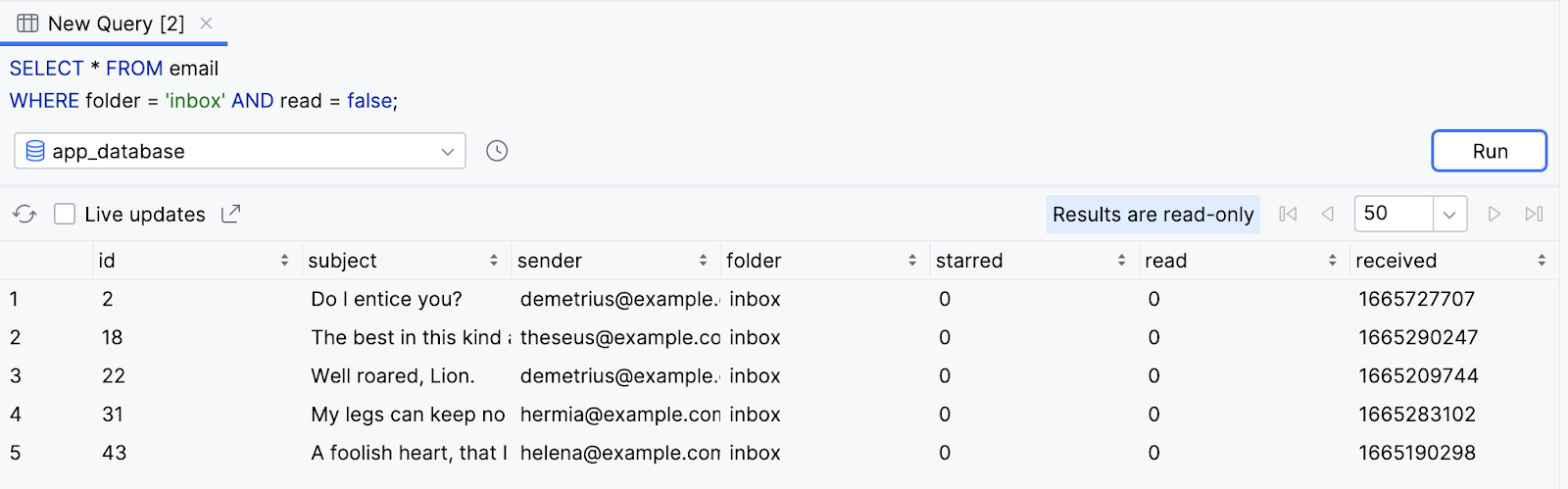
SELECT * FROM email
WHERE folder = 'inbox' AND read = false;
- Depois de executar a consulta, os resultados vão ter apenas e-mails não lidos na caixa de entrada do usuário.
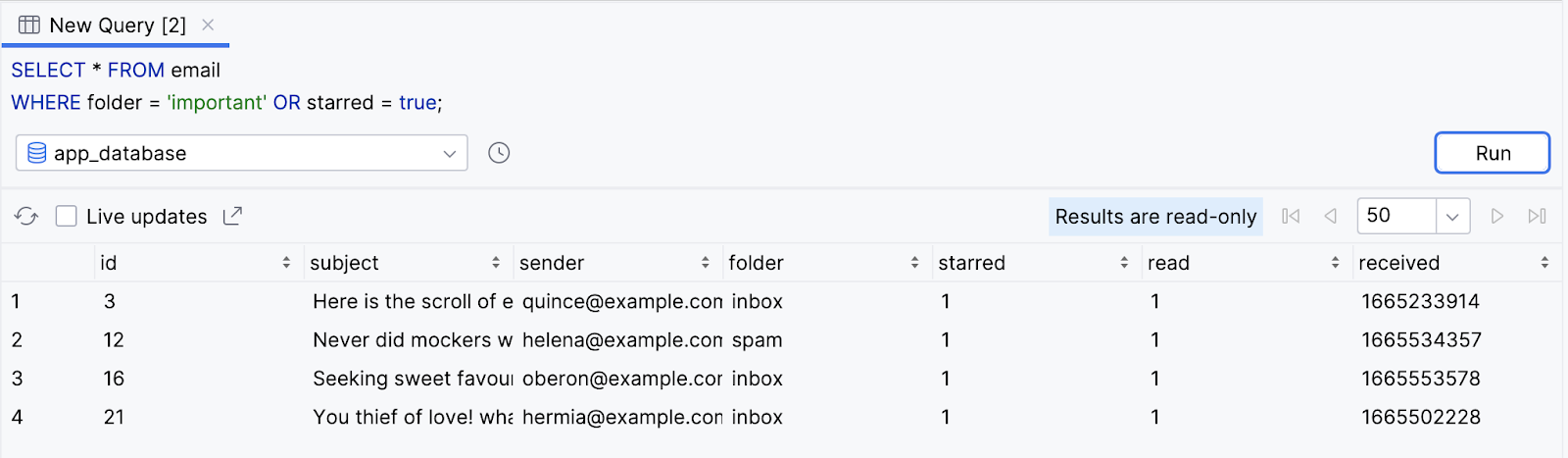
- Retorne todos os e-mails que estão na pasta important
OR(ou) com estrela (starred = true). Isso significa que o resultado inclui e-mails em pastas diferentes, desde que eles tenham estrela.
SELECT * FROM email
WHERE folder = 'important' OR starred = true;
- Observe o resultado.
Pesquisar texto usando LIKE
Uma coisa muito útil a fazer com uma cláusula WHERE é pesquisar texto em uma coluna específica. Para alcançar esse resultado, especifique um nome de coluna, seguido pela palavra-chave LIKE e por uma string de pesquisa.

A string de pesquisa começa com o símbolo de porcentagem (%), seguido pelo texto a ser pesquisado (termo de pesquisa) e pelo símbolo de porcentagem (%) novamente.

Se você estiver pesquisando um prefixo, com resultados que começam com o texto especificado, omita o primeiro símbolo de porcentagem (%).

Como alternativa, se você estiver procurando um sufixo, omita o último símbolo de porcentagem (%).

Existem muitos casos de uso em que um app pode usar a pesquisa de texto, como pesquisar e-mails que contenham um texto específico na linha de assunto ou atualizar sugestões de preenchimento automático enquanto o usuário digita.
Com as instruções abaixo, você vai poder usar a pesquisa de texto ao consultar a tabela de email.
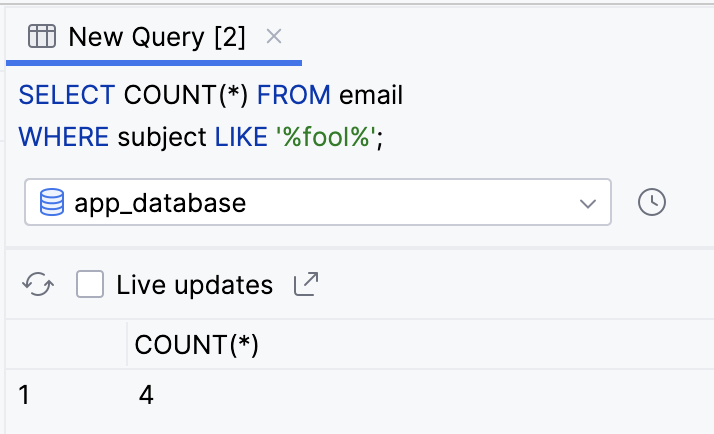
- Os personagens de Shakespeare, como aqueles do nosso banco de dados, adoravam falar sobre tolos (fool, em inglês). Execute a consulta a seguir para conferir o número total de e-mails com o texto "fool" na linha de assunto.
SELECT COUNT(*) FROM email
WHERE subject LIKE '%fool%';
- Observe o resultado.
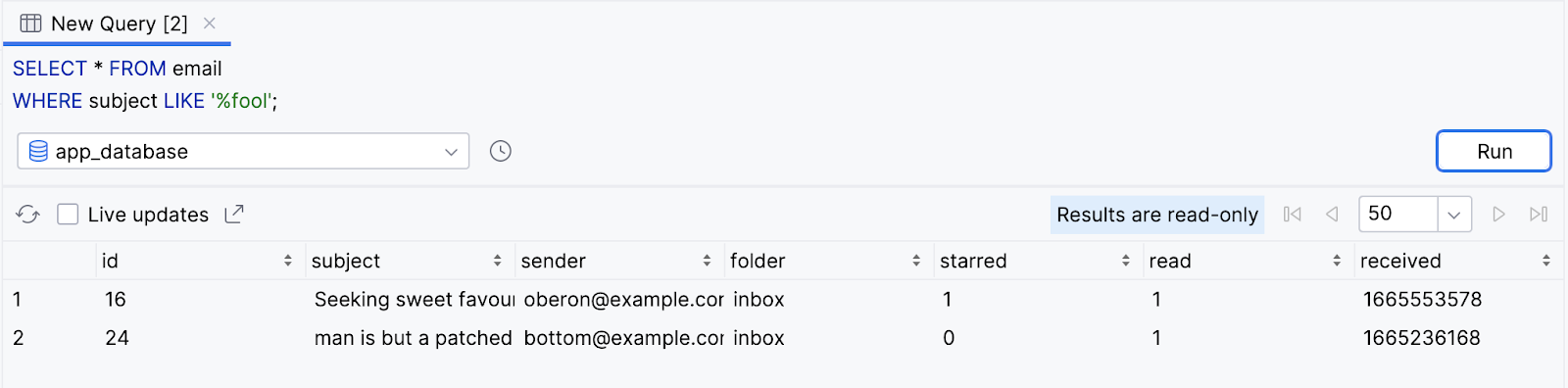
- Execute a consulta abaixo para retornar todas as colunas de todas as linhas em que o assunto termina com a palavra "fool".
SELECT * FROM email
WHERE subject LIKE '%fool';
- Observe que duas linhas são retornadas.
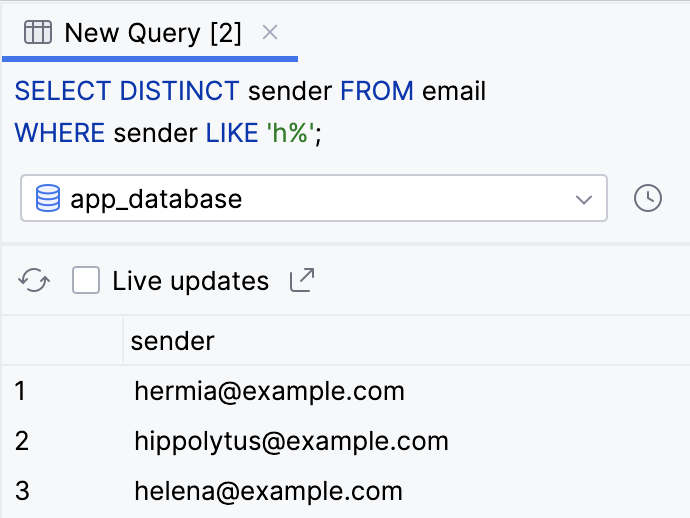
- Execute a consulta abaixo para retornar valores distintos da coluna
senderque começam com a letrah.
SELECT DISTINCT sender FROM email
WHERE sender LIKE 'h%';
- A consulta retorna três valores:
helena@example.com,hyppolytus@example.comehermia@example.com.
7. Agrupar, ordenar e limitar os resultados
Agrupar resultados com GROUP BY
Você acabou de aprender a usar funções de agregação e a cláusula WHERE para filtrar e reduzir resultados. O SQL oferece várias outras cláusulas que podem ajudar a formatar os resultados da consulta. Entre essas cláusulas estão o agrupamento, a ordenação e a limitação de resultados.
É possível usar uma cláusula GROUP BY para agrupar os resultados. Assim, todas as linhas com o mesmo valor de uma determinada coluna são agrupadas entre si nos resultados. Essa cláusula não muda os resultados, apenas a ordem em que são retornadas.
Para adicionar uma cláusula GROUP BY a uma instrução SELECT, inclua a palavra-chave GROUP BY seguida pelo nome da coluna que você quer usar para agrupar os resultados.

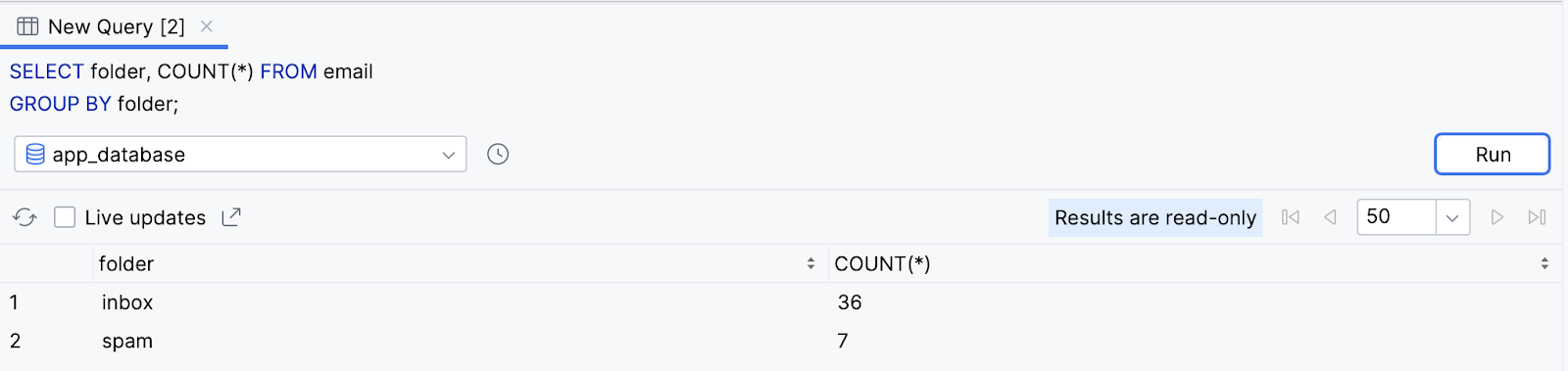
Um caso de uso comum é unir uma cláusula GROUP BY com uma função agregada para particionar o resultado da função em diferentes buckets, como valores de uma coluna. Veja um exemplo. Imagine que você quer saber o número de e-mails em cada pasta: 'inbox', 'spam' etc. É possível selecionar a coluna folder e a função agregada COUNT() e especificar a coluna folder na cláusula GROUP BY.
- Execute a consulta abaixo para selecionar a coluna de pasta e o resultado da função agregada
COUNT(). Use uma cláusulaGROUP BYpara agrupar os resultados pelo valor na colunafolder.
SELECT folder, COUNT(*) FROM email
GROUP BY folder;
- Observe os resultados. A consulta retorna o número total de e-mails para cada pasta.
Classificar resultados com ORDER BY
Também é possível alterar a ordem dos resultados da consulta ao classificá-los com a cláusula ORDER BY. Adicione a palavra-chave ORDER BY, seguida por um nome de coluna e pela direção de classificação.

Por padrão, a direção de classificação é em a ordem crescente, que pode ser omitida da cláusula ORDER BY. Se você quiser classificar os resultados em ordem decrescente, adicione DESC após o nome da coluna.
É provável que um app de e-mails mostre os e-mails mais recentes primeiro. As instruções abaixo permitem fazer isso com uma cláusula ORDER BY.
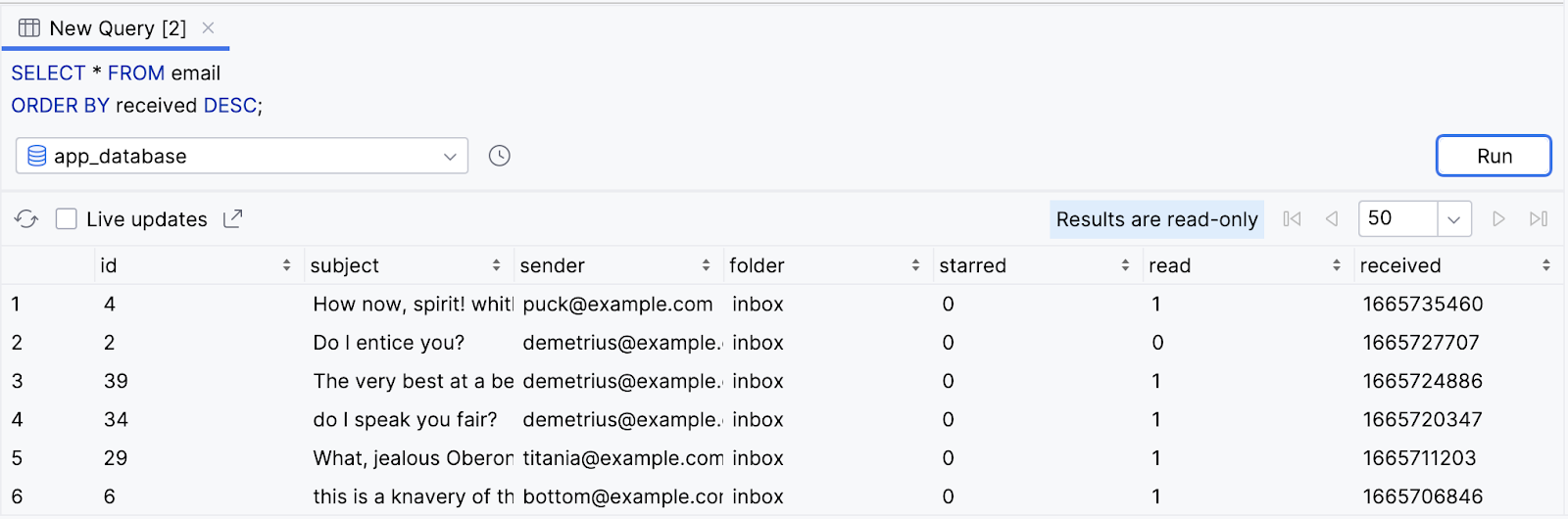
- Adicione uma cláusula
ORDER BYpara classificar e-mails não lidos com base na colunareceived. Como a ordem crescente (mais antiga ou mais antiga primeiro) é o padrão, é necessário usar a palavra-chaveDESC.
SELECT * FROM email
ORDER BY received DESC;
- Observe o resultado.
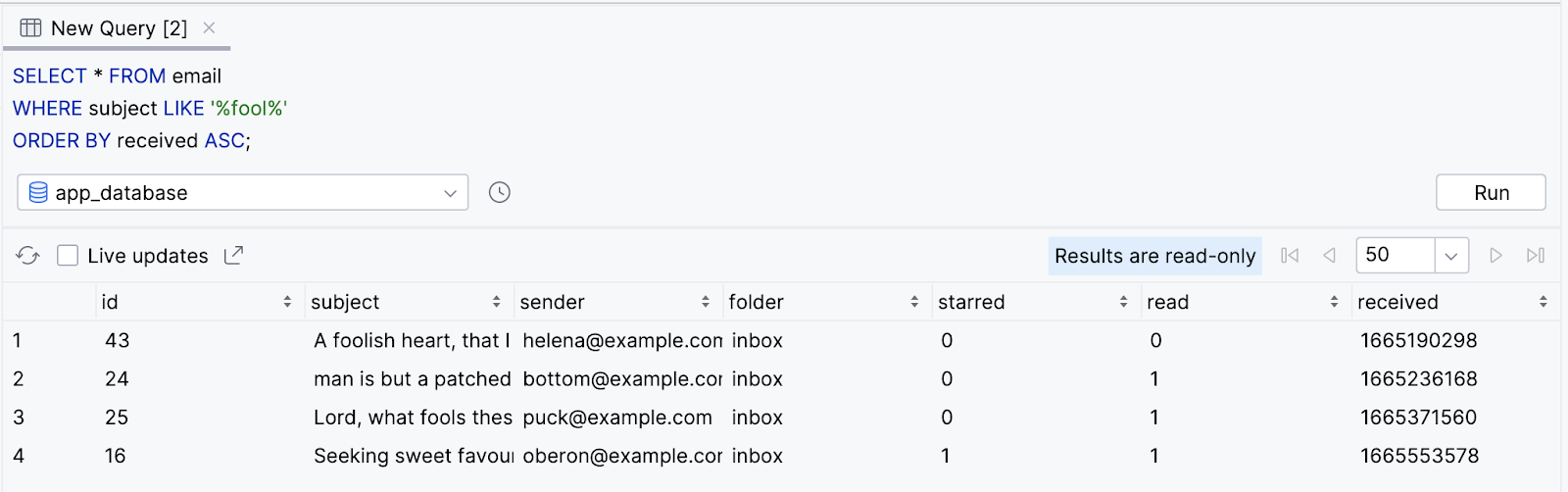
É possível usar uma cláusula ORDER BY com uma cláusula WHERE. Digamos que um usuário queira pesquisar e-mails antigos que tenham o texto fool. Ele pode classificar os resultados para mostrar primeiro os e-mails mais antigos, em ordem crescente.
- Selecione todos os e-mails em que o assunto contém o texto "fool" e classifique os resultados em ordem crescente. Como a ordem é crescente, que é a ordem padrão quando nenhuma é especificada, usar a palavra-chave
ASCcom a cláusulaORDER BYé opcional.
SELECT * FROM email
WHERE subject LIKE '%fool%'
ORDER BY received ASC;
- Observe que os resultados filtrados são retornados com o valor mais antigo (o mais baixo da coluna recebida) em primeiro lugar.
Restringir o número de resultados com LIMIT
Até agora, todos os exemplos retornam todos os resultados do banco de dados que correspondem à consulta. Em muitos casos, você só precisa mostrar um número limitado de linhas do banco de dados. É possível adicionar uma cláusula LIMIT à consulta para retornar somente um número específico de resultados. Adicione a palavra-chave LIMIT, seguida do número máximo de linhas que você quer retornar. Se aplicável, a cláusula LIMIT vem depois da cláusula ORDER BY.

Também é possível incluir a palavra-chave OFFSET seguida por outro valor para que o número de linhas seja "ignorado". Por exemplo, se você quiser mostrar os próximos 10 resultados, depois dos 10 primeiros, mas não quiser retornar 20 resultados, use LIMIT 10 OFFSET 10.

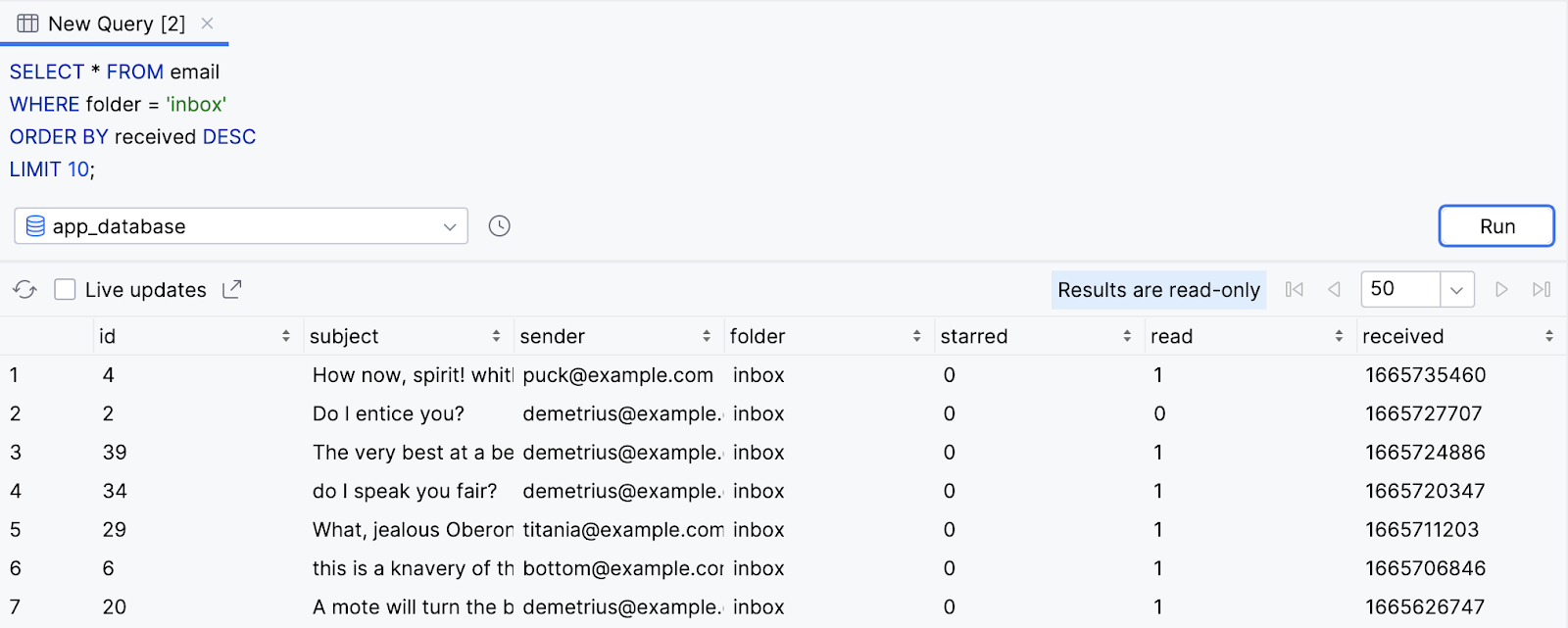
Em um app, talvez você queira carregar os e-mails mais rapidamente retornando apenas os dez primeiros e-mails na caixa de entrada do usuário. Os usuários podem rolar para encontrar as próximas páginas de e-mails. As instruções abaixo usam uma cláusula LIMIT para fazer isso.
- Execute a instrução
SELECTabaixo para colocar todos os e-mails na caixa de entrada do usuário em ordem decrescente e limitados aos dez primeiros resultados.
SELECT * FROM email
WHERE folder = 'inbox'
ORDER BY received DESC
LIMIT 10;
- Observe que apenas dez resultados são retornados.
- Modifique e execute novamente a consulta para incluir a palavra-chave
OFFSETcom o valor10.
SELECT * FROM email
WHERE folder = 'inbox'
ORDER BY received DESC
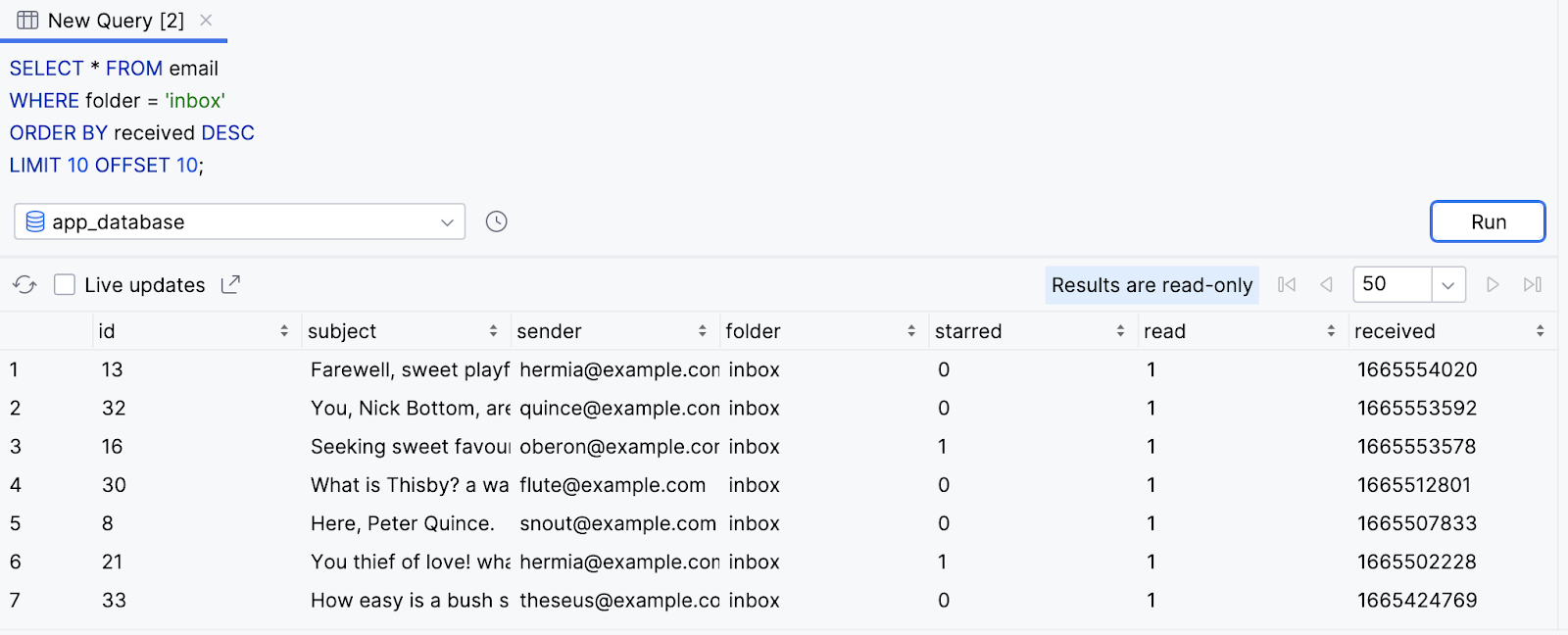
LIMIT 10 OFFSET 10;
- A consulta retorna dez resultados em ordem decrescente. No entanto, a consulta pula o primeiro conjunto de dez resultados.
8. Inserir, atualizar e excluir dados em um banco de dados
Inserir dados em um banco de dados
Além de ler em um banco de dados, há diferentes instruções SQL para gravar em um banco de dados. Os dados precisam ser armazenados de alguma forma.
É possível adicionar uma nova linha a um banco de dados com uma instrução INSERT. Uma instrução INSERT começa com INSERT INTO, seguida pelo nome da tabela em que você quer inserir uma nova linha. A palavra-chave VALUES aparece em uma nova linha seguida de um conjunto de parênteses com uma lista de valores separados por vírgulas. Você precisa listar os valores na mesma ordem das colunas do banco de dados.

Imagine que o usuário recebe um novo e-mail, e precisamos armazená-lo no banco de dados do app. É possível usar uma instrução INSERT para adicionar uma nova linha à tabela email.
- Execute uma instrução
INSERTcom os dados abaixo para um novo e-mail. Como o e-mail é novo, ele não foi lido e aparece inicialmente na pastafolderda caixa de entrada. Um valor deNULLé fornecido para a colunaid, o que significa queidserá gerado automaticamente com o próximo número inteiro autoincrementado disponível.
INSERT INTO email
VALUES (
NULL, 'Lorem ipsum dolor sit amet', 'sender@example.com', 'inbox', false, false, CURRENT_TIMESTAMP
);
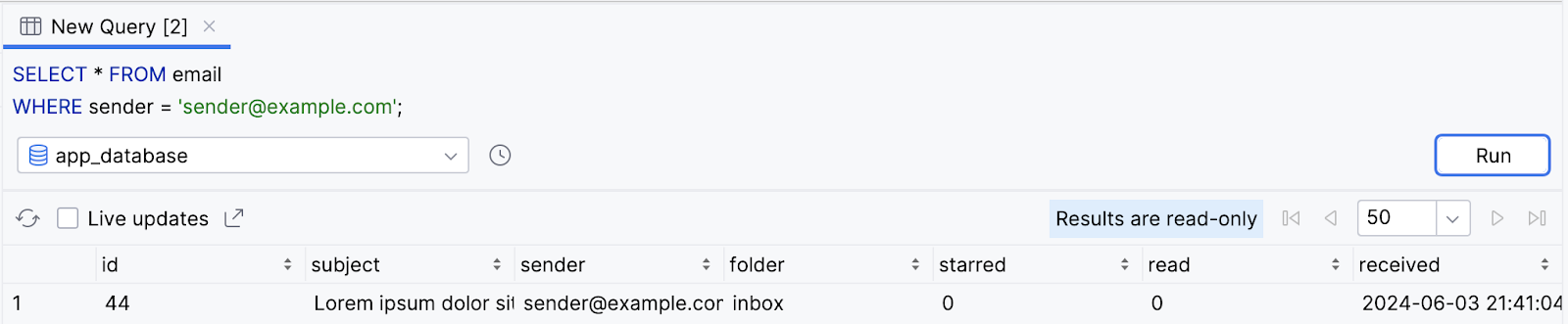
- O resultado é inserido no banco de dados com um
idde44.
SELECT * FROM email
WHERE sender = 'sender@example.com';
Atualizar dados existentes em um banco de dados
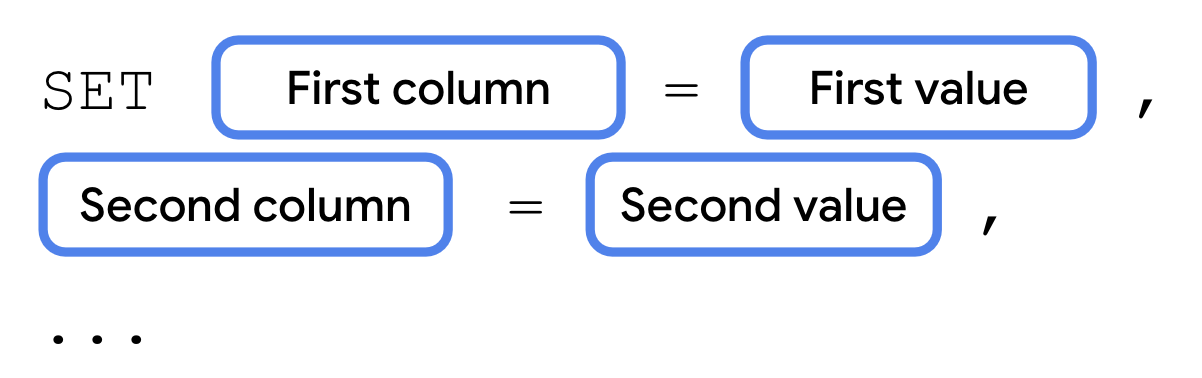
Depois de inserir dados em uma tabela, ainda é possível fazer mudanças. É possível atualizar o valor de uma ou mais colunas usando uma instrução UPDATE. Uma instrução UPDATE começa com a palavra-chave UPDATE, seguida pelo nome da tabela e uma cláusula SET.

Uma cláusula SET consiste na palavra-chave SET, seguida pelo nome da coluna que você quer atualizar.
Em geral, uma instrução UPDATE inclui uma cláusula WHERE para especificar uma ou várias linhas que você quer atualizar com o par de valores de colunas especificado.

Se o usuário quiser marcar um e-mail como lido, por exemplo, use uma instrução UPDATE para atualizar o banco de dados. As instruções abaixo permitem marcar o e-mail inserido na etapa anterior como lido.
- Execute a instrução
UPDATEabaixo para definir a linha com umidde44, de modo que o valor da colunareadsejatrue.
UPDATE email
SET read = true
WHERE id = 44;
- Execute uma instrução
SELECTpara essa linha específica para validar o resultado.
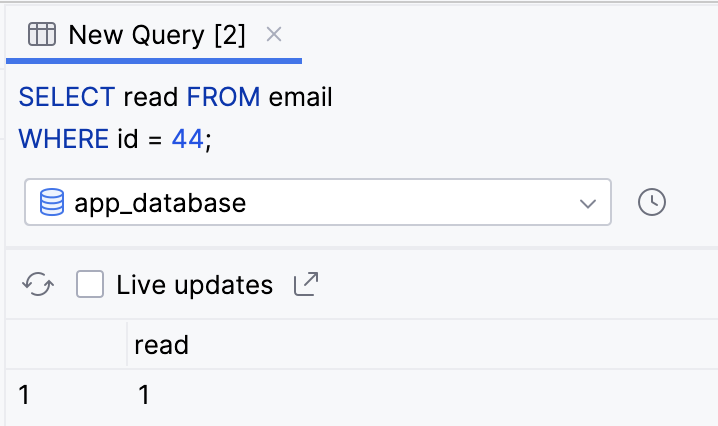
SELECT read FROM email
WHERE id = 44;
- O valor da coluna de leitura agora é
1para um valor "true" em vez de0para "false".
Excluir uma linha de um banco de dados
Por fim, use uma instrução SQL DELETE para excluir uma ou mais linhas de uma tabela. Uma instrução DELETE começa com a palavra-chave DELETE, seguida pela palavra-chave FROM, seguida pelo nome da tabela e por uma cláusula WHERE para especificar quais linhas você quer excluir.

As instruções abaixo usam uma instrução DELETE para excluir a linha inserida anteriormente e a atualizada depois do banco de dados.
- Execute a instrução
DELETEabaixo para excluir a linha com umidde44do banco de dados.
DELETE FROM email
WHERE id = 44;
- Valide as mudanças usando uma instrução
SELECT.
SELECT * FROM email
WHERE id = 44;
- Uma linha com um
idde44não existe mais.
9. Resumo
Parabéns! Você aprendeu muito! Agora é possível ler dados em um banco de dados usando instruções SELECT, incluindo as cláusulas WHERE, GROUP BY, ORDER BY e LIMIT para filtrar os resultados. Você também aprendeu sobre as funções de agregação usadas com frequência, a palavra-chave DISTINCT para especificar resultados exclusivos e a palavra-chave LIKE para realizar uma pesquisa de texto nos valores de uma coluna. Por fim, você aprendeu a usar as linhas INSERT, UPDATE e DELETE em uma tabela de dados.
Essas habilidades vão ser convertidas diretamente pelo Room e, com seu conhecimento de SQL, você estará mais preparado para usar a persistência de dados nos próximos apps.
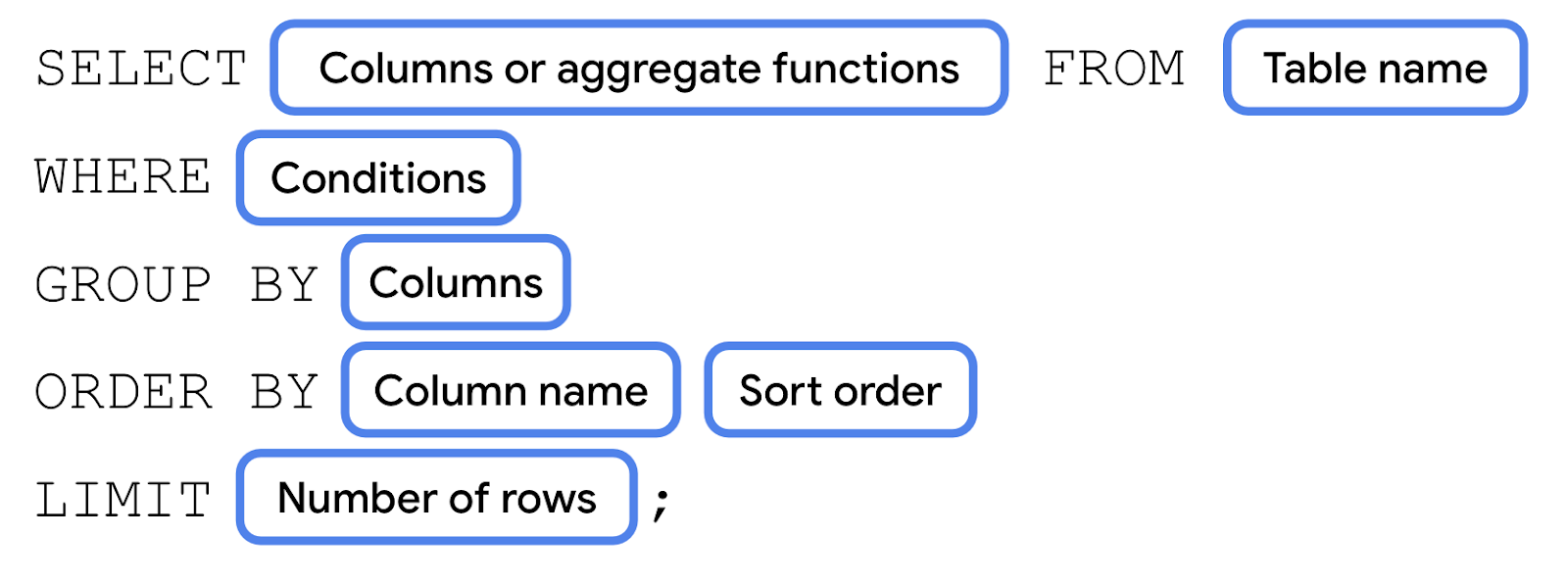
Sintaxe da instrução SELECT:
10. Saiba mais
Embora o foco esteja nas noções básicas do SQL e em alguns casos de uso comuns para desenvolvimento para Android, o SQL pode fazer muito mais. Consulte os recursos abaixo como referências extra sobre o que você aprendeu ou para saber mais sobre o assunto.
- Database Inspector
- Salvar dados usando o SQLite
- Funções de agregação
- Referência rápida do SQL (link em inglês)
- Como criar tabelas de dados (link em inglês)
- Agrupamentos do SQL (link em inglês)
- Performance do SQLite