
En este codelab, aprenderás a usar el compilador de LiveData a fin de combinar corrutinas de Kotlin con LiveData en una app para Android. También usaremos el flujo asíncrono de corrutinas, que es un tipo de la biblioteca de corrutinas utilizado en la representación y la implementación de una secuencia asíncrona (o un flujo) de valores.
Comenzarás con una app existente, compilada con los componentes de la arquitectura de Android, que usa LiveData con el fin de obtener una lista de objetos de una base de datos de Room y mostrarlos en un diseño de cuadrícula de RecyclerView.
A continuación, te presentamos algunos fragmentos de código que te darán una idea de lo que harás. Este es el código existente para consultar la base de datos de Room:
val plants: LiveData<List<Plant>> = plantDao.getPlants()
Se actualizará LiveData usando el compilador de LiveData y las corrutinas con lógica de ordenamiento adicional:
val plants: LiveData<List<Plant>> = liveData<List<Plant>> {
val plantsLiveData = plantDao.getPlants()
val customSortOrder = plantsListSortOrderCache.getOrAwait()
emitSource(plantsLiveData.map { plantList -> plantList.applySort(customSortOrder) })
}
También implementarás la misma lógica con Flow:
private val customSortFlow = plantsListSortOrderCache::getOrAwait.asFlow()
val plantsFlow: Flow<List<Plant>>
get() = plantDao.getPlantsFlow()
.combine(customSortFlow) { plants, sortOrder ->
plants.applySort(sortOrder)
}
.flowOn(defaultDispatcher)
.conflate()
Requisitos previos
- Experiencia con los componentes de la arquitectura
ViewModel,LiveData,RepositoryyRoom - Experiencia con la sintaxis de Kotlin, incluidas las funciones de extensión y lambdas
- Experiencia con las corrutinas de Kotlin
- Conocimientos básicos sobre el uso de subprocesos en Android, como el subproceso principal, los subprocesos en segundo plano y las devoluciones de llamada
Actividades
- Convierte un
LiveDataexistente a los efectos de usar el compilador deLiveDatacompatible con corrutinas de Kotlin. - Agrega lógica en un compilador de
LiveData. - Usa
Flowpara operaciones asíncronas. - Combina
Flowsy transforma varias fuentes asíncronas. - Controla la simultaneidad con
Flows. - Obtén información para elegir entre
LiveDatayFlow.
Requisitos
- Android Studio 4.1 o una versión posterior. Es posible que el codelab funcione con otras versiones, pero algo podría faltar o verse diferente.
Si a medida que avanzas con este codelab encuentras algún problema (errores de código, errores gramaticales, texto poco claro, etc.), infórmalo mediante el vínculo "Informar un error" que se encuentra en la esquina inferior izquierda del codelab.
Descarga el código
Haz clic en el siguiente vínculo a fin de descargar todo el código de este codelab:
… o clona el repositorio de GitHub desde la línea de comandos con el siguiente comando:
$ git clone https://github.com/googlecodelabs/kotlin-coroutines.git
El código de este codelab se encuentra en el directorio advanced-coroutines-codelab.
Preguntas frecuentes
Primero, veamos el aspecto de la app de ejemplo inicial. Sigue estas instrucciones para abrir la app de muestra en Android Studio.
- Si descargaste el archivo ZIP
kotlin-coroutines, descomprímelo. - Abre el directorio
advanced-coroutines-codelaben Android Studio. - Asegúrate de que
startesté seleccionado en el menú desplegable de configuración. - Haz clic en el botón Run
 y elige un dispositivo emulado o conecta tu dispositivo Android. El dispositivo debe poder ejecutar Android Lollipop (el SDK mínimo compatible es el 21).
y elige un dispositivo emulado o conecta tu dispositivo Android. El dispositivo debe poder ejecutar Android Lollipop (el SDK mínimo compatible es el 21).
Cuando la app se ejecute por primera vez, aparecerá una lista de tarjetas, que mostrarán el nombre y la imagen de una planta específica:

Cada Plant tiene un growZoneNumber, un atributo que representa la región en la que es más probable que la planta crezca. Los usuarios pueden presionar el ícono de filtro  para activar o desactivar la opción de mostrar todas las plantas y aquellas de una zona de crecimiento específica, codificadas en la zona 9. Presiona el botón de filtro varias veces para verlo en acción.
para activar o desactivar la opción de mostrar todas las plantas y aquellas de una zona de crecimiento específica, codificadas en la zona 9. Presiona el botón de filtro varias veces para verlo en acción.

Descripción general de la arquitectura
Esta app usa los componentes de la arquitectura para separar el código de IU en MainActivity y PlantListFragment de la lógica de la aplicación en PlantListViewModel. PlantRepository proporciona un puente entre ViewModel y PlantDao, que accede a la base de datos de Room a fin de mostrar una lista de objetos Plant. La IU tomará esta lista de plantas y las mostrará en el diseño de la cuadrícula de RecyclerView.
Antes de comenzar a modificar el código, observemos rápidamente cómo fluyen los datos de la base de datos a la IU. A continuación se muestra cómo se carga la lista de plantas en ViewModel:
PlantListViewModel.kt
val plants: LiveData<List<Plant>> = growZone.switchMap { growZone ->
if (growZone == NoGrowZone) {
plantRepository.plants
} else {
plantRepository.getPlantsWithGrowZone(growZone)
}
}
Una GrowZone es una clase intercalada que solo contiene un Int que representa su zona. NoGrowZone representa la ausencia de una zona y solo se usa para el filtrado.
Plant.kt
inline class GrowZone(val number: Int)
val NoGrowZone = GrowZone(-1)
El growZone se activará y desactivará cuando se presione el botón de filtro. Usaremos un switchMap a fin de determinar la lista de plantas que se mostrarán.
A continuación, se muestra el aspecto del repositorio y el objeto de acceso a datos (DAO) a la hora de recuperar los datos de plantas de la base de datos:
PlantDao.kt
@Query("SELECT * FROM plants ORDER BY name")
fun getPlants(): LiveData<List<Plant>>
@Query("SELECT * FROM plants WHERE growZoneNumber = :growZoneNumber ORDER BY name")
fun getPlantsWithGrowZoneNumber(growZoneNumber: Int): LiveData<List<Plant>>
PlantRepository.kt
val plants = plantDao.getPlants()
fun getPlantsWithGrowZone(growZone: GrowZone) =
plantDao.getPlantsWithGrowZoneNumber(growZone.number)
Si bien la mayoría de las modificaciones de código se encuentran en PlantListViewModel y PlantRepository, recomendamos que te familiarices con la estructura del proyecto y te enfoques en la forma en que se muestran los datos de la planta en las diferentes capas desde la base de datos hasta el Fragment. En el siguiente paso, modificaremos el código de modo que se agregue un criterio personalizado de orden mediante el compilador de LiveData.
La lista de plantas se muestra en orden alfabético, pero queremos cambiar ese orden a fin de mostrar algunas plantas primero y, luego, ordenar el resto alfabéticamente. Esto es similar a las apps de compras que muestran resultados patrocinados en la parte superior de una lista de artículos disponibles para la compra. Nuestro equipo de producto desea poder cambiar el orden de forma dinámica sin necesidad de lanzar una nueva versión de la app, por lo que primero obtendremos del backend la lista de plantas que ordenaremos.
Así se verá la app con el ordenamiento personalizado:
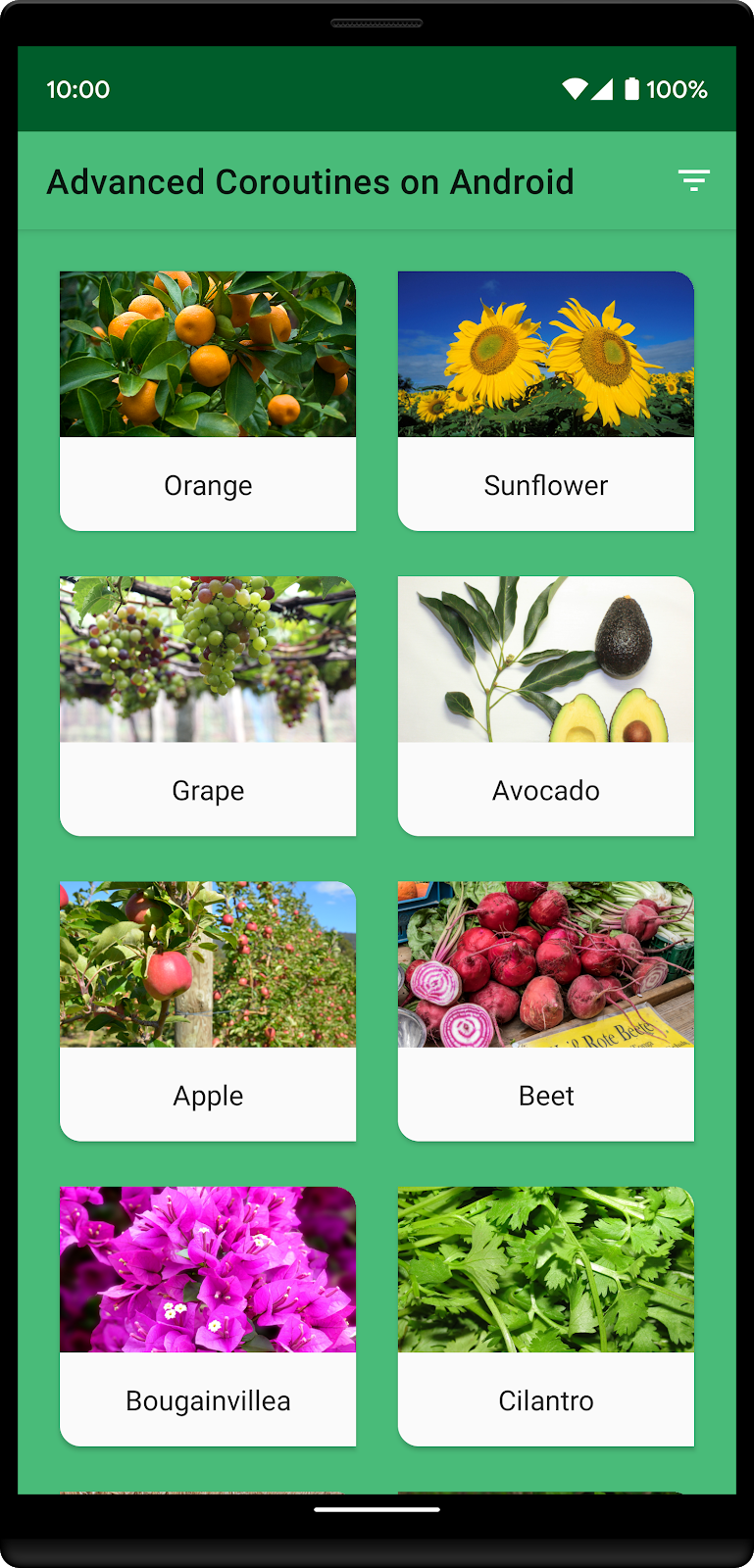
La lista de orden de clasificación personalizado consiste en estas cuatro plantas: naranjo, girasol, vid y aguacate. Observa cómo aparecen primero en la lista, seguidas por el resto de las plantas en orden alfabético.
Ahora, si presionas el botón de filtro (y solo se muestran las plantas de la GrowZone 9), el girasol desaparecerá de la lista porque su GrowZone no es 9. Las otras tres plantas de la lista de orden personalizado se encuentran en la GrowZone 9, de modo que permanecerán en la parte superior de la lista. La única otra planta en la GrowZone 9 es la tomatera, que aparecerá al final de esta lista.
Comencemos a escribir código a fin de implementar el orden personalizado.
Empezaremos escribiendo una función de suspensión para obtener el orden de clasificación personalizado de la red y, luego, almacenarlo en caché en la memoria.
Agrega lo siguiente a PlantRepository:
PlantRepository.kt
private var plantsListSortOrderCache =
CacheOnSuccess(onErrorFallback = { listOf<String>() }) {
plantService.customPlantSortOrder()
}
plantsListSortOrderCache se usa como caché en memoria para el orden de clasificación personalizado. Usará una lista vacía como resguardo en caso de que haya un error de red, de modo que nuestra app aún pueda mostrar datos, aunque no se recupere el orden de clasificación.
Este código usa la clase de utilidad CacheOnSuccess proporcionada en el módulo sunflower a fin de controlar el almacenamiento en caché. Cuando se quitan los detalles de la implementación del almacenamiento en caché como en este caso, el código de la aplicación resulta más sencillo. Dado que CacheOnSuccess ya se probó, no será necesario escribir tantas pruebas para nuestro repositorio a fin de que se garantice un comportamiento correcto. Te recomendamos que ingreses abstracciones de nivel superior similares en tu código cuando uses kotlinx-coroutines.
Ahora, incorporemos lógica para aplicar el ordenamiento a una lista de plantas.
Agrega lo siguiente a PlantRepository:
PlantRepository.kt
private fun List<Plant>.applySort(customSortOrder: List<String>): List<Plant> {
return sortedBy { plant ->
val positionForItem = customSortOrder.indexOf(plant.plantId).let { order ->
if (order > -1) order else Int.MAX_VALUE
}
ComparablePair(positionForItem, plant.name)
}
}
Esta función de extensión reorganizará la lista y colocará Plants que estén en el customSortOrder al principio de la lista.
Ahora que la lógica de ordenamiento está lista, reemplaza el código por plants y getPlantsWithGrowZone con el compilador de LiveData a continuación:
PlantRepository.kt
val plants: LiveData<List<Plant>> = liveData<List<Plant>> {
val plantsLiveData = plantDao.getPlants()
val customSortOrder = plantsListSortOrderCache.getOrAwait()
emitSource(plantsLiveData.map {
plantList -> plantList.applySort(customSortOrder)
})
}
fun getPlantsWithGrowZone(growZone: GrowZone) = liveData {
val plantsGrowZoneLiveData = plantDao.getPlantsWithGrowZoneNumber(growZone.number)
val customSortOrder = plantsListSortOrderCache.getOrAwait()
emitSource(plantsGrowZoneLiveData.map { plantList ->
plantList.applySort(customSortOrder)
})
}
Ahora, si ejecutas la app, debería aparecer la lista de plantas ordenada de forma personalizada:
El compilador de LiveData nos permite calcular valores de manera asíncrona, ya que liveData cuenta con el respaldo de corrutinas. Aquí tenemos una función de suspensión para recuperar una lista de LiveData de plantas desde la base de datos y llamar a una función de suspensión de modo que se obtenga el orden de clasificación personalizado. Luego, combinaremos estos dos valores a fin de ordenar la lista de plantas y mostrar el valor, todo dentro del compilador.
La corrutina comienza la ejecución cuando se la observa y se cancela cuando finaliza correctamente o falla la llamada de red o a la base de datos.
En el siguiente paso, exploraremos una variación de getPlantsWithGrowZone utilizando una Transformación.
Ahora, modificaremos PlantRepository para implementar una transformación de suspensión a medida que se procese cada valor, a fin de aprender a compilar transformaciones asíncronas complejas en LiveData. Como requisito previo, creemos una versión del algoritmo de ordenamiento que se pueda usar en el subproceso principal. Podemos usar withContext a los efectos de cambiar a otro despachador solo para la lambda y, luego, reanudar el despachador con el que comenzamos.
Agrega lo siguiente a PlantRepository:
PlantRepository.kt
@AnyThread
suspend fun List<Plant>.applyMainSafeSort(customSortOrder: List<String>) =
withContext(defaultDispatcher) {
this@applyMainSafeSort.applySort(customSortOrder)
}
Luego, podremos usar este nuevo orden seguro para el subproceso principal con el compilador de LiveData. Actualiza el bloque a fin de usar un switchMap, lo que te permitirá apuntar a un nuevo LiveData cada vez que se reciba un valor nuevo.
PlantRepository.kt
fun getPlantsWithGrowZone(growZone: GrowZone) =
plantDao.getPlantsWithGrowZoneNumber(growZone.number)
.switchMap { plantList ->
liveData {
val customSortOrder = plantsListSortOrderCache.getOrAwait()
emit(plantList.applyMainSafeSort(customSortOrder))
}
}
En comparación con la versión anterior, una vez que se reciba el orden de clasificación personalizado de la red, este se podrá usar con el nuevo applyMainSafeSort seguro para el subproceso principal. A su vez, este resultado se emitirá a switchMap como el valor nuevo que muestra getPlantsWithGrowZone.
Al igual que con el LiveData de plants que aparece más arriba, la corrutina comenzará la ejecución cuando se la observe y finalizará si se completa o si falla la llamada de red o a la base de datos. La diferencia aquí es que será seguro realizar la llamada de red en el mapa, ya que se almacenó en caché.
Ahora observemos cómo se implementa este código en Flow y comparemos las implementaciones.
Vamos a compilar la misma lógica usando Flow desde kotlinx-coroutines. Sin embargo, primero veremos qué es un flujo y cómo puedes incluirlo en tu app.
Un flujo es una versión asíncrona de una Secuencia, un tipo de colección cuyos valores se producen de manera diferida. Al igual que una secuencia, un flujo produce cada valor a pedido siempre que se lo necesita, y los flujos pueden contener una cantidad infinita de valores.
Entonces, ¿por qué Kotlin introdujo un nuevo tipo de Flow, y en qué se diferencia de una secuencia normal? La respuesta está en la magia de la asincronía. Flow incluye compatibilidad completa con corrutinas. Esto significa que puedes compilar, transformar y consumir un Flow mediante corrutinas. También puedes controlar la simultaneidad, lo que implica coordinar la ejecución de varias corrutinas de manera declarativa con Flow.
Esto abre muchas posibilidades emocionantes.
Flow puede usarse en un estilo de programación completamente reactivo. Si con anterioridad usaste un elemento similar a RxJava, Flow brinda funcionalidades similares. La lógica de la aplicación se puede expresar de forma concisa mediante la transformación de un flujo con operadores funcionales como map, flatMapLatest, combine, etcétera.
Flow también admite funciones de suspensión en la mayoría de los operadores. Esto te permitirá realizar tareas asíncronas secuenciales dentro de un operador como map. Cuando uses operaciones de suspensión dentro de un flujo, a menudo dará como resultado una codificación más corta y fácil de leer que el código equivalente en un estilo totalmente reactivo.
En este codelab, exploraremos los dos enfoques.
Cómo se ejecuta un flujo
Para acostumbrarse a la manera en que Flow produce valores a pedido (o de manera diferida), observa el siguiente flujo que emite los valores (1, 2, 3) e imprime antes y después de que se produzca cada elemento, así como durante el proceso.
fun makeFlow() = flow {
println("sending first value")
emit(1)
println("first value collected, sending another value")
emit(2)
println("second value collected, sending a third value")
emit(3)
println("done")
}
scope.launch {
makeFlow().collect { value ->
println("got $value")
}
println("flow is completed")
}
Si lo ejecutas, generará el siguiente resultado:
sending first value got 1 first value collected, sending another value got 2 second value collected, sending a third value got 3 done flow is completed
Puedes ver cómo rebota la ejecución entre la lambda collect y el compilador de flow. Cada vez que el compilador de flujo llame a emit, se suspends hasta que el elemento se procese por completo. Luego, cuando se solicite otro valor desde el flujo, se resumes desde el punto en que se detuvo hasta que se vuelva a emitir la llamada. Cuando se complete el compilador de flow, se cancelará el Flow y se reanudará la acción de collect, lo que permitirá que la corrutina que realiza la llamada imprima "se completó el flujo".
La llamada a collect es muy importante. Flow usa operadores de suspensión, como collect, en lugar de exponer una interfaz Iterator, de modo que siempre sepa cuándo se está consumiendo activamente. Más importante aún, sabe que el llamador no puede solicitar más valores para que pueda limpiar recursos.
Cuándo se ejecuta un flujo
El Flow del ejemplo anterior comienza a ejecutarse cuando lo hace el operador collect. Crear un Flow nuevo por medio de una llamada al compilador de flow o a otras API no hace que se ejecute ningún trabajo. El operador de suspensión collect se denomina operador de terminal en Flow. Hay otros operadores de terminal de suspensión, como toList, first y single enviados con kotlinx-coroutines, y tú puedes crear el tuyo.
De forma predeterminada, Flow se ejecutará en los siguientes casos:
- Cada vez que se aplique un operador de terminal (cada invocación nueva es independiente de otras que se hayan iniciado con anterioridad)
- Hasta que se cancele la corrutina en la que se esté ejecutando
- Cuando el último valor se procese por completo y se solicite otro valor
Debido a estas reglas, un Flow puede participar en la simultaneidad estructurada, y resulta seguro iniciar corrutinas de larga duración desde un Flow. No hay ninguna probabilidad de que Flow pierda recursos, ya que siempre se limpiarán por medio de reglas de cancelación cooperativas cuando se cancele el llamador.
Modifiquemos el flujo anterior para concentrarnos en los primeros dos elementos mediante el operador take y, luego, recopilémoslo dos veces.
scope.launch {
val repeatableFlow = makeFlow().take(2) // we only care about the first two elements
println("first collection")
repeatableFlow.collect()
println("collecting again")
repeatableFlow.collect()
println("second collection completed")
}
Si ejecutas el siguiente código, verás el resultado que se incluye a continuación:
first collection sending first value first value collected, sending another value collecting again sending first value first value collected, sending another value second collection completed
La lambda flow comienza desde el principio cada vez que se llama a collect. Esto es importante si el flujo realizó un trabajo costoso, como hacer una solicitud de red. Además, como aplicamos el operador take(2), el flujo solo producirá dos valores. No reanudará la lambda del flujo otra vez después de la segunda llamada a emit, por lo que la línea "second value collected…" (segundo valor recopilado…) no se imprimirá nunca.
El Flow es diferido como una Sequence, pero ¿cómo es asíncrono también? Veamos un ejemplo de una secuencia asíncrona que observa los cambios en una base de datos.
En este ejemplo, debemos coordinar los datos generados en un grupo de subprocesos de base de datos con observadores que viven en otro subproceso como el principal o de IU. Y, como emitiremos los resultados de manera repetida a medida que cambien los datos, esta situación es una opción ideal para un patrón de secuencia asíncrona.
Imagina que tienes la tarea de escribir la integración de Room para Flow. Si comenzaste con la compatibilidad para la búsqueda por suspensión en Room, puedes escribir algo como lo siguiente:
// This code is a simplified version of how Room implements flow
fun <T> createFlow(query: Query, tables: List<Tables>): Flow<T> = flow {
val changeTracker = tableChangeTracker(tables)
while(true) {
emit(suspendQuery(query))
changeTracker.suspendUntilChanged()
}
}
Este código se basa en dos funciones de suspensión imaginarias a fin de generar un Flow:
suspendQuery: Es una función segura para el subproceso principal que ejecuta una búsqueda de suspensión deRoomnormal.suspendUntilChanged: Es una función que suspende la corrutina hasta que una de las tablas cambia.
Cuando se recopila, el flujo emits inicialmente el primer valor de la búsqueda. Una vez que se procese ese valor, el flujo se reanudará y llamará a suspendUntilChanged, que, como indica, suspenderá el flujo hasta que cambie una de las tablas. En este punto, no pasará nada en el sistema hasta que una de las tablas cambie y se reanude el flujo.
Cuando eso ocurra, se realizará otra búsqueda segura para el subproceso principal y el flujo emits los resultados. Este proceso continúa en un bucle infinito.
Flujo y simultaneidad estructurada
No queremos que se produzcan pérdidas de trabajo. La corrutina no es muy costosa en sí, pero se activa varias veces para realizar una búsqueda en la base de datos. Eso es algo bastante costoso para perder.
Aunque creamos un bucle infinito, Flow nos ayudará mediante la compatibilidad con la simultaneidad estructurada.
La única forma de consumir valores o iterar un flujo es usar un operador de terminal. Debido a que todos estos operadores son funciones de suspensión, el trabajo estará vinculado al ciclo de vida del alcance que las llama. Cuando se cancele el alcance, el flujo se cancelará automáticamente mediante las reglas de cancelación cooperativas normales de las corrutinas. Por lo tanto, aunque escribimos un bucle infinito en el compilador de flujo, podemos consumirlo de forma segura sin pérdidas debido a la simultaneidad estructurada.
En este paso, aprenderás a usar Flow con Room y a vincularlo con la IU.
Este paso es común para muchos usos de Flow. Cuando se use de esta manera, el Flow de Room funcionará como una búsqueda de base de datos observable similar a un LiveData.
Actualiza el Dao
Para comenzar, abre PlantDao.kt y agrega dos búsquedas nuevas que muestren Flow<List<Plant>>:
PlantDao.kt
@Query("SELECT * from plants ORDER BY name")
fun getPlantsFlow(): Flow<List<Plant>>
@Query("SELECT * from plants WHERE growZoneNumber = :growZoneNumber ORDER BY name")
fun getPlantsWithGrowZoneNumberFlow(growZoneNumber: Int): Flow<List<Plant>>
Observa que, a excepción de los tipos de datos que se muestran, estas funciones son idénticas a las versiones de LiveData. Sin embargo, los desarrollaremos juntos a fin de compararlos.
Cuando se especifica Flow como el tipo de datos que se muestra, Room ejecuta la búsqueda con las siguientes características:
- Seguridad del subproceso principal: Las consultas con
Flowcomo el tipo de datos que se muestra siempre se ejecutarán en los ejecutores deRoom, por lo que siempre serán seguros para el subproceso principal. No necesitas hacer nada en tu código a fin de que se ejecuten desde el subproceso principal. - Observación de cambios:
Roomobservará automáticamente los cambios y emitirá valores nuevos al flujo. - Secuencia asíncrona:
Flowemitirá todo el resultado de la búsqueda en cada cambio y no introducirá búferes. Si muestras unaFlow<List<T>>, el flujo emitirá unaList<T>que contendrá todas las filas de los resultados de la búsqueda. Se ejecutará como una secuencia: se emitirá un resultado de la búsqueda por vez y se suspenderá hasta que se solicite el siguiente. - Capacidad de cancelación: Cuando se cancele el alcance que recopila estos flujos,
Roomcancelará la observación de esta búsqueda.
En conjunto, esto hará que Flow sea un gran tipo de datos que se muestra a los efectos de observar la base de datos desde la capa de IU.
Actualiza el repositorio
A fin de continuar vinculando los nuevos valores que se muestran con la IU, abre PlantRepository.kt y agrega el siguiente código:
PlantRepository.kt
val plantsFlow: Flow<List<Plant>>
get() = plantDao.getPlantsFlow()
fun getPlantsWithGrowZoneFlow(growZoneNumber: GrowZone): Flow<List<Plant>> {
return plantDao.getPlantsWithGrowZoneNumberFlow(growZoneNumber.number)
}
Por ahora, solo pasaremos los valores de Flow al llamador. Esto es exactamente lo mismo que cuando comenzamos este codelab, cuando pasamos el LiveData al ViewModel.
Actualiza el ViewModel
En PlantListViewModel.kt, comencemos con lo simple y expongamos el plantsFlow. Vamos a agregar el botón para activar y desactivar la zona de crecimiento en la versión del flujo que se encuentra en los próximos pasos.
PlantListViewModel.kt
// add a new property to plantListViewModel
val plantsUsingFlow: LiveData<List<Plant>> = plantRepository.plantsFlow.asLiveData()
Una vez más, conservaremos la versión de LiveData (val plants) para establecer comparaciones durante el proceso.
Como queremos conservar LiveData en la capa de IU de este codelab, usaremos la función de extensión asLiveData a fin de convertir nuestro Flow en un LiveData. Al igual que el compilador de LiveData, esto agregará un tiempo de espera configurable al LiveData generado. Esto es bueno, ya que evita que reiniciemos nuestra búsqueda cada vez que cambie la configuración (como ocurre cuando se rota el dispositivo).
Dado que el flujo ofrece la seguridad del subproceso principal y la capacidad de cancelación, puedes optar por pasar el Flow a la capa de IU sin convertirlo en un LiveData. Sin embargo, para este codelab, seguiremos usando LiveData en la capa de IU.
En el archivo ViewModel, agrega una actualización de la caché al bloque init. Por el momento, este paso es opcional, pero si borras la caché y no agregas esta llamada, no verás ningún dato en la app.
PlantListViewModel.kt
init {
clearGrowZoneNumber() // keep this
// fetch the full plant list
launchDataLoad { plantRepository.tryUpdateRecentPlantsCache() }
}
Actualiza Fragment
Abre PlantListFragment.kt y cambia la función subscribeUi para que apunte a nuestro nuevo LiveData de plantsUsingFlow.
PlantListFragment.kt
private fun subscribeUi(adapter: PlantAdapter) {
viewModel.plantsUsingFlow.observe(viewLifecycleOwner) { plants ->
adapter.submitList(plants)
}
}
Ejecuta la app con Flow
Si vuelves a ejecutar la app, deberías ver que estás cargando los datos usando Flow. Como todavía no implementamos switchMap, la opción de filtro no realizará ninguna acción.
En el siguiente paso, veremos cómo transformar los datos en un Flow.
En este paso, aplicarás el orden de clasificación a plantsFlow. Haremos esto con la API declarativa de flow.
Usamos transformaciones como map, combine y mapLatest a fin de expresar cómo nos gustaría transformar cada elemento a medida que pasa por el flujo de forma declarativa. También nos permite expresar simultaneidad de forma declarativa, lo que realmente simplifica el código. En esta sección, verás cómo puedes usar los operadores para indicarle a Flow que lance dos corrutinas y combine sus resultados de forma declarativa.
Para comenzar, abre PlantRepository.kt y define un nuevo flujo privado llamado customSortFlow:
PlantRepository.kt
private val customSortFlow = flow { emit(plantsListSortOrderCache.getOrAwait()) }
Esto define un Flow que, cuando se recopile, llamará a getOrAwait y emit el orden de clasificación.
Como este flujo solo emite un valor único, también puedes compilarlo directamente desde la función getOrAwait por medio de asFlow.
// Create a flow that calls a single function
private val customSortFlow = plantsListSortOrderCache::getOrAwait.asFlow()
Este código creará un Flow nuevo que llamará a getOrAwait y emitirá el resultado como su primer y único valor. Para ello, haz una referencia al método getOrAwait con :: y llama a asFlow en el objeto Function resultante.
Ambos flujos hacen lo mismo: llaman a getOrAwait y emiten el resultado antes de completarse.
Combina varios flujos de forma declarativa
Ahora que tenemos dos flujos, customSortFlow y plantsFlow, los combinaremos de forma declarativa.
Agrega un operador combine a plantsFlow:
PlantRepository.kt
private val customSortFlow = plantsListSortOrderCache::getOrAwait.asFlow()
val plantsFlow: Flow<List<Plant>>
get() = plantDao.getPlantsFlow()
// When the result of customSortFlow is available,
// this will combine it with the latest value from
// the flow above. Thus, as long as both `plants`
// and `sortOrder` are have an initial value (their
// flow has emitted at least one value), any change
// to either `plants` or `sortOrder` will call
// `plants.applySort(sortOrder)`.
.combine(customSortFlow) { plants, sortOrder ->
plants.applySort(sortOrder)
}
El operador combine combina dos flujos. Ambos flujos se ejecutarán en su propia corrutina y, cuando cualquiera de ellos produzca un valor nuevo, la transformación se llamará con el valor más reciente de estos.
Mediante el uso de combine, podemos combinar la búsqueda de red en caché con nuestra búsqueda en la base de datos. Ambas se ejecutarán en distintas corrutinas simultáneamente. Eso significa que, si bien Room iniciará la solicitud de red, Retrofit podrá iniciar la búsqueda de red. Luego, tan pronto como un resultado esté disponible para ambos flujos, este llamará a la lambda combine en la que aplicaremos el orden de clasificación para las plantas cargadas.
A fin de revisar cómo funciona el operador combine, modifica customSortFlow para emitir dos veces con una demora considerable en onStart de la siguiente manera:
// Create a flow that calls a single function
private val customSortFlow = plantsListSortOrderCache::getOrAwait.asFlow()
.onStart {
emit(listOf())
delay(1500)
}
La transformación onStart se producirá cuando un observador escuche antes otros operadores y podrá emitir valores de marcador de posición. Por lo tanto, emitiremos una lista vacía, retrasaremos la llamada a getOrAwait 1,500 ms y, luego, continuaremos con el flujo original. Si ejecutas la aplicación ahora, verás que la búsqueda de la base de datos de Room se mostrará de inmediato y se combinará con la lista vacía (es decir, se ordenará alfabéticamente). Después de alrededor de 1,500 ms, se aplicará el orden personalizado.
Antes de continuar con el codelab, quita la transformación onStart de customSortFlow.
Flujo y seguridad del subproceso principal
Flow puede llamar a funciones seguras para el subproceso principal, como estamos haciendo aquí, y conservará las garantías normales de seguridad de las corrutinas. Tanto Room como Retrofit nos proporcionarán una seguridad del subproceso principal, por lo que no necesitaremos tomar ninguna otra acción para realizar solicitudes de red o búsquedas de base de datos con Flow.
Este flujo ya usa los siguientes subprocesos:
plantService.customPlantSortOrderse ejecuta en un subproceso de Retrofit (llama aCall.enqueue).getPlantsFlowejecutará búsquedas en un Ejecutor de Room.applySortse ejecutará en el despachador de recopilaciones (en este caso,Dispatchers.Main).
Por lo tanto, si lo que estábamos haciendo solo era llamar a las funciones de suspensión en Retrofit y usar los flujos de Room, no tendríamos que complicar este código con cuestiones relacionadas con la seguridad del subproceso principal.
Sin embargo, a medida que el conjunto de datos crezca, es posible que la llamada a applySort se vuelva lo suficientemente lenta como para bloquear el subproceso principal. Flow ofrece una API declarativa llamada flowOn a fin de controlar en qué subproceso se ejecutará el flujo.
Agrega flowOn a plantsFlow de la siguiente manera:
PlantRepository.kt
private val customSortFlow = plantsListSortOrderCache::getOrAwait.asFlow()
val plantsFlow: Flow<List<Plant>>
get() = plantDao.getPlantsFlow()
.combine(customSortFlow) { plants, sortOrder ->
plants.applySort(sortOrder)
}
.flowOn(defaultDispatcher)
.conflate()
Llamar a flowOn tiene dos efectos importantes sobre la manera en que se ejecuta el código:
- Lanzará una corrutina nueva en el
defaultDispatcher(en este caso,Dispatchers.Default) a los efectos de ejecutar y recopilar el flujo antes de la llamada aflowOn. - Presentará un búfer para enviar resultados de la corrutina nueva a llamadas posteriores.
- Emitirá los valores de ese búfer al
Flowdespués deflowOn. En este caso, seráasLiveDataen elViewModel.
Esto es muy similar al funcionamiento de withContext para cambiar de despachador, pero introduce un búfer en medio de nuestras transformaciones que cambia la forma en que funciona el flujo. La corrutina que lanza flowOn puede producir resultados más rápido que lo que el emisor los consume y almacenar en búfer una gran cantidad de ellos de forma predeterminada.
En este caso, planeamos enviar los resultados a la IU, por lo que solo nos interesará el resultado más reciente. Eso es lo que hace el operador conflate: modifica el búfer de flowOn de modo que se almacene solo el último resultado. Si aparece otro resultado antes de que se lea el anterior, este se reemplazará.
Ejecuta la app
Si vuelves a ejecutar la app, deberías ver que estás cargando los datos y aplicando el orden de clasificación personalizado usando Flow. Como todavía no implementamos switchMap, la opción de filtro no realizará ninguna acción.
En el siguiente paso, analizaremos otra forma de proporcionar seguridad al subproceso principal por medio de flow.
Para finalizar la versión de flujo de esta API, abre PlantListViewModel.kt y cambia los flujos según la GrowZone, como lo hacemos en la versión LiveData.
Agrega el siguiente código debajo del liveData de plants:
PlantListViewModel.kt
private val growZoneFlow = MutableStateFlow<GrowZone>(NoGrowZone)
val plantsUsingFlow: LiveData<List<Plant>> = growZoneFlow.flatMapLatest { growZone ->
if (growZone == NoGrowZone) {
plantRepository.plantsFlow
} else {
plantRepository.getPlantsWithGrowZoneFlow(growZone)
}
}.asLiveData()
En este patrón, se muestra cómo integrar eventos (cambios de zona de crecimiento) en un flujo. Hará exactamente lo mismo que la versión LiveData.switchMap, que alterna entre dos fuentes de datos según un evento.
Recorre el código
PlantListViewModel.kt
private val growZoneFlow = MutableStateFlow<GrowZone>(NoGrowZone)
Esto define un MutableStateFlow nuevo con un valor inicial de NoGrowZone. Se trata de un tipo especial de contenedor de valor de Flow que contendrá solo el último valor proporcionado. Es una primitiva de simultaneidad segura para subprocesos, por lo que puedes escribir en ella desde varios subprocesos al mismo tiempo (y prevalecerá lo que se considere "último").
También puedes suscribirte a fin de recibir actualizaciones sobre el valor actual. En términos generales, tiene un comportamiento similar a un LiveData: solo contendrá el último valor y te permitirá observar los cambios en él.
PlantListViewModel.kt
val plantsUsingFlow: LiveData<List<Plant>> = growZoneFlow.flatMapLatest { growZone ->
StateFlow también es un Flow normal, por lo que puedes usar todos los operadores como lo harías normalmente.
Aquí, usamos el operador flatMapLatest, que es exactamente el mismo que switchMap de LiveData. Cuando growZone cambie su valor, se aplicará esta lambda y ella deberá mostrar un Flow. Luego, el Flow que se muestra se usará como el Flow para todos los operadores descendentes.
En esencia, esto nos permite alternar entre diferentes flujos según el valor de growZone.
PlantListViewModel.kt
if (growZone == NoGrowZone) {
plantRepository.plantsFlow
} else {
plantRepository.getPlantsWithGrowZoneFlow(growZone)
}
Dentro del flatMapLatest, alternaremos según la growZone. Este código es casi el mismo que el de la versión de LiveData.switchMap. La única diferencia es que muestra Flows en lugar de LiveDatas.
PlantListViewModel.kt
}.asLiveData()
Por último, convertiremos el Flow en un LiveData, ya que nuestro Fragment espera que se exponga un LiveData del ViewModel.
Cambia un valor de StateFlow
A fin de permitir que la app detecte el cambio de filtro, podemos configurar MutableStateFlow.value. Esta es una manera fácil de comunicar un evento a una corrutina como estamos haciendo aquí.
PlantListViewModel.kt
fun setGrowZoneNumber(num: Int) {
growZone.value = GrowZone(num)
growZoneFlow.value = GrowZone(num)
launchDataLoad {
plantRepository.tryUpdateRecentPlantsForGrowZoneCache(GrowZone(num)) }
}
fun clearGrowZoneNumber() {
growZone.value = NoGrowZone
growZoneFlow.value = NoGrowZone
launchDataLoad {
plantRepository.tryUpdateRecentPlantsCache()
}
}
Vuelve a ejecutar la app
Si vuelves a ejecutar la app, el filtro ahora funcionará tanto para la versión LiveData como para la versión Flow.
En el siguiente paso, aplicaremos el ordenamiento personalizado a getPlantsWithGrowZoneFlow.
Una de las funciones más interesantes de Flow es su compatibilidad de primera clase con las funciones de suspensión. El compilador de flow y casi todas las transformaciones exponen un operador suspend que puede llamar a cualquier función de suspensión. Como resultado, se puede usar la seguridad del subproceso principal para las llamadas a bases de datos, así como para organizar varias operaciones asíncronas con llamadas a funciones de suspensión regulares desde el flujo.
De hecho, esto te permite combinar transformaciones declarativas con código imperativo de forma natural. Como verás en este ejemplo, dentro de un operador de mapa normal puedes organizar varias operaciones asíncronas sin aplicar transformaciones adicionales. En muchos lugares, esto puede lograr un código mucho más simple que el de un enfoque totalmente declarativo.
Usa funciones de suspensión con el fin de organizar el trabajo asíncrono
Para finalizar la exploración de Flow, aplicaremos el ordenamiento personalizado mediante los operadores de suspensión.
Abre PlantRepository.kt y agrega una transformación de mapa a getPlantsWithGrowZoneNumberFlow.
PlantRepository.kt
fun getPlantsWithGrowZoneFlow(growZone: GrowZone): Flow<List<Plant>> {
return plantDao.getPlantsWithGrowZoneNumberFlow(growZone.number)
.map { plantList ->
val sortOrderFromNetwork = plantsListSortOrderCache.getOrAwait()
val nextValue = plantList.applyMainSafeSort(sortOrderFromNetwork)
nextValue
}
}
Dado que depende de funciones de suspensión normales para controlar el trabajo asíncrono, esta operación de mapa resultará segura para el subproceso principal aunque combina dos operaciones asíncronas.
A medida que se muestre cada resultado de la base de datos, obtendremos el orden de clasificación en caché. Si aún no está listo, esperará la solicitud de red asíncrona. Una vez que tengamos el orden de clasificación, será seguro llamar a applyMainSafeSort, que ejecutará el ordenamiento en el despachador predeterminado.
Ahora este código será totalmente seguro para el subproceso principal, ya que remitirá las cuestiones de seguridad de ese subproceso a las funciones de suspensión normales. Es un poco más simple que la misma transformación implementada en plantsFlow.
Sin embargo, cabe señalar que se ejecutará de una forma un poco diferente. El valor almacenado en caché se recuperará cada vez que la base de datos emita un valor nuevo. Esto está bien porque se almacena en caché de manera correcta en plantsListSortOrderCache, pero si con esto se inicia una nueva solicitud de red, esta implementación realizará numerosas solicitudes de red innecesarias. Además, en la versión .combine, la solicitud de red y la búsqueda en la base de datos se ejecutarán simultáneamente, mientras que en esta versión lo harán de forma secuencial.
Debido a estas diferencias, no hay una regla clara para estructurar este código. En muchos casos, está bien usar transformaciones de suspensión como estamos haciendo aquí, lo que hace que todas las operaciones asíncronas sean secuenciales. Sin embargo, en otros casos, será mejor usar operadores a fin de controlar la simultaneidad y proporcionar la seguridad del subproceso principal.
Ya casi Como paso final (opcional), pasemos las solicitudes de red a una corrutina basada en el flujo.
De esta manera, quitaremos la lógica para realizar llamadas de red desde los controladores que onClick llama y los sacaremos de la growZone. Esto nos ayudará a crear una sola fuente de confianza y a evitar la duplicación de código. No hay forma de que un código pueda cambiar el filtro sin actualizar la caché.
Abre PlantListViewModel.kt y agrega lo siguiente al bloque init:
PlantListViewModel.kt
init {
clearGrowZoneNumber()
growZone.mapLatest { growZone ->
_spinner.value = true
if (growZone == NoGrowZone) {
plantRepository.tryUpdateRecentPlantsCache()
} else {
plantRepository.tryUpdateRecentPlantsForGrowZoneCache(growZone)
}
}
.onEach { _spinner.value = false }
.catch { throwable -> _snackbar.value = throwable.message }
.launchIn(viewModelScope)
}
Este código lanzará una corrutina nueva a los efectos de observar los valores enviados a growZoneChannel. Ya puedes comentar las llamadas de red en los métodos que se muestran a continuación, dado que solo serán necesarias para la versión de LiveData.
PlantListViewModel.kt
fun setGrowZoneNumber(num: Int) {
growZone.value = GrowZone(num)
growZoneFlow.value = GrowZone(num)
// launchDataLoad {
// plantRepository.tryUpdateRecentPlantsForGrowZoneCache(GrowZone(num))
// }
}
fun clearGrowZoneNumber() {
growZone.value = NoGrowZone
growZoneFlow.value = NoGrowZone
// launchDataLoad {
// plantRepository.tryUpdateRecentPlantsCache()
// }
}
Vuelve a ejecutar la app
Si vuelves a ejecutar la app, verás que la actualización de la red ahora está controlada por la growZone. Mejoramos el código de forma sustancial, ya que habrá más formas de cambiar el filtro y el canal funcionará como una única fuente de confianza para la cual el filtro estará activo. De esa manera, la solicitud de red y el filtro actual nunca podrán desincronizarse.
Recorre el código
Analicemos de a una todas las funciones nuevas utilizadas, comenzando desde el exterior:
PlantListViewModel.kt
growZone
// ...
.launchIn(viewModelScope)
Esta vez, usaremos el operador launchIn para recopilar el flujo dentro de nuestro ViewModel.
El operador launchIn creará una corrutina nueva y recopilará cada uno de los valores del flujo. Se lanzará en el CoroutineScope proporcionado; en este caso, viewModelScope. Esto es genial porque significa que, cuando se borre este ViewModel, se cancelará la recopilación.
Si no proporcionamos ningún otro operador, esto no hará demasiado. Sin embargo, como Flow proporciona lambdas de suspensión en todos sus operadores, resultará fácil realizar acciones asíncronas en función de cada valor.
PlantListViewModel.kt
.mapLatest { growZone ->
_spinner.value = true
if (growZone == NoGrowZone) {
plantRepository.tryUpdateRecentPlantsCache()
} else {
plantRepository.tryUpdateRecentPlantsForGrowZoneCache(growZone)
}
}
Aquí es donde radica la magia: mapLatest aplicará esta función de mapa para cada valor. Sin embargo, a diferencia del map normal, este lanzará una corrutina nueva para cada llamada a la transformación de mapa. Luego, si growZoneChannel emite un nuevo valor antes de que se complete la corrutina anterior, la cancelará antes de iniciar una nueva.
Podemos usar mapLatest para controlar la simultaneidad. En lugar de compilar una lógica de cancelación/reinicio, la transformación del flujo podrá encargarse de ella. Esto ahorra mucho código y complejidad en comparación con escribir la misma lógica de cancelación de forma manual.
La cancelación de un Flow sigue las reglas de cancelación cooperativas normales de las corrutinas.
PlantListViewModel.kt
.onEach { _spinner.value = false }
.catch { throwable -> _snackbar.value = throwable.message }
Se llamará a onEach cada vez que el flujo anterior emita un valor. Aquí lo estamos usando para restablecer el ícono giratorio después de que se complete el procesamiento.
El operador catch capturará cualquier excepción que se arroje arriba en el flujo y podrá emitir un nuevo valor al flujo como un estado de error, volver a arrojar la excepción al flujo o realizar el trabajo como estamos haciendo aquí.
Cuando haya un error, solo le diremos a nuestra _snackbar que muestre el mensaje de error.
Finalización
En este paso, se mostró la manera en que puedes controlar la simultaneidad mediante Flow y consumir Flows dentro de un ViewModel sin depender de un observador de la IU.
A modo de desafío, define una función que encapsule la carga de datos de este flujo con la siguiente firma:
fun <T> loadDataFor(source: StateFlow<T>, block: suspend (T) -> Unit) {