
कोरूटीन में, फ़्लो एक ऐसा टाइप है जिससे कई वैल्यू निकल सकती हैं क्रम में, ये ऐसे सस्पेंड फ़ंक्शन इस्तेमाल करते हैं जो सिर्फ़ नतीजे दिखाते हैं का इस्तेमाल करें. उदाहरण के लिए, लाइव जाने के लिए फ़्लो का इस्तेमाल किया जा सकता है किसी डेटाबेस से अपडेट होते हैं.
फ़्लो, कोरूटीन पर बने होते हैं और एक से ज़्यादा वैल्यू दे सकते हैं.
सैद्धांतिक रूप से फ़्लो, डेटा की एक स्ट्रीम है, जिसका हिसाब लगाया जा सकता है
एसिंक्रोनस रूप से. जनरेट की गई वैल्यू एक ही तरह की होनी चाहिए. इसके लिए
उदाहरण के लिए, Flow<Int> ऐसा फ़्लो है जिससे पूर्णांक वैल्यू निकलती हैं.
कोई फ़्लो काफ़ी हद तक Iterator की तरह होता है, जो
वैल्यू बनाई गई है, लेकिन वैल्यू बनाने और उनका इस्तेमाल करने के लिए, सस्पेंड फ़ंक्शन का इस्तेमाल किया गया है
एसिंक्रोनस रूप से. उदाहरण के लिए, इसका मतलब है कि फ़्लो, सुरक्षित तरीके से
मुख्य साइट को ब्लॉक किए बिना, नेटवर्क अनुरोध अगली वैल्यू जनरेट करता है
थ्रेड.
डेटा की स्ट्रीम में तीन इकाइयां शामिल होती हैं:
- प्रोड्यूसर, स्ट्रीम में जोड़ा जाने वाला डेटा बनाता है. इन्हें धन्यवाद कोरूटीन, फ़्लो भी एसिंक्रोनस तरीके से डेटा दे सकते हैं.
- (ज़रूरी नहीं) मध्यस्थ, का इस्तेमाल करें.
- उपभोक्ता, स्ट्रीम से मिली वैल्यू का इस्तेमाल करता है.
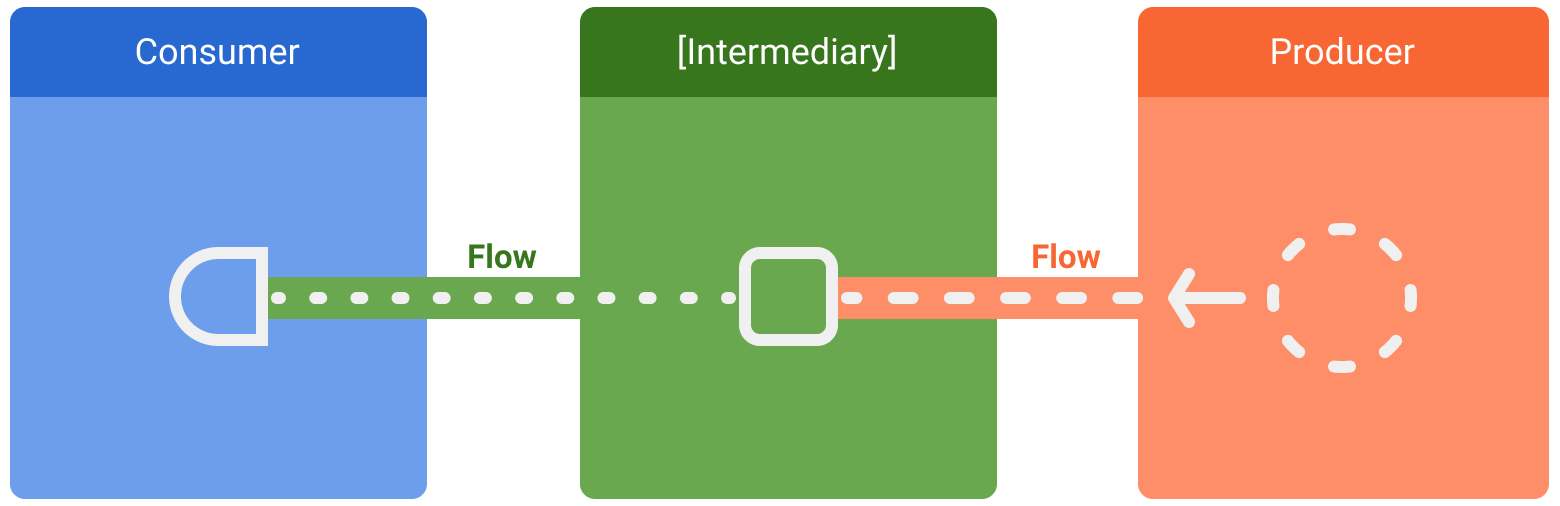
Android में, डेटा स्टोर करने की जगह यह यूज़र इंटरफ़ेस (यूआई) डेटा का प्रोड्यूसर है, जिसमें उपभोक्ता के तौर पर यूज़र इंटरफ़ेस (यूआई) होता है जो आखिर में डेटा दिखाती है. अन्य मामलों में, यूज़र इंटरफ़ेस (यूआई) लेयर यूज़र इनपुट इवेंट और हैरारकी की अन्य लेयर इनका इस्तेमाल करती हैं. इसमें लेयर उत्पादक और उपभोक्ता के बीच आम तौर पर मध्यस्थों की तरह काम करते हैं जो का इस्तेमाल किया जा सकता है.
कोई फ़्लो बनाना
फ़्लो बनाने के लिए,
फ़्लो बिल्डर
एपीआई. flow बिल्डर फ़ंक्शन एक नया फ़्लो बनाता है, जहां मैन्युअल तरीके से
इसका इस्तेमाल करके डेटा स्ट्रीम में नई वैल्यू छोड़ सकते हैं
emit
फ़ंक्शन का इस्तेमाल करना होगा.
यहां दिए गए उदाहरण में, एक डेटा सोर्स नई खबरें फ़ेच करता है एक तय समय में अपने-आप माइग्रेट हो जाता है. निलंबित फ़ंक्शन के तौर पर, ये काम नहीं किए जा सकते लगातार एक से ज़्यादा वैल्यू दिखाता है. डेटा सोर्स बनाता और दिखाता है फ़्लो के बारे में ज़्यादा जानकारी मिलेगी. इस मामले में, डेटा सोर्स .
class NewsRemoteDataSource(
private val newsApi: NewsApi,
private val refreshIntervalMs: Long = 5000
) {
val latestNews: Flow<List<ArticleHeadline>> = flow {
while(true) {
val latestNews = newsApi.fetchLatestNews()
emit(latestNews) // Emits the result of the request to the flow
delay(refreshIntervalMs) // Suspends the coroutine for some time
}
}
}
// Interface that provides a way to make network requests with suspend functions
interface NewsApi {
suspend fun fetchLatestNews(): List<ArticleHeadline>
}
flow बिल्डर को कोरूटीन में एक्ज़ीक्यूट किया जाता है. इस तरह, इससे फ़ायदा होता है
कुछ सुविधाएं लागू होंगी, लेकिन इन पर कुछ पाबंदियां लागू होती हैं:
- फ़्लो क्रम में होते हैं. कॉल करते समय, क्योंकि प्रोड्यूसर कोरूटीन में होता है
जब तक सस्पेंड फ़ंक्शन नहीं होता, तब तक प्रोड्यूसर इस फ़ंक्शन को निलंबित नहीं करता
वापस करना. उदाहरण में, निर्माता
fetchLatestNewsतक निलंबित करता है नेटवर्क अनुरोध पूरा होता है. इसके बाद ही, स्ट्रीम में नतीजा दिखाया जाता है. flowबिल्डर से, निर्माता किसीemitभिन्नCoroutineContext. इसलिए,emitको किसी दूसरे नंबर पर कॉल न करें नए कोरूटीन बनाकर याwithContextका इस्तेमाल करके,CoroutineContextकोड के ब्लॉक. आपके पास अन्य फ़्लो बिल्डर इस्तेमाल करने का भी विकल्प होता है, जैसे किcallbackFlowशामिल हैं.
स्ट्रीम में बदलाव करना
मध्यस्थ, स्ट्रीम में बदलाव करने के लिए इंटरमीडिएट ऑपरेटर का इस्तेमाल कर सकते हैं इस्तेमाल नहीं किया जा सकता. ये ऑपरेटर ऐसे फ़ंक्शन होते हैं जो डेटा की स्ट्रीम पर लागू किया जा सकता है. ऐसी कार्रवाइयों की चेन सेट अप करें जो आने वाले समय में वैल्यू के पूरा होने तक लागू किया जाता है. इसके बारे में ज़्यादा जानें इंटरमीडिएट ऑपरेटर फ़्लो रेफ़रंस दस्तावेज़.
नीचे दिए गए उदाहरण में, रिपॉज़िटरी लेयर, इंटरमीडिएट ऑपरेटर का इस्तेमाल करती है
map
View पर दिखाए जाने वाले डेटा को बदलने के लिए:
class NewsRepository(
private val newsRemoteDataSource: NewsRemoteDataSource,
private val userData: UserData
) {
/**
* Returns the favorite latest news applying transformations on the flow.
* These operations are lazy and don't trigger the flow. They just transform
* the current value emitted by the flow at that point in time.
*/
val favoriteLatestNews: Flow<List<ArticleHeadline>> =
newsRemoteDataSource.latestNews
// Intermediate operation to filter the list of favorite topics
.map { news -> news.filter { userData.isFavoriteTopic(it) } }
// Intermediate operation to save the latest news in the cache
.onEach { news -> saveInCache(news) }
}
एक के बाद एक इंटरमीडिएट ऑपरेटर लागू किए जा सकते हैं, जिससे एक चेन बन जाती है ऐसे ऑपरेशन जो तब किए जाते हैं, जब किसी आइटम को फ़्लो. ध्यान दें कि किसी स्ट्रीम पर इंटरमीडिएट ऑपरेटर लागू करने से फ़्लो कलेक्शन शुरू नहीं करते.
फ़्लो से इकट्ठा करना
सुनना शुरू करने के लिए, फ़्लो को ट्रिगर करने के लिए, टर्मिनल ऑपरेटर का इस्तेमाल करें
वैल्यू. स्ट्रीम में उत्सर्जन के हिसाब से सभी वैल्यू पाने के लिए, इसका इस्तेमाल करें
collect.
टर्मिनल ऑपरेटर के बारे में ज़्यादा जानने के लिए,
आधिकारिक फ़्लो से जुड़ा दस्तावेज़.
collect एक सस्पेंड फ़ंक्शन है, इसलिए इसे
एक कोरूटीन. यह एक पैरामीटर के रूप में lambda को लेता है, जिसे कॉल किया जाता है
को भी शामिल कर सकता है. क्योंकि यह एक सस्पेंड फ़ंक्शन है, इसलिए इस
फ़्लो बंद होने तक, collect कॉल निलंबित किए जा सकते हैं.
पिछले उदाहरण में, यहां दिए गए तरीके को
रिपॉज़िटरी लेयर से डेटा इस्तेमाल करने वाला ViewModel:
class LatestNewsViewModel(
private val newsRepository: NewsRepository
) : ViewModel() {
init {
viewModelScope.launch {
// Trigger the flow and consume its elements using collect
newsRepository.favoriteLatestNews.collect { favoriteNews ->
// Update View with the latest favorite news
}
}
}
}
फ़्लो इकट्ठा करने से प्रोड्यूसर ताज़ा खबरें रीफ़्रेश करते हैं
और यह एक तय इंटरवल में नेटवर्क अनुरोध का नतीजा दिखाता है. जिस तरह
स्ट्रीम while(true) लूप के साथ, प्रोड्यूसर हमेशा ऐक्टिव रहता है
का डेटा बंद हो जाएगा, जब ViewModel साफ़ होगा और
viewModelScope रद्द कर दी गई है.
इन वजहों से फ़्लो इकट्ठा करना बंद हो सकता है:
- जैसा कि पिछले उदाहरण में दिखाया गया है, इकट्ठा किया जाने वाला कोरूटीन रद्द कर दिया जाता है. इससे पहले से मौजूद प्रोड्यूसर भी रुक जाते हैं.
- मैन्युफ़ैक्चरर उन आइटम को बाहर निकालता है जो इनका उत्सर्जन करते हैं. इस मामले में, डेटा की स्ट्रीम
बंद है और
collectजिस कोरूटीन को कहते हैं वह फिर से एक्ज़ीक्यूशन करना शुरू कर देता है.
फ़्लो ठंडा और लेज़ी होता है. हालांकि, किसी दूसरे इंटरमीडिएट
ऑपरेटर का इस्तेमाल करें. इसका मतलब है कि निर्माता कोड हर बार उस समय निष्पादित होता है जब
टर्मिनल ऑपरेटर को फ़्लो पर कॉल किया जाता है. पिछले उदाहरण में,
एक से ज़्यादा फ़्लो कलेक्टर होने से डेटा सोर्स
अलग-अलग तय इंटरवल पर कई बार ताज़ा खबरें दी जाती हैं. ऑप्टिमाइज़ करने और
जब कई उपभोक्ता एक साथ डेटा इकट्ठा करते हैं, तो फ़्लो शेयर करने के लिए,
shareIn ऑपरेटर.
ऐसे अपवाद दिख रहे हैं जिनकी उम्मीद नहीं थी
निर्माता को लागू करने की प्रक्रिया, किसी तीसरे पक्ष की लाइब्रेरी से हो सकती है.
इसका मतलब है कि इसमें ऐसे अपवाद भी हो सकते हैं जिनकी उम्मीद न हो. मैनेज करने के लिए
अपवाद के तौर पर,
catch
इंटरमीडिएट ऑपरेटर.
class LatestNewsViewModel(
private val newsRepository: NewsRepository
) : ViewModel() {
init {
viewModelScope.launch {
newsRepository.favoriteLatestNews
// Intermediate catch operator. If an exception is thrown,
// catch and update the UI
.catch { exception -> notifyError(exception) }
.collect { favoriteNews ->
// Update View with the latest favorite news
}
}
}
}
पिछले उदाहरण में, कोई अपवाद होने पर, collect
लैम्डा को कॉल नहीं किया गया, क्योंकि कोई नया आइटम नहीं मिला है.
catch, फ़्लो में emit आइटम भी दे सकता है. डेटा स्टोर करने की जगह का उदाहरण
लेयर इसके बजाय, कैश मेमोरी में सेव की गई वैल्यू emit कर सकती है:
class NewsRepository(...) {
val favoriteLatestNews: Flow<List<ArticleHeadline>> =
newsRemoteDataSource.latestNews
.map { news -> news.filter { userData.isFavoriteTopic(it) } }
.onEach { news -> saveInCache(news) }
// If an error happens, emit the last cached values
.catch { exception -> emit(lastCachedNews()) }
}
इस उदाहरण में, कोई अपवाद होने पर, collect lambda यह है
कॉल किया गया है, क्योंकि स्ट्रीम में नया आइटम उत्सर्जित किया गया है क्योंकि
अपवाद.
किसी अलग CoroutineContext में एक्ज़ीक्यूट करना
डिफ़ॉल्ट रूप से, flow बिल्डर का प्रोड्यूसर
CoroutineContext कोरूटीन से इकट्ठा किया जाता है.
जैसा कि पहले बताया गया है, यह किसी अन्यemit
CoroutineContext. कुछ मामलों में ऐसा करने की ज़रूरत नहीं होती.
उदाहरण के लिए, इस विषय में इस्तेमाल किए गए उदाहरणों में, डेटा स्टोर करने की जगह
लेयर को उस Dispatchers.Main पर कार्रवाई नहीं करनी चाहिए जो
viewModelScope ने इसका इस्तेमाल किया है.
किसी फ़्लो का CoroutineContext बदलने के लिए, इंटरमीडिएट ऑपरेटर का इस्तेमाल करें
flowOn.
flowOn, अपस्ट्रीम फ़्लो के CoroutineContext को बदल देता है, इसका मतलब है
प्रोड्यूसर और किसी भी इंटरमीडिएट ऑपरेटर को पहले (या ऊपर) लागू किया गया हो
flowOn. डाउनस्ट्रीम फ़्लो (flowOn के बाद इंटरमीडिएट ऑपरेटर
साथ ही, उपभोक्ता) प्रभावित नहीं होती है और
फ़्लो से collect तक CoroutineContext इस्तेमाल किया गया. अगर कोई
कई flowOn ऑपरेटर होते हैं, जिनमें से हर एक ऑपरेटर को इसके
आपकी जगह की जानकारी.
class NewsRepository(
private val newsRemoteDataSource: NewsRemoteDataSource,
private val userData: UserData,
private val defaultDispatcher: CoroutineDispatcher
) {
val favoriteLatestNews: Flow<List<ArticleHeadline>> =
newsRemoteDataSource.latestNews
.map { news -> // Executes on the default dispatcher
news.filter { userData.isFavoriteTopic(it) }
}
.onEach { news -> // Executes on the default dispatcher
saveInCache(news)
}
// flowOn affects the upstream flow ↑
.flowOn(defaultDispatcher)
// the downstream flow ↓ is not affected
.catch { exception -> // Executes in the consumer's context
emit(lastCachedNews())
}
}
इस कोड के साथ, onEach और map ऑपरेटर defaultDispatcher,
जबकि catch ऑपरेटर और उपभोक्ता को इस पर एक्ज़ीक्यूट किया जाता है
viewModelScope ने Dispatchers.Main इस्तेमाल किया.
डेटा सोर्स लेयर, I/O से जुड़े काम कर रहा है. इसलिए, आपको डिस्पैचर का इस्तेमाल करना चाहिए जो I/O कार्रवाइयों के लिए ऑप्टिमाइज़ किया गया है:
class NewsRemoteDataSource(
...,
private val ioDispatcher: CoroutineDispatcher
) {
val latestNews: Flow<List<ArticleHeadline>> = flow {
// Executes on the IO dispatcher
...
}
.flowOn(ioDispatcher)
}
Jetpack लाइब्रेरी में फ़्लो
फ़्लो को कई Jetpack लाइब्रेरी में इंटिग्रेट किया गया है. साथ ही, यह इन लाइब्रेरी के बीच लोकप्रिय है Android पर तीसरे पक्ष की लाइब्रेरी. फ़्लो, लाइव डेटा अपडेट के लिए सबसे सही है और डेटा का कभी न खत्म होने वाला होता है.
Google Analytics 4 पर माइग्रेट करने के लिए,
रूम के साथ खुशहाली
सूचना मिलती है. इसका इस्तेमाल करते समय
डेटा ऐक्सेस ऑब्जेक्ट (डीएओ),
लाइव अपडेट पाने के लिए, Flow टाइप दिखाएं.
@Dao
abstract class ExampleDao {
@Query("SELECT * FROM Example")
abstract fun getExamples(): Flow<List<Example>>
}
जब भी Example टेबल में कोई बदलाव होता है, तो एक नई सूची जनरेट होती है
डेटाबेस में नए आइटम के साथ शुरुआत करते हैं.
कॉलबैक आधारित एपीआई को फ़्लो में बदलना
callbackFlow
एक फ़्लो बिल्डर है जो आपको कॉलबैक-आधारित एपीआई को फ़्लो में बदलने देता है.
उदाहरण के लिए, Firebase Firestore
Android के एपीआई, कॉलबैक का इस्तेमाल करते हैं.
इन एपीआई को फ़्लो में बदलने और Firestore डेटाबेस के अपडेट सुनने के लिए, आपको इस कोड का इस्तेमाल कर सकता है:
class FirestoreUserEventsDataSource(
private val firestore: FirebaseFirestore
) {
// Method to get user events from the Firestore database
fun getUserEvents(): Flow<UserEvents> = callbackFlow {
// Reference to use in Firestore
var eventsCollection: CollectionReference? = null
try {
eventsCollection = FirebaseFirestore.getInstance()
.collection("collection")
.document("app")
} catch (e: Throwable) {
// If Firebase cannot be initialized, close the stream of data
// flow consumers will stop collecting and the coroutine will resume
close(e)
}
// Registers callback to firestore, which will be called on new events
val subscription = eventsCollection?.addSnapshotListener { snapshot, _ ->
if (snapshot == null) { return@addSnapshotListener }
// Sends events to the flow! Consumers will get the new events
try {
trySend(snapshot.getEvents())
} catch (e: Throwable) {
// Event couldn't be sent to the flow
}
}
// The callback inside awaitClose will be executed when the flow is
// either closed or cancelled.
// In this case, remove the callback from Firestore
awaitClose { subscription?.remove() }
}
}
flow बिल्डर, callbackFlow के उलट
अलग-अलग CoroutineContext से वैल्यू उत्सर्जित करने की अनुमति देता है.
send
फ़ंक्शन या कोरूटीन के बाहर मौजूद है.
trySend
फ़ंक्शन का इस्तेमाल करना होगा.
अंदरूनी तौर पर, callbackFlow
चैनल,
जो सैद्धांतिक तौर पर ब्लॉकिंग
सूची.
चैनल को capacity के साथ कॉन्फ़िगर किया गया है, जो कि एलिमेंट की ज़्यादा से ज़्यादा संख्या हो सकती है
जिसे बफ़र किया जा सकता है. callbackFlow में बनाए गए चैनल की डिफ़ॉल्ट वैल्यू यह है
64 एलिमेंट की क्षमता. जब आप पूरे डेटा में कोई नया एलिमेंट जोड़ने की कोशिश करते हैं
जब तक नए चैनल के लिए जगह नहीं बचती, तब तक send चैनल प्रोड्यूसर को निलंबित कर देगा
एलिमेंट शामिल होता है, जबकि trySend, चैनल में एलिमेंट नहीं जोड़ता और वापस
false तुरंत.
trySend बताए गए एलिमेंट को चैनल में तुरंत जोड़ देता है,
यदि इससे इसकी क्षमता से संबंधित प्रतिबंधों का उल्लंघन नहीं होता है और तब यह
सफल नतीजा.
फ़्लो के अन्य संसाधन
- Android पर Kotlin की जांच करना
StateFlowऔरSharedFlow- Kotlin कोरूटीन और फ़्लो के लिए अतिरिक्त संसाधन