
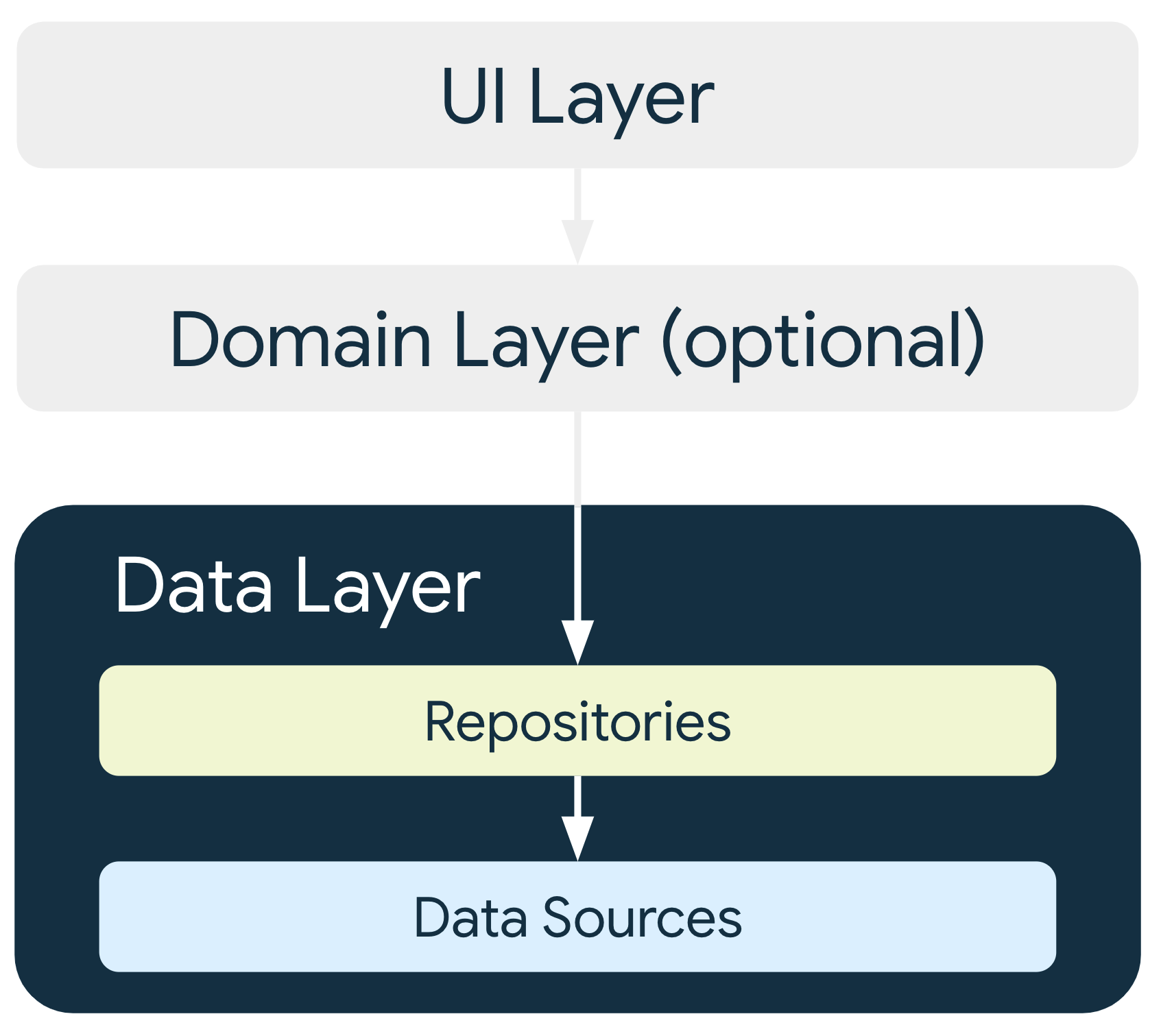
यूज़र इंटरफ़ेस (यूआई) लेयर में, यूआई से जुड़ी स्थिति और यूआई लॉजिक होता है. वहीं, डेटा लेयर में ऐप्लिकेशन डेटा और कारोबार से जुड़ा लॉजिक होता है. बिज़नेस लॉजिक, आपके ऐप्लिकेशन को वैल्यू देता है. यह रीयल-वर्ल्ड (असल) बिज़नेस के नियमों से बना होता है. इससे यह तय होता है कि ऐप्लिकेशन का डेटा कैसे बनाया, सेव किया, और बदला जाना चाहिए.
इस तरह से, डेटा लेयर को कई स्क्रीन पर इस्तेमाल किया जा सकता है. साथ ही, ऐप्लिकेशन के अलग-अलग हिस्सों के बीच जानकारी शेयर की जा सकती है. इसके अलावा, यूनिट टेस्टिंग के लिए यूज़र इंटरफ़ेस (यूआई) से बाहर कारोबार के लॉजिक को फिर से बनाया जा सकता है. डेटा लेयर के फ़ायदों के बारे में ज़्यादा जानने के लिए, आर्किटेक्चर की खास जानकारी वाला पेज देखें.
डेटा लेयर का आर्किटेक्चर
डेटा लेयर, रिपॉज़िटरी से बनी होती है. हर रिपॉज़िटरी में, शून्य से लेकर कई डेटा सोर्स हो सकते हैं. आपको अपने ऐप्लिकेशन में मैनेज किए जाने वाले हर तरह के डेटा के लिए, एक रिपॉज़िटरी क्लास बनानी चाहिए. उदाहरण के लिए, फ़िल्मों से जुड़े डेटा के लिए MoviesRepository क्लास या पेमेंट से जुड़े डेटा के लिए PaymentsRepository क्लास बनाई जा सकती है.
रिपॉज़िटरी क्लास, ये काम करती हैं:
- डेटा को ऐप्लिकेशन के बाकी हिस्सों के लिए उपलब्ध कराना.
- डेटा में किए गए बदलावों को एक जगह पर मैनेज करना.
- एक से ज़्यादा डेटा सोर्स के बीच होने वाले टकरावों को हल करना.
- डेटा के सोर्स को बाकी ऐप्लिकेशन से एब्स्ट्रैक्ट करना.
- इसमें कारोबारी नियम शामिल होते हैं.
हर डेटा सोर्स क्लास की ज़िम्मेदारी सिर्फ़ एक डेटा सोर्स के साथ काम करने की होनी चाहिए. यह डेटा सोर्स कोई फ़ाइल, नेटवर्क सोर्स या लोकल डेटाबेस हो सकता है. डेटा सोर्स क्लास, डेटा ऑपरेशन के लिए ऐप्लिकेशन और सिस्टम के बीच एक पुल की तरह काम करती हैं.
क्रम में मौजूद अन्य लेयर को डेटा सोर्स को सीधे तौर पर ऐक्सेस नहीं करना चाहिए. डेटा लेयर के एंट्री पॉइंट हमेशा रिपॉज़िटरी क्लास होते हैं. स्टेट होल्डर क्लास (यूज़र इंटरफ़ेस लेयर की गाइड देखें) या इस्तेमाल के उदाहरण वाली क्लास (डोमेन लेयर की गाइड देखें) में, डेटा सोर्स को कभी भी सीधे तौर पर डिपेंडेंसी के तौर पर नहीं रखना चाहिए. रिपॉज़िटरी क्लास को एंट्री पॉइंट के तौर पर इस्तेमाल करने से, आर्किटेक्चर की अलग-अलग लेयर को स्वतंत्र रूप से स्केल किया जा सकता है.
इस लेयर से दिखने वाला डेटा, बदला नहीं जा सकता. ऐसा इसलिए, ताकि दूसरी क्लास इसमें बदलाव न कर पाएं. इससे इसकी वैल्यू में गड़बड़ी हो सकती है. बदला न जा सकने वाला डेटा, कई थ्रेड से भी सुरक्षित तरीके से मैनेज किया जा सकता है. ज़्यादा जानकारी के लिए, थ्रेडिंग सेक्शन देखें.
डिपेंडेंसी इंजेक्शन के सबसे सही तरीकों के मुताबिक, रिपॉज़िटरी अपने कंस्ट्रक्टर में डेटा सोर्स को डिपेंडेंसी के तौर पर लेती है:
class ExampleRepository(
private val exampleRemoteDataSource: ExampleRemoteDataSource, // network
private val exampleLocalDataSource: ExampleLocalDataSource // database
) { /* ... */ }
एपीआई उपलब्ध कराना
डेटा लेयर में मौजूद क्लास, आम तौर पर एक बार में बनाने, पढ़ने, अपडेट करने, और मिटाने (CRUD) के कॉल करने के लिए फ़ंक्शन उपलब्ध कराती हैं. इसके अलावा, समय के साथ डेटा में होने वाले बदलावों के बारे में सूचना पाने के लिए भी फ़ंक्शन उपलब्ध कराती हैं. इन सभी मामलों के लिए, डेटा लेयर को यह जानकारी देनी चाहिए:
- एक बार में होने वाली कार्रवाइयों के लिए, सस्पेंड फ़ंक्शन दिखाएं.
- समय के साथ डेटा में होने वाले बदलावों की सूचना पाने के लिए, फ़्लो को दिखाएं.
class ExampleRepository(
private val exampleRemoteDataSource: ExampleRemoteDataSource, // network
private val exampleLocalDataSource: ExampleLocalDataSource // database
) {
val data: Flow<Example> = ...
suspend fun modifyData(example: Example) { ... }
}
इस गाइड में नेमिंग कनवेंशन
इस गाइड में, रिपॉज़िटरी क्लास के नाम उस डेटा के हिसाब से रखे गए हैं जिसके लिए वे ज़िम्मेदार हैं. कन्वेंशन इस तरह है:
डेटा का टाइप + Repository.
उदाहरण के लिए: NewsRepository, MoviesRepository या PaymentsRepository.
डेटा सोर्स क्लास के नाम, उस डेटा के हिसाब से रखे जाते हैं जिसके लिए वे ज़िम्मेदार होती हैं. साथ ही, उस सोर्स के हिसाब से भी नाम रखे जाते हैं जिसका वे इस्तेमाल करती हैं. कन्वेंशन इस तरह है:
type of data + type of source + DataSource.
डेटा के टाइप के लिए, रिमोट या लोकल का इस्तेमाल करें, ताकि यह ज़्यादा सामान्य हो. ऐसा इसलिए, क्योंकि लागू करने के तरीके बदल सकते हैं. उदाहरण के लिए: NewsRemoteDataSource या NewsLocalDataSource. अगर सोर्स अहम है, तो उसके बारे में ज़्यादा जानकारी देने के लिए, सोर्स के टाइप का इस्तेमाल करें. उदाहरण के लिए: NewsNetworkDataSource या NewsDiskDataSource.
डेटा सोर्स का नाम, लागू करने के तरीके के आधार पर न रखें. उदाहरण के लिए,
UserSharedPreferencesDataSource. ऐसा इसलिए, क्योंकि उस डेटा सोर्स का इस्तेमाल करने वाली रिपॉज़िटरी को यह पता नहीं होना चाहिए कि डेटा कैसे सेव किया जाता है. इस नियम का पालन करने पर, डेटा सोर्स को लागू करने के तरीके में बदलाव किया जा सकता है. उदाहरण के लिए, SharedPreferences से DataStore पर माइग्रेट किया जा सकता है. इससे उस लेयर पर कोई असर नहीं पड़ता जो उस सोर्स को कॉल करती है.
एक से ज़्यादा लेवल की रिपॉज़िटरी
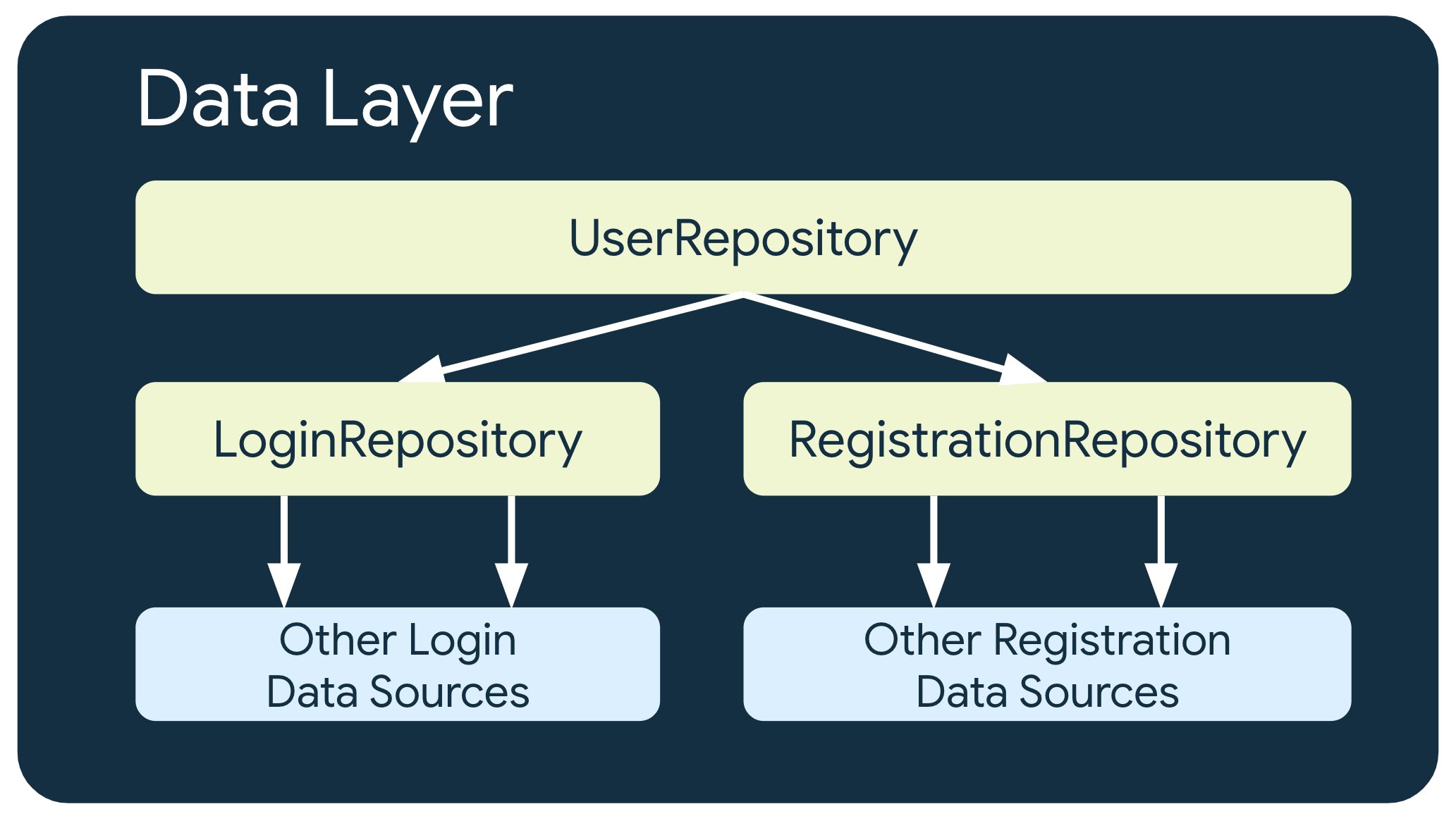
कारोबार की ज़्यादा जटिल ज़रूरतों वाले कुछ मामलों में, किसी रिपॉज़िटरी को दूसरी रिपॉज़िटरी पर निर्भर रहना पड़ सकता है. ऐसा इसलिए हो सकता है, क्योंकि इसमें शामिल डेटा कई डेटा सोर्स से एग्रीगेट किया गया है. इसके अलावा, ऐसा इसलिए भी हो सकता है, क्योंकि ज़िम्मेदारी को किसी अन्य रिपॉज़िटरी क्लास में शामिल करना ज़रूरी है.
उदाहरण के लिए, उपयोगकर्ता की पहचान की पुष्टि करने वाले डेटा को मैनेज करने वाली रिपॉज़िटरी UserRepository, अपनी ज़रूरतों को पूरा करने के लिए अन्य रिपॉज़िटरी पर निर्भर हो सकती है. जैसे, LoginRepository और RegistrationRepository.
सही और पूरी जानकारी का सोर्स
यह ज़रूरी है कि हर रिपॉज़िटरी, डेटा के लिए एक ही भरोसेमंद सोर्स तय करे. सोर्स ऑफ़ ट्रुथ में हमेशा ऐसा डेटा होता है जो एक जैसा, सही, और अप-टू-डेट होता है. दरअसल, रिपॉज़िटरी से दिखने वाला डेटा हमेशा, भरोसेमंद सोर्स से मिलने वाला डेटा होना चाहिए.
सोर्स ऑफ़ ट्रुथ, कोई डेटा सोर्स हो सकता है. उदाहरण के लिए, डेटाबेस. यह कोई इन-मेमोरी कैश भी हो सकता है, जो रिपॉज़िटरी में मौजूद हो सकता है. डेटा सोर्स को एक साथ लाने के लिए रिपॉज़िटरी का इस्तेमाल किया जाता है. साथ ही, डेटा सोर्स के बीच होने वाले किसी भी संभावित टकराव को हल किया जाता है. इससे, सिंगल सोर्स ऑफ़ ट्रुथ को नियमित तौर पर अपडेट किया जा सकता है. इसके अलावा, उपयोगकर्ता के इनपुट इवेंट की वजह से भी इसे अपडेट किया जा सकता है.
आपके ऐप्लिकेशन में मौजूद अलग-अलग रिपॉज़िटरी में, डेटा के अलग-अलग सोर्स हो सकते हैं. उदाहरण के लिए, LoginRepository क्लास, सोर्स ऑफ़ ट्रूथ के तौर पर अपनी कैश मेमोरी का इस्तेमाल कर सकती है. वहीं, PaymentsRepository क्लास, नेटवर्क डेटा सोर्स का इस्तेमाल कर सकती है.
ऑफ़लाइन-फ़र्स्ट ऐप्लिकेशन के लिए, स्थानीय डेटा सोर्स—जैसे कि डेटाबेस—को सोर्स ऑफ़ ट्रुथ के तौर पर इस्तेमाल करने का सुझाव दिया जाता है.
थ्रेडिंग
डेटा सोर्स और रिपॉज़िटरी को कॉल करने वाले फ़ंक्शन main-safe होने चाहिए. इसका मतलब है कि उन्हें मुख्य थ्रेड से कॉल किया जा सकता है. ये क्लास, लंबे समय तक चलने वाले ब्लॉकिंग ऑपरेशन करते समय, अपने लॉजिक को सही थ्रेड पर ले जाने के लिए ज़िम्मेदार होती हैं. उदाहरण के लिए, किसी डेटा सोर्स के लिए फ़ाइल से डेटा पढ़ना सुरक्षित होना चाहिए. इसी तरह, किसी रिपॉज़िटरी के लिए बड़ी सूची पर फ़िल्टरिंग करना सुरक्षित होना चाहिए.
ध्यान दें कि ज़्यादातर डेटा सोर्स पहले से ही मुख्य थ्रेड को ब्लॉक न करने वाले एपीआई उपलब्ध कराते हैं. जैसे, Room, Retrofit या Ktor से उपलब्ध कराए गए suspend मेथड कॉल. जब ये एपीआई उपलब्ध हों, तब आपकी रिपॉज़िटरी इनका फ़ायदा ले सकती है.
थ्रेडिंग के बारे में ज़्यादा जानने के लिए, बैकग्राउंड प्रोसेसिंग से जुड़ी गाइड देखें. Kotlin का इस्तेमाल करने वाले लोगों के लिए, कोरूटीन का इस्तेमाल करने का सुझाव दिया जाता है.
लाइफ़साइकल
डेटा लेयर में मौजूद क्लास के इंस्टेंस, मेमोरी में तब तक बने रहते हैं, जब तक उन्हें गार्बेज कलेक्शन रूट से ऐक्सेस किया जा सकता है. आम तौर पर, ऐसा तब होता है, जब उन्हें आपके ऐप्लिकेशन में मौजूद अन्य ऑब्जेक्ट से रेफ़र किया जाता है.
अगर किसी क्लास में इन-मेमोरी डेटा है, जैसे कि कैश मेमोरी, तो हो सकता है कि आपको उस क्लास के एक ही इंस्टेंस का इस्तेमाल किसी खास अवधि के लिए फिर से करना हो. इसे क्लास इंस्टेंस का लाइफ़साइकल भी कहा जाता है.
अगर क्लास की ज़िम्मेदारी पूरे ऐप्लिकेशन के लिए ज़रूरी है, तो उस क्लास के इंस्टेंस को Application क्लास के लिए स्कोप किया जा सकता है. इससे इंस्टेंस, ऐप्लिकेशन के लाइफ़साइकल को फ़ॉलो करता है. इसके अलावा, अगर आपको अपने ऐप्लिकेशन के किसी फ़्लो में सिर्फ़ एक ही इंस्टेंस का फिर से इस्तेमाल करना है, तो आपको उस इंस्टेंस को उस क्लास के स्कोप में रखना चाहिए जो उस फ़्लो के लाइफ़साइकल का मालिक है. उदाहरण के लिए, रजिस्ट्रेशन या लॉगिन फ़्लो. उदाहरण के लिए, मेमोरी में मौजूद डेटा वाले RegistrationRepository को RegistrationActivity या NavEntryDecorator का इस्तेमाल करके बैकस्टैक में स्कोप किया जा सकता है.
हर इंस्टेंस का लाइफ़साइकल, यह तय करने में अहम भूमिका निभाता है कि आपके ऐप्लिकेशन में डिपेंडेंसी कैसे दी जाएं. हमारा सुझाव है कि आप डिपेंडेंसी इंजेक्शन के सबसे सही तरीकों का पालन करें. इससे डिपेंडेंसी को मैनेज किया जा सकता है और उन्हें डिपेंडेंसी कंटेनर के दायरे में रखा जा सकता है. Android में स्कोपिंग के बारे में ज़्यादा जानने के लिए, Android और Hilt में स्कोपिंग ब्लॉग पोस्ट पढ़ें.
कारोबार के मॉडल के बारे में जानकारी देना
डेटा लेयर से दिखाए जाने वाले डेटा मॉडल, अलग-अलग डेटा सोर्स से मिली जानकारी का सबसेट हो सकते हैं. आदर्श रूप से, नेटवर्क और लोकल, दोनों तरह के अलग-अलग डेटा सोर्स को सिर्फ़ वह जानकारी देनी चाहिए जिसकी आपके ऐप्लिकेशन को ज़रूरत है. हालांकि, ऐसा अक्सर नहीं होता.
उदाहरण के लिए, मान लें कि News API का कोई सर्वर है. यह लेख की जानकारी के साथ-साथ, बदलाव का इतिहास, उपयोगकर्ता की टिप्पणियां, और कुछ मेटाडेटा भी दिखाता है:
data class ArticleApiModel(
val id: Long,
val title: String,
val content: String,
val publicationDate: Date,
val modifications: Array<ArticleApiModel>,
val comments: Array<CommentApiModel>,
val lastModificationDate: Date,
val authorId: Long,
val authorName: String,
val authorDateOfBirth: Date,
val readTimeMin: Int
)
ऐप्लिकेशन को लेख के बारे में ज़्यादा जानकारी की ज़रूरत नहीं होती, क्योंकि यह सिर्फ़ स्क्रीन पर लेख का कॉन्टेंट दिखाता है. साथ ही, इसके लेखक के बारे में बुनियादी जानकारी दिखाता है. मॉडल क्लास को अलग-अलग रखना एक अच्छा तरीका है. साथ ही, आपकी रिपॉज़िटरी सिर्फ़ उस डेटा को दिखाती हैं जिसकी ज़रूरत हाइरार्की की अन्य लेयर को होती है. उदाहरण के लिए, यहां बताया गया है कि डोमेन और यूज़र इंटरफ़ेस (यूआई) लेयर को ArticleApiModel मॉडल क्लास दिखाने के लिए, नेटवर्क से ArticleApiModel को कैसे कम किया जा सकता है:Article
data class Article(
val id: Long,
val title: String,
val content: String,
val publicationDate: Date,
val authorName: String,
val readTimeMin: Int
)
मॉडल क्लास को अलग-अलग करने से ये फ़ायदे मिलते हैं:
- यह सिर्फ़ ज़रूरी डेटा को सेव करता है, जिससे ऐप्लिकेशन की मेमोरी बचती है.
- यह बाहरी डेटा टाइप को आपके ऐप्लिकेशन में इस्तेमाल किए गए डेटा टाइप के हिसाब से बदलता है. उदाहरण के लिए, आपका ऐप्लिकेशन तारीखों को दिखाने के लिए किसी दूसरे डेटा टाइप का इस्तेमाल कर सकता है.
- इससे काम को बेहतर तरीके से बांटा जा सकता है. उदाहरण के लिए, अगर मॉडल क्लास पहले से तय है, तो बड़ी टीम के सदस्य किसी सुविधा की नेटवर्क और यूज़र इंटरफ़ेस (यूआई) लेयर पर अलग-अलग काम कर सकते हैं.
इस तरीके को बढ़ाया जा सकता है. साथ ही, अपने ऐप्लिकेशन आर्किटेक्चर के अन्य हिस्सों में अलग-अलग मॉडल क्लास तय की जा सकती हैं. उदाहरण के लिए, डेटा सोर्स क्लास और ViewModels में. हालांकि, इसके लिए आपको अतिरिक्त क्लास और लॉजिक तय करने होंगे. आपको इनका दस्तावेज़ बनाना होगा और इनकी जांच करनी होगी. हमारा सुझाव है कि आप कम से कम उन मामलों में नए मॉडल बनाएं जहां किसी डेटा सोर्स को ऐसा डेटा मिलता है जो आपके ऐप्लिकेशन के बाकी डेटा से मेल नहीं खाता.
डेटा ऑपरेशन के टाइप
डेटा लेयर, अलग-अलग तरह की कार्रवाइयों को मैनेज कर सकती है. ये कार्रवाइयां, उनकी अहमियत के हिसाब से अलग-अलग होती हैं: यूज़र इंटरफ़ेस (यूआई) से जुड़ी कार्रवाइयां, ऐप्लिकेशन से जुड़ी कार्रवाइयां, और कारोबार से जुड़ी कार्रवाइयां.
यूज़र इंटरफ़ेस (यूआई) से जुड़ी कार्रवाइयां
यूज़र इंटरफ़ेस से जुड़ी कार्रवाइयां सिर्फ़ तब काम की होती हैं, जब उपयोगकर्ता किसी खास स्क्रीन पर होता है. साथ ही, जब उपयोगकर्ता उस स्क्रीन से हट जाता है, तो ये कार्रवाइयां रद्द हो जाती हैं. उदाहरण के लिए, डेटाबेस से मिला कुछ डेटा दिखाया जा रहा है.
यूज़र इंटरफ़ेस (यूआई) से जुड़े ऑपरेशन आम तौर पर यूज़र इंटरफ़ेस (यूआई) लेयर से ट्रिगर होते हैं. साथ ही, ये कॉलर के लाइफ़साइकल को फ़ॉलो करते हैं. उदाहरण के लिए, ViewModel का लाइफ़साइकल. यूज़र इंटरफ़ेस (यूआई) से जुड़ी कार्रवाई के उदाहरण के लिए, नेटवर्क अनुरोध करना सेक्शन देखें.
ऐप्लिकेशन से जुड़ी कार्रवाइयां
ऐप्लिकेशन से जुड़ी कार्रवाइयां तब तक काम करती हैं, जब तक ऐप्लिकेशन खुला रहता है. ऐप्लिकेशन बंद होने या प्रोसेस के रुकने पर, ये कार्रवाइयां रद्द हो जाती हैं. उदाहरण के लिए, नेटवर्क अनुरोध के नतीजे को कैश मेमोरी में सेव करना, ताकि ज़रूरत पड़ने पर बाद में उसका इस्तेमाल किया जा सके. ज़्यादा जानने के लिए, मेमोरी में मौजूद डेटा को कैश मेमोरी में सेव करने की सुविधा लागू करना सेक्शन देखें.
ये कार्रवाइयां आम तौर पर Application क्लास या डेटा लेयर की लाइफ़साइकल के हिसाब से होती हैं. उदाहरण के लिए, स्क्रीन पर दिखने वाले समय से ज़्यादा समय तक किसी ऑपरेशन को लाइव रखना सेक्शन देखें.
कारोबार से जुड़ी कार्रवाइयां
कारोबार से जुड़े ऑपरेशंस को रद्द नहीं किया जा सकता. इन्हें प्रोसेस बंद होने के बाद भी सेव रहना चाहिए. उदाहरण के लिए, उपयोगकर्ता को अपनी प्रोफ़ाइल पर कोई फ़ोटो पोस्ट करनी है. इस फ़ोटो को अपलोड करने की प्रोसेस पूरी होने में समय लगता है.
कारोबार से जुड़ी कार्रवाइयों के लिए, WorkManager का इस्तेमाल करने का सुझाव दिया जाता है. ज़्यादा जानने के लिए, WorkManager का इस्तेमाल करके टास्क शेड्यूल करना सेक्शन देखें.
गड़बड़ियों के बारे में जानकारी देना
डेटा के सोर्स और रिपॉज़िटरी के साथ इंटरैक्शन, या तो सफल हो सकते हैं या किसी गड़बड़ी के होने पर अपवाद दिखा सकते हैं. को-रूटीन और फ़्लो के लिए, आपको Kotlin के पहले से मौजूद गड़बड़ी ठीक करने वाले सिस्टम का इस्तेमाल करना चाहिए. निलंबित किए गए फ़ंक्शन की वजह से होने वाली गड़बड़ियों के लिए, ज़रूरत के हिसाब से try/catch ब्लॉक का इस्तेमाल करें. साथ ही, फ़्लो में catch ऑपरेटर का इस्तेमाल करें. इस तरीके में, यूज़र इंटरफ़ेस (यूआई) लेयर को डेटा लेयर को कॉल करते समय अपवादों को हैंडल करना होता है.
डेटा लेयर, अलग-अलग तरह की गड़बड़ियों को समझ सकती है और उन्हें ठीक कर सकती है. साथ ही, कस्टम अपवादों का इस्तेमाल करके उन्हें दिखा सकती है. उदाहरण के लिए, UserNotAuthenticatedException.
T
कोरूटीन में होने वाली गड़बड़ियों के बारे में ज़्यादा जानने के लिए, कोरूटीन में अपवाद ब्लॉग पोस्ट पढ़ें.
सामान्य कार्य
यहां दिए गए सेक्शन में, Android ऐप्लिकेशन में आम तौर पर किए जाने वाले कुछ टास्क के लिए, डेटा लेयर का इस्तेमाल करने और उसे डिज़ाइन करने के उदाहरण दिए गए हैं. ये उदाहरण, इस गाइड में पहले बताए गए सामान्य समाचार ऐप्लिकेशन पर आधारित हैं.
नेटवर्क अनुरोध करना
नेटवर्क अनुरोध करना, Android ऐप्लिकेशन के सबसे सामान्य टास्क में से एक है. News ऐप्लिकेशन को उपयोगकर्ता को नेटवर्क से फ़ेच की गई ताज़ा खबरें दिखानी चाहिए. इसलिए, ऐप्लिकेशन को नेटवर्क ऑपरेशन मैनेज करने के लिए, डेटा सोर्स क्लास की ज़रूरत होती है: NewsRemoteDataSource. ऐप्लिकेशन के बाकी हिस्सों को जानकारी देने के लिए, खबरों के डेटा पर कार्रवाइयां करने वाली नई रिपॉज़िटरी बनाई जाती है: NewsRepository.
ज़रूरी है कि जब उपयोगकर्ता स्क्रीन खोले, तब हमेशा नई खबरें अपडेट की जाएं. इसलिए, यह यूज़र इंटरफ़ेस (यूआई) से जुड़ा ऑपरेशन है.
डेटा सोर्स बनाना
डेटा सोर्स को एक ऐसा फ़ंक्शन उपलब्ध कराना होगा जो ताज़ा खबरें दिखाता हो. जैसे, ArticleHeadline इंस्टेंस की सूची. डेटा सोर्स को नेटवर्क से नई खबरें पाने के लिए, मुख्य फ़्रेम में सुरक्षित तरीके से काम करने वाला तरीका उपलब्ध कराना होगा. इसके लिए, इसे CoroutineDispatcher या Executor पर निर्भर रहना पड़ता है, ताकि टास्क को चलाया जा सके.
नेटवर्क का अनुरोध करना, एक बार किया जाने वाला कॉल है. इसे नए fetchLatestNews()
तरीके से हैंडल किया जाता है:
class NewsRemoteDataSource(
private val newsApi: NewsApi,
private val ioDispatcher: CoroutineDispatcher
) {
/**
* Fetches the latest news from the network and returns the result.
* This executes on an IO-optimized thread pool, the function is main-safe.
*/
suspend fun fetchLatestNews(): List<ArticleHeadline> =
// Move the execution to an IO-optimized thread since the ApiService
// doesn't support coroutines and makes synchronous requests.
withContext(ioDispatcher) {
newsApi.fetchLatestNews()
}
}
// Makes news-related network synchronous requests.
interface NewsApi {
fun fetchLatestNews(): List<ArticleHeadline>
}
NewsApi इंटरफ़ेस, नेटवर्क एपीआई क्लाइंट को लागू करने की प्रोसेस को छिपाता है. इससे कोई फ़र्क़ नहीं पड़ता कि इंटरफ़ेस को Retrofit या HttpURLConnection से बैकअप लिया गया है. इंटरफ़ेस पर भरोसा करने से, एपीआई को लागू करने के तरीके को आपके ऐप्लिकेशन में बदला जा सकता है.
डेटाबेस बनाना
इस टास्क के लिए, रिपॉज़िटरी क्लास में किसी अतिरिक्त लॉजिक की ज़रूरत नहीं होती. इसलिए, NewsRepository नेटवर्क डेटा सोर्स के लिए प्रॉक्सी के तौर पर काम करता है. ऐब्स्ट्रैक्शन की इस अतिरिक्त लेयर को जोड़ने के फ़ायदों के बारे में, इन-मेमोरी कैश मेमोरी सेक्शन में बताया गया है.
// NewsRepository is consumed from other layers of the hierarchy.
class NewsRepository(
private val newsRemoteDataSource: NewsRemoteDataSource
) {
suspend fun fetchLatestNews(): List<ArticleHeadline> =
newsRemoteDataSource.fetchLatestNews()
}
यूज़र इंटरफ़ेस (यूआई) लेयर से सीधे तौर पर रिपॉज़िटरी क्लास का इस्तेमाल करने का तरीका जानने के लिए, यूज़र इंटरफ़ेस (यूआई) लेयर गाइड देखें.
मेमोरी में डेटा कैश करने की सुविधा लागू करना
मान लें कि News ऐप्लिकेशन के लिए एक नई ज़रूरी शर्त जोड़ी गई है: जब उपयोगकर्ता स्क्रीन खोले, तो उसे कैश की गई खबरें दिखनी चाहिए. हालांकि, ऐसा तब ही होना चाहिए, जब पहले कोई अनुरोध किया गया हो. अगर ऐसा नहीं है, तो ऐप्लिकेशन को नेटवर्क अनुरोध करना चाहिए, ताकि वह ताज़ा खबरें फ़ेच कर सके.
नई ज़रूरी शर्त के मुताबिक, जब तक उपयोगकर्ता ने ऐप्लिकेशन खोला हुआ है, तब तक ऐप्लिकेशन को मेमोरी में नई खबरें सेव करके रखनी होंगी. इसलिए, यह ऐप्लिकेशन से जुड़ा ऑपरेशन है.
कैश मेमोरी
उपयोगकर्ता के ऐप्लिकेशन में रहने के दौरान, डेटा को सुरक्षित रखा जा सकता है. इसके लिए, इन-मेमोरी डेटा कैशिंग की सुविधा जोड़ें. कैश का इस्तेमाल, कुछ जानकारी को मेमोरी में सेव करने के लिए किया जाता है. ऐसा कुछ समय के लिए किया जाता है. इस मामले में, जब तक उपयोगकर्ता ऐप्लिकेशन में रहता है, तब तक जानकारी सेव रहती है. कैश को अलग-अलग तरीकों से लागू किया जा सकता है. ये वैरिएबल, सामान्य तौर पर बदलाव किए जा सकने वाले वैरिएबल से लेकर, ज़्यादा बेहतर क्लास तक हो सकते हैं. ये क्लास, कई थ्रेड पर रीड/राइट ऑपरेशन से सुरक्षा करती हैं. इस्तेमाल के उदाहरण के आधार पर, कैश मेमोरी को रिपॉज़िटरी या डेटा सोर्स क्लास में लागू किया जा सकता है.
नेटवर्क अनुरोध के नतीजे को कैश मेमोरी में सेव करना
आसानी से समझने के लिए, NewsRepository ने एक ऐसे वैरिएबल का इस्तेमाल किया है जिसमें बदलाव किया जा सकता है. इससे, ताज़ा खबरों को कैश मेमोरी में सेव किया जा सकता है. अलग-अलग थ्रेड से डेटा को पढ़ने और लिखने की प्रोसेस को सुरक्षित रखने के लिए, Mutex का इस्तेमाल किया जाता है. शेयर किए गए म्यूटबल स्टेट और कॉंकुरेंसी के बारे में ज़्यादा जानने के लिए, Kotlin का दस्तावेज़ देखें.
यहां दिए गए कोड में, नई खबरों की जानकारी को रिपॉज़िटरी में मौजूद ऐसे वैरिएबल में सेव किया जाता है जिसे Mutex से सुरक्षित किया गया है. अगर नेटवर्क अनुरोध का नतीजा सही होता है, तो डेटा को latestNews वैरिएबल को असाइन कर दिया जाता है.
class NewsRepository(
private val newsRemoteDataSource: NewsRemoteDataSource
) {
// Mutex to make writes to cached values thread-safe.
private val latestNewsMutex = Mutex()
// Cache of the latest news got from the network.
private var latestNews: List<ArticleHeadline> = emptyList()
suspend fun getLatestNews(refresh: Boolean = false): List<ArticleHeadline> {
if (refresh || latestNews.isEmpty()) {
val networkResult = newsRemoteDataSource.fetchLatestNews()
// Thread-safe write to latestNews
latestNewsMutex.withLock {
this.latestNews = networkResult
}
}
return latestNewsMutex.withLock { this.latestNews }
}
}
स्क्रीन पर दिखने वाले किसी ऑपरेशन को ज़्यादा समय तक लाइव रखना
अगर नेटवर्क अनुरोध पूरा होने से पहले उपयोगकर्ता स्क्रीन से हट जाता है, तो अनुरोध रद्द हो जाएगा और नतीजे को कैश मेमोरी में सेव नहीं किया जाएगा. NewsRepository को इस लॉजिक को लागू करने के लिए, कॉलर के CoroutineScope का इस्तेमाल नहीं करना चाहिए. इसके बजाय, NewsRepository को अपने लाइफ़साइकल से जुड़ी CoroutineScope का इस्तेमाल करना चाहिए.
ताज़ा खबरें पाने के लिए, ऐप्लिकेशन से जुड़ी कार्रवाई करनी होगी.
डिपेंडेंसी इंजेक्शन के सबसे सही तरीकों को फ़ॉलो करने के लिए, NewsRepository को अपने कंस्ट्रक्टर में पैरामीटर के तौर पर स्कोप मिलना चाहिए. इसके बजाय, इसे अपना CoroutineScope नहीं बनाना चाहिए. रिपॉज़िटरी को अपना ज़्यादातर काम बैकग्राउंड थ्रेड में करना चाहिए. इसलिए, आपको CoroutineScope को Dispatchers.Default या अपने थ्रेड पूल के साथ कॉन्फ़िगर करना चाहिए.
class NewsRepository(
...,
// This could be CoroutineScope(SupervisorJob() + Dispatchers.Default).
private val externalScope: CoroutineScope
) { ... }
NewsRepository, बाहरी CoroutineScope के साथ ऐप्लिकेशन से जुड़े ऑपरेशन करने के लिए तैयार है. इसलिए, इसे डेटा सोर्स को कॉल करना होगा और उसके नतीजे को उस स्कोप से शुरू किए गए नए कोरूटीन के साथ सेव करना होगा:
class NewsRepository(
private val newsRemoteDataSource: NewsRemoteDataSource,
private val externalScope: CoroutineScope
) {
/* ... */
suspend fun getLatestNews(refresh: Boolean = false): List<ArticleHeadline> {
return if (refresh) {
externalScope.async {
newsRemoteDataSource.fetchLatestNews().also { networkResult ->
// Thread-safe write to latestNews.
latestNewsMutex.withLock {
latestNews = networkResult
}
}
}.await()
} else {
return latestNewsMutex.withLock { this.latestNews }
}
}
}
async का इस्तेमाल, बाहरी स्कोप में कोरूटीन शुरू करने के लिए किया जाता है. await को नई कोरूटीन पर कॉल किया जाता है, ताकि नेटवर्क अनुरोध वापस आने तक उसे सस्पेंड किया जा सके. साथ ही, नतीजे को कैश मेमोरी में सेव किया जा सके. अगर उपयोगकर्ता उस समय तक स्क्रीन पर रहता है, तो उसे ताज़ा खबरें दिखेंगी. अगर उपयोगकर्ता स्क्रीन से हट जाता है, तो await रद्द हो जाता है. हालांकि, async में मौजूद लॉजिक काम करता रहता है.
CoroutineScope के पैटर्न के बारे में ज़्यादा जानें.
डिस्क से डेटा सेव करना और उसे वापस पाना
मान लें कि आपको बुकमार्क की गई खबरों और उपयोगकर्ता की प्राथमिकताओं जैसा डेटा सेव करना है. इस तरह के डेटा को प्रोसेस बंद होने के बाद भी सेव रहना चाहिए. साथ ही, अगर उपयोगकर्ता नेटवर्क से कनेक्ट नहीं है, तब भी इसे ऐक्सेस किया जा सकता है.
अगर आपको प्रोसेस बंद होने के बाद भी डेटा को बनाए रखना है, तो आपको उसे डिस्क पर सेव करना होगा. इसके लिए, इनमें से कोई एक तरीका अपनाएं:
- अगर आपको बड़े डेटासेट के लिए क्वेरी करनी है, रेफ़रेंशियल इंटिग्रिटी की ज़रूरत है या आंशिक अपडेट करने हैं, तो डेटा को Room डेटाबेस में सेव करें. उदाहरण के लिए, News ऐप्लिकेशन में समाचार लेख या लेखकों को डेटाबेस में सेव किया जा सकता है.
- छोटे डेटासेट के लिए DataStore का इस्तेमाल करें. इन डेटासेट को सिर्फ़ वापस पाना और सेट करना होता है. इन्हें क्वेरी नहीं किया जाता या आंशिक रूप से अपडेट नहीं किया जाता. उदाहरण के लिए, News ऐप्लिकेशन में उपयोगकर्ता की पसंद के तारीख के फ़ॉर्मैट या डिसप्ले से जुड़ी अन्य सेटिंग को DataStore में सेव किया जा सकता है.
- JSON ऑब्जेक्ट जैसे डेटा के हिस्सों के लिए, फ़ाइल का इस्तेमाल करें.
भरोसेमंद सोर्स सेक्शन में बताया गया है कि हर डेटा सोर्स, सिर्फ़ एक सोर्स के साथ काम करता है और किसी खास डेटा टाइप (उदाहरण के लिए, News, Authors, NewsAndAuthors या UserPreferences) से मेल खाता है. डेटा सोर्स का इस्तेमाल करने वाली क्लास को यह नहीं पता होना चाहिए कि डेटा कैसे सेव किया जाता है. उदाहरण के लिए, डेटाबेस में या किसी फ़ाइल में.
डेटा सोर्स के तौर पर रूम
हर डेटा सोर्स को किसी खास तरह के डेटा के लिए, सिर्फ़ एक सोर्स के साथ काम करना चाहिए. इसलिए, Room डेटा सोर्स को पैरामीटर के तौर पर, डेटा ऐक्सेस ऑब्जेक्ट (डीएओ) या डेटाबेस मिलेगा. उदाहरण के लिए, NewsLocalDataSource, NewsDao के इंस्टेंस को पैरामीटर के तौर पर ले सकता है. वहीं, AuthorsLocalDataSource, AuthorsDao के इंस्टेंस को पैरामीटर के तौर पर ले सकता है.
कुछ मामलों में, अगर किसी अतिरिक्त लॉजिक की ज़रूरत नहीं है, तो डीएओ को सीधे तौर पर रिपॉज़िटरी में इंजेक्ट किया जा सकता है. ऐसा इसलिए, क्योंकि डीएओ एक ऐसा इंटरफ़ेस है जिसे टेस्ट में आसानी से बदला जा सकता है.
Room API इस्तेमाल करने के बारे में ज़्यादा जानने के लिए, Room API से जुड़ी गाइड देखें.
DataStore को डेटा सोर्स के तौर पर इस्तेमाल करना
DataStore, उपयोगकर्ता की सेटिंग जैसे की-वैल्यू पेयर को सेव करने के लिए सबसे सही है. उदाहरण के लिए, समय का फ़ॉर्मैट, सूचना पाने की प्राथमिकताएं, और उपयोगकर्ता के समाचार पढ़ने के बाद उन्हें दिखाना है या छिपाना है. DataStore, प्रोटोकॉल बफ़र के साथ टाइप किए गए ऑब्जेक्ट भी सेव कर सकता है.
किसी भी अन्य ऑब्जेक्ट की तरह, DataStore से जुड़े डेटा सोर्स में किसी खास तरह का डेटा या ऐप्लिकेशन के किसी खास हिस्से का डेटा होना चाहिए. यह बात DataStore के लिए और भी ज़्यादा ज़रूरी है, क्योंकि DataStore के डेटा को फ़्लो के तौर पर दिखाया जाता है. जब भी कोई वैल्यू अपडेट होती है, तब यह फ़्लो चालू हो जाता है. इस वजह से, आपको मिलती-जुलती प्राथमिकताओं को एक ही DataStore में सेव करना चाहिए.
उदाहरण के लिए, आपके पास एक NotificationsDataStore हो सकता है, जो सिर्फ़ सूचना से जुड़ी प्राथमिकताओं को मैनेज करता है. साथ ही, एक NewsPreferencesDataStore हो सकता है, जो सिर्फ़ खबरों की स्क्रीन से जुड़ी प्राथमिकताओं को मैनेज करता है. इस तरह, अपडेट को बेहतर तरीके से स्कोप किया जा सकता है, क्योंकि newsScreenPreferencesDataStore.data फ़्लो सिर्फ़ तब चालू होता है, जब उस स्क्रीन से जुड़ी कोई प्राथमिकता बदली जाती है. इसका यह भी मतलब है कि ऑब्जेक्ट का लाइफ़साइकल छोटा हो सकता है, क्योंकि यह सिर्फ़ तब तक मौजूद रह सकता है, जब तक खबरों वाली स्क्रीन दिखती है.
DataStore API के साथ काम करने के बारे में ज़्यादा जानने के लिए, DataStore गाइड देखें.
डेटा सोर्स के तौर पर फ़ाइल
JSON ऑब्जेक्ट या बिटमैप जैसे बड़े ऑब्जेक्ट के साथ काम करते समय, आपको File ऑब्जेक्ट के साथ काम करना होगा और थ्रेड स्विच करने की प्रोसेस को मैनेज करना होगा.
फ़ाइल स्टोरेज के साथ काम करने के बारे में ज़्यादा जानने के लिए, स्टोरेज की खास जानकारी पेज देखें.
WorkManager का इस्तेमाल करके टास्क शेड्यूल करना
मान लें कि News ऐप्लिकेशन के लिए एक नई ज़रूरी शर्त जोड़ी गई है: ऐप्लिकेशन को उपयोगकर्ता को यह विकल्प देना होगा कि जब तक डिवाइस चार्ज हो रहा है और वह बिना मीटर वाले नेटवर्क से कनेक्ट है, तब तक वह नियमित तौर पर और अपने-आप ताज़ा खबरें फ़ेच कर सके. इसलिए, यह कारोबार से जुड़ी कार्रवाई है. इस ज़रूरी शर्त को पूरा करने से, उपयोगकर्ता को हाल की खबरें दिखती हैं. भले ही, जब वह ऐप्लिकेशन खोले, तब डिवाइस इंटरनेट से कनेक्ट न हो.
WorkManager की मदद से, एसिंक्रोनस और भरोसेमंद काम को आसानी से शेड्यूल किया जा सकता है. साथ ही, यह कंस्ट्रेंट मैनेजमेंट का ध्यान रख सकता है. यह लगातार काम करने के लिए सुझाई गई लाइब्रेरी है. ऊपर बताए गए टास्क को पूरा करने के लिए, Worker क्लास बनाई जाती है: RefreshLatestNewsWorker. यह क्लास, NewsRepository को डिपेंडेंसी के तौर पर इस्तेमाल करती है, ताकि ताज़ा खबरें फ़ेच की जा सकें और उन्हें डिस्क पर कैश किया जा सके.
class RefreshLatestNewsWorker(
private val newsRepository: NewsRepository,
context: Context,
params: WorkerParameters
) : CoroutineWorker(context, params) {
override suspend fun doWork(): Result = try {
newsRepository.refreshLatestNews()
Result.success()
} catch (error: Throwable) {
Result.failure()
}
}
इस तरह के टास्क के लिए, कारोबार से जुड़े लॉजिक को अपनी क्लास में शामिल किया जाना चाहिए. साथ ही, इसे अलग डेटा सोर्स के तौर पर इस्तेमाल किया जाना चाहिए. इसके बाद, WorkManager की यह ज़िम्मेदारी होगी कि सभी शर्तों के पूरा होने पर, यह काम बैकग्राउंड थ्रेड पर किया जाए. इस पैटर्न का पालन करके, ज़रूरत के हिसाब से अलग-अलग एनवायरमेंट पर लागू किए गए बदलावों को तुरंत बदला जा सकता है.
इस उदाहरण में, खबर से जुड़े इस टास्क को NewsRepository से कॉल किया जाना चाहिए. इसके लिए, एक नए डेटा सोर्स की ज़रूरत होगी. NewsTasksDataSource को इस तरह लागू किया जाएगा:
private const val REFRESH_RATE_HOURS = 4L
private const val FETCH_LATEST_NEWS_TASK = "FetchLatestNewsTask"
private const val TAG_FETCH_LATEST_NEWS = "FetchLatestNewsTaskTag"
class NewsTasksDataSource(
private val workManager: WorkManager
) {
fun fetchNewsPeriodically() {
val fetchNewsRequest = PeriodicWorkRequestBuilder<RefreshLatestNewsWorker>(
REFRESH_RATE_HOURS, TimeUnit.HOURS
).setConstraints(
Constraints.Builder()
.setRequiredNetworkType(NetworkType.TEMPORARILY_UNMETERED)
.setRequiresCharging(true)
.build()
)
.addTag(TAG_FETCH_LATEST_NEWS)
workManager.enqueueUniquePeriodicWork(
FETCH_LATEST_NEWS_TASK,
ExistingPeriodicWorkPolicy.KEEP,
fetchNewsRequest.build()
)
}
fun cancelFetchingNewsPeriodically() {
workManager.cancelAllWorkByTag(TAG_FETCH_LATEST_NEWS)
}
}
इन क्लास के नाम, उस डेटा के हिसाब से रखे जाते हैं जिसकी ज़िम्मेदारी इन पर होती है. उदाहरण के लिए, NewsTasksDataSource या PaymentsTasksDataSource. किसी खास तरह के डेटा से जुड़े सभी टास्क, एक ही क्लास में शामिल होने चाहिए.
अगर ऐप्लिकेशन शुरू होने पर टास्क को ट्रिगर करना है, तो App Startup लाइब्रेरी का इस्तेमाल करके WorkManager अनुरोध को ट्रिगर करने का सुझाव दिया जाता है. यह लाइब्रेरी, Initializer से रिपॉज़िटरी को कॉल करती है.
WorkManager API के साथ काम करने के बारे में ज़्यादा जानने के लिए, WorkManager गाइड देखें.
जांच करना
डिपेंडेंसी इंजेक्शन के सबसे सही तरीके, ऐप्लिकेशन की टेस्टिंग के दौरान मदद करते हैं. बाहरी संसाधनों से कम्यूनिकेट करने वाली क्लास के लिए, इंटरफ़ेस पर भरोसा करना भी मददगार होता है. किसी यूनिट की जांच करते समय, उसकी डिपेंडेंसी के फ़र्ज़ी वर्शन डाले जा सकते हैं. इससे जांच को भरोसेमंद और तय किया जा सकता है.
यूनिट टेस्ट
डेटा लेयर की जांच करते समय, जांच से जुड़े सामान्य दिशा-निर्देश लागू होते हैं. यूनिट टेस्ट के लिए, ज़रूरत पड़ने पर असली ऑब्जेक्ट का इस्तेमाल करें. साथ ही, बाहरी सोर्स से संपर्क करने वाली किसी भी डिपेंडेंसी को फ़र्ज़ी बनाएं. जैसे, किसी फ़ाइल या नेटवर्क से डेटा पढ़ना.
इंटिग्रेशन टेस्ट
बाहरी सोर्स को ऐक्सेस करने वाले इंटिग्रेशन टेस्ट, कम भरोसेमंद होते हैं. ऐसा इसलिए, क्योंकि उन्हें किसी असली डिवाइस पर चलाना होता है. हमारा सुझाव है कि आप इन टेस्ट को कंट्रोल किए गए एनवायरमेंट में करें, ताकि इंटिग्रेशन टेस्ट ज़्यादा भरोसेमंद हो सकें.
डेटाबेस के लिए, Room आपको इन-मेमोरी डेटाबेस बनाने की सुविधा देता है. इसे टेस्ट में पूरी तरह से कंट्रोल किया जा सकता है. ज़्यादा जानने के लिए, अपने डेटाबेस की जांच करना और उसे डीबग करना पेज पर जाएं.
नेटवर्किंग के लिए, WireMock या MockWebServer जैसी लोकप्रिय लाइब्रेरी उपलब्ध हैं. इनकी मदद से, एचटीटीपी और एचटीटीपीएस कॉल को फ़र्ज़ी बनाया जा सकता है. साथ ही, यह पुष्टि की जा सकती है कि अनुरोध उम्मीद के मुताबिक किए गए थे.
अन्य संसाधन
सैंपल
- Jetcaster
- आर्किटेक्चर स्टार्टर टेंप्लेट (मल्टी-मॉड्यूल)
- आर्किटेक्चर
- आर्किटेक्चर का स्टार्टर टेंप्लेट (सिंगल मॉड्यूल)
- Now in Android ऐप्लिकेशन
आपके लिए सुझाव
- ध्यान दें: JavaScript बंद होने पर लिंक का टेक्स्ट दिखता है
- डोमेन लेयर
- ऑफ़लाइन-फ़र्स्ट ऐप्लिकेशन बनाना
- यूज़र इंटरफ़ेस (यूआई) स्टेट प्रोडक्शन