
L'API Android Neural Networks (NNAPI) è un'API C di Android progettata per eseguire operazioni di machine learning a elevata intensità di calcolo sui dispositivi Android. NNAPI è progettata per fornire un livello base di funzionalità per framework di machine learning di livello superiore, come TensorFlow Lite e Caffe2, che creano e addestrano reti neurali. L'API è disponibile su tutti i dispositivi Android con Android 8.1 (livello API 27) o versioni successive, ma è stata ritirata in Android 15.
NNAPI supporta l'inferenza applicando i dati dei dispositivi Android a modelli precedentemente addestrati e definiti dagli sviluppatori. Esempi di inferenza includono la classificazione di immagini, la previsione del comportamento degli utenti e la selezione di risposte appropriate a una query di ricerca.
L'inferenza sul dispositivo offre molti vantaggi:
- Latenza: non è necessario inviare una richiesta tramite una connessione di rete e attendere una risposta. Ad esempio, questo può essere fondamentale per le applicazioni video che elaborano fotogrammi successivi provenienti da una videocamera.
- Disponibilità: l'applicazione viene eseguita anche al di fuori della copertura di rete.
- Velocità: il nuovo hardware specifico per l'elaborazione delle reti neurali fornisce una velocità di calcolo notevolmente superiore rispetto a una CPU per uso generico.
- Privacy: i dati non vengono trasferiti dal dispositivo Android.
- Costo: non è necessaria una server farm quando tutti i calcoli vengono eseguiti sul dispositivo Android.
Inoltre, uno sviluppatore deve tenere presente alcuni compromessi:
- Utilizzo del sistema: la valutazione delle reti neurali comporta molti calcoli, il che potrebbe aumentare l'utilizzo della batteria. Ti consigliamo di monitorare lo stato della batteria se questo è un problema per la tua app, soprattutto per i calcoli di lunga durata.
- Dimensioni dell'applicazione: presta attenzione alle dimensioni dei tuoi modelli. I modelli potrebbero occupare diversi megabyte di spazio. Se il raggruppamento di modelli di grandi dimensioni nell'APK avrebbe un impatto eccessivo sugli utenti, potresti prendere in considerazione il download dei modelli dopo l'installazione dell'app, l'utilizzo di modelli più piccoli o l'esecuzione dei calcoli nel cloud. NNAPI non fornisce funzionalità per l'esecuzione di modelli nel cloud.
Consulta l'esempio di API Android Neural Networks per vedere un esempio di come utilizzare NNAPI.
Informazioni sul runtime dell'API Neural Networks
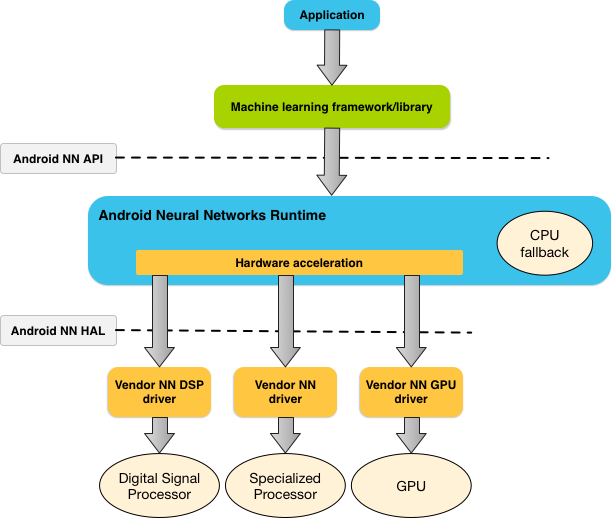
L'API NN è pensata per essere chiamata da librerie, framework e strumenti di machine learning che consentono agli sviluppatori di addestrare i propri modelli off-device ed eseguirne il deployment su dispositivi Android. In genere, le app non utilizzano direttamente NNAPI, ma framework di machine learning di livello superiore. Questi framework a loro volta potrebbero utilizzare NNAPI per eseguire operazioni di inferenza con accelerazione hardware sui dispositivi supportati.
In base ai requisiti di un'app e alle funzionalità hardware di un dispositivo Android, l'ambiente di runtime della rete neurale di Android può distribuire in modo efficiente il carico di lavoro di calcolo tra i processori disponibili sul dispositivo, tra cui hardware di rete neurale dedicato, unità di elaborazione grafica (GPU) e processori di segnali digitali (DSP).
Per i dispositivi Android che non dispongono di un driver fornitore specializzato, il runtime NNAPI esegue le richieste sulla CPU.
La figura 1 mostra l'architettura di sistema di alto livello per NNAPI.
Modello di programmazione dell'API Neural Networks
Per eseguire i calcoli utilizzando NNAPI, devi prima costruire un grafico diretto che definisca i calcoli da eseguire. Questo grafico di calcolo, combinato con i dati di input (ad esempio, i pesi e i bias ereditati da un framework di machine learning), forma il modello per la valutazione del runtime NNAPI.
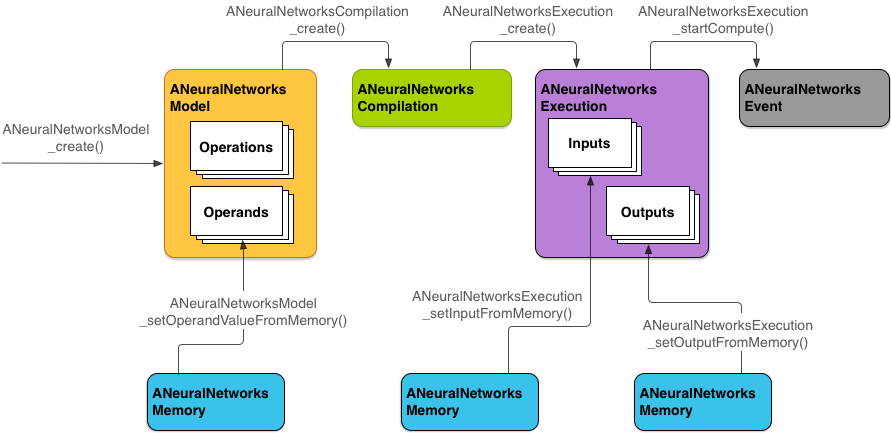
L'API NN utilizza quattro astrazioni principali:
- Modello: un grafico di calcolo di operazioni matematiche e i valori costanti
appresi tramite un processo di addestramento. Queste operazioni sono specifiche per
le reti neurali. Questi includono la convoluzione bidimensionale (2D), l'attivazione logistica (sigmoide), l'attivazione lineare rettificata (ReLU) e altro ancora. La creazione di un modello è un'operazione sincrona.
Una volta creato correttamente, può essere riutilizzato in più thread e compilazioni.
In NNAPI, un modello è rappresentato come un'istanza
ANeuralNetworksModel. - Compilazione: rappresenta una configurazione per la compilazione di un modello NNAPI in codice di livello inferiore. La creazione di una compilation è un'operazione sincrona. Una volta
creato correttamente, può essere riutilizzato in più thread ed esecuzioni. In
NNAPI, ogni compilazione è rappresentata da un'istanza
ANeuralNetworksCompilation. - Memoria: rappresenta la memoria condivisa, i file mappati nella memoria e buffer di memoria simili. L'utilizzo di un buffer di memoria consente al runtime NNAPI di trasferire i dati ai driver
in modo più efficiente. In genere, un'app crea un buffer di memoria condiviso che
contiene tutti i tensori necessari per definire un modello. Puoi anche utilizzare i buffer di memoria per archiviare gli input e gli output di un'istanza di esecuzione. In NNAPI,
ogni buffer di memoria è rappresentato come un'istanza
ANeuralNetworksMemory. Esecuzione: interfaccia per applicare un modello NNAPI a un insieme di input e raccogliere i risultati. L'esecuzione può essere eseguita in modo sincrono o asincrono.
Per l'esecuzione asincrona, più thread possono attendere la stessa esecuzione. Al termine dell'esecuzione, tutti i thread vengono rilasciati.
In NNAPI, ogni esecuzione è rappresentata da un'istanza
ANeuralNetworksExecution.
La Figura 2 mostra il flusso di programmazione di base.
Il resto di questa sezione descrive i passaggi per configurare il modello NNAPI per eseguire il calcolo, compilare il modello ed eseguire il modello compilato.
Fornire l'accesso ai dati di addestramento
I dati di pesi e bias addestrati sono probabilmente archiviati in un file. Per fornire
all'ambiente di runtime NNAPI un accesso efficiente a questi dati, crea un'istanza
ANeuralNetworksMemory
chiamando la funzione
ANeuralNetworksMemory_createFromFd()
e passando il descrittore del file di dati aperto. Puoi anche
specificare i flag di protezione della memoria e un offset in cui inizia la regione di memoria condivisa
nel file.
// Create a memory buffer from the file that contains the trained data
ANeuralNetworksMemory* mem1 = NULL;
int fd = open("training_data", O_RDONLY);
ANeuralNetworksMemory_createFromFd(file_size, PROT_READ, fd, 0, &mem1);
Anche se in questo esempio utilizziamo una sola istanza di ANeuralNetworksMemory per tutti i nostri pesi, è possibile utilizzare più istanze di ANeuralNetworksMemory per più file.
Utilizzare i buffer hardware nativi
Puoi utilizzare i buffer hardware nativi
per gli input, gli output e i valori degli operandi costanti del modello. In alcuni casi, un
acceleratore NNAPI può accedere
a oggetti AHardwareBuffer
senza che il driver debba copiare i dati. AHardwareBuffer ha molte
configurazioni diverse e non tutti gli acceleratori NNAPI potrebbero supportare tutte
queste configurazioni. A causa di questa limitazione, fai riferimento ai vincoli
elencati nella
documentazione di riferimento di ANeuralNetworksMemory_createFromAHardwareBuffer
e testa in anticipo sui dispositivi di destinazione per assicurarti che le compilazioni e le esecuzioni
che utilizzano AHardwareBuffer si comportino come previsto, utilizzando
l'assegnazione dei dispositivi per specificare l'acceleratore.
Per consentire al runtime NNAPI di accedere a un oggetto AHardwareBuffer, crea un'istanza di ANeuralNetworksMemory chiamando la funzione ANeuralNetworksMemory_createFromAHardwareBuffer e passando l'oggetto AHardwareBuffer, come mostrato nel seguente esempio di codice:
// Configure and create AHardwareBuffer object AHardwareBuffer_Desc desc = ... AHardwareBuffer* ahwb = nullptr; AHardwareBuffer_allocate(&desc, &ahwb); // Create ANeuralNetworksMemory from AHardwareBuffer ANeuralNetworksMemory* mem2 = NULL; ANeuralNetworksMemory_createFromAHardwareBuffer(ahwb, &mem2);
Quando NNAPI non ha più bisogno di accedere all'oggetto AHardwareBuffer, libera l'istanza ANeuralNetworksMemory corrispondente:
ANeuralNetworksMemory_free(mem2);
Nota:
- Puoi utilizzare
AHardwareBuffersolo per l'intero buffer; non puoi utilizzarlo con un parametroARect. - L'ambiente di runtime NNAPI non svuoterà il buffer. Prima di pianificare l'esecuzione, devi assicurarti che i buffer di input e output siano accessibili.
- Non è supportata la sincronizzazione dei descrittori di file.
- Per un
AHardwareBuffercon formati e bit di utilizzo specifici del fornitore, spetta all'implementazione del fornitore determinare se il client o il driver è responsabile dello svuotamento della cache.
Modello
Un modello è l'unità di calcolo fondamentale in NNAPI. Ogni modello è definito da uno o più operandi e operazioni.
Operandi
Gli operandi sono oggetti di dati utilizzati per definire il grafico. Questi includono gli input e gli output del modello, i nodi intermedi che contengono i dati che scorrono da un'operazione all'altra e le costanti passate a queste operazioni.
Esistono due tipi di operandi che possono essere aggiunti ai modelli NNAPI: scalari e tensori.
Uno scalare rappresenta un singolo valore. NNAPI supporta valori scalari nei formati booleano, virgola mobile a 16 bit, virgola mobile a 32 bit, numero intero a 32 bit e numero intero a 32 bit senza segno.
La maggior parte delle operazioni in NNAPI coinvolge i tensori. I tensori sono array n-dimensionali. NNAPI supporta tensori con valori in virgola mobile a 16 bit, in virgola mobile a 32 bit, quantizzati a 8 bit, quantizzati a 16 bit, interi a 32 bit e booleani a 8 bit.
Ad esempio, la figura 3 rappresenta un modello con due operazioni: un'addizione seguita da una moltiplicazione. Il modello accetta un tensore di input e produce un tensore di output.
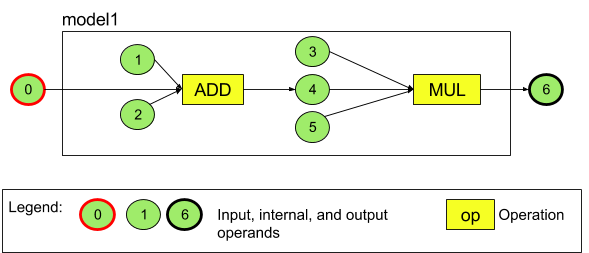
Il modello precedente ha sette operandi. Questi operandi vengono identificati implicitamente dall'indice dell'ordine in cui vengono aggiunti al modello. Il primo operando aggiunto ha indice 0, il secondo indice 1 e così via. Gli operandi 1, 2, 3 e 5 sono costanti.
L'ordine in cui aggiungi gli operandi non è importante. Ad esempio, l'operando di output del modello potrebbe essere il primo aggiunto. La parte importante è utilizzare il valore di indice corretto quando si fa riferimento a un operando.
Gli operandi hanno dei tipi. Questi vengono specificati quando vengono aggiunti al modello.
Un operando non può essere utilizzato sia come input che come output di un modello.
Ogni operando deve essere un input del modello, una costante o l'operando di output di esattamente un'operazione.
Per ulteriori informazioni sull'utilizzo degli operandi, consulta Ulteriori informazioni sugli operandi.
Fasi operative
Un'operazione specifica i calcoli da eseguire. Ogni operazione è composta dai seguenti elementi:
- un tipo di operazione (ad esempio addizione, moltiplicazione, convoluzione),
- un elenco degli indici degli operandi che l'operazione utilizza per l'input e
- un elenco degli indici degli operandi che l'operazione utilizza per l'output.
L'ordine in questi elenchi è importante. Consulta il riferimento API NNAPI per gli input e gli output previsti di ogni tipo di operazione.
Prima di aggiungere l'operazione, devi aggiungere al modello gli operandi che un'operazione utilizza o produce.
L'ordine in cui aggiungi le operazioni non è importante. NNAPI si basa sulle dipendenze stabilite dal grafico di calcolo di operandi e operazioni per determinare l'ordine di esecuzione delle operazioni.
Le operazioni supportate da NNAPI sono riassunte nella tabella seguente:
Problema noto nel livello API 28: quando si passano
tensori ANEURALNETWORKS_TENSOR_QUANT8_ASYMM
all'operazione
ANEURALNETWORKS_PAD, disponibile su Android 9 (livello API 28) e versioni successive, l'output di NNAPI potrebbe non corrispondere all'output di framework di machine learning di livello superiore, come
TensorFlow Lite. Devi invece passare solo
ANEURALNETWORKS_TENSOR_FLOAT32.
Il problema è stato risolto in Android 10 (livello API 29) e versioni successive.
Creare modelli
Nell'esempio seguente, creiamo il modello a due operazioni riportato nella Figura 3.
Per creare il modello:
Chiama la funzione
ANeuralNetworksModel_create()per definire un modello vuoto.ANeuralNetworksModel* model = NULL; ANeuralNetworksModel_create(&model);
Aggiungi gli operandi al modello chiamando
ANeuralNetworks_addOperand(). I relativi tipi di dati sono definiti utilizzando la struttura dei datiANeuralNetworksOperandType.// In our example, all our tensors are matrices of dimension [3][4] ANeuralNetworksOperandType tensor3x4Type; tensor3x4Type.type = ANEURALNETWORKS_TENSOR_FLOAT32; tensor3x4Type.scale = 0.f; // These fields are used for quantized tensors tensor3x4Type.zeroPoint = 0; // These fields are used for quantized tensors tensor3x4Type.dimensionCount = 2; uint32_t dims[2] = {3, 4}; tensor3x4Type.dimensions = dims;
// We also specify operands that are activation function specifiers ANeuralNetworksOperandType activationType; activationType.type = ANEURALNETWORKS_INT32; activationType.scale = 0.f; activationType.zeroPoint = 0; activationType.dimensionCount = 0; activationType.dimensions = NULL;
// Now we add the seven operands, in the same order defined in the diagram ANeuralNetworksModel_addOperand(model, &tensor3x4Type); // operand 0 ANeuralNetworksModel_addOperand(model, &tensor3x4Type); // operand 1 ANeuralNetworksModel_addOperand(model, &activationType); // operand 2 ANeuralNetworksModel_addOperand(model, &tensor3x4Type); // operand 3 ANeuralNetworksModel_addOperand(model, &tensor3x4Type); // operand 4 ANeuralNetworksModel_addOperand(model, &activationType); // operand 5 ANeuralNetworksModel_addOperand(model, &tensor3x4Type); // operand 6Per gli operandi con valori costanti, come pesi e bias che la tua app ottiene da un processo di addestramento, utilizza le funzioni
ANeuralNetworksModel_setOperandValue()eANeuralNetworksModel_setOperandValueFromMemory().Nell'esempio seguente, impostiamo valori costanti dal file di dati di addestramento corrispondenti al buffer di memoria creato in Fornisci l'accesso ai dati di addestramento.
// In our example, operands 1 and 3 are constant tensors whose values were // established during the training process const int sizeOfTensor = 3 * 4 * 4; // The formula for size calculation is dim0 * dim1 * elementSize ANeuralNetworksModel_setOperandValueFromMemory(model, 1, mem1, 0, sizeOfTensor); ANeuralNetworksModel_setOperandValueFromMemory(model, 3, mem1, sizeOfTensor, sizeOfTensor);
// We set the values of the activation operands, in our example operands 2 and 5 int32_t noneValue = ANEURALNETWORKS_FUSED_NONE; ANeuralNetworksModel_setOperandValue(model, 2, &noneValue, sizeof(noneValue)); ANeuralNetworksModel_setOperandValue(model, 5, &noneValue, sizeof(noneValue));Per ogni operazione nel grafico diretto che vuoi calcolare, aggiungi l'operazione al modello chiamando la funzione
ANeuralNetworksModel_addOperation().Come parametri di questa chiamata, la tua app deve fornire:
- il tipo di operazione
- il conteggio dei valori di input
- l'array degli indici per gli operandi di input
- il conteggio dei valori di output
- l'array degli indici per gli operandi di output
Tieni presente che un operando non può essere utilizzato sia per l'input che per l'output della stessa operazione.
// We have two operations in our example // The first consumes operands 1, 0, 2, and produces operand 4 uint32_t addInputIndexes[3] = {1, 0, 2}; uint32_t addOutputIndexes[1] = {4}; ANeuralNetworksModel_addOperation(model, ANEURALNETWORKS_ADD, 3, addInputIndexes, 1, addOutputIndexes);
// The second consumes operands 3, 4, 5, and produces operand 6 uint32_t multInputIndexes[3] = {3, 4, 5}; uint32_t multOutputIndexes[1] = {6}; ANeuralNetworksModel_addOperation(model, ANEURALNETWORKS_MUL, 3, multInputIndexes, 1, multOutputIndexes);Identifica gli operandi che il modello deve trattare come input e output chiamando la funzione
ANeuralNetworksModel_identifyInputsAndOutputs().// Our model has one input (0) and one output (6) uint32_t modelInputIndexes[1] = {0}; uint32_t modelOutputIndexes[1] = {6}; ANeuralNetworksModel_identifyInputsAndOutputs(model, 1, modelInputIndexes, 1 modelOutputIndexes);
(Facoltativo) Specifica se
ANEURALNETWORKS_TENSOR_FLOAT32può essere calcolato con un intervallo o una precisione pari a quella del formato in virgola mobile a 16 bit IEEE 754 chiamandoANeuralNetworksModel_relaxComputationFloat32toFloat16().Chiama il numero
ANeuralNetworksModel_finish()per finalizzare la definizione del modello. Se non sono presenti errori, questa funzione restituisce un codice risultatoANEURALNETWORKS_NO_ERROR.ANeuralNetworksModel_finish(model);
Una volta creato un modello, puoi compilarlo tutte le volte che vuoi ed eseguire ogni compilazione tutte le volte che vuoi.
Flusso di controllo
Per incorporare il flusso di controllo in un modello NNAPI:
Costruisci i sottografi di esecuzione corrispondenti (sottografi
theneelseper un'istruzioneIF, sottograficonditionebodyper un cicloWHILE) come modelliANeuralNetworksModel*autonomi:ANeuralNetworksModel* thenModel = makeThenModel(); ANeuralNetworksModel* elseModel = makeElseModel();
Crea operandi che fanno riferimento a questi modelli all'interno del modello contenente il flusso di controllo:
ANeuralNetworksOperandType modelType = { .type = ANEURALNETWORKS_MODEL, }; ANeuralNetworksModel_addOperand(model, &modelType); // kThenOperandIndex ANeuralNetworksModel_addOperand(model, &modelType); // kElseOperandIndex ANeuralNetworksModel_setOperandValueFromModel(model, kThenOperandIndex, &thenModel); ANeuralNetworksModel_setOperandValueFromModel(model, kElseOperandIndex, &elseModel);
Aggiungi l'operazione di controllo del flusso:
uint32_t inputs[] = {kConditionOperandIndex, kThenOperandIndex, kElseOperandIndex, kInput1, kInput2, kInput3}; uint32_t outputs[] = {kOutput1, kOutput2}; ANeuralNetworksModel_addOperation(model, ANEURALNETWORKS_IF, std::size(inputs), inputs, std::size(output), outputs);
Compilation
Il passaggio di compilazione determina su quali processori verrà eseguito il modello e chiede ai driver corrispondenti di prepararsi per l'esecuzione. Ciò potrebbe includere la generazione di codice macchina specifico per i processori su cui verrà eseguito il modello.
Per compilare un modello:
Chiama la funzione
ANeuralNetworksCompilation_create()per creare una nuova istanza di compilazione.// Compile the model ANeuralNetworksCompilation* compilation; ANeuralNetworksCompilation_create(model, &compilation);
Se vuoi, puoi utilizzare l'assegnazione dei dispositivi per scegliere esplicitamente su quali dispositivi eseguire l'azione.
Se vuoi, puoi influire sul compromesso tra l'utilizzo della batteria e la velocità di esecuzione del runtime. Puoi farlo chiamando il numero
ANeuralNetworksCompilation_setPreference().// Ask to optimize for low power consumption ANeuralNetworksCompilation_setPreference(compilation, ANEURALNETWORKS_PREFER_LOW_POWER);
Le preferenze che puoi specificare includono:
ANEURALNETWORKS_PREFER_LOW_POWER: Preferisci l'esecuzione in modo da ridurre al minimo il consumo della batteria. Questo è auspicabile per le compilazioni eseguite spesso.ANEURALNETWORKS_PREFER_FAST_SINGLE_ANSWER: Preferisci restituire una singola risposta il più rapidamente possibile, anche se ciò comporta un maggiore consumo energetico. Questa è l'impostazione predefinita.ANEURALNETWORKS_PREFER_SUSTAINED_SPEED: Preferisci massimizzare il throughput dei frame successivi, ad esempio quando elabori i frame successivi provenienti dalla videocamera.
Se vuoi, puoi configurare la memorizzazione nella cache della compilazione chiamando
ANeuralNetworksCompilation_setCaching.// Set up compilation caching ANeuralNetworksCompilation_setCaching(compilation, cacheDir, token);
Utilizza
getCodeCacheDir()percacheDir. Iltokenspecificato deve essere univoco per ogni modello all'interno dell'applicazione.Finalizza la definizione della compilazione chiamando
ANeuralNetworksCompilation_finish(). Se non sono presenti errori, questa funzione restituisce un codice risultatoANEURALNETWORKS_NO_ERROR.ANeuralNetworksCompilation_finish(compilation);
Rilevamento e assegnazione dei dispositivi
Sui dispositivi Android con Android 10 (livello API 29) e versioni successive, NNAPI fornisce funzioni che consentono alle librerie e alle app del framework di machine learning di ottenere informazioni sui dispositivi disponibili e specificare i dispositivi da utilizzare per l'esecuzione. Fornire informazioni sui dispositivi disponibili consente alle app di ottenere la versione esatta dei driver trovati su un dispositivo per evitare incompatibilità note. Consentendo alle app di specificare quali dispositivi devono eseguire diverse sezioni di un modello, le app possono essere ottimizzate per il dispositivo Android su cui vengono implementate.
Rilevamento dispositivi
Utilizza
ANeuralNetworks_getDeviceCount
per ottenere il numero di dispositivi disponibili. Per ogni dispositivo, utilizza
ANeuralNetworks_getDevice
per impostare un'istanza ANeuralNetworksDevice su un riferimento a quel dispositivo.
Una volta ottenuto un riferimento del dispositivo, puoi trovare ulteriori informazioni su questo dispositivo utilizzando le seguenti funzioni:
ANeuralNetworksDevice_getFeatureLevelANeuralNetworksDevice_getNameANeuralNetworksDevice_getTypeANeuralNetworksDevice_getVersion
Assegnazione dei dispositivi
Utilizza
ANeuralNetworksModel_getSupportedOperationsForDevices
per scoprire quali operazioni di un modello possono essere eseguite su dispositivi specifici.
Per controllare quali acceleratori utilizzare per l'esecuzione, chiama
ANeuralNetworksCompilation_createForDevices
al posto di ANeuralNetworksCompilation_create.
Utilizza l'oggetto ANeuralNetworksCompilation risultante normalmente.
La funzione restituisce un errore se il modello fornito contiene operazioni non supportate dai dispositivi selezionati.
Se vengono specificati più dispositivi, il runtime è responsabile della distribuzione del lavoro tra i dispositivi.
Analogamente ad altri dispositivi, l'implementazione della CPU NNAPI è rappresentata da un
ANeuralNetworksDevice con il nome nnapi-reference e il tipo
ANEURALNETWORKS_DEVICE_TYPE_CPU. Quando viene chiamato
ANeuralNetworksCompilation_createForDevices, l'implementazione della CPU non
viene utilizzata per gestire i casi di errore per la compilazione e l'esecuzione del modello.
È responsabilità di un'applicazione partizionare un modello in sottomodelli che
possono essere eseguiti sui dispositivi specificati. Le applicazioni che non devono eseguire il partizionamento manuale devono continuare a chiamare il metodo ANeuralNetworksCompilation_create più semplice per utilizzare tutti i dispositivi disponibili (inclusa la CPU) per accelerare il modello. Se il modello non può essere supportato completamente dai dispositivi specificati
utilizzando ANeuralNetworksCompilation_createForDevices,
viene restituito ANEURALNETWORKS_BAD_DATA.
Partizionamento del modello
Quando per il modello sono disponibili più dispositivi, il runtime NNAPI
distribuisce il lavoro tra i dispositivi. Ad esempio, se a ANeuralNetworksCompilation_createForDevices è stato fornito più di un dispositivo, tutti quelli specificati verranno presi in considerazione per l'assegnazione del lavoro. Tieni presente che se il dispositivo CPU
non è presente nell'elenco, l'esecuzione della CPU verrà disattivata. Quando utilizzi ANeuralNetworksCompilation_create,
vengono presi in considerazione tutti i dispositivi disponibili, inclusa la CPU.
La distribuzione viene eseguita selezionando dall'elenco dei dispositivi disponibili, per ciascuna delle operazioni nel modello, il dispositivo che supporta l'operazione e che dichiara le prestazioni migliori, ovvero il tempo di esecuzione più rapido o il consumo energetico più basso, a seconda della preferenza di esecuzione specificata dal client. Questo algoritmo di partizionamento non tiene conto delle possibili
inefficienze causate dall'I/O tra i diversi processori, pertanto, quando
si specificano più processori (in modo esplicito quando si utilizza
ANeuralNetworksCompilation_createForDevices o in modo implicito utilizzando
ANeuralNetworksCompilation_create), è importante profilare l'applicazione
risultante.
Per capire come è stato partizionato il modello da NNAPI, controlla i log di Android per un messaggio (a livello INFO con tag ExecutionPlan):
ModelBuilder::findBestDeviceForEachOperation(op-name): device-index
op-name è il nome descrittivo dell'operazione nel grafico e
device-index è l'indice del dispositivo candidato nell'elenco dei dispositivi.
Questo elenco è l'input fornito a ANeuralNetworksCompilation_createForDevices
o, se utilizzi ANeuralNetworksCompilation_createForDevices, l'elenco dei dispositivi
restituiti durante l'iterazione su tutti i dispositivi utilizzando ANeuralNetworks_getDeviceCount e
ANeuralNetworks_getDevice.
Il messaggio (a livello INFO con tag ExecutionPlan):
ModelBuilder::partitionTheWork: only one best device: device-name
Questo messaggio indica che l'intero grafico è stato accelerato sul dispositivo
device-name.
Esecuzione
Il passaggio di esecuzione applica il modello a un insieme di input e memorizza gli output di calcolo in uno o più buffer utente o spazi di memoria allocati dalla tua app.
Per eseguire un modello compilato:
Chiama la funzione
ANeuralNetworksExecution_create()per creare una nuova istanza di esecuzione.// Run the compiled model against a set of inputs ANeuralNetworksExecution* run1 = NULL; ANeuralNetworksExecution_create(compilation, &run1);
Specifica dove la tua app legge i valori di input per il calcolo. La tua app può leggere i valori di input da un buffer utente o da uno spazio di memoria allocato chiamando
ANeuralNetworksExecution_setInput()oANeuralNetworksExecution_setInputFromMemory()rispettivamente.// Set the single input to our sample model. Since it is small, we won't use a memory buffer float32 myInput[3][4] = { ...the data... }; ANeuralNetworksExecution_setInput(run1, 0, NULL, myInput, sizeof(myInput));
Specifica dove la tua app scrive i valori di output. La tua app può scrivere i valori di output in un buffer utente o in uno spazio di memoria allocato chiamando rispettivamente
ANeuralNetworksExecution_setOutput()oANeuralNetworksExecution_setOutputFromMemory().// Set the output float32 myOutput[3][4]; ANeuralNetworksExecution_setOutput(run1, 0, NULL, myOutput, sizeof(myOutput));
Pianifica l'esecuzione per l'avvio chiamando la funzione
ANeuralNetworksExecution_startCompute(). Se non sono presenti errori, questa funzione restituisce un codice risultatoANEURALNETWORKS_NO_ERROR.// Starts the work. The work proceeds asynchronously ANeuralNetworksEvent* run1_end = NULL; ANeuralNetworksExecution_startCompute(run1, &run1_end);
Chiama la funzione
ANeuralNetworksEvent_wait()per attendere il completamento dell'esecuzione. Se l'esecuzione ha avuto esito positivo, questa funzione restituisce un codice risultatoANEURALNETWORKS_NO_ERROR. L'attesa può essere eseguita su un thread diverso da quello che avvia l'esecuzione.// For our example, we have no other work to do and will just wait for the completion ANeuralNetworksEvent_wait(run1_end); ANeuralNetworksEvent_free(run1_end); ANeuralNetworksExecution_free(run1);
Se vuoi, puoi applicare un diverso insieme di input al modello compilato utilizzando la stessa istanza di compilazione per creare una nuova istanza di
ANeuralNetworksExecution.// Apply the compiled model to a different set of inputs ANeuralNetworksExecution* run2; ANeuralNetworksExecution_create(compilation, &run2); ANeuralNetworksExecution_setInput(run2, ...); ANeuralNetworksExecution_setOutput(run2, ...); ANeuralNetworksEvent* run2_end = NULL; ANeuralNetworksExecution_startCompute(run2, &run2_end); ANeuralNetworksEvent_wait(run2_end); ANeuralNetworksEvent_free(run2_end); ANeuralNetworksExecution_free(run2);
Esecuzione sincrona
L'esecuzione asincrona richiede tempo per generare e sincronizzare i thread. Inoltre, la latenza può essere estremamente variabile, con i ritardi più lunghi che raggiungono fino a 500 microsecondi tra il momento in cui un thread viene notificato o riattivato e il momento in cui viene infine associato a un core della CPU.
Per migliorare la latenza, puoi invece indirizzare un'applicazione a effettuare una chiamata di inferenza sincrona al runtime. La chiamata verrà restituita solo al termine di un'inferenza, non all'avvio. Anziché chiamare
ANeuralNetworksExecution_startCompute
per una chiamata di inferenza asincrona al runtime, l'applicazione chiama
ANeuralNetworksExecution_compute
per effettuare una chiamata sincrona al runtime. Una chiamata a
ANeuralNetworksExecution_compute non richiede un ANeuralNetworksEvent e
non è accoppiata a una chiamata a ANeuralNetworksEvent_wait.
Esecuzioni burst
Sui dispositivi Android con Android 10 (livello API 29) e versioni successive, l'API NN supporta le esecuzioni
in burst tramite l'oggetto
ANeuralNetworksBurst. Le esecuzioni burst sono una sequenza di esecuzioni della stessa compilazione
che si verificano in rapida successione, ad esempio quelle che operano sui frame di un'acquisizione
della videocamera o su campioni audio successivi. L'utilizzo di oggetti ANeuralNetworksBurst può
comportare esecuzioni più rapide, in quanto indicano agli acceleratori che le risorse possono
essere riutilizzate tra le esecuzioni e che gli acceleratori devono rimanere in uno
stato di prestazioni elevate per la durata del burst.
ANeuralNetworksBurst introduce solo una piccola variazione nel normale percorso di esecuzione. Crea un oggetto burst utilizzando
ANeuralNetworksBurst_create,
come mostrato nel seguente snippet di codice:
// Create burst object to be reused across a sequence of executions ANeuralNetworksBurst* burst = NULL; ANeuralNetworksBurst_create(compilation, &burst);
Le esecuzioni burst sono sincrone. Tuttavia, anziché utilizzare
ANeuralNetworksExecution_compute
per eseguire ogni inferenza, accoppia i vari
oggetti ANeuralNetworksExecution
con lo stesso ANeuralNetworksBurst nelle chiamate alla funzione
ANeuralNetworksExecution_burstCompute.
// Create and configure first execution object // ... // Execute using the burst object ANeuralNetworksExecution_burstCompute(execution1, burst); // Use results of first execution and free the execution object // ... // Create and configure second execution object // ... // Execute using the same burst object ANeuralNetworksExecution_burstCompute(execution2, burst); // Use results of second execution and free the execution object // ...
Libera l'oggetto ANeuralNetworksBurst con
ANeuralNetworksBurst_free
quando non è più necessario.
// Cleanup ANeuralNetworksBurst_free(burst);
Code di comandi asincroni ed esecuzione controllata
In Android 11 e versioni successive, NNAPI supporta un modo aggiuntivo per pianificare l'esecuzione asincrona tramite il metodo ANeuralNetworksExecution_startComputeWithDependencies(). Quando utilizzi questo metodo, l'esecuzione attende che tutti gli eventi dipendenti
vengano segnalati prima di iniziare la valutazione. Una volta completata l'esecuzione e pronti i risultati, l'evento restituito viene segnalato.
A seconda dei dispositivi che gestiscono l'esecuzione, l'evento potrebbe essere supportato da una
barriera di sincronizzazione. Devi
chiamare
ANeuralNetworksEvent_wait()
per attendere l'evento e recuperare le risorse utilizzate dall'esecuzione. Puoi importare le barriere di sincronizzazione in un oggetto evento utilizzando
ANeuralNetworksEvent_createFromSyncFenceFd() e puoi esportarle da un oggetto evento utilizzando
ANeuralNetworksEvent_getSyncFenceFd().
Output con dimensioni dinamiche
Per supportare i modelli in cui le dimensioni dell'output dipendono dai dati di input, ovvero quando le dimensioni non possono essere determinate al momento dell'esecuzione del modello, utilizza
ANeuralNetworksExecution_getOutputOperandRank
e
ANeuralNetworksExecution_getOutputOperandDimensions.
Il seguente esempio di codice mostra come eseguire questa operazione:
// Get the rank of the output uint32_t myOutputRank = 0; ANeuralNetworksExecution_getOutputOperandRank(run1, 0, &myOutputRank); // Get the dimensions of the output std::vector<uint32_t> myOutputDimensions(myOutputRank); ANeuralNetworksExecution_getOutputOperandDimensions(run1, 0, myOutputDimensions.data());
Pulizia
Il passaggio di pulizia gestisce la liberazione delle risorse interne utilizzate per il calcolo.
// Cleanup ANeuralNetworksCompilation_free(compilation); ANeuralNetworksModel_free(model); ANeuralNetworksMemory_free(mem1);
Gestione degli errori e fallback della CPU
Se si verifica un errore durante il partizionamento, se un driver non riesce a compilare una parte di un modello o se non riesce a eseguire una parte di un modello compilata, NNAPI potrebbe ripiegare sulla propria implementazione della CPU di una o più operazioni.
Se il client NNAPI contiene versioni ottimizzate dell'operazione (ad esempio TFLite), potrebbe essere vantaggioso disattivare il fallback della CPU e gestire gli errori con l'implementazione ottimizzata dell'operazione del client.
In Android 10, se la compilazione viene eseguita utilizzando
ANeuralNetworksCompilation_createForDevices, il fallback della CPU verrà disattivato.
In Android P, l'esecuzione di NNAPI viene eseguita sulla CPU se l'esecuzione sul driver non riesce.
Questo vale anche per Android 10 quando viene utilizzato ANeuralNetworksCompilation_create anziché ANeuralNetworksCompilation_createForDevices.
La prima esecuzione viene eseguita per una singola partizione e, se ancora non va a buon fine, viene riprovata l'intera esecuzione del modello sulla CPU.
Se il partizionamento o la compilazione non va a buon fine, l'intero modello verrà provato sulla CPU.
Esistono casi in cui alcune operazioni non sono supportate sulla CPU e in questi casi la compilazione o l'esecuzione non andrà a buon fine anziché eseguire il fallback.
Anche dopo aver disattivato il fallback della CPU, potrebbero essere presenti operazioni nel modello
pianificate sulla CPU. Se la CPU è nell'elenco dei processori forniti
a ANeuralNetworksCompilation_createForDevices ed è l'unico
processore che supporta queste operazioni o è il processore che offre le migliori
prestazioni per queste operazioni, verrà scelto come executor principale (non di riserva).
Per assicurarti che non venga eseguita la CPU, utilizza ANeuralNetworksCompilation_createForDevices
escludendo nnapi-reference dall'elenco dei dispositivi.
A partire da Android P, è possibile disattivare il fallback in fase di esecuzione nelle build DEBUG impostando la proprietà debug.nn.partition su 2.
Domini di memoria
In Android 11 e versioni successive, NNAPI supporta i domini di memoria che forniscono interfacce di allocatore per memorie opache. Ciò consente alle applicazioni di trasferire le memorie native del dispositivo tra le esecuzioni, in modo che NNAPI non copi o trasformi i dati inutilmente quando esegue esecuzioni consecutive sullo stesso driver.
La funzionalità del dominio di memoria è pensata per i tensori che sono principalmente interni al driver e che non richiedono un accesso frequente al lato client. Esempi di questi tensori includono i tensori di stato nei modelli di sequenza. Per i tensori che richiedono un accesso frequente alla CPU lato client, utilizza invece pool di memoria condivisa.
Per allocare una memoria opaca, segui questi passaggi:
Chiama la funzione
ANeuralNetworksMemoryDesc_create()per creare un nuovo descrittore di memoria:// Create a memory descriptor ANeuralNetworksMemoryDesc* desc; ANeuralNetworksMemoryDesc_create(&desc);
Specifica tutti i ruoli di input e output previsti chiamando
ANeuralNetworksMemoryDesc_addInputRole()eANeuralNetworksMemoryDesc_addOutputRole().// Specify that the memory may be used as the first input and the first output // of the compilation ANeuralNetworksMemoryDesc_addInputRole(desc, compilation, 0, 1.0f); ANeuralNetworksMemoryDesc_addOutputRole(desc, compilation, 0, 1.0f);
(Facoltativo) Specifica le dimensioni della memoria chiamando
ANeuralNetworksMemoryDesc_setDimensions().// Specify the memory dimensions uint32_t dims[] = {3, 4}; ANeuralNetworksMemoryDesc_setDimensions(desc, 2, dims);
Finalizza la definizione del descrittore chiamando
ANeuralNetworksMemoryDesc_finish().ANeuralNetworksMemoryDesc_finish(desc);
Alloca tutta la memoria di cui hai bisogno passando il descrittore a
ANeuralNetworksMemory_createFromDesc().// Allocate two opaque memories with the descriptor ANeuralNetworksMemory* opaqueMem; ANeuralNetworksMemory_createFromDesc(desc, &opaqueMem);
Libera il descrittore di memoria quando non ti serve più.
ANeuralNetworksMemoryDesc_free(desc);
Il cliente può utilizzare l'oggetto ANeuralNetworksMemory creato solo con
ANeuralNetworksExecution_setInputFromMemory() o
ANeuralNetworksExecution_setOutputFromMemory() in base ai ruoli
specificati nell'oggetto ANeuralNetworksMemoryDesc. Gli argomenti offset e lunghezza
devono essere impostati su 0, a indicare che viene utilizzata l'intera memoria. Il client
può anche impostare o estrarre esplicitamente i contenuti della memoria utilizzando
ANeuralNetworksMemory_copy().
Puoi creare ricordi opachi con ruoli di dimensioni o rango non specificati.
In questo caso, la creazione della memoria potrebbe non riuscire con lo stato
ANEURALNETWORKS_OP_FAILED se non è supportata dal driver
sottostante. Il client è invitato a implementare una logica di fallback allocando un buffer
sufficientemente grande supportato da Ashmem o AHardwareBuffer in modalità BLOB.
Quando NNAPI non ha più bisogno di accedere all'oggetto di memoria opaco, libera l'istanza ANeuralNetworksMemory corrispondente:
ANeuralNetworksMemory_free(opaqueMem);
Misurare il rendimento
Puoi valutare il rendimento della tua app misurando il tempo di esecuzione o tramite la profilazione.
Tempo di esecuzione
Quando vuoi determinare il tempo di esecuzione totale tramite il runtime, puoi utilizzare
l'API di esecuzione sincrona e misurare il tempo impiegato dalla chiamata. Quando vuoi determinare il tempo di esecuzione totale tramite un livello inferiore dello stack software, puoi utilizzare ANeuralNetworksExecution_setMeasureTiming e ANeuralNetworksExecution_getDuration per ottenere:
- tempo di esecuzione su un acceleratore (non nel driver, che viene eseguito sul processore host).
- tempo di esecuzione nel driver, incluso il tempo sull'acceleratore.
Il tempo di esecuzione nel driver esclude l'overhead, ad esempio quello del runtime stesso e l'IPC necessario per la comunicazione del runtime con il driver.
Queste API misurano la durata tra gli eventi di lavoro inviato e lavoro completato, anziché il tempo che un driver o un acceleratore dedica all'esecuzione dell'inferenza, che potrebbe essere interrotta dal cambio di contesto.
Ad esempio, se inizia l'inferenza 1, il driver interrompe il lavoro per eseguire l'inferenza 2, poi riprende e completa l'inferenza 1, il tempo di esecuzione dell'inferenza 1 includerà il tempo in cui il lavoro è stato interrotto per eseguire l'inferenza 2.
Queste informazioni sui tempi possono essere utili per un deployment di produzione di un'applicazione per raccogliere dati di telemetria per l'utilizzo offline. Puoi utilizzare i dati di temporizzazione per modificare l'app per ottenere prestazioni migliori.
Quando utilizzi questa funzionalità, tieni presente quanto segue:
- La raccolta di informazioni sui tempi potrebbe comportare un costo in termini di prestazioni.
- Solo un driver è in grado di calcolare il tempo trascorso al suo interno o sull'acceleratore, escluso il tempo trascorso nel runtime NNAPI e in IPC.
- Puoi utilizzare queste API solo con un
ANeuralNetworksExecutioncreato conANeuralNetworksCompilation_createForDevicesconnumDevices = 1. - Non è necessario che un autista sia in grado di segnalare le informazioni sui tempi.
Profila la tua applicazione con Android Systrace
A partire da Android 10, NNAPI genera automaticamente eventi systrace che puoi utilizzare per profilare la tua applicazione.
L'origine NNAPI include un'utilità parse_systrace per elaborare gli eventi
systrace generati dalla tua applicazione e generare una visualizzazione tabellare che mostra
il tempo trascorso nelle diverse fasi del ciclo di vita del modello (istanziamento,
preparazione, esecuzione della compilazione e terminazione) e nei diversi livelli delle
applicazioni. I livelli in cui è suddivisa l'applicazione sono:
Application: il codice dell'applicazione principaleRuntime: NNAPI RuntimeIPC: La comunicazione interprocesso tra il runtime NNAPI e il codice del driverDriver: il processo del driver dell'acceleratore.
Generare i dati dell'analisi di profilazione
Supponendo di aver estratto l'albero dei sorgenti AOSP in $ANDROID_BUILD_TOP e utilizzando l'esempio di classificazione delle immagini TFLite come applicazione di destinazione, puoi generare i dati di profilazione NNAPI con i seguenti passaggi:
- Avvia Android systrace con il seguente comando:
$ANDROID_BUILD_TOP/external/chromium-trace/systrace.py -o trace.html -a org.tensorflow.lite.examples.classification nnapi hal freq sched idle load binder_driver
Il parametro -o trace.html indica che le tracce verranno scritte in trace.html. Quando profili la tua applicazione, devi
sostituire org.tensorflow.lite.examples.classification con il nome del processo
specificato nel file manifest dell'app.
In questo modo, una delle console shell rimarrà occupata. Non eseguire il comando in
background, poiché attende in modo interattivo la chiusura di enter.
- Dopo aver avviato lo strumento di raccolta systrace, avvia l'app ed esegui il test benchmark.
Nel nostro caso, puoi avviare l'app Classificazione delle immagini da Android Studio o direttamente dall'interfaccia utente del telefono di test se l'app è già stata installata. Per generare alcuni dati NNAPI, devi configurare l'app in modo che utilizzi NNAPI selezionando NNAPI come dispositivo di destinazione nella finestra di dialogo di configurazione dell'app.
Al termine del test, termina la traccia di sistema premendo
enternel terminale della console attivo dal passaggio 1.Esegui l'utilità
systrace_parserper generare statistiche cumulative:
$ANDROID_BUILD_TOP/frameworks/ml/nn/tools/systrace_parser/parse_systrace.py --total-times trace.html
Il parser accetta i seguenti parametri:
- --total-times: mostra il tempo totale trascorso in un livello, incluso il tempo
trascorso in attesa dell'esecuzione di una chiamata a un livello sottostante
- --print-detail: stampa tutti gli eventi raccolti da systrace
- --per-execution: stampa solo l'esecuzione e le relative sottofasi
(come tempi per esecuzione) anziché le statistiche per tutte le fasi
- --json: produce l'output in formato JSON
Di seguito è riportato un esempio di output:
===========================================================================================================================================
NNAPI timing summary (total time, ms wall-clock) Execution
----------------------------------------------------
Initialization Preparation Compilation I/O Compute Results Ex. total Termination Total
-------------- ----------- ----------- ----------- ------------ ----------- ----------- ----------- ----------
Application n/a 19.06 1789.25 n/a n/a 6.70 21.37 n/a 1831.17*
Runtime - 18.60 1787.48 2.93 11.37 0.12 14.42 1.32 1821.81
IPC 1.77 - 1781.36 0.02 8.86 - 8.88 - 1792.01
Driver 1.04 - 1779.21 n/a n/a n/a 7.70 - 1787.95
Total 1.77* 19.06* 1789.25* 2.93* 11.74* 6.70* 21.37* 1.32* 1831.17*
===========================================================================================================================================
* This total ignores missing (n/a) values and thus is not necessarily consistent with the rest of the numbers
Il parser potrebbe non funzionare se gli eventi raccolti non rappresentano una traccia completa dell'applicazione. In particolare, potrebbe non riuscire se gli eventi systrace generati per contrassegnare la fine di una sezione sono presenti nella traccia senza un evento di inizio sezione associato. Ciò si verifica in genere se vengono generati alcuni eventi di una sessione di profilazione precedente quando avvii il raccoglitore systrace. In questo caso, dovrai eseguire di nuovo la profilazione.
Aggiungere statistiche per il codice dell'applicazione all'output di systrace_parser
L'applicazione parse_systrace si basa sulla funzionalità systrace integrata di Android. Puoi aggiungere tracce per operazioni specifiche nella tua app utilizzando l'API systrace (per Java , per le applicazioni native ) con nomi di eventi personalizzati.
Per associare gli eventi personalizzati alle fasi del ciclo di vita dell'applicazione, anteponi al nome dell'evento una delle seguenti stringhe:
[NN_LA_PI]: Evento a livello di applicazione per l'inizializzazione[NN_LA_PP]: Evento a livello di applicazione per la preparazione[NN_LA_PC]: Evento a livello di applicazione per la compilazione[NN_LA_PE]: Evento a livello di applicazione per l'esecuzione
Ecco un esempio di come puoi modificare il codice di esempio di classificazione delle immagini TFLite
aggiungendo una sezione runInferenceModel per la fase Execution e il
livello Application contenente altre sezioni preprocessBitmap che
non verranno prese in considerazione nelle tracce NNAPI. La sezione runInferenceModel farà parte degli eventi systrace elaborati dal parser systrace nnapi:
Kotlin
/** Runs inference and returns the classification results. */ fun recognizeImage(bitmap: Bitmap): List{ // This section won’t appear in the NNAPI systrace analysis Trace.beginSection("preprocessBitmap") convertBitmapToByteBuffer(bitmap) Trace.endSection() // Run the inference call. // Add this method in to NNAPI systrace analysis. Trace.beginSection("[NN_LA_PE]runInferenceModel") long startTime = SystemClock.uptimeMillis() runInference() long endTime = SystemClock.uptimeMillis() Trace.endSection() ... return recognitions }
Java
/** Runs inference and returns the classification results. */ public ListrecognizeImage(final Bitmap bitmap) { // This section won’t appear in the NNAPI systrace analysis Trace.beginSection("preprocessBitmap"); convertBitmapToByteBuffer(bitmap); Trace.endSection(); // Run the inference call. // Add this method in to NNAPI systrace analysis. Trace.beginSection("[NN_LA_PE]runInferenceModel"); long startTime = SystemClock.uptimeMillis(); runInference(); long endTime = SystemClock.uptimeMillis(); Trace.endSection(); ... Trace.endSection(); return recognitions; }
Qualità del servizio
In Android 11 e versioni successive, NNAPI consente una migliore qualità del servizio (QoS) consentendo a un'applicazione di indicare le priorità relative dei suoi modelli, la quantità massima di tempo prevista per preparare un determinato modello e la quantità massima di tempo prevista per completare un determinato calcolo. Android 11 introduce anche codici di risultato NNAPI aggiuntivi che consentono alle applicazioni di comprendere errori come il mancato rispetto delle scadenze di esecuzione.
Impostare la priorità di un workload
Per impostare la priorità di un workload NNAPI, chiama
ANeuralNetworksCompilation_setPriority()
prima di chiamare ANeuralNetworksCompilation_finish().
Impostare scadenze
Le applicazioni possono impostare scadenze sia per la compilazione del modello che per l'inferenza.
- Per impostare il timeout di compilazione, chiama
ANeuralNetworksCompilation_setTimeout()prima di chiamareANeuralNetworksCompilation_finish(). - Per impostare il timeout dell'inferenza, chiama
ANeuralNetworksExecution_setTimeout()prima di avviare la compilazione.
Scopri di più sugli operandi
La sezione seguente tratta argomenti avanzati sull'utilizzo degli operandi.
Tensori quantizzati
Un tensore quantizzato è un modo compatto per rappresentare un array n-dimensionale di valori in virgola mobile.
NNAPI supporta i tensori quantizzati asimmetrici a 8 bit. Per questi tensori, il valore di ogni cella è rappresentato da un numero intero a 8 bit. Al tensore sono associati un valore di scala e un punto zero. Questi vengono utilizzati per convertire gli interi a 8 bit nei valori in virgola mobile rappresentati.
La formula è:
(cellValue - zeroPoint) * scale
dove il valore zeroPoint è un numero intero a 32 bit e la scala un valore in virgola mobile a 32 bit.
Rispetto ai tensori di valori in virgola mobile a 32 bit, i tensori quantizzati a 8 bit presentano due vantaggi:
- La tua applicazione è più piccola, poiché i pesi addestrati occupano un quarto delle dimensioni dei tensori a 32 bit.
- I calcoli possono spesso essere eseguiti più rapidamente. Ciò è dovuto alla minore quantità di dati da recuperare dalla memoria e all'efficienza dei processori, come i DSP, nell'esecuzione di calcoli con numeri interi.
Sebbene sia possibile convertire un modello in virgola mobile in uno quantizzato, la nostra esperienza ha dimostrato che si ottengono risultati migliori addestrando direttamente un modello quantizzato. In effetti, la rete neurale impara a compensare l'aumento della granularità di ogni valore. Per ogni tensore quantizzato, i valori di scala e zeroPoint vengono determinati durante il processo di addestramento.
In NNAPI, definisci i tipi di tensore quantizzati impostando il campo del tipo della struttura di dati
ANeuralNetworksOperandType
su
ANEURALNETWORKS_TENSOR_QUANT8_ASYMM.
Specifichi anche la scala e il valore zeroPoint del tensore in questa struttura di dati.
Oltre ai tensori quantizzati asimmetrici a 8 bit, l'API NN supporta quanto segue:
ANEURALNETWORKS_TENSOR_QUANT8_SYMM_PER_CHANNELche puoi utilizzare per rappresentare i pesi per le operazioniCONV/DEPTHWISE_CONV/TRANSPOSED_CONV.ANEURALNETWORKS_TENSOR_QUANT16_ASYMMche puoi utilizzare per lo stato interno diQUANTIZED_16BIT_LSTM.ANEURALNETWORKS_TENSOR_QUANT8_SYMMche può essere un input perANEURALNETWORKS_DEQUANTIZE.
Operandi facoltativi
Alcune operazioni, come
ANEURALNETWORKS_LSH_PROJECTION,
accettano operandi facoltativi. Per indicare nel modello che l'operando facoltativo è
omesso, chiama la funzione
ANeuralNetworksModel_setOperandValue(), passando NULL per il buffer e 0 per la lunghezza.
Se la decisione di indicare se l'operando è presente o meno varia per ogni
esecuzione, indica che l'operando viene omesso utilizzando le funzioni
ANeuralNetworksExecution_setInput()
o
ANeuralNetworksExecution_setOutput(), passando NULL per il buffer e 0 per la lunghezza.
Tensori di rango sconosciuto
Android 9 (livello API 28) ha introdotto operandi del modello di dimensioni sconosciute ma di rango noto (il numero di dimensioni). Android 10 (livello API 29) ha introdotto tensori di rango sconosciuto, come mostrato in ANeuralNetworksOperandType.
Benchmark NNAPI
Il benchmark NNAPI è disponibile su AOSP in platform/test/mlts/benchmark
(app di benchmark) e platform/test/mlts/models (modelli e set di dati).
Il benchmark valuta la latenza e l'accuratezza e confronta i driver con lo stesso lavoro svolto utilizzando TensorFlow Lite in esecuzione sulla CPU, per gli stessi modelli e set di dati.
Per utilizzare il benchmark:
Collega un dispositivo Android di destinazione al computer, apri una finestra del terminale e assicurati che il dispositivo sia raggiungibile tramite ADB.
Se sono connessi più dispositivi Android, esporta la variabile di ambiente
ANDROID_SERIALdel dispositivo di destinazione.Vai alla directory di origine di primo livello di Android.
Esegui questi comandi:
lunch aosp_arm-userdebug # Or aosp_arm64-userdebug if available ./test/mlts/benchmark/build_and_run_benchmark.sh
Al termine di un'esecuzione del benchmark, i risultati verranno presentati come una pagina HTML trasferita a
xdg-open.
Log NNAPI
NNAPI genera informazioni diagnostiche utili nei log di sistema. Per analizzare i log, utilizza l'utilità logcat.
Attiva la registrazione dettagliata di NNAPI per fasi o componenti specifici impostando la proprietà
debug.nn.vlog (utilizzando adb shell) sul seguente elenco di valori,
separati da spazio, due punti o virgola:
model: Creazione del modellocompilation: Generazione del piano di esecuzione del modello e compilazioneexecution: Esecuzione del modellocpuexe: Esecuzione di operazioni utilizzando l'implementazione della CPU NNAPImanager: Estensioni NNAPI, interfacce disponibili e informazioni sulle funzionalità correlateallo1: tutti gli elementi precedenti
Ad esempio, per attivare il logging dettagliato completo, utilizza il comando
adb shell setprop debug.nn.vlog all. Per disattivare la registrazione dettagliata, utilizza il comando
adb shell setprop debug.nn.vlog '""'.
Una volta abilitato, il logging dettagliato genera voci di log a livello INFO con un tag impostato sul nome della fase o del componente.
Oltre ai messaggi controllati debug.nn.vlog, i componenti dell'API NNAPI forniscono
altre voci di log a vari livelli, ognuna delle quali utilizza un tag di log specifico.
Per ottenere un elenco di componenti, cerca nell'albero delle origini utilizzando la seguente espressione:
grep -R 'define LOG_TAG' | awk -F '"' '{print $2}' | sort -u | egrep -v "Sample|FileTag|test"
Questa espressione restituisce attualmente i seguenti tag:
- BurstBuilder
- Callback
- CompilationBuilder
- CpuExecutor
- ExecutionBuilder
- ExecutionBurstController
- ExecutionBurstServer
- ExecutionPlan
- FibonacciDriver
- GraphDump
- IndexedShapeWrapper
- IonWatcher
- Manager
- Memoria
- MemoryUtils
- MetaModel
- ModelArgumentInfo
- ModelBuilder
- NeuralNetworks
- OperationResolver
- Fasi operative
- OperationsUtils
- PackageInfo
- TokenHasher
- TypeManager
- Utils
- ValidateHal
- VersionedInterfaces
Per controllare il livello dei messaggi di log mostrati da logcat, utilizza
la variabile di ambiente ANDROID_LOG_TAGS.
Per mostrare l'insieme completo di messaggi di log NNAPI e disabilitare tutti gli altri, imposta ANDROID_LOG_TAGS su
quanto segue:
BurstBuilder:V Callbacks:V CompilationBuilder:V CpuExecutor:V ExecutionBuilder:V ExecutionBurstController:V ExecutionBurstServer:V ExecutionPlan:V FibonacciDriver:V GraphDump:V IndexedShapeWrapper:V IonWatcher:V Manager:V MemoryUtils:V Memory:V MetaModel:V ModelArgumentInfo:V ModelBuilder:V NeuralNetworks:V OperationResolver:V OperationsUtils:V Operations:V PackageInfo:V TokenHasher:V TypeManager:V Utils:V ValidateHal:V VersionedInterfaces:V *:S.
Puoi impostare ANDROID_LOG_TAGS utilizzando il seguente comando:
export ANDROID_LOG_TAGS=$(grep -R 'define LOG_TAG' | awk -F '"' '{ print $2 ":V" }' | sort -u | egrep -v "Sample|FileTag|test" | xargs echo -n; echo ' *:S')
Tieni presente che si tratta solo di un filtro che si applica a logcat. Devi comunque
impostare la proprietà debug.nn.vlog su all per generare informazioni dettagliate sui log.