
In Coroutinen ist ein Flow ein Typ, der mehrere Werte sequenziell ausgeben kann. Suspend-Funktionen geben dagegen nur einen einzelnen Wert zurück. Sie können beispielsweise einen Ablauf verwenden, um Live-Updates aus einer Datenbank zu erhalten.
Flows basieren auf Coroutinen und können mehrere Werte liefern.
Ein Flow ist konzeptionell ein Datenstream, der asynchron berechnet werden kann. Die ausgegebenen Werte müssen denselben Typ haben. Ein Flow<Int> ist beispielsweise ein Flow, der Ganzzahlwerte ausgibt.
Ein Flow ähnelt sehr stark einem Iterator, der eine Sequenz von Werten erzeugt, verwendet jedoch suspend-Funktionen, um Werte asynchron zu erzeugen und zu verarbeiten. Das bedeutet beispielsweise, dass der Flow sicher eine Netzwerkanfrage stellen kann, um den nächsten Wert zu erzeugen, ohne den Hauptthread zu blockieren.
Es gibt drei Entitäten, die an Datenstreams beteiligt sind:
- Ein Producer erzeugt Daten, die dem Stream hinzugefügt werden. Dank Coroutinen können Flows auch asynchron Daten erzeugen.
- (Optional) Intermediaries können jeden Wert, der in den Stream ausgegeben wird, oder den Stream selbst ändern.
- Ein Consumer verwendet die Werte aus dem Stream.
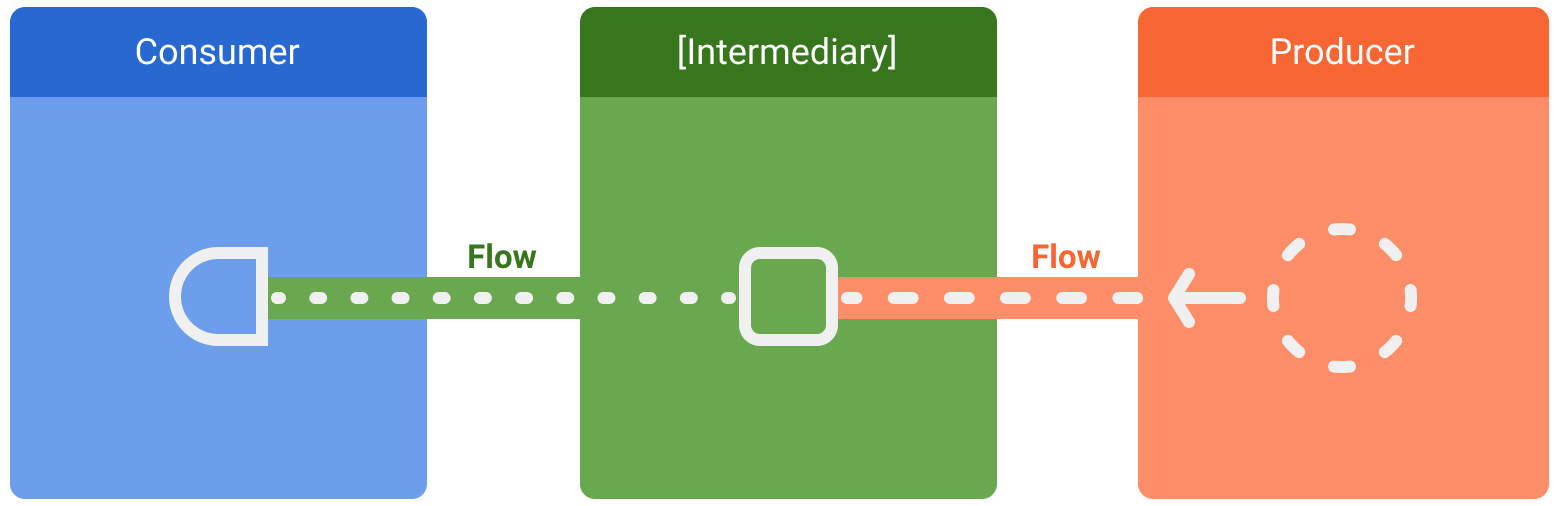
In Android ist ein Repository in der Regel ein Erzeuger von UI-Daten, wobei die Benutzeroberfläche (UI) der Consumer ist, der die Daten letztendlich anzeigt. Manchmal ist die UI-Ebene ein Erzeuger von Nutzereingabeereignissen und andere Ebenen der Hierarchie nutzen sie. Ebenen zwischen Ersteller und Nutzer fungieren in der Regel als Vermittler, die den Datenstrom an die Anforderungen der folgenden Ebene anpassen.
Ablauf erstellen
Verwenden Sie zum Erstellen von Abläufen die APIs des Flow Builder. Die Builder-Funktion flow erstellt einen neuen Flow, in den Sie mit der Funktion emit manuell neue Werte in den Datenstream einfügen können.
Im folgenden Beispiel ruft eine Datenquelle die neuesten Nachrichten automatisch in einem festen Intervall ab. Da eine suspend-Funktion nicht mehrere aufeinanderfolgende Werte zurückgeben kann, erstellt und gibt die Datenquelle einen Flow zurück, um diese Anforderung zu erfüllen. In diesem Fall fungiert die Datenquelle als Producer.
class NewsRemoteDataSource( private val newsApi: NewsApi, private val refreshIntervalMs: Long = 5000 ) { val latestNews: Flow<List<ArticleHeadline>> = flow { while (true) { val latestNews = newsApi.fetchLatestNews() emit(latestNews) // Emits the result of the request to the flow delay(refreshIntervalMs) // Suspends the coroutine for some time } } } // Interface that provides a way to make network requests with suspend functions interface NewsApi { suspend fun fetchLatestNews(): List<ArticleHeadline> }
Der flow-Builder wird in einer Coroutine ausgeführt. Daher profitiert sie von denselben asynchronen APIs, es gelten jedoch einige Einschränkungen:
- Flows sind sequenziell. Da sich der Producer in einer Coroutine befindet, wird er beim Aufrufen einer suspend-Funktion angehalten, bis die suspend-Funktion zurückkehrt. Im Beispiel wird der Producer angehalten, bis die Netzwerkanfrage
fetchLatestNewsabgeschlossen ist. Erst dann wird das Ergebnis an den Stream ausgegeben. - Mit dem
flow-Builder kann der Producer keineemit-Werte aus einem anderenCoroutineContextabrufen. Rufen Sieemitdaher nicht in einem anderenCoroutineContextauf, indem Sie neue Coroutinen erstellen oderwithContext-Codeblöcke verwenden. In diesen Fällen können Sie andere Flow-Builder wiecallbackFlowverwenden.
Stream ändern.
Vermittler können Zwischenoperatoren verwenden, um den Datenstrom zu ändern, ohne die Werte zu nutzen. Diese Operatoren sind Funktionen, die, wenn sie auf einen Datenstream angewendet werden, eine Kette von Vorgängen einrichten, die erst ausgeführt werden, wenn die Werte in der Zukunft verwendet werden. Weitere Informationen zu Zwischenoperatoren
Im Beispiel unten wird in der Repository-Ebene der Zwischenoperator map verwendet, um die Daten für die Anzeige auf der View zu transformieren:
class NewsRepository( private val newsRemoteDataSource: NewsRemoteDataSource, private val userData: UserData ) { /** * Returns the favorite latest news applying transformations on the flow. * These operations are lazy and don't trigger the flow. They just transform * the current value emitted by the flow at that point in time. */ val favoriteLatestNews: Flow<List<ArticleHeadline>> = newsRemoteDataSource.latestNews // Intermediate operation to filter the list of favorite topics .map { news -> news.filter { userData.isFavoriteTopic(it) } } // Intermediate operation to save the latest news in the cache .onEach { news -> saveInCache(news) } }
Zwischenoperatoren können nacheinander angewendet werden und bilden so eine Kette von Vorgängen, die verzögert ausgeführt werden, wenn ein Element in den Flow ausgegeben wird. Wenn Sie einen Zwischenoperator auf einen Stream anwenden, wird die Flow-Erfassung nicht gestartet.
Einnahmen aus einem Flow erzielen
Verwenden Sie einen Terminal-Operator, um den Ablauf zu starten und auf Werte zu warten. Wenn Sie alle Werte im Stream abrufen möchten, sobald sie ausgegeben werden, verwenden Sie collect.
Weitere Informationen zu Terminaloperatoren finden Sie in der offiziellen Flow-Dokumentation.
Da collect eine suspend-Funktion ist, muss sie in einer Koroutine ausgeführt werden. Sie verwendet eine Lambda-Funktion als Parameter, die für jeden neuen Wert aufgerufen wird. Da es sich um eine suspend-Funktion handelt, kann die Coroutine, die collect aufruft, angehalten werden, bis der Flow geschlossen wird.
Hier sehen Sie eine einfache Implementierung von ViewModel, die die Daten aus der Repository-Ebene verwendet:
class LatestNewsViewModel( private val newsRepository: NewsRepository ) : ViewModel() { init { viewModelScope.launch { // Trigger the flow and consume its elements using collect newsRepository.favoriteLatestNews.collect { favoriteNews -> // Update UI with the latest favorite news } } } }
Durch das Erfassen des Flows wird der Producer ausgelöst, der die neuesten Nachrichten aktualisiert und das Ergebnis der Netzwerkanfrage in einem festen Intervall ausgibt. Da der Producer mit der while(true)-Schleife immer aktiv bleibt, wird der Datenstream geschlossen, wenn das ViewModel gelöscht und viewModelScope abgebrochen wird.
Die Erfassung von Flows kann aus folgenden Gründen beendet werden:
- Die Coroutine, die die Daten erfasst, wird wie im vorherigen Beispiel abgebrochen. Dadurch wird auch der zugrunde liegende Producer beendet.
- Der Producer hat alle Elemente ausgegeben. In diesem Fall wird der Datenstream geschlossen und die Coroutine, die
collectaufgerufen hat, wird fortgesetzt.
Flows sind kalt und lazy, sofern nicht mit anderen Zwischenoperatoren angegeben. Das bedeutet, dass der Erstellercode jedes Mal ausgeführt wird, wenn ein terminaler Operator für den Flow aufgerufen wird. Im vorherigen Beispiel führt das Vorhandensein mehrerer Flow-Collectoren dazu, dass die Datenquelle die neuesten Nachrichten mehrmals in verschiedenen festen Intervallen abruft. Wenn Sie einen Flow optimieren und freigeben möchten, wenn mehrere Nutzer gleichzeitig Daten erfassen, verwenden Sie den Operator shareIn.
Unerwartete Ausnahmen abfangen
Die Implementierung des Producers kann aus einer Drittanbieterbibliothek stammen.
Das bedeutet, dass unerwartete Ausnahmen ausgelöst werden können. Verwenden Sie den Zwischenoperator catch, um diese Ausnahmen zu verarbeiten.
class LatestNewsViewModel( private val newsRepository: NewsRepository ) : ViewModel() { init { viewModelScope.launch { newsRepository.favoriteLatestNews // Intermediate catch operator. If an exception is thrown, // catch and update the UI .catch { exception -> notifyError(exception) } .collect { favoriteNews -> // Update UI with the latest favorite news } } } }
Im vorherigen Beispiel wird die Lambda-Funktion collect nicht aufgerufen, wenn eine Ausnahme auftritt, da kein neues Element empfangen wurde.
Mit catch können auch emit-Elemente in den Ablauf eingefügt werden. Die Beispiel-Repository-Ebene könnte stattdessen emit:
class NewsRepository( // ... ) { val favoriteLatestNews: Flow<List<ArticleHeadline>> = newsRemoteDataSource.latestNews .map { news -> news.filter { userData.isFavoriteTopic(it) } } .onEach { news -> saveInCache(news) } // If an error happens, emit the last cached values .catch { exception -> emit(lastCachedNews()) } }
In diesem Beispiel wird bei Auftreten einer Ausnahme die Lambda-Funktion collect aufgerufen, da aufgrund der Ausnahme ein neues Element in den Stream ausgegeben wurde.
Ausführung in einem anderen CoroutineContext
Standardmäßig wird der Producer eines flow-Builders im CoroutineContext der Coroutine ausgeführt, die Daten daraus abruft. Wie bereits erwähnt, können keine emit-Werte aus einem anderen CoroutineContext abgerufen werden. Dieses Verhalten ist in einigen Fällen möglicherweise unerwünscht.
In den Beispielen in diesem Thema sollte die Repository-Ebene beispielsweise keine Vorgänge für Dispatchers.Main ausführen, die von viewModelScope verwendet werden.
Wenn Sie die CoroutineContext eines Ablaufs ändern möchten, verwenden Sie den Zwischenoperator flowOn.
flowOn ändert die CoroutineContext des Upstream-Flows, d. h. des Producers und aller Zwischenoperatoren, die vor (oder über)
flowOn angewendet werden. Der Downstream-Flow (die Zwischenoperatoren after flowOn zusammen mit dem Consumer) ist nicht betroffen und wird auf dem CoroutineContext ausgeführt, der zum collect des Flows verwendet wird. Wenn es mehrere flowOn-Operatoren gibt, wird der Upstream durch jeden Operator an seiner aktuellen Position geändert.
class NewsRepository( private val newsRemoteDataSource: NewsRemoteDataSource, private val userData: UserData, private val defaultDispatcher: CoroutineDispatcher ) { val favoriteLatestNews: Flow<List<ArticleHeadline>> = newsRemoteDataSource.latestNews .map { news -> // Executes on the default dispatcher news.filter { userData.isFavoriteTopic(it) } } .onEach { news -> // Executes on the default dispatcher saveInCache(news) } // flowOn affects the upstream flow ↑ .flowOn(defaultDispatcher) // the downstream flow ↓ is not affected .catch { exception -> // Executes in the consumer's context emit(lastCachedNews()) } }
In diesem Code verwenden die Operatoren onEach und map defaultDispatcher, während der Operator catch und der Consumer auf Dispatchers.Main ausgeführt werden, das von viewModelScope verwendet wird.
Da die Datenquellenschicht E/A-Vorgänge ausführt, sollten Sie einen Dispatcher verwenden, der für E/A-Vorgänge optimiert ist:
class NewsRemoteDataSource( // ... private val ioDispatcher: CoroutineDispatcher ) { val latestNews: Flow<List<ArticleHeadline>> = flow { // Executes on the IO dispatcher // ... } .flowOn(ioDispatcher) }
Flows in Jetpack-Bibliotheken
Flow ist in viele Jetpack-Bibliotheken integriert und wird häufig in Android-Drittanbieterbibliotheken verwendet. Flow eignet sich hervorragend für Live-Datenupdates und endlose Datenstreams.
Mit Flow mit Room können Sie sich über Änderungen in einer Datenbank benachrichtigen lassen. Wenn Sie Data Access Objects (DAO) verwenden, geben Sie den Typ Flow zurück, um Live-Updates zu erhalten.
@Dao abstract class ExampleDao { @Query("SELECT * FROM Example") abstract fun getExamples(): Flow<List<Example>> }
Jedes Mal, wenn sich die Tabelle Example ändert, wird eine neue Liste mit den neuen Elementen in der Datenbank ausgegeben.
Callback-basierte APIs in Flows konvertieren
callbackFlow ist ein Flow-Builder, mit dem Sie auf Callbacks basierende APIs in Flows umwandeln können.
Die Android-APIs für Firebase Firestore verwenden beispielsweise Callbacks.
So konvertieren Sie diese APIs in Flows und warten auf Firestore-Datenbankupdates:
class FirestoreUserEventsDataSource(
private val firestore: FirebaseFirestore
) {
// Method to get user events from the Firestore database
fun getUserEvents(): Flow<UserEvents> = callbackFlow {
// Reference to use in Firestore
var eventsCollection: CollectionReference? = null
try {
eventsCollection = FirebaseFirestore.getInstance()
.collection("collection")
.document("app")
} catch (e: Throwable) {
// If Firebase cannot be initialized, close the stream of data
// flow consumers will stop collecting and the coroutine will resume
close(e)
}
// Registers callback to firestore, which will be called on new events
val subscription = eventsCollection?.addSnapshotListener { snapshot, _ ->
if (snapshot == null) { return@addSnapshotListener }
// Sends events to the flow! Consumers will get the new events
try {
trySend(snapshot.getEvents())
} catch (e: Throwable) {
// Event couldn't be sent to the flow
}
}
// The callback inside awaitClose will be executed when the flow is
// either closed or cancelled.
// In this case, remove the callback from Firestore
awaitClose { subscription?.remove() }
}
}
Im Gegensatz zum flow-Builder können mit callbackFlow Werte mit der Funktion send aus einem anderen CoroutineContext oder mit der Funktion trySend außerhalb einer Coroutine ausgegeben werden.
Intern verwendet callbackFlow einen Channel, der konzeptionell einer blockierenden Queue sehr ähnlich ist.
Ein Channel wird mit einer Kapazität konfiguriert, der maximalen Anzahl von Elementen, die gepuffert werden können. Der in callbackFlow erstellte Channel hat eine Standardkapazität von 64 Elementen. Wenn Sie versuchen, einem vollen Channel ein neues Element hinzuzufügen, wird der Producer bei send angehalten, bis Platz für das neue Element vorhanden ist. Bei trySend wird das Element nicht dem Channel hinzugefügt und false wird sofort zurückgegeben.
trySend fügt das angegebene Element sofort dem Channel hinzu, sofern dadurch die Kapazitätsbeschränkungen nicht verletzt werden, und gibt dann das erfolgreiche Ergebnis zurück.
Zusätzliche Ressourcen für den Ablauf
- Kotlin-Flows unter Android testen
StateFlowundSharedFlow- Zusätzliche Ressourcen für Kotlin-Coroutinen und -Flow