
Sposób testowania jednostek lub modułów, które komunikują się z przepływem, zależy od tego, czy testowany podmiot używa przepływu jako wejścia czy wyjścia.
- Jeśli badana osoba obserwuje przepływ, możesz wygenerować przepływy w ramach fałszywych zależności, które możesz kontrolować za pomocą testów.
- Jeśli jednostka lub moduł udostępnia przepływ, możesz odczytać i zweryfikować co najmniej 1 element wygenerowany przez przepływ w ramach testu.
Tworzenie fałszywego producenta
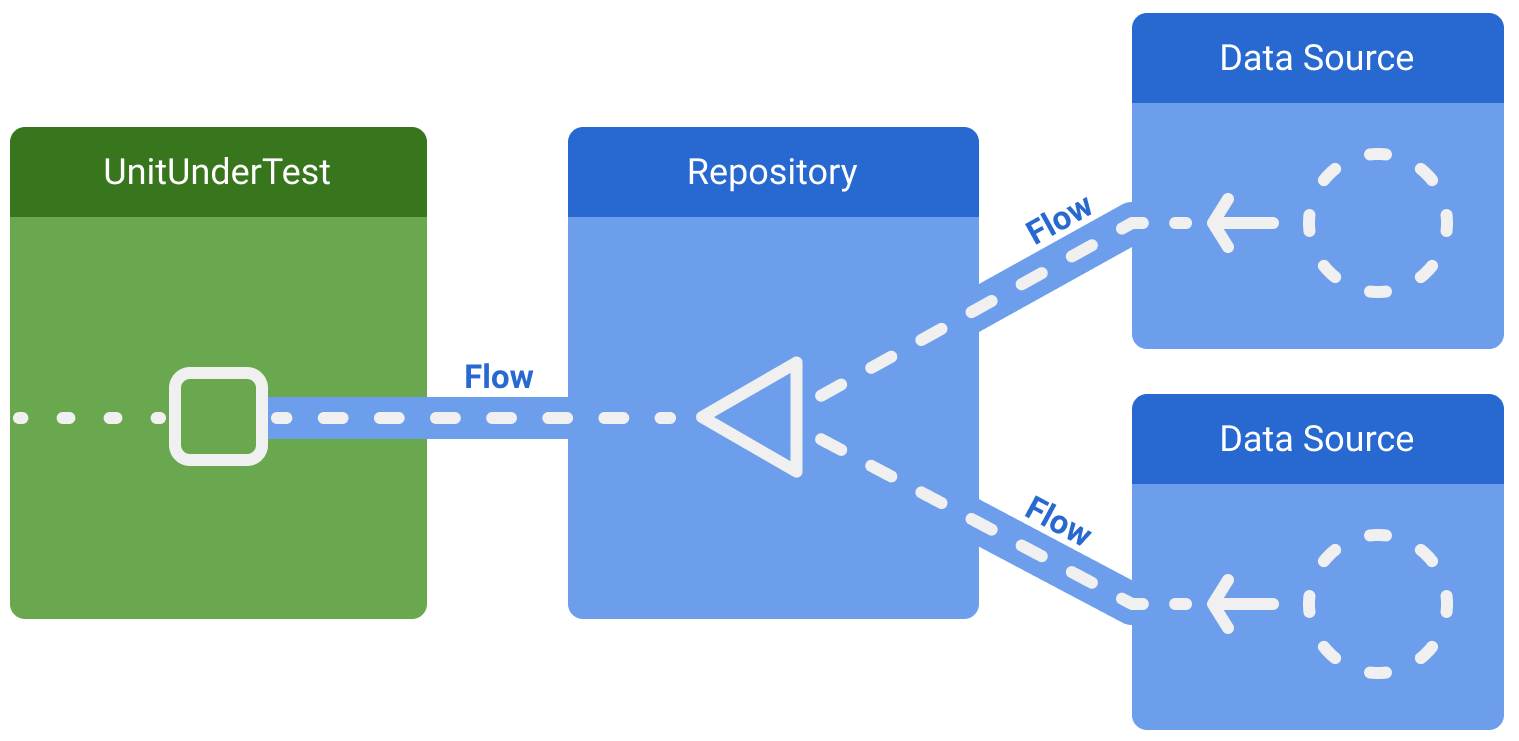
Jeśli testowany podmiot jest konsumentem przepływu, jednym z popularnych sposobów przetestowania go jest zastąpienie producenta fałszywą implementacją. Na przykład klasa, która obserwuje repozytorium pobierające dane z 2 źródeł danych w produkcji:
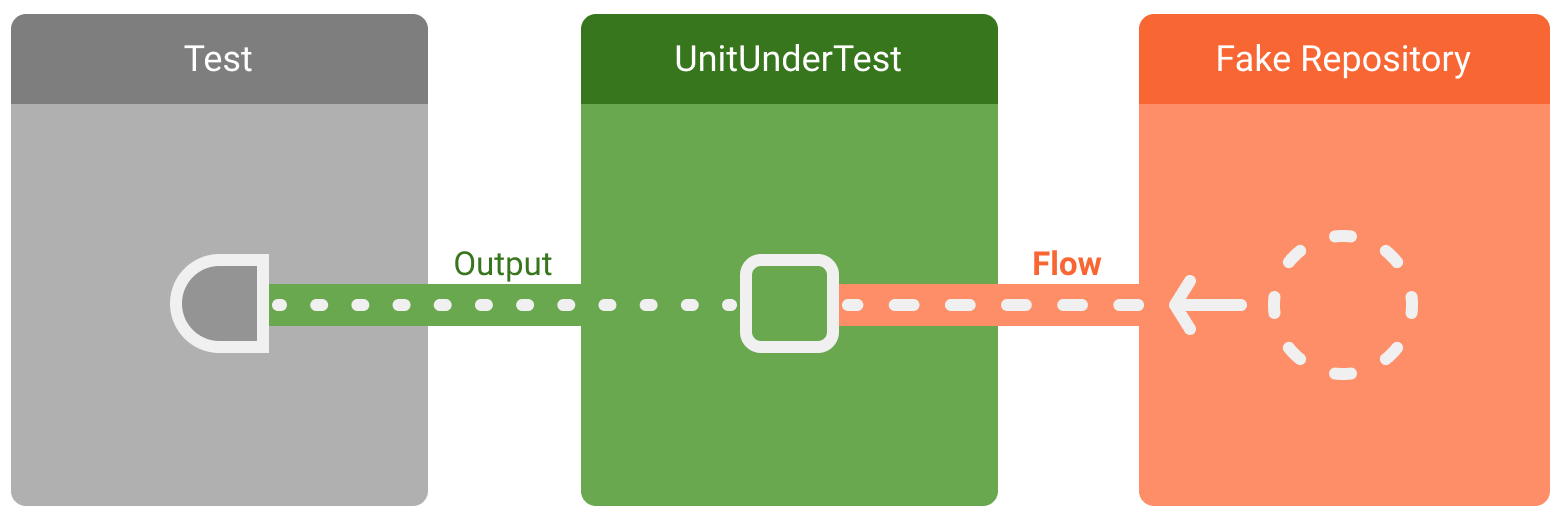
Aby test był deterministyczny, możesz zastąpić repozytorium i jego zależności fałszywym repozytorium, które zawsze emituje te same fałszywe dane:
Aby wygenerować w przepływie zdefiniowany wcześniej ciąg wartości, użyj kreatora flow:
class MyFakeRepository : MyRepository {
fun observeCount() = flow {
emit(ITEM_1)
}
}
Podczas testu to fałszywe repozytorium jest wstrzykiwane, zastępując prawdziwą implementację:
@Test
fun myTest() {
// Given a class with fake dependencies:
val sut = MyUnitUnderTest(MyFakeRepository())
// Trigger and verify
...
}
Teraz, gdy masz kontrolę nad wyjściami testowanego podmiotu, możesz sprawdzić, czy działa on prawidłowo, sprawdzając jego wyjścia.
Sprawdzanie emisji w przepływie w teście
Jeśli testowany obiekt udostępnia przepływ danych, test musi zawierać stwierdzenia dotyczące elementów strumienia danych.
Załóżmy, że repozytorium z poprzedniego przykładu udostępnia przepływ:
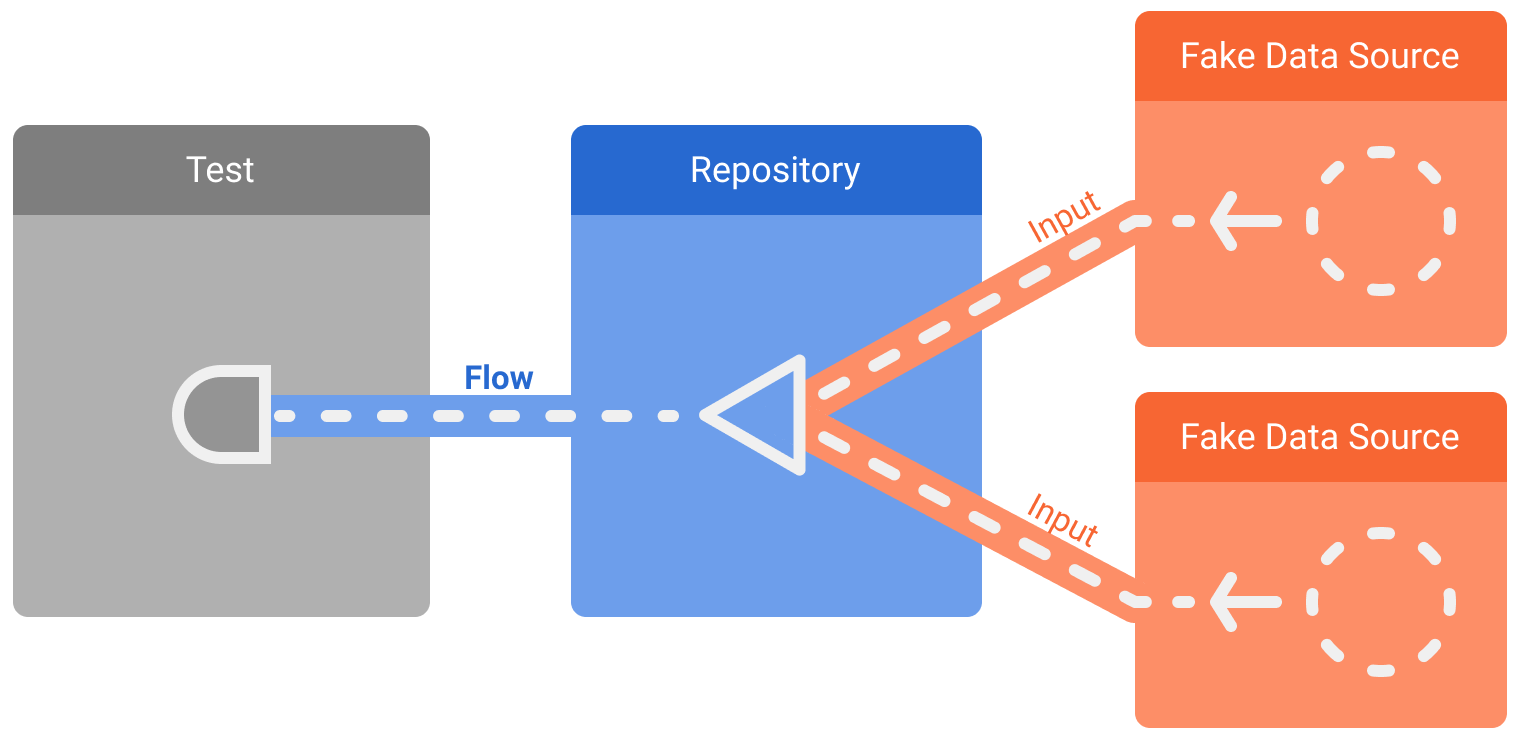
W przypadku niektórych testów wystarczy sprawdzić tylko pierwszą emisję lub ograniczoną liczbę elementów pochodzących z przepływu.
Możesz wykorzystać pierwszy element emitowany do przepływu, wywołując funkcję first(). Ta funkcja czeka na otrzymanie pierwszego elementu, a potem wysyła sygnał anulowania do producenta.
@Test
fun myRepositoryTest() = runTest {
// Given a repository that combines values from two data sources:
val repository = MyRepository(fakeSource1, fakeSource2)
// When the repository emits a value
val firstItem = repository.counter.first() // Returns the first item in the flow
// Then check it's the expected item
assertEquals(ITEM_1, firstItem)
}
Jeśli test musi sprawdzić wiele wartości, wywołanie funkcji toList() powoduje, że przepływ czeka na wyemitowanie wszystkich wartości przez źródło, a następnie zwraca te wartości jako listę. Działa to tylko w przypadku strumieni danych o ograniczonym czasie trwania.
@Test
fun myRepositoryTest() = runTest {
// Given a repository with a fake data source that emits ALL_MESSAGES
val messages = repository.observeChatMessages().toList()
// When all messages are emitted then they should be ALL_MESSAGES
assertEquals(ALL_MESSAGES, messages)
}
W przypadku strumieni danych, które wymagają bardziej złożonej kolekcji elementów lub nie zwracają skończonej liczby elementów, możesz użyć interfejsu API Flow do wybierania i przekształcania elementów. Oto przykłady:
// Take the second item
outputFlow.drop(1).first()
// Take the first 5 items
outputFlow.take(5).toList()
// Takes the first item verifying that the flow is closed after that
outputFlow.single()
// Finite data streams
// Verify that the flow emits exactly N elements (optional predicate)
outputFlow.count()
outputFlow.count(predicate)
Ciągłe zbieranie danych podczas testu
Zbieranie danych za pomocą funkcji toList(), jak w poprzednim przykładzie, używa wewnętrznie funkcji collect() i zostaje zawieszone, dopóki cała lista wyników nie będzie gotowa do zwrócenia.
Aby przeplatać działania, które powodują emisję wartości przez przepływ i sprawdzenia tych wartości, możesz stale zbierać wartości z przepływu podczas testu.
Weźmy na przykład klasę Repository, która ma być testowana, oraz towarzyszącą jej implementację fałszywego źródła danych, która ma metodę emit do dynamicznego generowania wartości podczas testu:
class Repository(private val dataSource: DataSource) {
fun scores(): Flow<Int> {
return dataSource.counts().map { it * 10 }
}
}
class FakeDataSource : DataSource {
private val flow = MutableSharedFlow<Int>()
suspend fun emit(value: Int) = flow.emit(value)
override fun counts(): Flow<Int> = flow
}
Gdy używasz tego fałszywego obiektu w teście, możesz utworzyć coroutine zbierającą, która będzie stale otrzymywać wartości z obiektu Repository. W tym przykładzie zbieramy je na liście, a potem sprawdzamy ich zawartość:
@Test
fun continuouslyCollect() = runTest {
val dataSource = FakeDataSource()
val repository = Repository(dataSource)
val values = mutableListOf<Int>()
backgroundScope.launch(UnconfinedTestDispatcher(testScheduler)) {
repository.scores().toList(values)
}
dataSource.emit(1)
assertEquals(10, values[0]) // Assert on the list contents
dataSource.emit(2)
dataSource.emit(3)
assertEquals(30, values[2])
assertEquals(3, values.size) // Assert the number of items collected
}
Ponieważ przepływ danych udostępniony przez Repository nigdy się nie kończy, wywołanie toList, które go zbiera, nigdy nie zwraca danych. Uruchomienie coroutine zbierającej w TestScope.backgroundScope zapewnia, że coroutine zostanie anulowana przed zakończeniem testu. W przeciwnym razie runTest będzie czekać na jego zakończenie, co spowoduje, że test przestanie odpowiadać i ostatecznie zakończy się niepowodzeniem.
Zwróć uwagę, że w tym przypadku do zbierania danych służy UnconfinedTestDispatcher. Dzięki temu coroutine do zbierania jest uruchamiana z energicznym wywołaniem i jest gotowa do odbierania wartości po zwróceniu przez launch.
Korzystanie z Turbine
Biblioteka zewnętrzna Turbine udostępnia wygodny interfejs API do tworzenia coroutine zbierających, a także inne przydatne funkcje do testowania przepływów:
@Test
fun usingTurbine() = runTest {
val dataSource = FakeDataSource()
val repository = Repository(dataSource)
repository.scores().test {
// Make calls that will trigger value changes only within test{}
dataSource.emit(1)
assertEquals(10, awaitItem())
dataSource.emit(2)
awaitItem() // Ignore items if needed, can also use skip(n)
dataSource.emit(3)
assertEquals(30, awaitItem())
}
}
Aby dowiedzieć się więcej, zapoznaj się z dokumentacją biblioteki.
Testowanie StateFlow
StateFlow to obserwowalny uchwyt danych, który można zbierać, aby obserwować wartości, które zawiera w czasie jako strumień. Pamiętaj, że ten strumień wartości jest łączony, co oznacza, że jeśli wartości są ustawiane w StateFlow bardzo szybko, odbiorcom tego StateFlow nie jest gwarantowane otrzymywanie wszystkich wartości pośrednich, tylko najnowszej.
Podczas testów, jeśli weźmiesz pod uwagę konwergencję, możesz zbierać wartości StateFlow, tak jak w przypadku innych strumieni danych, np. Turbine. W niektórych scenariuszach testów może być przydatne zebranie wszystkich wartości pośrednich i sprawdzenie ich.
Zasadniczo zalecamy jednak traktowanie elementu StateFlow jako trzymacza danych i zamiast tego stosowanie w przypadku tego elementu właściwości value. Dzięki temu testy sprawdzają aktualny stan obiektu w danym momencie i nie zależą od tego, czy nastąpiło połączenie.
Na przykład ViewModel, który zbiera wartości z Repository i wyświetla je w interfejsie w komponencie StateFlow:
class MyViewModel(private val myRepository: MyRepository) : ViewModel() {
private val _score = MutableStateFlow(0)
val score: StateFlow<Int> = _score.asStateFlow()
fun initialize() {
viewModelScope.launch {
myRepository.scores().collect { score ->
_score.value = score
}
}
}
}
Fałszywa implementacja tego Repository może wyglądać tak:
class FakeRepository : MyRepository {
private val flow = MutableSharedFlow<Int>()
suspend fun emit(value: Int) = flow.emit(value)
override fun scores(): Flow<Int> = flow
}
Podczas testowania ViewModel z tym fałszywym obiektem możesz emitować wartości z fałszywego obiektu, aby wywołać aktualizacje w StateFlow obiektu ViewModel, a potem przeprowadzić weryfikację na podstawie zaktualizowanego obiektu value:
@Test
fun testHotFakeRepository() = runTest {
val fakeRepository = FakeRepository()
val viewModel = MyViewModel(fakeRepository)
assertEquals(0, viewModel.score.value) // Assert on the initial value
// Start collecting values from the Repository
viewModel.initialize()
// Then we can send in values one by one, which the ViewModel will collect
fakeRepository.emit(1)
assertEquals(1, viewModel.score.value)
fakeRepository.emit(2)
fakeRepository.emit(3)
assertEquals(3, viewModel.score.value) // Assert on the latest value
}
Praca z automatami stanów utworzonymi przez stateIn
W poprzedniej sekcji funkcja ViewModel używa pola MutableStateFlow do przechowywania najnowszej wartości wyemitowanej przez przepływ z pola Repository. Jest to typowy schemat, który zwykle jest realizowany w prostszy sposób za pomocą operatora stateIn, który zamienia zimny przepływ w ciepły StateFlow:
class MyViewModelWithStateIn(myRepository: MyRepository) : ViewModel() {
val score: StateFlow<Int> = myRepository.scores()
.stateIn(viewModelScope, SharingStarted.WhileSubscribed(5000L), 0)
}
Operator stateIn ma parametr SharingStarted, który określa, kiedy staje się aktywny i zaczyna używać podstawowego przepływu danych. W modelach widoków często używane są opcje takie jak SharingStarted.Lazily i SharingStarted.WhileSubscribed.
Nawet jeśli w teście sprawdzasz value z StateFlow, musisz utworzyć kolekcjonera. Może to być pusty kolekcjoner:
@Test
fun testLazilySharingViewModel() = runTest {
val fakeRepository = HotFakeRepository()
val viewModel = MyViewModelWithStateIn(fakeRepository)
// Create an empty collector for the StateFlow
backgroundScope.launch(UnconfinedTestDispatcher(testScheduler)) {
viewModel.score.collect {}
}
assertEquals(0, viewModel.score.value) // Can assert initial value
// Trigger-assert like before
fakeRepository.emit(1)
assertEquals(1, viewModel.score.value)
fakeRepository.emit(2)
fakeRepository.emit(3)
assertEquals(3, viewModel.score.value)
}
Dodatkowe materiały
- Testowanie coroutines w Kotlinie na Androidzie
- Kotlin Flow na Androidzie
StateFlowiSharedFlow- Dodatkowe materiały dotyczące coroutines i flow w Kotlinie