
Android Neural Networks API (NNAPI) — это API Android C, разработанный для выполнения ресурсоёмких вычислительных операций машинного обучения на устройствах Android. NNAPI разработан для обеспечения базового уровня функциональности для высокоуровневых фреймворков машинного обучения, таких как TensorFlow Lite и Caffe2, которые создают и обучают нейронные сети. API доступен на всех устройствах Android под управлением Android 8.1 (API уровня 27) и выше, но в Android 15 он был объявлен устаревшим.
NNAPI поддерживает вывод данных, применяя данные с устройств Android к ранее обученным моделям, определенным разработчиком. Примерами вывода являются классификация изображений, прогнозирование поведения пользователя и выбор подходящих ответов на поисковый запрос.
Вывод на устройстве имеет множество преимуществ:
- Задержка : вам не нужно отправлять запрос по сетевому соединению и ждать ответа. Например, это может быть критически важно для видеоприложений, обрабатывающих последовательные кадры с камеры.
- Доступность : приложение работает даже за пределами зоны действия сети.
- Скорость : Новое аппаратное обеспечение, предназначенное специально для обработки нейронных сетей, обеспечивает значительно более быстрые вычисления, чем обычный универсальный процессор.
- Конфиденциальность : данные не покидают пределы устройства Android.
- Стоимость : если все вычисления выполняются на устройстве Android, серверная ферма не требуется.
Разработчику также следует помнить о некоторых компромиссах:
- Использование системы : Оценка нейронных сетей требует большого объёма вычислений, что может привести к увеличению расхода заряда батареи. Если это важно для вашего приложения, особенно при длительных вычислениях, рекомендуется следить за состоянием батареи.
- Размер приложения : обратите внимание на размер ваших моделей. Модели могут занимать несколько мегабайт. Если объединение больших моделей в APK-файл может негативно повлиять на работу пользователей, рассмотрите возможность загрузки моделей после установки приложения, использования моделей меньшего размера или выполнения вычислений в облаке. NNAPI не предоставляет возможности запуска моделей в облаке.
Ознакомьтесь с примером API нейронных сетей Android , чтобы увидеть один из примеров использования NNAPI.
Понимание среды выполнения API нейронных сетей
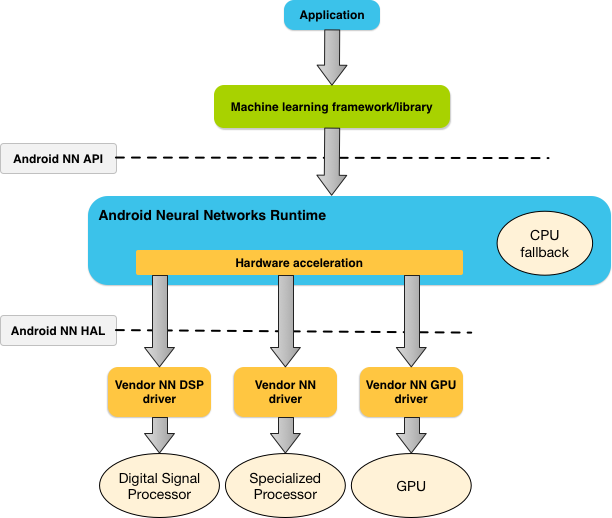
NNAPI предназначен для использования библиотеками, фреймворками и инструментами машинного обучения, позволяющими разработчикам обучать модели вне устройства и развертывать их на устройствах Android. Приложения, как правило, не используют NNAPI напрямую, а используют более высокоуровневые фреймворки машинного обучения. Эти фреймворки, в свою очередь, могут использовать NNAPI для выполнения аппаратно-ускоренных операций вывода на поддерживаемых устройствах.
Исходя из требований приложения и аппаратных возможностей устройства Android, среда выполнения нейронной сети Android может эффективно распределять вычислительную нагрузку между доступными процессорами устройства, включая выделенное аппаратное обеспечение нейронной сети, графические процессоры (GPU) и цифровые сигнальные процессоры (DSP).
Для устройств Android, на которых отсутствует специализированный драйвер поставщика, среда выполнения NNAPI выполняет запросы на ЦП.
На рисунке 1 показана высокоуровневая архитектура системы NNAPI.
Модель программирования API нейронных сетей
Для выполнения вычислений с использованием NNAPI необходимо сначала построить ориентированный граф, определяющий выполняемые вычисления. Этот граф вычислений в сочетании с входными данными (например, весами и смещениями, полученными от фреймворка машинного обучения) формирует модель для оценки времени выполнения NNAPI.
NNAPI использует четыре основные абстракции:
- Модель : граф вычислений, состоящий из математических операций и констант, полученных в процессе обучения. Эти операции специфичны для нейронных сетей. К ним относятся двумерная (2D) свёртка , логистическая ( сигмоидальная ) активация, ректифицированная линейная (ReLU) активация и другие. Создание модели — синхронная операция. После успешного создания её можно использовать повторно в разных потоках и компиляциях. В NNAPI модель представлена как экземпляр
ANeuralNetworksModel. - Компиляция : представляет собой конфигурацию для компиляции модели NNAPI в низкоуровневый код. Создание компиляции — синхронная операция. После успешного создания её можно повторно использовать в разных потоках и выполнениях. В NNAPI каждая компиляция представлена экземпляром
ANeuralNetworksCompilation. - Память : представляет собой разделяемую память, файлы, отображаемые в память, и аналогичные буферы памяти. Использование буфера памяти позволяет среде выполнения NNAPI более эффективно передавать данные драйверам. Приложение обычно создаёт один разделяемый буфер памяти, содержащий все тензоры, необходимые для определения модели. Буферы памяти также можно использовать для хранения входных и выходных данных для экземпляра выполнения. В NNAPI каждый буфер памяти представлен как экземпляр
ANeuralNetworksMemory. Выполнение : Интерфейс для применения модели NNAPI к набору входных данных и сбора результатов. Выполнение может осуществляться синхронно или асинхронно.
При асинхронном выполнении несколько потоков могут ожидать выполнения одного и того же кода. После завершения выполнения все потоки освобождаются.
В NNAPI каждое выполнение представлено как экземпляр
ANeuralNetworksExecution.
На рисунке 2 показана базовая схема программирования.

В оставшейся части этого раздела описываются шаги по настройке модели NNAPI для выполнения вычислений, компиляции модели и выполнения скомпилированной модели.
Предоставить доступ к учебным данным
Данные об обученных весах и смещениях, вероятно, хранятся в файле. Чтобы предоставить среде выполнения NNAPI эффективный доступ к этим данным, создайте экземпляр ANeuralNetworksMemory , вызвав функцию ANeuralNetworksMemory_createFromFd() и передав ей дескриптор открытого файла данных. Также укажите флаги защиты памяти и смещение начала области общей памяти в файле.
// Create a memory buffer from the file that contains the trained data
ANeuralNetworksMemory* mem1 = NULL;
int fd = open("training_data", O_RDONLY);
ANeuralNetworksMemory_createFromFd(file_size, PROT_READ, fd, 0, &mem1);
Хотя в этом примере мы используем только один экземпляр ANeuralNetworksMemory для всех наших весов, можно использовать более одного экземпляра ANeuralNetworksMemory для нескольких файлов.
Использовать собственные аппаратные буферы
Вы можете использовать собственные аппаратные буферы для входных и выходных данных модели, а также константных значений операндов. В некоторых случаях ускоритель NNAPI может обращаться к объектам AHardwareBuffer без необходимости копирования данных драйвером. AHardwareBuffer имеет множество различных конфигураций, и не каждый ускоритель NNAPI может поддерживать все из них. В связи с этим ограничением обратитесь к ограничениям, перечисленным в справочной документации ANeuralNetworksMemory_createFromAHardwareBuffer , и проведите предварительное тестирование на целевых устройствах, чтобы убедиться в ожидаемом результате компиляции и выполнения, использующих AHardwareBuffer , используя назначение устройства для указания ускорителя.
Чтобы разрешить среде выполнения NNAPI доступ к объекту AHardwareBuffer , создайте экземпляр ANeuralNetworksMemory , вызвав функцию ANeuralNetworksMemory_createFromAHardwareBuffer и передав объект AHardwareBuffer , как показано в следующем примере кода:
// Configure and create AHardwareBuffer object AHardwareBuffer_Desc desc = ... AHardwareBuffer* ahwb = nullptr; AHardwareBuffer_allocate(&desc, &ahwb); // Create ANeuralNetworksMemory from AHardwareBuffer ANeuralNetworksMemory* mem2 = NULL; ANeuralNetworksMemory_createFromAHardwareBuffer(ahwb, &mem2);
Когда NNAPI больше не требуется доступ к объекту AHardwareBuffer , освободите соответствующий экземпляр ANeuralNetworksMemory :
ANeuralNetworksMemory_free(mem2);
Примечание:
- Вы можете использовать
AHardwareBufferтолько для всего буфера; вы не можете использовать его с параметромARect. - Среда выполнения NNAPI не очищает буфер. Перед планированием выполнения необходимо убедиться, что входной и выходной буферы доступны.
- Поддержка файловых дескрипторов синхронного забора отсутствует.
- Для
AHardwareBufferс форматами и битами использования, специфичными для поставщика, реализация поставщика должна определить, кто отвечает за очистку кэша — клиент или драйвер.
Модель
Модель — это фундаментальная единица вычислений в NNAPI. Каждая модель определяется одним или несколькими операндами и операциями.
Операнды
Операнды — это объекты данных, используемые для определения графа. К ним относятся входы и выходы модели, промежуточные узлы, содержащие данные, передаваемые от одной операции к другой, и константы, передаваемые в эти операции.
В модели NNAPI можно добавлять два типа операндов: скаляры и тензоры .
Скаляр представляет собой единичное значение. NNAPI поддерживает скалярные значения в форматах логического типа, 16-битного числа с плавающей запятой, 32-битного числа с плавающей запятой, 32-битного целого числа и 32-битного беззнакового целого числа.
Большинство операций в NNAPI работают с тензорами. Тензоры — это n-мерные массивы. NNAPI поддерживает тензоры с 16-битными числами с плавающей запятой, 32-битными числами с плавающей запятой, 8-битными квантованными числами , 16-битными квантованными числами, 32-битными целыми числами и 8-битными булевыми значениями.
Например, на рисунке 3 представлена модель с двумя операциями: сложением и умножением. Модель принимает входной тензор и создаёт один выходной тензор.

В представленной выше модели семь операндов. Эти операнды неявно идентифицируются индексом порядка их добавления в модель. Первый добавленный операнд имеет индекс 0, второй — индекс 1 и т. д. Операнды 1, 2, 3 и 5 являются константными операндами.
Порядок добавления операндов не имеет значения. Например, выходной операнд модели может быть добавлен первым. Важно использовать правильное значение индекса при ссылке на операнд.
Операнды имеют типы. Они указываются при их добавлении в модель.
Операнд не может использоваться одновременно как вход и выход модели.
Каждый операнд должен быть либо входом модели, либо константой, либо выходным операндом ровно одной операции.
Дополнительную информацию об использовании операндов см. в разделе Подробнее об операндах .
Операции
Операция определяет вычисления, которые необходимо выполнить. Каждая операция состоит из следующих элементов:
- тип операции (например, сложение, умножение, свертка),
- список индексов операндов, которые операция использует для ввода, и
- список индексов операндов, которые операция использует для вывода.
Порядок в этих списках имеет значение; см. справочник API NNAPI для получения информации об ожидаемых входных и выходных данных каждого типа операции.
Перед добавлением операции необходимо добавить в модель операнды, которые операция потребляет или производит.
Порядок добавления операций не имеет значения. NNAPI опирается на зависимости, установленные графом вычислений операндов и операций, для определения порядка выполнения операций.
Операции, поддерживаемые NNAPI, перечислены в таблице ниже:
Известная проблема в API уровня 28: при передаче тензоров ANEURALNETWORKS_TENSOR_QUANT8_ASYMM в операцию ANEURALNETWORKS_PAD , доступную в Android 9 (API уровня 28) и выше, выходные данные NNAPI могут не совпадать с выходными данными высокоуровневых фреймворков машинного обучения, таких как TensorFlow Lite . Вместо этого следует передавать только ANEURALNETWORKS_TENSOR_FLOAT32 . Проблема решена в Android 10 (API уровня 29) и выше.
Построение моделей
В следующем примере мы создаем двухоперационную модель, показанную на рисунке 3 .
Чтобы построить модель, выполните следующие действия:
Вызовите функцию
ANeuralNetworksModel_create(), чтобы определить пустую модель.ANeuralNetworksModel* model = NULL; ANeuralNetworksModel_create(&model);
Добавьте операнды в модель, вызвав
ANeuralNetworks_addOperand(). Их типы данных определяются с помощью структуры данныхANeuralNetworksOperandType.// In our example, all our tensors are matrices of dimension [3][4] ANeuralNetworksOperandType tensor3x4Type; tensor3x4Type.type = ANEURALNETWORKS_TENSOR_FLOAT32; tensor3x4Type.scale = 0.f; // These fields are used for quantized tensors tensor3x4Type.zeroPoint = 0; // These fields are used for quantized tensors tensor3x4Type.dimensionCount = 2; uint32_t dims[2] = {3, 4}; tensor3x4Type.dimensions = dims;
// We also specify operands that are activation function specifiers ANeuralNetworksOperandType activationType; activationType.type = ANEURALNETWORKS_INT32; activationType.scale = 0.f; activationType.zeroPoint = 0; activationType.dimensionCount = 0; activationType.dimensions = NULL;
// Now we add the seven operands, in the same order defined in the diagram ANeuralNetworksModel_addOperand(model, &tensor3x4Type); // operand 0 ANeuralNetworksModel_addOperand(model, &tensor3x4Type); // operand 1 ANeuralNetworksModel_addOperand(model, &activationType); // operand 2 ANeuralNetworksModel_addOperand(model, &tensor3x4Type); // operand 3 ANeuralNetworksModel_addOperand(model, &tensor3x4Type); // operand 4 ANeuralNetworksModel_addOperand(model, &activationType); // operand 5 ANeuralNetworksModel_addOperand(model, &tensor3x4Type); // operand 6Для операндов с постоянными значениями, такими как веса и смещения, которые ваше приложение получает в процессе обучения, используйте функции
ANeuralNetworksModel_setOperandValue()иANeuralNetworksModel_setOperandValueFromMemory().В следующем примере мы устанавливаем постоянные значения из файла обучающих данных, соответствующего буферу памяти, который мы создали в разделе Предоставление доступа к обучающим данным .
// In our example, operands 1 and 3 are constant tensors whose values were // established during the training process const int sizeOfTensor = 3 * 4 * 4; // The formula for size calculation is dim0 * dim1 * elementSize ANeuralNetworksModel_setOperandValueFromMemory(model, 1, mem1, 0, sizeOfTensor); ANeuralNetworksModel_setOperandValueFromMemory(model, 3, mem1, sizeOfTensor, sizeOfTensor);
// We set the values of the activation operands, in our example operands 2 and 5 int32_t noneValue = ANEURALNETWORKS_FUSED_NONE; ANeuralNetworksModel_setOperandValue(model, 2, &noneValue, sizeof(noneValue)); ANeuralNetworksModel_setOperandValue(model, 5, &noneValue, sizeof(noneValue));Для каждой операции в ориентированном графе, которую вы хотите вычислить, добавьте операцию в свою модель, вызвав функцию
ANeuralNetworksModel_addOperation().В качестве параметров этого вызова ваше приложение должно предоставить:
- тип операции
- количество входных значений
- массив индексов для входных операндов
- количество выходных значений
- массив индексов для выходных операндов
Обратите внимание, что операнд нельзя использовать и для входа, и для выхода одной и той же операции.
// We have two operations in our example // The first consumes operands 1, 0, 2, and produces operand 4 uint32_t addInputIndexes[3] = {1, 0, 2}; uint32_t addOutputIndexes[1] = {4}; ANeuralNetworksModel_addOperation(model, ANEURALNETWORKS_ADD, 3, addInputIndexes, 1, addOutputIndexes);
// The second consumes operands 3, 4, 5, and produces operand 6 uint32_t multInputIndexes[3] = {3, 4, 5}; uint32_t multOutputIndexes[1] = {6}; ANeuralNetworksModel_addOperation(model, ANEURALNETWORKS_MUL, 3, multInputIndexes, 1, multOutputIndexes);Определите, какие операнды модель должна обрабатывать как входы и выходы, вызвав функцию
ANeuralNetworksModel_identifyInputsAndOutputs().// Our model has one input (0) and one output (6) uint32_t modelInputIndexes[1] = {0}; uint32_t modelOutputIndexes[1] = {6}; ANeuralNetworksModel_identifyInputsAndOutputs(model, 1, modelInputIndexes, 1 modelOutputIndexes);
При желании укажите, разрешено ли вычислять
ANEURALNETWORKS_TENSOR_FLOAT32с диапазоном или точностью ниже, чем у 16-битного формата с плавающей запятой IEEE 754, вызвавANeuralNetworksModel_relaxComputationFloat32toFloat16().Вызовите функцию
ANeuralNetworksModel_finish()для завершения определения модели. Если ошибок нет, эта функция возвращает код результатаANEURALNETWORKS_NO_ERROR.ANeuralNetworksModel_finish(model);
Создав модель, вы можете компилировать ее любое количество раз и выполнять каждую компиляцию любое количество раз.
Поток управления
Чтобы включить поток управления в модель NNAPI, выполните следующие действия:
Постройте соответствующие подграфы выполнения (подграфы
thenиelseдля оператораIF, подграфыconditionиbodyдля циклаWHILE) как отдельные моделиANeuralNetworksModel*:ANeuralNetworksModel* thenModel = makeThenModel(); ANeuralNetworksModel* elseModel = makeElseModel();
Создайте операнды, которые ссылаются на эти модели внутри модели, содержащей поток управления:
ANeuralNetworksOperandType modelType = { .type = ANEURALNETWORKS_MODEL, }; ANeuralNetworksModel_addOperand(model, &modelType); // kThenOperandIndex ANeuralNetworksModel_addOperand(model, &modelType); // kElseOperandIndex ANeuralNetworksModel_setOperandValueFromModel(model, kThenOperandIndex, &thenModel); ANeuralNetworksModel_setOperandValueFromModel(model, kElseOperandIndex, &elseModel);
Добавьте операцию управления потоком:
uint32_t inputs[] = {kConditionOperandIndex, kThenOperandIndex, kElseOperandIndex, kInput1, kInput2, kInput3}; uint32_t outputs[] = {kOutput1, kOutput2}; ANeuralNetworksModel_addOperation(model, ANEURALNETWORKS_IF, std::size(inputs), inputs, std::size(output), outputs);
Компиляция
На этапе компиляции определяется, на каких процессорах будет выполняться ваша модель, и соответствующим драйверам задаётся задача подготовки к её выполнению. Это может включать генерацию машинного кода, специфичного для процессоров, на которых будет выполняться ваша модель.
Чтобы скомпилировать модель, выполните следующие действия:
Вызовите функцию
ANeuralNetworksCompilation_create(), чтобы создать новый экземпляр компиляции.// Compile the model ANeuralNetworksCompilation* compilation; ANeuralNetworksCompilation_create(model, &compilation);
При желании вы можете использовать назначение устройств , чтобы явно выбрать, на каких устройствах выполняться.
При желании вы можете влиять на баланс между потреблением заряда батареи и скоростью выполнения. Это можно сделать, вызвав
ANeuralNetworksCompilation_setPreference().// Ask to optimize for low power consumption ANeuralNetworksCompilation_setPreference(compilation, ANEURALNETWORKS_PREFER_LOW_POWER);
Настройки, которые вы можете указать, включают:
-
ANEURALNETWORKS_PREFER_LOW_POWER: Предпочитает выполнение, минимизирующее расход заряда батареи. Это желательно для часто выполняемых компиляций. -
ANEURALNETWORKS_PREFER_FAST_SINGLE_ANSWER: Предпочитать возврат одного ответа как можно быстрее, даже если это приводит к повышенному энергопотреблению. Это значение по умолчанию. -
ANEURALNETWORKS_PREFER_SUSTAINED_SPEED: Предпочтение отдается максимизации пропускной способности последовательных кадров, например, при обработке последовательных кадров, поступающих с камеры.
-
При желании вы можете настроить кэширование компиляции, вызвав
ANeuralNetworksCompilation_setCaching.// Set up compilation caching ANeuralNetworksCompilation_setCaching(compilation, cacheDir, token);
Используйте
getCodeCacheDir()дляcacheDir. Указанныйtokenдолжен быть уникальным для каждой модели в приложении.Завершите определение компиляции, вызвав
ANeuralNetworksCompilation_finish(). Если ошибок нет, эта функция возвращает код результатаANEURALNETWORKS_NO_ERROR.ANeuralNetworksCompilation_finish(compilation);
Обнаружение и назначение устройств
На устройствах Android под управлением Android 10 (уровень API 29) и выше NNAPI предоставляет функции, позволяющие библиотекам и приложениям фреймворков машинного обучения получать информацию о доступных устройствах и указывать устройства, которые будут использоваться для выполнения. Предоставление информации о доступных устройствах позволяет приложениям получать точную версию драйверов, обнаруженных на устройстве, чтобы избежать известных несовместимостей. Предоставляя приложениям возможность указывать, какие устройства должны выполнять различные разделы модели, можно оптимизировать приложения для устройства Android, на котором они развернуты.
Обнаружение устройства
Используйте функцию ANeuralNetworks_getDeviceCount для получения количества доступных устройств. Для каждого устройства используйте ANeuralNetworks_getDevice , чтобы присвоить экземпляру ANeuralNetworksDevice ссылку на это устройство.
Получив ссылку на устройство, вы можете узнать дополнительную информацию об этом устройстве, используя следующие функции:
-
ANeuralNetworksDevice_getFeatureLevel -
ANeuralNetworksDevice_getName -
ANeuralNetworksDevice_getType -
ANeuralNetworksDevice_getVersion
Назначение устройства
Используйте ANeuralNetworksModel_getSupportedOperationsForDevices чтобы узнать, какие операции модели можно запустить на конкретных устройствах.
Чтобы управлять ускорителями, используемыми для выполнения, вызовите ANeuralNetworksCompilation_createForDevices вместо ANeuralNetworksCompilation_create . Используйте полученный объект ANeuralNetworksCompilation как обычно. Функция возвращает ошибку, если предоставленная модель содержит операции, не поддерживаемые выбранными устройствами.
Если указано несколько устройств, среда выполнения отвечает за распределение работы между устройствами.
Как и в случае с другими устройствами, реализация NNAPI на уровне ЦП представлена объектом ANeuralNetworksDevice с именем nnapi-reference и типом ANEURALNETWORKS_DEVICE_TYPE_CPU . При вызове ANeuralNetworksCompilation_createForDevices реализация ЦП не используется для обработки случаев сбоев при компиляции и выполнении модели.
Приложение отвечает за разделение модели на подмодели, которые могут работать на указанных устройствах. Приложения, которым не требуется ручное разделение, должны продолжать вызывать более простой метод ANeuralNetworksCompilation_create , чтобы использовать все доступные устройства (включая ЦП) для ускорения модели. Если модель не удалось полностью поддержать устройствами, указанными с помощью ANeuralNetworksCompilation_createForDevices , возвращается ANEURALNETWORKS_BAD_DATA .
Разбиение модели
Если для модели доступно несколько устройств, среда выполнения NNAPI распределяет работу между ними. Например, если в ANeuralNetworksCompilation_createForDevices было указано более одного устройства, все указанные устройства будут учтены при распределении работы. Обратите внимание, что если устройство CPU отсутствует в списке, выполнение на CPU будет отключено. При использовании ANeuralNetworksCompilation_create будут учтены все доступные устройства, включая CPU.
Распределение выполняется путём выбора из списка доступных устройств для каждой операции в модели устройства, поддерживающего операцию, и объявления наилучшей производительности, то есть самого быстрого выполнения или самого низкого энергопотребления, в зависимости от предпочтений клиента. Этот алгоритм разбиения не учитывает возможную неэффективность, вызванную взаимодействием между различными процессорами, поэтому при указании нескольких процессоров (явно с помощью ANeuralNetworksCompilation_createForDevices или неявно с помощью ANeuralNetworksCompilation_create ) важно профилировать результирующее приложение.
Чтобы понять, как NNAPI разделила вашу модель, проверьте наличие сообщения в журналах Android (на уровне INFO с тегом ExecutionPlan ):
ModelBuilder::findBestDeviceForEachOperation(op-name): device-index
op-name — описательное имя операции в графе, а device-index — индекс устройства-кандидата в списке устройств. Этот список является входными данными для функции ANeuralNetworksCompilation_createForDevices или, при использовании ANeuralNetworksCompilation_createForDevices , списком устройств, возвращаемым при переборе всех устройств с помощью ANeuralNetworks_getDeviceCount и ANeuralNetworks_getDevice .
Сообщение (на уровне INFO с тегом ExecutionPlan ):
ModelBuilder::partitionTheWork: only one best device: device-name
Это сообщение указывает на то, что весь график был ускорен на устройстве device-name устройства.
Исполнение
На этапе выполнения модель применяет к набору входных данных и сохраняет выходные данные вычислений в одном или нескольких пользовательских буферах или областях памяти, выделенных вашим приложением.
Чтобы выполнить скомпилированную модель, выполните следующие действия:
Вызовите функцию
ANeuralNetworksExecution_create(), чтобы создать новый экземпляр выполнения.// Run the compiled model against a set of inputs ANeuralNetworksExecution* run1 = NULL; ANeuralNetworksExecution_create(compilation, &run1);
Укажите, откуда ваше приложение будет считывать входные значения для вычислений. Ваше приложение может считывать входные значения либо из пользовательского буфера, либо из выделенной области памяти, вызывая
ANeuralNetworksExecution_setInput()илиANeuralNetworksExecution_setInputFromMemory()соответственно.// Set the single input to our sample model. Since it is small, we won't use a memory buffer float32 myInput[3][4] = { ...the data... }; ANeuralNetworksExecution_setInput(run1, 0, NULL, myInput, sizeof(myInput));
Укажите, куда ваше приложение будет записывать выходные значения. Приложение может записывать выходные значения либо в пользовательский буфер, либо в выделенную область памяти, вызывая
ANeuralNetworksExecution_setOutput()илиANeuralNetworksExecution_setOutputFromMemory()соответственно.// Set the output float32 myOutput[3][4]; ANeuralNetworksExecution_setOutput(run1, 0, NULL, myOutput, sizeof(myOutput));
Запланируйте начало выполнения, вызвав функцию
ANeuralNetworksExecution_startCompute(). Если ошибок нет, эта функция возвращает код результатаANEURALNETWORKS_NO_ERROR.// Starts the work. The work proceeds asynchronously ANeuralNetworksEvent* run1_end = NULL; ANeuralNetworksExecution_startCompute(run1, &run1_end);
Вызовите функцию
ANeuralNetworksEvent_wait(), чтобы дождаться завершения выполнения. Если выполнение прошло успешно, эта функция возвращает код результатаANEURALNETWORKS_NO_ERROR. Ожидание может осуществляться в потоке, отличном от того, который начал выполнение.// For our example, we have no other work to do and will just wait for the completion ANeuralNetworksEvent_wait(run1_end); ANeuralNetworksEvent_free(run1_end); ANeuralNetworksExecution_free(run1);
При желании вы можете применить другой набор входных данных к скомпилированной модели, используя тот же экземпляр компиляции для создания нового экземпляра
ANeuralNetworksExecution.// Apply the compiled model to a different set of inputs ANeuralNetworksExecution* run2; ANeuralNetworksExecution_create(compilation, &run2); ANeuralNetworksExecution_setInput(run2, ...); ANeuralNetworksExecution_setOutput(run2, ...); ANeuralNetworksEvent* run2_end = NULL; ANeuralNetworksExecution_startCompute(run2, &run2_end); ANeuralNetworksEvent_wait(run2_end); ANeuralNetworksEvent_free(run2_end); ANeuralNetworksExecution_free(run2);
Синхронное выполнение
Асинхронное выполнение тратит время на создание и синхронизацию потоков. Более того, задержка может быть очень разной: самые длительные задержки достигают 500 микросекунд между моментом получения уведомления или пробуждения потока и моментом его окончательной привязки к ядру процессора.
Чтобы уменьшить задержку, можно указать приложению выполнить синхронный вызов вывода к среде выполнения. Этот вызов вернётся только после завершения вывода, а не после его начала. Вместо вызова ANeuralNetworksExecution_startCompute для асинхронного вызова вывода к среде выполнения приложение вызывает ANeuralNetworksExecution_compute для выполнения синхронного вызова к среде выполнения. Вызов ANeuralNetworksExecution_compute не принимает ANeuralNetworksEvent и не связан с вызовом ANeuralNetworksEvent_wait .
Серийные казни
На устройствах Android под управлением Android 10 (уровень API 29) и выше интерфейс NNAPI поддерживает пакетное выполнение через объект ANeuralNetworksBurst . Пакетное выполнение представляет собой последовательность быстро следующих друг за другом выполнений одной и той же компиляции, например, при обработке кадров с камеры или последовательных аудиофрагментов. Использование объектов ANeuralNetworksBurst может привести к ускорению выполнения, поскольку они указывают ускорителям на возможность повторного использования ресурсов между выполнениями и на необходимость поддержания высокопроизводительного состояния ускорителей в течение всего периода пакетного выполнения.
ANeuralNetworksBurst вносит лишь небольшое изменение в обычный путь выполнения. Объект burst создается с помощью ANeuralNetworksBurst_create , как показано в следующем фрагменте кода:
// Create burst object to be reused across a sequence of executions ANeuralNetworksBurst* burst = NULL; ANeuralNetworksBurst_create(compilation, &burst);
Выполнение пакетов выполняется синхронно. Однако вместо использования ANeuralNetworksExecution_compute для каждого вывода вы связываете различные объекты ANeuralNetworksExecution с одним и тем же ANeuralNetworksBurst в вызовах функции ANeuralNetworksExecution_burstCompute .
// Create and configure first execution object // ... // Execute using the burst object ANeuralNetworksExecution_burstCompute(execution1, burst); // Use results of first execution and free the execution object // ... // Create and configure second execution object // ... // Execute using the same burst object ANeuralNetworksExecution_burstCompute(execution2, burst); // Use results of second execution and free the execution object // ...
Освободите объект ANeuralNetworksBurst с помощью ANeuralNetworksBurst_free , когда он больше не нужен.
// Cleanup ANeuralNetworksBurst_free(burst);
Асинхронные очереди команд и огражденное выполнение
В Android 11 и более поздних версиях NNAPI поддерживает дополнительный способ планирования асинхронного выполнения с помощью метода ANeuralNetworksExecution_startComputeWithDependencies() . При использовании этого метода выполнение ожидает получения сигнала от всех зависимых событий, прежде чем начать вычисление. После завершения выполнения и готовности выходных данных к использованию возвращается сигнал о событии.
В зависимости от того, какие устройства обрабатывают выполнение, событие может быть подкреплено синхронизирующим барьером . Необходимо вызвать ANeuralNetworksEvent_wait() , чтобы дождаться события и восстановить ресурсы, использованные при выполнении. Вы можете импортировать синхронизирующие барьеры в объект события с помощью ANeuralNetworksEvent_createFromSyncFenceFd() , а также экспортировать синхронизирующие барьеры из объекта события с помощью ANeuralNetworksEvent_getSyncFenceFd() .
Динамически изменяемые размеры выходных данных
Для поддержки моделей, в которых размер выходных данных зависит от входных данных (то есть размер невозможно определить во время выполнения модели), используйте ANeuralNetworksExecution_getOutputOperandRank и ANeuralNetworksExecution_getOutputOperandDimensions .
Следующий пример кода показывает, как это сделать:
// Get the rank of the output uint32_t myOutputRank = 0; ANeuralNetworksExecution_getOutputOperandRank(run1, 0, &myOutputRank); // Get the dimensions of the output std::vector<uint32_t> myOutputDimensions(myOutputRank); ANeuralNetworksExecution_getOutputOperandDimensions(run1, 0, myOutputDimensions.data());
Очистка
На этапе очистки происходит освобождение внутренних ресурсов, используемых для вычислений.
// Cleanup ANeuralNetworksCompilation_free(compilation); ANeuralNetworksModel_free(model); ANeuralNetworksMemory_free(mem1);
Управление ошибками и откат ЦП
Если во время разбиения на разделы произошла ошибка, если драйверу не удалось скомпилировать (часть) модели или если драйверу не удалось выполнить скомпилированную (часть) модели, NNAPI может вернуться к собственной реализации ЦП одной или нескольких операций.
Если клиент NNAPI содержит оптимизированные версии операции (например, TFLite), может быть выгодно отключить откат ЦП и обрабатывать сбои с помощью оптимизированной реализации операции клиента.
В Android 10, если компиляция выполняется с использованием ANeuralNetworksCompilation_createForDevices , то откат ЦП будет отключен.
В Android P выполнение NNAPI возвращается к центральному процессору в случае сбоя драйвера. Это также справедливо и для Android 10 при использовании ANeuralNetworksCompilation_create вместо ANeuralNetworksCompilation_createForDevices .
Сначала выполняется возврат к одному разделу, и если это снова не удается, система повторяет попытку всей модели на ЦП.
Если разбиение или компиляция не удались, вся модель будет опробована на ЦП.
Бывают случаи, когда некоторые операции не поддерживаются на ЦП, и в таких ситуациях компиляция или выполнение не будут выполнены, а вместо этого произойдет откат.
Даже после отключения резервного использования ЦП в модели могут остаться операции, запланированные на ЦП. Если ЦП входит в список процессоров, предоставленный ANeuralNetworksCompilation_createForDevices , и является либо единственным процессором, поддерживающим эти операции, либо процессором, обеспечивающим максимальную производительность для этих операций, он будет выбран в качестве основного (не резервного) исполнителя.
Чтобы исключить выполнение кода на процессоре, используйте ANeuralNetworksCompilation_createForDevices , исключив nnapi-reference из списка устройств. Начиная с Android P, можно отключить откат во время выполнения в сборках DEBUG, установив свойство debug.nn.partition в значение 2.
Домены памяти
В Android 11 и более поздних версиях NNAPI поддерживает домены памяти, предоставляющие интерфейсы распределения для непрозрачной памяти. Это позволяет приложениям передавать память устройства между выполнениями, чтобы NNAPI не копировал и не преобразовывал данные без необходимости при последовательных выполнениях на одном и том же драйвере.
Функция домена памяти предназначена для тензоров, которые в основном находятся внутри драйвера и не требуют частого доступа к клиентской части. Примерами таких тензоров являются тензоры состояния в моделях последовательностей. Для тензоров, которым требуется частый доступ к процессору на клиентской части, используйте общие пулы памяти.
Чтобы выделить непрозрачную память, выполните следующие действия:
Вызовите функцию
ANeuralNetworksMemoryDesc_create(), чтобы создать новый дескриптор памяти:// Create a memory descriptor ANeuralNetworksMemoryDesc* desc; ANeuralNetworksMemoryDesc_create(&desc);
Укажите все предполагаемые роли ввода и вывода, вызвав
ANeuralNetworksMemoryDesc_addInputRole()иANeuralNetworksMemoryDesc_addOutputRole().// Specify that the memory may be used as the first input and the first output // of the compilation ANeuralNetworksMemoryDesc_addInputRole(desc, compilation, 0, 1.0f); ANeuralNetworksMemoryDesc_addOutputRole(desc, compilation, 0, 1.0f);
При желании укажите размеры памяти, вызвав
ANeuralNetworksMemoryDesc_setDimensions().// Specify the memory dimensions uint32_t dims[] = {3, 4}; ANeuralNetworksMemoryDesc_setDimensions(desc, 2, dims);
Завершите определение дескриптора, вызвав
ANeuralNetworksMemoryDesc_finish().ANeuralNetworksMemoryDesc_finish(desc);
Выделите столько памяти, сколько необходимо, передав дескриптор в
ANeuralNetworksMemory_createFromDesc().// Allocate two opaque memories with the descriptor ANeuralNetworksMemory* opaqueMem; ANeuralNetworksMemory_createFromDesc(desc, &opaqueMem);
Освободите дескриптор памяти, когда он вам больше не нужен.
ANeuralNetworksMemoryDesc_free(desc);
Клиент может использовать созданный объект ANeuralNetworksMemory только с помощью ANeuralNetworksExecution_setInputFromMemory() или ANeuralNetworksExecution_setOutputFromMemory() в соответствии с ролями, указанными в объекте ANeuralNetworksMemoryDesc . Аргументы offset и length должны быть равны 0, что указывает на использование всей памяти. Клиент также может явно задать или извлечь содержимое памяти с помощью метода ANeuralNetworksMemory_copy() .
Вы можете создавать непрозрачные области памяти с ролями неопределённого размера или ранга. В этом случае создание памяти может завершиться ошибкой со статусом ANEURALNETWORKS_OP_FAILED , если это не поддерживается базовым драйвером. Клиенту рекомендуется реализовать резервную логику, выделив достаточно большой буфер, поддерживаемый Ashmem или AHardwareBuffer в режиме BLOB.
Когда NNAPI больше не требуется доступ к объекту непрозрачной памяти, освободите соответствующий экземпляр ANeuralNetworksMemory :
ANeuralNetworksMemory_free(opaqueMem);
Измерить производительность
Вы можете оценить производительность своего приложения, измерив время выполнения или выполнив профилирование.
Время выполнения
Чтобы определить общее время выполнения во время выполнения, можно использовать API синхронного выполнения и измерить время, затраченное на вызов. Чтобы определить общее время выполнения на более низком уровне программного стека, можно использовать ANeuralNetworksExecution_setMeasureTiming и ANeuralNetworksExecution_getDuration для получения:
- время выполнения на ускорителе (не в драйвере, который работает на главном процессоре).
- время выполнения в драйвере, включая время на педали газа.
Время выполнения в драйвере не включает накладные расходы, такие как расходы на саму среду выполнения и IPC, необходимые для взаимодействия среды выполнения с драйвером.
Эти API измеряют продолжительность времени между событиями отправки и завершения работы, а не время, которое драйвер или ускоритель уделяет выполнению вывода, возможно, прерываемому переключением контекста.
Например, если начинается вывод 1, затем драйвер останавливает работу, чтобы выполнить вывод 2, затем возобновляет и завершает вывод 1, время выполнения вывода 1 будет включать время, когда работа была остановлена для выполнения вывода 2.
Эта информация о времени может быть полезна при развертывании приложения в рабочей среде для сбора телеметрии для использования в автономном режиме. Вы можете использовать эти данные для модификации приложения для повышения его производительности.
При использовании этой функции имейте в виду следующее:
- Сбор информации о времени может иметь негативные последствия для производительности.
- Только драйвер способен вычислить время, затраченное им самим или на ускорителе, за исключением времени, затраченного в среде выполнения NNAPI и в IPC.
- Использовать эти API можно только с
ANeuralNetworksExecution, созданным с помощьюANeuralNetworksCompilation_createForDevicesсnumDevices = 1. - Водителю не требуется сообщать информацию о времени.
Профилируйте свое приложение с помощью Android Systrace
Starting with Android 10, NNAPI automatically generates systrace events that you can use to profile your application.
The NNAPI Source comes with a parse_systrace utility to process the systrace events generated by your application and generate a table view showing the time spent in the different phases of the model lifecycle (Instantiation, Preparation, Compilation Execution and Termination) and different layers of the applications. The layers in which your application is split are:
-
Application: the main application code -
Runtime: NNAPI Runtime -
IPC: The inter process communication between NNAPI Runtime and the Driver code -
Driver: the accelerator driver process.
Generate the profiling analysys data
Assuming you checked out the AOSP source tree at $ANDROID_BUILD_TOP, and using the TFLite image classification example as target application, you can generate the NNAPI profiling data with the following steps:
- Start the Android systrace with the following command:
$ANDROID_BUILD_TOP/external/chromium-trace/systrace.py -o trace.html -a org.tensorflow.lite.examples.classification nnapi hal freq sched idle load binder_driver
The -o trace.html parameter indicates that the traces will be written in the trace.html . When profiling own application you will need to replace org.tensorflow.lite.examples.classification with the process name specified in your app manifest.
This will keep one of your shell console busy, don't run the command in background since it is interactively waiting for an enter to terminate.
- After the systrace collector is started, start your app and run your benchmark test.
In our case you can start the Image Classification app from Android Studio or directly from your test phone UI if the app has already been installed. To generate some NNAPI data you need to configure the app to use NNAPI by selecting NNAPI as target device in the app configuration dialog.
When the test completes, terminate the systrace by pressing
enteron the console terminal active since step 1.Run the
systrace_parserutility generate cumulative statistics:
$ANDROID_BUILD_TOP/frameworks/ml/nn/tools/systrace_parser/parse_systrace.py --total-times trace.html
The parser accepts the following parameters: - --total-times : shows the total time spent in a layer including the time spent waiting for execution on a call to an underlying layer - --print-detail : prints all the events that have been collected from systrace - --per-execution : prints only the execution and its subphases (as per-execution times) instead of stats for all phases - --json : produces the output in JSON format
An example of the output is shown below:
===========================================================================================================================================
NNAPI timing summary (total time, ms wall-clock) Execution
----------------------------------------------------
Initialization Preparation Compilation I/O Compute Results Ex. total Termination Total
-------------- ----------- ----------- ----------- ------------ ----------- ----------- ----------- ----------
Application n/a 19.06 1789.25 n/a n/a 6.70 21.37 n/a 1831.17*
Runtime - 18.60 1787.48 2.93 11.37 0.12 14.42 1.32 1821.81
IPC 1.77 - 1781.36 0.02 8.86 - 8.88 - 1792.01
Driver 1.04 - 1779.21 n/a n/a n/a 7.70 - 1787.95
Total 1.77* 19.06* 1789.25* 2.93* 11.74* 6.70* 21.37* 1.32* 1831.17*
===========================================================================================================================================
* This total ignores missing (n/a) values and thus is not necessarily consistent with the rest of the numbers
The parser might fail if the collected events do not represent a complete application trace. In particular it might fail if systrace events generated to mark the end of a section are present in the trace without an associated section start event. This usually happens if some events from a previous profiling session are being generated when you start the systrace collector. In this case you would have to run your profiling again.
Add statistics for your application code to systrace_parser output
The parse_systrace application is based on the built-in Android systrace functionality. You can add traces for specific operations in your app using the systrace API ( for Java , for native applications ) with custom event names.
To associate your custom events with phases of the Application lifecycle, prepend your event name with one of the following strings:
-
[NN_LA_PI]: Application level event for Initialization -
[NN_LA_PP]: Application level event for Preparation -
[NN_LA_PC]: Application level event for Compilation -
[NN_LA_PE]: Application level event for Execution
Here is an example of how you can alter the TFLite image classification example code by adding a runInferenceModel section for the Execution phase and the Application layer containing another other sections preprocessBitmap that won't be considered in NNAPI traces. The runInferenceModel section will be part of the systrace events processed by the nnapi systrace parser:
Котлин
/** Runs inference and returns the classification results. */ fun recognizeImage(bitmap: Bitmap): List{ // This section won’t appear in the NNAPI systrace analysis Trace.beginSection("preprocessBitmap") convertBitmapToByteBuffer(bitmap) Trace.endSection() // Run the inference call. // Add this method in to NNAPI systrace analysis. Trace.beginSection("[NN_LA_PE]runInferenceModel") long startTime = SystemClock.uptimeMillis() runInference() long endTime = SystemClock.uptimeMillis() Trace.endSection() ... return recognitions }
Ява
/** Runs inference and returns the classification results. */ public ListrecognizeImage(final Bitmap bitmap) { // This section won’t appear in the NNAPI systrace analysis Trace.beginSection("preprocessBitmap"); convertBitmapToByteBuffer(bitmap); Trace.endSection(); // Run the inference call. // Add this method in to NNAPI systrace analysis. Trace.beginSection("[NN_LA_PE]runInferenceModel"); long startTime = SystemClock.uptimeMillis(); runInference(); long endTime = SystemClock.uptimeMillis(); Trace.endSection(); ... Trace.endSection(); return recognitions; }
Качество обслуживания
In Android 11 and higher, NNAPI enables better quality of service (QoS) by allowing an application to indicate the relative priorities of its models, the maximum amount of time expected to prepare a given model, and the maximum amount of time expected to complete a given computation. Android 11 also introduces additional NNAPI result codes that enable applications to understand failures such as missed execution deadlines.
Set the priority of a workload
To set the priority of an NNAPI workload, call ANeuralNetworksCompilation_setPriority() prior to calling ANeuralNetworksCompilation_finish() .
Set deadlines
Applications can set deadlines for both model compilation and inference.
- To set the compilation timeout, call
ANeuralNetworksCompilation_setTimeout()prior to callingANeuralNetworksCompilation_finish(). - To set the inference timeout, call
ANeuralNetworksExecution_setTimeout()prior to starting the compilation .
More about operands
The following section covers advanced topics about using operands.
Quantized tensors
A quantized tensor is a compact way to represent an n-dimensional array of floating point values.
NNAPI supports 8-bit asymmetric quantized tensors. For these tensors, the value of each cell is represented by an 8-bit integer. Associated with the tensor is a scale and a zero point value. These are used to convert the 8-bit integers into the floating point values that are being represented.
The formula is:
(cellValue - zeroPoint) * scale
where the zeroPoint value is a 32-bit integer and the scale a 32-bit floating point value.
Compared to tensors of 32-bit floating point values, 8-bit quantized tensors have two advantages:
- Your application is smaller, as the trained weights take a quarter of the size of 32-bit tensors.
- Computations can often be executed faster. This is due to the smaller amount of data that needs to be fetched from memory and the efficiency of processors such as DSPs in doing integer math.
While it is possible to convert a floating point model to a quantized one, our experience has shown that better results are achieved by training a quantized model directly. In effect, the neural network learns to compensate for the increased granularity of each value. For each quantized tensor, the scale and zeroPoint values are determined during the training process.
In NNAPI, you define quantized tensor types by setting the type field of the ANeuralNetworksOperandType data structure to ANEURALNETWORKS_TENSOR_QUANT8_ASYMM . You also specify the scale and zeroPoint value of the tensor in that data structure.
In addition to 8-bit asymmetric quantized tensors, NNAPI supports the following:
-
ANEURALNETWORKS_TENSOR_QUANT8_SYMM_PER_CHANNELwhich you can use for representing weights toCONV/DEPTHWISE_CONV/TRANSPOSED_CONVoperations. -
ANEURALNETWORKS_TENSOR_QUANT16_ASYMMwhich you can use for the internal state ofQUANTIZED_16BIT_LSTM. -
ANEURALNETWORKS_TENSOR_QUANT8_SYMMwhich can be an input toANEURALNETWORKS_DEQUANTIZE.
Optional operands
A few operations, like ANEURALNETWORKS_LSH_PROJECTION , take optional operands. To indicate in the model that the optional operand is omitted, call the ANeuralNetworksModel_setOperandValue() function, passing NULL for the buffer and 0 for the length.
If the decision on whether the operand is present or not varies for each execution, you indicate that the operand is omitted by using the ANeuralNetworksExecution_setInput() or ANeuralNetworksExecution_setOutput() functions, passing NULL for the buffer and 0 for the length.
Tensors of unknown rank
Android 9 (API level 28) introduced model operands of unknown dimensions but known rank (the number of dimensions). Android 10 (API level 29) introduced tensors of unknown rank, as shown in ANeuralNetworksOperandType .
NNAPI benchmark
The NNAPI benchmark is available on AOSP in platform/test/mlts/benchmark (benchmark app) and platform/test/mlts/models (models and datasets).
The benchmark evaluates latency and accuracy and compares drivers to the same work done using Tensorflow Lite running on the CPU, for the same models and datasets.
To use the benchmark, do the following:
Connect a target Android device to your computer, open a terminal window, and make sure the device is reachable through adb.
If more than one Android device is connected, export the target device
ANDROID_SERIALenvironment variable.Navigate to the Android top-level source directory.
Выполните следующие команды:
lunch aosp_arm-userdebug # Or aosp_arm64-userdebug if available ./test/mlts/benchmark/build_and_run_benchmark.sh
At the end of a benchmark run, its results will be presented as an HTML page passed to
xdg-open.
NNAPI logs
NNAPI generates useful diagnostic information in the system logs. To analyze the logs, use the logcat utility.
Enable verbose NNAPI logging for specific phases or components by setting the property debug.nn.vlog (using adb shell ) to the following list of values, separated by space, colon, or comma:
-
model: Model building -
compilation: Generation of the model execution plan and compilation -
execution: Model execution -
cpuexe: Execution of operations using the NNAPI CPU implementation -
manager: NNAPI extensions, available interfaces and capabilities related info -
allor1: All the elements above
For example, to enable full verbose logging use the command adb shell setprop debug.nn.vlog all . To disable verbose logging, use the command adb shell setprop debug.nn.vlog '""' .
Once enabled, verbose logging generates log entries at INFO level with a tag set to the phase or component name.
Beside the debug.nn.vlog controlled messages, NNAPI API components provide other log entries at various levels, each one using a specific log tag.
To get a list of components, search the source tree using the following expression:
grep -R 'define LOG_TAG' | awk -F '"' '{print $2}' | sort -u | egrep -v "Sample|FileTag|test"
This expression currently returns the following tags:
- BurstBuilder
- Обратные вызовы
- CompilationBuilder
- CpuExecutor
- ExecutionBuilder
- ExecutionBurstController
- ExecutionBurstServer
- ExecutionPlan
- FibonacciDriver
- GraphDump
- IndexedShapeWrapper
- IonWatcher
- Менеджер
- Память
- MemoryUtils
- MetaModel
- ModelArgumentInfo
- ModelBuilder
- NeuralNetworks
- OperationResolver
- Операции
- OperationsUtils
- PackageInfo
- TokenHasher
- TypeManager
- Utils
- ValidateHal
- VersionedInterfaces
To control the level of log messages shown by logcat , use the environment variable ANDROID_LOG_TAGS .
To show the full set of NNAPI log messages and disable any others, set ANDROID_LOG_TAGS to the following:
BurstBuilder:V Callbacks:V CompilationBuilder:V CpuExecutor:V ExecutionBuilder:V ExecutionBurstController:V ExecutionBurstServer:V ExecutionPlan:V FibonacciDriver:V GraphDump:V IndexedShapeWrapper:V IonWatcher:V Manager:V MemoryUtils:V Memory:V MetaModel:V ModelArgumentInfo:V ModelBuilder:V NeuralNetworks:V OperationResolver:V OperationsUtils:V Operations:V PackageInfo:V TokenHasher:V TypeManager:V Utils:V ValidateHal:V VersionedInterfaces:V *:S.
You can set ANDROID_LOG_TAGS using the following command:
export ANDROID_LOG_TAGS=$(grep -R 'define LOG_TAG' | awk -F '"' '{ print $2 ":V" }' | sort -u | egrep -v "Sample|FileTag|test" | xargs echo -n; echo ' *:S')
Note that this is just a filter that applies to logcat . You still need to set the property debug.nn.vlog to all to generate verbose log info.