
Android Neural Networks API (NNAPI) 是一個 Android C API,專為在 Android 裝置上執行計算密集型作業,以便進行機器學習而設計。 NNAPI 可以為更高層級的機器學習架構 (例如 TensorFlow Lite 和 Caffe2) 提供基本功能層,用來建構及訓練類神經網路。搭載 Android 8.1 (API 級別 27) 以上版本的所有 Android 裝置都有提供此 API,但 Android 15 已將其淘汰。
NNAPI 支援透過將 Android 裝置的資料用於先前所訓練、由開發人員定義的模型來執行推論。推論包括圖片分類、預測使用者行為和針對搜尋查詢提供適當的回應。
在裝置端推論有許多好處:
- 延遲:您不需要透過網路連線傳送要求並等待回覆。舉例來說,對於要處理從相機傳入的連續影格的影片應用程式,這點非常重要。
- 可用性:即使不在網路服務涵蓋範圍內,應用程式仍可執行。
- 速度:專用於類神經網路處理的新硬體在計算速度方面明顯比單獨的一般用途 CPU 還要快。
- 隱私:資料不會從 Android 裝置流出。
- 費用:所有計算都會在 Android 裝置上執行,因此不需要伺服器陣列。
開發人員也應在以下方面做出取捨:
- 系統使用率:評估類神經網路需要進行大量計算,可能會增加電池耗電量。如果您擔心應用程式會增加耗電量 (尤其是長時間執行運算時),建議您監測電池健康度。
- 應用程式大小:請留意模型大小。模型可能會占用數個 MB 的空間。如果在您的 APK 綁定大型模型會對使用者造成極大影響,建議您在應用程式安裝後下載模型、使用較小的模型或在雲端執行計算。NNAPI 並未提供在雲端執行模型的功能。
請參閱 Android Neural Networks API 範例,查看有關如何使用 NNAPI 的範例。
瞭解 Neural Networks API 執行階段
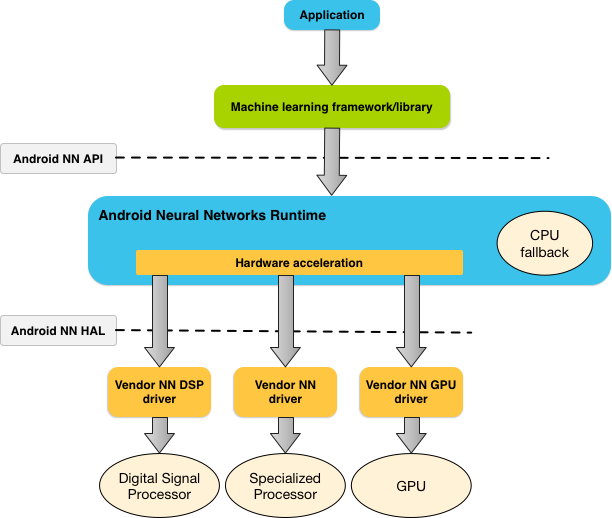
NNAPI 應由機器學習程式庫、架構和工具呼叫,這樣可讓開發人員在裝置外訓練模型,並將其部署在 Android 裝置上。應用程式一般不會直接使用 NNAPI,而是會使用更高層級的機器學習架構。這些架構進而可以使用 NNAPI 在支援的裝置上執行硬體加速推論作業。
根據應用程式的要求和 Android 裝置的硬體功能,Android 的類神經網路執行階段能夠在可用的裝置端處理器 (包括專用的類神經網路硬體、圖形處理器 (GPU) 和數位訊號處理器 (DSP)) 之間有效地分配計算工作負載。
對於缺少專用供應商驅動程式的 Android 裝置,NNAPI 執行階段會在 CPU 上執行要求。
圖 1 是 NNAPI 的高層級系統架構。
Neural Networks API 程式設計模型
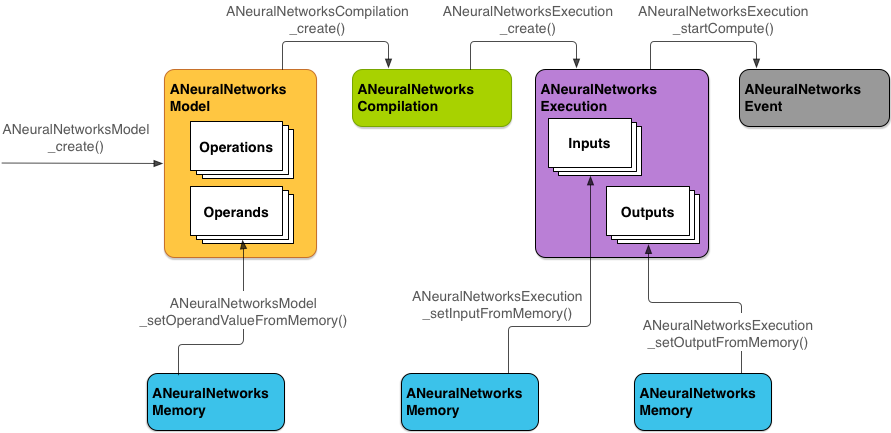
要使用 NNAPI 執行計算,您首先需要一張定義要執行的計算的有向圖。此計算圖加上您的輸入資料 (例如,從機器學習架構傳送的權重和偏誤) 便構成 NNAPI 執行階段評估模型。
NNAPI 主要使用以下四個抽象化概念:
- 模型:由數學運算和訓練過程學習到的常數值構成的計算圖。這些運算僅適用於類神經網路,它們包括 2 維 (2D) 卷積、邏輯 (sigmoid) 激勵函數、修正線性 (ReLU) 激勵函數等。建立模型是一項同步作業。
成功建立後,便可在執行緒和編譯之間重複使用模型。
在 NNAPI 中,模型表示為
ANeuralNetworksModel執行個體。 - 編譯:代表用於將 NNAPI 模型編譯至較低等級程式碼的設定。建立編譯是一項同步作業。成功建立後,便可在執行緒和執行作業之間重複使用編譯。在 NNAPI 中,每個編譯都會表示為
ANeuralNetworksCompilation執行個體。 - 記憶體:代表共用記憶體、記憶體對應檔案和類似的記憶體緩衝區。使用記憶體緩衝區後,NNAPI 執行階段就能更有效地將資料轉移至驅動程式。應用程式通常會建立一個共用記憶體緩衝區,其中包含定義模型所需的每個張量。您還可以使用記憶體緩衝區來儲存執行個體的輸入和輸出。在 NNAPI 中,每個記憶體緩衝區都會表示為
ANeuralNetworksMemory執行個體。 執行作業:用於將 NNAPI 模型應用到一組輸入並收集結果的介面。執行作業可以同步進行,也可以非同步進行。
對於非同步執行作業,多個執行緒可以等待同一個執行作業。在此執行作業完成後,所有的執行緒都會被釋出。
在 NNAPI 中,每個執行作業都會表示為
ANeuralNetworksExecution執行個體。
圖 2 是基本的程式設計流程。
本節其餘內容將介紹一些具體步驟,說明如何設定 NNAPI 模型以便執行計算、編譯模型及執行已編譯的模型。
提供訓練資料存取權
您的訓練權重和偏誤資料可能儲存在同一個檔案中。為了讓 NNAPI 執行階段可以有效地存取這些資料,您可以建立 ANeuralNetworksMemory 執行個體,方法是呼叫 ANeuralNetworksMemory_createFromFd() 函式,並傳入已開啟資料檔案的檔案描述元。您也可以指定記憶體保護旗標,以及檔案中共用記憶體區域開始處的偏移量。
// Create a memory buffer from the file that contains the trained data
ANeuralNetworksMemory* mem1 = NULL;
int fd = open("training_data", O_RDONLY);
ANeuralNetworksMemory_createFromFd(file_size, PROT_READ, fd, 0, &mem1);
雖然在本範例中,我們僅為所有權重使用了一個 ANeuralNetworksMemory 執行個體,不過也可以針對多個檔案使用多個 ANeuralNetworksMemory 執行個體。
使用原生硬體緩衝區
您可以將原生硬體緩衝區用於模型輸入、輸出和常數運算元值。在某些情況下,NNAPI 加速器可以存取 AHardwareBuffer 物件,而無需驅動程式複製資料。AHardwareBuffer 有許多不同的設定,並非每一個 NNAPI 加速器都支援所有這些設定。由於有這項限制,因此請參閱 ANeuralNetworksMemory_createFromAHardwareBuffer 參考文件中列出的限制條件,提前在目標裝置上測試 (方法是透過指派裝置指定加速器),確保使用 AHardwareBuffer 的編譯和執行行為符合預期。
如要允許 NNAPI 執行階段存取 AHardwareBuffer 物件,請建立 ANeuralNetworksMemory 執行個體,方法是呼叫 ANeuralNetworksMemory_createFromAHardwareBuffer 函式並傳入 AHardwareBuffer 物件,如下列程式碼範例所示:
// Configure and create AHardwareBuffer object AHardwareBuffer_Desc desc = ... AHardwareBuffer* ahwb = nullptr; AHardwareBuffer_allocate(&desc, &ahwb); // Create ANeuralNetworksMemory from AHardwareBuffer ANeuralNetworksMemory* mem2 = NULL; ANeuralNetworksMemory_createFromAHardwareBuffer(ahwb, &mem2);
當 NNAPI 不再需要存取 AHardwareBuffer 物件時,便會釋放對應的 ANeuralNetworksMemory 執行個體:
ANeuralNetworksMemory_free(mem2);
注意:
- 您只能針對整個緩衝區使用
AHardwareBuffer,而不能將其與ARect參數搭配使用。 - NNAPI 執行階段不會清除緩衝區。因此,在排定執行作業之前,請務必確認輸入和輸出緩衝區可供存取。
- 不支援同步柵欄檔案描述元。
- 對於具有供應商專用格式和使用位元的
AHardwareBuffer,由供應商實作決定用戶端或驅動程式是否負責清除快取。
模型
模型是 NNAPI 中的基本計算單位。每個模型都由一或多個運算元和運算定義。
運算元
運算元是用於定義圖表的資料物件,其中包括模型的輸入和輸出、包含從一項運算流向另一項運算的資料的中間節點,以及傳遞至這些運算的常數。
在新增運算元至 NNAPI 模型時,有兩種類型可以選擇,分別是純量和張量。
純量代表單個值。NNAPI 支援採用布林、16 位元浮點、32 位元浮點、32 位元整數,以及無正負號 32 位元整數格式的純量值。
NNAPI 大多數運算都涉及張量。張量是 N 維陣列。 NNAPI 支援具有 16 位元浮點值、32 位元浮點值、8 位元量化值、16 位元量化值、32 位元整數和 8 位元布林值的張量。
例如,圖 3 表示的是具有兩項運算 (先加法後乘法) 的模型。這個模型接受一個輸入張量,並產生一個輸出張量。
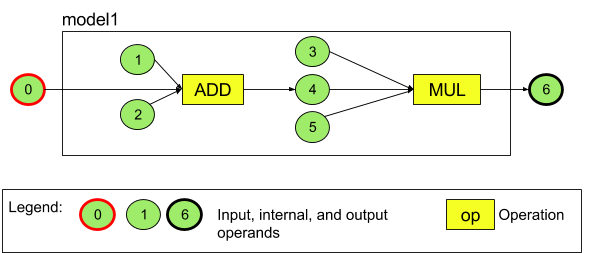
以上模型有七個運算元。系統會根據這些運算元新增至模型的順序給予索引,並依據此索引以隱含方式識別運算元。新增的第一個運算元的索引為 0,第二個為 1,以此類推。運算元 1、2、3 和 5 是常數運算元。
新增運算元的順序無關緊要。例如,模型輸出運算元可能是第一個新增的運算元。重要的是在引用運算元時使用正確的索引值。
有不同類型的運算元,這些類型會在將運算元新增至模型時指定。
運算元不能同時用做模型的輸入和輸出。
每個運算元都必須是單一運算的模型輸入、常數或輸出運算元。
如需進一步瞭解如何使用運算元,請參閱運算元詳細介紹。
運算
運算可以指定要執行的計算。每項運算由下列元素組成:
- 運算類型 (例如加法、乘法、卷積),
- 運算用於輸入的運算元索引清單,以及
- 運算用於輸出的運算元索引清單。
清單中的索引順序非常重要;如需瞭解每種運算類型的預期輸入和輸出,請參閱 NNAPI API 參考資料。
在新增運算之前,您必須先在模型中新增運算消耗或產生的運算元。
新增運算的順序無關緊要。NNAPI 依靠由運算元和運算的計算圖建立的依附元件來決定執行運算的順序。
下表匯總 NNAPI 支援的運算:
API 級別 28 中的已知問題:將 ANEURALNETWORKS_TENSOR_QUANT8_ASYMM 張量傳遞給 Android 9 (API 級別 28) 或以上版本中提供的 ANEURALNETWORKS_PAD 運算時,NNAPI 的輸出可能與更高層級機器學習架構 (例如 TensorFlow Lite) 的輸出不相符。您應改為僅傳遞 ANEURALNETWORKS_TENSOR_FLOAT32。
這項問題在 Android 10 (API 級別 29) 和以上版本中已解決。
建構模型
在以下範例中,我們建立了圖 3 所示的雙運算模型。
如要建構模型,請按照下列步驟操作:
呼叫
ANeuralNetworksModel_create()函式來定義空模型。ANeuralNetworksModel* model = NULL; ANeuralNetworksModel_create(&model);
透過呼叫
ANeuralNetworks_addOperand()將運算元新增至模型。 使用ANeuralNetworksOperandType資料結構定義運算元的資料類型。// In our example, all our tensors are matrices of dimension [3][4] ANeuralNetworksOperandType tensor3x4Type; tensor3x4Type.type = ANEURALNETWORKS_TENSOR_FLOAT32; tensor3x4Type.scale = 0.f; // These fields are used for quantized tensors tensor3x4Type.zeroPoint = 0; // These fields are used for quantized tensors tensor3x4Type.dimensionCount = 2; uint32_t dims[2] = {3, 4}; tensor3x4Type.dimensions = dims;
// We also specify operands that are activation function specifiers ANeuralNetworksOperandType activationType; activationType.type = ANEURALNETWORKS_INT32; activationType.scale = 0.f; activationType.zeroPoint = 0; activationType.dimensionCount = 0; activationType.dimensions = NULL;
// Now we add the seven operands, in the same order defined in the diagram ANeuralNetworksModel_addOperand(model, &tensor3x4Type); // operand 0 ANeuralNetworksModel_addOperand(model, &tensor3x4Type); // operand 1 ANeuralNetworksModel_addOperand(model, &activationType); // operand 2 ANeuralNetworksModel_addOperand(model, &tensor3x4Type); // operand 3 ANeuralNetworksModel_addOperand(model, &tensor3x4Type); // operand 4 ANeuralNetworksModel_addOperand(model, &activationType); // operand 5 ANeuralNetworksModel_addOperand(model, &tensor3x4Type); // operand 6對於具有常數值的運算元,例如應用程式從訓練過程中取得的權重和偏誤,請使用
ANeuralNetworksModel_setOperandValue()和ANeuralNetworksModel_setOperandValueFromMemory()函式。在以下範例中,我們從訓練資料檔案設定常數值,該資料檔案對應我們在「提供訓練資料存取權部」一節建立的記憶體緩衝區。
// In our example, operands 1 and 3 are constant tensors whose values were // established during the training process const int sizeOfTensor = 3 * 4 * 4; // The formula for size calculation is dim0 * dim1 * elementSize ANeuralNetworksModel_setOperandValueFromMemory(model, 1, mem1, 0, sizeOfTensor); ANeuralNetworksModel_setOperandValueFromMemory(model, 3, mem1, sizeOfTensor, sizeOfTensor);
// We set the values of the activation operands, in our example operands 2 and 5 int32_t noneValue = ANEURALNETWORKS_FUSED_NONE; ANeuralNetworksModel_setOperandValue(model, 2, &noneValue, sizeof(noneValue)); ANeuralNetworksModel_setOperandValue(model, 5, &noneValue, sizeof(noneValue));對於要計算的有向圖中的每項運算,請透過呼叫
ANeuralNetworksModel_addOperation()函式將該運算新增至模型中。您的應用程式必須提供以下項目,做為此呼叫的參數:
- 運算類型
- 輸入值的數量
- 輸入運算元的索引陣列
- 輸出值的數量
- 輸出運算元的索引陣列
請注意,單一運算元不能同時用於同一項運算的輸入和輸出。
// We have two operations in our example // The first consumes operands 1, 0, 2, and produces operand 4 uint32_t addInputIndexes[3] = {1, 0, 2}; uint32_t addOutputIndexes[1] = {4}; ANeuralNetworksModel_addOperation(model, ANEURALNETWORKS_ADD, 3, addInputIndexes, 1, addOutputIndexes);
// The second consumes operands 3, 4, 5, and produces operand 6 uint32_t multInputIndexes[3] = {3, 4, 5}; uint32_t multOutputIndexes[1] = {6}; ANeuralNetworksModel_addOperation(model, ANEURALNETWORKS_MUL, 3, multInputIndexes, 1, multOutputIndexes);透過呼叫
ANeuralNetworksModel_identifyInputsAndOutputs()函式確定模型應將那些運算元視為輸入和輸出。// Our model has one input (0) and one output (6) uint32_t modelInputIndexes[1] = {0}; uint32_t modelOutputIndexes[1] = {6}; ANeuralNetworksModel_identifyInputsAndOutputs(model, 1, modelInputIndexes, 1 modelOutputIndexes);
您可以視需要呼叫
ANeuralNetworksModel_relaxComputationFloat32toFloat16(),指定是否允許ANEURALNETWORKS_TENSOR_FLOAT32的計算範圍或精確度與 IEEE 754 16 位元浮點格式一樣低。呼叫
ANeuralNetworksModel_finish()來完成模型的定義。如果沒有錯誤,此函式會傳回結果碼ANEURALNETWORKS_NO_ERROR。ANeuralNetworksModel_finish(model);
建立模型後,您可以無限次編譯模型,每項編譯的執行次數也沒有限制。
控制流程
如需在 NNAPI 模型中納入控制流程,請執行以下操作:
建立對應的執行子圖表 (例如
IF陳述式的then和else子圖表,以及WHILE迴圈的condition和body子圖表) 做為獨立ANeuralNetworksModel*模型:ANeuralNetworksModel* thenModel = makeThenModel(); ANeuralNetworksModel* elseModel = makeElseModel();
在包含控制流程的模型中建立引用這些模型的運算元:
ANeuralNetworksOperandType modelType = { .type = ANEURALNETWORKS_MODEL, }; ANeuralNetworksModel_addOperand(model, &modelType); // kThenOperandIndex ANeuralNetworksModel_addOperand(model, &modelType); // kElseOperandIndex ANeuralNetworksModel_setOperandValueFromModel(model, kThenOperandIndex, &thenModel); ANeuralNetworksModel_setOperandValueFromModel(model, kElseOperandIndex, &elseModel);
新增控制流程運算:
uint32_t inputs[] = {kConditionOperandIndex, kThenOperandIndex, kElseOperandIndex, kInput1, kInput2, kInput3}; uint32_t outputs[] = {kOutput1, kOutput2}; ANeuralNetworksModel_addOperation(model, ANEURALNETWORKS_IF, std::size(inputs), inputs, std::size(output), outputs);
編譯
編譯步驟可確定您的模型將在哪些處理器上執行,並會要求對應的驅動程式為執行作業做好準備。這可能包括產生執行模型的處理器專屬的機器碼。
如需編譯模型,請按照下列步驟操作:
呼叫
ANeuralNetworksCompilation_create()函式建立新的編譯執行個體。// Compile the model ANeuralNetworksCompilation* compilation; ANeuralNetworksCompilation_create(model, &compilation);
如有需要,您可以透過指派裝置明確選擇要在哪些裝置上執行。
如有需要,您可以控制執行階段如何在耗電量和執行速度之間取捨。您可以透過呼叫
ANeuralNetworksCompilation_setPreference()完成此操作。// Ask to optimize for low power consumption ANeuralNetworksCompilation_setPreference(compilation, ANEURALNETWORKS_PREFER_LOW_POWER);
您可以指定的偏好設定包括:
ANEURALNETWORKS_PREFER_LOW_POWER:偏好以盡可能減少電池耗電的方式執行。這種設定適合經常執行的編譯。ANEURALNETWORKS_PREFER_FAST_SINGLE_ANSWER:偏好盡快傳回答案,即使這會消耗更多電量也無妨。此為預設值。ANEURALNETWORKS_PREFER_SUSTAINED_SPEED:偏好最大程度提高連續影格的處理量,例如在處理來自相機的連續影格時。
如有需要,您可以透過呼叫
ANeuralNetworksCompilation_setCaching來設定編譯快取。// Set up compilation caching ANeuralNetworksCompilation_setCaching(compilation, cacheDir, token);
為
cacheDir使用getCodeCacheDir()。對於應用程式內每個模型而言,所指定的token不得重複。透過呼叫
ANeuralNetworksCompilation_finish()完成編譯定義。 如果沒有錯誤,此函式會傳回結果碼ANEURALNETWORKS_NO_ERROR。ANeuralNetworksCompilation_finish(compilation);
探索和指派裝置
在搭載 Android 10 (API 級別 29) 和以上版本的 Android 裝置中,NNAPI 提供了一些函式,可讓機器學習架構程式庫和應用程式取得與可用裝置相關的資訊,並指定要用於執行的裝置。透過提供可用裝置相關資訊,可讓應用程式取得裝置上所安裝驅動程式的確切版本,從而避免已知的不相容問題。如果允許應用程式指定要使用哪些裝置執行模型的不同部分,應用程式就能針對自己部署所在的 Android 裝置進行最佳化。
探索裝置
使用 ANeuralNetworks_getDeviceCount 取得可用裝置的數量。對於每部裝置,請使用 ANeuralNetworks_getDevice 將 ANeuralNetworksDevice 執行個體設定為該裝置的引用。
設定裝置引用後,您可以使用以下函式找出該裝置的其他資訊:
ANeuralNetworksDevice_getFeatureLevelANeuralNetworksDevice_getNameANeuralNetworksDevice_getTypeANeuralNetworksDevice_getVersion
指派裝置
使用 ANeuralNetworksModel_getSupportedOperationsForDevices 來探索模型的哪些運算可以在特定裝置上執行。
如需控制用於執行的加速器,請呼叫 ANeuralNetworksCompilation_createForDevices (而不是 ANeuralNetworksCompilation_create)。
請像往常一樣使用產生的 ANeuralNetworksCompilation 物件。
如果提供的模型包含所選裝置不支援的運算,此函式會傳回錯誤。
如果指定了多個裝置,執行階段將負責在裝置之間分配作業。
與其他裝置類似,NNAPI CPU 實作以 ANeuralNetworksDevice 表示,其名稱為 nnapi-reference,類型則為 ANEURALNETWORKS_DEVICE_TYPE_CPU。呼叫 ANeuralNetworksCompilation_createForDevices 時,CPU 實作不用於處理模型編譯和執行失敗的情況。
應用程式負責將模型分區為可以在指定裝置上執行的子模型。如果應用程式不需要手動將模型分區,應繼續呼叫比較簡單的 ANeuralNetworksCompilation_create,從而使用所有可用裝置 (包括 CPU) 來為模型加速。如果您使用 ANeuralNetworksCompilation_createForDevices 指定的裝置不完全支援模型,系統將傳回 ANEURALNETWORKS_BAD_DATA。
模型分區
當模型有多部可用裝置時,NNAPI 執行階段會跨裝置分配工作。例如,如果為 ANeuralNetworksCompilation_createForDevices 提供多部裝置,則在分配工作時會考慮所有指定的裝置。請注意,如果 CPU 裝置不在清單中,便會停用 CPU 執行作業。使用 ANeuralNetworksCompilation_create 時,系統會考慮所有可用裝置 (包括 CPU)。
系統會針對模型的每項運算,從可用裝置清單中選取支援運算的裝置,並宣告最佳效能 (即最快的執行時間或最低的耗電量) 來完成分配作業,具體取決於用戶端指定的執行效能。不同處理器之間的 IO 差異可能會導致效率不佳,但這項分區演算法不考慮此情形,因此,在指定多個處理器 (使用 ANeuralNetworksCompilation_createForDevices 明確指定或使用 ANeuralNetworksCompilation_create 隱含指定) 時,務必要對應用程式進行分析。
如需瞭解 NNAPI 如何將模型分區,請在 Android 記錄中查看訊息 (在有 ExecutionPlan 標記的 INFO 層級查看):
ModelBuilder::findBestDeviceForEachOperation(op-name): device-index
op-name 是圖表中運算的描述性名稱,device-index 則是裝置清單中候選裝置的索引。
這份清單中會列出提供給 ANeuralNetworksCompilation_createForDevices 的輸入;或者,如果使用 ANeuralNetworksCompilation_createForDevices,則會列出在為所有使用 ANeuralNetworks_getDeviceCount 和 ANeuralNetworks_getDevice 的裝置進行疊代時傳回的裝置。
訊息 (在有 ExecutionPlan 標記的 INFO 層級查看):
ModelBuilder::partitionTheWork: only one best device: device-name
此訊息表示整個圖已在裝置 device-name 上加速。
執行
執行步驟會將模型套用至一組輸入,並將計算輸出儲存至一或多個使用者緩衝區或應用程式分配的記憶體空間。
如要執行已編譯的模型,請按照下列步驟操作:
呼叫
ANeuralNetworksExecution_create()函式來建立新的執行個體。// Run the compiled model against a set of inputs ANeuralNetworksExecution* run1 = NULL; ANeuralNetworksExecution_create(compilation, &run1);
指定應用程式要在何處讀取計算所需的輸入值。應用程式可以分別呼叫
ANeuralNetworksExecution_setInput()或ANeuralNetworksExecution_setInputFromMemory(),以便從使用者緩衝區或分配的記憶體空間讀取輸入值。// Set the single input to our sample model. Since it is small, we won't use a memory buffer float32 myInput[3][4] = { ...the data... }; ANeuralNetworksExecution_setInput(run1, 0, NULL, myInput, sizeof(myInput));
指定應用程式要在何處寫入輸出值。應用程式可以分別呼叫
ANeuralNetworksExecution_setOutput()或ANeuralNetworksExecution_setOutputFromMemory(),以便將輸出值寫入使用者緩衝區或分配的記憶體空間。// Set the output float32 myOutput[3][4]; ANeuralNetworksExecution_setOutput(run1, 0, NULL, myOutput, sizeof(myOutput));
透過呼叫
ANeuralNetworksExecution_startCompute()函式安排開始執行。如果沒有錯誤,此函式會傳回結果碼ANEURALNETWORKS_NO_ERROR。// Starts the work. The work proceeds asynchronously ANeuralNetworksEvent* run1_end = NULL; ANeuralNetworksExecution_startCompute(run1, &run1_end);
呼叫
ANeuralNetworksEvent_wait()函式等待執行完成。如果執行成功,此函式會傳回結果碼ANEURALNETWORKS_NO_ERROR。 要等待執行完成時,可以在不同於開始執行的執行緒上進行。// For our example, we have no other work to do and will just wait for the completion ANeuralNetworksEvent_wait(run1_end); ANeuralNetworksEvent_free(run1_end); ANeuralNetworksExecution_free(run1);
如有需要,您可以使用相同的編譯執行個體,將不同輸入組套用至已編譯的模型,進而建立新的
ANeuralNetworksExecution執行個體。// Apply the compiled model to a different set of inputs ANeuralNetworksExecution* run2; ANeuralNetworksExecution_create(compilation, &run2); ANeuralNetworksExecution_setInput(run2, ...); ANeuralNetworksExecution_setOutput(run2, ...); ANeuralNetworksEvent* run2_end = NULL; ANeuralNetworksExecution_startCompute(run2, &run2_end); ANeuralNetworksEvent_wait(run2_end); ANeuralNetworksEvent_free(run2_end); ANeuralNetworksExecution_free(run2);
同步執行作業
非同步執行作業需要花費時間來建立和同步處理執行緒。 此外,延遲時間可能差異極大,從通知或喚醒執行緒到最終綁定至 CPU 核心,這段時間的最長延誤時間長達 500 微秒。
為了縮短延遲時間,您可以改為指示應用程式對執行階段進行同步推論呼叫。此呼叫只會在推論完成後傳回,而不會在推論開始時傳回。應用程式會呼叫 ANeuralNetworksExecution_compute 對執行階段進行同步呼叫,而不是呼叫 ANeuralNetworksExecution_startCompute 對執行階段進行非同步推論呼叫。對 ANeuralNetworksExecution_compute 的呼叫不會使用 ANeuralNetworksEvent,也不會與對 ANeuralNetworksEvent_wait 的呼叫配對。
爆發執行作業
在搭載 Android 10 (API 級別 29) 或以上版本的 Android 裝置上,NNAPI 支援透過 ANeuralNetworksBurst 物件進行爆發執行作業。爆發執行作業是針對同一編譯,快速連續進行的一系列執行作業,例如執行相機所拍攝的影格或連續音訊取樣。使用 ANeuralNetworksBurst 物件可以提高執行速度,因為這些物件會指示加速器可以在執行作業間重複使用資源,且加速器應在爆發持續時間維持高效能狀態。
ANeuralNetworksBurst 只會稍微改動正常的執行路徑。請依以下程式碼片段所示,使用 ANeuralNetworksBurst_create 建立爆發物件:
// Create burst object to be reused across a sequence of executions ANeuralNetworksBurst* burst = NULL; ANeuralNetworksBurst_create(compilation, &burst);
爆發執行作業會同步處理。不過,請勿使用 ANeuralNetworksExecution_compute 執行每項推論,而是在對 ANeuralNetworksExecution_burstCompute 函式的呼叫中,將每項 ANeuralNetworksExecution 物件與相同的 ANeuralNetworksBurst 配對。
// Create and configure first execution object // ... // Execute using the burst object ANeuralNetworksExecution_burstCompute(execution1, burst); // Use results of first execution and free the execution object // ... // Create and configure second execution object // ... // Execute using the same burst object ANeuralNetworksExecution_burstCompute(execution2, burst); // Use results of second execution and free the execution object // ...
如果不再需要 ANeuralNetworksBurst 物件,請使用 ANeuralNetworksBurst_free 將其釋放。
// Cleanup ANeuralNetworksBurst_free(burst);
非同步指令佇列和柵欄執行作業
在 Android 11 以上版本中,NNAPI 還支援透過 ANeuralNetworksExecution_startComputeWithDependencies() 方法排定非同步執行作業。使用這項方法時,執行作業會等待所有依附事件收到訊號,再開始評估。當完成執行作業且輸出可供使用時,傳回的事件就會收到訊號。
該事件可能由同步柵欄提供支援,具體取決於在哪個裝置上處理執行作業。您必須呼叫 ANeuralNetworksEvent_wait() 來等待事件,並恢復執行作業所使用的資源。您可以使用 ANeuralNetworksEvent_createFromSyncFenceFd() 將同步柵欄匯入事件物件,並使用 ANeuralNetworksEvent_getSyncFenceFd() 從事件物件匯出同步柵欄。
大小會動態變化的輸出
如需支援輸出大小取決於輸入資料的模型 (也就是在執行模型時無法確定大小的模型),請使用 ANeuralNetworksExecution_getOutputOperandRank 和 ANeuralNetworksExecution_getOutputOperandDimensions。
以下程式碼範例示範如何執行這項操作:
// Get the rank of the output uint32_t myOutputRank = 0; ANeuralNetworksExecution_getOutputOperandRank(run1, 0, &myOutputRank); // Get the dimensions of the output std::vector<uint32_t> myOutputDimensions(myOutputRank); ANeuralNetworksExecution_getOutputOperandDimensions(run1, 0, myOutputDimensions.data());
清除
清除步驟可以釋放用於計算的內部資源。
// Cleanup ANeuralNetworksCompilation_free(compilation); ANeuralNetworksModel_free(model); ANeuralNetworksMemory_free(mem1);
錯誤管理和 CPU 回退
如果在分區過程中出現錯誤、驅動程式無法編譯模型 (或部分模型),或者驅動程式無法執行已編譯的模型 (或部分模型),NNAPI 可能會改回使用自身一或多種運算的 CPU 實作。
如果 NNAPI 用戶端包含最佳化版本的運算 (例如,TFLite),則透過用戶端的最佳化運算實作停用 CPU 回退並處理故障或許對您更有利。
在 Android 10 中,如果使用 ANeuralNetworksCompilation_createForDevices 執行編譯,將會停用 CPU 回退。
在 Android P 中,如果驅動程式上的執行作業失敗,NNAPI 執行作業會改回使用 CPU。
在 Android 10 上使用 ANeuralNetworksCompilation_create 而不是 ANeuralNetworksCompilation_createForDevices 時,情況亦同。
第一次執行作業會針對單一分區進行回退,如果仍然失敗,就會在 CPU 上再次嘗試執行整個模型。
如果分區或編譯失敗,就會在 CPU 上嘗試執行整個模型。
在某些情況下,CPU 不支援特定運算,如果有此類情況,編譯或執行作業將會失敗,而不會發生回退情形。
即使在停用 CPU 回退後,模型中仍可能有運算排定在 CPU 上執行。如果 CPU 列在提供給 ANeuralNetworksCompilation_createForDevices 的處理器清單中,而且是唯一支援這些運算的處理器,或者是在處理這些運算上效能最佳的處理器,便會被選為主要的 (非回退) 執行程式。
為確保沒有 CPU 執行作業,請在從裝置清單中排除 nnapi-reference 時同時使用 ANeuralNetworksCompilation_createForDevices。
從 Android P 開始,只要將 debug.nn.partition 屬性設為 2,就能在偵錯版本中於執行時停用回退。
記憶體網域
在 Android 11 和以上版本中,NNAPI 支援為不透明記憶體提供配置器介面的記憶體網域。有了這項功能,應用程式可以在執行過程中傳送裝置原生記憶體,這讓 NNAPI 在同一驅動程式中進行連續執行作業時,不會有不必要的資料複製和轉換情形。
記憶體網域功能適用於主要在驅動程式內部使用,而且無需頻繁存取用戶端的張量。此類張量包括序列模型中的狀態張量。對於需要在用戶端頻繁存取 CPU 的張量,請改為使用共用記憶體集區。
如要分配不透明記憶體,請執行以下步驟:
呼叫
ANeuralNetworksMemoryDesc_create()函式來建立新的記憶體描述元:// Create a memory descriptor ANeuralNetworksMemoryDesc* desc; ANeuralNetworksMemoryDesc_create(&desc);
透過呼叫
ANeuralNetworksMemoryDesc_addInputRole()和ANeuralNetworksMemoryDesc_addOutputRole()指定所有預期的輸入和輸出角色。// Specify that the memory may be used as the first input and the first output // of the compilation ANeuralNetworksMemoryDesc_addInputRole(desc, compilation, 0, 1.0f); ANeuralNetworksMemoryDesc_addOutputRole(desc, compilation, 0, 1.0f);
如有需要,可透過呼叫
ANeuralNetworksMemoryDesc_setDimensions()指定記憶體維度。// Specify the memory dimensions uint32_t dims[] = {3, 4}; ANeuralNetworksMemoryDesc_setDimensions(desc, 2, dims);
透過呼叫
ANeuralNetworksMemoryDesc_finish()來完成描述元定義。ANeuralNetworksMemoryDesc_finish(desc);
將描述元傳送給
ANeuralNetworksMemory_createFromDesc()以便依據需要分配任意數量的記憶體。// Allocate two opaque memories with the descriptor ANeuralNetworksMemory* opaqueMem; ANeuralNetworksMemory_createFromDesc(desc, &opaqueMem);
釋放不再需要的記憶體描述元。
ANeuralNetworksMemoryDesc_free(desc);
根據 ANeuralNetworksMemoryDesc 物件中指定的角色,用戶端只能將建立的 ANeuralNetworksMemory 物件和 ANeuralNetworksExecution_setInputFromMemory() 或 ANeuralNetworksExecution_setOutputFromMemory() 搭配使用。必須將偏移和長度引數設為 0,表示已使用所有記憶體。用戶端還可以使用 ANeuralNetworksMemory_copy() 明確設定或擷取記憶體內容。
您可以使用未指定的維度或秩的角色建立不透明的記憶體。
在這種情況下,如果底層驅動程式不支援這項操作,可能會無法建立記憶體並顯示 ANEURALNETWORKS_OP_FAILED 狀態。建議用戶端要實作回退邏輯時,分配 Ashmem 或 BLOB 模式 AHardwareBuffer 支援,且大小足夠的緩衝區。
當 NNAPI 不再需要存取不透明的記憶體物件時,請釋放對應的 ANeuralNetworksMemory 執行個體:
ANeuralNetworksMemory_free(opaqueMem);
評估效能
如要評估應用程式的效能,您可以測量執行時間或進行效能分析。
執行時間
如要透過執行階段確定總執行時間,您可以使用同步執行 API 並測量呼叫所花費的時間。如要透過較低層級的軟體堆疊確定總執行時間,您可以使用 ANeuralNetworksExecution_setMeasureTiming 和 ANeuralNetworksExecution_getDuration,以便取得以下資訊:
- 加速器的執行時間 (而不是在主機處理器執行的驅動程式的執行時間)。
- 驅動程式的執行時間 (包括加速器所花費的時間)。
驅動程式的執行時間不包含部分開銷,例如執行階段本身,以及執行階段與驅動程式進行通訊所需的處理序間通訊 (IPC)。
這些 API 會測量從提交到完成作業的持續時間,而不是驅動程式或加速器執行推論所需的時間 (此時間可能會因為環境切換而中斷)。
比方說,如果推論 1 先開始,接著驅動程式停止作業以便執行推論 2,然後繼續執行並完成推論 1,則推論 1 的執行時間將包括為了執行推論 2 而停止作業的時間。
對於應用程式的實際工作環境部署作業,這項時間資訊可能很實用,有助於應用程式收集遙測資料供離線使用。您可以使用時間資料來修改應用程式,就能提高效能。
在使用這項功能時,請注意以下幾點:
- 搜集時間資訊可能會導致效能降低。
- 只有驅動程式能夠計算在自身或加速器上花費的時間,但不包括在 NNAPI 執行階段和 IPC 上花費的時間。
- 您只能將這些 API 與使用
ANeuralNetworksCompilation_createForDevices(其中numDevices = 1) 建立的ANeuralNetworksExecution搭配使用。 - 不需要驅動程式即可回報時間資訊。
使用 Android Systrace 對應用程式進行效能分析
從 Android 10 開始,NNAPI 會自動產生 systrace 事件,您可以使用該事件分析應用程式效能。
NNAPI 原始碼附帶 parse_systrace 公用程式,用於處理應用程式產生的 systrace 事件,並會產生表格檢視畫面,顯示在模型生命週期的不同階段 (建立執行個體、準備、編譯執行作業和終止) 以及應用程式不同層級上花費的時間。應用程式中的層級包括:
Application:主要應用程式程式碼Runtime:NNAPI 執行階段IPC:NNAPI 執行階段和驅動程式程式碼之間的處理序間通訊Driver:加速器驅動程式程序。
產生效能分析資料
假設您在 $ANDROID_BUILD_TOP 中切換為 AOSP 來源樹,並使用 TFLite 圖片分類範例做為目標應用程式,您可以按照以下步驟產生 NNAPI 效能分析資料:
- 使用以下指令啟動 Android systrace:
$ANDROID_BUILD_TOP/external/chromium-trace/systrace.py -o trace.html -a org.tensorflow.lite.examples.classification nnapi hal freq sched idle load binder_driver
-o trace.html 參數表示將在 trace.html 中寫入追蹤記錄。在分析您的應用程式時,您需要將 org.tensorflow.lite.examples.classification 替換為應用程式資訊清單中指定的程序名稱。
這項操作會讓其中一個殼層主控台處於忙碌狀態,而且不會在背景執行該指令,因為它會以互動方式等待 enter 終止。
- 在 systrace 搜集器啟動後,啟動您的應用程式並執行基準測試。
在我們的範例中,您可以從 Android Studio 啟動圖片分類應用程式,也可以直接從測試手機使用者介面啟動 (如果已安裝該應用程式)。 如要產生特定 NNAPI 資料,您需要將應用程式設為使用 NNAPI,方法是在應用程式設定對話方塊中選取 NNAPI 做為目標裝置。
測試完成後,請從第 1 步開始在主控台終端機上按
enter,以終止 systrace。執行
systrace_parser公用程式以便產生累計統計資料:
$ANDROID_BUILD_TOP/frameworks/ml/nn/tools/systrace_parser/parse_systrace.py --total-times trace.html
剖析器接受以下參數:
- --total-times:顯示在層級花費的總時間,包括等待向基礎層發出呼叫所花費的時間
- --print-detail:列印從 systrace 收集的所有事件
- --per-execution:僅列印執行作業及其子階段的統計資料 (按執行次數),而不是所有階段的統計資料
- --json:產生 JSON 格式的輸出檔案
輸出範例如下所示:
===========================================================================================================================================
NNAPI timing summary (total time, ms wall-clock) Execution
----------------------------------------------------
Initialization Preparation Compilation I/O Compute Results Ex. total Termination Total
-------------- ----------- ----------- ----------- ------------ ----------- ----------- ----------- ----------
Application n/a 19.06 1789.25 n/a n/a 6.70 21.37 n/a 1831.17*
Runtime - 18.60 1787.48 2.93 11.37 0.12 14.42 1.32 1821.81
IPC 1.77 - 1781.36 0.02 8.86 - 8.88 - 1792.01
Driver 1.04 - 1779.21 n/a n/a n/a 7.70 - 1787.95
Total 1.77* 19.06* 1789.25* 2.93* 11.74* 6.70* 21.37* 1.32* 1831.17*
===========================================================================================================================================
* This total ignores missing (n/a) values and thus is not necessarily consistent with the rest of the numbers
如果收集的事件不是完整的應用程式追蹤記錄,剖析器可能會無法正常運作。具體來說,如果為標記區段結尾而產生的 systrace 事件出現在追蹤記錄中,但沒有相關的區段開始事件,剖析器可能會無法正常運作。當您啟動 systrace 收集器時,如果產生先前效能分析階段中的某些事件,通常就會發生這類情況。 在這種情況下,您必須再次執行效能分析。
將應用程式程式碼的統計資料新增至 systrace_parser 輸出
parse_systrace 應用程式以內建的 Android systrace 功能為基礎。您可以使用具有自訂事件名稱的 systrace API (適用於 Java、原生應用程式的 API) 為應用程式中的特定運算新增追蹤記錄。
如要將自訂事件與應用程式生命週期的各個階段建立關聯,請在事件名稱前方加上以下其中一個字串:
[NN_LA_PI]:初始化階段的應用程式層級事件[NN_LA_PP]:準備階段的應用程式層級事件[NN_LA_PC]:編譯階段的應用程式層級事件[NN_LA_PE]:執行階段的應用程式層級事件
以下範例說明如何透過為 Execution 階段和 Application 層 (當中包含在 NNAPI 追蹤記錄中不會考慮的其他 preprocessBitmap 區段) 新增 runInferenceModel 區段,藉此更改 TFLite 圖片分類範例程式碼。runInferenceModel 區段是 NNAPI systrace 剖析器處理的 systrace 事件的一部分:
Kotlin
/** Runs inference and returns the classification results. */ fun recognizeImage(bitmap: Bitmap): List{ // This section won’t appear in the NNAPI systrace analysis Trace.beginSection("preprocessBitmap") convertBitmapToByteBuffer(bitmap) Trace.endSection() // Run the inference call. // Add this method in to NNAPI systrace analysis. Trace.beginSection("[NN_LA_PE]runInferenceModel") long startTime = SystemClock.uptimeMillis() runInference() long endTime = SystemClock.uptimeMillis() Trace.endSection() ... return recognitions }
Java
/** Runs inference and returns the classification results. */ public ListrecognizeImage(final Bitmap bitmap) { // This section won’t appear in the NNAPI systrace analysis Trace.beginSection("preprocessBitmap"); convertBitmapToByteBuffer(bitmap); Trace.endSection(); // Run the inference call. // Add this method in to NNAPI systrace analysis. Trace.beginSection("[NN_LA_PE]runInferenceModel"); long startTime = SystemClock.uptimeMillis(); runInference(); long endTime = SystemClock.uptimeMillis(); Trace.endSection(); ... Trace.endSection(); return recognitions; }
服務品質
在 Android 11 以上版本中,NNAPI 讓應用程式可以指示模型的相對優先順序、準備指定模型的預計最長時間,以及完成指定計算的預計最長時間,從而改善服務品質 (QoS)。Android 11 還支援其他 NNAPI 結果碼,可讓應用程式瞭解超過執行期限等錯誤情況。
設定工作負載的優先順序
如要設定 NNAPI 工作負載的優先順序,請先呼叫 ANeuralNetworksCompilation_setPriority(),再呼叫 ANeuralNetworksCompilation_finish()。
設定期限
應用程式可以為模型編譯和推論設定期限。
- 如需設定編譯逾時,請先呼叫
ANeuralNetworksCompilation_setTimeout(),然後再呼叫ANeuralNetworksCompilation_finish()。 - 如需設定推論逾時,請先呼叫
ANeuralNetworksExecution_setTimeout(),然後開始編譯。
運算元詳細介紹
以下部分介紹關於使用運算元的進階主題。
量化張量
量化張量是一種表示 N 維浮點值陣列的簡潔方式。
NNAPI 支援 8 位元非對稱式量化張量。對於這些張量,每個儲存格的值都會以 8 位元整數表示。與張量相關聯的是一個比例和一個零點值,可用於將 8 位元整數轉換為要表示的浮點值。
公式如下:
(cellValue - zeroPoint) * scale
其中,zeroPoint 值為 32 位元整數,scale 則是 32 位元浮點值。
與 32 位元浮點值的張量相比,8 位元量化張量具有以下兩項優勢:
- 應用程式變得更小,因為訓練的權重占 32 位元張量大小的四分之一。
- 在一般情況下,計算的執行速度可以變得更快。這是由於您只需要從記憶體中擷取少量資料,而且 DSP 等處理器進行整數數學計算的效率更高。
雖然您可以將浮點模型轉換為量化模型,但根據我們的經驗,直接訓練量化模型可以獲得更好的結果。事實上,類神經網路會透過學習來補償每個值增加的精細程度。對於每個量化張量,scale 和 zeroPoint 值會在訓練過程中確定。
在 NNAPI 中,您可以透過將 ANeuralNetworksOperandType 資料結構的類型欄位設定為 ANEURALNETWORKS_TENSOR_QUANT8_ASYMM 來定義量化張量類型。
您還可以在該資料結構中指定張量的 scale 和 zeroPoint 值。
除 8 位元非對稱式量化張量外,NNAPI 也支援以下項目:
ANEURALNETWORKS_TENSOR_QUANT8_SYMM_PER_CHANNEL,可用於表示CONV/DEPTHWISE_CONV/TRANSPOSED_CONV運算的權重。ANEURALNETWORKS_TENSOR_QUANT16_ASYMM,可用於QUANTIZED_16BIT_LSTM的內部狀態。ANEURALNETWORKS_TENSOR_QUANT8_SYMM,可做為對ANEURALNETWORKS_DEQUANTIZE的輸入。
可選用的運算元
一些運算 (如 ANEURALNETWORKS_LSH_PROJECTION) 採用可選用的運算元。如需在模型中表明省略了可選用的運算元,請呼叫 ANeuralNetworksModel_setOperandValue() 函式,針對緩衝區傳遞 NULL,並針對長度傳遞 0。
如果是否選用運算元在各個執行作業中皆不相同,您可以使用 ANeuralNetworksExecution_setInput() 或 ANeuralNetworksExecution_setOutput() 函式,針對緩衝區傳遞 NULL,並針對長度傳遞 0,藉此表明省略了運算元。
未知秩的張量
Android 9 (API 級別 28) 引入了維度未知但秩已知 (維度數目) 的模型運算元。Android 10 (API 級別 29) 引入了未知秩的張量,如 ANeuralNetworksOperandType 中所示。
NNAPI 基準
AOSP 中的 platform/test/mlts/benchmark (基準應用程式) 和 platform/test/mlts/models (模型和資料集) 提供了 NNAPI 基準。
該基準會評估延遲時間和準確率,並針對相同的模型和資料集,將驅動程式與透過 CPU 上執行的 Tensorflow Lite 完成的作業相比較。
如需使用基準,請執行以下操作:
將目標 Android 裝置與電腦連接,並開啟終端機視窗,確保可透過 ADB 存取該裝置。
如果連接了多個 Android 裝置,請匯出目標裝置
ANDROID_SERIAL環境變數。前往 Android 頂層來源目錄。
執行下列指令:
lunch aosp_arm-userdebug # Or aosp_arm64-userdebug if available ./test/mlts/benchmark/build_and_run_benchmark.sh
在基準執行結束後,其結果將表示為傳遞給
xdg-open的 HTML 頁面。
NNAPI 記錄
NNAPI 會在系統記錄中產生有用的診斷資訊。 如要分析記錄,請使用 logcat 公用程式。
將屬性 debug.nn.vlog (使用 adb shell) 設為下列以空格、冒號或逗號分隔的值清單,為特定階段或元件啟用詳細 NNAPI 記錄:
model:建構模型compilation:產生模型執行計畫和編譯execution:執行模型cpuexe:使用 NNAPI CPU 實作執行運算manager:NNAPI 擴充功能、可用介面和功能相關資訊all或1:以上所有元素
例如,如需啟用完整的詳細記錄,請使用 adb shell setprop debug.nn.vlog all 指令。如要停用詳細記錄,請使用 adb shell setprop debug.nn.vlog '""' 指令。
詳細記錄啟用後,會產生 INFO 層級的記錄項目,並將標記設定為階段或元件名稱。
在 debug.nn.vlog 控制的訊息旁邊,NNAPI API 元件提供其他不同層級的記錄項目,每個記錄項目都使用特定的記錄標記。
如要取得元件清單,請使用以下運算式搜尋來源樹:
grep -R 'define LOG_TAG' | awk -F '"' '{print $2}' | sort -u | egrep -v "Sample|FileTag|test"
此運算式目前會返回以下標記:
- BurstBuilder
- Callbacks
- CompilationBuilder
- CpuExecutor
- ExecutionBuilder
- ExecutionBurstController
- ExecutionBurstServer
- ExecutionPlan
- FibonacciDriver
- GraphDump
- IndexedShapeWrapper
- IonWatcher
- Manager
- Memory
- MemoryUtils
- MetaModel
- ModelArgumentInfo
- ModelBuilder
- NeuralNetworks
- OperationResolver
- Operations
- OperationsUtils
- PackageInfo
- TokenHasher
- TypeManager
- Utils
- ValidateHal
- VersionedInterfaces
如需控制 logcat 所顯示的記錄訊息層級,請使用環境變數 ANDROID_LOG_TAGS。
如要顯示完整的 NNAPI 記錄訊息集並停用其他訊息,請將 ANDROID_LOG_TAGS 設為以下內容:
BurstBuilder:V Callbacks:V CompilationBuilder:V CpuExecutor:V ExecutionBuilder:V ExecutionBurstController:V ExecutionBurstServer:V ExecutionPlan:V FibonacciDriver:V GraphDump:V IndexedShapeWrapper:V IonWatcher:V Manager:V MemoryUtils:V Memory:V MetaModel:V ModelArgumentInfo:V ModelBuilder:V NeuralNetworks:V OperationResolver:V OperationsUtils:V Operations:V PackageInfo:V TokenHasher:V TypeManager:V Utils:V ValidateHal:V VersionedInterfaces:V *:S.
您可以使用以下指令設定 ANDROID_LOG_TAGS:
export ANDROID_LOG_TAGS=$(grep -R 'define LOG_TAG' | awk -F '"' '{ print $2 ":V" }' | sort -u | egrep -v "Sample|FileTag|test" | xargs echo -n; echo ' *:S')
請注意,這只是適用於 logcat 的篩選條件。您仍需要將屬性 debug.nn.vlog 設為 all,才能產生詳細記錄資訊。