
অ্যান্ড্রয়েড নিউরাল নেটওয়ার্কস এপিআই (এনএএনএপিআই) হল একটি অ্যান্ড্রয়েড সি এপিআই যা অ্যান্ড্রয়েড ডিভাইসে মেশিন লার্নিংয়ের জন্য কম্পিউটেশনালি ইনটেনসিভ অপারেশন চালানোর জন্য ডিজাইন করা হয়েছে। এনএনএপিআই উচ্চ-স্তরের মেশিন লার্নিং ফ্রেমওয়ার্ক, যেমন টেনসরফ্লো লাইট এবং ক্যাফে২, এর জন্য কার্যকারিতার একটি বেস স্তর প্রদান করার জন্য ডিজাইন করা হয়েছে, যা নিউরাল নেটওয়ার্ক তৈরি এবং প্রশিক্ষণ দেয়। এপিআইটি অ্যান্ড্রয়েড 8.1 (এপিআই লেভেল 27) বা তার বেশি চলমান সমস্ত অ্যান্ড্রয়েড ডিভাইসে উপলব্ধ, তবে অ্যান্ড্রয়েড 15 এ এটি বন্ধ করা হয়েছে।
NNAPI পূর্বে প্রশিক্ষিত, ডেভেলপার-সংজ্ঞায়িত মডেলগুলিতে অ্যান্ড্রয়েড ডিভাইস থেকে ডেটা প্রয়োগ করে ইনফারেন্সিং সমর্থন করে। ইনফারেন্সিংয়ের উদাহরণগুলির মধ্যে রয়েছে চিত্রগুলিকে শ্রেণীবদ্ধ করা, ব্যবহারকারীর আচরণের পূর্বাভাস দেওয়া এবং অনুসন্ধান প্রশ্নের উপযুক্ত প্রতিক্রিয়া নির্বাচন করা।
ডিভাইসে ইনফারেন্সিংয়ের অনেক সুবিধা রয়েছে:
- লেটেন্সি : আপনাকে নেটওয়ার্ক সংযোগের মাধ্যমে একটি অনুরোধ পাঠাতে হবে না এবং প্রতিক্রিয়ার জন্য অপেক্ষা করতে হবে না। উদাহরণস্বরূপ, এটি এমন ভিডিও অ্যাপ্লিকেশনগুলির জন্য গুরুত্বপূর্ণ হতে পারে যা ক্যামেরা থেকে আসা ধারাবাহিক ফ্রেমগুলি প্রক্রিয়া করে।
- উপলব্ধতা : নেটওয়ার্ক কভারেজের বাইরে থাকা সত্ত্বেও অ্যাপ্লিকেশনটি কাজ করে।
- গতি : নিউরাল নেটওয়ার্ক প্রক্রিয়াকরণের জন্য নির্দিষ্ট নতুন হার্ডওয়্যার শুধুমাত্র একটি সাধারণ-উদ্দেশ্য সিপিইউর তুলনায় উল্লেখযোগ্যভাবে দ্রুত গণনা প্রদান করে।
- গোপনীয়তা : ডেটা অ্যান্ড্রয়েড ডিভাইস থেকে বের হয় না।
- খরচ : অ্যান্ড্রয়েড ডিভাইসে সমস্ত গণনা সম্পন্ন হলে কোনও সার্ভার ফার্মের প্রয়োজন হয় না।
একজন ডেভেলপারের মনে রাখা উচিত এমন কিছু বিনিময়-বিষয়ও রয়েছে:
- সিস্টেমের ব্যবহার : নিউরাল নেটওয়ার্ক মূল্যায়নে অনেক গণনার প্রয়োজন হয়, যা ব্যাটারির শক্তির ব্যবহার বাড়িয়ে দিতে পারে। যদি এটি আপনার অ্যাপের জন্য উদ্বেগের বিষয় হয়, বিশেষ করে দীর্ঘমেয়াদী গণনার জন্য, তাহলে আপনার ব্যাটারির স্বাস্থ্য পর্যবেক্ষণ করার কথা বিবেচনা করা উচিত।
- অ্যাপ্লিকেশনের আকার : আপনার মডেলের আকারের দিকে মনোযোগ দিন। মডেলগুলি একাধিক মেগাবাইট জায়গা নিতে পারে। যদি আপনার APK-তে বড় মডেলগুলি বান্ডেল করা আপনার ব্যবহারকারীদের উপর অপ্রয়োজনীয় প্রভাব ফেলে, তাহলে আপনি অ্যাপ ইনস্টলেশনের পরে মডেলগুলি ডাউনলোড করার, ছোট মডেলগুলি ব্যবহার করার, অথবা ক্লাউডে আপনার গণনা চালানোর কথা বিবেচনা করতে পারেন। NNAPI ক্লাউডে মডেলগুলি চালানোর জন্য কার্যকারিতা প্রদান করে না।
NNAPI কীভাবে ব্যবহার করবেন তার একটি উদাহরণ দেখতে Android Neural Networks API নমুনাটি দেখুন।
নিউরাল নেটওয়ার্ক API রানটাইম বুঝুন
NNAPI বলতে মেশিন লার্নিং লাইব্রেরি, ফ্রেমওয়ার্ক এবং টুলগুলিকে বোঝানো হয় যা ডেভেলপারদের তাদের মডেলগুলিকে ডিভাইসের বাইরে প্রশিক্ষণ দিতে এবং অ্যান্ড্রয়েড ডিভাইসে স্থাপন করতে দেয়। অ্যাপগুলি সাধারণত সরাসরি NNAPI ব্যবহার করে না, বরং উচ্চ-স্তরের মেশিন লার্নিং ফ্রেমওয়ার্ক ব্যবহার করে। এই ফ্রেমওয়ার্কগুলি সমর্থিত ডিভাইসগুলিতে হার্ডওয়্যার-অ্যাক্সিলারেটেড ইনফারেন্স অপারেশন সম্পাদন করতে NNAPI ব্যবহার করতে পারে।
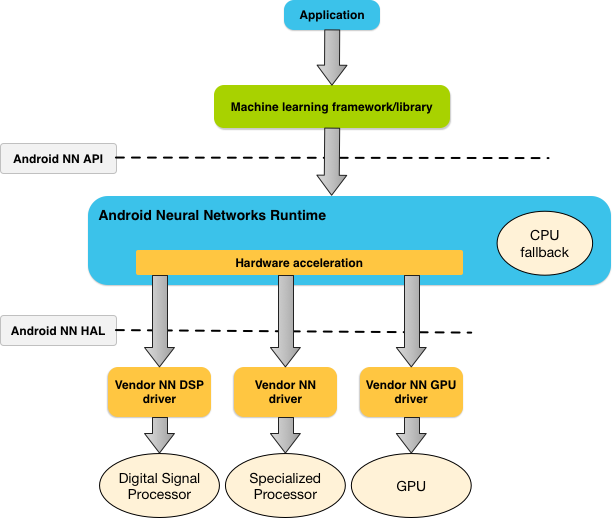
একটি অ্যাপের প্রয়োজনীয়তা এবং একটি অ্যান্ড্রয়েড ডিভাইসের হার্ডওয়্যার ক্ষমতার উপর ভিত্তি করে, অ্যান্ড্রয়েডের নিউরাল নেটওয়ার্ক রানটাইম ডেডিকেটেড নিউরাল নেটওয়ার্ক হার্ডওয়্যার, গ্রাফিক্স প্রসেসিং ইউনিট (GPU) এবং ডিজিটাল সিগন্যাল প্রসেসর (DSP) সহ উপলব্ধ অন-ডিভাইস প্রসেসরগুলিতে গণনার কাজের চাপ দক্ষতার সাথে বিতরণ করতে পারে।
যেসব অ্যান্ড্রয়েড ডিভাইসে বিশেষায়িত বিক্রেতা ড্রাইভার নেই, তাদের জন্য NNAPI রানটাইম CPU-তে অনুরোধগুলি কার্যকর করে।
চিত্র ১-এ NNAPI-এর উচ্চ-স্তরের সিস্টেম আর্কিটেকচার দেখানো হয়েছে।
নিউরাল নেটওয়ার্ক API প্রোগ্রামিং মডেল
NNAPI ব্যবহার করে গণনা সম্পাদন করার জন্য, আপনাকে প্রথমে একটি নির্দেশিত গ্রাফ তৈরি করতে হবে যা সম্পাদনের জন্য গণনাগুলি সংজ্ঞায়িত করে। এই গণনা গ্রাফ, আপনার ইনপুট ডেটার সাথে মিলিত হয়ে (উদাহরণস্বরূপ, একটি মেশিন লার্নিং ফ্রেমওয়ার্ক থেকে প্রেরিত ওজন এবং পক্ষপাত), NNAPI রানটাইম মূল্যায়নের মডেল তৈরি করে।
NNAPI চারটি প্রধান বিমূর্তকরণ ব্যবহার করে:
- মডেল : গাণিতিক ক্রিয়াকলাপ এবং প্রশিক্ষণ প্রক্রিয়ার মাধ্যমে শেখা ধ্রুবক মানগুলির একটি গণনা গ্রাফ। এই ক্রিয়াকলাপগুলি নিউরাল নেটওয়ার্কগুলির জন্য নির্দিষ্ট। এর মধ্যে রয়েছে 2-মাত্রিক (2D) কনভলিউশন , লজিস্টিক ( সিগময়েড ) অ্যাক্টিভেশন, রেক্টিফাইড লিনিয়ার (ReLU) অ্যাক্টিভেশন এবং আরও অনেক কিছু। একটি মডেল তৈরি করা একটি সিঙ্ক্রোনাস অপারেশন। একবার সফলভাবে তৈরি হয়ে গেলে, এটি থ্রেড এবং সংকলনগুলিতে পুনরায় ব্যবহার করা যেতে পারে। NNAPI তে, একটি মডেলকে
ANeuralNetworksModelইনস্ট্যান্স হিসাবে উপস্থাপন করা হয়। - সংকলন : একটি NNAPI মডেলকে নিম্ন-স্তরের কোডে সংকলনের জন্য একটি কনফিগারেশন প্রতিনিধিত্ব করে। একটি সংকলন তৈরি করা একটি সিঙ্ক্রোনাস অপারেশন। একবার সফলভাবে তৈরি হয়ে গেলে, এটি থ্রেড এবং এক্সিকিউশন জুড়ে পুনরায় ব্যবহার করা যেতে পারে। NNAPI তে, প্রতিটি সংকলনকে একটি
ANeuralNetworksCompilationউদাহরণ হিসাবে উপস্থাপন করা হয়। - মেমোরি : শেয়ার্ড মেমোরি, মেমোরি ম্যাপ করা ফাইল এবং অনুরূপ মেমোরি বাফার উপস্থাপন করে। মেমোরি বাফার ব্যবহার করলে NNAPI রানটাইম ড্রাইভারগুলিতে ডেটা আরও দক্ষতার সাথে স্থানান্তর করতে পারে। একটি অ্যাপ সাধারণত একটি শেয়ার্ড মেমোরি বাফার তৈরি করে যাতে একটি মডেল সংজ্ঞায়িত করার জন্য প্রয়োজনীয় প্রতিটি টেনসর থাকে। আপনি একটি এক্সিকিউশন ইনস্ট্যান্সের জন্য ইনপুট এবং আউটপুট সংরক্ষণ করতে মেমোরি বাফারও ব্যবহার করতে পারেন। NNAPI তে, প্রতিটি মেমোরি বাফারকে
ANeuralNetworksMemoryইনস্ট্যান্স হিসাবে উপস্থাপন করা হয়। এক্সিকিউশন : ইনপুটগুলির একটি সেটে একটি NNAPI মডেল প্রয়োগ করার এবং ফলাফল সংগ্রহ করার জন্য ইন্টারফেস। এক্সিকিউশন সিঙ্ক্রোনাস বা অ্যাসিঙ্ক্রোনাসভাবে করা যেতে পারে।
অ্যাসিঙ্ক্রোনাস এক্সিকিউশনের জন্য, একাধিক থ্রেড একই এক্সিকিউশনের জন্য অপেক্ষা করতে পারে। এই এক্সিকিউশনটি সম্পন্ন হলে, সমস্ত থ্রেড মুক্তি পায়।
NNAPI তে, প্রতিটি এক্সিকিউশনকে একটি
ANeuralNetworksExecutionইনস্ট্যান্স হিসেবে উপস্থাপন করা হয়।
চিত্র ২ মৌলিক প্রোগ্রামিং প্রবাহ দেখায়।

এই বিভাগের বাকি অংশে গণনা সম্পাদন, মডেল কম্পাইল এবং কম্পাইল করা মডেল কার্যকর করার জন্য আপনার NNAPI মডেল সেট আপ করার ধাপগুলি বর্ণনা করা হয়েছে।
প্রশিক্ষণের তথ্যে অ্যাক্সেস প্রদান করুন
আপনার প্রশিক্ষিত ওজন এবং পক্ষপাতের ডেটা সম্ভবত একটি ফাইলে সংরক্ষণ করা হয়েছে। NNAPI রানটাইমকে এই ডেটাতে দক্ষ অ্যাক্সেস প্রদান করতে, ANeuralNetworksMemory_createFromFd() ফাংশনটি কল করে এবং খোলা ডেটা ফাইলের ফাইল বর্ণনাকারীতে পাস করে একটি ANeuralNetworksMemory ইনস্ট্যান্স তৈরি করুন। আপনি মেমোরি সুরক্ষা ফ্ল্যাগ এবং একটি অফসেটও নির্দিষ্ট করেন যেখানে ফাইলটিতে ভাগ করা মেমোরি অঞ্চল শুরু হয়।
// Create a memory buffer from the file that contains the trained data
ANeuralNetworksMemory* mem1 = NULL;
int fd = open("training_data", O_RDONLY);
ANeuralNetworksMemory_createFromFd(file_size, PROT_READ, fd, 0, &mem1);
যদিও এই উদাহরণে আমরা আমাদের সমস্ত ওজনের জন্য শুধুমাত্র একটি ANeuralNetworksMemory ইনস্ট্যান্স ব্যবহার করি, একাধিক ফাইলের জন্য একাধিক ANeuralNetworksMemory ইনস্ট্যান্স ব্যবহার করা সম্ভব।
নেটিভ হার্ডওয়্যার বাফার ব্যবহার করুন
মডেল ইনপুট, আউটপুট এবং ধ্রুবক অপারেন্ড মানের জন্য আপনি নেটিভ হার্ডওয়্যার বাফার ব্যবহার করতে পারেন। কিছু ক্ষেত্রে, একটি NNAPI অ্যাক্সিলারেটর ড্রাইভারকে ডেটা কপি না করেই AHardwareBuffer অবজেক্ট অ্যাক্সেস করতে পারে। AHardwareBuffer এর অনেকগুলি ভিন্ন কনফিগারেশন রয়েছে এবং প্রতিটি NNAPI অ্যাক্সিলারেটর এই সমস্ত কনফিগারেশন সমর্থন করতে পারে না। এই সীমাবদ্ধতার কারণে, ANeuralNetworksMemory_createFromAHardwareBuffer রেফারেন্স ডকুমেন্টেশনে তালিকাভুক্ত সীমাবদ্ধতাগুলি দেখুন এবং লক্ষ্য ডিভাইসগুলিতে আগে থেকে পরীক্ষা করুন যাতে নিশ্চিত করা যায় যে AHardwareBuffer ব্যবহার করে এমন সংকলন এবং সম্পাদনগুলি প্রত্যাশিতভাবে আচরণ করে, অ্যাক্সিলারেটর নির্দিষ্ট করার জন্য ডিভাইস অ্যাসাইনমেন্ট ব্যবহার করে।
NNAPI রানটাইমকে একটি AHardwareBuffer অবজেক্ট অ্যাক্সেস করার অনুমতি দিতে, ANeuralNetworksMemory_createFromAHardwareBuffer ফাংশনটি কল করে এবং AHardwareBuffer অবজেক্টটি পাস করে একটি ANeuralNetworksMemory ইনস্ট্যান্স তৈরি করুন, যেমনটি নিম্নলিখিত কোড নমুনায় দেখানো হয়েছে:
// Configure and create AHardwareBuffer object AHardwareBuffer_Desc desc = ... AHardwareBuffer* ahwb = nullptr; AHardwareBuffer_allocate(&desc, &ahwb); // Create ANeuralNetworksMemory from AHardwareBuffer ANeuralNetworksMemory* mem2 = NULL; ANeuralNetworksMemory_createFromAHardwareBuffer(ahwb, &mem2);
যখন NNAPI-এর আর AHardwareBuffer অবজেক্ট অ্যাক্সেস করার প্রয়োজন না হয়, তখন সংশ্লিষ্ট ANeuralNetworksMemory ইনস্ট্যান্সটি খালি করুন:
ANeuralNetworksMemory_free(mem2);
বিঃদ্রঃ:
- আপনি শুধুমাত্র পুরো বাফারের জন্য
AHardwareBufferব্যবহার করতে পারেন; আপনি এটিARectপ্যারামিটারের সাথে ব্যবহার করতে পারবেন না। - NNAPI রানটাইম বাফারটি ফ্লাশ করবে না। এক্সিকিউশন শিডিউল করার আগে আপনাকে নিশ্চিত করতে হবে যে ইনপুট এবং আউটপুট বাফারগুলি অ্যাক্সেসযোগ্য।
- সিঙ্ক ফেন্স ফাইল বর্ণনাকারীর জন্য কোনও সমর্থন নেই।
- বিক্রেতা-নির্দিষ্ট ফর্ম্যাট এবং ব্যবহারের বিট সহ একটি
AHardwareBufferজন্য, ক্যাশে ফ্লাশ করার জন্য ক্লায়েন্ট নাকি ড্রাইভার দায়ী তা নির্ধারণ করা বিক্রেতা বাস্তবায়নের উপর নির্ভর করে।
মডেল
NNAPI-তে গণনার মৌলিক একক হল একটি মডেল। প্রতিটি মডেল এক বা একাধিক অপারেন্ড এবং ক্রিয়াকলাপ দ্বারা সংজ্ঞায়িত করা হয়।
অপারেন্ডস
অপারেন্ড হল গ্রাফ সংজ্ঞায়িত করার জন্য ব্যবহৃত ডেটা অবজেক্ট। এর মধ্যে রয়েছে মডেলের ইনপুট এবং আউটপুট, এক অপারেশন থেকে অন্য অপারেশনে প্রবাহিত ডেটা ধারণকারী মধ্যবর্তী নোড এবং এই অপারেশনগুলিতে প্রেরিত ধ্রুবক।
NNAPI মডেলগুলিতে দুই ধরণের অপারেন্ড যোগ করা যেতে পারে: স্কেলার এবং টেনসর ।
একটি স্কেলার একটি একক মান প্রতিনিধিত্ব করে। NNAPI বুলিয়ান, 16-বিট ফ্লোটিং পয়েন্ট, 32-বিট ফ্লোটিং পয়েন্ট, 32-বিট পূর্ণসংখ্যা এবং স্বাক্ষরবিহীন 32-বিট পূর্ণসংখ্যা বিন্যাসে স্কেলার মান সমর্থন করে।
NNAPI-তে বেশিরভাগ অপারেশনে টেনসর ব্যবহার করা হয়। টেনসর হল n-মাত্রিক অ্যারে। NNAPI ১৬-বিট ফ্লোটিং পয়েন্ট, ৩২-বিট ফ্লোটিং পয়েন্ট, ৮-বিট কোয়ান্টাইজড , ১৬-বিট কোয়ান্টাইজড, ৩২-বিট পূর্ণসংখ্যা এবং ৮-বিট বুলিয়ান মান সহ টেনসর সমর্থন করে।
উদাহরণস্বরূপ, চিত্র ৩ দুটি ক্রিয়াকলাপ সহ একটি মডেলকে উপস্থাপন করে: একটি যোগের পরে একটি গুণ। মডেলটি একটি ইনপুট টেনসর নেয় এবং একটি আউটপুট টেনসর তৈরি করে।
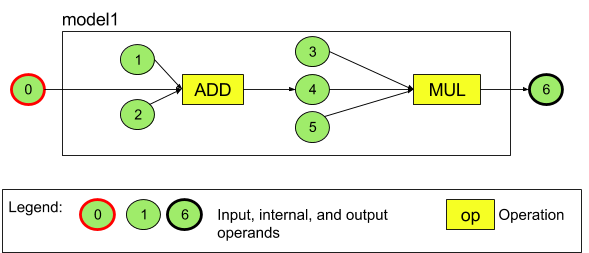
উপরের মডেলটিতে সাতটি অপারেন্ড রয়েছে। এই অপারেন্ডগুলি মডেলে যে ক্রম অনুসারে যোগ করা হয়েছে তার সূচক দ্বারা পরোক্ষভাবে চিহ্নিত করা হয়। যোগ করা প্রথম অপারেন্ডের সূচক 0, দ্বিতীয়টির সূচক 1, ইত্যাদি। অপারেন্ড 1, 2, 3 এবং 5 হল ধ্রুবক অপারেন্ড।
আপনি কোন ক্রমে অপারেন্ড যোগ করবেন তা গুরুত্বপূর্ণ নয়। উদাহরণস্বরূপ, মডেল আউটপুট অপারেন্ডটি প্রথম যোগ করা হতে পারে। গুরুত্বপূর্ণ অংশ হল একটি অপারেন্ড উল্লেখ করার সময় সঠিক সূচক মান ব্যবহার করা।
অপারেন্ডের প্রকারভেদ আছে। মডেলে যোগ করার সময় এগুলো নির্দিষ্ট করা হয়।
একটি অপারেন্ড একটি মডেলের ইনপুট এবং আউটপুট উভয় হিসেবে ব্যবহার করা যাবে না।
প্রতিটি অপারেন্ড অবশ্যই একটি মডেল ইনপুট, একটি ধ্রুবক, অথবা ঠিক একটি অপারেশনের আউটপুট অপারেন্ড হতে হবে।
অপারেন্ড ব্যবহার সম্পর্কে আরও তথ্যের জন্য, অপারেন্ড সম্পর্কে আরও দেখুন।
অপারেশনস
একটি অপারেশন কোন কোন গণনা সম্পাদন করতে হবে তা নির্দিষ্ট করে। প্রতিটি অপারেশনে নিম্নলিখিত উপাদানগুলি থাকে:
- একটি অপারেশন টাইপ (উদাহরণস্বরূপ, যোগ, গুণ, রূপান্তর),
- ইনপুটের জন্য অপারেশনটি যে অপারেন্ডগুলি ব্যবহার করে তার সূচকের একটি তালিকা, এবং
- আউটপুটের জন্য অপারেশনটি যে অপারেন্ডগুলি ব্যবহার করে তার সূচকের একটি তালিকা।
এই তালিকাগুলির ক্রম গুরুত্বপূর্ণ; প্রতিটি অপারেশন ধরণের প্রত্যাশিত ইনপুট এবং আউটপুটের জন্য NNAPI API রেফারেন্স দেখুন।
অপারেশন যোগ করার আগে আপনাকে মডেলে একটি অপারেশন যে অপারেন্ড ব্যবহার করে বা উৎপন্ন করে তা যোগ করতে হবে।
আপনি কোন ক্রমে অপারেশন যোগ করবেন তা গুরুত্বপূর্ণ নয়। NNAPI অপারেন্ড এবং অপারেশনের গণনা গ্রাফ দ্বারা প্রতিষ্ঠিত নির্ভরতার উপর নির্ভর করে কোন ক্রমানুসারে অপারেশন সম্পাদন করা হয় তা নির্ধারণ করে।
NNAPI যে ক্রিয়াকলাপগুলি সমর্থন করে তা নীচের সারণীতে সংক্ষিপ্ত করা হয়েছে:
API লেভেল ২৮-এ জ্ঞাত সমস্যা: ANEURALNETWORKS_TENSOR_QUANT8_ASYMM টেনসরগুলিকে ANEURALNETWORKS_PAD অপারেশনে পাস করার সময়, যা Android 9 (API লেভেল ২৮) এবং উচ্চতর সংস্করণে উপলব্ধ, NNAPI থেকে আউটপুট উচ্চ-স্তরের মেশিন লার্নিং ফ্রেমওয়ার্ক, যেমন TensorFlow Lite থেকে আউটপুটের সাথে মেলে নাও হতে পারে। পরিবর্তে আপনার কেবল ANEURALNETWORKS_TENSOR_FLOAT32 পাস করা উচিত। Android 10 (API লেভেল ২৯) এবং উচ্চতর সংস্করণে সমস্যাটি সমাধান করা হয়েছে।
মডেল তৈরি করুন
নিম্নলিখিত উদাহরণে, আমরা চিত্র 3- এ পাওয়া দুই-অপারেশন মডেল তৈরি করি।
মডেলটি তৈরি করতে, এই পদক্ষেপগুলি অনুসরণ করুন:
একটি খালি মডেল সংজ্ঞায়িত করতে
ANeuralNetworksModel_create()ফাংশনটি কল করুন।ANeuralNetworksModel* model = NULL; ANeuralNetworksModel_create(&model);
ANeuralNetworks_addOperand()কল করে আপনার মডেলে অপারেন্ডগুলি যোগ করুন। তাদের ডেটা টাইপগুলিANeuralNetworksOperandTypeডেটা স্ট্রাকচার ব্যবহার করে সংজ্ঞায়িত করা হয়।// In our example, all our tensors are matrices of dimension [3][4] ANeuralNetworksOperandType tensor3x4Type; tensor3x4Type.type = ANEURALNETWORKS_TENSOR_FLOAT32; tensor3x4Type.scale = 0.f; // These fields are used for quantized tensors tensor3x4Type.zeroPoint = 0; // These fields are used for quantized tensors tensor3x4Type.dimensionCount = 2; uint32_t dims[2] = {3, 4}; tensor3x4Type.dimensions = dims;
// We also specify operands that are activation function specifiers ANeuralNetworksOperandType activationType; activationType.type = ANEURALNETWORKS_INT32; activationType.scale = 0.f; activationType.zeroPoint = 0; activationType.dimensionCount = 0; activationType.dimensions = NULL;
// Now we add the seven operands, in the same order defined in the diagram ANeuralNetworksModel_addOperand(model, &tensor3x4Type); // operand 0 ANeuralNetworksModel_addOperand(model, &tensor3x4Type); // operand 1 ANeuralNetworksModel_addOperand(model, &activationType); // operand 2 ANeuralNetworksModel_addOperand(model, &tensor3x4Type); // operand 3 ANeuralNetworksModel_addOperand(model, &tensor3x4Type); // operand 4 ANeuralNetworksModel_addOperand(model, &activationType); // operand 5 ANeuralNetworksModel_addOperand(model, &tensor3x4Type); // operand 6যেসব অপারেন্ডের মান ধ্রুবক, যেমন ওজন এবং পক্ষপাত যা আপনার অ্যাপ প্রশিক্ষণ প্রক্রিয়া থেকে পায়, তাদের জন্য
ANeuralNetworksModel_setOperandValue()এবংANeuralNetworksModel_setOperandValueFromMemory()ফাংশন ব্যবহার করুন।নিম্নলিখিত উদাহরণে, আমরা প্রশিক্ষণ ডেটাতে অ্যাক্সেস প্রদানে তৈরি মেমরি বাফারের সাথে সম্পর্কিত প্রশিক্ষণ ডেটা ফাইল থেকে ধ্রুবক মান সেট করি।
// In our example, operands 1 and 3 are constant tensors whose values were // established during the training process const int sizeOfTensor = 3 * 4 * 4; // The formula for size calculation is dim0 * dim1 * elementSize ANeuralNetworksModel_setOperandValueFromMemory(model, 1, mem1, 0, sizeOfTensor); ANeuralNetworksModel_setOperandValueFromMemory(model, 3, mem1, sizeOfTensor, sizeOfTensor);
// We set the values of the activation operands, in our example operands 2 and 5 int32_t noneValue = ANEURALNETWORKS_FUSED_NONE; ANeuralNetworksModel_setOperandValue(model, 2, &noneValue, sizeof(noneValue)); ANeuralNetworksModel_setOperandValue(model, 5, &noneValue, sizeof(noneValue));আপনি যে নির্দেশিত গ্রাফটি গণনা করতে চান তার প্রতিটি অপারেশনের জন্য,
ANeuralNetworksModel_addOperation()ফাংশনটি কল করে আপনার মডেলে অপারেশনটি যোগ করুন।এই কলের প্যারামিটার হিসেবে, আপনার অ্যাপে অবশ্যই নিম্নলিখিতগুলি প্রদান করতে হবে:
- অপারেশনের ধরণ
- ইনপুট মানের গণনা
- ইনপুট অপারেন্ডের জন্য সূচকের অ্যারে
- আউটপুট মানের গণনা
- আউটপুট অপারেন্ডের জন্য সূচকের অ্যারে
মনে রাখবেন যে একটি অপারেন্ড একই অপারেশনের ইনপুট এবং আউটপুট উভয়ের জন্য ব্যবহার করা যাবে না।
// We have two operations in our example // The first consumes operands 1, 0, 2, and produces operand 4 uint32_t addInputIndexes[3] = {1, 0, 2}; uint32_t addOutputIndexes[1] = {4}; ANeuralNetworksModel_addOperation(model, ANEURALNETWORKS_ADD, 3, addInputIndexes, 1, addOutputIndexes);
// The second consumes operands 3, 4, 5, and produces operand 6 uint32_t multInputIndexes[3] = {3, 4, 5}; uint32_t multOutputIndexes[1] = {6}; ANeuralNetworksModel_addOperation(model, ANEURALNETWORKS_MUL, 3, multInputIndexes, 1, multOutputIndexes);ANeuralNetworksModel_identifyInputsAndOutputs()ফাংশনটি কল করে মডেলটি কোন অপারেন্ডগুলিকে তার ইনপুট এবং আউটপুট হিসাবে বিবেচনা করবে তা সনাক্ত করুন।// Our model has one input (0) and one output (6) uint32_t modelInputIndexes[1] = {0}; uint32_t modelOutputIndexes[1] = {6}; ANeuralNetworksModel_identifyInputsAndOutputs(model, 1, modelInputIndexes, 1 modelOutputIndexes);
ঐচ্ছিকভাবে,
ANEURALNETWORKS_TENSOR_FLOAT32IEEE 754 16-বিট ফ্লোটিং-পয়েন্ট ফর্ম্যাটের মতো কম পরিসর বা নির্ভুলতার সাথে গণনা করার অনুমতি আছে কিনা তাANeuralNetworksModel_relaxComputationFloat32toFloat16()কল করে নির্দিষ্ট করুন।আপনার মডেলের সংজ্ঞা চূড়ান্ত করতে
ANeuralNetworksModel_finish()কল করুন। যদি কোনও ত্রুটি না থাকে, তাহলে এই ফাংশনটিANEURALNETWORKS_NO_ERRORএর একটি ফলাফল কোড প্রদান করে।ANeuralNetworksModel_finish(model);
একবার আপনি একটি মডেল তৈরি করলে, আপনি এটিকে যতবার কম্পাইল করতে পারবেন এবং প্রতিটি কম্পাইলেশন যতবার সম্পাদন করতে পারবেন।
নিয়ন্ত্রণ প্রবাহ
একটি NNAPI মডেলে নিয়ন্ত্রণ প্রবাহ অন্তর্ভুক্ত করতে, নিম্নলিখিতগুলি করুন:
সংশ্লিষ্ট এক্সিকিউশন সাবগ্রাফগুলি (একটি
IFস্টেটমেন্টের জন্যthenএবংelseসাবগ্রাফ, একটিWHILEলুপের জন্যconditionএবংbodyসাবগ্রাফ) স্বতন্ত্রANeuralNetworksModel*মডেল হিসাবে তৈরি করুন:ANeuralNetworksModel* thenModel = makeThenModel(); ANeuralNetworksModel* elseModel = makeElseModel();
নিয়ন্ত্রণ প্রবাহ ধারণকারী মডেলের মধ্যে সেই মডেলগুলিকে উল্লেখ করে এমন অপারেন্ড তৈরি করুন:
ANeuralNetworksOperandType modelType = { .type = ANEURALNETWORKS_MODEL, }; ANeuralNetworksModel_addOperand(model, &modelType); // kThenOperandIndex ANeuralNetworksModel_addOperand(model, &modelType); // kElseOperandIndex ANeuralNetworksModel_setOperandValueFromModel(model, kThenOperandIndex, &thenModel); ANeuralNetworksModel_setOperandValueFromModel(model, kElseOperandIndex, &elseModel);
নিয়ন্ত্রণ প্রবাহ অপারেশন যোগ করুন:
uint32_t inputs[] = {kConditionOperandIndex, kThenOperandIndex, kElseOperandIndex, kInput1, kInput2, kInput3}; uint32_t outputs[] = {kOutput1, kOutput2}; ANeuralNetworksModel_addOperation(model, ANEURALNETWORKS_IF, std::size(inputs), inputs, std::size(output), outputs);
সংকলন
সংকলন ধাপটি নির্ধারণ করে যে আপনার মডেলটি কোন প্রসেসরে কার্যকর করা হবে এবং সংশ্লিষ্ট ড্রাইভারদের এটি কার্যকর করার জন্য প্রস্তুত হতে বলে। এর মধ্যে আপনার মডেলটি যে প্রসেসরে চলবে তার জন্য নির্দিষ্ট মেশিন কোড তৈরি করা অন্তর্ভুক্ত থাকতে পারে।
একটি মডেল কম্পাইল করতে, এই পদক্ষেপগুলি অনুসরণ করুন:
একটি নতুন কম্পাইলেশন ইনস্ট্যান্স তৈরি করতে
ANeuralNetworksCompilation_create()ফাংশনটি কল করুন।// Compile the model ANeuralNetworksCompilation* compilation; ANeuralNetworksCompilation_create(model, &compilation);
ঐচ্ছিকভাবে, আপনি ডিভাইস অ্যাসাইনমেন্ট ব্যবহার করে কোন ডিভাইসগুলিতে কাজ চালানো হবে তা স্পষ্টভাবে বেছে নিতে পারেন।
ব্যাটারি পাওয়ার ব্যবহার এবং এক্সিকিউশন গতির মধ্যে রানটাইম কীভাবে লেনদেন হয় তা আপনি ঐচ্ছিকভাবে প্রভাবিত করতে পারেন। আপনি
ANeuralNetworksCompilation_setPreference()কল করে এটি করতে পারেন।// Ask to optimize for low power consumption ANeuralNetworksCompilation_setPreference(compilation, ANEURALNETWORKS_PREFER_LOW_POWER);
আপনি যে পছন্দগুলি নির্দিষ্ট করতে পারেন তার মধ্যে রয়েছে:
-
ANEURALNETWORKS_PREFER_LOW_POWER: এমনভাবে সম্পাদনা করা পছন্দ করুন যাতে ব্যাটারির খরচ কম হয়। ঘন ঘন সম্পাদনা করা কম্পাইলেশনের জন্য এটি বাঞ্ছনীয়। -
ANEURALNETWORKS_PREFER_FAST_SINGLE_ANSWER: যত দ্রুত সম্ভব একটি উত্তর ফেরত দেওয়া পছন্দ করুন, এমনকি যদি এর ফলে বেশি বিদ্যুৎ খরচ হয়। এটি ডিফল্ট। -
ANEURALNETWORKS_PREFER_SUSTAINED_SPEED: ধারাবাহিক ফ্রেমের থ্রুপুট সর্বাধিক করতে পছন্দ করুন, যেমন ক্যামেরা থেকে আসা ধারাবাহিক ফ্রেম প্রক্রিয়াকরণের সময়।
-
আপনি ঐচ্ছিকভাবে
ANeuralNetworksCompilation_setCachingকল করে কম্পাইলেশন ক্যাশিং সেট আপ করতে পারেন।// Set up compilation caching ANeuralNetworksCompilation_setCaching(compilation, cacheDir, token);
cacheDirএর জন্যgetCodeCacheDir()ব্যবহার করুন। নির্দিষ্টtokenঅ্যাপ্লিকেশনের মধ্যে প্রতিটি মডেলের জন্য অনন্য হতে হবে।ANeuralNetworksCompilation_finish()কল করে সংকলন সংজ্ঞা চূড়ান্ত করুন। যদি কোনও ত্রুটি না থাকে, তাহলে এই ফাংশনটিANEURALNETWORKS_NO_ERRORএর একটি ফলাফল কোড প্রদান করে।ANeuralNetworksCompilation_finish(compilation);
ডিভাইস আবিষ্কার এবং অ্যাসাইনমেন্ট
অ্যান্ড্রয়েড ১০ (এপিআই লেভেল ২৯) এবং উচ্চতর ভার্সন চালিত অ্যান্ড্রয়েড ডিভাইসগুলিতে, NNAPI এমন ফাংশন প্রদান করে যা মেশিন লার্নিং ফ্রেমওয়ার্ক লাইব্রেরি এবং অ্যাপগুলিকে উপলব্ধ ডিভাইসগুলি সম্পর্কে তথ্য পেতে এবং কার্যকর করার জন্য ব্যবহৃত ডিভাইসগুলি নির্দিষ্ট করতে দেয়। উপলব্ধ ডিভাইসগুলি সম্পর্কে তথ্য প্রদানের ফলে অ্যাপগুলি পরিচিত অসঙ্গতিগুলি এড়াতে ডিভাইসে পাওয়া ড্রাইভারগুলির সঠিক সংস্করণ পেতে পারে। অ্যাপগুলিকে একটি মডেলের বিভিন্ন বিভাগ কার্যকর করার জন্য কোন ডিভাইসগুলি নির্দিষ্ট করার ক্ষমতা প্রদান করে, অ্যাপগুলিকে যে অ্যান্ড্রয়েড ডিভাইসে স্থাপন করা হয়েছে তার জন্য অপ্টিমাইজ করা যেতে পারে।
ডিভাইস আবিষ্কার
উপলব্ধ ডিভাইসের সংখ্যা পেতে ANeuralNetworks_getDeviceCount ব্যবহার করুন। প্রতিটি ডিভাইসের জন্য, ANeuralNetworks_getDevice ব্যবহার করে সেই ডিভাইসের একটি রেফারেন্সে একটি ANeuralNetworksDevice ইনস্ট্যান্স সেট করুন।
একবার আপনার কাছে একটি ডিভাইসের রেফারেন্স হয়ে গেলে, আপনি নিম্নলিখিত ফাংশনগুলি ব্যবহার করে সেই ডিভাইস সম্পর্কে অতিরিক্ত তথ্য জানতে পারবেন:
-
ANeuralNetworksDevice_getFeatureLevel -
ANeuralNetworksDevice_getName -
ANeuralNetworksDevice_getType -
ANeuralNetworksDevice_getVersion
ডিভাইস অ্যাসাইনমেন্ট
নির্দিষ্ট ডিভাইসে কোন মডেলের কোন ক্রিয়াকলাপ চালানো যেতে পারে তা আবিষ্কার করতে ANeuralNetworksModel_getSupportedOperationsForDevices ব্যবহার করুন।
কোন অ্যাক্সিলারেটর ব্যবহার করে এক্সিকিউশন করা হবে তা নিয়ন্ত্রণ করতে, ANeuralNetworksCompilation_createForDevices কল করুন, ANeuralNetworksCompilation_create এর পরিবর্তে। স্বাভাবিকভাবে ANeuralNetworksCompilation অবজেক্টটি ব্যবহার করুন। যদি প্রদত্ত মডেলটিতে এমন ক্রিয়াকলাপ থাকে যা নির্বাচিত ডিভাইস দ্বারা সমর্থিত নয় তবে ফাংশনটি একটি ত্রুটি ফেরত দেয়।
যদি একাধিক ডিভাইস নির্দিষ্ট করা থাকে, তাহলে রানটাইম ডিভাইস জুড়ে কাজ বিতরণের জন্য দায়ী।
অন্যান্য ডিভাইসের মতো, NNAPI CPU বাস্তবায়নটি nnapi-reference নাম এবং ANEURALNETWORKS_DEVICE_TYPE_CPU টাইপের একটি ANeuralNetworksDevice দ্বারা প্রতিনিধিত্ব করা হয়। ANeuralNetworksCompilation_createForDevices কল করার সময়, মডেল সংকলন এবং সম্পাদনের জন্য ব্যর্থতার ক্ষেত্রে CPU বাস্তবায়ন ব্যবহার করা হয় না।
একটি মডেলকে নির্দিষ্ট ডিভাইসে চালানোর জন্য উপ-মডেলগুলিতে ভাগ করা একটি অ্যাপ্লিকেশনের দায়িত্ব। যেসব অ্যাপ্লিকেশনকে ম্যানুয়াল পার্টিশন করার প্রয়োজন হয় না তাদের মডেলটিকে ত্বরান্বিত করার জন্য সমস্ত উপলব্ধ ডিভাইস (CPU সহ) ব্যবহার করার জন্য সহজ ANeuralNetworksCompilation_create কল করা চালিয়ে যাওয়া উচিত। যদি ANeuralNetworksCompilation_createForDevices ব্যবহার করে আপনার নির্দিষ্ট ডিভাইসগুলি দ্বারা মডেলটি সম্পূর্ণরূপে সমর্থিত না হতে পারে, তাহলে ANEURALNETWORKS_BAD_DATA ফেরত পাঠানো হবে।
মডেল পার্টিশনিং
যখন মডেলের জন্য একাধিক ডিভাইস উপলব্ধ থাকে, তখন NNAPI রানটাইম ডিভাইসগুলিতে কাজ বিতরণ করে। উদাহরণস্বরূপ, যদি ANeuralNetworksCompilation_createForDevices কে একাধিক ডিভাইস সরবরাহ করা হয়, তাহলে কাজ বরাদ্দ করার সময় নির্দিষ্ট সমস্ত ডিভাইস বিবেচনা করা হবে। মনে রাখবেন, যদি CPU ডিভাইসটি তালিকায় না থাকে, তাহলে CPU এক্সিকিউশন অক্ষম করা হবে। ANeuralNetworksCompilation_create ব্যবহার করার সময় CPU সহ সমস্ত উপলব্ধ ডিভাইস বিবেচনা করা হবে।
মডেলের প্রতিটি অপারেশনের জন্য উপলব্ধ ডিভাইসের তালিকা থেকে, অপারেশন সমর্থনকারী ডিভাইস নির্বাচন করে এবং সর্বোত্তম কর্মক্ষমতা ঘোষণা করে বিতরণ করা হয়, অর্থাৎ ক্লায়েন্ট দ্বারা নির্দিষ্ট এক্সিকিউশন পছন্দের উপর নির্ভর করে দ্রুততম এক্সিকিউশন সময় বা সর্বনিম্ন পাওয়ার খরচ। এই পার্টিশনিং অ্যালগরিদম বিভিন্ন প্রসেসরের মধ্যে IO দ্বারা সৃষ্ট সম্ভাব্য অদক্ষতার জন্য হিসাব করে না, তাই, একাধিক প্রসেসর নির্দিষ্ট করার সময় ( ANeuralNetworksCompilation_createForDevices ব্যবহার করার সময় স্পষ্টভাবে অথবা ANeuralNetworksCompilation_create ব্যবহার করে স্পষ্টভাবে) ফলাফল প্রাপ্ত অ্যাপ্লিকেশনটির প্রোফাইল তৈরি করা গুরুত্বপূর্ণ।
NNAPI দ্বারা আপনার মডেলটি কীভাবে পার্টিশন করা হয়েছে তা বুঝতে, একটি বার্তার জন্য অ্যান্ড্রয়েড লগগুলি পরীক্ষা করুন (INFO স্তরে ExecutionPlan ট্যাগ সহ):
ModelBuilder::findBestDeviceForEachOperation(op-name): device-index
গ্রাফে অপারেশনের বর্ণনামূলক নাম হল op-name এবং device-index হল ডিভাইসের তালিকার ক্যান্ডিডেট ডিভাইসের সূচক। এই তালিকাটি হল ANeuralNetworksCompilation_createForDevices এ প্রদত্ত ইনপুট অথবা, যদি ANeuralNetworksCompilation_createForDevices ব্যবহার করা হয়, তাহলে ANeuralNetworks_getDeviceCount এবং ANeuralNetworks_getDevice ব্যবহার করে সমস্ত ডিভাইসে পুনরাবৃত্তি করার সময় ফিরে আসা ডিভাইসের তালিকা।
বার্তাটি (INFO স্তরে ExecutionPlan ট্যাগ সহ):
ModelBuilder::partitionTheWork: only one best device: device-name
এই বার্তাটি নির্দেশ করে যে পুরো গ্রাফটি ডিভাইস device-name ত্বরান্বিত হয়েছে।
মৃত্যুদন্ড
এক্সিকিউশন ধাপটি মডেলটিকে ইনপুটগুলির একটি সেটে প্রয়োগ করে এবং গণনার আউটপুটগুলিকে আপনার অ্যাপ দ্বারা বরাদ্দ করা এক বা একাধিক ব্যবহারকারী বাফার বা মেমরি স্পেসে সংরক্ষণ করে।
একটি কম্পাইল করা মডেল কার্যকর করতে, এই পদক্ষেপগুলি অনুসরণ করুন:
একটি নতুন এক্সিকিউশন ইনস্ট্যান্স তৈরি করতে
ANeuralNetworksExecution_create()ফাংশনটি কল করুন।// Run the compiled model against a set of inputs ANeuralNetworksExecution* run1 = NULL; ANeuralNetworksExecution_create(compilation, &run1);
আপনার অ্যাপটি গণনার জন্য ইনপুট মানগুলি কোথায় পড়বে তা নির্দিষ্ট করুন। আপনার অ্যাপটি যথাক্রমে
ANeuralNetworksExecution_setInput()অথবাANeuralNetworksExecution_setInputFromMemory()কল করে ব্যবহারকারীর বাফার অথবা বরাদ্দকৃত মেমোরি স্পেস থেকে ইনপুট মানগুলি পড়তে পারে।// Set the single input to our sample model. Since it is small, we won't use a memory buffer float32 myInput[3][4] = { ...the data... }; ANeuralNetworksExecution_setInput(run1, 0, NULL, myInput, sizeof(myInput));
আপনার অ্যাপটি আউটপুট মান কোথায় লিখবে তা নির্দিষ্ট করুন। আপনার অ্যাপটি যথাক্রমে
ANeuralNetworksExecution_setOutput()অথবাANeuralNetworksExecution_setOutputFromMemory()কল করে ব্যবহারকারীর বাফারে অথবা বরাদ্দকৃত মেমোরি স্পেসে আউটপুট মান লিখতে পারে।// Set the output float32 myOutput[3][4]; ANeuralNetworksExecution_setOutput(run1, 0, NULL, myOutput, sizeof(myOutput));
ANeuralNetworksExecution_startCompute()ফাংশনটি কল করে এক্সিকিউশন শুরু করার সময় নির্ধারণ করুন। যদি কোনও ত্রুটি না থাকে, তাহলে এই ফাংশনটিANEURALNETWORKS_NO_ERRORএর একটি ফলাফল কোড প্রদান করে।// Starts the work. The work proceeds asynchronously ANeuralNetworksEvent* run1_end = NULL; ANeuralNetworksExecution_startCompute(run1, &run1_end);
এক্সিকিউশন সম্পূর্ণ হওয়ার জন্য অপেক্ষা করার জন্য
ANeuralNetworksEvent_wait()ফাংশনটি কল করুন। যদি এক্সিকিউশন সফল হয়, তাহলে এই ফাংশনটিANEURALNETWORKS_NO_ERRORএর একটি ফলাফল কোড প্রদান করে। এক্সিকিউশন শুরু করার থ্রেডের চেয়ে ভিন্ন থ্রেডে অপেক্ষা করা যেতে পারে।// For our example, we have no other work to do and will just wait for the completion ANeuralNetworksEvent_wait(run1_end); ANeuralNetworksEvent_free(run1_end); ANeuralNetworksExecution_free(run1);
ঐচ্ছিকভাবে, আপনি একই কম্পাইলেশন ইনস্ট্যান্স ব্যবহার করে একটি নতুন
ANeuralNetworksExecutionইনস্ট্যান্স তৈরি করে কম্পাইল করা মডেলে ভিন্ন ইনপুট প্রয়োগ করতে পারেন।// Apply the compiled model to a different set of inputs ANeuralNetworksExecution* run2; ANeuralNetworksExecution_create(compilation, &run2); ANeuralNetworksExecution_setInput(run2, ...); ANeuralNetworksExecution_setOutput(run2, ...); ANeuralNetworksEvent* run2_end = NULL; ANeuralNetworksExecution_startCompute(run2, &run2_end); ANeuralNetworksEvent_wait(run2_end); ANeuralNetworksEvent_free(run2_end); ANeuralNetworksExecution_free(run2);
সিঙ্ক্রোনাস এক্সিকিউশন
অ্যাসিঙ্ক্রোনাস এক্সিকিউশন থ্রেড তৈরি এবং সিঙ্ক্রোনাইজ করতে সময় ব্যয় করে। তদুপরি, ল্যাটেন্সি অত্যন্ত পরিবর্তনশীল হতে পারে, একটি থ্রেডকে বিজ্ঞপ্তি বা জাগ্রত করার সময় থেকে শেষ পর্যন্ত এটি একটি CPU কোরের সাথে আবদ্ধ হওয়ার সময় পর্যন্ত দীর্ঘতম বিলম্ব 500 মাইক্রোসেকেন্ড পর্যন্ত পৌঁছায়।
ল্যাটেন্সি উন্নত করার জন্য, আপনি একটি অ্যাপ্লিকেশনকে রানটাইমে একটি সিঙ্ক্রোনাস ইনফারেন্স কল করার জন্য নির্দেশ করতে পারেন। সেই কলটি শুধুমাত্র একটি ইনফারেন্স সম্পন্ন হওয়ার পরেই ফিরে আসবে, একটি ইনফারেন্স শুরু হওয়ার পরে ফিরে আসবে না। রানটাইমে একটি অ্যাসিঙ্ক্রোনাস ইনফারেন্স কলের জন্য ANeuralNetworksExecution_startCompute কল করার পরিবর্তে, অ্যাপ্লিকেশনটি রানটাইমে একটি সিঙ্ক্রোনাস কল করার জন্য ANeuralNetworksExecution_compute কল করে। ANeuralNetworksExecution_compute এ একটি কল ANeuralNetworksEvent গ্রহণ করে না এবং ANeuralNetworksEvent_wait এ একটি কলের সাথে যুক্ত হয় না।
বার্স্ট মৃত্যুদণ্ড
অ্যান্ড্রয়েড ১০ (এপিআই লেভেল ২৯) এবং তার উচ্চতর ভার্সন চালিত অ্যান্ড্রয়েড ডিভাইসগুলিতে, NNAPI ANeuralNetworksBurst অবজেক্টের মাধ্যমে বার্স্ট এক্সিকিউশন সমর্থন করে। বার্স্ট এক্সিকিউশন হল একই কম্পাইলেশনের এক্সিকিউশনের একটি ক্রম যা দ্রুত ধারাবাহিকভাবে ঘটে, যেমন ক্যামেরা ক্যাপচারের ফ্রেমে বা ধারাবাহিক অডিও নমুনায় কাজ করা। ANeuralNetworksBurst অবজেক্ট ব্যবহার করলে দ্রুত এক্সিকিউশন হতে পারে, কারণ এটি অ্যাক্সিলারেটরদের নির্দেশ করে যে এক্সিকিউশনের মধ্যে রিসোর্সগুলি পুনরায় ব্যবহার করা যেতে পারে এবং অ্যাক্সিলারেটরগুলি বার্স্টের সময়কালের জন্য উচ্চ-কার্যক্ষমতাসম্পন্ন অবস্থায় থাকা উচিত।
ANeuralNetworksBurst সাধারণ এক্সিকিউশন পাথে শুধুমাত্র একটি ছোট পরিবর্তন আনে। আপনি ANeuralNetworksBurst_create ব্যবহার করে একটি burst অবজেক্ট তৈরি করতে পারেন, যেমনটি নিম্নলিখিত কোড স্নিপেটে দেখানো হয়েছে:
// Create burst object to be reused across a sequence of executions ANeuralNetworksBurst* burst = NULL; ANeuralNetworksBurst_create(compilation, &burst);
বার্স্ট এক্সিকিউশনগুলি সিঙ্ক্রোনাস। তবে, প্রতিটি অনুমান সম্পাদনের জন্য ANeuralNetworksExecution_compute ব্যবহার করার পরিবর্তে, আপনি ANeuralNetworksExecution_burstCompute ফাংশনে কল করার সময় বিভিন্ন ANeuralNetworksExecution অবজেক্টগুলিকে একই ANeuralNetworksBurst এর সাথে যুক্ত করেন।
// Create and configure first execution object // ... // Execute using the burst object ANeuralNetworksExecution_burstCompute(execution1, burst); // Use results of first execution and free the execution object // ... // Create and configure second execution object // ... // Execute using the same burst object ANeuralNetworksExecution_burstCompute(execution2, burst); // Use results of second execution and free the execution object // ...
যখন আর প্রয়োজন না থাকে, তখন ANeuralNetworksBurst_free দিয়ে ANeuralNetworksBurst অবজেক্টটি খালি করুন।
// Cleanup ANeuralNetworksBurst_free(burst);
অ্যাসিঙ্ক্রোনাস কমান্ড সারি এবং বেড়াযুক্ত সম্পাদন
অ্যান্ড্রয়েড ১১ এবং তার পরবর্তী সংস্করণে, NNAPI ANeuralNetworksExecution_startComputeWithDependencies() পদ্ধতির মাধ্যমে অ্যাসিঙ্ক্রোনাস এক্সিকিউশন শিডিউল করার একটি অতিরিক্ত উপায় সমর্থন করে। যখন আপনি এই পদ্ধতিটি ব্যবহার করেন, তখন এক্সিকিউশন মূল্যায়ন শুরু করার আগে সমস্ত নির্ভরশীল ইভেন্টের সংকেত পাওয়ার জন্য অপেক্ষা করে। এক্সিকিউশন সম্পন্ন হয়ে গেলে এবং আউটপুটগুলি ব্যবহারের জন্য প্রস্তুত হয়ে গেলে, ফেরত ইভেন্টটি সিগন্যাল করা হয়।
কোন ডিভাইসগুলি এক্সিকিউশন পরিচালনা করে তার উপর নির্ভর করে, ইভেন্টটি একটি সিঙ্ক ফেন্স দ্বারা সমর্থিত হতে পারে। ইভেন্টের জন্য অপেক্ষা করতে এবং এক্সিকিউশনে ব্যবহৃত রিসোর্সগুলি পুনরুদ্ধার করতে আপনাকে ANeuralNetworksEvent_wait() কল করতে হবে। আপনি ANeuralNetworksEvent_createFromSyncFenceFd() ব্যবহার করে একটি ইভেন্ট অবজেক্টে সিঙ্ক ফেন্স আমদানি করতে পারেন, এবং আপনি ANeuralNetworksEvent_getSyncFenceFd() ব্যবহার করে একটি ইভেন্ট অবজেক্ট থেকে সিঙ্ক ফেন্স রপ্তানি করতে পারেন।
গতিশীল আকারের আউটপুট
এমন মডেলগুলিকে সমর্থন করার জন্য যেখানে আউটপুটের আকার ইনপুট ডেটার উপর নির্ভর করে—অর্থাৎ, যেখানে মডেল এক্সিকিউশনের সময় আকার নির্ধারণ করা যায় না— ANeuralNetworksExecution_getOutputOperandRank এবং ANeuralNetworksExecution_getOutputOperandDimensions ব্যবহার করুন।
নিম্নলিখিত কোড নমুনাটি এটি কীভাবে করবেন তা দেখায়:
// Get the rank of the output uint32_t myOutputRank = 0; ANeuralNetworksExecution_getOutputOperandRank(run1, 0, &myOutputRank); // Get the dimensions of the output std::vector<uint32_t> myOutputDimensions(myOutputRank); ANeuralNetworksExecution_getOutputOperandDimensions(run1, 0, myOutputDimensions.data());
পরিষ্কার করা
পরিষ্কারের ধাপটি আপনার গণনার জন্য ব্যবহৃত অভ্যন্তরীণ সম্পদ মুক্ত করার কাজ পরিচালনা করে।
// Cleanup ANeuralNetworksCompilation_free(compilation); ANeuralNetworksModel_free(model); ANeuralNetworksMemory_free(mem1);
ত্রুটি ব্যবস্থাপনা এবং CPU ফলব্যাক
পার্টিশনের সময় যদি কোনও ত্রুটি দেখা দেয়, যদি কোনও ড্রাইভার একটি (a) মডেল কম্পাইল করতে ব্যর্থ হয়, অথবা যদি কোনও ড্রাইভার একটি কম্পাইল করা (a) মডেল কার্যকর করতে ব্যর্থ হয়, তাহলে NNAPI এক বা একাধিক ক্রিয়াকলাপের নিজস্ব CPU বাস্তবায়নে ফিরে যেতে পারে।
যদি NNAPI ক্লায়েন্টে অপারেশনের অপ্টিমাইজড ভার্সন থাকে (যেমন, TFLite), তাহলে CPU ফলব্যাক নিষ্ক্রিয় করা এবং ক্লায়েন্টের অপ্টিমাইজড অপারেশন বাস্তবায়নের মাধ্যমে ব্যর্থতাগুলি পরিচালনা করা সুবিধাজনক হতে পারে।
অ্যান্ড্রয়েড ১০-এ, যদি ANeuralNetworksCompilation_createForDevices ব্যবহার করে সংকলন করা হয়, তাহলে CPU ফলব্যাক অক্ষম করা হবে।
অ্যান্ড্রয়েড পি-তে, ড্রাইভারে এক্সিকিউশন ব্যর্থ হলে NNAPI এক্সিকিউশন CPU-তে ফিরে আসে। এটি অ্যান্ড্রয়েড 10-এর ক্ষেত্রেও সত্য যখন ANeuralNetworksCompilation_create ব্যবহার না করে ANeuralNetworksCompilation_createForDevices ব্যবহার করা হয়।
প্রথম এক্সিকিউশনটি সেই একক পার্টিশনের জন্য পিছিয়ে যায়, এবং যদি তাও ব্যর্থ হয়, তবে এটি CPU-তে পুরো মডেলটি পুনরায় চেষ্টা করে।
যদি পার্টিশন বা সংকলন ব্যর্থ হয়, তাহলে সম্পূর্ণ মডেলটি CPU-তে চেষ্টা করা হবে।
এমন কিছু ক্ষেত্রে আছে যেখানে কিছু অপারেশন CPU তে সমর্থিত নয়, এবং এই ধরনের পরিস্থিতিতে সংকলন বা সম্পাদন পিছিয়ে যাওয়ার পরিবর্তে ব্যর্থ হবে।
CPU ফলব্যাক নিষ্ক্রিয় করার পরেও, CPU-তে নির্ধারিত মডেলে এখনও কিছু অপারেশন থাকতে পারে। যদি CPU ANeuralNetworksCompilation_createForDevices এ সরবরাহ করা প্রসেসরের তালিকায় থাকে, এবং হয় একমাত্র প্রসেসর যা এই অপারেশনগুলিকে সমর্থন করে অথবা সেই প্রসেসর যা এই অপারেশনগুলির জন্য সেরা পারফরম্যান্স দাবি করে, তাহলে এটিকে একটি প্রাথমিক (নন-ফলব্যাক) এক্সিকিউটর হিসেবে বেছে নেওয়া হবে।
CPU এক্সিকিউশন নিশ্চিত করতে, ডিভাইসের তালিকা থেকে nnapi-reference বাদ দিয়ে ANeuralNetworksCompilation_createForDevices ব্যবহার করুন। Android P থেকে শুরু করে, debug.nn.partition প্রোপার্টি 2 তে সেট করে DEBUG বিল্ডে এক্সিকিউশনের সময় ফলব্যাক অক্ষম করা সম্ভব।
মেমোরি ডোমেন
অ্যান্ড্রয়েড ১১ এবং উচ্চতর সংস্করণে, NNAPI মেমোরি ডোমেন সমর্থন করে যা অস্বচ্ছ স্মৃতির জন্য অ্যালোকেটর ইন্টারফেস প্রদান করে। এটি অ্যাপ্লিকেশনগুলিকে এক্সিকিউশন জুড়ে ডিভাইস-নেটিভ স্মৃতি প্রেরণ করতে দেয়, যাতে একই ড্রাইভারে পরপর এক্সিকিউশন করার সময় NNAPI অপ্রয়োজনীয়ভাবে ডেটা কপি বা রূপান্তর না করে।
মেমোরি ডোমেন বৈশিষ্ট্যটি এমন টেনসরগুলির জন্য তৈরি যা বেশিরভাগই ড্রাইভারের অভ্যন্তরীণ এবং ক্লায়েন্ট সাইডে ঘন ঘন অ্যাক্সেসের প্রয়োজন হয় না। এই ধরণের টেনসরগুলির উদাহরণগুলির মধ্যে রয়েছে সিকোয়েন্স মডেলের স্টেট টেনসর। ক্লায়েন্ট সাইডে ঘন ঘন CPU অ্যাক্সেসের প্রয়োজন হয় এমন টেনসরগুলির জন্য, পরিবর্তে শেয়ার্ড মেমোরি পুল ব্যবহার করুন।
একটি অস্বচ্ছ মেমরি বরাদ্দ করতে, নিম্নলিখিত পদক্ষেপগুলি সম্পাদন করুন:
একটি নতুন মেমোরি বর্ণনাকারী তৈরি করতে
ANeuralNetworksMemoryDesc_create()ফাংশনটি কল করুন:// Create a memory descriptor ANeuralNetworksMemoryDesc* desc; ANeuralNetworksMemoryDesc_create(&desc);
ANeuralNetworksMemoryDesc_addInputRole()এবংANeuralNetworksMemoryDesc_addOutputRole()কল করে সমস্ত উদ্দিষ্ট ইনপুট এবং আউটপুট ভূমিকা নির্দিষ্ট করুন।// Specify that the memory may be used as the first input and the first output // of the compilation ANeuralNetworksMemoryDesc_addInputRole(desc, compilation, 0, 1.0f); ANeuralNetworksMemoryDesc_addOutputRole(desc, compilation, 0, 1.0f);
ঐচ্ছিকভাবে,
ANeuralNetworksMemoryDesc_setDimensions()কল করে মেমরির মাত্রা নির্দিষ্ট করুন।// Specify the memory dimensions uint32_t dims[] = {3, 4}; ANeuralNetworksMemoryDesc_setDimensions(desc, 2, dims);
ANeuralNetworksMemoryDesc_finish()কল করে বর্ণনাকারীর সংজ্ঞা চূড়ান্ত করুন।ANeuralNetworksMemoryDesc_finish(desc);
বর্ণনাকারীটি
ANeuralNetworksMemory_createFromDesc()এ পাস করে আপনার যতগুলি প্রয়োজন স্মৃতি বরাদ্দ করুন।// Allocate two opaque memories with the descriptor ANeuralNetworksMemory* opaqueMem; ANeuralNetworksMemory_createFromDesc(desc, &opaqueMem);
যখন আপনার আর প্রয়োজন হবে না তখন মেমরি বর্ণনাকারীটি খালি করুন।
ANeuralNetworksMemoryDesc_free(desc);
ক্লায়েন্ট শুধুমাত্র ANeuralNetworksMemoryDesc অবজেক্টে নির্দিষ্ট ভূমিকা অনুসারে ANeuralNetworksExecution_setInputFromMemory() অথবা ANeuralNetworksExecution_setOutputFromMemory() দিয়ে তৈরি ANeuralNetworksMemory অবজেক্ট ব্যবহার করতে পারবে। অফসেট এবং দৈর্ঘ্যের আর্গুমেন্ট 0 তে সেট করতে হবে, যা নির্দেশ করে যে পুরো মেমোরিটি ব্যবহৃত হয়েছে। ক্লায়েন্ট ANeuralNetworksMemory_copy() ব্যবহার করে মেমোরির বিষয়বস্তু স্পষ্টভাবে সেট বা এক্সট্র্যাক্ট করতে পারে।
আপনি অনির্দিষ্ট মাত্রা বা র্যাঙ্কের ভূমিকা সহ অস্বচ্ছ স্মৃতি তৈরি করতে পারেন। সেই ক্ষেত্রে, অন্তর্নিহিত ড্রাইভার দ্বারা সমর্থিত না হলে ANEURALNETWORKS_OP_FAILED স্ট্যাটাসের সাথে মেমরি তৈরি ব্যর্থ হতে পারে। ক্লায়েন্টকে Ashmem বা BLOB-মোড AHardwareBuffer দ্বারা সমর্থিত একটি যথেষ্ট বড় বাফার বরাদ্দ করে ফলব্যাক লজিক বাস্তবায়ন করতে উৎসাহিত করা হয়।
যখন NNAPI-এর আর অস্বচ্ছ মেমোরি অবজেক্ট অ্যাক্সেস করার প্রয়োজন না হয়, তখন সংশ্লিষ্ট ANeuralNetworksMemory ইনস্ট্যান্সটি মুক্ত করুন:
ANeuralNetworksMemory_free(opaqueMem);
কর্মক্ষমতা পরিমাপ করুন
আপনি আপনার অ্যাপের কর্মক্ষমতা মূল্যায়ন করতে পারেন কার্যকর করার সময় পরিমাপ করে অথবা প্রোফাইলিং করে।
কার্যকর করার সময়
যখন আপনি রানটাইমের মাধ্যমে মোট এক্সিকিউশন সময় নির্ধারণ করতে চান, তখন আপনি সিঙ্ক্রোনাস এক্সিকিউশন API ব্যবহার করতে পারেন এবং কল দ্বারা নেওয়া সময় পরিমাপ করতে পারেন। যখন আপনি সফ্টওয়্যার স্ট্যাকের নিম্ন স্তরের মাধ্যমে মোট এক্সিকিউশন সময় নির্ধারণ করতে চান, তখন আপনি ANeuralNetworksExecution_setMeasureTiming এবং ANeuralNetworksExecution_getDuration ব্যবহার করে পেতে পারেন:
- একটি অ্যাক্সিলারেটরে কার্যকর করার সময় (ড্রাইভারে নয়, যা হোস্ট প্রসেসরে চলে)।
- ড্রাইভারের ক্ষেত্রে কার্যকর করার সময়, অ্যাক্সিলারেটরে সময় সহ।
ড্রাইভারের এক্সিকিউশন টাইম রানটাইমের মতো ওভারহেড এবং ড্রাইভারের সাথে যোগাযোগের জন্য রানটাইমের জন্য প্রয়োজনীয় IPC বাদ দেয়।
এই API গুলি জমা দেওয়া কাজ এবং সম্পন্ন হওয়া কাজের মধ্যে সময়কাল পরিমাপ করে, ড্রাইভার বা অ্যাক্সিলারেটর অনুমান সম্পাদনের জন্য যে সময় ব্যয় করে, সম্ভবত প্রসঙ্গ পরিবর্তনের কারণে তা ব্যাহত হয়।
উদাহরণস্বরূপ, যদি অনুমান ১ শুরু হয়, তারপর ড্রাইভার অনুমান ২ সম্পাদনের জন্য কাজ বন্ধ করে, তারপর এটি পুনরায় শুরু করে এবং অনুমান ১ সম্পন্ন করে, তাহলে অনুমান ১ এর কার্যকর করার সময়টিতে অনুমান ২ সম্পাদনের জন্য কাজ বন্ধ করার সময় অন্তর্ভুক্ত থাকবে।
অফলাইন ব্যবহারের জন্য টেলিমেট্রি সংগ্রহের জন্য একটি অ্যাপ্লিকেশনের উৎপাদন স্থাপনের জন্য এই সময় তথ্য কার্যকর হতে পারে। উচ্চতর কর্মক্ষমতার জন্য আপনি অ্যাপটি পরিবর্তন করতে সময় তথ্য ব্যবহার করতে পারেন।
এই কার্যকারিতা ব্যবহার করার সময়, নিম্নলিখিত বিষয়গুলি মনে রাখবেন:
- সময়ের তথ্য সংগ্রহের জন্য কর্মক্ষমতা খরচ হতে পারে।
- শুধুমাত্র একজন ড্রাইভারই নিজের মধ্যে বা অ্যাক্সিলারেটরে ব্যয় করা সময় গণনা করতে সক্ষম, NNAPI রানটাইম এবং IPC তে ব্যয় করা সময় বাদ দিয়ে।
- আপনি এই API গুলি শুধুমাত্র
ANeuralNetworksExecutionএর মাধ্যমে ব্যবহার করতে পারবেন যাANeuralNetworksCompilation_createForDevicesদিয়েnumDevices = 1দিয়ে তৈরি করা হয়েছে। - No driver is required to be able to report timing information.
Profile your application with Android Systrace
Starting with Android 10, NNAPI automatically generates systrace events that you can use to profile your application.
The NNAPI Source comes with a parse_systrace utility to process the systrace events generated by your application and generate a table view showing the time spent in the different phases of the model lifecycle (Instantiation, Preparation, Compilation Execution and Termination) and different layers of the applications. The layers in which your application is split are:
-
Application: the main application code -
Runtime: NNAPI Runtime -
IPC: The inter process communication between NNAPI Runtime and the Driver code -
Driver: the accelerator driver process.
Generate the profiling analysys data
Assuming you checked out the AOSP source tree at $ANDROID_BUILD_TOP, and using the TFLite image classification example as target application, you can generate the NNAPI profiling data with the following steps:
- Start the Android systrace with the following command:
$ANDROID_BUILD_TOP/external/chromium-trace/systrace.py -o trace.html -a org.tensorflow.lite.examples.classification nnapi hal freq sched idle load binder_driver
The -o trace.html parameter indicates that the traces will be written in the trace.html . When profiling own application you will need to replace org.tensorflow.lite.examples.classification with the process name specified in your app manifest.
This will keep one of your shell console busy, don't run the command in background since it is interactively waiting for an enter to terminate.
- After the systrace collector is started, start your app and run your benchmark test.
In our case you can start the Image Classification app from Android Studio or directly from your test phone UI if the app has already been installed. To generate some NNAPI data you need to configure the app to use NNAPI by selecting NNAPI as target device in the app configuration dialog.
When the test completes, terminate the systrace by pressing
enteron the console terminal active since step 1.Run the
systrace_parserutility generate cumulative statistics:
$ANDROID_BUILD_TOP/frameworks/ml/nn/tools/systrace_parser/parse_systrace.py --total-times trace.html
The parser accepts the following parameters: - --total-times : shows the total time spent in a layer including the time spent waiting for execution on a call to an underlying layer - --print-detail : prints all the events that have been collected from systrace - --per-execution : prints only the execution and its subphases (as per-execution times) instead of stats for all phases - --json : produces the output in JSON format
An example of the output is shown below:
===========================================================================================================================================
NNAPI timing summary (total time, ms wall-clock) Execution
----------------------------------------------------
Initialization Preparation Compilation I/O Compute Results Ex. total Termination Total
-------------- ----------- ----------- ----------- ------------ ----------- ----------- ----------- ----------
Application n/a 19.06 1789.25 n/a n/a 6.70 21.37 n/a 1831.17*
Runtime - 18.60 1787.48 2.93 11.37 0.12 14.42 1.32 1821.81
IPC 1.77 - 1781.36 0.02 8.86 - 8.88 - 1792.01
Driver 1.04 - 1779.21 n/a n/a n/a 7.70 - 1787.95
Total 1.77* 19.06* 1789.25* 2.93* 11.74* 6.70* 21.37* 1.32* 1831.17*
===========================================================================================================================================
* This total ignores missing (n/a) values and thus is not necessarily consistent with the rest of the numbers
The parser might fail if the collected events do not represent a complete application trace. In particular it might fail if systrace events generated to mark the end of a section are present in the trace without an associated section start event. This usually happens if some events from a previous profiling session are being generated when you start the systrace collector. In this case you would have to run your profiling again.
Add statistics for your application code to systrace_parser output
The parse_systrace application is based on the built-in Android systrace functionality. You can add traces for specific operations in your app using the systrace API ( for Java , for native applications ) with custom event names.
To associate your custom events with phases of the Application lifecycle, prepend your event name with one of the following strings:
-
[NN_LA_PI]: Application level event for Initialization -
[NN_LA_PP]: Application level event for Preparation -
[NN_LA_PC]: Application level event for Compilation -
[NN_LA_PE]: Application level event for Execution
Here is an example of how you can alter the TFLite image classification example code by adding a runInferenceModel section for the Execution phase and the Application layer containing another other sections preprocessBitmap that won't be considered in NNAPI traces. The runInferenceModel section will be part of the systrace events processed by the nnapi systrace parser:
কোটলিন
/** Runs inference and returns the classification results. */ fun recognizeImage(bitmap: Bitmap): List{ // This section won’t appear in the NNAPI systrace analysis Trace.beginSection("preprocessBitmap") convertBitmapToByteBuffer(bitmap) Trace.endSection() // Run the inference call. // Add this method in to NNAPI systrace analysis. Trace.beginSection("[NN_LA_PE]runInferenceModel") long startTime = SystemClock.uptimeMillis() runInference() long endTime = SystemClock.uptimeMillis() Trace.endSection() ... return recognitions }
জাভা
/** Runs inference and returns the classification results. */ public ListrecognizeImage(final Bitmap bitmap) { // This section won’t appear in the NNAPI systrace analysis Trace.beginSection("preprocessBitmap"); convertBitmapToByteBuffer(bitmap); Trace.endSection(); // Run the inference call. // Add this method in to NNAPI systrace analysis. Trace.beginSection("[NN_LA_PE]runInferenceModel"); long startTime = SystemClock.uptimeMillis(); runInference(); long endTime = SystemClock.uptimeMillis(); Trace.endSection(); ... Trace.endSection(); return recognitions; }
Quality of service
In Android 11 and higher, NNAPI enables better quality of service (QoS) by allowing an application to indicate the relative priorities of its models, the maximum amount of time expected to prepare a given model, and the maximum amount of time expected to complete a given computation. Android 11 also introduces additional NNAPI result codes that enable applications to understand failures such as missed execution deadlines.
Set the priority of a workload
To set the priority of an NNAPI workload, call ANeuralNetworksCompilation_setPriority() prior to calling ANeuralNetworksCompilation_finish() .
Set deadlines
Applications can set deadlines for both model compilation and inference.
- To set the compilation timeout, call
ANeuralNetworksCompilation_setTimeout()prior to callingANeuralNetworksCompilation_finish(). - To set the inference timeout, call
ANeuralNetworksExecution_setTimeout()prior to starting the compilation .
More about operands
The following section covers advanced topics about using operands.
Quantized tensors
A quantized tensor is a compact way to represent an n-dimensional array of floating point values.
NNAPI supports 8-bit asymmetric quantized tensors. For these tensors, the value of each cell is represented by an 8-bit integer. Associated with the tensor is a scale and a zero point value. These are used to convert the 8-bit integers into the floating point values that are being represented.
সূত্রটি হল:
(cellValue - zeroPoint) * scale
where the zeroPoint value is a 32-bit integer and the scale a 32-bit floating point value.
Compared to tensors of 32-bit floating point values, 8-bit quantized tensors have two advantages:
- Your application is smaller, as the trained weights take a quarter of the size of 32-bit tensors.
- Computations can often be executed faster. This is due to the smaller amount of data that needs to be fetched from memory and the efficiency of processors such as DSPs in doing integer math.
While it is possible to convert a floating point model to a quantized one, our experience has shown that better results are achieved by training a quantized model directly. In effect, the neural network learns to compensate for the increased granularity of each value. For each quantized tensor, the scale and zeroPoint values are determined during the training process.
In NNAPI, you define quantized tensor types by setting the type field of the ANeuralNetworksOperandType data structure to ANEURALNETWORKS_TENSOR_QUANT8_ASYMM . You also specify the scale and zeroPoint value of the tensor in that data structure.
In addition to 8-bit asymmetric quantized tensors, NNAPI supports the following:
-
ANEURALNETWORKS_TENSOR_QUANT8_SYMM_PER_CHANNELwhich you can use for representing weights toCONV/DEPTHWISE_CONV/TRANSPOSED_CONVoperations. -
ANEURALNETWORKS_TENSOR_QUANT16_ASYMMwhich you can use for the internal state ofQUANTIZED_16BIT_LSTM. -
ANEURALNETWORKS_TENSOR_QUANT8_SYMMwhich can be an input toANEURALNETWORKS_DEQUANTIZE.
Optional operands
A few operations, like ANEURALNETWORKS_LSH_PROJECTION , take optional operands. To indicate in the model that the optional operand is omitted, call the ANeuralNetworksModel_setOperandValue() function, passing NULL for the buffer and 0 for the length.
If the decision on whether the operand is present or not varies for each execution, you indicate that the operand is omitted by using the ANeuralNetworksExecution_setInput() or ANeuralNetworksExecution_setOutput() functions, passing NULL for the buffer and 0 for the length.
Tensors of unknown rank
Android 9 (API level 28) introduced model operands of unknown dimensions but known rank (the number of dimensions). Android 10 (API level 29) introduced tensors of unknown rank, as shown in ANeuralNetworksOperandType .
NNAPI benchmark
The NNAPI benchmark is available on AOSP in platform/test/mlts/benchmark (benchmark app) and platform/test/mlts/models (models and datasets).
The benchmark evaluates latency and accuracy and compares drivers to the same work done using Tensorflow Lite running on the CPU, for the same models and datasets.
To use the benchmark, do the following:
Connect a target Android device to your computer, open a terminal window, and make sure the device is reachable through adb.
If more than one Android device is connected, export the target device
ANDROID_SERIALenvironment variable.Navigate to the Android top-level source directory.
Run the following commands:
lunch aosp_arm-userdebug # Or aosp_arm64-userdebug if available ./test/mlts/benchmark/build_and_run_benchmark.sh
At the end of a benchmark run, its results will be presented as an HTML page passed to
xdg-open.
NNAPI logs
NNAPI generates useful diagnostic information in the system logs. To analyze the logs, use the logcat utility.
Enable verbose NNAPI logging for specific phases or components by setting the property debug.nn.vlog (using adb shell ) to the following list of values, separated by space, colon, or comma:
-
model: Model building -
compilation: Generation of the model execution plan and compilation -
execution: Model execution -
cpuexe: Execution of operations using the NNAPI CPU implementation -
manager: NNAPI extensions, available interfaces and capabilities related info -
allor1: All the elements above
For example, to enable full verbose logging use the command adb shell setprop debug.nn.vlog all . To disable verbose logging, use the command adb shell setprop debug.nn.vlog '""' .
Once enabled, verbose logging generates log entries at INFO level with a tag set to the phase or component name.
Beside the debug.nn.vlog controlled messages, NNAPI API components provide other log entries at various levels, each one using a specific log tag.
To get a list of components, search the source tree using the following expression:
grep -R 'define LOG_TAG' | awk -F '"' '{print $2}' | sort -u | egrep -v "Sample|FileTag|test"
This expression currently returns the following tags:
- BurstBuilder
- Callbacks
- CompilationBuilder
- CpuExecutor
- ExecutionBuilder
- ExecutionBurstController
- ExecutionBurstServer
- ExecutionPlan
- FibonacciDriver
- GraphDump
- IndexedShapeWrapper
- IonWatcher
- ম্যানেজার
- স্মৃতি
- MemoryUtils
- MetaModel
- ModelArgumentInfo
- ModelBuilder
- NeuralNetworks
- OperationResolver
- অপারেশনস
- OperationsUtils
- PackageInfo
- TokenHasher
- TypeManager
- Utils
- ValidateHal
- VersionedInterfaces
To control the level of log messages shown by logcat , use the environment variable ANDROID_LOG_TAGS .
To show the full set of NNAPI log messages and disable any others, set ANDROID_LOG_TAGS to the following:
BurstBuilder:V Callbacks:V CompilationBuilder:V CpuExecutor:V ExecutionBuilder:V ExecutionBurstController:V ExecutionBurstServer:V ExecutionPlan:V FibonacciDriver:V GraphDump:V IndexedShapeWrapper:V IonWatcher:V Manager:V MemoryUtils:V Memory:V MetaModel:V ModelArgumentInfo:V ModelBuilder:V NeuralNetworks:V OperationResolver:V OperationsUtils:V Operations:V PackageInfo:V TokenHasher:V TypeManager:V Utils:V ValidateHal:V VersionedInterfaces:V *:S.
You can set ANDROID_LOG_TAGS using the following command:
export ANDROID_LOG_TAGS=$(grep -R 'define LOG_TAG' | awk -F '"' '{ print $2 ":V" }' | sort -u | egrep -v "Sample|FileTag|test" | xargs echo -n; echo ' *:S')
Note that this is just a filter that applies to logcat . You still need to set the property debug.nn.vlog to all to generate verbose log info.