
Android Neural Networks API (NNAPI) adalah Android C API yang dirancang untuk menjalankan operasi komputasi intensif bagi machine learning di perangkat Android. NNAPI dirancang untuk menyediakan lapisan dasar fungsionalitas bagi framework machine learning dengan level lebih tinggi, seperti TensorFlow Lite dan Caffe2, yang membuat dan melatih jaringan neural. API ini tersedia di semua perangkat Android yang menjalankan Android 8.1 (level API 27) atau yang lebih tinggi, tetapi tidak digunakan lagi di Android 15.
NNAPI mendukung inferensi dengan menerapkan data dari perangkat Android ke model yang telah dilatih sebelumnya dan ditetapkan oleh developer. Contoh inferensi meliputi mengklasifikasi gambar, memprediksi perilaku pengguna, dan memilih respons yang tepat untuk sebuah kueri penelusuran.
Inferensi di perangkat memiliki banyak manfaat:
- Latensi: Anda tidak perlu mengirim permintaan melalui koneksi jaringan dan menunggu respons. Misalnya, ini sangat penting untuk aplikasi video yang memproses frame berurutan dari kamera.
- Ketersediaan: Aplikasi dapat berjalan bahkan saat berada di luar jangkauan jaringan.
- Kecepatan: Hardware baru yang khusus untuk pemrosesan jaringan neural menghasilkan komputasi yang jauh lebih cepat daripada CPU biasa.
- Privasi: Data disimpan di perangkat Android.
- Biaya: Farm server tidak diperlukan jika semua komputasi dilakukan di perangkat Android.
Ada juga beberapa konsekuensi yang harus dipertimbangkan developer:
- Pemanfaatan sistem: Evaluasi jaringan neural melibatkan banyak komputasi yang dapat meningkatkan penggunaan daya baterai. Sebaiknya Anda mempertimbangkan pemantauan kesehatan baterai jika hal ini menjadi perhatian bagi aplikasi Anda, terutama untuk komputasi yang berjalan lama.
- Ukuran aplikasi: Perhatikan ukuran model Anda. Model dapat berukuran hingga beberapa megabyte. Jika pemaketan model besar dalam APK akan berdampak buruk bagi pengguna, Anda mungkin perlu mempertimbangkan untuk mendownload model setelah penginstalan aplikasi, menggunakan model yang lebih kecil, atau menjalankan komputasi di cloud. NNAPI tidak menyediakan fungsi untuk menjalankan model di cloud.
Lihat contoh Android Neural Networks API untuk mengetahui cara menggunakan NNAPI.
Memahami runtime Neural Networks API
NNAPI dimaksudkan untuk dipanggil oleh library, framework, dan alat machine learning yang memungkinkan developer melatih model di luar perangkat dan men-deploy model tersebut di perangkat Android. Aplikasi biasanya tidak langsung menggunakan NNAPI, tetapi secara langsung menggunakan framework machine learning dengan level lebih tinggi. Framework ini nantinya dapat menggunakan NNAPI untuk menjalankan operasi inferensi dengan akselerasi hardware pada perangkat yang didukung.
Berdasarkan persyaratan aplikasi dan kemampuan hardware pada perangkat Android, runtime jaringan neural Android dapat secara efisien mendistribusikan beban kerja komputasi ke seluruh prosesor di perangkat yang ada, termasuk hardware jaringan neural khusus, unit pemrosesan grafis (GPU), dan digital signal processor (DSP).
Untuk perangkat Android yang tidak memiliki driver vendor khusus, runtime NNAPI akan mengeksekusi permintaan pada CPU.
Gambar 1 menunjukkan arsitektur sistem level tinggi untuk NNAPI.

Model pemrograman Neural Networks API
Untuk menjalankan komputasi menggunakan NNAPI, Anda harus membuat grafik terarah terlebih dahulu yang akan menentukan komputasi yang dilakukan. Grafik komputasi ini, yang digabungkan dengan data input Anda (misalnya, bobot dan bias yang diturunkan dari framework machine learning), membentuk model untuk evaluasi runtime NNAPI.
NNAPI menggunakan empat abstraksi utama:
- Model: Grafik komputasi dari operasi matematis dan nilai
konstanta yang dipelajari melalui proses pelatihan. Operasi ini khusus untuk jaringan neural. Operasi ini mencakup konvolusi
2 dimensi (2D),
aktivasi logistik
(sigmoid),
aktivasi
linear terkoreksi
(ULT), dan lainnya. Pembuatan model adalah operasi sinkron.
Setelah berhasil dibuat, model dapat digunakan kembali pada berbagai thread dan kompilasi.
Pada NNAPI, model direpresentasikan sebagai
instance
ANeuralNetworksModel. - Kompilasi: Merepresentasikan konfigurasi untuk mengompilasi model NNAPI ke dalam
kode dengan level lebih rendah. Pembuatan kompilasi adalah operasi sinkron. Setelah
berhasil dibuat, kompilasi dapat digunakan kembali pada berbagai thread dan eksekusi. Pada
NNAPI, setiap kompilasi direpresentasikan sebagai
instance
ANeuralNetworksCompilation. - Memori: Merepresentasikan memori bersama, file yang dipetakan memori, dan buffer memori
serupa. Penggunaan buffer memori memungkinkan runtime NNAPI mentransfer data ke driver
dengan lebih efisien. Sebuah aplikasi biasanya membuat satu buffer memori bersama yang
berisi setiap tensor yang diperlukan untuk menetapkan model. Anda juga dapat menggunakan buffer memori
guna menyimpan input dan output untuk instance eksekusi. Pada NNAPI,
setiap buffer memori direpresentasikan
sebagai instance
ANeuralNetworksMemory. Eksekusi: Antarmuka untuk menerapkan model NNAPI ke sekumpulan input dan mengumpulkan hasilnya. Eksekusi dapat dilakukan secara sinkron atau asinkron.
Untuk eksekusi asinkron, beberapa thread dapat menunggu eksekusi yang sama. Setelah eksekusi selesai, semua thread akan dirilis.
Pada NNAPI, setiap eksekusi direpresentasikan sebagai instance
ANeuralNetworksExecution.
Gambar 2 menunjukkan alur pemrograman dasar.
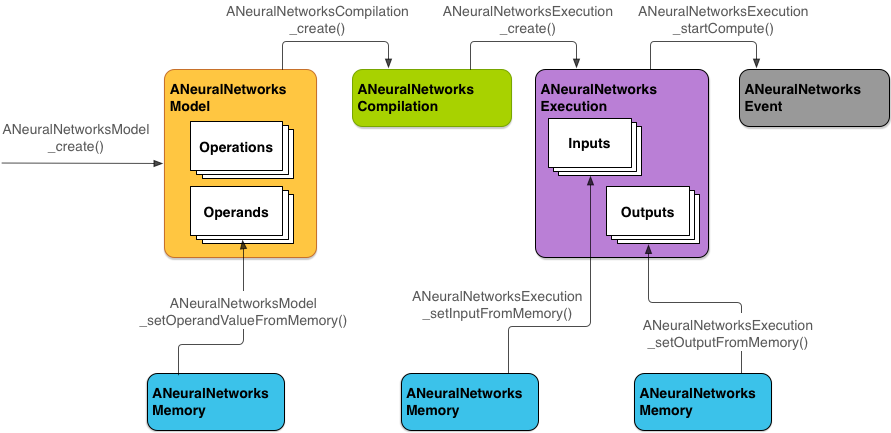
Bagian berikutnya menjelaskan langkah-langkah untuk menyiapkan model NNAPI guna menjalankan komputasi, mengompilasi model, dan mengeksekusi model yang dikompilasi.
Menyediakan akses ke data pelatihan
Data bias dan bobot terlatih kemungkinan tersimpan dalam sebuah file. Untuk menyediakan runtime NNAPI dengan akses yang efisien ke data ini, buat instance ANeuralNetworksMemory dengan memanggil fungsi ANeuralNetworksMemory_createFromFd() dan meneruskan deskriptor file dari file data yang terbuka. Tetapkan juga
flag proteksi memori dan offset tempat region memori bersama
dimulai dalam file.
// Create a memory buffer from the file that contains the trained data
ANeuralNetworksMemory* mem1 = NULL;
int fd = open("training_data", O_RDONLY);
ANeuralNetworksMemory_createFromFd(file_size, PROT_READ, fd, 0, &mem1);
Meski dalam contoh ini kami hanya menggunakan satu
instance
ANeuralNetworksMemory untuk semua bobot, Anda dapat menggunakan lebih dari satu
instance ANeuralNetworksMemory untuk beberapa file.
Menggunakan buffer hardware native
Anda dapat menggunakan buffer hardware native
untuk input, output, dan nilai operand konstanta model. Dalam kasus tertentu, akselerator
NNAPI dapat mengakses objek
AHardwareBuffer
tanpa driver perlu menyalin data. AHardwareBuffer memiliki banyak
konfigurasi yang berbeda, dan tidak semua akselerator NNAPI dapat mendukung semua
konfigurasi ini. Karena keterbatasan ini, lihat batasan
yang tercantum dalam
dokumentasi referensi ANeuralNetworksMemory_createFromAHardwareBuffer
dan uji terlebih dahulu di perangkat target untuk memastikan kompilasi dan eksekusi
yang menggunakan AHardwareBuffer berperilaku sesuai harapan, menggunakan
penetapan perangkat untuk menentukan akselerator.
Untuk mengizinkan runtime NNAPI mengakses objek AHardwareBuffer, buat
instance ANeuralNetworksMemory
dengan memanggil
fungsi ANeuralNetworksMemory_createFromAHardwareBuffer dan meneruskan
objek AHardwareBuffer, sebagaimana ditunjukkan dalam contoh kode berikut:
// Configure and create AHardwareBuffer object AHardwareBuffer_Desc desc = ... AHardwareBuffer* ahwb = nullptr; AHardwareBuffer_allocate(&desc, &ahwb); // Create ANeuralNetworksMemory from AHardwareBuffer ANeuralNetworksMemory* mem2 = NULL; ANeuralNetworksMemory_createFromAHardwareBuffer(ahwb, &mem2);
Saat NNAPI tidak perlu lagi mengakses objek AHardwareBuffer, kosongkan
instance ANeuralNetworksMemory yang sesuai:
ANeuralNetworksMemory_free(mem2);
Catatan:
- Anda hanya dapat menggunakan
AHardwareBufferuntuk seluruh buffer; Anda tidak dapat menggunakannya dengan parameterARect. - Runtime NNAPI tidak akan menghapus buffer. Anda harus memastikan bahwa buffer input dan output dapat diakses sebelum menjadwalkan eksekusi.
- Tidak ada dukungan untuk deskriptor file fence sinkronisasi.
- Untuk
AHardwareBufferdengan format khusus vendor dan bit penggunaan, implementasi vendor akan menentukan apakah klien atau driver bertanggung jawab untuk menghapus cache.
Model
Model adalah unit dasar komputasi dalam NNAPI. Setiap model ditentukan oleh satu atau beberapa operand dan operasi.
Operand
Operand adalah objek data yang digunakan dalam menetapkan grafik. Operand mencakup input dan output model, node perantara yang berisi data yang mengalir dari satu operasi ke operasi lainnya, dan konstanta yang diteruskan ke operasi tersebut.
Ada dua jenis operand yang dapat ditambahkan ke model NNAPI: skalar dan tensor.
Skalar mewakili sebuah nilai. NNAPI mendukung nilai skalar dalam boolean, floating point 16-bit, floating point 32-bit, bilangan bulat 32-bit, dan format bilangan bulat 32-bit yang tidak ditandatangani.
Sebagian besar operasi di NNAPI melibatkan tensor. Tensor adalah array n-dimensional. NNAPI mendukung tensor dengan floating point 16 bit, floating point 32 bit, nilai terkuantisasi 8 bit, nilai terkuantisasi 16 bit, bilangan bulat 32 bit, dan nilai boolean 8 bit.
Misalnya, gambar 3 merepresentasikan model dengan dua operasi: penambahan diikuti dengan perkalian. Model ini mengambil sebuah tensor input dan menghasilkan satu tensor output.

Model di atas memiliki tujuh operand. Operand tersebut diidentifikasi secara implisit oleh indeks dengan urutan seperti saat ditambahkan ke model. Operand pertama yang ditambahkan memiliki indeks 0, yang kedua memiliki indeks 1, dan seterusnya. Operand 1, 2, 3, dan 5 adalah operand konstanta.
Urutan Anda menambahkan operand tidak menjadi masalah. Misalnya, operand output model dapat menjadi yang pertama ditambahkan. Bagian yang penting adalah menggunakan nilai indeks yang tepat saat merujuk ke sebuah operand.
Operand memiliki beberapa jenis. Jenis ini ditetapkan saat ditambahkan ke model.
Sebuah operand tidak dapat digunakan sebagai input sekaligus output untuk sebuah model.
Setiap operand harus berupa input model, konstanta, atau operand output dari tepat satu operasi.
Untuk informasi tambahan tentang penggunaan operand, lihat Selengkapnya tentang operand.
Operasi
Sebuah operasi menentukan komputasi yang akan dilakukan. Setiap operasi terdiri dari elemen-elemen ini:
- jenis operasi (misalnya, penambahan, perkalian, konvolusi),
- daftar indeks operand yang digunakan operasi untuk input, dan
- daftar indeks operand yang digunakan operasi untuk output.
Urutan dalam daftar ini penting; lihat Referensi NNAPI API untuk input dan output yang diharapkan dari setiap jenis operasi.
Anda harus menambahkan operand yang dipakai atau dihasilkan oleh operasi ke model sebelum menambahkan operasi tersebut.
Urutan Anda menambahkan operasi tidak menjadi masalah. NNAPI mengandalkan dependensi yang ditetapkan oleh grafik komputasi operand dan operasi untuk menentukan urutan eksekusi operasi.
Operasi yang didukung oleh NNAPI diringkas dalam tabel di bawah:
Masalah umum di API level 28: Saat meneruskan
tensor
ANEURALNETWORKS_TENSOR_QUANT8_ASYMM ke
operasi
ANEURALNETWORKS_PAD, yang tersedia di Android 9 (API level 28) dan yang lebih baru,
output dari NNAPI mungkin tidak cocok dengan output dari framework
machine learning yang levelnya lebih tinggi, seperti
TensorFlow Lite. Anda
seharusnya hanya meneruskan
ANEURALNETWORKS_TENSOR_FLOAT32.
Masalah ini telah diatasi di Android 10 (API level 29) dan yang lebih tinggi.
Membuat model
Dalam contoh berikut, kami membuat model dua operasi yang terdapat dalam gambar 3.
Untuk membuat model, ikuti langkah-langkah ini:
Panggil fungsi
ANeuralNetworksModel_create()untuk menetapkan model kosong.ANeuralNetworksModel* model = NULL; ANeuralNetworksModel_create(&model);
Tambahkan operand ke model dengan memanggil
ANeuralNetworks_addOperand(). Jenis datanya ditetapkan menggunakan struktur dataANeuralNetworksOperandType.// In our example, all our tensors are matrices of dimension [3][4] ANeuralNetworksOperandType tensor3x4Type; tensor3x4Type.type = ANEURALNETWORKS_TENSOR_FLOAT32; tensor3x4Type.scale = 0.f; // These fields are used for quantized tensors tensor3x4Type.zeroPoint = 0; // These fields are used for quantized tensors tensor3x4Type.dimensionCount = 2; uint32_t dims[2] = {3, 4}; tensor3x4Type.dimensions = dims;
// We also specify operands that are activation function specifiers ANeuralNetworksOperandType activationType; activationType.type = ANEURALNETWORKS_INT32; activationType.scale = 0.f; activationType.zeroPoint = 0; activationType.dimensionCount = 0; activationType.dimensions = NULL;
// Now we add the seven operands, in the same order defined in the diagram ANeuralNetworksModel_addOperand(model, &tensor3x4Type); // operand 0 ANeuralNetworksModel_addOperand(model, &tensor3x4Type); // operand 1 ANeuralNetworksModel_addOperand(model, &activationType); // operand 2 ANeuralNetworksModel_addOperand(model, &tensor3x4Type); // operand 3 ANeuralNetworksModel_addOperand(model, &tensor3x4Type); // operand 4 ANeuralNetworksModel_addOperand(model, &activationType); // operand 5 ANeuralNetworksModel_addOperand(model, &tensor3x4Type); // operand 6Untuk operand yang memiliki nilai konstanta, seperti bobot dan bias yang diperoleh aplikasi dari proses pelatihan, gunakan fungsi
ANeuralNetworksModel_setOperandValue()danANeuralNetworksModel_setOperandValueFromMemory().Dalam contoh berikut, kami menetapkan nilai konstanta dari file data pelatihan terkait buffer memori yang dibuat dalam Menyediakan akses ke data pelatihan.
// In our example, operands 1 and 3 are constant tensors whose values were // established during the training process const int sizeOfTensor = 3 * 4 * 4; // The formula for size calculation is dim0 * dim1 * elementSize ANeuralNetworksModel_setOperandValueFromMemory(model, 1, mem1, 0, sizeOfTensor); ANeuralNetworksModel_setOperandValueFromMemory(model, 3, mem1, sizeOfTensor, sizeOfTensor);
// We set the values of the activation operands, in our example operands 2 and 5 int32_t noneValue = ANEURALNETWORKS_FUSED_NONE; ANeuralNetworksModel_setOperandValue(model, 2, &noneValue, sizeof(noneValue)); ANeuralNetworksModel_setOperandValue(model, 5, &noneValue, sizeof(noneValue));Untuk setiap operasi dalam grafik terarah yang ingin Anda hitung, tambahkan operasi ke model dengan memanggil fungsi
ANeuralNetworksModel_addOperation().Sebagai parameter untuk panggilan ini, aplikasi harus menyediakan:
- jenis operasi
- jumlah nilai input
- array indeks untuk operand input
- jumlah nilai output
- array indeks untuk operand output
Perlu diketahui bahwa satu operand tidak dapat digunakan sekaligus untuk input dan output operasi yang sama.
// We have two operations in our example // The first consumes operands 1, 0, 2, and produces operand 4 uint32_t addInputIndexes[3] = {1, 0, 2}; uint32_t addOutputIndexes[1] = {4}; ANeuralNetworksModel_addOperation(model, ANEURALNETWORKS_ADD, 3, addInputIndexes, 1, addOutputIndexes);
// The second consumes operands 3, 4, 5, and produces operand 6 uint32_t multInputIndexes[3] = {3, 4, 5}; uint32_t multOutputIndexes[1] = {6}; ANeuralNetworksModel_addOperation(model, ANEURALNETWORKS_MUL, 3, multInputIndexes, 1, multOutputIndexes);Identifikasi operand yang harus diperlakukan oleh model sebagai input dan outputnya dengan memanggil fungsi
ANeuralNetworksModel_identifyInputsAndOutputs().// Our model has one input (0) and one output (6) uint32_t modelInputIndexes[1] = {0}; uint32_t modelOutputIndexes[1] = {6}; ANeuralNetworksModel_identifyInputsAndOutputs(model, 1, modelInputIndexes, 1 modelOutputIndexes);
Jika ingin, tentukan apakah
ANEURALNETWORKS_TENSOR_FLOAT32boleh dihitung dengan rentang atau presisi yang sama rendahnya seperti format floating point 16-bit IEEE 754 dengan memanggilANeuralNetworksModel_relaxComputationFloat32toFloat16().Panggil
ANeuralNetworksModel_finish()untuk menyelesaikan penetapan model. Jika tidak ada error, fungsi ini akan menampilkan kode hasilANEURALNETWORKS_NO_ERROR.ANeuralNetworksModel_finish(model);
Setelah membuat model, Anda dapat mengompilasinya berapa kali pun dan mengeksekusi setiap kompilasi berapa kali pun.
Alur kontrol
Untuk menggabungkan alur kontrol dalam model NNAPI, lakukan hal berikut:
Buat subgrafik eksekusi yang sesuai (subgrafik
thendanelseuntuk pernyataanIF, subgrafikconditiondanbodyuntuk loopWHILE) sebagai modelANeuralNetworksModel*mandiri:ANeuralNetworksModel* thenModel = makeThenModel(); ANeuralNetworksModel* elseModel = makeElseModel();
Buat operand yang mereferensikan model tersebut dalam model yang berisi alur kontrol:
ANeuralNetworksOperandType modelType = { .type = ANEURALNETWORKS_MODEL, }; ANeuralNetworksModel_addOperand(model, &modelType); // kThenOperandIndex ANeuralNetworksModel_addOperand(model, &modelType); // kElseOperandIndex ANeuralNetworksModel_setOperandValueFromModel(model, kThenOperandIndex, &thenModel); ANeuralNetworksModel_setOperandValueFromModel(model, kElseOperandIndex, &elseModel);
Tambahkan operasi alur kontrol:
uint32_t inputs[] = {kConditionOperandIndex, kThenOperandIndex, kElseOperandIndex, kInput1, kInput2, kInput3}; uint32_t outputs[] = {kOutput1, kOutput2}; ANeuralNetworksModel_addOperation(model, ANEURALNETWORKS_IF, std::size(inputs), inputs, std::size(output), outputs);
Kompilasi
Langkah kompilasi menentukan prosesor mana yang akan digunakan untuk mengeksekusi model dan meminta driver terkait untuk mempersiapkan eksekusinya. Langkah ini dapat mencakup pembuatan kode mesin khusus untuk prosesor tempat model akan dijalankan.
Untuk mengompilasi model, ikuti langkah-langkah berikut:
Panggil fungsi
ANeuralNetworksCompilation_create()untuk membuat instance kompilasi baru.// Compile the model ANeuralNetworksCompilation* compilation; ANeuralNetworksCompilation_create(model, &compilation);
Jika ingin, Anda dapat menggunakan penetapan perangkat untuk secara eksplisit memilih perangkat yang digunakan untuk mengeksekusi.
Anda dapat memengaruhi keseimbangan runtime antara penggunaan daya baterai dan kecepatan eksekusi. Anda dapat melakukannya dengan memanggil
ANeuralNetworksCompilation_setPreference().// Ask to optimize for low power consumption ANeuralNetworksCompilation_setPreference(compilation, ANEURALNETWORKS_PREFER_LOW_POWER);
Preferensi yang dapat ditentukan mencakup:
ANEURALNETWORKS_PREFER_LOW_POWER: Lebih memilih mengeksekusi dengan cara yang meminimalkan pemakaian daya baterai. Ini cocok untuk kompilasi yang sering dieksekusi.ANEURALNETWORKS_PREFER_FAST_SINGLE_ANSWER: Lebih memilih menampilkan satu jawaban secepat mungkin, meskipun ini akan menghabiskan lebih banyak daya. Ini adalah defaultnya.ANEURALNETWORKS_PREFER_SUSTAINED_SPEED: Lebih memilih memaksimalkan throughput frame berurutan, misalnya saat memproses frame berurutan yang berasal dari kamera.
Anda dapat menyiapkan pembuatan cache kompilasi dengan memanggil
ANeuralNetworksCompilation_setCaching.// Set up compilation caching ANeuralNetworksCompilation_setCaching(compilation, cacheDir, token);
Gunakan
getCodeCacheDir()untukcacheDir.tokenyang ditentukan harus unik untuk setiap model dalam aplikasi.Selesaikan penetapan kompilasi dengan memanggil
ANeuralNetworksCompilation_finish(). Jika tidak ada error, fungsi ini akan menampilkan kode hasilANEURALNETWORKS_NO_ERROR.ANeuralNetworksCompilation_finish(compilation);
Penemuan dan penetapan perangkat
Di perangkat Android yang menjalankan Android 10 (API level 29) dan yang lebih baru, NNAPI menyediakan fungsi yang memungkinkan library framework machine learning dan aplikasi mendapatkan informasi tentang perangkat yang tersedia dan menentukan perangkat yang akan digunakan untuk eksekusi. Menyediakan informasi tentang perangkat yang tersedia memungkinkan aplikasi mendapatkan versi driver tepat yang terdapat di perangkat untuk menghindari ketidakcocokan umum. Dengan memberi aplikasi kemampuan untuk menentukan perangkat mana yang akan mengeksekusi berbagai bagian model, aplikasi dapat dioptimalkan untuk perangkat Android tempat aplikasi di-deploy.
Penemuan perangkat
Gunakan
ANeuralNetworks_getDeviceCount
untuk mendapatkan jumlah perangkat yang tersedia. Untuk setiap perangkat, gunakan
ANeuralNetworks_getDevice
guna menetapkan instance ANeuralNetworksDevice untuk referensi ke perangkat tersebut.
Setelah memiliki referensi perangkat, Anda dapat mencari tahu informasi tambahan tentang perangkat tersebut menggunakan fungsi berikut:
ANeuralNetworksDevice_getFeatureLevelANeuralNetworksDevice_getNameANeuralNetworksDevice_getTypeANeuralNetworksDevice_getVersion
Penetapan perangkat
Gunakan
ANeuralNetworksModel_getSupportedOperationsForDevices
untuk menemukan operasi model yang dapat dijalankan di perangkat tertentu.
Guna mengontrol akselerator yang akan digunakan untuk eksekusi, panggil
ANeuralNetworksCompilation_createForDevices
sebagai pengganti ANeuralNetworksCompilation_create.
Gunakan objek ANeuralNetworksCompilation yang dihasilkan, seperti biasa.
Fungsi tersebut akan menampilkan error jika model yang disediakan berisi operasi yang
tidak didukung oleh perangkat yang dipilih.
Jika beberapa perangkat ditentukan, runtime akan bertanggung jawab untuk mendistribusikan tugas ke seluruh perangkat.
Serupa dengan perangkat lain, implementasi CPU NNAPI direpresentasikan oleh
ANeuralNetworksDevice dengan nama nnapi-reference dan jenis
ANEURALNETWORKS_DEVICE_TYPE_CPU. Saat memanggil
ANeuralNetworksCompilation_createForDevices, implementasi CPU tidak
digunakan untuk menangani kasus kegagalan untuk kompilasi dan eksekusi model.
Aplikasi bertanggung jawab untuk membuat partisi model menjadi submodel yang dapat berjalan di perangkat yang ditentukan. Aplikasi yang tidak perlu melakukan partisi
manual harus terus memanggil
ANeuralNetworksCompilation_create
yang lebih sederhana untuk menggunakan semua perangkat yang tersedia (termasuk CPU) untuk mempercepat
model. Jika model tidak dapat sepenuhnya didukung oleh perangkat yang Anda tentukan
menggunakan ANeuralNetworksCompilation_createForDevices,
ANEURALNETWORKS_BAD_DATA
akan ditampilkan.
Pembuatan partisi model
Bila beberapa perangkat tersedia untuk model, runtime NNAPI
akan mendistribusikan tugas ke seluruh perangkat. Misalnya, jika lebih dari satu perangkat
disediakan ke ANeuralNetworksCompilation_createForDevices, semua perangkat yang ditentukan akan
dipertimbangkan saat mengalokasikan tugas tersebut. Perlu diketahui bahwa jika perangkat CPU
tidak ada dalam daftar, eksekusi CPU akan dinonaktifkan. Saat menggunakan ANeuralNetworksCompilation_create,
semua perangkat yang tersedia akan dipertimbangkan, termasuk CPU.
Distribusi dilakukan dengan memilih daftar perangkat yang tersedia, untuk setiap
operasi dalam model, perangkat yang mendukung operasi, dan
mendeklarasikan performa terbaik, yaitu waktu eksekusi tercepat atau
penggunaan daya terendah, yang bergantung pada preferensi eksekusi yang ditentukan oleh
klien. Algoritma pembuatan partisi ini tidak memperhitungkan kemungkinan inefisiensi yang disebabkan oleh IO antarprosesor yang berbeda. Jadi, saat menentukan beberapa prosesor (baik secara eksplisit saat menggunakan ANeuralNetworksCompilation_createForDevices maupun secara implisit menggunakan ANeuralNetworksCompilation_create), sebaiknya buat profil pada aplikasi yang dihasilkan.
Untuk memahami cara model Anda dipartisi oleh NNAPI, periksa
pesan (pada level INFO dengan tag ExecutionPlan) dalam log Android:
ModelBuilder::findBestDeviceForEachOperation(op-name): device-index
op-name adalah nama deskriptif operasi dalam grafik dan
device-index adalah indeks perangkat kandidat dalam daftar perangkat.
Daftar ini adalah input yang diberikan ke ANeuralNetworksCompilation_createForDevices,
atau jika menggunakan ANeuralNetworksCompilation_createForDevices, adalah daftar perangkat
yang ditampilkan saat melakukan iterasi di semua perangkat menggunakan ANeuralNetworks_getDeviceCount dan
ANeuralNetworks_getDevice.
Pesan (pada level INFO dengan tag ExecutionPlan):
ModelBuilder::partitionTheWork: only one best device: device-name
Pesan ini menunjukkan bahwa seluruh grafik telah dipercepat pada
device-name perangkat.
Eksekusi
Langkah eksekusi menerapkan model ke sekumpulan input dan menyimpan output komputasi ke satu atau beberapa buffer pengguna atau ruang memori yang dialokasikan oleh aplikasi Anda.
Untuk mengeksekusi model yang telah dikompilasi, ikuti langkah-langkah ini:
Panggil fungsi
ANeuralNetworksExecution_create()untuk membuat instance eksekusi baru.// Run the compiled model against a set of inputs ANeuralNetworksExecution* run1 = NULL; ANeuralNetworksExecution_create(compilation, &run1);
Tetapkan tempat aplikasi membaca nilai input untuk komputasi. Aplikasi Anda dapat membaca nilai input dari buffer pengguna atau ruang memori yang dialokasikan dengan masing-masing memanggil
ANeuralNetworksExecution_setInput()atauANeuralNetworksExecution_setInputFromMemory().// Set the single input to our sample model. Since it is small, we won't use a memory buffer float32 myInput[3][4] = { ...the data... }; ANeuralNetworksExecution_setInput(run1, 0, NULL, myInput, sizeof(myInput));
Tetapkan tempat aplikasi menulis nilai output. Aplikasi dapat menulis nilai output ke buffer pengguna atau ruang memori yang dialokasikan, dengan masing-masing memanggil
ANeuralNetworksExecution_setOutput()atauANeuralNetworksExecution_setOutputFromMemory().// Set the output float32 myOutput[3][4]; ANeuralNetworksExecution_setOutput(run1, 0, NULL, myOutput, sizeof(myOutput));
Jadwalkan waktu mulai eksekusi dengan memanggil fungsi
ANeuralNetworksExecution_startCompute(). Jika tidak ada error, fungsi ini akan menampilkan kode hasilANEURALNETWORKS_NO_ERROR.// Starts the work. The work proceeds asynchronously ANeuralNetworksEvent* run1_end = NULL; ANeuralNetworksExecution_startCompute(run1, &run1_end);
Panggil fungsi
ANeuralNetworksEvent_wait()untuk menunggu hingga eksekusi selesai. Jika eksekusi berhasil, fungsi ini akan menampilkan kode hasilANEURALNETWORKS_NO_ERROR. Proses menunggu dapat dilakukan pada thread lain, bukan hanya pada thread yang memulai eksekusi.// For our example, we have no other work to do and will just wait for the completion ANeuralNetworksEvent_wait(run1_end); ANeuralNetworksEvent_free(run1_end); ANeuralNetworksExecution_free(run1);
Jika ingin, Anda dapat menerapkan kumpulan input lain ke model yang telah dikompilasi menggunakan instance kompilasi yang sama untuk membuat instance
ANeuralNetworksExecutionbaru.// Apply the compiled model to a different set of inputs ANeuralNetworksExecution* run2; ANeuralNetworksExecution_create(compilation, &run2); ANeuralNetworksExecution_setInput(run2, ...); ANeuralNetworksExecution_setOutput(run2, ...); ANeuralNetworksEvent* run2_end = NULL; ANeuralNetworksExecution_startCompute(run2, &run2_end); ANeuralNetworksEvent_wait(run2_end); ANeuralNetworksEvent_free(run2_end); ANeuralNetworksExecution_free(run2);
Eksekusi sinkron
Eksekusi asinkron menghabiskan waktu untuk menghasilkan dan menyinkronkan thread. Selain itu, latensi dapat menjadi sangat bervariasi, dengan keterlambatan terlama mencapai hingga 500 mikrodetik antara waktu thread diberi tahu atau dibangunkan dan waktu thread pada akhirnya diikat ke inti CPU.
Agar latensi berkurang, Anda dapat mengarahkan aplikasi agar membuat panggilan
inferensi sinkron ke runtime. Panggilan tersebut hanya akan ditampilkan sekali setelah
inferensi selesai, bukan pada saat inferensi dimulai. Daripada
memanggil
ANeuralNetworksExecution_startCompute untuk panggilan inferensi asinkron ke runtime, aplikasi akan memanggil
ANeuralNetworksExecution_compute
untuk melakukan panggilan sinkron ke runtime. Panggilan ke
ANeuralNetworksExecution_compute tidak memerlukan ANeuralNetworksEvent dan
tidak disambungkan dengan panggilan ke ANeuralNetworksEvent_wait.
Eksekusi burst
Di perangkat Android yang menjalankan Android 10 (API level 29) dan yang lebih tinggi, NNAPI mendukung eksekusi
burst melalui
objek
ANeuralNetworksBurst. Eksekusi burst adalah urutan eksekusi dari kompilasi sama
yang terjadi dengan cepat, seperti yang berjalan pada frame pengambilan gambar kamera
atau sampel audio berturut-turut. Penggunaan objek ANeuralNetworksBurst dapat
menghasilkan eksekusi yang lebih cepat karena objek tersebut menunjukkan pada akselerator bahwa resource dapat
digunakan kembali antar-eksekusi dan akselerator harus tetap dalam
kondisi performa tinggi selama durasi burst.
ANeuralNetworksBurst hanya memberikan sedikit perubahan pada jalur eksekusi
normal. Buat objek burst menggunakan
ANeuralNetworksBurst_create,
sebagaimana ditunjukkan dalam cuplikan kode berikut:
// Create burst object to be reused across a sequence of executions ANeuralNetworksBurst* burst = NULL; ANeuralNetworksBurst_create(compilation, &burst);
Eksekusi burst dilakukan secara sinkron. Namun, daripada menggunakan
ANeuralNetworksExecution_compute
untuk menjalankan setiap inferensi, sambungkan berbagai objek
ANeuralNetworksExecution
dengan ANeuralNetworksBurst yang sama dalam panggilan ke fungsi
ANeuralNetworksExecution_burstCompute.
// Create and configure first execution object // ... // Execute using the burst object ANeuralNetworksExecution_burstCompute(execution1, burst); // Use results of first execution and free the execution object // ... // Create and configure second execution object // ... // Execute using the same burst object ANeuralNetworksExecution_burstCompute(execution2, burst); // Use results of second execution and free the execution object // ...
Bebaskan objek ANeuralNetworksBurst dengan
ANeuralNetworksBurst_free
bila tidak lagi diperlukan.
// Cleanup ANeuralNetworksBurst_free(burst);
Eksekusi dengan fence dan antrean perintah asinkron
Di Android 11 dan yang lebih tinggi, NNAPI mendukung cara tambahan untuk menjadwalkan
eksekusi asinkron melalui
metode
ANeuralNetworksExecution_startComputeWithDependencies(). Bila Anda menggunakan metode ini, eksekusi akan menunggu semua peristiwa
yang bergantung diberi sinyal sebelum memulai evaluasi. Setelah eksekusi selesai
dan output siap dipakai, peristiwa yang ditampilkan akan
diberi sinyal.
Bergantung pada perangkat yang menangani eksekusi, peristiwa mungkin didukung oleh
fence sinkronisasi. Anda
harus memanggil
ANeuralNetworksEvent_wait()
untuk menunggu peristiwa dan memulihkan resource yang digunakan eksekusi. Anda
dapat mengimpor fence sinkronisasi ke objek peristiwa menggunakan
ANeuralNetworksEvent_createFromSyncFenceFd(),
dan mengekspor fence sinkronisasi dari objek peristiwa menggunakan
ANeuralNetworksEvent_getSyncFenceFd().
Output berukuran dinamis
Untuk mendukung model yang ukuran output-nya bergantung pada data
input—yaitu yang ukurannya tidak dapat ditentukan pada waktu eksekusi
model—gunakan
ANeuralNetworksExecution_getOutputOperandRank
dan
ANeuralNetworksExecution_getOutputOperandDimensions.
Contoh kode berikut menunjukkan cara melakukannya:
// Get the rank of the output uint32_t myOutputRank = 0; ANeuralNetworksExecution_getOutputOperandRank(run1, 0, &myOutputRank); // Get the dimensions of the output std::vector<uint32_t> myOutputDimensions(myOutputRank); ANeuralNetworksExecution_getOutputOperandDimensions(run1, 0, myOutputDimensions.data());
Pembersihan
Langkah pembersihan menangani pengosongan resource internal yang digunakan untuk komputasi.
// Cleanup ANeuralNetworksCompilation_free(compilation); ANeuralNetworksModel_free(model); ANeuralNetworksMemory_free(mem1);
Pengelolaan error dan penggantian CPU
Jika terjadi error pada waktu pembuatan partisi, jika driver gagal mengompilasi (sebagian dari) model, atau jika driver gagal mengeksekusi (sebagian dari) model yang dikompilasi, NNAPI mungkin akan kembali ke implementasi CPU-nya sendiri dari satu atau beberapa operasi.
Jika klien NNAPI berisi versi operasi yang dioptimalkan (misalnya, TFLite), akan lebih mudah untuk menonaktifkan penggantian CPU dan menangani kegagalan dengan implementasi operasi yang dioptimalkan klien.
Di Android 10, jika kompilasi dilakukan menggunakan
ANeuralNetworksCompilation_createForDevices, maka penggantian CPU akan dinonaktifkan.
Di Android P, eksekusi NNAPI akan beralih kembali ke CPU jika eksekusi pada driver gagal.
Hal ini juga berlaku pada Android 10 saat ANeuralNetworksCompilation_create dipilih untuk digunakan
daripada ANeuralNetworksCompilation_createForDevices.
Eksekusi pertama akan beralih kembali untuk partisi tersebut, dan jika masih gagal, seluruh model di CPU akan dicoba ulang.
Jika pembuatan partisi atau kompilasi gagal, seluruh model akan dicoba pada CPU.
Terdapat kasus saat beberapa operasi tidak didukung pada CPU, dan dalam situasi seperti ini, kompilasi atau eksekusi akan gagal, bukan beralih kembali.
Bahkan setelah menonaktifkan penggantian CPU, mungkin masih ada operasi dalam model
yang dijadwalkan pada CPU. Jika CPU termasuk dalam daftar prosesor yang disertakan
ke ANeuralNetworksCompilation_createForDevices, dan merupakan satu-satunya
prosesor yang mendukung operasi tersebut atau merupakan prosesor yang mengklaim memiliki
performa terbaik untuk operasi tersebut, CPU akan dipilih sebagai eksekutor (non-penggantian)
utama.
Untuk memastikan tidak adanya eksekusi CPU, gunakan ANeuralNetworksCompilation_createForDevices
saat mengecualikan nnapi-reference dari daftar perangkat.
Mulai dari Android P, Anda dapat menonaktifkan penggantian pada waktu eksekusi di
build DEBUG dengan menetapkan properti debug.nn.partition ke 2.
Domain memori
Di Android 11 dan yang lebih tinggi, NNAPI mendukung domain memori yang menyediakan antarmuka pengalokasi untuk memori buram. Hal ini memungkinkan aplikasi meneruskan memori native perangkat di seluruh eksekusi, sehingga NNAPI tidak akan menyalin atau mengubah data yang tidak perlu saat menjalankan eksekusi berurutan pada driver yang sama.
Fitur domain memori ditujukan untuk tensor yang sebagian besar bersifat internal bagi driver dan yang tidak memerlukan akses sering ke sisi klien. Contoh tensor tersebut mencakup tensor status dalam model barisan. Untuk tensor yang perlu sering mengakses CPU pada sisi klien, gunakan gabungan memori bersama.
Untuk mengalokasikan memori buram, lakukan langkah-langkah berikut:
Panggil fungsi
ANeuralNetworksMemoryDesc_create()untuk membuat deskriptor memori baru:// Create a memory descriptor ANeuralNetworksMemoryDesc* desc; ANeuralNetworksMemoryDesc_create(&desc);
Tentukan semua peran input dan output yang dimaksudkan dengan memanggil
ANeuralNetworksMemoryDesc_addInputRole()danANeuralNetworksMemoryDesc_addOutputRole().// Specify that the memory may be used as the first input and the first output // of the compilation ANeuralNetworksMemoryDesc_addInputRole(desc, compilation, 0, 1.0f); ANeuralNetworksMemoryDesc_addOutputRole(desc, compilation, 0, 1.0f);
Jika ingin, tentukan dimensi memori dengan memanggil
ANeuralNetworksMemoryDesc_setDimensions().// Specify the memory dimensions uint32_t dims[] = {3, 4}; ANeuralNetworksMemoryDesc_setDimensions(desc, 2, dims);
Selesaikan penetapan deskriptor dengan memanggil
ANeuralNetworksMemoryDesc_finish().ANeuralNetworksMemoryDesc_finish(desc);
Alokasikan memori sesuai keperluan dengan meneruskan deskriptor ke
ANeuralNetworksMemory_createFromDesc().// Allocate two opaque memories with the descriptor ANeuralNetworksMemory* opaqueMem; ANeuralNetworksMemory_createFromDesc(desc, &opaqueMem);
Kosongkan deskriptor memori bila Anda tidak lagi memerlukannya.
ANeuralNetworksMemoryDesc_free(desc);
Klien hanya dapat menggunakan objek ANeuralNetworksMemory yang dibuat dengan
ANeuralNetworksExecution_setInputFromMemory() atau ANeuralNetworksExecution_setOutputFromMemory() sesuai dengan peran
yang ditentukan dalam objek ANeuralNetworksMemoryDesc. Argumen offset dan panjang
harus ditetapkan ke 0, yang menunjukkan bahwa seluruh memori digunakan. Klien
juga dapat menetapkan secara eksplisit atau mengekstrak isi memori menggunakan
ANeuralNetworksMemory_copy().
Anda dapat membuat memori buram dengan peran dimensi atau peringkat yang tidak ditentukan.
Dalam hal ini, pembuatan memori mungkin gagal dengan
status ANEURALNETWORKS_OP_FAILED jika tidak didukung oleh
driver-nya. Klien dianjurkan untuk menerapkan logika penggantian dengan mengalokasikan
buffer cukup besar yang didukung oleh mode Ashmem atau BLOB AHardwareBuffer.
Bila NNAPI tidak perlu lagi mengakses objek memori buram, kosongkan
instance ANeuralNetworksMemory terkait:
ANeuralNetworksMemory_free(opaqueMem);
Mengukur performa
Anda dapat mengevaluasi performa aplikasi dengan mengukur waktu eksekusi atau dengan pembuatan profil.
Waktu eksekusi
Bila ingin menentukan total waktu eksekusi selama runtime, Anda dapat menggunakan
API eksekusi sinkron dan menghitung waktu yang dibutuhkan oleh panggilan. Apabila ingin
menentukan total waktu eksekusi melalui level stack software
yang lebih rendah, Anda dapat menggunakan
ANeuralNetworksExecution_setMeasureTiming
dan
ANeuralNetworksExecution_getDuration
untuk mendapatkan:
- waktu eksekusi pada akselerator (bukan di driver, yang dijalankan pada prosesor host).
- waktu eksekusi pada driver, termasuk waktu pada akselerator.
Waktu eksekusi pada driver tidak mencakup overhead seperti pada runtime itu sendiri dan IPC yang diperlukan oleh runtime untuk berkomunikasi dengan driver.
API ini mengukur durasi antara peristiwa tugas yang dikirimkan dan tugas yang diselesaikan, bukan waktu yang digunakan oleh driver atau akselerator untuk menjalankan inferensi, yang mungkin diganggu oleh peralihan konteks.
Misalnya, jika inferensi 1 dimulai, driver menghentikan tugas untuk menjalankan inferensi 2, lalu melanjutkan dan menyelesaikan inferensi 1, waktu eksekusi untuk inferensi 1 akan mencakup waktu saat tugas dihentikan untuk melakukan inferensi 2.
Informasi waktu ini mungkin berguna untuk deployment produksi aplikasi guna mengumpulkan telemetri untuk penggunaan offline. Anda dapat menggunakan data waktu untuk memodifikasi aplikasi agar performanya lebih baik.
Saat menggunakan fungsi ini, perlu diingat hal berikut:
- Pengumpulan informasi waktu mungkin memengaruhi performa.
- Hanya driver yang dapat menghitung waktu yang dihabiskan pada driver itu sendiri atau pada akselerator, dengan tidak mencakup waktu yang digunakan dalam runtime NNAPI dan pada IPC.
- Anda dapat menggunakan API ini hanya dengan
ANeuralNetworksExecutionyang dibuat denganANeuralNetworksCompilation_createForDevicesbesertanumDevices = 1. - Driver tidak diperlukan untuk dapat melaporkan informasi waktu.
Membuat profil aplikasi dengan Systrace Android
Mulai dari Android 10, NNAPI otomatis menghasilkan peristiwa systrace yang dapat digunakan untuk membuat profil aplikasi.
Sumber NNAPI disertai dengan utilitas parse_systrace untuk memproses
peristiwa systrace yang dihasilkan oleh aplikasi Anda dan membuat tampilan tabel yang menunjukkan
penggunaan waktu dalam berbagai fase siklus proses model (Pembuatan Instance,
Persiapan, Eksekusi dan Penghentian Kompilasi) dan berbagai lapisan
aplikasi tersebut. Lapisan pembagian aplikasi Anda meliputi:
Application: kode aplikasi utamaRuntime: Runtime NNAPIIPC: Komunikasi antarproses antara Runtime NNAPI dan kode DriverDriver: proses driver akselerator.
Membuat data analisis pembuatan profil
Dengan asumsi bahwa Anda telah memeriksa struktur sumber AOSP di $ANDROID_BUILD_TOP dan menggunakan contoh klasifikasi gambar TFLite sebagai aplikasi target, Anda dapat membuat data pembuatan profil NNAPI dengan langkah-langkah berikut:
- Mulai systrace Android dengan perintah berikut:
$ANDROID_BUILD_TOP/external/chromium-trace/systrace.py -o trace.html -a org.tensorflow.lite.examples.classification nnapi hal freq sched idle load binder_driver
Parameter -o trace.html menunjukkan bahwa rekaman aktivitas akan
ditulis dalam trace.html. Saat membuat profil aplikasi Anda sendiri, Anda harus
mengganti org.tensorflow.lite.examples.classification dengan nama proses yang ditentukan
dalam manifes aplikasi.
Tindakan ini akan membuat salah satu konsol shell Anda tetap aktif, dan jangan menjalankan perintah
di latar belakang karena secara interaktif konsol sedang menunggu enter berhenti.
- Setelah kolektor systrace dimulai, mulai aplikasi Anda dan jalankan pengujian tolok ukur.
Dalam situasi ini, Anda dapat memulai aplikasi Klasifikasi Gambar dari Android Studio atau langsung dari UI ponsel pengujian jika aplikasi sudah diinstal. Untuk membuat beberapa data NNAPI, Anda perlu mengonfigurasi aplikasi untuk menggunakan NNAPI dengan memilih NNAPI sebagai perangkat target dalam dialog konfigurasi aplikasi.
Setelah pengujian selesai, hentikan systrace dengan menekan
enterpada terminal konsol yang aktif sejak langkah 1.Jalankan utilitas
systrace_parseruntuk mendapatkan statistik kumulatif:
$ANDROID_BUILD_TOP/frameworks/ml/nn/tools/systrace_parser/parse_systrace.py --total-times trace.html
Parser menerima parameter berikut:
- --total-times: menunjukkan total waktu yang digunakan dalam satu lapisan, termasuk waktu
untuk menunggu eksekusi pada panggilan ke lapisan yang mendasari
- --print-detail: menampilkan semua peristiwa yang telah dikumpulkan dari systrace
- --per-execution: hanya menampilkan eksekusi beserta subfasenya
(sesuai waktu eksekusi), bukan statistik untuk semua fase
- --json: menghasilkan output dalam format JSON
Berikut adalah salah satu contoh output tersebut:
===========================================================================================================================================
NNAPI timing summary (total time, ms wall-clock) Execution
----------------------------------------------------
Initialization Preparation Compilation I/O Compute Results Ex. total Termination Total
-------------- ----------- ----------- ----------- ------------ ----------- ----------- ----------- ----------
Application n/a 19.06 1789.25 n/a n/a 6.70 21.37 n/a 1831.17*
Runtime - 18.60 1787.48 2.93 11.37 0.12 14.42 1.32 1821.81
IPC 1.77 - 1781.36 0.02 8.86 - 8.88 - 1792.01
Driver 1.04 - 1779.21 n/a n/a n/a 7.70 - 1787.95
Total 1.77* 19.06* 1789.25* 2.93* 11.74* 6.70* 21.37* 1.32* 1831.17*
===========================================================================================================================================
* This total ignores missing (n/a) values and thus is not necessarily consistent with the rest of the numbers
Parser mungkin akan gagal jika peristiwa yang dikumpulkan tidak merepresentasikan rekaman aktivitas aplikasi lengkap. Secara khusus, parser mungkin gagal jika ada peristiwa systrace yang dihasilkan untuk menandai akhir bagian dalam rekaman aktivitas tanpa peristiwa awal bagian yang terkait. Ini biasanya terjadi jika ada beberapa peristiwa dari sesi pembuatan profil sebelumnya yang dihasilkan saat Anda memulai kolektor systrace. Dalam hal ini, Anda harus kembali menjalankan pembuatan profil.
Menambahkan statistik untuk kode aplikasi ke output systrace_parser
Aplikasi parse_systrace didasarkan pada fungsi systrace Android bawaan. Anda dapat menambahkan rekaman aktivitas untuk operasi tertentu dalam aplikasi menggunakan API systrace (untuk Java, untuk aplikasi native) dengan nama peristiwa kustom.
Untuk mengaitkan peristiwa kustom dengan fase siklus proses Aplikasi, awali nama peristiwa Anda dengan salah satu string berikut:
[NN_LA_PI]: Peristiwa tingkat aplikasi untuk Inisialisasi[NN_LA_PP]: Peristiwa tingkat aplikasi untuk Persiapan[NN_LA_PC]: Peristiwa tingkat aplikasi untuk Kompilasi[NN_LA_PE]: Peristiwa tingkat aplikasi untuk Eksekusi
Berikut ini adalah contoh bagaimana Anda dapat mengubah kode contoh klasifikasi
gambar TFLite dengan menambahkan bagian runInferenceModel untuk fase Execution dan
lapisan Application yang berisi preprocessBitmap bagian lain yang
tidak akan dipertimbangkan dalam rekaman aktivitas NNAPI. Bagian runInferenceModel akan
menjadi bagian peristiwa systrace yang diproses oleh parser systrace nnapi:
Kotlin
/** Runs inference and returns the classification results. */ fun recognizeImage(bitmap: Bitmap): List{ // This section won’t appear in the NNAPI systrace analysis Trace.beginSection("preprocessBitmap") convertBitmapToByteBuffer(bitmap) Trace.endSection() // Run the inference call. // Add this method in to NNAPI systrace analysis. Trace.beginSection("[NN_LA_PE]runInferenceModel") long startTime = SystemClock.uptimeMillis() runInference() long endTime = SystemClock.uptimeMillis() Trace.endSection() ... return recognitions }
Java
/** Runs inference and returns the classification results. */ public ListrecognizeImage(final Bitmap bitmap) { // This section won’t appear in the NNAPI systrace analysis Trace.beginSection("preprocessBitmap"); convertBitmapToByteBuffer(bitmap); Trace.endSection(); // Run the inference call. // Add this method in to NNAPI systrace analysis. Trace.beginSection("[NN_LA_PE]runInferenceModel"); long startTime = SystemClock.uptimeMillis(); runInference(); long endTime = SystemClock.uptimeMillis(); Trace.endSection(); ... Trace.endSection(); return recognitions; }
Kualitas layanan
Di Android 11 dan yang lebih tinggi, NNAPI membuat kualitas layanan (QoS) menjadi lebih baik dengan memungkinkan aplikasi menunjukkan prioritas relatif modelnya, jumlah waktu maksimum yang diperkirakan untuk menyiapkan model tertentu, dan jumlah waktu maksimum yang diperkirakan untuk menyelesaikan penghitungan tertentu. Android 11 juga memperkenalkan kode hasil NNAPI tambahan yang memungkinkan aplikasi memahami kegagalan seperti batas waktu eksekusi yang terlewat.
Menetapkan prioritas beban kerja
Untuk menetapkan prioritas beban kerja NNAPI, panggil
ANeuralNetworksCompilation_setPriority()
sebelum memanggil ANeuralNetworksCompilation_finish().
Menetapkan batas waktu
Aplikasi dapat menetapkan batas waktu untuk kompilasi dan inferensi model.
- Untuk menetapkan waktu tunggu kompilasi, panggil
ANeuralNetworksCompilation_setTimeout()sebelum memanggilANeuralNetworksCompilation_finish(). - Untuk menetapkan waktu tunggu inferensi, panggil
ANeuralNetworksExecution_setTimeout()sebelum memulai kompilasi.
Selengkapnya tentang operand
Bagian berikut membahas topik lanjutan tentang penggunaan operand.
Tensor terkuantisasi
Tensor terkuantisasi adalah cara ringkas untuk merepresentasikan array n-dimensional dari nilai floating point.
NNAPI mendukung tensor terkuantisasi asimetris 8 bit. Untuk tensor ini, nilai setiap sel dinyatakan dengan bilangan bulat 8 bit. Tensor terkait dengan skala dan nilai zeroPoint yang digunakan untuk mengonversi bilangan bulat 8 bit menjadi nilai floating point yang direpresentasikan.
Rumusnya adalah:
(cellValue - zeroPoint) * scale
ketika nilai zeroPoint adalah bilangan bulat 32 bit dan skalanya adalah nilai floating point 32 bit.
Dibandingkan dengan tensor nilai floating point 32 bit, tensor terkuantisasi 8 bit memiliki dua keunggulan:
- Aplikasi Anda akan berukuran lebih kecil, karena bobot yang dilatih hanyalah seperempat dari ukuran tensor 32 bit.
- Komputasi dapat dijalankan lebih cepat. Hal ini disebabkan kecilnya data yang perlu diambil dari memori dan efisiensi prosesor seperti DSP dalam melakukan perhitungan bilangan bulat.
Meskipun memungkinkan untuk mengubah model floating point menjadi model terkuantisasi, pengalaman kami menunjukkan bahwa melatih model terkuantisasi secara langsung akan memberikan hasil lebih baik. Hasilnya, jaringan neural akan belajar untuk mengompensasi peningkatan granularitas dari masing-masing nilai. Untuk setiap tensor terkuantisasi, skala dan nilai zeroPoint ditetapkan selama proses pelatihan.
Di NNAPI, tentukan jenis tensor terkuantisasi dengan menetapkan kolom jenis
struktur data
ANeuralNetworksOperandType ke
ANEURALNETWORKS_TENSOR_QUANT8_ASYMM.
Selain itu, tentukan juga skala dan nilai zeroPoint tensor dalam struktur
data tersebut.
Selain tensor terkuantisasi asimetris 8-bit, NNAPI juga mendukung:
ANEURALNETWORKS_TENSOR_QUANT8_SYMM_PER_CHANNELyang dapat digunakan untuk merepresentasikan bobot ke operasiCONV/DEPTHWISE_CONV/TRANSPOSED_CONV.ANEURALNETWORKS_TENSOR_QUANT16_ASYMMyang dapat digunakan untuk status internalQUANTIZED_16BIT_LSTM.ANEURALNETWORKS_TENSOR_QUANT8_SYMMyang dapat menjadi input bagiANEURALNETWORKS_DEQUANTIZE.
Operand opsional
Beberapa operasi, seperti
ANEURALNETWORKS_LSH_PROJECTION,
mengambil operand opsional. Untuk menunjukkan dalam model bahwa operand opsional
dihilangkan, panggil
fungsi ANeuralNetworksModel_setOperandValue(),
dengan meluluskan NULL untuk buffer dan 0 untuk panjang.
Jika keputusan tentang ada atau tidaknya operand akan berbeda-beda untuk setiap
eksekusi, tunjukkan bahwa operand dihilangkan menggunakan
fungsi ANeuralNetworksExecution_setInput()
atau
ANeuralNetworksExecution_setOutput(),
dengan meluluskan NULL untuk buffer dan 0 untuk panjang.
Tensor urutan yang tidak diketahui
Android 9 (API level 28) memperkenalkan operand model dengan dimensi yang tidak diketahui, tetapi dengan urutan (jumlah dimensi) yang diketahui. Android 10 (API level 29) memperkenalkan tensor dengan urutan yang tidak diketahui, seperti yang ditunjukkan dalam ANeuralNetworksOperandType.
Tolok ukur NNAPI
Tolok ukur NNAPI tersedia pada AOSP di platform/test/mlts/benchmark
(aplikasi tolok ukur) dan platform/test/mlts/models (model dan set data).
Tolok ukur mengevaluasi latensi dan akurasi serta membandingkan driver ke tugas yang sama yang dilakukan menggunakan Tensorflow Lite yang berjalan di CPU, untuk model dan set data yang sama.
Untuk menggunakan tolok ukur, lakukan tindakan berikut:
Hubungkan perangkat Android target ke komputer, buka jendela terminal, dan pastikan perangkat dapat dijangkau melalui adb.
Jika lebih dari satu perangkat Android yang terhubung, ekspor variabel lingkungan
ANDROID_SERIALperangkat target.Buka direktori sumber level teratas Android.
Jalankan perintah berikut:
lunch aosp_arm-userdebug # Or aosp_arm64-userdebug if available ./test/mlts/benchmark/build_and_run_benchmark.sh
Di akhir proses tolok ukur, hasilnya akan ditampilkan sebagai halaman HTML yang diteruskan ke
xdg-open.
Log NNAPI
NNAPI membuat informasi diagnostik yang berguna dalam log sistem. Untuk menganalisis log, gunakan utilitas logcat.
Aktifkan logging panjang NNAPI untuk fase atau komponen tertentu dengan menetapkan
properti debug.nn.vlog (menggunakan adb shell) ke daftar nilai berikut,
dipisahkan dengan spasi, titik dua, atau koma:
model: Pembuatan modelcompilation: Pembuatan rencana eksekusi dan kompilasi modelexecution: Eksekusi modelcpuexe: Eksekusi operasi menggunakan implementasi CPU NNAPImanager: Ekstensi NNAPI, antarmuka yang tersedia, dan info yang terkait dengan kemampuanallatau1: Semua elemen di atas
Misalnya, untuk mengaktifkan logging panjang penuh, gunakan perintah
adb shell setprop debug.nn.vlog all. Untuk menonaktifkan logging panjang, gunakan perintah
adb shell setprop debug.nn.vlog '""'.
Setelah diaktifkan, logging panjang akan menghasilkan entri log pada level INFO dengan tag yang ditentukan sesuai nama komponen atau fase.
Selain pesan yang dikontrol debug.nn.vlog, komponen NNAPI API menyediakan
entri log lainnya di berbagai level, masing-masing menggunakan tag log tertentu.
Untuk mendapatkan daftar komponen, telusuri struktur sumber menggunakan ekspresi berikut:
grep -R 'define LOG_TAG' | awk -F '"' '{print $2}' | sort -u | egrep -v "Sample|FileTag|test"
Saat ini, ekspresi ini akan menampilkan tag berikut:
- BurstBuilder
- Callbacks
- CompilationBuilder
- CpuExecutor
- ExecutionBuilder
- ExecutionBurstController
- ExecutionBurstServer
- ExecutionPlan
- FibonacciDriver
- GraphDump
- IndexedShapeWrapper
- IonWatcher
- Manager
- Memory
- MemoryUtils
- MetaModel
- ModelArgumentInfo
- ModelBuilder
- NeuralNetworks
- OperationResolver
- Operations
- OperationsUtils
- PackageInfo
- TokenHasher
- TypeManager
- Utils
- ValidateHal
- VersionedInterfaces
Untuk mengontrol level pesan log yang ditampilkan oleh logcat, gunakan
variabel lingkungan ANDROID_LOG_TAGS.
Untuk menampilkan kumpulan lengkap pesan log NNAPI dan menonaktifkan lainnya, tetapkan ANDROID_LOG_TAGS
seperti berikut:
BurstBuilder:V Callbacks:V CompilationBuilder:V CpuExecutor:V ExecutionBuilder:V ExecutionBurstController:V ExecutionBurstServer:V ExecutionPlan:V FibonacciDriver:V GraphDump:V IndexedShapeWrapper:V IonWatcher:V Manager:V MemoryUtils:V Memory:V MetaModel:V ModelArgumentInfo:V ModelBuilder:V NeuralNetworks:V OperationResolver:V OperationsUtils:V Operations:V PackageInfo:V TokenHasher:V TypeManager:V Utils:V ValidateHal:V VersionedInterfaces:V *:S.
Anda dapat menetapkan ANDROID_LOG_TAGS menggunakan perintah berikut:
export ANDROID_LOG_TAGS=$(grep -R 'define LOG_TAG' | awk -F '"' '{ print $2 ":V" }' | sort -u | egrep -v "Sample|FileTag|test" | xargs echo -n; echo ' *:S')
Perlu diketahui bahwa kode ini hanyalah filter yang berlaku untuk logcat. Anda tetap harus
menyetel properti debug.nn.vlog ke all untuk menghasilkan info log panjang.