
Android Neural Networks API (NNAPI) 是一个 Android C API,专为在 Android 设备上运行计算密集型运算从而实现机器学习而设计。NNAPI 旨在为更高层级的机器学习框架(如 TensorFlow Lite 和 Caffe2)提供一个基本功能层,用来建立和训练神经网络。搭载 Android 8.1(API 级别 27)或更高版本的所有 Android 设备上都提供该 API,但该 API 已在 Android 15 中被弃用。
NNAPI 支持通过将 Android 设备中的数据应用到先前训练的开发者定义的模型来进行推断。推断的示例包括为图像分类、预测用户行为以及选择针对搜索查询的适当响应。
在设备上进行推断具备诸多优势:
- 延迟:您不需要通过网络连接发送请求并等待响应。例如,这对处理从相机传入的连续帧的视频应用至关重要。
- 可用性:即使在网络覆盖范围之外,应用也能运行。
- 速度:专用于神经网络处理的新硬件提供的计算速度明显快于单纯的通用 CPU。
- 隐私:数据不会离开 Android 设备。
- 费用:所有计算都在 Android 设备上执行,不需要服务器场。
开发者还应在以下几个方面做出权衡取舍:
- 系统利用率:评估神经网络涉及大量的计算,而这可能会增加电池电量消耗。如果您担心自己的应用耗电量会增加(尤其是对于长时间运行的计算),应考虑监控电池运行状况。
- 应用大小:应注意模型的大小。模型可能会占用数 MB 的空间。如果在您的 APK 中绑定较大的模型会对用户造成过度影响,那么您可能需要考虑在应用安装后下载模型、使用较小的模型或在云端运行计算。NNAPI 未提供在云端运行模型的功能。
请参阅 Android Neural Networks API 示例,查看关于如何使用 NNAPI 的一个示例。
了解 Neural Networks API 运行时
NNAPI 应由机器学习库、框架和工具调用,这样可让开发者在设备外训练他们的模型,并将其部署在 Android 设备上。应用一般不会直接使用 NNAPI,而会使用更高层级的机器学习框架。这些框架进而又可以使用 NNAPI 在受支持的设备上执行硬件加速的推断运算。
根据应用的要求和 Android 设备的硬件功能,Android 的神经网络运行时可以在可用的设备上处理器(包括专用的神经网络硬件、图形处理单元 (GPU) 和数字信号处理器 (DSP))之间高效地分配计算工作负载。
对于缺少专用供应商驱动程序的 Android 设备,NNAPI 运行时将在 CPU 上执行请求。
图 1 所示为 NNAPI 的简要系统架构。
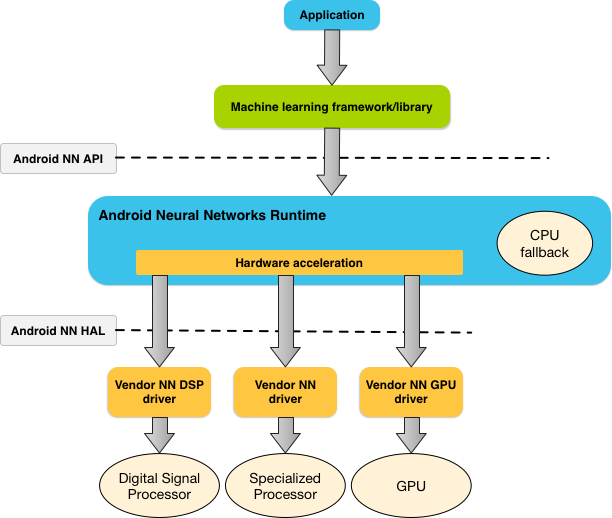
Neural Networks API 编程模型
若要使用 NNAPI 执行计算,您需要先构造一张有向图来定义要执行的计算。此计算图与您的输入数据(例如,从机器学习框架传递过来的权重和偏差)相结合,构成 NNAPI 运行时求值的模型。
NNAPI 使用四个主要抽象概念:
- 模型:由数学运算和通过训练过程学习到的常量值构成的计算图。这些运算特定于神经网络。它们包括二维 (2D) 卷积、逻辑 (sigmoid) 激活函数、修正线性 (ReLU) 激活函数等。创建模型是一项同步操作。成功创建后,便可在线程和编译之间重用模型。在 NNAPI 中,模型表示为
ANeuralNetworksModel实例。 - 编译:表示用于将 NNAPI 模型编译到更低级别代码中的配置。创建编译是一项同步操作。成功创建后,便可在线程和执行之间重用编译。在 NNAPI 中,每个编译都表示为一个
ANeuralNetworksCompilation实例。 - 内存:表示共享内存、内存映射文件和类似内存缓冲区。使用内存缓冲区可让 NNAPI 运行时更高效地将数据传输到驱动程序。应用一般会创建一个共享内存缓冲区,其中包含定义模型所需的每个张量。您还可以使用内存缓冲区来存储执行实例的输入和输出。在 NNAPI 中,每个内存缓冲区均表示为一个
ANeuralNetworksMemory实例。 执行:用于将 NNAPI 模型应用到一组输入并收集结果的接口。执行可以同步执行,也可以异步执行。
对于异步执行,多个线程可以等待同一执行。此执行完成后,所有线程都被释放。
在 NNAPI 中,每次执行均表示为一个
ANeuralNetworksExecution实例。
图 2 显示了基本的编程流程。
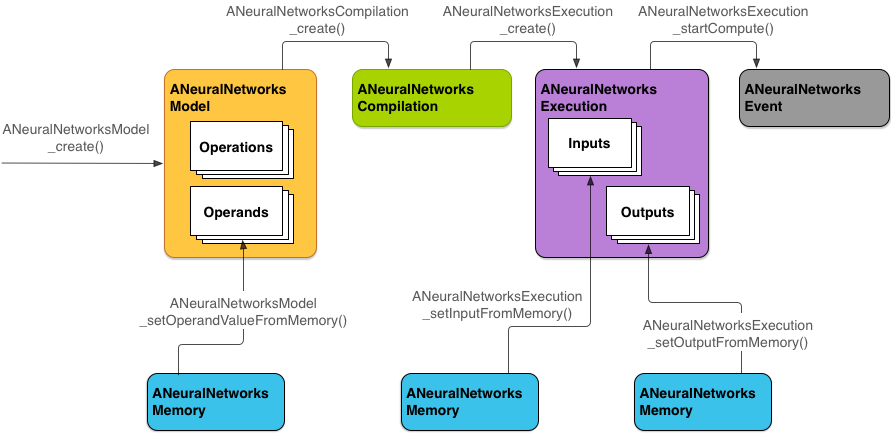
本部分的其余内容将介绍一些具体步骤,说明如何设置 NNAPI 模型以执行计算、编译模型并执行编译的模型。
提供训练数据访问权限
您的训练权重和偏差数据可能存储在一个文件中。如需为 NNAPI 运行时提供对此类数据的高效访问途径,请通过调用 ANeuralNetworksMemory_createFromFd() 函数并传入已打开的数据文件的文件描述符来创建 ANeuralNetworksMemory 实例。您也可以指定内存保护标记和文件中共享内存区域开始处的偏移。
// Create a memory buffer from the file that contains the trained data
ANeuralNetworksMemory* mem1 = NULL;
int fd = open("training_data", O_RDONLY);
ANeuralNetworksMemory_createFromFd(file_size, PROT_READ, fd, 0, &mem1);
虽然在本示例中,我们仅对所有权重使用一个 ANeuralNetworksMemory 实例,但可以为多个文件使用多个 ANeuralNetworksMemory 实例。
使用原生硬件缓冲区
您可以将原生硬件缓冲区用于模型输入、输出和常量运算数值。在某些情况下,NNAPI 加速器可以访问 AHardwareBuffer 对象,而无需驱动程序复制数据。AHardwareBuffer 具有许多不同的配置,并非每个 NNAPI 加速器都支持所有这些配置。由于存在此限制,因此请参阅 ANeuralNetworksMemory_createFromAHardwareBuffer 参考文档中列出的约束条件,并提前在目标设备上进行测试,以确保使用 AHardwareBuffer 的编译和执行的行为符合预期(使用设备分配指定加速器)。
若要允许 NNAPI 运行时访问 AHardwareBuffer 对象,请通过调用 ANeuralNetworksMemory_createFromAHardwareBuffer 函数并传入 AHardwareBuffer 对象来创建 ANeuralNetworksMemory 实例,如以下代码示例所示:
// Configure and create AHardwareBuffer object AHardwareBuffer_Desc desc = ... AHardwareBuffer* ahwb = nullptr; AHardwareBuffer_allocate(&desc, &ahwb); // Create ANeuralNetworksMemory from AHardwareBuffer ANeuralNetworksMemory* mem2 = NULL; ANeuralNetworksMemory_createFromAHardwareBuffer(ahwb, &mem2);
当 NNAPI 不再需要访问 AHardwareBuffer 对象时,释放相应的 ANeuralNetworksMemory 实例:
ANeuralNetworksMemory_free(mem2);
注意:
- 您只能对整个缓冲区使用
AHardwareBuffer,而不能将其与ARect参数配合使用。 - NNAPI 运行时不会刷新缓冲区。在安排执行之前,您需要确保输入和输出缓冲区可访问。
- 不支持同步栅栏文件描述符。
- 对于具有供应商特定格式和使用位的
AHardwareBuffer,由供应商实现来决定客户端或驱动程序是否负责刷新缓存。
模型
模型是 NNAPI 中的基本计算单位。每个模型都由一个或多个运算数和运算定义。
运算数
运算数是用于定义图表的数据对象,其中包括模型的输入和输出、包含从一项运算流向另一项运算的数据的中间节点,以及传递给这些运算的常量。
可以向 NNAPI 模型添加两种类型的运算数:标量和张量。
标量表示单个值。NNAPI 支持采用布尔值、16 位浮点值、32 位浮点值、32 位整数和无符号 32 位整数格式的标量值。
NNAPI 中的大多数运算都涉及张量。张量是 N 维数组。NNAPI 支持具有 16 位浮点值、32 位浮点值、8 位量化值、16 位量化值、32 位整数和 8 位布尔值的张量。
例如,图 3 表示一个包含两项运算(先加法后乘法)的模型。该模型接受一个输入张量,并生成一个输出张量。

上面的模型有七个运算数。这些运算数由它们添加到模型的顺序的索引来隐式标识。添加的第一个运算数的索引为 0,第二个运算数的索引为 1,依此类推。运算数 1、2、3 和 5 是常量运算数。
添加运算数的顺序无关紧要。例如,模型输出运算数可能是添加的第一个运算数。重要的是在引用运算数时使用正确的索引值。
运算数具有类型。这些类型在运算数添加到模型时指定。
一个运算数不能同时用作模型的输入和输出。
每个运算数必须是一项运算的模型输入、常量或输出运算数。
如需详细了解如何使用运算数,请参阅运算数详细说明。
运算
运算指定要执行的计算。每项运算都由下面这些元素组成:
- 运算类型(例如,加法、乘法、卷积),
- 运算用于输入的运算数索引列表,以及
- 运算用于输出的运算数索引列表。
这些列表中的索引顺序非常重要;如需了解每种运算类型的预期输入和输出,请参阅 NNAPI API 参考文档。
在添加运算之前,您必须先将运算消耗或生成的运算数添加到模型。
添加运算的顺序无关紧要。NNAPI 依靠由运算数和运算的计算图建立的依赖关系来确定运算的执行顺序。
下表汇总了 NNAPI 支持的运算:
API 级别 28 中的已知问题:将 ANEURALNETWORKS_TENSOR_QUANT8_ASYMM 张量传递给 Android 9(API 级别 28)及更高版本中提供的 ANEURALNETWORKS_PAD 运算时,NNAPI 的输出可能与更高层级机器学习框架(如 TensorFlow Lite)的输出不匹配。您应改为只传递 ANEURALNETWORKS_TENSOR_FLOAT32。该问题在 Android 10(API 级别 29)及更高版本中已解决。
构建模型
在下面的示例中,我们创建了图 3 中所示的双运算模型。
如需构建模型,请按以下步骤操作:
调用
ANeuralNetworksModel_create()函数来定义空模型。ANeuralNetworksModel* model = NULL; ANeuralNetworksModel_create(&model);
通过调用
ANeuralNetworks_addOperand()将运算数添加到模型中。它们的数据类型使用ANeuralNetworksOperandType数据结构定义。// In our example, all our tensors are matrices of dimension [3][4] ANeuralNetworksOperandType tensor3x4Type; tensor3x4Type.type = ANEURALNETWORKS_TENSOR_FLOAT32; tensor3x4Type.scale = 0.f; // These fields are used for quantized tensors tensor3x4Type.zeroPoint = 0; // These fields are used for quantized tensors tensor3x4Type.dimensionCount = 2; uint32_t dims[2] = {3, 4}; tensor3x4Type.dimensions = dims;
// We also specify operands that are activation function specifiers ANeuralNetworksOperandType activationType; activationType.type = ANEURALNETWORKS_INT32; activationType.scale = 0.f; activationType.zeroPoint = 0; activationType.dimensionCount = 0; activationType.dimensions = NULL;
// Now we add the seven operands, in the same order defined in the diagram ANeuralNetworksModel_addOperand(model, &tensor3x4Type); // operand 0 ANeuralNetworksModel_addOperand(model, &tensor3x4Type); // operand 1 ANeuralNetworksModel_addOperand(model, &activationType); // operand 2 ANeuralNetworksModel_addOperand(model, &tensor3x4Type); // operand 3 ANeuralNetworksModel_addOperand(model, &tensor3x4Type); // operand 4 ANeuralNetworksModel_addOperand(model, &activationType); // operand 5 ANeuralNetworksModel_addOperand(model, &tensor3x4Type); // operand 6对于具有常量值的运算数,例如应用从训练过程获得的权重和偏差,请使用
ANeuralNetworksModel_setOperandValue()和ANeuralNetworksModel_setOperandValueFromMemory()函数。在以下示例中,我们从训练数据文件中设置常量值,该值与我们在提供训练数据访问权限中创建的内存缓冲区对应。
// In our example, operands 1 and 3 are constant tensors whose values were // established during the training process const int sizeOfTensor = 3 * 4 * 4; // The formula for size calculation is dim0 * dim1 * elementSize ANeuralNetworksModel_setOperandValueFromMemory(model, 1, mem1, 0, sizeOfTensor); ANeuralNetworksModel_setOperandValueFromMemory(model, 3, mem1, sizeOfTensor, sizeOfTensor);
// We set the values of the activation operands, in our example operands 2 and 5 int32_t noneValue = ANEURALNETWORKS_FUSED_NONE; ANeuralNetworksModel_setOperandValue(model, 2, &noneValue, sizeof(noneValue)); ANeuralNetworksModel_setOperandValue(model, 5, &noneValue, sizeof(noneValue));对于要计算的有向图中的每个运算,通过调用
ANeuralNetworksModel_addOperation()函数将该运算添加到模型中。您的应用必须以此调用的参数形式提供以下各项:
- 运算类型
- 输入值的计数
- 输入运算数的索引的数组
- 输出值的计数
- 输出运算数的索引数组
请注意,一个运算数不能同时用于同一运算的输入和输出。
// We have two operations in our example // The first consumes operands 1, 0, 2, and produces operand 4 uint32_t addInputIndexes[3] = {1, 0, 2}; uint32_t addOutputIndexes[1] = {4}; ANeuralNetworksModel_addOperation(model, ANEURALNETWORKS_ADD, 3, addInputIndexes, 1, addOutputIndexes);
// The second consumes operands 3, 4, 5, and produces operand 6 uint32_t multInputIndexes[3] = {3, 4, 5}; uint32_t multOutputIndexes[1] = {6}; ANeuralNetworksModel_addOperation(model, ANEURALNETWORKS_MUL, 3, multInputIndexes, 1, multOutputIndexes);通过调用
ANeuralNetworksModel_identifyInputsAndOutputs()函数,确定模型应将哪些运算数视为其输入和输出。// Our model has one input (0) and one output (6) uint32_t modelInputIndexes[1] = {0}; uint32_t modelOutputIndexes[1] = {6}; ANeuralNetworksModel_identifyInputsAndOutputs(model, 1, modelInputIndexes, 1 modelOutputIndexes);
可以通过调用
ANeuralNetworksModel_relaxComputationFloat32toFloat16()来指定是否允许计算范围或精度像 IEEE 754 16 位浮点格式的范围或精度一样低的ANEURALNETWORKS_TENSOR_FLOAT32。调用
ANeuralNetworksModel_finish()来完成模型的定义。如果没有出现错误,此函数将返回结果代码ANEURALNETWORKS_NO_ERROR。ANeuralNetworksModel_finish(model);
创建模型后,您可以对其进行任意次数的编译,并可以对每项编译执行任意次数。
控制流
如需在 NNAPI 模型中纳入控制流,请执行以下操作:
构造相应的执行子图(
IF语句的then和else子图,WHILE循环的condition和body子图)作为独立的ANeuralNetworksModel*模型:ANeuralNetworksModel* thenModel = makeThenModel(); ANeuralNetworksModel* elseModel = makeElseModel();
在包含控制流的模型中创建引用这些模型的操作数:
ANeuralNetworksOperandType modelType = { .type = ANEURALNETWORKS_MODEL, }; ANeuralNetworksModel_addOperand(model, &modelType); // kThenOperandIndex ANeuralNetworksModel_addOperand(model, &modelType); // kElseOperandIndex ANeuralNetworksModel_setOperandValueFromModel(model, kThenOperandIndex, &thenModel); ANeuralNetworksModel_setOperandValueFromModel(model, kElseOperandIndex, &elseModel);
添加控制流运算:
uint32_t inputs[] = {kConditionOperandIndex, kThenOperandIndex, kElseOperandIndex, kInput1, kInput2, kInput3}; uint32_t outputs[] = {kOutput1, kOutput2}; ANeuralNetworksModel_addOperation(model, ANEURALNETWORKS_IF, std::size(inputs), inputs, std::size(output), outputs);
编译
编译步骤可确定您的模型将在哪些处理器上执行,并会要求对应的驱动程序为其执行操作做好准备。这可能包括生成运行模型的处理器专用的机器代码。
如需编译模型,请按以下步骤操作:
调用
ANeuralNetworksCompilation_create()函数以创建新的编译实例。// Compile the model ANeuralNetworksCompilation* compilation; ANeuralNetworksCompilation_create(model, &compilation);
您可以选择使用设备分配来明确选择要在哪些设备上执行。
您可以选择性地控制运行时如何在电池电量消耗与执行速度之间权衡取舍。您可以通过调用
ANeuralNetworksCompilation_setPreference()来完成此操作。// Ask to optimize for low power consumption ANeuralNetworksCompilation_setPreference(compilation, ANEURALNETWORKS_PREFER_LOW_POWER);
您可以指定的偏好设置包括:
ANEURALNETWORKS_PREFER_LOW_POWER:倾向于以最大限度减少电池消耗的方式执行。这种设置适合经常执行的编译。ANEURALNETWORKS_PREFER_FAST_SINGLE_ANSWER:倾向于尽快返回单个答案,即使这会耗费更多电量。这是默认值。ANEURALNETWORKS_PREFER_SUSTAINED_SPEED:倾向于最大限度地提高连续帧的吞吐量,例如,在处理来自相机的连续帧时。
您可以选择通过调用
ANeuralNetworksCompilation_setCaching来设置编译缓存。// Set up compilation caching ANeuralNetworksCompilation_setCaching(compilation, cacheDir, token);
为
cacheDir使用getCodeCacheDir()。指定的token对应用内的每个模型而言必须是唯一的。通过调用
ANeuralNetworksCompilation_finish()完成编译定义。如果没有出现错误,此函数将返回结果代码ANEURALNETWORKS_NO_ERROR。ANeuralNetworksCompilation_finish(compilation);
设备发现和分配
在搭载 Android 10(API 级别 29)及更高版本的 Android 设备上,NNAPI 提供了一些函数,可让机器学习框架库和应用获取有关可用设备的信息,并指定要用于执行的设备。通过提供有关可用设备的信息,可让应用获取设备上安装的驱动程序的确切版本,从而避免出现已知的不兼容性。通过让应用能够指定哪些设备要执行模型的不同部分,应用可以针对部署它们的 Android 设备进行优化。
设备发现
使用 ANeuralNetworks_getDeviceCount 获取可用设备的数量。对于每台设备,请使用 ANeuralNetworks_getDevice 将 ANeuralNetworksDevice 实例设置为对该设备的引用。
设置设备引用后,您可以使用以下函数找到有关该设备的其他信息:
ANeuralNetworksDevice_getFeatureLevelANeuralNetworksDevice_getNameANeuralNetworksDevice_getTypeANeuralNetworksDevice_getVersion
设备分配
使用 ANeuralNetworksModel_getSupportedOperationsForDevices 可了解模型的哪些运算可以在特定设备上运行。
如需控制用于执行的加速器,请调用 ANeuralNetworksCompilation_createForDevices 而不是 ANeuralNetworksCompilation_create。像往常一样使用生成的 ANeuralNetworksCompilation 对象。如果提供的模型包含选定设备不支持的运算,此函数将返回错误。
如果指定了多个设备,运行时将负责在设备之间分配工作。
与其他设备类似,NNAPI CPU 实现由 ANeuralNetworksDevice 表示,其名称为 nnapi-reference 且类型为 ANEURALNETWORKS_DEVICE_TYPE_CPU。调用 ANeuralNetworksCompilation_createForDevices 时,CPU 实现不用于处理模型编译和执行失败的情况。
应用负责将模型分区为可以在指定设备上运行的子模型。不需要对模型进行手动分区的应用应继续调用比较简单的 ANeuralNetworksCompilation_create,以使用所有可用设备(包括 CPU)来为模型加速。如果您使用 ANeuralNetworksCompilation_createForDevices 指定的设备无法完全支持相应的模型,将会返回 ANEURALNETWORKS_BAD_DATA。
模型分区
当模型有多个设备时,NNAPI 运行时会跨设备分配工作。例如,如果向 ANeuralNetworksCompilation_createForDevices 提供多个设备,在分配工作时将会考虑所有指定的设备。请注意,如果 CPU 设备不在列表中,CPU 执行将被停用。使用 ANeuralNetworksCompilation_create 时,系统会考虑所有可用的设备,包括 CPU。
通过从可用设备列表中为模型中的每个操作选择支持操作的设备,并声明最佳性能(即最快的执行时间或最低的功耗)来完成分发,具体取决于客户端指定的执行偏好。此分区算法不考虑不同处理器之间的 IO 可能导致的低效率,因此,在指定多个处理器时(使用 ANeuralNetworksCompilation_createForDevices 明确指定或使用 ANeuralNetworksCompilation_create 隐式指定),对应用进行性能剖析至关重要。
如需了解 NNAPI 如何对模型进行分区,请在 Android 日志中查找消息(在带有标签 ExecutionPlan 的 INFO 级别查找):
ModelBuilder::findBestDeviceForEachOperation(op-name): device-index
op-name 是图表中运算的描述性名称,device-index 是设备列表中候选设备的索引。此列表是提供给 ANeuralNetworksCompilation_createForDevices 的输入,如果使用 ANeuralNetworksCompilation_createForDevices,那就是在所有使用 ANeuralNetworks_getDeviceCount 和 ANeuralNetworks_getDevice 的设备上进行迭代时返回的设备列表。
消息(在带有标签 ExecutionPlan 的 INFO 级别):
ModelBuilder::partitionTheWork: only one best device: device-name
此消息表明整个图表已在设备 device-name 上加速。
执行
执行步骤会将模型应用到一组输入,并将计算输出存储到一个或多个用户缓冲区或者您的应用分配的内存空间。
如需执行编译的模型,请按以下步骤操作:
调用
ANeuralNetworksExecution_create()函数以创建新的执行实例。// Run the compiled model against a set of inputs ANeuralNetworksExecution* run1 = NULL; ANeuralNetworksExecution_create(compilation, &run1);
指定您的应用在何处读取计算的输入值。您的应用可以通过分别调用
ANeuralNetworksExecution_setInput()或ANeuralNetworksExecution_setInputFromMemory()从用户缓冲区或已分配的内存空间读取输入值。// Set the single input to our sample model. Since it is small, we won't use a memory buffer float32 myInput[3][4] = { ...the data... }; ANeuralNetworksExecution_setInput(run1, 0, NULL, myInput, sizeof(myInput));
指定您的应用在何处写入输出值。您的应用可以通过分别调用
ANeuralNetworksExecution_setOutput()或ANeuralNetworksExecution_setOutputFromMemory()将输出值写入用户缓冲区或已分配的内存空间。// Set the output float32 myOutput[3][4]; ANeuralNetworksExecution_setOutput(run1, 0, NULL, myOutput, sizeof(myOutput));
通过调用
ANeuralNetworksExecution_startCompute()函数,安排开始执行。如果没有出现错误,此函数将返回结果代码ANEURALNETWORKS_NO_ERROR。// Starts the work. The work proceeds asynchronously ANeuralNetworksEvent* run1_end = NULL; ANeuralNetworksExecution_startCompute(run1, &run1_end);
调用
ANeuralNetworksEvent_wait()函数以等待执行完成。如果执行成功,此函数将返回结果代码ANEURALNETWORKS_NO_ERROR。等待可以在不同于开始执行的线程上完成。// For our example, we have no other work to do and will just wait for the completion ANeuralNetworksEvent_wait(run1_end); ANeuralNetworksEvent_free(run1_end); ANeuralNetworksExecution_free(run1);
您可以选择通过使用同一编译实例将不同的输入集应用于已编译的模型,从而创建新的
ANeuralNetworksExecution实例。// Apply the compiled model to a different set of inputs ANeuralNetworksExecution* run2; ANeuralNetworksExecution_create(compilation, &run2); ANeuralNetworksExecution_setInput(run2, ...); ANeuralNetworksExecution_setOutput(run2, ...); ANeuralNetworksEvent* run2_end = NULL; ANeuralNetworksExecution_startCompute(run2, &run2_end); ANeuralNetworksEvent_wait(run2_end); ANeuralNetworksEvent_free(run2_end); ANeuralNetworksExecution_free(run2);
同步执行
异步执行需要花费时间来衍生和同步线程。此外,延迟时间可能变化很大,从通知或唤醒线程的时间到线程最终绑定到 CPU 核心的时间,最长延迟时间长达 500 微秒。
为了缩短延迟时间,您可以改为指示应用对运行时进行同步推断调用。该调用将仅在推断完成后返回,而不是在推断开始后返回。应用调用 ANeuralNetworksExecution_compute 以便对运行时进行同步调用,而不是调用 ANeuralNetworksExecution_startCompute 对运行时进行异步推断调用。对 ANeuralNetworksExecution_compute 的调用不会使用 ANeuralNetworksEvent,也不会与对 ANeuralNetworksEvent_wait 的调用配对。
突发执行
在搭载 Android 10(API 级别 29)及更高版本的 Android 设备上,NNAPI 支持通过 ANeuralNetworksBurst 对象进行突发执行。突发执行是快速连续发生的同一编译的一系列执行,例如对相机拍摄的帧或连续音频样本的执行。使用 ANeuralNetworksBurst 对象可以提高执行速度,因为这些对象会向加速器指示可以在执行之间重复使用资源,并且加速器应在爆发持续时间内保持高性能状态。
ANeuralNetworksBurst 只是对正常的执行路径稍作改动。使用 ANeuralNetworksBurst_create 创建爆发对象,如以下代码段所示:
// Create burst object to be reused across a sequence of executions ANeuralNetworksBurst* burst = NULL; ANeuralNetworksBurst_create(compilation, &burst);
突发执行是同步的。但是,请不要使用 ANeuralNetworksExecution_compute 执行各个推断,而是在对函数 ANeuralNetworksExecution_burstCompute 的调用中将各种 ANeuralNetworksExecution 对象与相同的 ANeuralNetworksBurst 配对。
// Create and configure first execution object // ... // Execute using the burst object ANeuralNetworksExecution_burstCompute(execution1, burst); // Use results of first execution and free the execution object // ... // Create and configure second execution object // ... // Execute using the same burst object ANeuralNetworksExecution_burstCompute(execution2, burst); // Use results of second execution and free the execution object // ...
如果不再需要 ANeuralNetworksBurst 对象,请使用 ANeuralNetworksBurst_free 将其释放。
// Cleanup ANeuralNetworksBurst_free(burst);
异步命令队列和围栏执行
在 Android 11 及更高版本中,NNAPI 还支持通过 ANeuralNetworksExecution_startComputeWithDependencies() 方法调度异步执行。使用此方法时,执行将等待所有依赖事件都收到信号通知,然后再开始评估。一旦执行完成并且输出可供使用,返回的事件就会收到信号通知。
该事件可能由同步栅栏提供支持,具体取决于在哪些设备上处理执行任务。您必须调用 ANeuralNetworksEvent_wait() 来等待事件,并恢复执行使用的资源。您可以使用 ANeuralNetworksEvent_createFromSyncFenceFd() 将同步栅栏导入事件对象,并可以使用 ANeuralNetworksEvent_getSyncFenceFd() 从事件对象导出同步栅栏。
大小动态变化的输出
如需支持输出大小取决于输入数据(即,在模型执行时无法确定大小)的模型,请使用 ANeuralNetworksExecution_getOutputOperandRank 和 ANeuralNetworksExecution_getOutputOperandDimensions。
以下代码示例展示了如何执行此操作:
// Get the rank of the output uint32_t myOutputRank = 0; ANeuralNetworksExecution_getOutputOperandRank(run1, 0, &myOutputRank); // Get the dimensions of the output std::vector<uint32_t> myOutputDimensions(myOutputRank); ANeuralNetworksExecution_getOutputOperandDimensions(run1, 0, myOutputDimensions.data());
清理
清理步骤可以释放用于计算的内部资源。
// Cleanup ANeuralNetworksCompilation_free(compilation); ANeuralNetworksModel_free(model); ANeuralNetworksMemory_free(mem1);
错误管理和 CPU 回退
如果在分区过程中出现错误、驱动程序无法编译模型(或模型的一部分),或者驱动程序无法执行已编译的模型(或模型的一部分),NNAPI 可能会回退到其自身的一种或多种操作的 CPU 实现。
如果 NNAPI 客户端包含优化版本的操作(例如,TFLite),通过客户端的优化操作实现来停用 CPU 回退和处理故障具有优势。
在 Android 10 中,如果使用 ANeuralNetworksCompilation_createForDevices 执行编译,CPU 回退将停用。
在 Android P 中,如果驱动程序上的执行失败,NNAPI 执行会回退到 CPU。在使用 ANeuralNetworksCompilation_create 而不是 ANeuralNetworksCompilation_createForDevices 时,在 Android 10 上也是如此。
第一次执行会针对该单个分区进行回退,如果仍然失败,将会在 CPU 上重试整个模型。
如果分区或编译失败,将在 CPU 上尝试运行整个模型。
在某些情况下,某些操作不受 CPU 支持,如果不受支持,编译或执行将会失败,而不会退回。
即使在停用 CPU 回退之后,模型中仍可能有操作会安排在 CPU 上运行。如果 CPU 位于提供给 ANeuralNetworksCompilation_createForDevices 的处理器列表中,并且是唯一支持这些操作的处理器,或者是针对这些操作的性能最佳的处理器,它会被选为主要(非回退)执行程序。
为了确保没有 CPU 执行,请在排除设备列表中的 nnapi-reference 的同时使用 ANeuralNetworksCompilation_createForDevices。从 Android P 开始,通过将 debug.nn.partition 属性设置为 2,可以在调试 build 上停用在执行时实施回退。
内存域
在 Android 11 及更高版本中,NNAPI 支持为不透明内存提供分配器接口的内存域。这样应用可以在执行过程中传递设备原生内存,以便 NNAPI 在同一驱动程序上进行连续执行时不会进行不必要的数据复制或转换。
内存域功能适用于主要在驱动程序内部使用且无需频繁访问客户端的张量。此类张量的示例包括序列模型中的状态张量。对于需要在客户端上频繁访问 CPU 的张量,请改用共享内存池。
如需分配不透明内存,请执行以下步骤:
调用
ANeuralNetworksMemoryDesc_create()函数来创建新的内存描述符:// Create a memory descriptor ANeuralNetworksMemoryDesc* desc; ANeuralNetworksMemoryDesc_create(&desc);
通过调用
ANeuralNetworksMemoryDesc_addInputRole()和ANeuralNetworksMemoryDesc_addOutputRole()指定所有预期的输入和输出角色。// Specify that the memory may be used as the first input and the first output // of the compilation ANeuralNetworksMemoryDesc_addInputRole(desc, compilation, 0, 1.0f); ANeuralNetworksMemoryDesc_addOutputRole(desc, compilation, 0, 1.0f);
(可选)通过调用
ANeuralNetworksMemoryDesc_setDimensions()来指定内存维度。// Specify the memory dimensions uint32_t dims[] = {3, 4}; ANeuralNetworksMemoryDesc_setDimensions(desc, 2, dims);
通过调用
ANeuralNetworksMemoryDesc_finish()完成描述符定义。ANeuralNetworksMemoryDesc_finish(desc);
通过将描述符传递给
ANeuralNetworksMemory_createFromDesc()来分配任意数量的内存。// Allocate two opaque memories with the descriptor ANeuralNetworksMemory* opaqueMem; ANeuralNetworksMemory_createFromDesc(desc, &opaqueMem);
释放不再需要的内存描述符。
ANeuralNetworksMemoryDesc_free(desc);
根据在 ANeuralNetworksMemoryDesc 对象中指定的角色,客户端只能将创建的 ANeuralNetworksMemory 对象与 ANeuralNetworksExecution_setInputFromMemory() 或 ANeuralNetworksExecution_setOutputFromMemory() 搭配使用。偏移和长度参数必须设置为 0,表示使用全部内存。客户端还可以使用 ANeuralNetworksMemory_copy() 明确设置或提取内存内容。
您可以使用未指定维度或秩的角色创建不透明内存。在这种情况下,如果底层驱动程序不支持,则内存创建可能会失败并显示 ANEURALNETWORKS_OP_FAILED 状态。建议客户端通过分配由 Ashmem 或 BLOB 模式 AHardwareBuffer 支持的足够大的缓冲区来实现回退逻辑。
当 NNAPI 不再需要访问不透明内存对象时,请释放相应的 ANeuralNetworksMemory 实例:
ANeuralNetworksMemory_free(opaqueMem);
衡量性能
您可以通过衡量执行时间或进行性能剖析来评估应用性能。
执行时间
如果要通过运行时确定总执行时间,您可以使用同步执行 API 并测量调用所花费的时间。如果要通过较低级别的软件堆栈确定总执行时间,您可以使用 ANeuralNetworksExecution_setMeasureTiming 和 ANeuralNetworksExecution_getDuration 以获取:
- 加速器上的执行时间(而不是在主机处理器上运行的驱动程序中的执行时间)。
- 驱动程序中的执行时间,包括加速器上的时间。
驱动程序中的执行时间不包括一些开销,如运行时本身以及运行时与驱动程序进行通信所需 IPC 的开销。
这些 API 测量工作提交事件与工作完成事件之间的持续时间,而不是驱动程序或加速器专用于执行推断的时间,该时间可能会因上下文切换而中断。
例如,如果推断 1 先开始,而后驱动程序为了执行推断 2 而停止工作,后来又继续执行并完成推断 1,那么推断 1 的执行时间将包括为了执行推断 2 而停止工作的时间。
此时间信息对于应用的生产部署可能很有用,可让应用收集遥测数据以供离线使用。您可以使用时间数据来修改应用以获得更高的性能。
使用此功能时,请记住以下几点:
- 收集时间信息可能会降低性能。
- 只有驱动程序才能计算在自身中或加速器上花费的时间,不包括在 NNAPI 运行时和 IPC 中花费的时间。
- 您只能将这些 API 与使用
ANeuralNetworksCompilation_createForDevices(其中numDevices = 1)创建的ANeuralNetworksExecution一起使用。 - 不需要驱动程序即可报告时间信息。
使用 Android Systrace 对应用进行性能剖析
从 Android 10 开始,NNAPI 会自动生成 systrace 事件,您可以使用该事件来剖析应用的性能。
NNAPI 源代码附带 parse_systrace 实用程序,用于处理您的应用生成的 systrace 事件,并生成表格视图,显示在模型生命周期的不同阶段(实例化、准备、编译执行和终止)以及应用的不同层级上所花费的时间。拆分应用的层包括:
Application:主应用代码Runtime:NNAPI 运行时IPC:NNAPI 运行时与驱动程序代码之间的进程间通信Driver:加速器驱动程序进程。
生成性能剖析分析数据
假设您在 $ANDROID_BUILD_TOP 中检出了 AOSP 源代码树,并且使用 TFLite 图像分类示例作为目标应用,可以按照以下步骤生成 NNAPI 性能剖析数据:
- 使用以下命令启动 Android Systrace:
$ANDROID_BUILD_TOP/external/chromium-trace/systrace.py -o trace.html -a org.tensorflow.lite.examples.classification nnapi hal freq sched idle load binder_driver
-o trace.html 参数表示将在 trace.html 中写入跟踪记录。剖析自己的应用时,您需要将 org.tensorflow.lite.examples.classification 替换为应用清单中指定的进程名称。
该操作将使其中一个 shell 控制台处于忙碌状态,不要在后台运行该命令,因为它会以交互方式等待 enter 终止。
- 在 systrace 收集器启动后,启动您的应用并运行基准测试。
在我们的示例中,您可以从 Android Studio 启动图像分类应用,或者直接从测试手机界面启动(如果已安装该应用)。若要生成某些 NNAPI 数据,您需要在应用配置对话框中选择 NNAPI 作为目标设备来将应用配置为使用 NNAPI。
测试完成后,请从第 1 步开始在活动的控制台终端上按
enter,以终止 systrace。运行
systrace_parser实用程序以生成累计统计信息:
$ANDROID_BUILD_TOP/frameworks/ml/nn/tools/systrace_parser/parse_systrace.py --total-times trace.html
解析器接受以下参数:- --total-times:显示在图层上花费的总时间,包括等待调用底层图层所花的时间;- --print-detail:打印从 systrace 收集的所有事件;- --per-execution:仅打印执行及其子阶段的统计信息(按执行次数),而不是所有阶段的统计信息;- --json:生成 JSON 格式的输出
输出示例如下所示:
===========================================================================================================================================
NNAPI timing summary (total time, ms wall-clock) Execution
----------------------------------------------------
Initialization Preparation Compilation I/O Compute Results Ex. total Termination Total
-------------- ----------- ----------- ----------- ------------ ----------- ----------- ----------- ----------
Application n/a 19.06 1789.25 n/a n/a 6.70 21.37 n/a 1831.17*
Runtime - 18.60 1787.48 2.93 11.37 0.12 14.42 1.32 1821.81
IPC 1.77 - 1781.36 0.02 8.86 - 8.88 - 1792.01
Driver 1.04 - 1779.21 n/a n/a n/a 7.70 - 1787.95
Total 1.77* 19.06* 1789.25* 2.93* 11.74* 6.70* 21.37* 1.32* 1831.17*
===========================================================================================================================================
* This total ignores missing (n/a) values and thus is not necessarily consistent with the rest of the numbers
如果收集的事件不是完整的应用跟踪记录,解析器可能会出现故障。具体而言,如果为标记部分结束而生成的 systrace 事件在跟踪记录中出现但没有关联的部分开始事件,解析器可能会出现故障。当您启动 systrace 收集器时,如果生成先前剖析会话中的某些事件,将会出现上述情况。在这种情况下,您必须重新运行性能剖析。
将应用代码的统计信息添加到 systrace_parser 输出
parse_systrace 应用基于内置的 Android systrace 功能。您可以使用具有自定义事件名称的 systrace API 为应用中的特定操作添加跟踪记录(Java、原生应用)。
若要将自定义事件与应用生命周期的各个阶段相关联,请在事件名称前添加以下字符串之一:
[NN_LA_PI]:初始化的应用级事件[NN_LA_PP]:准备阶段的应用级事件[NN_LA_PC]:编译的应用级事件[NN_LA_PE]:执行的应用级事件
以下示例说明了如何通过以下方法更改 TFLite 图像分类示例代码:为 Execution 阶段和 Application 层(其中包含在 NNAPI 跟踪记录中不会考虑的其他部分 preprocessBitmap)添加 runInferenceModel 部分。runInferenceModel 部分是 NNAPI Systrace 解析器处理的 systrace 事件的一部分:
Kotlin
/** Runs inference and returns the classification results. */ fun recognizeImage(bitmap: Bitmap): List{ // This section won’t appear in the NNAPI systrace analysis Trace.beginSection("preprocessBitmap") convertBitmapToByteBuffer(bitmap) Trace.endSection() // Run the inference call. // Add this method in to NNAPI systrace analysis. Trace.beginSection("[NN_LA_PE]runInferenceModel") long startTime = SystemClock.uptimeMillis() runInference() long endTime = SystemClock.uptimeMillis() Trace.endSection() ... return recognitions }
Java
/** Runs inference and returns the classification results. */ public ListrecognizeImage(final Bitmap bitmap) { // This section won’t appear in the NNAPI systrace analysis Trace.beginSection("preprocessBitmap"); convertBitmapToByteBuffer(bitmap); Trace.endSection(); // Run the inference call. // Add this method in to NNAPI systrace analysis. Trace.beginSection("[NN_LA_PE]runInferenceModel"); long startTime = SystemClock.uptimeMillis(); runInference(); long endTime = SystemClock.uptimeMillis(); Trace.endSection(); ... Trace.endSection(); return recognitions; }
服务质量
在 Android 11 及更高版本中,NNAPI 允许应用指示其模型的相对优先级、准备给定模型的预计最长时间以及完成给定计算的预计最长时间,从而改进服务质量 (QoS)。Android 11 还引入了其他 NNAPI 结果代码,可让应用了解执行截止时间缺失等失败情况。
设置工作负载的优先级
如需设置 NNAPI 工作负载的优先级,请先调用 ANeuralNetworksCompilation_setPriority(),然后再调用 ANeuralNetworksCompilation_finish()。
设置截止时间
应用可以为模型编译和推断设置截止时间。
- 如需设置编译超时,请先调用
ANeuralNetworksCompilation_setTimeout(),然后再调用ANeuralNetworksCompilation_finish()。 - 如需设置推断超时,请在启动编译之前调用
ANeuralNetworksExecution_setTimeout()。
运算数详细说明
接下来这部分介绍关于使用运算数的高级主题。
量化张量
量化张量是一种表示 N 维浮点值数组的简洁方式。
NNAPI 支持 8 位非对称量化张量。对于这些张量,每个单元格的值都通过一个 8 位整数表示。与张量相关联的是一个比例和一个零点值。这几项可用于将 8 位整数转换成要表示的浮点值。
公式为:
(cellValue - zeroPoint) * scale
其中,zeroPoint 值是一个 32 位整数,scale 是一个 32 位浮点值。
与 32 位浮点值的张量相比,8 位量化张量具有以下两个优势:
- 您的应用变得更小,因为训练的权重占 32 位张量大小的四分之一。
- 计算通常可以更快地执行。这是因为您只需要从内存提取少量数据,而且 DSP 等处理器进行整数数学运算的效率更高。
尽管您可以将浮点值模型转换成量化模型,但我们的经验表明,直接训练量化模型可以获取更好的结果。事实上,神经网络会通过学习来补偿每个值增大的粒度。对于每个量化张量,scale 和 zeroPoint 值会在训练过程中确定。
在 NNAPI 中,您可以通过将 ANeuralNetworksOperandType 数据结构的类型字段设置为 ANEURALNETWORKS_TENSOR_QUANT8_ASYMM 来定义量化张量类型。
您还可以在该数据结构中指定张量的 scale 和 zeroPoint 值。
除了 8 位非对称量化张量之外,NNAPI 还支持以下各项:
ANEURALNETWORKS_TENSOR_QUANT8_SYMM_PER_CHANNEL,可用于表示CONV/DEPTHWISE_CONV/TRANSPOSED_CONV运算的权重。ANEURALNETWORKS_TENSOR_QUANT16_ASYMM,可用于QUANTIZED_16BIT_LSTM的内部状态。ANEURALNETWORKS_TENSOR_QUANT8_SYMM,可作为对ANEURALNETWORKS_DEQUANTIZE的输入。
可选运算数
一些运算(如 ANEURALNETWORKS_LSH_PROJECTION)采用可选运算数。如需在模型中指明省略了可选运算数,请调用 ANeuralNetworksModel_setOperandValue() 函数,针对缓冲区传递 NULL,针对长度传递 0。
如果是否存在运算数的决定因各执行而异,您可以通过以下方式指示省略了运算数:使用 ANeuralNetworksExecution_setInput() 或 ANeuralNetworksExecution_setOutput() 函数,针对缓冲区传递 NULL,针对长度传递 0。
未知秩的张量
Android 9(API 级别 28)引入了未知维度但已知秩(维度数量)的模型运算数。Android 10(API 级别 29)引入了未知秩的张量,如 ANeuralNetworksOperandType 中所示。
NNAPI 基准
AOSP 中 platform/test/mlts/benchmark(基准应用)和 platform/test/mlts/models(模型和数据集)内提供了 NNAPI 基准。
该基准会评估延迟时间和准确性,并针对相同的模型和数据集,将驱动程序与使用 CPU 上运行的 Tensorflow Lite 完成的同一工作进行比较。
如需使用基准,请执行以下操作:
将目标 Android 设备连接到您的计算机,打开一个终端窗口,并确保该设备可通过 adb 进行访问。
如果连接了多个 Android 设备,请导出目标设备
ANDROID_SERIAL环境变量。导航到 Android 顶级源目录。
运行以下命令:
lunch aosp_arm-userdebug # Or aosp_arm64-userdebug if available ./test/mlts/benchmark/build_and_run_benchmark.sh
在基准运行结束时,其结果将显示为传递给
xdg-open的 HTML 页面。
NNAPI 日志
NNAPI 在系统日志中生成有用的诊断信息。如需分析日志,请使用 logcat 实用程序。
通过将属性 debug.nn.vlog(使用 adb shell)设置为以下以空格、冒号或逗号分隔的值列表,为特定阶段或组件启用详细 NNAPI 日志记录:
model:建模compilation:生成模型执行计划和编译execution:执行模型cpuexe:使用 NNAPI CPU 实现执行操作manager:NNAPI 扩展,可用接口和功能相关信息all或1:以上所有元素
例如,如需启用完整详细日志记录,请使用命令 adb shell setprop debug.nn.vlog all。如需停用详细日志记录,请使用命令 adb shell setprop debug.nn.vlog '""'。
详细日志记录启用后,会生成 INFO 级别的日志条目,并将标签设置为阶段或组件名称。
在 debug.nn.vlog 控制的消息旁边,NNAPI API 组件提供不同级别的其他日志条目,每个日志条目都使用特定的日志标签。
如需获取组件列表,请使用以下表达式搜索源代码树:
grep -R 'define LOG_TAG' | awk -F '"' '{print $2}' | sort -u | egrep -v "Sample|FileTag|test"
此表达式当前返回以下标签:
- BurstBuilder
- Callbacks
- CompilationBuilder
- CpuExecutor
- ExecutionBuilder
- ExecutionBurstController
- ExecutionBurstServer
- ExecutionPlan
- FibonacciDriver
- GraphDump
- IndexedShapeWrapper
- IonWatcher
- Manager
- Memory
- MemoryUtils
- MetaModel
- ModelArgumentInfo
- ModelBuilder
- NeuralNetworks
- OperationResolver
- Operations
- OperationsUtils
- PackageInfo
- TokenHasher
- TypeManager
- Utils
- ValidateHal
- VersionedInterfaces
如需控制 logcat 所显示日志消息的级别,请使用环境变量 ANDROID_LOG_TAGS。
如需显示完整的 NNAPI 日志消息集并停用其他任何消息,请将 ANDROID_LOG_TAGS 设置为以下内容:
BurstBuilder:V Callbacks:V CompilationBuilder:V CpuExecutor:V ExecutionBuilder:V ExecutionBurstController:V ExecutionBurstServer:V ExecutionPlan:V FibonacciDriver:V GraphDump:V IndexedShapeWrapper:V IonWatcher:V Manager:V MemoryUtils:V Memory:V MetaModel:V ModelArgumentInfo:V ModelBuilder:V NeuralNetworks:V OperationResolver:V OperationsUtils:V Operations:V PackageInfo:V TokenHasher:V TypeManager:V Utils:V ValidateHal:V VersionedInterfaces:V *:S.
您可以使用以下命令设置 ANDROID_LOG_TAGS:
export ANDROID_LOG_TAGS=$(grep -R 'define LOG_TAG' | awk -F '"' '{ print $2 ":V" }' | sort -u | egrep -v "Sample|FileTag|test" | xargs echo -n; echo ' *:S')
请注意,这只是适用于 logcat 的过滤条件。您仍然需要将属性 debug.nn.vlog 设置为 all 才能生成详细日志信息。