
Android Neural Networks API (NNAPI), Android C API है. इसे Android डिवाइसों पर मशीन लर्निंग के लिए, कंप्यूटेशनल इंटेंसिव ऑपरेशन चलाने के लिए डिज़ाइन किया गया है. NNAPI को, मशीन लर्निंग के बेहतर फ़्रेमवर्क के लिए फ़ंक्शन की बुनियादी लेयर उपलब्ध कराने के लिए डिज़ाइन किया गया है. जैसे, TensorFlow Lite और Caffe2, जो न्यूरल नेटवर्क बनाते हैं और उन्हें ट्रेन करते हैं. यह एपीआई, Android 8.1 (एपीआई लेवल 27) या इसके बाद के वर्शन पर काम करने वाले सभी Android डिवाइसों पर उपलब्ध है. हालांकि, Android 15 में इसे बंद कर दिया गया था.
NNAPI, Android डिवाइसों से मिले डेटा को पहले से ट्रेन किए गए और डेवलपर के तय किए गए मॉडल पर लागू करके, अनुमान लगाने की सुविधा देता है. अनुमान लगाने के उदाहरणों में, इमेज को कैटगरी में बांटना, उपयोगकर्ता के व्यवहार का अनुमान लगाना, और खोज क्वेरी के लिए सही जवाब चुनना शामिल है.
डिवाइस पर मौजूद डेटा का इस्तेमाल करके अनुमान लगाने की सुविधा के कई फ़ायदे हैं:
- लेटेंसी: आपको नेटवर्क कनेक्शन पर कोई अनुरोध भेजने और जवाब का इंतज़ार करने की ज़रूरत नहीं है. उदाहरण के लिए, यह वीडियो ऐप्लिकेशन के लिए ज़रूरी हो सकता है. ये ऐप्लिकेशन, कैमरे से आने वाले फ़्रेम को प्रोसेस करते हैं.
- उपलब्धता: यह ऐप्लिकेशन, नेटवर्क कवरेज से बाहर होने पर भी काम करता है.
- स्पीड: न्यूरल नेटवर्क प्रोसेसिंग के लिए खास तौर पर डिज़ाइन किया गया नया हार्डवेयर, सामान्य सीपीयू की तुलना में काफ़ी तेज़ी से कंप्यूटिंग करता है.
- निजता: यह डेटा, Android डिवाइस से बाहर नहीं जाता.
- लागत: सभी कंप्यूटेशन Android डिवाइस पर किए जाते हैं. इसलिए, सर्वर फ़ार्म की ज़रूरत नहीं होती.
डेवलपर को इन बातों का भी ध्यान रखना चाहिए:
- सिस्टम का इस्तेमाल: न्यूरल नेटवर्क का आकलन करने के लिए, काफ़ी कंप्यूटेशन की ज़रूरत होती है. इससे बैटरी की खपत बढ़ सकती है. अगर आपके ऐप्लिकेशन के लिए बैटरी की परफ़ॉर्मेंस एक समस्या है, तो आपको बैटरी की परफ़ॉर्मेंस पर नज़र रखनी चाहिए. खास तौर पर, लंबे समय तक चलने वाली प्रोसेस के लिए ऐसा करना ज़रूरी है.
- ऐप्लिकेशन का साइज़: अपने मॉडल के साइज़ पर ध्यान दें. मॉडल कई मेगाबाइट की जगह ले सकते हैं. अगर आपके APK में बड़े मॉडल बंडल करने से उपयोगकर्ताओं पर बुरा असर पड़ता है, तो ऐप्लिकेशन इंस्टॉल करने के बाद मॉडल डाउनलोड करने, छोटे मॉडल का इस्तेमाल करने या क्लाउड में कंप्यूटेशन चलाने पर विचार करें. NNAPI, क्लाउड में मॉडल चलाने की सुविधा नहीं देता.
NNAPI का इस्तेमाल करने का एक उदाहरण देखने के लिए, Android Neural Networks API का सैंपल देखें.
Neural Networks API के रनटाइम के बारे में जानकारी
NNAPI को मशीन लर्निंग लाइब्रेरी, फ़्रेमवर्क, और टूल से कॉल किया जाता है. इनकी मदद से डेवलपर, डिवाइस से बाहर अपने मॉडल को ट्रेन कर सकते हैं और उन्हें Android डिवाइसों पर डिप्लॉय कर सकते हैं. ऐप्लिकेशन आम तौर पर NNAPI का सीधे तौर पर इस्तेमाल नहीं करते हैं. इसके बजाय, वे मशीन लर्निंग के हायर-लेवल फ़्रेमवर्क का इस्तेमाल करते हैं. बदले में, ये फ़्रेमवर्क NNAPI का इस्तेमाल करके, हार्डवेयर की मदद से अनुमान लगाने की प्रोसेस को तेज़ कर सकते हैं. हालांकि, ऐसा सिर्फ़ उन डिवाइसों पर किया जा सकता है जिन पर NNAPI काम करता है.
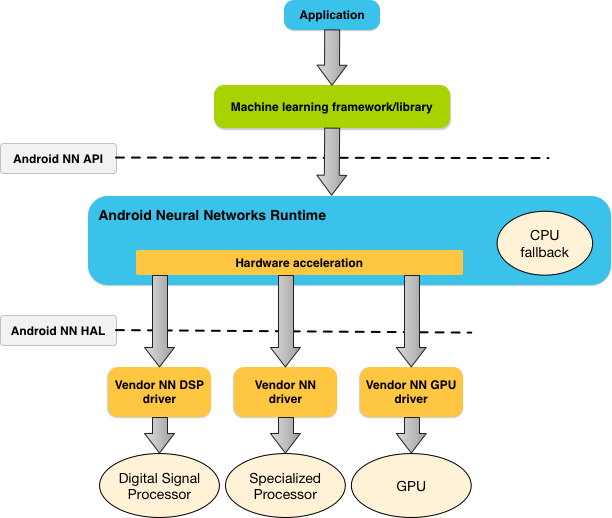
किसी ऐप्लिकेशन की ज़रूरतों और Android डिवाइस पर मौजूद हार्डवेयर की क्षमताओं के आधार पर, Android का न्यूरल नेटवर्क रनटाइम, कंप्यूटेशन वर्कलोड को डिवाइस पर मौजूद प्रोसेसर के बीच आसानी से बांट सकता है. इनमें न्यूरल नेटवर्क के लिए खास तौर पर बनाया गया हार्डवेयर, ग्राफ़िक्स प्रोसेसिंग यूनिट (जीपीयू), और डिजिटल सिग्नल प्रोसेसर (डीएसपी) शामिल हैं.
जिन Android डिवाइसों में वेंडर का खास ड्राइवर नहीं होता है उनके लिए, NNAPI रनटाइम सीपीयू पर अनुरोधों को पूरा करता है.
पहली इमेज में, NNAPI के लिए हाई-लेवल सिस्टम आर्किटेक्चर दिखाया गया है.
Neural Networks API प्रोग्रामिंग मॉडल
NNAPI का इस्तेमाल करके कैलकुलेशन करने के लिए, आपको सबसे पहले एक डायरेक्टेड ग्राफ़ बनाना होगा. यह ग्राफ़, उन कैलकुलेशन को तय करता है जिन्हें पूरा करना है. यह कंप्यूटेशन ग्राफ़, आपके इनपुट डेटा के साथ मिलकर NNAPI रनटाइम के आकलन के लिए मॉडल बनाता है. उदाहरण के लिए, मशीन लर्निंग फ़्रेमवर्क से मिले वेट और बायस.
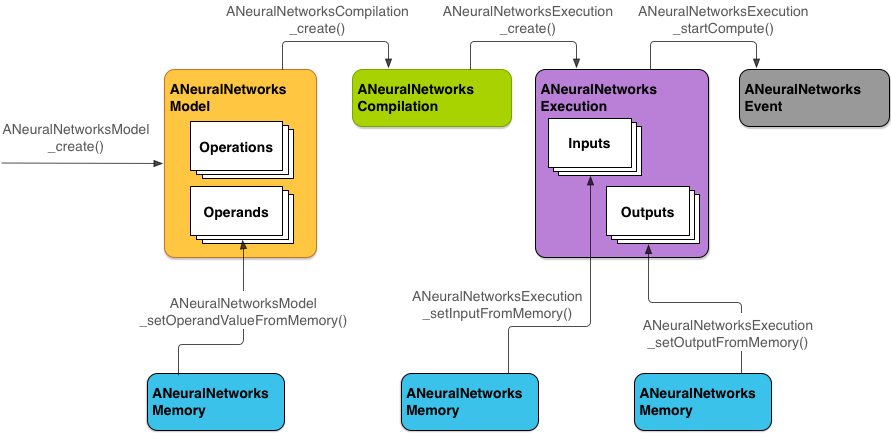
NNAPI में चार मुख्य ऐब्स्ट्रैक्शन का इस्तेमाल किया जाता है:
- मॉडल: यह गणितीय ऑपरेशनों और ट्रेनिंग प्रोसेस के ज़रिए सीखी गई स्थिर वैल्यू का कंप्यूटेशन ग्राफ़ होता है. ये कार्रवाइयां, न्यूरल नेटवर्क के लिए खास तौर पर बनाई गई हैं. इनमें 2 डाइमेंशनल (2D) कन्वलूशन, लॉजिस्टिक (सिग्मॉइड) ऐक्टिवेशन, रेक्टिफ़ाइड लीनियर (ReLU) ऐक्टिवेशन वगैरह शामिल हैं. मॉडल बनाना एक सिंक्रोनस ऑपरेशन है.
बन जाने के बाद, इसका इस्तेमाल सभी थ्रेड और कंपाइलेशन में किया जा सकता है.
NNAPI में, मॉडल को
ANeuralNetworksModelइंस्टेंस के तौर पर दिखाया जाता है. - कंपाइलेशन: यह NNAPI मॉडल को लोअर-लेवल कोड में कंपाइल करने के लिए कॉन्फ़िगरेशन दिखाता है. कंपाइलेशन बनाने की प्रोसेस, एक साथ कई काम करने वाली प्रोसेस है. एक बार बन जाने के बाद, इसका इस्तेमाल सभी थ्रेड और एक्ज़ीक्यूशन में किया जा सकता है. NNAPI में, हर कंपाइलेशन को
ANeuralNetworksCompilationइंस्टेंस के तौर पर दिखाया जाता है. - मेमोरी: यह शेयर की गई मेमोरी, मेमोरी मैप की गई फ़ाइलों, और इसी तरह के मेमोरी बफ़र को दिखाता है. मेमोरी बफ़र का इस्तेमाल करने से, NNAPI रनटाइम, ड्राइवर को डेटा ज़्यादा बेहतर तरीके से ट्रांसफ़र कर पाता है. आम तौर पर, कोई ऐप्लिकेशन एक शेयर किया गया मेमोरी बफ़र बनाता है. इसमें मॉडल को तय करने के लिए ज़रूरी हर टेंसर होता है. किसी एक्ज़ीक्यूशन इंस्टेंस के इनपुट और आउटपुट को सेव करने के लिए, मेमोरी बफ़र का इस्तेमाल भी किया जा सकता है. NNAPI में, हर मेमोरी बफ़र को
ANeuralNetworksMemoryइंस्टेंस के तौर पर दिखाया जाता है. एक्ज़ीक्यूशन: यह एक इंटरफ़ेस है. इसका इस्तेमाल, इनपुट के सेट पर NNAPI मॉडल लागू करने और नतीजे इकट्ठा करने के लिए किया जाता है. इसे सिंक्रोनस या असिंक्रोनस तरीके से लागू किया जा सकता है.
एसिंक्रोनस तरीके से एक्ज़ीक्यूट करने के लिए, कई थ्रेड एक ही एक्ज़ीक्यूशन का इंतज़ार कर सकती हैं. यह प्रोसेस पूरी होने के बाद, सभी थ्रेड रिलीज़ हो जाती हैं.
NNAPI में, हर एक्ज़ीक्यूशन को
ANeuralNetworksExecutionइंस्टेंस के तौर पर दिखाया जाता है.
दूसरी इमेज में, प्रोग्रामिंग का बुनियादी फ़्लो दिखाया गया है.
इस सेक्शन में, NNAPI मॉडल को सेट अप करने का तरीका बताया गया है. इससे कंप्यूटेशन किया जा सकता है, मॉडल को कंपाइल किया जा सकता है, और कंपाइल किए गए मॉडल को एक्ज़ीक्यूट किया जा सकता है.
ट्रेनिंग डेटा का ऐक्सेस देना
ट्रेन किए गए वेट और बायस का डेटा, किसी फ़ाइल में सेव किया जाता है. NNAPI रनटाइम को इस डेटा का बेहतर तरीके से ऐक्सेस देने के लिए, ANeuralNetworksMemory इंस्टेंस बनाएं. इसके लिए, ANeuralNetworksMemory_createFromFd() फ़ंक्शन को कॉल करें और खोली गई डेटा फ़ाइल का फ़ाइल डिस्क्रिप्टर पास करें. इसके अलावा, मेमोरी सुरक्षा के फ़्लैग और ऑफ़सेट भी तय किए जा सकते हैं. ऑफ़सेट वह जगह होती है जहां फ़ाइल में शेयर की गई मेमोरी का क्षेत्र शुरू होता है.
// Create a memory buffer from the file that contains the trained data
ANeuralNetworksMemory* mem1 = NULL;
int fd = open("training_data", O_RDONLY);
ANeuralNetworksMemory_createFromFd(file_size, PROT_READ, fd, 0, &mem1);
इस उदाहरण में, हमने अपने सभी वज़न के लिए सिर्फ़ एक ANeuralNetworksMemory इंस्टेंस का इस्तेमाल किया है. हालांकि, एक से ज़्यादा फ़ाइलों के लिए, एक से ज़्यादा ANeuralNetworksMemory इंस्टेंस का इस्तेमाल किया जा सकता है.
नेटिव हार्डवेयर बफ़र का इस्तेमाल करना
मॉडल के इनपुट, आउटपुट, और कॉन्स्टेंट ऑपरेंड वैल्यू के लिए, नेटिव हार्डवेयर बफ़र का इस्तेमाल किया जा सकता है. कुछ मामलों में, NNAPI ऐक्सलरेटर, AHardwareBuffer ऑब्जेक्ट को ऐक्सेस कर सकता है. इसके लिए, ड्राइवर को डेटा कॉपी करने की ज़रूरत नहीं होती. AHardwareBuffer में कई अलग-अलग कॉन्फ़िगरेशन होते हैं. ऐसा हो सकता है कि हर NNAPI ऐक्सलरेटर, इन सभी कॉन्फ़िगरेशन के साथ काम न करे. इस सीमा की वजह से, ANeuralNetworksMemory_createFromAHardwareBuffer रेफ़रंस दस्तावेज़ में दी गई पाबंदियां देखें. साथ ही, टारगेट डिवाइसों पर पहले से ही टेस्ट करें, ताकि यह पक्का किया जा सके कि AHardwareBuffer का इस्तेमाल करने वाले कंपाइलेशन और एक्ज़ीक्यूशन, उम्मीद के मुताबिक काम कर रहे हैं. इसके लिए, ऐक्सलरेटर तय करने के लिए डिवाइस असाइनमेंट का इस्तेमाल करें.
NNAPI रनटाइम को AHardwareBuffer ऑब्जेक्ट ऐक्सेस करने की अनुमति देने के लिए, ANeuralNetworksMemory_createFromAHardwareBuffer फ़ंक्शन को कॉल करके ANeuralNetworksMemory इंस्टेंस बनाएं और उसमें AHardwareBuffer ऑब्जेक्ट पास करें. इसका उदाहरण यहां दिया गया है:
// Configure and create AHardwareBuffer object AHardwareBuffer_Desc desc = ... AHardwareBuffer* ahwb = nullptr; AHardwareBuffer_allocate(&desc, &ahwb); // Create ANeuralNetworksMemory from AHardwareBuffer ANeuralNetworksMemory* mem2 = NULL; ANeuralNetworksMemory_createFromAHardwareBuffer(ahwb, &mem2);
जब NNAPI को AHardwareBuffer ऑब्जेक्ट को ऐक्सेस करने की ज़रूरत न हो, तो उससे जुड़े ANeuralNetworksMemory इंस्टेंस को रिलीज़ करें:
ANeuralNetworksMemory_free(mem2);
ध्यान दें:
AHardwareBufferका इस्तेमाल सिर्फ़ पूरे बफ़र के लिए किया जा सकता है. इसका इस्तेमालARectपैरामीटर के साथ नहीं किया जा सकता.- NNAPI रनटाइम, बफ़र को फ़्लश नहीं करेगा. आपको यह पक्का करना होगा कि इनपुट और आउटपुट बफ़र, एक्ज़ीक्यूशन शेड्यूल करने से पहले ऐक्सेस किए जा सकते हों.
- सिंक फ़ेंस फ़ाइल डिस्क्रिप्टर के लिए, कोई सहायता उपलब्ध नहीं है.
- वेंडर के हिसाब से फ़ॉर्मैट और इस्तेमाल के बिट वाले
AHardwareBufferके लिए, वेंडर के लागू करने के तरीके से यह तय किया जाता है कि क्लाइंट या ड्राइवर, कैश मेमोरी को फ़्लश करने के लिए ज़िम्मेदार है या नहीं.
मॉडल
मॉडल, NNAPI में कंप्यूटेशन की बुनियादी इकाई होती है. हर मॉडल को एक या उससे ज़्यादा ऑपरेंड और ऑपरेशन से तय किया जाता है.
ऑपरेंड
ऑपरेंड, डेटा ऑब्जेक्ट होते हैं. इनका इस्तेमाल ग्राफ़ तय करने के लिए किया जाता है. इनमें मॉडल के इनपुट और आउटपुट, इंटरमीडिएट नोड (ऐसे नोड जिनमें एक ऑपरेशन से दूसरे ऑपरेशन में जाने वाला डेटा होता है), और ऐसे कॉन्स्टेंट शामिल होते हैं जिन्हें इन ऑपरेशन में पास किया जाता है.
NNAPI मॉडल में दो तरह के ऑपरेंड जोड़े जा सकते हैं: स्केलर और टेंसर.
स्केलर, एक वैल्यू दिखाता है. NNAPI, स्केलर वैल्यू के साथ काम करता है. ये वैल्यू, बूलियन, 16-बिट फ़्लोटिंग पॉइंट, 32-बिट फ़्लोटिंग पॉइंट, 32-बिट पूर्णांक, और बिना हस्ताक्षर वाले 32-बिट पूर्णांक फ़ॉर्मैट में होती हैं.
NNAPI में ज़्यादातर कार्रवाइयों में टेंसर शामिल होते हैं. टेंसर, n-डाइमेंशनल अरे होते हैं. NNAPI, 16-बिट फ़्लोटिंग पॉइंट, 32-बिट फ़्लोटिंग पॉइंट, 8-बिट क्वांटाइज़्ड, 16-बिट क्वांटाइज़्ड, 32-बिट पूर्णांक, और 8-बिट बूलियन वैल्यू वाले टेंसर के साथ काम करता है.
उदाहरण के लिए, तीसरे फ़िगर में दो कार्रवाइयों वाला मॉडल दिखाया गया है: जोड़ना और फिर गुणा करना. यह मॉडल, इनपुट टेंसर लेता है और एक आउटपुट टेंसर जनरेट करता है.
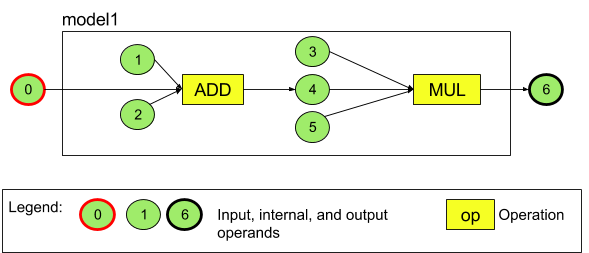
ऊपर दिए गए मॉडल में सात ऑपरेंड हैं. इन ऑपरेंड की पहचान, मॉडल में जोड़े जाने के क्रम के इंडेक्स से होती है. जोड़ा गया पहला ऑपरेंड, इंडेक्स 0 पर होता है. दूसरा ऑपरेंड, इंडेक्स 1 पर होता है. इसी तरह, यह क्रम आगे बढ़ता है. ऑपरेंड 1, 2, 3, और 5, कॉन्स्टेंट ऑपरेंड हैं.
ऑपरेंड को किसी भी क्रम में जोड़ा जा सकता है. उदाहरण के लिए, मॉडल आउटपुट ऑपरेंड को सबसे पहले जोड़ा जा सकता है. ऑपरेंड का रेफ़रंस देते समय, सही इंडेक्स वैल्यू का इस्तेमाल करना ज़रूरी है.
ऑपरेंड के टाइप होते हैं. इन्हें मॉडल में जोड़ते समय तय किया जाता है.
किसी मॉडल के इनपुट और आउटपुट, दोनों के तौर पर किसी ऑपरेंड का इस्तेमाल नहीं किया जा सकता.
हर ऑपरेंड, मॉडल का इनपुट, कॉन्सटेंट या सिर्फ़ एक ऑपरेशन का आउटपुट ऑपरेंड होना चाहिए.
ऑपरेंड इस्तेमाल करने के बारे में ज़्यादा जानकारी के लिए, ऑपरेंड के बारे में ज़्यादा जानकारी लेख पढ़ें.
ऑपरेशंस
ऑपरेशन से पता चलता है कि कौनसी कैलकुलेशन करनी हैं. हर ऑपरेशन में ये एलिमेंट शामिल होते हैं:
- कार्रवाई का टाइप (उदाहरण के लिए, जोड़ना, गुणा करना, कनवोल्यूशन),
- उन ऑपरेंड के इंडेक्स की सूची जिनका इस्तेमाल ऑपरेशन, इनपुट के लिए करता है, और
- ऑपरेंड के इंडेक्स की सूची, जिनका इस्तेमाल ऑपरेशन आउटपुट के लिए करता है.
इन सूचियों में क्रम मायने रखता है. हर ऑपरेशन टाइप के लिए, अनुमानित इनपुट और आउटपुट देखने के लिए, NNAPI API रेफ़रंस देखें.
आपको मॉडल में उन ऑपरेंड को जोड़ना होगा जिनका इस्तेमाल कोई ऑपरेशन करता है या जिन्हें वह बनाता है. इसके बाद ही, ऑपरेशन को जोड़ा जा सकेगा.
ऑपरेशन जोड़ने का क्रम मायने नहीं रखता. NNAPI, ऑपरेंड और कार्रवाइयों के कंप्यूटेशन ग्राफ़ से तय की गई डिपेंडेंसी पर निर्भर करता है. इससे यह तय किया जाता है कि कार्रवाइयों को किस क्रम में लागू किया जाए.
NNAPI के साथ काम करने वाली कार्रवाइयों के बारे में यहां दी गई टेबल में बताया गया है:
एपीआई लेवल 28 में मौजूद समस्या: Android 9 (एपीआई लेवल 28) और उसके बाद के वर्शन पर उपलब्ध ANEURALNETWORKS_PAD ऑपरेशन में ANEURALNETWORKS_TENSOR_QUANT8_ASYMM टेंसर पास करने पर, NNAPI से मिलने वाला आउटपुट, TensorFlow Lite जैसे हायर-लेवल मशीन लर्निंग फ़्रेमवर्क से मिलने वाले आउटपुट से मेल नहीं खा सकता. आपको इसके बजाय, सिर्फ़ ANEURALNETWORKS_TENSOR_FLOAT32 पास करना चाहिए.
इस समस्या को Android 10 (एपीआई लेवल 29) और इसके बाद के वर्शन में ठीक कर दिया गया है.
मॉडल बनाना
नीचे दिए गए उदाहरण में, हमने तीसरी इमेज में मौजूद दो ऑपरेशन वाला मॉडल बनाया है.
मॉडल बनाने के लिए, यह तरीका अपनाएं:
खाली मॉडल तय करने के लिए,
ANeuralNetworksModel_create()फ़ंक्शन को कॉल करें.ANeuralNetworksModel* model = NULL; ANeuralNetworksModel_create(&model);
ANeuralNetworks_addOperand()को कॉल करके, अपने मॉडल में ऑपरेंड जोड़ें. इनके डेटा टाइप,ANeuralNetworksOperandTypeडेटा स्ट्रक्चर का इस्तेमाल करके तय किए जाते हैं.// In our example, all our tensors are matrices of dimension [3][4] ANeuralNetworksOperandType tensor3x4Type; tensor3x4Type.type = ANEURALNETWORKS_TENSOR_FLOAT32; tensor3x4Type.scale = 0.f; // These fields are used for quantized tensors tensor3x4Type.zeroPoint = 0; // These fields are used for quantized tensors tensor3x4Type.dimensionCount = 2; uint32_t dims[2] = {3, 4}; tensor3x4Type.dimensions = dims;
// We also specify operands that are activation function specifiers ANeuralNetworksOperandType activationType; activationType.type = ANEURALNETWORKS_INT32; activationType.scale = 0.f; activationType.zeroPoint = 0; activationType.dimensionCount = 0; activationType.dimensions = NULL;
// Now we add the seven operands, in the same order defined in the diagram ANeuralNetworksModel_addOperand(model, &tensor3x4Type); // operand 0 ANeuralNetworksModel_addOperand(model, &tensor3x4Type); // operand 1 ANeuralNetworksModel_addOperand(model, &activationType); // operand 2 ANeuralNetworksModel_addOperand(model, &tensor3x4Type); // operand 3 ANeuralNetworksModel_addOperand(model, &tensor3x4Type); // operand 4 ANeuralNetworksModel_addOperand(model, &activationType); // operand 5 ANeuralNetworksModel_addOperand(model, &tensor3x4Type); // operand 6जिन ऑपरेंड की वैल्यू स्थिर होती है उनके लिए
ANeuralNetworksModel_setOperandValue()औरANeuralNetworksModel_setOperandValueFromMemory()फ़ंक्शन का इस्तेमाल करें. जैसे, ट्रेनिंग प्रोसेस से आपका ऐप्लिकेशन जिन वेट और बायस को हासिल करता है.यहां दिए गए उदाहरण में, हमने ट्रेनिंग डेटा फ़ाइल से कॉन्स्टेंट वैल्यू सेट की हैं. ये वैल्यू, ट्रेनिंग डेटा का ऐक्सेस दें में बनाए गए मेमोरी बफ़र से जुड़ी हैं.
// In our example, operands 1 and 3 are constant tensors whose values were // established during the training process const int sizeOfTensor = 3 * 4 * 4; // The formula for size calculation is dim0 * dim1 * elementSize ANeuralNetworksModel_setOperandValueFromMemory(model, 1, mem1, 0, sizeOfTensor); ANeuralNetworksModel_setOperandValueFromMemory(model, 3, mem1, sizeOfTensor, sizeOfTensor);
// We set the values of the activation operands, in our example operands 2 and 5 int32_t noneValue = ANEURALNETWORKS_FUSED_NONE; ANeuralNetworksModel_setOperandValue(model, 2, &noneValue, sizeof(noneValue)); ANeuralNetworksModel_setOperandValue(model, 5, &noneValue, sizeof(noneValue));डायरेक्टेड ग्राफ़ में मौजूद जिस भी ऑपरेशन का हिसाब लगाना है उसे अपने मॉडल में जोड़ें. इसके लिए,
ANeuralNetworksModel_addOperation()फ़ंक्शन को कॉल करें.इस कॉल के पैरामीटर के तौर पर, आपके ऐप्लिकेशन को ये चीज़ें उपलब्ध करानी होंगी:
- कार्रवाई का टाइप
- इनपुट वैल्यू की संख्या
- इनपुट ऑपरेंड के इंडेक्स का कलेक्शन
- आउटपुट वैल्यू की संख्या
- आउटपुट ऑपरेंड के इंडेक्स का कलेक्शन
ध्यान दें कि किसी ऑपरेंड का इस्तेमाल, एक ही ऑपरेशन के इनपुट और आउटपुट, दोनों के लिए नहीं किया जा सकता.
// We have two operations in our example // The first consumes operands 1, 0, 2, and produces operand 4 uint32_t addInputIndexes[3] = {1, 0, 2}; uint32_t addOutputIndexes[1] = {4}; ANeuralNetworksModel_addOperation(model, ANEURALNETWORKS_ADD, 3, addInputIndexes, 1, addOutputIndexes);
// The second consumes operands 3, 4, 5, and produces operand 6 uint32_t multInputIndexes[3] = {3, 4, 5}; uint32_t multOutputIndexes[1] = {6}; ANeuralNetworksModel_addOperation(model, ANEURALNETWORKS_MUL, 3, multInputIndexes, 1, multOutputIndexes);ANeuralNetworksModel_identifyInputsAndOutputs()फ़ंक्शन को कॉल करके, यह तय करें कि मॉडल को किन ऑपरेंड को इनपुट और आउटपुट के तौर पर इस्तेमाल करना चाहिए.// Our model has one input (0) and one output (6) uint32_t modelInputIndexes[1] = {0}; uint32_t modelOutputIndexes[1] = {6}; ANeuralNetworksModel_identifyInputsAndOutputs(model, 1, modelInputIndexes, 1 modelOutputIndexes);
इसके अलावा, यह भी तय किया जा सकता है कि
ANEURALNETWORKS_TENSOR_FLOAT32की गणना, रेंज या सटीक वैल्यू के साथ की जा सकती है या नहीं. यह रेंज या सटीक वैल्यू, IEEE 754 16-बिट फ़्लोटिंग-पॉइंट फ़ॉर्मैट के बराबर होनी चाहिए. इसके लिए,ANeuralNetworksModel_relaxComputationFloat32toFloat16()को कॉल करें.अपने मॉडल की परिभाषा को फ़ाइनल करने के लिए, कॉल
ANeuralNetworksModel_finish()करें. अगर कोई गड़बड़ी नहीं है, तो यह फ़ंक्शनANEURALNETWORKS_NO_ERRORनतीजे वाला कोड दिखाता है.ANeuralNetworksModel_finish(model);
मॉडल बनाने के बाद, उसे जितनी बार चाहें उतनी बार कंपाइल किया जा सकता है. साथ ही, हर कंपाइलेशन को जितनी बार चाहें उतनी बार एक्ज़ीक्यूट किया जा सकता है.
कंट्रोल फ़्लो
NNAPI मॉडल में कंट्रोल फ़्लो शामिल करने के लिए, यह तरीका अपनाएं:
अलग-अलग
ANeuralNetworksModel*मॉडल के तौर पर, एक्ज़ीक्यूशन के सबग्राफ़ (IFस्टेटमेंट के लिएthenऔरelseसबग्राफ़,WHILEलूप के लिएconditionऔरbodyसबग्राफ़) बनाएं:ANeuralNetworksModel* thenModel = makeThenModel(); ANeuralNetworksModel* elseModel = makeElseModel();
ऐसे ऑपरेंड बनाएं जो कंट्रोल फ़्लो वाले मॉडल में उन मॉडल को रेफ़रंस करते हों:
ANeuralNetworksOperandType modelType = { .type = ANEURALNETWORKS_MODEL, }; ANeuralNetworksModel_addOperand(model, &modelType); // kThenOperandIndex ANeuralNetworksModel_addOperand(model, &modelType); // kElseOperandIndex ANeuralNetworksModel_setOperandValueFromModel(model, kThenOperandIndex, &thenModel); ANeuralNetworksModel_setOperandValueFromModel(model, kElseOperandIndex, &elseModel);
कंट्रोल फ़्लो ऑपरेशन जोड़ें:
uint32_t inputs[] = {kConditionOperandIndex, kThenOperandIndex, kElseOperandIndex, kInput1, kInput2, kInput3}; uint32_t outputs[] = {kOutput1, kOutput2}; ANeuralNetworksModel_addOperation(model, ANEURALNETWORKS_IF, std::size(inputs), inputs, std::size(output), outputs);
कंपाइलेशन
कंपाइलेशन चरण में यह तय किया जाता है कि आपका मॉडल किन प्रोसेसर पर एक्ज़ीक्यूट होगा. साथ ही, यह संबंधित ड्राइवर से मॉडल को एक्ज़ीक्यूट करने के लिए तैयार रहने को कहता है. इसमें, आपके मॉडल को चलाने वाले प्रोसेसर के लिए मशीन कोड जनरेट करना शामिल हो सकता है.
किसी मॉडल को कंपाइल करने के लिए, यह तरीका अपनाएं:
नया कंपाइलेशन इंस्टेंस बनाने के लिए,
ANeuralNetworksCompilation_create()फ़ंक्शन को कॉल करें.// Compile the model ANeuralNetworksCompilation* compilation; ANeuralNetworksCompilation_create(model, &compilation);
इसके अलावा, डिवाइस असाइनमेंट का इस्तेमाल करके, यह साफ़ तौर पर चुना जा सकता है कि किस डिवाइस पर रूटीन को लागू करना है.
आपके पास यह तय करने का विकल्प होता है कि बैटरी की खपत और प्रोग्राम के चलने की स्पीड के बीच किस तरह से समझौता किया जाए. इसके लिए,
ANeuralNetworksCompilation_setPreference()पर कॉल करें.// Ask to optimize for low power consumption ANeuralNetworksCompilation_setPreference(compilation, ANEURALNETWORKS_PREFER_LOW_POWER);
इन प्राथमिकताओं को सेट किया जा सकता है:
ANEURALNETWORKS_PREFER_LOW_POWER: ऐसे तरीके से काम करो जिससे बैटरी कम खर्च हो. यह उन कंपाइलेशन के लिए ज़रूरी है जिन्हें अक्सर एक्ज़ीक्यूट किया जाता है.ANEURALNETWORKS_PREFER_FAST_SINGLE_ANSWER: जवाब को जल्द से जल्द वापस भेजें, भले ही इससे बैटरी की खपत ज़्यादा हो. यह डिफ़ॉल्ट विकल्प है.ANEURALNETWORKS_PREFER_SUSTAINED_SPEED: इस मोड में, लगातार फ़्रेम प्रोसेस करने पर ज़्यादा ध्यान दिया जाता है. जैसे, कैमरे से लगातार फ़्रेम प्रोसेस करते समय.
ANeuralNetworksCompilation_setCachingको कॉल करके, वैकल्पिक तौर पर कंपाइलेशन कैशिंग सेट अप की जा सकती है.// Set up compilation caching ANeuralNetworksCompilation_setCaching(compilation, cacheDir, token);
cacheDirके लिए,getCodeCacheDir()का इस्तेमाल करें. ऐप्लिकेशन में मौजूद हर मॉडल के लिए, बताया गयाtokenयूनीक होना चाहिए.ANeuralNetworksCompilation_finish()को कॉल करके, कंपाइलेशन की परिभाषा को फ़ाइनल करें. अगर कोई गड़बड़ी नहीं है, तो यह फ़ंक्शनANEURALNETWORKS_NO_ERRORनतीजे वाला कोड दिखाता है.ANeuralNetworksCompilation_finish(compilation);
डिवाइस खोजना और असाइन करना
Android 10 (एपीआई लेवल 29) और इसके बाद के वर्शन वाले Android डिवाइसों पर, NNAPI ऐसे फ़ंक्शन उपलब्ध कराता है जिनकी मदद से मशीन लर्निंग फ़्रेमवर्क लाइब्रेरी और ऐप्लिकेशन, उपलब्ध डिवाइसों के बारे में जानकारी पा सकते हैं. साथ ही, यह तय कर सकते हैं कि एक्ज़ीक्यूशन के लिए किन डिवाइसों का इस्तेमाल किया जाना है. उपलब्ध डिवाइसों के बारे में जानकारी देने से, ऐप्लिकेशन को किसी डिवाइस पर मौजूद ड्राइवर का सटीक वर्शन मिल जाता है. इससे, उन समस्याओं से बचा जा सकता है जिनके बारे में पहले से पता है कि वे ड्राइवर के वर्शन के साथ काम नहीं करते. ऐप्लिकेशन को यह तय करने की सुविधा देकर कि मॉडल के अलग-अलग सेक्शन को किन डिवाइसों पर लागू करना है, ऐप्लिकेशन को उस Android डिवाइस के लिए ऑप्टिमाइज़ किया जा सकता है जिस पर उन्हें डिप्लॉय किया गया है.
कास्ट की सुविधा वाले डिवाइस खोजना
उपलब्ध डिवाइसों की संख्या पाने के लिए, ANeuralNetworks_getDeviceCount का इस्तेमाल करें. हर डिवाइस के लिए, ANeuralNetworks_getDevice का इस्तेमाल करके, ANeuralNetworksDevice इंस्टेंस को उस डिवाइस के रेफ़रंस पर सेट करें.
डिवाइस का रेफ़रंस मिलने के बाद, इन फ़ंक्शन का इस्तेमाल करके उस डिवाइस के बारे में ज़्यादा जानकारी पाई जा सकती है:
ANeuralNetworksDevice_getFeatureLevelANeuralNetworksDevice_getNameANeuralNetworksDevice_getTypeANeuralNetworksDevice_getVersion
डिवाइस असाइन करना
ANeuralNetworksModel_getSupportedOperationsForDevices का इस्तेमाल करके यह पता लगाएं कि किसी मॉडल के कौनसे ऑपरेशन, खास डिवाइसों पर चलाए जा सकते हैं.
यह कंट्रोल करने के लिए कि एक्ज़ीक्यूशन के लिए किन ऐक्सलरेटर का इस्तेमाल करना है, ANeuralNetworksCompilation_create की जगह ANeuralNetworksCompilation_createForDevices को कॉल करें.
नतीजे के तौर पर मिले ANeuralNetworksCompilation ऑब्जेक्ट का इस्तेमाल सामान्य तरीके से करें.
अगर दिए गए मॉडल में ऐसी कार्रवाइयां शामिल हैं जो चुने गए डिवाइसों पर काम नहीं करती हैं, तो फ़ंक्शन गड़बड़ी वाला मान दिखाता है.
अगर एक से ज़्यादा डिवाइसों के बारे में बताया गया है, तो रनटाइम की यह ज़िम्मेदारी होती है कि वह काम को सभी डिवाइसों के बीच बांट दे.
अन्य डिवाइसों की तरह, NNAPI सीपीयू को ANeuralNetworksDevice के तौर पर दिखाया जाता है. इसका नाम nnapi-reference और टाइप ANEURALNETWORKS_DEVICE_TYPE_CPU होता है. ANeuralNetworksCompilation_createForDevices को कॉल करते समय, मॉडल कंपाइल करने और उसे लागू करने से जुड़ी समस्याओं को हल करने के लिए, सीपीयू इंप्लिमेंटेशन का इस्तेमाल नहीं किया जाता.
किसी ऐप्लिकेशन की यह ज़िम्मेदारी होती है कि वह मॉडल को ऐसे सब-मॉडल में बांटे जो बताए गए डिवाइसों पर चल सकें. जिन ऐप्लिकेशन को मैन्युअल तरीके से पार्टीशन करने की ज़रूरत नहीं है उन्हें मॉडल को बेहतर बनाने के लिए, उपलब्ध सभी डिवाइसों (सीपीयू भी शामिल है) का इस्तेमाल करने के लिए, आसान ANeuralNetworksCompilation_create को कॉल करना जारी रखना चाहिए. अगर आपने ANeuralNetworksCompilation_createForDevices एट्रिब्यूट का इस्तेमाल करके जो डिवाइस बताए हैं उन पर मॉडल पूरी तरह से काम नहीं करता है, तो ANEURALNETWORKS_BAD_DATA वैल्यू दिखेगी.
मॉडल पार्टिशनिंग
अगर मॉडल के लिए एक से ज़्यादा डिवाइस उपलब्ध हैं, तो NNAPI रनटाइम, काम को सभी डिवाइसों के बीच बांट देता है. उदाहरण के लिए, अगर ANeuralNetworksCompilation_createForDevices को एक से ज़्यादा डिवाइस दिए गए थे, तो काम बांटते समय, बताए गए सभी डिवाइसों को ध्यान में रखा जाएगा. ध्यान दें कि अगर सीपीयू डिवाइस सूची में नहीं है, तो सीपीयू एक्ज़ीक्यूशन बंद हो जाएगा. ANeuralNetworksCompilation_create का इस्तेमाल करते समय, सीपीयू के साथ-साथ सभी उपलब्ध डिवाइसों को ध्यान में रखा जाएगा.
डिवाइसों को इस तरह से डिस्ट्रिब्यूट किया जाता है: मॉडल में मौजूद हर ऑपरेशन के लिए, उपलब्ध डिवाइसों की सूची में से उस डिवाइस को चुना जाता है जो ऑपरेशन को सपोर्ट करता है और सबसे अच्छी परफ़ॉर्मेंस देता है.जैसे, सबसे कम समय में ऑपरेशन पूरा करने वाला डिवाइस या सबसे कम बिजली की खपत करने वाला डिवाइस. यह क्लाइंट की ओर से तय की गई प्राथमिकता पर निर्भर करता है. यह पार्टीशनिंग एल्गोरिदम, अलग-अलग प्रोसेसर के बीच आईओ की वजह से होने वाली संभावित समस्याओं को ध्यान में नहीं रखता है. इसलिए, एक से ज़्यादा प्रोसेसर (ANeuralNetworksCompilation_createForDevices का इस्तेमाल करते समय साफ़ तौर पर या ANeuralNetworksCompilation_create का इस्तेमाल करते समय परोक्ष रूप से) तय करते समय, नतीजे में मिलने वाले ऐप्लिकेशन की प्रोफ़ाइल बनाना ज़रूरी है.
यह समझने के लिए कि NNAPI ने आपके मॉडल को कैसे बांटा है, Android के लॉग में यह मैसेज देखें (INFO लेवल पर, ExecutionPlan टैग के साथ):
ModelBuilder::findBestDeviceForEachOperation(op-name): device-index
op-name ग्राफ़ में ऑपरेशन का ब्यौरे वाला नाम है और device-index डिवाइसों की सूची में उम्मीदवार डिवाइस का इंडेक्स है.
यह सूची, ANeuralNetworksCompilation_createForDevices को दी गई इनपुट सूची है. अगर ANeuralNetworksCompilation_createForDevices का इस्तेमाल किया जा रहा है, तो यह सूची उन डिवाइसों की सूची है जो ANeuralNetworks_getDeviceCount और ANeuralNetworks_getDevice का इस्तेमाल करके सभी डिवाइसों पर दोहराने पर मिलती है.
मैसेज (INFO लेवल पर, ExecutionPlan टैग के साथ):
ModelBuilder::partitionTheWork: only one best device: device-name
इस मैसेज से पता चलता है कि पूरे ग्राफ़ को डिवाइस device-name पर तेज़ी से रेंडर किया गया है.
प्लान लागू करना
एक्ज़ीक्यूशन चरण में, मॉडल को इनपुट के सेट पर लागू किया जाता है. साथ ही, कंप्यूटेशन के आउटपुट को एक या उससे ज़्यादा उपयोगकर्ता बफ़र या मेमोरी स्पेस में सेव किया जाता है. ये बफ़र या मेमोरी स्पेस, आपके ऐप्लिकेशन ने असाइन किए होते हैं.
कंपाइल किए गए मॉडल को लागू करने के लिए, यह तरीका अपनाएं:
नया एक्ज़ीक्यूशन इंस्टेंस बनाने के लिए,
ANeuralNetworksExecution_create()फ़ंक्शन को कॉल करें.// Run the compiled model against a set of inputs ANeuralNetworksExecution* run1 = NULL; ANeuralNetworksExecution_create(compilation, &run1);
यह बताएं कि आपका ऐप्लिकेशन, कैलकुलेशन के लिए इनपुट वैल्यू कहां से पढ़ता है. आपका ऐप्लिकेशन, उपयोगकर्ता बफ़र या मेमोरी के लिए तय की गई जगह से इनपुट वैल्यू पढ़ सकता है. इसके लिए, उसे
ANeuralNetworksExecution_setInput()याANeuralNetworksExecution_setInputFromMemory()को कॉल करना होगा.// Set the single input to our sample model. Since it is small, we won't use a memory buffer float32 myInput[3][4] = { ...the data... }; ANeuralNetworksExecution_setInput(run1, 0, NULL, myInput, sizeof(myInput));
यह बताएं कि आपका ऐप्लिकेशन आउटपुट वैल्यू कहां लिखता है. आपका ऐप्लिकेशन, आउटपुट वैल्यू को उपयोगकर्ता के बफ़र या मेमोरी स्पेस में लिख सकता है. इसके लिए, उसे
ANeuralNetworksExecution_setOutput()याANeuralNetworksExecution_setOutputFromMemory()को कॉल करना होगा.// Set the output float32 myOutput[3][4]; ANeuralNetworksExecution_setOutput(run1, 0, NULL, myOutput, sizeof(myOutput));
ANeuralNetworksExecution_startCompute()फ़ंक्शन को कॉल करके, एक्ज़ीक्यूशन शुरू होने का समय शेड्यूल करें. अगर कोई गड़बड़ी नहीं है, तो यह फ़ंक्शनANEURALNETWORKS_NO_ERRORनतीजे वाला कोड दिखाता है.// Starts the work. The work proceeds asynchronously ANeuralNetworksEvent* run1_end = NULL; ANeuralNetworksExecution_startCompute(run1, &run1_end);
एक्ज़ीक्यूशन पूरा होने का इंतज़ार करने के लिए,
ANeuralNetworksEvent_wait()फ़ंक्शन को कॉल करें. अगर यह फ़ंक्शन सही तरीके से काम करता है, तो यहANEURALNETWORKS_NO_ERRORनतीजे वाला कोड दिखाता है. इंतज़ार करने की प्रोसेस, उस थ्रेड से अलग थ्रेड पर की जा सकती है जो एक्ज़ीक्यूशन शुरू करती है.// For our example, we have no other work to do and will just wait for the completion ANeuralNetworksEvent_wait(run1_end); ANeuralNetworksEvent_free(run1_end); ANeuralNetworksExecution_free(run1);
विकल्प के तौर पर, कंपाइल किए गए मॉडल में इनपुट का कोई दूसरा सेट लागू किया जा सकता है. इसके लिए, कंपाइलेशन के उसी इंस्टेंस का इस्तेमाल करके, नया
ANeuralNetworksExecutionइंस्टेंस बनाएं.// Apply the compiled model to a different set of inputs ANeuralNetworksExecution* run2; ANeuralNetworksExecution_create(compilation, &run2); ANeuralNetworksExecution_setInput(run2, ...); ANeuralNetworksExecution_setOutput(run2, ...); ANeuralNetworksEvent* run2_end = NULL; ANeuralNetworksExecution_startCompute(run2, &run2_end); ANeuralNetworksEvent_wait(run2_end); ANeuralNetworksEvent_free(run2_end); ANeuralNetworksExecution_free(run2);
सिंक्रोनस एक्ज़ीक्यूशन
एसिंक्रोनस एक्ज़ीक्यूशन में, थ्रेड को स्पॉन और सिंक करने में समय लगता है. इसके अलावा, इंतज़ार का समय बहुत अलग-अलग हो सकता है. थ्रेड को सूचना मिलने या चालू होने और सीपीयू कोर से बाइंड होने के बीच, सबसे ज़्यादा देरी 500 माइक्रोसेकंड तक हो सकती है.
लेटेंसी को कम करने के लिए, किसी ऐप्लिकेशन को रनटाइम पर सिंक्रोनस इन्फ़रेंस कॉल करने का निर्देश दिया जा सकता है. वह कॉल, अनुमान लगाने की प्रोसेस पूरी होने के बाद ही वापस आएगा. अनुमान लगाने की प्रोसेस शुरू होने के बाद वह वापस नहीं आएगा. एसिंक्रोनस इन्फ़रेंस कॉल के लिए, रनटाइम को ANeuralNetworksExecution_startCompute पर कॉल करने के बजाय, ऐप्लिकेशन रनटाइम को ANeuralNetworksExecution_compute पर कॉल करके सिंक्रोनस कॉल करता है. ANeuralNetworksExecution_compute को किए गए कॉल में ANeuralNetworksEvent नहीं लगता और इसे ANeuralNetworksEvent_wait को किए गए कॉल के साथ नहीं जोड़ा जाता.
बर्स्ट एक्ज़ीक्यूशन
Android 10 (एपीआई लेवल 29) और इसके बाद के वर्शन वाले Android डिवाइसों पर, NNAPI, ANeuralNetworksBurst ऑब्जेक्ट के ज़रिए बस्ट एक्ज़ीक्यूशन की सुविधा देता है. बर्स्ट एक्ज़ीक्यूशन, एक ही कंपाइलेशन के एक्ज़ीक्यूशन का ऐसा क्रम होता है जो तेज़ी से होता है. जैसे, कैमरा कैप्चर के फ़्रेम या लगातार ऑडियो सैंपल पर काम करने वाले एक्ज़ीक्यूशन. ANeuralNetworksBurst ऑब्जेक्ट का इस्तेमाल करने से, प्रोसेस तेज़ी से पूरी हो सकती है. ऐसा इसलिए, क्योंकि ये ऑब्जेक्ट ऐक्सलरेटर को यह बताते हैं कि प्रोसेस के दौरान संसाधनों का फिर से इस्तेमाल किया जा सकता है. साथ ही, ऐक्सलरेटर को यह भी बताते हैं कि बस्ट के दौरान, उन्हें बेहतर परफ़ॉर्म करना चाहिए.
ANeuralNetworksBurst सामान्य एक्ज़ीक्यूशन पाथ में सिर्फ़ थोड़ा बदलाव करता है. ANeuralNetworksBurst_create का इस्तेमाल करके, बर्स्ट ऑब्जेक्ट बनाया जाता है. इसे यहां दिए गए कोड स्निपेट में दिखाया गया है:
// Create burst object to be reused across a sequence of executions ANeuralNetworksBurst* burst = NULL; ANeuralNetworksBurst_create(compilation, &burst);
बर्स्ट एक्ज़ीक्यूशन सिंक्रोनस होते हैं. हालांकि, हर अनुमान के लिए ANeuralNetworksExecution_compute का इस्तेमाल करने के बजाय, अलग-अलग ANeuralNetworksExecution ऑब्जेक्ट को फ़ंक्शन ANeuralNetworksExecution_burstCompute को किए गए कॉल में एक ही ANeuralNetworksBurst के साथ जोड़ा जाता है.
// Create and configure first execution object // ... // Execute using the burst object ANeuralNetworksExecution_burstCompute(execution1, burst); // Use results of first execution and free the execution object // ... // Create and configure second execution object // ... // Execute using the same burst object ANeuralNetworksExecution_burstCompute(execution2, burst); // Use results of second execution and free the execution object // ...
जब ANeuralNetworksBurst ऑब्जेक्ट की ज़रूरत न हो, तब उसे ANeuralNetworksBurst_free की मदद से रिलीज़ करें.
// Cleanup ANeuralNetworksBurst_free(burst);
एसिंक्रोनस कमांड कतारें और फ़ेंस किए गए एक्ज़ीक्यूशन
Android 11 और इसके बाद के वर्शन में, NNAPI ANeuralNetworksExecution_startComputeWithDependencies() तरीके से एसिंक्रोनस एक्ज़ीक्यूशन को शेड्यूल करने का एक और तरीका उपलब्ध कराता है. इस तरीके का इस्तेमाल करने पर, एक्ज़ीक्यूशन तब तक इंतज़ार करता है, जब तक कि सभी इवेंट के बारे में सूचना नहीं मिल जाती. इसके बाद ही, आकलन शुरू होता है. जब एक्ज़ीक्यूशन पूरा हो जाता है और आउटपुट इस्तेमाल के लिए तैयार हो जाते हैं, तब इवेंट को वापस भेज दिया जाता है.
इवेंट को लागू करने वाले डिवाइसों के आधार पर, इवेंट को सिंक फ़ेंस से बैक अप लिया जा सकता है. आपको इवेंट के लिए इंतज़ार करने और एक्ज़ीक्यूशन में इस्तेमाल किए गए संसाधनों को वापस पाने के लिए, ANeuralNetworksEvent_wait() को कॉल करना होगा. ANeuralNetworksEvent_createFromSyncFenceFd() का इस्तेमाल करके, इवेंट ऑब्जेक्ट में सिंक फ़ेंस इंपोर्ट किए जा सकते हैं. साथ ही, ANeuralNetworksEvent_getSyncFenceFd() का इस्तेमाल करके, इवेंट ऑब्जेक्ट से सिंक फ़ेंस एक्सपोर्ट किए जा सकते हैं.
डाइनैमिक रूप से साइज़ किए गए आउटपुट
ऐसे मॉडल के लिए जहां आउटपुट का साइज़, इनपुट डेटा पर निर्भर करता है—यानी कि जहां मॉडल को एक्ज़ीक्यूट करने के समय साइज़ का पता नहीं लगाया जा सकता—ANeuralNetworksExecution_getOutputOperandRank और ANeuralNetworksExecution_getOutputOperandDimensions का इस्तेमाल करें.
नीचे दिए गए कोड सैंपल में, ऐसा करने का तरीका बताया गया है:
// Get the rank of the output uint32_t myOutputRank = 0; ANeuralNetworksExecution_getOutputOperandRank(run1, 0, &myOutputRank); // Get the dimensions of the output std::vector<uint32_t> myOutputDimensions(myOutputRank); ANeuralNetworksExecution_getOutputOperandDimensions(run1, 0, myOutputDimensions.data());
क्लीनअप करें
सफ़ाई करने वाले चरण में, आपके कंप्यूटेशन के लिए इस्तेमाल किए गए इंटरनल रिसॉर्स को खाली करने का काम किया जाता है.
// Cleanup ANeuralNetworksCompilation_free(compilation); ANeuralNetworksModel_free(model); ANeuralNetworksMemory_free(mem1);
गड़बड़ी को मैनेज करना और सीपीयू फ़ॉलबैक
अगर पार्टीशनिंग के दौरान कोई गड़बड़ी होती है, कोई ड्राइवर मॉडल के किसी हिस्से को कंपाइल नहीं कर पाता है या कोई ड्राइवर कंपाइल किए गए मॉडल के किसी हिस्से को एक्ज़ीक्यूट नहीं कर पाता है, तो NNAPI एक या उससे ज़्यादा कार्रवाइयों के लिए, सीपीयू पर लागू होने वाले अपने वर्शन का इस्तेमाल कर सकता है.
अगर NNAPI क्लाइंट में ऑपरेशन के ऑप्टिमाइज़ किए गए वर्शन (जैसे कि TFLite) शामिल हैं, तो सीपीयू फ़ॉलबैक को बंद करना फ़ायदेमंद हो सकता है. साथ ही, क्लाइंट के ऑप्टिमाइज़ किए गए ऑपरेशन को लागू करने के दौरान होने वाली गड़बड़ियों को ठीक किया जा सकता है.
Android 10 में, अगर ANeuralNetworksCompilation_createForDevices का इस्तेमाल करके कंपाइल किया जाता है, तो सीपीयू फ़ॉलबैक बंद हो जाएगा.
Android P में, ड्राइवर पर NNAPI को लागू न कर पाने पर, सीपीयू पर लागू किया जाता है.
Android 10 पर भी ऐसा ही होता है, जब ANeuralNetworksCompilation_createForDevices के बजाय ANeuralNetworksCompilation_create का इस्तेमाल किया जाता है.
पहली बार लागू करने पर, उस एक पार्टीशन के लिए फ़ॉलबैक होता है. अगर यह अब भी काम नहीं करता है, तो यह पूरे मॉडल को सीपीयू पर फिर से आज़माता है.
अगर पार्टीशनिंग या कंपाइलेशन नहीं हो पाता है, तो पूरे मॉडल को सीपीयू पर आज़माया जाएगा.
कुछ मामलों में, सीपीयू पर कुछ कार्रवाइयां नहीं की जा सकतीं. ऐसे में, फ़ॉलबैक करने के बजाय, कंपाइल या एक्ज़ीक्यूट करने की प्रोसेस पूरी नहीं होगी.
सीपीयू फ़ॉलबैक की सुविधा बंद करने के बाद भी, मॉडल में ऐसी कार्रवाइयां हो सकती हैं जिन्हें सीपीयू पर शेड्यूल किया गया हो. अगर सीपीयू, ANeuralNetworksCompilation_createForDevices को दिए गए प्रोसेसर की सूची में शामिल है और वह उन कार्रवाइयों को सपोर्ट करने वाला एकमात्र प्रोसेसर है या उन कार्रवाइयों के लिए सबसे अच्छी परफ़ॉर्मेंस देने वाला प्रोसेसर है, तो उसे प्राइमरी (नॉन-फ़ॉलबैक) एक्ज़ीक्यूटर के तौर पर चुना जाएगा.
यह पक्का करने के लिए कि सीपीयू का इस्तेमाल न हो, डिवाइसों की सूची से nnapi-reference को हटाते समय ANeuralNetworksCompilation_createForDevices का इस्तेमाल करें.
Android P से, debug.nn.partition प्रॉपर्टी को 2 पर सेट करके, डीबग बिल्ड पर एक्ज़ीक्यूशन के समय फ़ॉलबैक को बंद किया जा सकता है.
मेमोरी डोमेन
Android 11 और इसके बाद के वर्शन में, NNAPI ऐसे मेमोरी डोमेन के साथ काम करता है जो ओपेक मेमोरी के लिए ऐलोकेटर इंटरफ़ेस उपलब्ध कराते हैं. इससे ऐप्लिकेशन, डिवाइस में मौजूद मेमोरी को एक से ज़्यादा बार इस्तेमाल कर पाते हैं. इससे NNAPI को एक ही ड्राइवर पर लगातार प्रोसेस करते समय, डेटा को कॉपी या ट्रांसफ़ॉर्म करने की ज़रूरत नहीं पड़ती.
मेमोरी डोमेन की सुविधा, उन टेंसर के लिए है जो ड्राइवर के लिए ज़्यादातर इंटरनल होते हैं. साथ ही, उन्हें क्लाइंट साइड से बार-बार ऐक्सेस करने की ज़रूरत नहीं होती. इस तरह के टेंसर के उदाहरणों में, क्रम से मॉडल बनाने वाले टेंसर में मौजूद स्टेट टेंसर शामिल हैं. ऐसे टेंसर के लिए शेयर की गई मेमोरी पूल का इस्तेमाल करें जिन्हें क्लाइंट साइड पर सीपीयू का बार-बार ऐक्सेस चाहिए.
ओपेक मेमोरी को असाइन करने के लिए, यह तरीका अपनाएं:
नया मेमोरी डिस्क्रिप्टर बनाने के लिए,
ANeuralNetworksMemoryDesc_create()फ़ंक्शन को कॉल करें:// Create a memory descriptor ANeuralNetworksMemoryDesc* desc; ANeuralNetworksMemoryDesc_create(&desc);
ANeuralNetworksMemoryDesc_addInputRole()औरANeuralNetworksMemoryDesc_addOutputRole()को कॉल करके, इनपुट और आउटपुट की सभी भूमिकाएं तय करें.// Specify that the memory may be used as the first input and the first output // of the compilation ANeuralNetworksMemoryDesc_addInputRole(desc, compilation, 0, 1.0f); ANeuralNetworksMemoryDesc_addOutputRole(desc, compilation, 0, 1.0f);
इसके अलावा,
ANeuralNetworksMemoryDesc_setDimensions()को कॉल करके मेमोरी डाइमेंशन तय किए जा सकते हैं.// Specify the memory dimensions uint32_t dims[] = {3, 4}; ANeuralNetworksMemoryDesc_setDimensions(desc, 2, dims);
ANeuralNetworksMemoryDesc_finish()को कॉल करके, डिसक्रिप्टर की परिभाषा को फ़ाइनल करें.ANeuralNetworksMemoryDesc_finish(desc);
ANeuralNetworksMemory_createFromDesc()को डिस्क्रिप्टर पास करके, जितनी चाहें उतनी मेमोरी असाइन करें.// Allocate two opaque memories with the descriptor ANeuralNetworksMemory* opaqueMem; ANeuralNetworksMemory_createFromDesc(desc, &opaqueMem);
जब आपको मेमोरी डिस्क्रिप्टर की ज़रूरत न हो, तो उसे खाली कर दें.
ANeuralNetworksMemoryDesc_free(desc);
क्लाइंट, बनाए गए ANeuralNetworksMemory ऑब्जेक्ट का इस्तेमाल सिर्फ़ ANeuralNetworksExecution_setInputFromMemory() या ANeuralNetworksExecution_setOutputFromMemory() के साथ कर सकता है. ऐसा ANeuralNetworksMemoryDesc ऑब्जेक्ट में बताई गई भूमिकाओं के हिसाब से किया जा सकता है. ऑफ़सेट और लंबाई वाले आर्ग्युमेंट को 0 पर सेट किया जाना चाहिए. इससे पता चलता है कि पूरी मेमोरी का इस्तेमाल किया गया है. क्लाइंट, ANeuralNetworksMemory_copy() का इस्तेमाल करके, मेमोरी के कॉन्टेंट को साफ़ तौर पर सेट या एक्सट्रैक्ट भी कर सकता है.
आपके पास ऐसी अपारदर्शी मेमोरी बनाने का विकल्प होता है जिनमें डाइमेंशन या रैंक की जानकारी नहीं दी गई होती है.
ऐसे में, हो सकता है कि मेमोरी बनाने की प्रोसेस पूरी न हो पाए और आपको ANEURALNETWORKS_OP_FAILED स्टेटस दिखे. ऐसा तब होता है, जब ड्राइवर इस सुविधा के साथ काम नहीं करता है. क्लाइंट को फ़ॉलबैक लॉजिक लागू करने का सुझाव दिया जाता है. इसके लिए, Ashmem या BLOB-mode AHardwareBuffer की मदद से, काफ़ी बड़ा बफ़र असाइन करें.
जब NNAPI को ओपेक मेमोरी ऑब्जेक्ट को ऐक्सेस करने की ज़रूरत न हो, तो उससे जुड़े ANeuralNetworksMemory इंस्टेंस को खाली करें:
ANeuralNetworksMemory_free(opaqueMem);
परफ़ॉर्मेंस का आकलन करना
एक्ज़ीक्यूशन टाइम को मेज़र करके या प्रोफ़ाइलिंग करके, अपने ऐप्लिकेशन की परफ़ॉर्मेंस का आकलन किया जा सकता है.
लागू करने का समय
अगर आपको रनटाइम के ज़रिए, कुल एक्ज़ीक्यूशन टाइम का पता लगाना है, तो सिंक्रोनस एक्ज़ीक्यूशन एपीआई का इस्तेमाल करें. साथ ही, कॉल में लगने वाले समय को मेज़र करें. जब आपको सॉफ़्टवेयर स्टैक के निचले लेवल से कुल एक्ज़ीक्यूशन टाइम का पता लगाना हो, तो ANeuralNetworksExecution_setMeasureTiming और ANeuralNetworksExecution_getDuration का इस्तेमाल करके यह जानकारी पाई जा सकती है:
- ऐक्सलरेटर पर एक्ज़ीक्यूशन का समय (ड्राइवर में नहीं, जो होस्ट प्रोसेसर पर चलता है).
- ड्राइवर के लिए, ऐक्सेलरेटर पर लगने वाले समय के साथ-साथ, ड्राइविंग में लगने वाला समय.
ड्राइवर में कोड को पूरा होने में लगने वाले समय में, रनटाइम और ड्राइवर के बीच कम्यूनिकेशन के लिए ज़रूरी आईपीसी जैसे ओवरहेड शामिल नहीं होते.
ये एपीआई, काम सबमिट करने और काम पूरा होने के इवेंट के बीच की अवधि को मेज़र करते हैं. ये उस समय को मेज़र नहीं करते हैं जो ड्राइवर या ऐक्सलरेटर, अनुमान लगाने में लगाता है. ऐसा हो सकता है कि संदर्भ बदलने की वजह से, अनुमान लगाने में रुकावट आई हो.
उदाहरण के लिए, अगर इन्फ़रेंस 1 शुरू होता है, तो ड्राइवर इन्फ़रेंस 2 को पूरा करने के लिए काम रोक देता है. इसके बाद, इन्फ़रेंस 1 फिर से शुरू होता है और पूरा हो जाता है. ऐसे में, इन्फ़रेंस 1 को पूरा करने में लगने वाले समय में, इन्फ़रेंस 2 को पूरा करने के लिए काम रोकने का समय भी शामिल होगा.
यह टाइमिंग की जानकारी, किसी ऐप्लिकेशन को प्रोडक्शन में डिप्लॉय करने के लिए काम की हो सकती है. इससे ऑफ़लाइन इस्तेमाल के लिए टेलीमेट्री डेटा इकट्ठा किया जा सकता है. टाइमिंग के डेटा का इस्तेमाल करके, ऐप्लिकेशन में बदलाव किया जा सकता है, ताकि उसकी परफ़ॉर्मेंस बेहतर हो.
इस सुविधा का इस्तेमाल करते समय, इन बातों का ध्यान रखें:
- समय की जानकारी इकट्ठा करने से, परफ़ॉर्मेंस पर असर पड़ सकता है.
- सिर्फ़ ड्राइवर, खुद या ऐक्सलरेटर पर बिताए गए समय का हिसाब लगा सकता है. इसमें NNAPI रनटाइम और आईपीसी में बिताया गया समय शामिल नहीं होता.
- इन एपीआई का इस्तेमाल सिर्फ़ उस
ANeuralNetworksExecutionके साथ किया जा सकता है जिसेnumDevices = 1के साथANeuralNetworksCompilation_createForDevicesका इस्तेमाल करके बनाया गया था. - समय की जानकारी देने के लिए, किसी ड्राइवर की ज़रूरत नहीं होती.
Android Systrace की मदद से अपने ऐप्लिकेशन की प्रोफ़ाइल बनाना
Android 10 से, NNAPI अपने-आप systrace इवेंट जनरेट करता है. इनका इस्तेमाल करके, अपने ऐप्लिकेशन की प्रोफ़ाइल बनाई जा सकती है.
NNAPI सोर्स में, parse_systrace यूटिलिटी होती है. इसका इस्तेमाल, आपके ऐप्लिकेशन से जनरेट हुए systrace इवेंट को प्रोसेस करने के लिए किया जाता है. साथ ही, यह टेबल व्यू जनरेट करता है. इसमें मॉडल के लाइफ़साइकल (इंस्टैंटिएशन, तैयारी, कंपाइलेशन, एक्ज़ीक्यूशन, और टर्मिनेशन) के अलग-अलग चरणों और ऐप्लिकेशन की अलग-अलग लेयर में बिताया गया समय दिखता है. आपका ऐप्लिकेशन इन लेयर में बंटा होता है:
Application: मुख्य ऐप्लिकेशन कोडRuntime: NNAPI RuntimeIPC: NNAPI रनटाइम और ड्राइवर कोड के बीच इंटर प्रोसेस कम्यूनिकेशनDriver: ऐक्सलरेटर ड्राइवर प्रोसेस.
प्रोफ़ाइलिंग के विश्लेषण का डेटा जनरेट करना
मान लें कि आपने $ANDROID_BUILD_TOP पर AOSP सोर्स ट्री को चेक आउट कर लिया है. साथ ही, टारगेट ऐप्लिकेशन के तौर पर TFLite इमेज क्लासिफ़िकेशन के उदाहरण का इस्तेमाल किया जा रहा है. ऐसे में, यहां दिए गए चरणों को पूरा करके NNAPI प्रोफ़ाइलिंग डेटा जनरेट किया जा सकता है:
- नीचे दिए गए निर्देश का इस्तेमाल करके, Android systrace शुरू करें:
$ANDROID_BUILD_TOP/external/chromium-trace/systrace.py -o trace.html -a org.tensorflow.lite.examples.classification nnapi hal freq sched idle load binder_driver
-o trace.html पैरामीटर से पता चलता है कि ट्रेस, trace.html में लिखे जाएंगे. अपने ऐप्लिकेशन की प्रोफ़ाइल बनाते समय, आपको org.tensorflow.lite.examples.classification को अपने ऐप्लिकेशन मेनिफ़ेस्ट में दिए गए प्रोसेस के नाम से बदलना होगा.
इससे आपकी एक शेल कंसोल व्यस्त रहेगी. इस कमांड को बैकग्राउंड में न चलाएं, क्योंकि यह enter के बंद होने का इंतज़ार कर रही है.
- सिस्टम ट्रेस कलेक्टर शुरू होने के बाद, अपना ऐप्लिकेशन शुरू करें और बेंचमार्क टेस्ट चलाएं.
हमारे मामले में, Android Studio से इमेज क्लासिफ़िकेशन ऐप्लिकेशन शुरू किया जा सकता है. अगर ऐप्लिकेशन पहले से इंस्टॉल है, तो सीधे तौर पर अपने टेस्ट फ़ोन के यूज़र इंटरफ़ेस (यूआई) से भी इसे शुरू किया जा सकता है. NNAPI का कुछ डेटा जनरेट करने के लिए, आपको ऐप्लिकेशन को NNAPI का इस्तेमाल करने के लिए कॉन्फ़िगर करना होगा. इसके लिए, ऐप्लिकेशन कॉन्फ़िगरेशन डायलॉग में NNAPI को टारगेट डिवाइस के तौर पर चुनें.
जांच पूरी होने के बाद, पहले चरण से चालू कंसोल टर्मिनल पर
enterदबाकर, सिस्ट्रेस को बंद करें.systrace_parserयूटिलिटी जनरेट करने के लिए, कुल आंकड़े चलाएं:
$ANDROID_BUILD_TOP/frameworks/ml/nn/tools/systrace_parser/parse_systrace.py --total-times trace.html
पार्सर इन पैरामीटर को स्वीकार करता है:
- --total-times: इससे किसी लेयर में बिताया गया कुल समय दिखता है. इसमें, किसी कॉल के लिए अंडरलाइंग लेयर पर एक्ज़ीक्यूशन का इंतज़ार करने में लगा समय भी शामिल होता है
- --print-detail: इससे systrace से इकट्ठा किए गए सभी इवेंट प्रिंट होते हैं
- --per-execution: इससे सभी फ़ेज़ के आंकड़ों के बजाय, सिर्फ़ एक्ज़ीक्यूशन और उसके सबफ़ेज़ (हर एक्ज़ीक्यूशन के समय के हिसाब से) प्रिंट होते हैं
- --json: इससे आउटपुट JSON फ़ॉर्मैट में मिलता है
आउटपुट का एक उदाहरण यहां दिया गया है:
===========================================================================================================================================
NNAPI timing summary (total time, ms wall-clock) Execution
----------------------------------------------------
Initialization Preparation Compilation I/O Compute Results Ex. total Termination Total
-------------- ----------- ----------- ----------- ------------ ----------- ----------- ----------- ----------
Application n/a 19.06 1789.25 n/a n/a 6.70 21.37 n/a 1831.17*
Runtime - 18.60 1787.48 2.93 11.37 0.12 14.42 1.32 1821.81
IPC 1.77 - 1781.36 0.02 8.86 - 8.88 - 1792.01
Driver 1.04 - 1779.21 n/a n/a n/a 7.70 - 1787.95
Total 1.77* 19.06* 1789.25* 2.93* 11.74* 6.70* 21.37* 1.32* 1831.17*
===========================================================================================================================================
* This total ignores missing (n/a) values and thus is not necessarily consistent with the rest of the numbers
अगर इकट्ठा किए गए इवेंट, ऐप्लिकेशन के पूरे ट्रेस को नहीं दिखाते हैं, तो पार्सर काम नहीं कर सकता. खास तौर पर, ऐसा तब हो सकता है, जब किसी सेक्शन के खत्म होने का समय मार्क करने के लिए जनरेट किए गए systrace इवेंट, ट्रेस में मौजूद हों. हालांकि, उनसे जुड़ा सेक्शन शुरू होने का इवेंट मौजूद न हो. आम तौर पर, ऐसा तब होता है, जब systrace कलेक्टर शुरू करने पर, पिछले प्रोफ़ाइलिंग सेशन के कुछ इवेंट जनरेट हो रहे हों. इस मामले में, आपको फिर से प्रोफ़ाइलिंग करनी होगी.
systrace_parser के आउटपुट में, अपने ऐप्लिकेशन कोड के आंकड़े जोड़ना
parse_systrace ऐप्लिकेशन, Android systrace की इन-बिल्ट सुविधा पर आधारित है. कस्टम इवेंट के नामों के साथ, systrace API (Java के लिए, नेटिव ऐप्लिकेशन के लिए) का इस्तेमाल करके, अपने ऐप्लिकेशन में खास कार्रवाइयों के लिए ट्रेस जोड़े जा सकते हैं.
अपने कस्टम इवेंट को ऐप्लिकेशन के लाइफ़साइकल के फ़ेज़ से जोड़ने के लिए, अपने इवेंट के नाम से पहले इनमें से कोई स्ट्रिंग जोड़ें:
[NN_LA_PI]: ऐप्लिकेशन लेवल पर, ऐप्लिकेशन शुरू करने से जुड़ा इवेंट[NN_LA_PP]: तैयारी के लिए ऐप्लिकेशन लेवल का इवेंट[NN_LA_PC]: Compilation के लिए ऐप्लिकेशन लेवल का इवेंट[NN_LA_PE]: Execution के लिए ऐप्लिकेशन-लेवल का इवेंट
यहां एक उदाहरण दिया गया है, जिसमें बताया गया है कि Execution फ़ेज़ के लिए runInferenceModel सेक्शन और Application लेयर जोड़कर, TFLite इमेज क्लासिफ़िकेशन के उदाहरण वाले कोड में कैसे बदलाव किया जा सकता है. इस लेयर में अन्य सेक्शन preprocessBitmap शामिल हैं, जिन्हें NNAPI ट्रेस में शामिल नहीं किया जाएगा. runInferenceModel सेक्शन, nnapi systrace पार्सर से प्रोसेस किए गए systrace इवेंट का हिस्सा होगा:
Kotlin
/** Runs inference and returns the classification results. */ fun recognizeImage(bitmap: Bitmap): List{ // This section won’t appear in the NNAPI systrace analysis Trace.beginSection("preprocessBitmap") convertBitmapToByteBuffer(bitmap) Trace.endSection() // Run the inference call. // Add this method in to NNAPI systrace analysis. Trace.beginSection("[NN_LA_PE]runInferenceModel") long startTime = SystemClock.uptimeMillis() runInference() long endTime = SystemClock.uptimeMillis() Trace.endSection() ... return recognitions }
Java
/** Runs inference and returns the classification results. */ public ListrecognizeImage(final Bitmap bitmap) { // This section won’t appear in the NNAPI systrace analysis Trace.beginSection("preprocessBitmap"); convertBitmapToByteBuffer(bitmap); Trace.endSection(); // Run the inference call. // Add this method in to NNAPI systrace analysis. Trace.beginSection("[NN_LA_PE]runInferenceModel"); long startTime = SystemClock.uptimeMillis(); runInference(); long endTime = SystemClock.uptimeMillis(); Trace.endSection(); ... Trace.endSection(); return recognitions; }
सेवा की क्वालिटी
Android 11 और इसके बाद के वर्शन में, NNAPI बेहतर क्वालिटी ऑफ़ सर्विस (QoS) उपलब्ध कराता है. इसके लिए, यह किसी ऐप्लिकेशन को अपने मॉडल की प्राथमिकताएं, किसी मॉडल को तैयार करने में लगने वाला ज़्यादा से ज़्यादा समय, और किसी कंप्यूटेशन को पूरा करने में लगने वाला ज़्यादा से ज़्यादा समय बताने की अनुमति देता है. Android 11 में, NNAPI के कुछ और नतीजे के कोड भी जोड़े गए हैं. इनकी मदद से ऐप्लिकेशन, निष्पादन की समयसीमा खत्म होने जैसी गड़बड़ियों को समझ पाते हैं.
किसी वर्कलोड की प्राथमिकता सेट करना
NNAPI वर्कलोड की प्राथमिकता सेट करने के लिए, ANeuralNetworksCompilation_finish() को कॉल करने से पहले ANeuralNetworksCompilation_setPriority() को कॉल करें.
समयसीमाएं सेट करना
ऐप्लिकेशन, मॉडल कंपाइल करने और अनुमान लगाने, दोनों के लिए समयसीमाएं सेट कर सकते हैं.
- कंपाइलेशन का समय खत्म होने की अवधि सेट करने के लिए,
ANeuralNetworksCompilation_finish()को कॉल करने से पहलेANeuralNetworksCompilation_setTimeout()को कॉल करें. - अनुमान लगाने के लिए टाइम आउट सेट करने के लिए,
ANeuralNetworksExecution_setTimeout()को कंपाइलेशन शुरू करने से पहले कॉल करें.
ऑपरेंड के बारे में ज़्यादा जानकारी
यहां दिए गए सेक्शन में, ऑपरेंड इस्तेमाल करने के बारे में ऐडवांस विषयों के बारे में बताया गया है.
क्वांटाइज़ किए गए टेंसर
क्वांटाइज़्ड टेंसर, फ़्लोटिंग पॉइंट वैल्यू के n-डाइमेंशनल ऐरे को दिखाने का एक छोटा तरीका है.
NNAPI, 8-बिट के असिमेट्रिक क्वांटाइज़्ड टेंसर के साथ काम करता है. इन टेंसर के लिए, हर सेल की वैल्यू को 8-बिट पूर्णांक के तौर पर दिखाया जाता है. टेंसर से एक स्केल और शून्य पॉइंट वैल्यू जुड़ी होती है. इनका इस्तेमाल, 8-बिट पूर्णांकों को फ़्लोटिंग पॉइंट वैल्यू में बदलने के लिए किया जाता है.
फ़ॉर्मूला यह है:
(cellValue - zeroPoint) * scale
इसमें zeroPoint वैल्यू 32-बिट पूर्णांक होती है और स्केल 32-बिट फ़्लोटिंग पॉइंट वैल्यू होती है.
32-बिट फ़्लोटिंग पॉइंट वैल्यू वाले टेंसर की तुलना में, 8-बिट क्वांटाइज़्ड टेंसर के दो फ़ायदे हैं:
- आपका ऐप्लिकेशन छोटा है, क्योंकि ट्रेन किए गए वेट का साइज़, 32-बिट टेंसर के साइज़ का एक चौथाई होता है.
- कैलकुलेशन अक्सर तेज़ी से की जा सकती हैं. ऐसा इसलिए होता है, क्योंकि मेमोरी से कम डेटा फ़ेच करना पड़ता है. साथ ही, डीएसएपी जैसे प्रोसेसर, पूर्णांकों के गणितीय सवालों को हल करने में ज़्यादा बेहतर होते हैं.
फ़्लोटिंग पॉइंट मॉडल को क्वांटाइज़्ड मॉडल में बदला जा सकता है. हालांकि, हमारे अनुभव से पता चला है कि सीधे तौर पर क्वांटाइज़्ड मॉडल को ट्रेन करने से बेहतर नतीजे मिलते हैं. इस तरह, न्यूरल नेटवर्क हर वैल्यू की बढ़ी हुई बारीकी के लिए, भरपाई करना सीखता है. क्वांटाइज़ किए गए हर टेंसर के लिए, ट्रेनिंग प्रोसेस के दौरान स्केल और zeroPoint वैल्यू तय की जाती हैं.
NNAPI में, क्वांटाइज़ किए गए टेंसर टाइप तय करने के लिए, ANeuralNetworksOperandType डेटा स्ट्रक्चर के टाइप फ़ील्ड को ANEURALNETWORKS_TENSOR_QUANT8_ASYMM पर सेट करें.
उस डेटा स्ट्रक्चर में, आपको टेंसर की स्केल और zeroPoint वैल्यू भी तय करनी होती है.
NNAPI, 8-बिट के एसिमेट्रिक क्वांटाइज़्ड टेंसर के साथ-साथ इन सुविधाओं के साथ भी काम करता है:
ANEURALNETWORKS_TENSOR_QUANT8_SYMM_PER_CHANNELजिसका इस्तेमालCONV/DEPTHWISE_CONV/TRANSPOSED_CONVकार्रवाइयों के लिए वज़न दिखाने के लिए किया जा सकता है.ANEURALNETWORKS_TENSOR_QUANT16_ASYMMजिसका इस्तेमालQUANTIZED_16BIT_LSTMकी इंटरनल स्थिति के लिए किया जा सकता है.ANEURALNETWORKS_TENSOR_QUANT8_SYMMजोANEURALNETWORKS_DEQUANTIZEके लिए इनपुट हो सकता है.
वैकल्पिक ऑपरेंड
कुछ कार्रवाइयों, जैसे कि
ANEURALNETWORKS_LSH_PROJECTION,
में वैकल्पिक ऑपरेंड इस्तेमाल किए जाते हैं. मॉडल में यह बताने के लिए कि वैकल्पिक ऑपरेंड को शामिल नहीं किया गया है, ANeuralNetworksModel_setOperandValue() फ़ंक्शन को कॉल करें. इसके लिए, बफ़र के लिए NULL और लंबाई के लिए 0 पास करें.
अगर हर बार के एक्ज़ीक्यूशन के लिए, यह फ़ैसला अलग-अलग होता है कि ऑपरेंड मौजूद है या नहीं, तो ANeuralNetworksExecution_setInput() या ANeuralNetworksExecution_setOutput() फ़ंक्शन का इस्तेमाल करके यह बताया जाता है कि ऑपरेंड को शामिल नहीं किया गया है. इसके लिए, बफ़र के लिए NULL और लंबाई के लिए 0 पास किया जाता है.
अज्ञात रैंक वाले टेंसर
Android 9 (एपीआई लेवल 28) में, अज्ञात डाइमेंशन वाले मॉडल ऑपरेंड पेश किए गए थे. हालांकि, इनकी रैंक (डाइमेंशन की संख्या) के बारे में जानकारी थी. Android 10 (एपीआई लेवल 29) में, अननोन रैंक वाले टेंसर पेश किए गए थे. इन्हें ANeuralNetworksOperandType में दिखाया गया है.
NNAPI बेंचमार्क
NNAPI बेंचमार्क, AOSP पर platform/test/mlts/benchmark
(बेंचमार्क ऐप्लिकेशन) और platform/test/mlts/models (मॉडल और डेटासेट) में उपलब्ध है.
इस बेंचमार्क में, लेटेन्सी और सटीकता का आकलन किया जाता है. साथ ही, ड्राइवर की तुलना, सीपीयू पर चलने वाले TensorFlow Lite का इस्तेमाल करके किए गए काम से की जाती है. यह तुलना, एक ही मॉडल और डेटासेट के लिए की जाती है.
मानदंड का इस्तेमाल करने के लिए, यह तरीका अपनाएं:
टारगेट किए गए Android डिवाइस को अपने कंप्यूटर से कनेक्ट करें. इसके बाद, टर्मिनल विंडो खोलें और पक्का करें कि डिवाइस को adb के ज़रिए ऐक्सेस किया जा सकता है.
अगर एक से ज़्यादा Android डिवाइस कनेक्ट हैं, तो टारगेट डिवाइस के
ANDROID_SERIALएनवायरमेंट वैरिएबल को एक्सपोर्ट करें.Android की टॉप-लेवल सोर्स डायरेक्ट्री पर जाएं.
ये कमांड चलाएं:
lunch aosp_arm-userdebug # Or aosp_arm64-userdebug if available ./test/mlts/benchmark/build_and_run_benchmark.sh
बेंचमार्क रन के आखिर में, इसके नतीजे एचटीएमएल पेज के तौर पर दिखाए जाएंगे. यह पेज
xdg-openको भेजा जाएगा.
NNAPI लॉग
NNAPI, सिस्टम लॉग में गड़बड़ी की अहम जानकारी जनरेट करता है. लॉग का विश्लेषण करने के लिए, logcat यूटिलिटी का इस्तेमाल करें.
debug.nn.vlog प्रॉपर्टी (adb shell का इस्तेमाल करके) को यहां दी गई वैल्यू की सूची पर सेट करके, कुछ फ़ेज़ या कॉम्पोनेंट के लिए NNAPI की ज़्यादा जानकारी वाली लॉगिंग चालू करें. इन वैल्यू को स्पेस, कॉलन या कॉमा से अलग किया जाता है:
model: मॉडल बनानाcompilation: मॉडल को लागू करने के प्लान और कंपाइलेशन को जनरेट करनाexecution: मॉडल को लागू करनाcpuexe: NNAPI सीपीयू को लागू करने की सुविधा का इस्तेमाल करके ऑपरेशन पूरे करनाmanager: NNAPI एक्सटेंशन, उपलब्ध इंटरफ़ेस, और क्षमताओं से जुड़ी जानकारीallया1: ऊपर दिए गए सभी एलिमेंट
उदाहरण के लिए, पूरी Verbose logging चालू करने के लिए, adb shell setprop debug.nn.vlog all कमांड का इस्तेमाल करें. ज़्यादा जानकारी वाली लॉगिंग की सुविधा बंद करने के लिए, adb shell setprop debug.nn.vlog '""' कमांड का इस्तेमाल करें.
इस सुविधा को चालू करने पर, वर्बोस लॉगिंग से INFO लेवल पर लॉग एंट्री जनरेट होती हैं. इनमें टैग को फ़ेज़ या कॉम्पोनेंट के नाम पर सेट किया जाता है.
debug.nn.vlog कंट्रोल किए गए मैसेज के अलावा, NNAPI एपीआई कॉम्पोनेंट अलग-अलग लेवल पर अन्य लॉग एंट्री देते हैं. इनमें से हर एक, किसी खास लॉग टैग का इस्तेमाल करता है.
कॉम्पोनेंट की सूची पाने के लिए, सोर्स ट्री में यह एक्सप्रेशन खोजें:
grep -R 'define LOG_TAG' | awk -F '"' '{print $2}' | sort -u | egrep -v "Sample|FileTag|test"
फ़िलहाल, यह एक्सप्रेशन इन टैग को दिखाता है:
- BurstBuilder
- कॉलबैक
- CompilationBuilder
- CpuExecutor
- ExecutionBuilder
- ExecutionBurstController
- ExecutionBurstServer
- ExecutionPlan
- FibonacciDriver
- GraphDump
- IndexedShapeWrapper
- IonWatcher
- मैनेजर
- मेमोरी
- MemoryUtils
- MetaModel
- ModelArgumentInfo
- ModelBuilder
- NeuralNetworks
- OperationResolver
- ऑपरेशंस
- OperationsUtils
- PackageInfo
- TokenHasher
- TypeManager
- Utils
- ValidateHal
- VersionedInterfaces
logcat से दिखाए गए लॉग मैसेज के लेवल को कंट्रोल करने के लिए, ANDROID_LOG_TAGS एनवायरमेंट वैरिएबल का इस्तेमाल करें.
NNAPI के सभी लॉग मैसेज दिखाने और अन्य मैसेज बंद करने के लिए, ANDROID_LOG_TAGS को यहां दिए गए मान पर सेट करें:
BurstBuilder:V Callbacks:V CompilationBuilder:V CpuExecutor:V ExecutionBuilder:V ExecutionBurstController:V ExecutionBurstServer:V ExecutionPlan:V FibonacciDriver:V GraphDump:V IndexedShapeWrapper:V IonWatcher:V Manager:V MemoryUtils:V Memory:V MetaModel:V ModelArgumentInfo:V ModelBuilder:V NeuralNetworks:V OperationResolver:V OperationsUtils:V Operations:V PackageInfo:V TokenHasher:V TypeManager:V Utils:V ValidateHal:V VersionedInterfaces:V *:S.
ANDROID_LOG_TAGS को सेट करने के लिए, इस निर्देश का इस्तेमाल किया जा सकता है:
export ANDROID_LOG_TAGS=$(grep -R 'define LOG_TAG' | awk -F '"' '{ print $2 ":V" }' | sort -u | egrep -v "Sample|FileTag|test" | xargs echo -n; echo ' *:S')
ध्यान दें कि यह सिर्फ़ एक फ़िल्टर है, जो logcat पर लागू होता है. ज़्यादा जानकारी वाले लॉग जनरेट करने के लिए, आपको प्रॉपर्टी debug.nn.vlog को all पर सेट करना होगा.