
অ্যান্ড্রয়েড নিউরাল নেটওয়ার্ক এপিআই (এনএনএপিআই) হল একটি অ্যান্ড্রয়েড সি এপিআই যা অ্যান্ড্রয়েড ডিভাইসে মেশিন লার্নিংয়ের জন্য গণনামূলকভাবে নিবিড় অপারেশন চালানোর জন্য ডিজাইন করা হয়েছে। NNAPI উচ্চ-স্তরের মেশিন লার্নিং ফ্রেমওয়ার্ক, যেমন TensorFlow Lite এবং Caffe2, যেগুলি নিউরাল নেটওয়ার্ক তৈরি এবং প্রশিক্ষিত করে তার জন্য কার্যকারিতার একটি বেস লেয়ার প্রদান করার জন্য ডিজাইন করা হয়েছে। APIটি Android 8.1 (API লেভেল 27) বা উচ্চতর চলমান সমস্ত Android ডিভাইসে উপলব্ধ, কিন্তু Android 15-এ এটি বাতিল করা হয়েছে।
এনএনএপিআই পূর্বে প্রশিক্ষিত, বিকাশকারী-সংজ্ঞায়িত মডেলগুলিতে অ্যান্ড্রয়েড ডিভাইস থেকে ডেটা প্রয়োগ করে অনুমান সমর্থন করে। অনুমান করার উদাহরণগুলির মধ্যে রয়েছে চিত্রগুলিকে শ্রেণিবদ্ধ করা, ব্যবহারকারীর আচরণের পূর্বাভাস দেওয়া এবং একটি অনুসন্ধান প্রশ্নের উপযুক্ত প্রতিক্রিয়া নির্বাচন করা।
অন-ডিভাইস ইনফারেন্সিংয়ের অনেক সুবিধা রয়েছে:
- লেটেন্সি : আপনাকে একটি নেটওয়ার্ক সংযোগের মাধ্যমে একটি অনুরোধ পাঠাতে হবে না এবং একটি প্রতিক্রিয়ার জন্য অপেক্ষা করতে হবে৷ উদাহরণস্বরূপ, এটি ভিডিও অ্যাপ্লিকেশনগুলির জন্য গুরুত্বপূর্ণ হতে পারে যা একটি ক্যামেরা থেকে আসা ধারাবাহিক ফ্রেমগুলি প্রক্রিয়া করে৷
- উপলব্ধতা : নেটওয়ার্ক কভারেজের বাইরে থাকলেও অ্যাপ্লিকেশনটি চলে।
- গতি : নিউরাল নেটওয়ার্ক প্রক্রিয়াকরণের জন্য নির্দিষ্ট নতুন হার্ডওয়্যার একা সাধারণ-উদ্দেশ্য CPU-র তুলনায় উল্লেখযোগ্যভাবে দ্রুত গণনা প্রদান করে।
- গোপনীয়তা : ডেটা অ্যান্ড্রয়েড ডিভাইস ছেড়ে যায় না।
- খরচ : অ্যান্ড্রয়েড ডিভাইসে সমস্ত গণনা করা হলে কোনো সার্ভার ফার্মের প্রয়োজন হয় না।
এছাড়াও ট্রেড-অফ রয়েছে যা একজন বিকাশকারীকে মনে রাখা উচিত:
- সিস্টেম ইউটিলাইজেশন : নিউরাল নেটওয়ার্কের মূল্যায়নের জন্য অনেক কম্পিউটেশন জড়িত, যা ব্যাটারি পাওয়ার ব্যবহার বাড়াতে পারে। আপনার ব্যাটারি স্বাস্থ্য নিরীক্ষণ বিবেচনা করা উচিত যদি এটি আপনার অ্যাপের জন্য উদ্বেগ হয়, বিশেষ করে দীর্ঘস্থায়ী গণনার জন্য।
- অ্যাপ্লিকেশন আকার : আপনার মডেলের আকার মনোযোগ দিন. মডেলগুলি একাধিক মেগাবাইট স্থান নিতে পারে। যদি আপনার APK-এ বড় মডেলগুলিকে বান্ডিল করা আপনার ব্যবহারকারীদেরকে অযৌক্তিকভাবে প্রভাবিত করে, আপনি অ্যাপ ইনস্টলেশনের পরে মডেলগুলি ডাউনলোড করার, ছোট মডেলগুলি ব্যবহার করে বা ক্লাউডে আপনার গণনা চালানোর কথা বিবেচনা করতে পারেন৷ NNAPI ক্লাউডে মডেল চালানোর জন্য কার্যকারিতা প্রদান করে না।
কীভাবে NNAPI ব্যবহার করবেন তার একটি উদাহরণ দেখতে Android নিউরাল নেটওয়ার্ক API নমুনা দেখুন।
নিউরাল নেটওয়ার্ক API রানটাইম বুঝুন
NNAPI বলতে মেশিন লার্নিং লাইব্রেরি, ফ্রেমওয়ার্ক এবং টুল দ্বারা ডাকা হয় যা ডেভেলপারদের তাদের মডেলগুলিকে ডিভাইসের বাইরে প্রশিক্ষণ দিতে এবং Android ডিভাইসে স্থাপন করতে দেয়। অ্যাপগুলি সাধারণত সরাসরি NNAPI ব্যবহার করবে না, বরং উচ্চ-স্তরের মেশিন লার্নিং ফ্রেমওয়ার্ক ব্যবহার করবে। এই ফ্রেমওয়ার্কগুলি পরিবর্তিতভাবে সমর্থিত ডিভাইসগুলিতে হার্ডওয়্যার-ত্বরিত অনুমান ক্রিয়াকলাপ সম্পাদন করতে NNAPI ব্যবহার করতে পারে।
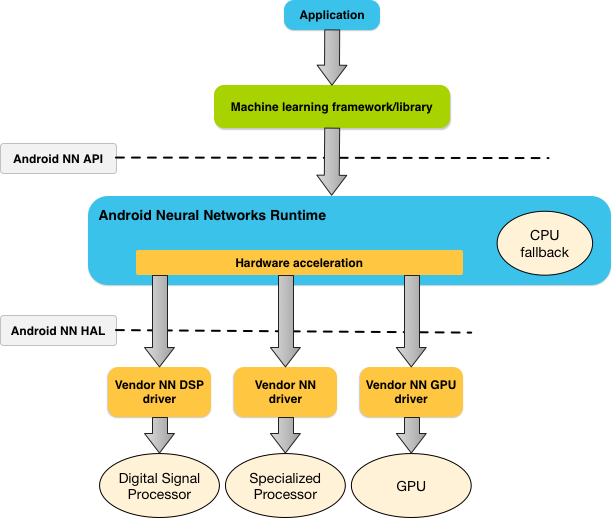
একটি অ্যাপের প্রয়োজনীয়তা এবং একটি অ্যান্ড্রয়েড ডিভাইসে হার্ডওয়্যার ক্ষমতার উপর ভিত্তি করে, অ্যান্ড্রয়েডের নিউরাল নেটওয়ার্ক রানটাইম দক্ষতার সাথে ডেডিকেটেড নিউরাল নেটওয়ার্ক হার্ডওয়্যার, গ্রাফিক্স প্রসেসিং ইউনিট (GPUs) এবং ডিজিটাল সিগন্যাল প্রসেসর (DSPs) সহ উপলব্ধ অন-ডিভাইস প্রসেসর জুড়ে গণনার কাজের চাপ বিতরণ করতে পারে।
যে অ্যান্ড্রয়েড ডিভাইসগুলির জন্য একটি বিশেষ বিক্রেতা ড্রাইভারের অভাব রয়েছে, NNAPI রানটাইম CPU-তে অনুরোধগুলি কার্যকর করে৷
চিত্র 1 NNAPI-এর জন্য উচ্চ-স্তরের সিস্টেম আর্কিটেকচার দেখায়।
নিউরাল নেটওয়ার্ক এপিআই প্রোগ্রামিং মডেল
NNAPI ব্যবহার করে গণনা সম্পাদন করতে, আপনাকে প্রথমে একটি নির্দেশিত গ্রাফ তৈরি করতে হবে যা সঞ্চালনের জন্য গণনাগুলিকে সংজ্ঞায়িত করে। এই গণনা গ্রাফ, আপনার ইনপুট ডেটার সাথে মিলিত (উদাহরণস্বরূপ, একটি মেশিন লার্নিং ফ্রেমওয়ার্ক থেকে প্রাপ্ত ওজন এবং পক্ষপাত), NNAPI রানটাইম মূল্যায়নের মডেল তৈরি করে।
NNAPI চারটি প্রধান বিমূর্ততা ব্যবহার করে:
- মডেল : গাণিতিক ক্রিয়াকলাপগুলির একটি গণনা গ্রাফ এবং একটি প্রশিক্ষণ প্রক্রিয়ার মাধ্যমে শেখা ধ্রুবক মান। এই অপারেশনগুলি নিউরাল নেটওয়ার্কের জন্য নির্দিষ্ট। এর মধ্যে রয়েছে 2-মাত্রিক (2D) কনভোলিউশন , লজিস্টিক ( সিগমায়েড ) অ্যাক্টিভেশন, রেক্টিফায়েড লিনিয়ার (ReLU) অ্যাক্টিভেশন এবং আরও অনেক কিছু। একটি মডেল তৈরি করা একটি সিঙ্ক্রোনাস অপারেশন। একবার সফলভাবে তৈরি হয়ে গেলে, এটি থ্রেড এবং সংকলন জুড়ে পুনরায় ব্যবহার করা যেতে পারে। এনএনএপিআই-তে, একটি মডেলকে একটি
ANeuralNetworksModelউদাহরণ হিসাবে উপস্থাপন করা হয়। - সংকলন : নিম্ন-স্তরের কোডে একটি NNAPI মডেল কম্পাইল করার জন্য একটি কনফিগারেশনের প্রতিনিধিত্ব করে। একটি সংকলন তৈরি করা একটি সিঙ্ক্রোনাস অপারেশন। একবার সফলভাবে তৈরি হয়ে গেলে, এটি থ্রেড এবং মৃত্যুদন্ড জুড়ে পুনরায় ব্যবহার করা যেতে পারে। এনএনএপিআই-এ, প্রতিটি সংকলন একটি
ANeuralNetworksCompilationউদাহরণ হিসাবে উপস্থাপন করা হয়। - মেমরি : শেয়ার করা মেমরি, মেমরি ম্যাপ করা ফাইল এবং অনুরূপ মেমরি বাফার প্রতিনিধিত্ব করে। একটি মেমরি বাফার ব্যবহার করে NNAPI রানটাইম ডেটা আরও দক্ষতার সাথে ড্রাইভারদের কাছে স্থানান্তর করতে দেয়। একটি অ্যাপ সাধারণত একটি ভাগ করা মেমরি বাফার তৈরি করে যাতে একটি মডেল সংজ্ঞায়িত করার জন্য প্রয়োজনীয় প্রতিটি টেনসর থাকে। আপনি একটি কার্যকরী উদাহরণের জন্য ইনপুট এবং আউটপুট সংরক্ষণ করতে মেমরি বাফার ব্যবহার করতে পারেন। এনএনএপিআই-এ, প্রতিটি মেমরি বাফার একটি
ANeuralNetworksMemoryউদাহরণ হিসাবে উপস্থাপন করা হয়। এক্সিকিউশন : ইনপুটগুলির একটি সেটে একটি NNAPI মডেল প্রয়োগ করার জন্য এবং ফলাফল সংগ্রহের জন্য ইন্টারফেস। এক্সিকিউশন সিঙ্ক্রোনাস বা অ্যাসিঙ্ক্রোনাসভাবে সঞ্চালিত হতে পারে।
অ্যাসিঙ্ক্রোনাস এক্সিকিউশনের জন্য, একাধিক থ্রেড একই এক্সিকিউশনের জন্য অপেক্ষা করতে পারে। এই এক্সিকিউশন শেষ হলে, সমস্ত থ্রেড রিলিজ হয়।
এনএনএপিআই-এ, প্রতিটি মৃত্যুদন্ডকে একটি
ANeuralNetworksExecutionউদাহরণ হিসাবে উপস্থাপন করা হয়।
চিত্র 2 মৌলিক প্রোগ্রামিং প্রবাহ দেখায়।
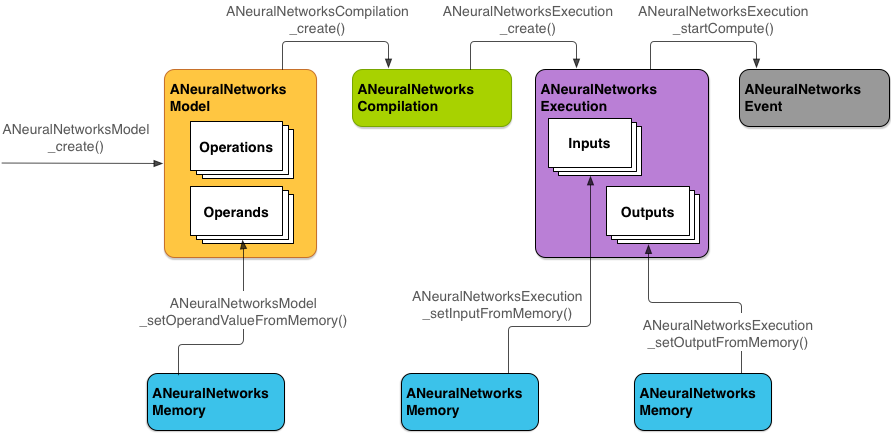
এই বিভাগের বাকি অংশে আপনার NNAPI মডেল সেট আপ করার ধাপগুলি গণনা করা, মডেল কম্পাইল করা এবং কম্পাইল করা মডেল চালানোর জন্য বর্ণনা করা হয়েছে।
প্রশিক্ষণ তথ্য অ্যাক্সেস প্রদান
আপনার প্রশিক্ষিত ওজন এবং পক্ষপাতের ডেটা সম্ভবত একটি ফাইলে সংরক্ষণ করা হয়। এই ডেটাতে দক্ষ অ্যাক্সেস সহ NNAPI রানটাইম প্রদান করতে, ANeuralNetworksMemory_createFromFd() ফাংশনে কল করে এবং খোলা ডেটা ফাইলের ফাইল বর্ণনাকারীতে পাস করে একটি ANeuralNetworksMemory উদাহরণ তৈরি করুন। আপনি মেমরি সুরক্ষা পতাকা এবং একটি অফসেট উল্লেখ করেন যেখানে ফাইলটিতে ভাগ করা মেমরি অঞ্চল শুরু হয়।
// Create a memory buffer from the file that contains the trained data
ANeuralNetworksMemory* mem1 = NULL;
int fd = open("training_data", O_RDONLY);
ANeuralNetworksMemory_createFromFd(file_size, PROT_READ, fd, 0, &mem1);
যদিও এই উদাহরণে আমরা আমাদের সমস্ত ওজনের জন্য শুধুমাত্র একটি ANeuralNetworksMemory উদাহরণ ব্যবহার করি, একাধিক ফাইলের জন্য একাধিক ANeuralNetworksMemory উদাহরণ ব্যবহার করা সম্ভব।
নেটিভ হার্ডওয়্যার বাফার ব্যবহার করুন
আপনি মডেল ইনপুট, আউটপুট এবং ধ্রুবক অপারেন্ড মানগুলির জন্য নেটিভ হার্ডওয়্যার বাফার ব্যবহার করতে পারেন। কিছু ক্ষেত্রে, একটি এনএনএপিআই অ্যাক্সিলারেটর AHardwareBuffer অবজেক্ট অ্যাক্সেস করতে পারে ড্রাইভারকে ডেটা কপি করার প্রয়োজন ছাড়াই। AHardwareBuffer অনেকগুলি ভিন্ন কনফিগারেশন রয়েছে এবং প্রতিটি NNAPI অ্যাক্সিলারেটর এই সমস্ত কনফিগারেশনকে সমর্থন করতে পারে না। এই সীমাবদ্ধতার কারণে, ANeuralNetworksMemory_createFromAHardwareBuffer রেফারেন্স ডকুমেন্টেশনে তালিকাভুক্ত সীমাবদ্ধতাগুলি পড়ুন এবং AHardwareBuffer ব্যবহার করে এমন সংকলন এবং এক্সিকিউশনগুলি নিশ্চিত করার জন্য নির্ধারিত ডিভাইসগুলিতে সময়ের আগে পরীক্ষা করুন, যাতে এক্সিলারেটর নির্দিষ্ট করার জন্য ডিভাইস অ্যাসাইনমেন্ট ব্যবহার করা হয়।
NNAPI রানটাইমকে একটি AHardwareBuffer অবজেক্ট অ্যাক্সেস করার অনুমতি দিতে, ANeuralNetworksMemory_createFromAHardwareBuffer ফাংশনকে কল করে এবং AHardwareBuffer অবজেক্টে পাস করার মাধ্যমে একটি ANeuralNetworksMemory উদাহরণ তৈরি করুন, যেমনটি নিম্নলিখিত কোড নমুনায় দেখানো হয়েছে:
// Configure and create AHardwareBuffer object AHardwareBuffer_Desc desc = ... AHardwareBuffer* ahwb = nullptr; AHardwareBuffer_allocate(&desc, &ahwb); // Create ANeuralNetworksMemory from AHardwareBuffer ANeuralNetworksMemory* mem2 = NULL; ANeuralNetworksMemory_createFromAHardwareBuffer(ahwb, &mem2);
যখন NNAPI-এর আর AHardwareBuffer অবজেক্ট অ্যাক্সেস করার প্রয়োজন নেই, তখন সংশ্লিষ্ট ANeuralNetworksMemory দৃষ্টান্ত মুক্ত করুন:
ANeuralNetworksMemory_free(mem2);
দ্রষ্টব্য:
- আপনি শুধুমাত্র পুরো বাফারের জন্য
AHardwareBufferব্যবহার করতে পারেন; আপনি এটি একটিARectপ্যারামিটার দিয়ে ব্যবহার করতে পারবেন না। - NNAPI রানটাইম বাফার ফ্লাশ করবে না। কার্যকর করার সময়সূচী করার আগে আপনাকে নিশ্চিত করতে হবে যে ইনপুট এবং আউটপুট বাফারগুলি অ্যাক্সেসযোগ্য।
- সিঙ্ক বেড়া ফাইল বর্ণনাকারীর জন্য কোন সমর্থন নেই.
- বিক্রেতা-নির্দিষ্ট ফর্ম্যাট এবং ব্যবহারের বিট সহ একটি
AHardwareBufferজন্য, ক্যাশে ফ্লাশ করার জন্য ক্লায়েন্ট বা ড্রাইভার দায়ী কিনা তা নির্ধারণ করা বিক্রেতার বাস্তবায়নের উপর নির্ভর করে।
মডেল
একটি মডেল হল NNAPI-তে গণনার মৌলিক একক। প্রতিটি মডেল এক বা একাধিক অপারেন্ড এবং অপারেশন দ্বারা সংজ্ঞায়িত করা হয়।
অপারেন্ডস
অপারেন্ডগুলি গ্রাফ সংজ্ঞায়িত করতে ব্যবহৃত ডেটা অবজেক্ট। এর মধ্যে রয়েছে মডেলের ইনপুট এবং আউটপুট, মধ্যবর্তী নোড যা ডেটা ধারণ করে যা এক অপারেশন থেকে অন্যটিতে প্রবাহিত হয় এবং এই ক্রিয়াকলাপে পাস করা ধ্রুবকগুলি।
NNAPI মডেলগুলিতে দুটি ধরণের অপারেন্ড যুক্ত করা যেতে পারে: স্কেলার এবং টেনসর ।
একটি স্কেলার একটি একক মান প্রতিনিধিত্ব করে। NNAPI বুলিয়ান, 16-বিট ফ্লোটিং পয়েন্ট, 32-বিট ফ্লোটিং পয়েন্ট, 32-বিট পূর্ণসংখ্যা, এবং স্বাক্ষরবিহীন 32-বিট পূর্ণসংখ্যা বিন্যাসে স্কেলার মান সমর্থন করে।
এনএনএপিআই-এর বেশিরভাগ অপারেশনে টেনসর জড়িত থাকে। টেনসর হল এন-ডাইমেনশনাল অ্যারে। NNAPI 16-বিট ফ্লোটিং পয়েন্ট, 32-বিট ফ্লোটিং পয়েন্ট, 8-বিট কোয়ান্টাইজড , 16-বিট কোয়ান্টাইজড, 32-বিট পূর্ণসংখ্যা, এবং 8-বিট বুলিয়ান মান সহ টেনসর সমর্থন করে।
উদাহরণস্বরূপ, চিত্র 3 দুটি ক্রিয়াকলাপ সহ একটি মডেলকে উপস্থাপন করে: একটি সংযোজন তারপর একটি গুণ। মডেলটি একটি ইনপুট টেনসর নেয় এবং একটি আউটপুট টেনসর তৈরি করে।
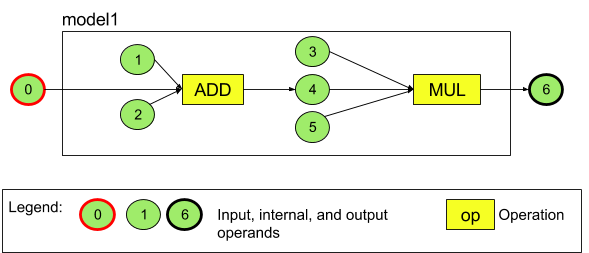
উপরের মডেলটিতে সাতটি অপারেন্ড রয়েছে। এই অপারেন্ডগুলিকে মডেলে যে ক্রমানুসারে যুক্ত করা হয় তার সূচী দ্বারা নিহিতভাবে চিহ্নিত করা হয়। যোগ করা প্রথম অপারেন্ডের একটি সূচক আছে 0, দ্বিতীয়টির সূচক 1, ইত্যাদি। অপারেন্ড 1, 2, 3, এবং 5 ধ্রুবক অপারেন্ড।
আপনি যে ক্রমে অপারেন্ড যোগ করেন তাতে কিছু যায় আসে না। উদাহরণস্বরূপ, মডেল আউটপুট অপারেন্ড প্রথম যোগ করা হতে পারে। গুরুত্বপূর্ণ অংশটি হল একটি অপারেন্ড উল্লেখ করার সময় সঠিক সূচক মান ব্যবহার করা।
অপারেন্ডের ধরন আছে। এগুলি মডেলে যোগ করার সময় নির্দিষ্ট করা হয়।
একটি অপারেন্ড একটি মডেলের ইনপুট এবং আউটপুট উভয় হিসাবে ব্যবহার করা যাবে না।
প্রতিটি অপারেন্ড অবশ্যই একটি মডেল ইনপুট, একটি ধ্রুবক, বা ঠিক একটি অপারেশনের আউটপুট অপারেন্ড হতে হবে।
অপারেন্ড ব্যবহার সম্পর্কে অতিরিক্ত তথ্যের জন্য, অপারেন্ড সম্পর্কে আরও দেখুন।
অপারেশন
একটি অপারেশন সঞ্চালিত গণনা নির্দিষ্ট করে। প্রতিটি অপারেশন নিম্নলিখিত উপাদান নিয়ে গঠিত:
- একটি অপারেশন টাইপ (উদাহরণস্বরূপ, যোগ, গুণ, কনভল্যুশন),
- অপারেন্ডের সূচীগুলির একটি তালিকা যা অপারেশন ইনপুটের জন্য ব্যবহার করে এবং
- অপারেন্ডের সূচীগুলির একটি তালিকা যা অপারেশন আউটপুটের জন্য ব্যবহার করে।
এই তালিকার ক্রম গুরুত্বপূর্ণ; প্রতিটি অপারেশন প্রকারের প্রত্যাশিত ইনপুট এবং আউটপুটের জন্য NNAPI API রেফারেন্স দেখুন।
অপারেশন যোগ করার আগে আপনাকে অবশ্যই সেই অপারেন্ডগুলি যোগ করতে হবে যা একটি অপারেশন ব্যবহার করে বা তৈরি করে মডেলটিতে।
আপনি যে ক্রমানুসারে ক্রিয়াকলাপ যুক্ত করেন তাতে কিছু যায় আসে না। এনএনএপিআই অপারেন্ড এবং অপারেশনগুলির গণনা গ্রাফ দ্বারা প্রতিষ্ঠিত নির্ভরতার উপর নির্ভর করে যে ক্রমানুসারে অপারেশন চালানো হয় তা নির্ধারণ করতে।
NNAPI যে ক্রিয়াকলাপগুলিকে সমর্থন করে সেগুলি নীচের সারণীতে সংক্ষিপ্ত করা হয়েছে:
API স্তর 28-এ পরিচিত সমস্যা: ANEURALNETWORKS_PAD অপারেশনে ANEURALNETWORKS_TENSOR_QUANT8_ASYMM টেনসর পাস করার সময়, যা Android 9 (API স্তর 28) এবং উচ্চতর তে পাওয়া যায়, NNAPI-এর আউটপুট উচ্চ-স্তরের মেশিন লার্নিং ফ্রেমওয়ার্ক, যেমন TF-এর নিম্ন স্তরের আউটপুটের সাথে মেলে না। আপনার পরিবর্তে শুধুমাত্র ANEURALNETWORKS_TENSOR_FLOAT32 পাস করা উচিত। সমস্যাটি Android 10 (API স্তর 29) এবং উচ্চতর সংস্করণে সমাধান করা হয়েছে।
মডেল তৈরি করুন
নিম্নলিখিত উদাহরণে, আমরা চিত্র 3- এ পাওয়া দুই-অপারেশন মডেল তৈরি করি।
মডেল তৈরি করতে, এই পদক্ষেপগুলি অনুসরণ করুন:
একটি খালি মডেল সংজ্ঞায়িত করতে
ANeuralNetworksModel_create()ফাংশনটি কল করুন।ANeuralNetworksModel* model = NULL; ANeuralNetworksModel_create(&model);
ANeuralNetworks_addOperand()কল করে আপনার মডেলে অপারেন্ড যোগ করুন। তাদের ডেটা প্রকারগুলিANeuralNetworksOperandTypeডেটা কাঠামো ব্যবহার করে সংজ্ঞায়িত করা হয়।// In our example, all our tensors are matrices of dimension [3][4] ANeuralNetworksOperandType tensor3x4Type; tensor3x4Type.type = ANEURALNETWORKS_TENSOR_FLOAT32; tensor3x4Type.scale = 0.f; // These fields are used for quantized tensors tensor3x4Type.zeroPoint = 0; // These fields are used for quantized tensors tensor3x4Type.dimensionCount = 2; uint32_t dims[2] = {3, 4}; tensor3x4Type.dimensions = dims;
// We also specify operands that are activation function specifiers ANeuralNetworksOperandType activationType; activationType.type = ANEURALNETWORKS_INT32; activationType.scale = 0.f; activationType.zeroPoint = 0; activationType.dimensionCount = 0; activationType.dimensions = NULL;
// Now we add the seven operands, in the same order defined in the diagram ANeuralNetworksModel_addOperand(model, &tensor3x4Type); // operand 0 ANeuralNetworksModel_addOperand(model, &tensor3x4Type); // operand 1 ANeuralNetworksModel_addOperand(model, &activationType); // operand 2 ANeuralNetworksModel_addOperand(model, &tensor3x4Type); // operand 3 ANeuralNetworksModel_addOperand(model, &tensor3x4Type); // operand 4 ANeuralNetworksModel_addOperand(model, &activationType); // operand 5 ANeuralNetworksModel_addOperand(model, &tensor3x4Type); // operand 6যে অপারেন্ডগুলির ধ্রুবক মান রয়েছে, যেমন ওজন এবং পক্ষপাত যা আপনার অ্যাপ প্রশিক্ষণ প্রক্রিয়া থেকে প্রাপ্ত হয়,
ANeuralNetworksModel_setOperandValue()এবংANeuralNetworksModel_setOperandValueFromMemory()ফাংশনগুলি ব্যবহার করুন৷নিম্নলিখিত উদাহরণে, আমরা প্রশিক্ষণ ডেটার অ্যাক্সেস প্রদানে তৈরি করা মেমরি বাফারের সাথে সম্পর্কিত প্রশিক্ষণ ডেটা ফাইল থেকে ধ্রুবক মান সেট করি।
// In our example, operands 1 and 3 are constant tensors whose values were // established during the training process const int sizeOfTensor = 3 * 4 * 4; // The formula for size calculation is dim0 * dim1 * elementSize ANeuralNetworksModel_setOperandValueFromMemory(model, 1, mem1, 0, sizeOfTensor); ANeuralNetworksModel_setOperandValueFromMemory(model, 3, mem1, sizeOfTensor, sizeOfTensor);
// We set the values of the activation operands, in our example operands 2 and 5 int32_t noneValue = ANEURALNETWORKS_FUSED_NONE; ANeuralNetworksModel_setOperandValue(model, 2, &noneValue, sizeof(noneValue)); ANeuralNetworksModel_setOperandValue(model, 5, &noneValue, sizeof(noneValue));নির্দেশিত গ্রাফের প্রতিটি অপারেশনের জন্য আপনি গণনা করতে চান,
ANeuralNetworksModel_addOperation()ফাংশন কল করে আপনার মডেলে অপারেশন যোগ করুন।এই কলের পরামিতি হিসাবে, আপনার অ্যাপ অবশ্যই প্রদান করবে:
- অপারেশন প্রকার
- ইনপুট মান গণনা
- ইনপুট অপারেন্ডের জন্য ইনডেক্সের অ্যারে
- আউটপুট মান গণনা
- আউটপুট অপারেন্ডের জন্য ইনডেক্সের অ্যারে
মনে রাখবেন যে একটি অপারেন্ড একই অপারেশনের ইনপুট এবং আউটপুট উভয়ের জন্য ব্যবহার করা যাবে না।
// We have two operations in our example // The first consumes operands 1, 0, 2, and produces operand 4 uint32_t addInputIndexes[3] = {1, 0, 2}; uint32_t addOutputIndexes[1] = {4}; ANeuralNetworksModel_addOperation(model, ANEURALNETWORKS_ADD, 3, addInputIndexes, 1, addOutputIndexes);
// The second consumes operands 3, 4, 5, and produces operand 6 uint32_t multInputIndexes[3] = {3, 4, 5}; uint32_t multOutputIndexes[1] = {6}; ANeuralNetworksModel_addOperation(model, ANEURALNETWORKS_MUL, 3, multInputIndexes, 1, multOutputIndexes);ANeuralNetworksModel_identifyInputsAndOutputs()ফাংশন কল করে মডেলটির কোন অপারেন্ডগুলিকে তার ইনপুট এবং আউটপুট হিসাবে বিবেচনা করা উচিত তা সনাক্ত করুন৷// Our model has one input (0) and one output (6) uint32_t modelInputIndexes[1] = {0}; uint32_t modelOutputIndexes[1] = {6}; ANeuralNetworksModel_identifyInputsAndOutputs(model, 1, modelInputIndexes, 1 modelOutputIndexes);
ঐচ্ছিকভাবে,
ANEURALNETWORKS_TENSOR_FLOAT32IEEE 754 16-বিট ফ্লোটিং-পয়েন্ট ফরম্যাটের মতো কম পরিসীমা বা নির্ভুলতার সাথে গণনা করার অনুমতি দেওয়া হয়েছে কিনা তা উল্লেখ করুনANeuralNetworksModel_relaxComputationFloat32toFloat16()কল করে।আপনার মডেলের সংজ্ঞা চূড়ান্ত করতে
ANeuralNetworksModel_finish()কে কল করুন। যদি কোন ত্রুটি না থাকে, এই ফাংশনটিANEURALNETWORKS_NO_ERRORএর ফলাফল কোড প্রদান করে।ANeuralNetworksModel_finish(model);
একবার আপনি একটি মডেল তৈরি করার পরে, আপনি এটি যেকোন সংখ্যক বার কম্পাইল করতে পারেন এবং প্রতিটি কম্পাইলেশন যেকোন সংখ্যক বার চালাতে পারেন।
নিয়ন্ত্রণ প্রবাহ
একটি NNAPI মডেলে নিয়ন্ত্রণ প্রবাহকে অন্তর্ভুক্ত করতে, নিম্নলিখিতগুলি করুন:
স্বতন্ত্র
ANeuralNetworksModel*মডেল হিসাবে সংশ্লিষ্ট এক্সিকিউশন সাবগ্রাফগুলি (thenelseএকটিWHILEলুপের জন্য একটিIFস্টেটমেন্ট,conditionএবংbodyসাবগ্রাফের জন্য সাবগ্রাফ) তৈরি করুন:ANeuralNetworksModel* thenModel = makeThenModel(); ANeuralNetworksModel* elseModel = makeElseModel();
অপারেন্ড তৈরি করুন যা নিয়ন্ত্রণ প্রবাহ ধারণকারী মডেলের মধ্যে সেই মডেলগুলিকে উল্লেখ করে:
ANeuralNetworksOperandType modelType = { .type = ANEURALNETWORKS_MODEL, }; ANeuralNetworksModel_addOperand(model, &modelType); // kThenOperandIndex ANeuralNetworksModel_addOperand(model, &modelType); // kElseOperandIndex ANeuralNetworksModel_setOperandValueFromModel(model, kThenOperandIndex, &thenModel); ANeuralNetworksModel_setOperandValueFromModel(model, kElseOperandIndex, &elseModel);
নিয়ন্ত্রণ প্রবাহ অপারেশন যোগ করুন:
uint32_t inputs[] = {kConditionOperandIndex, kThenOperandIndex, kElseOperandIndex, kInput1, kInput2, kInput3}; uint32_t outputs[] = {kOutput1, kOutput2}; ANeuralNetworksModel_addOperation(model, ANEURALNETWORKS_IF, std::size(inputs), inputs, std::size(output), outputs);
সংকলন
সংকলন পদক্ষেপটি নির্ধারণ করে যে কোন প্রসেসরগুলিতে আপনার মডেলটি কার্যকর করা হবে এবং সংশ্লিষ্ট ড্রাইভারদের এটি কার্যকর করার জন্য প্রস্তুত করতে বলে। আপনার মডেল যে প্রসেসরগুলিতে চলবে তার জন্য নির্দিষ্ট মেশিন কোডের জেনারেশন এর মধ্যে অন্তর্ভুক্ত থাকতে পারে।
একটি মডেল কম্পাইল করতে, এই পদক্ষেপগুলি অনুসরণ করুন:
একটি নতুন সংকলন উদাহরণ তৈরি করতে
ANeuralNetworksCompilation_create()ফাংশনটি কল করুন।// Compile the model ANeuralNetworksCompilation* compilation; ANeuralNetworksCompilation_create(model, &compilation);
ঐচ্ছিকভাবে, কোন ডিভাইসে এক্সিকিউট করতে হবে তা স্পষ্টভাবে বেছে নিতে আপনি ডিভাইস অ্যাসাইনমেন্ট ব্যবহার করতে পারেন।
আপনি ঐচ্ছিকভাবে ব্যাটারি পাওয়ার ব্যবহার এবং এক্সিকিউশন স্পিডের মধ্যে রানটাইম কিভাবে ব্যবসা বন্ধ করে তা প্রভাবিত করতে পারেন। আপনি
ANeuralNetworksCompilation_setPreference()কল করে তা করতে পারেন।// Ask to optimize for low power consumption ANeuralNetworksCompilation_setPreference(compilation, ANEURALNETWORKS_PREFER_LOW_POWER);
আপনি যে পছন্দগুলি নির্দিষ্ট করতে পারেন সেগুলির মধ্যে রয়েছে:
-
ANEURALNETWORKS_PREFER_LOW_POWER: ব্যাটারি ড্রেন কম করে এমনভাবে কার্যকর করা পছন্দ করুন। এটি প্রায়শই কার্যকর করা হয় এমন সংকলনের জন্য বাঞ্ছনীয়। -
ANEURALNETWORKS_PREFER_FAST_SINGLE_ANSWER: যত দ্রুত সম্ভব একটি একক উত্তর ফেরত দিতে পছন্দ করুন, এমনকি যদি এর ফলে বেশি বিদ্যুৎ খরচ হয়। এটি ডিফল্ট। -
ANEURALNETWORKS_PREFER_SUSTAINED_SPEED: ধারাবাহিক ফ্রেমের থ্রুপুট সর্বাধিক করা পছন্দ করুন, যেমন ক্যামেরা থেকে আসা ধারাবাহিক ফ্রেমগুলি প্রক্রিয়া করার সময়৷
-
আপনি
ANeuralNetworksCompilation_setCachingএ কল করে ঐচ্ছিকভাবে কম্পাইলেশন ক্যাশিং সেট আপ করতে পারেন।// Set up compilation caching ANeuralNetworksCompilation_setCaching(compilation, cacheDir, token);
cacheDirএর জন্যgetCodeCacheDir()ব্যবহার করুন। নির্দিষ্ট করাtokenঅবশ্যই আবেদনের মধ্যে প্রতিটি মডেলের জন্য অনন্য হতে হবে।ANeuralNetworksCompilation_finish()কল করে সংকলনের সংজ্ঞা চূড়ান্ত করুন। যদি কোন ত্রুটি না থাকে, এই ফাংশনটিANEURALNETWORKS_NO_ERRORএর ফলাফল কোড প্রদান করে।ANeuralNetworksCompilation_finish(compilation);
ডিভাইস আবিষ্কার এবং অ্যাসাইনমেন্ট
Android 10 (API স্তর 29) এবং উচ্চতর চলমান Android ডিভাইসগুলিতে, NNAPI এমন ফাংশন সরবরাহ করে যা মেশিন লার্নিং ফ্রেমওয়ার্ক লাইব্রেরি এবং অ্যাপগুলিকে উপলব্ধ ডিভাইসগুলি সম্পর্কে তথ্য পেতে এবং কার্যকর করার জন্য ব্যবহার করা ডিভাইসগুলিকে নির্দিষ্ট করতে দেয়৷ উপলব্ধ ডিভাইসগুলি সম্পর্কে তথ্য প্রদান করা অ্যাপগুলিকে পরিচিত অসঙ্গতিগুলি এড়াতে ডিভাইসে পাওয়া ড্রাইভারগুলির সঠিক সংস্করণ পেতে দেয়৷ অ্যাপগুলিকে নির্দিষ্ট করার ক্ষমতা দেওয়ার মাধ্যমে কোন ডিভাইসগুলি একটি মডেলের বিভিন্ন বিভাগ চালাতে পারে, অ্যাপগুলিকে Android ডিভাইসের জন্য অপ্টিমাইজ করা যেতে পারে যেটিতে তারা স্থাপন করা হয়েছে৷
ডিভাইস আবিষ্কার
উপলব্ধ ডিভাইসের সংখ্যা পেতে ANeuralNetworks_getDeviceCount ব্যবহার করুন। প্রতিটি ডিভাইসের জন্য, সেই ডিভাইসের একটি রেফারেন্সে একটি ANeuralNetworksDevice উদাহরণ সেট করতে ANeuralNetworks_getDevice ব্যবহার করুন।
একবার আপনার কাছে একটি ডিভাইসের রেফারেন্স হয়ে গেলে, আপনি নিম্নলিখিত ফাংশনগুলি ব্যবহার করে সেই ডিভাইস সম্পর্কে অতিরিক্ত তথ্য জানতে পারেন:
-
ANeuralNetworksDevice_getFeatureLevel -
ANeuralNetworksDevice_getName -
ANeuralNetworksDevice_getType -
ANeuralNetworksDevice_getVersion
ডিভাইস অ্যাসাইনমেন্ট
একটি মডেলের কোন অপারেশনগুলি নির্দিষ্ট ডিভাইসে চালানো যেতে পারে তা আবিষ্কার করতে ANeuralNetworksModel_getSupportedOperationsForDevices ব্যবহার করুন।
এক্সিকিউশনের জন্য কোন এক্সিলারেটর ব্যবহার করতে হবে তা নিয়ন্ত্রণ করতে, ANeuralNetworksCompilation_createForDevices এর জায়গায় ANeuralNetworksCompilation_create কল করুন। স্বাভাবিক হিসাবে, ফলে ANeuralNetworksCompilation অবজেক্ট ব্যবহার করুন। ফাংশনটি একটি ত্রুটি প্রদান করে যদি প্রদত্ত মডেলটিতে এমন অপারেশন থাকে যা নির্বাচিত ডিভাইস দ্বারা সমর্থিত নয়।
একাধিক ডিভাইস নির্দিষ্ট করা থাকলে, রানটাইম সমস্ত ডিভাইস জুড়ে কাজ বিতরণের জন্য দায়ী।
অন্যান্য ডিভাইসের মতোই, NNAPI CPU বাস্তবায়ন একটি ANeuralNetworksDevice দ্বারা nnapi-reference এবং প্রকার ANEURALNETWORKS_DEVICE_TYPE_CPU দ্বারা উপস্থাপিত হয়। ANeuralNetworksCompilation_createForDevices কল করার সময়, মডেল সংকলন এবং সম্পাদনের জন্য ব্যর্থতার ঘটনাগুলি পরিচালনা করতে CPU বাস্তবায়ন ব্যবহার করা হয় না।
একটি মডেলকে সাব-মডেলে বিভাজন করা একটি অ্যাপ্লিকেশনের দায়িত্ব যা নির্দিষ্ট ডিভাইসে চলতে পারে। যে অ্যাপ্লিকেশনগুলিকে ম্যানুয়াল পার্টিশন করার প্রয়োজন নেই সেগুলিকে মডেলটিকে ত্বরান্বিত করতে সমস্ত উপলব্ধ ডিভাইস (সিপিইউ সহ) ব্যবহার করার জন্য সহজ ANeuralNetworksCompilation_create কল করা চালিয়ে যেতে হবে। ANeuralNetworksCompilation_createForDevices ব্যবহার করে আপনার নির্দিষ্ট করা ডিভাইসগুলির দ্বারা মডেলটি সম্পূর্ণরূপে সমর্থিত না হলে, ANEURALNETWORKS_BAD_DATA ফেরত দেওয়া হয়।
মডেল পার্টিশন
যখন মডেলের জন্য একাধিক ডিভাইস উপলব্ধ থাকে, তখন NNAPI রানটাইম সমস্ত ডিভাইস জুড়ে কাজ বিতরণ করে। উদাহরণ স্বরূপ, যদি ANeuralNetworksCompilation_createForDevices এ একাধিক ডিভাইস সরবরাহ করা হয়, তবে কাজ বরাদ্দ করার সময় সমস্ত নির্দিষ্ট ডিভাইস বিবেচনা করা হবে। মনে রাখবেন, যদি সিপিইউ ডিভাইস তালিকায় না থাকে, তাহলে সিপিইউ এক্সিকিউশন অক্ষম করা হবে। ANeuralNetworksCompilation_create ব্যবহার করার সময় CPU সহ উপলব্ধ সমস্ত ডিভাইস বিবেচনা করা হবে।
উপলব্ধ ডিভাইসের তালিকা থেকে, মডেলের প্রতিটি ক্রিয়াকলাপের জন্য, অপারেশন সমর্থনকারী ডিভাইস এবং সর্বোত্তম কার্যক্ষমতা ঘোষণা করে, অর্থাত্ দ্রুততম কার্যকর করার সময় বা সর্বনিম্ন শক্তি খরচ, ক্লায়েন্টের দ্বারা নির্দিষ্ট করা এক্সিকিউশন পছন্দের উপর নির্ভর করে ডিস্ট্রিবিউশন করা হয়। এই পার্টিশনিং অ্যালগরিদমটি বিভিন্ন প্রসেসরের মধ্যে IO দ্বারা সৃষ্ট সম্ভাব্য অদক্ষতার জন্য দায়ী নয় তাই, একাধিক প্রসেসর নির্দিষ্ট করার সময় (হয় স্পষ্টভাবে ANeuralNetworksCompilation_createForDevices ব্যবহার করার সময় বা স্পষ্টভাবে ANeuralNetworksCompilation_create ব্যবহার করে) এটি গুরুত্বপূর্ণ অ্যাপ্লিকেশনটির ফলাফলের জন্য।
আপনার মডেলটি NNAPI দ্বারা কীভাবে বিভাজিত হয়েছে তা বোঝার জন্য, একটি বার্তার জন্য অ্যান্ড্রয়েড লগগুলি পরীক্ষা করুন (ট্যাগ ExecutionPlan সহ INFO স্তরে):
ModelBuilder::findBestDeviceForEachOperation(op-name): device-index
op-name হল গ্রাফে অপারেশনের বর্ণনামূলক নাম এবং device-index হল ডিভাইসের তালিকায় প্রার্থী ডিভাইসের সূচক। এই তালিকাটি হল ANeuralNetworksCompilation_createForDevices কে দেওয়া ইনপুট বা, যদি ANeuralNetworksCompilation_createForDevices ব্যবহার করা হয়, ANeuralNetworks_getDeviceCount এবং ANeuralNetworks_getDevice ব্যবহার করে সমস্ত ডিভাইসে পুনরাবৃত্তি করার সময় ডিভাইসের তালিকা ফিরে আসে।
বার্তাটি ( ExecutionPlan ট্যাগ সহ তথ্য স্তরে):
ModelBuilder::partitionTheWork: only one best device: device-name
এই বার্তাটি নির্দেশ করে যে পুরো গ্রাফটি ডিভাইস device-name ত্বরান্বিত হয়েছে।
মৃত্যুদন্ড
এক্সিকিউশন স্টেপ মডেলটিকে ইনপুটগুলির একটি সেটে প্রয়োগ করে এবং আপনার অ্যাপ বরাদ্দ করা এক বা একাধিক ব্যবহারকারীর বাফার বা মেমরি স্পেসগুলিতে গণনা আউটপুট সংরক্ষণ করে।
একটি সংকলিত মডেল চালানোর জন্য, এই পদক্ষেপগুলি অনুসরণ করুন:
একটি নতুন এক্সিকিউশন ইনস্ট্যান্স তৈরি করতে
ANeuralNetworksExecution_create()ফাংশনটি কল করুন।// Run the compiled model against a set of inputs ANeuralNetworksExecution* run1 = NULL; ANeuralNetworksExecution_create(compilation, &run1);
আপনার অ্যাপটি গণনার জন্য ইনপুট মানগুলি কোথায় পড়বে তা নির্দিষ্ট করুন৷ আপনার অ্যাপ যথাক্রমে
ANeuralNetworksExecution_setInput()বাANeuralNetworksExecution_setInputFromMemory()কল করে একটি ব্যবহারকারী বাফার বা একটি বরাদ্দকৃত মেমরি স্পেস থেকে ইনপুট মান পড়তে পারে।// Set the single input to our sample model. Since it is small, we won't use a memory buffer float32 myInput[3][4] = { ...the data... }; ANeuralNetworksExecution_setInput(run1, 0, NULL, myInput, sizeof(myInput));
আপনার অ্যাপ আউটপুট মান কোথায় লিখবে তা নির্দিষ্ট করুন। আপনার অ্যাপ যথাক্রমে
ANeuralNetworksExecution_setOutput()অথবাANeuralNetworksExecution_setOutputFromMemory()কল করে ব্যবহারকারীর বাফার বা একটি বরাদ্দকৃত মেমরি স্পেস আউটপুট মান লিখতে পারে।// Set the output float32 myOutput[3][4]; ANeuralNetworksExecution_setOutput(run1, 0, NULL, myOutput, sizeof(myOutput));
ANeuralNetworksExecution_startCompute()ফাংশনকে কল করে শুরু করার জন্য কার্যকর করার সময়সূচী করুন। যদি কোন ত্রুটি না থাকে, এই ফাংশনটিANEURALNETWORKS_NO_ERRORএর ফলাফল কোড প্রদান করে।// Starts the work. The work proceeds asynchronously ANeuralNetworksEvent* run1_end = NULL; ANeuralNetworksExecution_startCompute(run1, &run1_end);
এক্সিকিউশন সম্পূর্ণ হওয়ার জন্য অপেক্ষা করতে
ANeuralNetworksEvent_wait()ফাংশনটিতে কল করুন। যদি এক্সিকিউশন সফল হয়, তাহলে এই ফাংশনটিANEURALNETWORKS_NO_ERRORএর ফলাফল কোড প্রদান করে। অপেক্ষমাণ কার্যকর করা শুরু করার চেয়ে ভিন্ন থ্রেডে করা যেতে পারে।// For our example, we have no other work to do and will just wait for the completion ANeuralNetworksEvent_wait(run1_end); ANeuralNetworksEvent_free(run1_end); ANeuralNetworksExecution_free(run1);
ঐচ্ছিকভাবে, আপনি একটি নতুন
ANeuralNetworksExecutionদৃষ্টান্ত তৈরি করতে একই সংকলন উদাহরণ ব্যবহার করে কম্পাইল করা মডেলে ইনপুটগুলির একটি ভিন্ন সেট প্রয়োগ করতে পারেন।// Apply the compiled model to a different set of inputs ANeuralNetworksExecution* run2; ANeuralNetworksExecution_create(compilation, &run2); ANeuralNetworksExecution_setInput(run2, ...); ANeuralNetworksExecution_setOutput(run2, ...); ANeuralNetworksEvent* run2_end = NULL; ANeuralNetworksExecution_startCompute(run2, &run2_end); ANeuralNetworksEvent_wait(run2_end); ANeuralNetworksEvent_free(run2_end); ANeuralNetworksExecution_free(run2);
সিঙ্ক্রোনাস এক্সিকিউশন
অ্যাসিঙ্ক্রোনাস এক্সিকিউশন থ্রেড তৈরি করতে এবং সিঙ্ক্রোনাইজ করতে সময় ব্যয় করে। তদ্ব্যতীত, লেটেন্সি অত্যন্ত পরিবর্তনশীল হতে পারে, একটি থ্রেড নোটিফিকেশন বা জেগে ওঠার সময় এবং শেষ পর্যন্ত এটি একটি CPU কোরের সাথে আবদ্ধ হওয়ার মধ্যে 500 মাইক্রোসেকেন্ড পর্যন্ত পৌঁছাতে দীর্ঘতম বিলম্ব হয়।
লেটেন্সি উন্নত করতে, আপনি রানটাইমে একটি সিঙ্ক্রোনাস ইনফারেন্স কল করার জন্য একটি অ্যাপ্লিকেশনকে নির্দেশ দিতে পারেন। একটি অনুমান শুরু হওয়ার পরে ফিরে আসার পরিবর্তে একটি অনুমান সম্পূর্ণ হলেই সেই কলটি ফিরে আসবে৷ রানটাইমে একটি অ্যাসিঙ্ক্রোনাস ইনফারেন্স কলের জন্য ANeuralNetworksExecution_startCompute কল করার পরিবর্তে, অ্যাপ্লিকেশনটি রানটাইমে একটি সিঙ্ক্রোনাস কল করার জন্য ANeuralNetworksExecution_compute কল করে। ANeuralNetworksExecution_compute এ একটি কল একটি ANeuralNetworksEvent গ্রহণ করে না এবং ANeuralNetworksEvent_wait এ একটি কলের সাথে জোড়া হয় না।
ফাঁসি ফাঁসি
Android 10 (API স্তর 29) এবং উচ্চতর চলমান Android ডিভাইসগুলিতে, NNAPI ANeuralNetworksBurst অবজেক্টের মাধ্যমে বার্স্ট এক্সিকিউশন সমর্থন করে। বার্স্ট মৃত্যুদন্ড হল একই সংকলনের মৃত্যুদন্ডের একটি ক্রম যা দ্রুত পর্যায়ক্রমে ঘটে, যেমন ক্যামেরা ক্যাপচারের ফ্রেমে কাজ করে বা ধারাবাহিক অডিও নমুনা। ANeuralNetworksBurst অবজেক্ট ব্যবহার করলে দ্রুত এক্সিকিউশন হতে পারে, কারণ তারা এক্সিলারেটরদের ইঙ্গিত দেয় যে এক্সিকিউশনের মধ্যে রিসোর্স পুনঃব্যবহার করা যেতে পারে এবং এক্সিলারেটরগুলি বিস্ফোরণের সময়কালের জন্য একটি উচ্চ-পারফরম্যান্স অবস্থায় থাকা উচিত।
ANeuralNetworksBurst সাধারণ এক্সিকিউশন পাথে শুধুমাত্র একটি ছোট পরিবর্তন প্রবর্তন করে। আপনি ANeuralNetworksBurst_create ব্যবহার করে একটি বিস্ফোরিত বস্তু তৈরি করেন, যেমনটি নিম্নলিখিত কোড স্নিপেটে দেখানো হয়েছে:
// Create burst object to be reused across a sequence of executions ANeuralNetworksBurst* burst = NULL; ANeuralNetworksBurst_create(compilation, &burst);
বার্স্ট মৃত্যুদন্ড সিঙ্ক্রোনাস। যাইহোক, প্রতিটি অনুমান সঞ্চালনের জন্য ANeuralNetworksExecution_compute ব্যবহার করার পরিবর্তে, আপনি ANeuralNetworksExecution_burstCompute ফাংশনের কলগুলিতে একই ANeuralNetworksBurst এর সাথে বিভিন্ন ANeuralNetworksExecution অবজেক্ট যুক্ত করুন।
// Create and configure first execution object // ... // Execute using the burst object ANeuralNetworksExecution_burstCompute(execution1, burst); // Use results of first execution and free the execution object // ... // Create and configure second execution object // ... // Execute using the same burst object ANeuralNetworksExecution_burstCompute(execution2, burst); // Use results of second execution and free the execution object // ...
ANeuralNetworksBurst অবজেক্টকে ANeuralNetworksBurst_free দিয়ে মুক্ত করুন যখন এটির আর প্রয়োজন নেই।
// Cleanup ANeuralNetworksBurst_free(burst);
অ্যাসিঙ্ক্রোনাস কমান্ড সারি এবং বেড় কার্যকর করা
অ্যান্ড্রয়েড 11 এবং পরবর্তীতে, NNAPI ANeuralNetworksExecution_startComputeWithDependencies() পদ্ধতির মাধ্যমে অ্যাসিঙ্ক্রোনাস এক্সিকিউশনের সময়সূচী করার একটি অতিরিক্ত উপায় সমর্থন করে। আপনি যখন এই পদ্ধতিটি ব্যবহার করেন, তখন নির্বাহটি মূল্যায়ন শুরু করার আগে সমস্ত নির্ভরশীল ইভেন্টের সংকেত হওয়ার জন্য অপেক্ষা করে। একবার এক্সিকিউশন শেষ হয়ে গেলে এবং আউটপুটগুলি খাওয়ার জন্য প্রস্তুত হয়ে গেলে, ফিরে আসা ইভেন্টটি সংকেত হয়।
কোন ডিভাইসগুলি এক্সিকিউশন পরিচালনা করে তার উপর নির্ভর করে, ইভেন্টটি একটি সিঙ্ক বেড়া দ্বারা সমর্থিত হতে পারে৷ ইভেন্টের জন্য অপেক্ষা করতে আপনাকে অবশ্যই ANeuralNetworksEvent_wait() কল করতে হবে এবং এক্সিকিউশন ব্যবহার করা সংস্থানগুলি পুনরুদ্ধার করতে হবে। আপনি ANeuralNetworksEvent_createFromSyncFenceFd() ব্যবহার করে একটি ইভেন্ট অবজেক্টে সিঙ্ক বেড়া আমদানি করতে পারেন, এবং আপনি ANeuralNetworksEvent_getSyncFenceFd() ব্যবহার করে একটি ইভেন্ট অবজেক্ট থেকে সিঙ্ক বেড়া রপ্তানি করতে পারেন।
গতিশীল আকারের আউটপুট
মডেলগুলিকে সমর্থন করতে যেখানে আউটপুটের আকার ইনপুট ডেটার উপর নির্ভর করে—অর্থাৎ, যেখানে মডেল কার্যকর করার সময় আকার নির্ধারণ করা যায় না — ANeuralNetworksExecution_getOutputOperandRank এবং ANeuralNetworksExecution_getOutputOperandDimensions ব্যবহার করুন।
নিম্নলিখিত কোড নমুনা দেখায় কিভাবে এটি করতে হয়:
// Get the rank of the output uint32_t myOutputRank = 0; ANeuralNetworksExecution_getOutputOperandRank(run1, 0, &myOutputRank); // Get the dimensions of the output std::vector<uint32_t> myOutputDimensions(myOutputRank); ANeuralNetworksExecution_getOutputOperandDimensions(run1, 0, myOutputDimensions.data());
ক্লিনআপ
পরিচ্ছন্নতার পদক্ষেপটি আপনার গণনার জন্য ব্যবহৃত অভ্যন্তরীণ সংস্থানগুলিকে মুক্ত করা পরিচালনা করে।
// Cleanup ANeuralNetworksCompilation_free(compilation); ANeuralNetworksModel_free(model); ANeuralNetworksMemory_free(mem1);
ত্রুটি ব্যবস্থাপনা এবং CPU ফলব্যাক
পার্টিশন করার সময় যদি কোনো ত্রুটি থাকে, যদি কোনো ড্রাইভার একটি (a-এর টুকরা) মডেল কম্পাইল করতে ব্যর্থ হয়, অথবা যদি কোনো ড্রাইভার একটি কম্পাইল করা (a) মডেল কার্যকর করতে ব্যর্থ হয়, NNAPI এক বা একাধিক অপারেশনের নিজস্ব CPU বাস্তবায়নে ফিরে যেতে পারে।
যদি NNAPI ক্লায়েন্টে অপারেশনের অপ্টিমাইজ করা সংস্করণ থাকে (যেমন, যেমন, TFLite) তাহলে CPU ফলব্যাক নিষ্ক্রিয় করা এবং ক্লায়েন্টের অপ্টিমাইজ করা অপারেশন বাস্তবায়নের সাথে ব্যর্থতাগুলি পরিচালনা করা সুবিধাজনক হতে পারে।
Android 10-এ, যদি ANeuralNetworksCompilation_createForDevices ব্যবহার করে সংকলন করা হয়, তাহলে CPU ফলব্যাক অক্ষম করা হবে।
অ্যান্ড্রয়েড পি-তে, ড্রাইভারের উপর সঞ্চালন ব্যর্থ হলে NNAPI এক্সিকিউশন CPU-তে ফিরে আসে। এটি Android 10 এও সত্য যখন ANeuralNetworksCompilation_create এর পরিবর্তে ANeuralNetworksCompilation_createForDevices ব্যবহার করা হয়।
প্রথম এক্সিকিউশন সেই একক পার্টিশনের জন্য ফিরে আসে, এবং যদি এটি এখনও ব্যর্থ হয়, এটি CPU-তে সম্পূর্ণ মডেলটি পুনরায় চেষ্টা করে।
পার্টিশন বা সংকলন ব্যর্থ হলে, সম্পূর্ণ মডেলটি CPU-তে চেষ্টা করা হবে।
এমন কিছু ক্ষেত্রে রয়েছে যেখানে কিছু অপারেশন CPU-তে সমর্থিত নয় এবং এই ধরনের পরিস্থিতিতে কম্পাইলেশন বা এক্সিকিউশন পিছিয়ে পড়ার পরিবর্তে ব্যর্থ হবে।
এমনকি CPU ফলব্যাক নিষ্ক্রিয় করার পরেও, CPU-তে নির্ধারিত মডেলটিতে এখনও ক্রিয়াকলাপ থাকতে পারে। যদি CPU ANeuralNetworksCompilation_createForDevices এ সরবরাহ করা প্রসেসরের তালিকায় থাকে এবং হয় একমাত্র প্রসেসর যেটি সেই ক্রিয়াকলাপগুলিকে সমর্থন করে বা সেই প্রসেসর যা সেই ক্রিয়াকলাপগুলির জন্য সর্বোত্তম কর্মক্ষমতা দাবি করে, তবে এটি একটি প্রাথমিক (নন-ফলব্যাক) নির্বাহক হিসাবে নির্বাচিত হবে৷
কোন CPU এক্সিকিউশন নেই তা নিশ্চিত করতে, ডিভাইসের তালিকা থেকে nnapi-reference বাদ দিয়ে ANeuralNetworksCompilation_createForDevices ব্যবহার করুন। অ্যান্ড্রয়েড পি থেকে শুরু করে, debug.nn.partition প্রপার্টি 2 এ সেট করে DEBUG বিল্ডে এক্সিকিউশনের সময় ফলব্যাক অক্ষম করা সম্ভব।
মেমরি ডোমেইন
অ্যান্ড্রয়েড 11 এবং পরবর্তীতে, NNAPI মেমরি ডোমেনগুলিকে সমর্থন করে যা অস্বচ্ছ স্মৃতির জন্য বরাদ্দকারী ইন্টারফেস প্রদান করে। এটি অ্যাপ্লিকেশানগুলিকে এক্সিকিউশন জুড়ে ডিভাইস-নেটিভ স্মৃতিগুলিকে পাস করার অনুমতি দেয়, যাতে NNAPI একই ড্রাইভারে ক্রমাগত মৃত্যুদন্ড সম্পাদন করার সময় অপ্রয়োজনীয়ভাবে ডেটা অনুলিপি বা রূপান্তর না করে।
মেমরি ডোমেন বৈশিষ্ট্যটি টেনসরগুলির জন্য উদ্দিষ্ট যেগুলি বেশিরভাগ ড্রাইভারের অভ্যন্তরীণ এবং ক্লায়েন্টের দিকে ঘন ঘন অ্যাক্সেসের প্রয়োজন হয় না। এই ধরনের টেনসরের উদাহরণগুলির মধ্যে রয়েছে সিকোয়েন্স মডেলের স্টেট টেনসর। ক্লায়েন্ট সাইডে ঘন ঘন CPU অ্যাক্সেস প্রয়োজন এমন টেনসরগুলির জন্য, পরিবর্তে শেয়ার্ড মেমরি পুল ব্যবহার করুন।
একটি অস্বচ্ছ মেমরি বরাদ্দ করতে, নিম্নলিখিত পদক্ষেপগুলি সম্পাদন করুন:
একটি নতুন মেমরি বর্ণনাকারী তৈরি করতে
ANeuralNetworksMemoryDesc_create()ফাংশন কল করুন:// Create a memory descriptor ANeuralNetworksMemoryDesc* desc; ANeuralNetworksMemoryDesc_create(&desc);
ANeuralNetworksMemoryDesc_addInputRole()এবংANeuralNetworksMemoryDesc_addOutputRole()কল করে সমস্ত উদ্দেশ্যযুক্ত ইনপুট এবং আউটপুট ভূমিকাগুলি নির্দিষ্ট করুন৷// Specify that the memory may be used as the first input and the first output // of the compilation ANeuralNetworksMemoryDesc_addInputRole(desc, compilation, 0, 1.0f); ANeuralNetworksMemoryDesc_addOutputRole(desc, compilation, 0, 1.0f);
ঐচ্ছিকভাবে,
ANeuralNetworksMemoryDesc_setDimensions()কল করে মেমরির মাত্রা নির্দিষ্ট করুন।// Specify the memory dimensions uint32_t dims[] = {3, 4}; ANeuralNetworksMemoryDesc_setDimensions(desc, 2, dims);
ANeuralNetworksMemoryDesc_finish()কল করে বর্ণনাকারীর সংজ্ঞা চূড়ান্ত করুন।ANeuralNetworksMemoryDesc_finish(desc);
ANeuralNetworksMemory_createFromDesc()এ বর্ণনাকারী পাস করে আপনার যতগুলি স্মৃতি প্রয়োজন ততগুলি বরাদ্দ করুন৷// Allocate two opaque memories with the descriptor ANeuralNetworksMemory* opaqueMem; ANeuralNetworksMemory_createFromDesc(desc, &opaqueMem);
আপনার আর প্রয়োজন না হলে মেমরি বর্ণনাকারীকে মুক্ত করুন।
ANeuralNetworksMemoryDesc_free(desc);
ক্লায়েন্ট শুধুমাত্র ANeuralNetworksMemoryDesc অবজেক্টে নির্দিষ্ট ভূমিকা অনুযায়ী ANeuralNetworksExecution_setInputFromMemory() অথবা ANeuralNetworksMemoryDesc ANeuralNetworksExecution_setOutputFromMemory() দিয়ে তৈরি ANeuralNetworksMemory অবজেক্ট ব্যবহার করতে পারে। অফসেট এবং দৈর্ঘ্যের আর্গুমেন্টগুলি অবশ্যই 0 তে সেট করা উচিত, এটি নির্দেশ করে যে পুরো মেমরি ব্যবহার করা হয়েছে। ANeuralNetworksMemory_copy() ব্যবহার করে ক্লায়েন্ট স্পষ্টভাবে মেমরির বিষয়বস্তু সেট বা বের করতে পারে।
আপনি অনির্দিষ্ট মাত্রা বা পদমর্যাদার ভূমিকা সহ অস্বচ্ছ স্মৃতি তৈরি করতে পারেন। সেই ক্ষেত্রে, মেমরি তৈরি ANEURALNETWORKS_OP_FAILED স্ট্যাটাসের সাথে ব্যর্থ হতে পারে যদি এটি অন্তর্নিহিত ড্রাইভার দ্বারা সমর্থিত না হয়। Ashmem বা BLOB-মোড AHardwareBuffer দ্বারা সমর্থিত যথেষ্ট বড় বাফার বরাদ্দ করে ফলব্যাক যুক্তি প্রয়োগ করতে ক্লায়েন্টকে উৎসাহিত করা হয়।
যখন NNAPI-এর আর অস্বচ্ছ মেমরি অবজেক্ট অ্যাক্সেস করার প্রয়োজন হয় না, তখন সংশ্লিষ্ট ANeuralNetworksMemory উদাহরণ মুক্ত করুন:
ANeuralNetworksMemory_free(opaqueMem);
কর্মক্ষমতা পরিমাপ
আপনি এক্সিকিউশন সময় পরিমাপ করে বা প্রোফাইলিং করে আপনার অ্যাপের কর্মক্ষমতা মূল্যায়ন করতে পারেন।
মৃত্যুদন্ড কার্যকর করার সময়
আপনি যখন রানটাইমের মাধ্যমে মোট এক্সিকিউশন সময় নির্ধারণ করতে চান, আপনি সিঙ্ক্রোনাস এক্সিকিউশন API ব্যবহার করতে পারেন এবং কলের সময় পরিমাপ করতে পারেন। আপনি যখন সফ্টওয়্যার স্ট্যাকের নিম্ন স্তরের মাধ্যমে মোট সম্পাদনের সময় নির্ধারণ করতে চান, তখন আপনি পেতে ANeuralNetworksExecution_setMeasureTiming এবং ANeuralNetworksExecution_getDuration ব্যবহার করতে পারেন:
- একটি এক্সিলারেটরে কার্যকর করার সময় (ড্রাইভারে নয়, যা হোস্ট প্রসেসরে চলে)।
- চালকের এক্সিকিউশন সময়, এক্সিলারেটরের সময় সহ।
ড্রাইভারের এক্সিকিউশন টাইম ওভারহেড বাদ দেয় যেমন রানটাইম নিজেই এবং ড্রাইভারের সাথে যোগাযোগ করার জন্য রানটাইমের জন্য প্রয়োজনীয় IPC।
এই APIগুলি সাবমিট করা কাজ এবং কাজ সম্পন্ন ইভেন্টগুলির মধ্যে সময়কাল পরিমাপ করে, ড্রাইভার বা এক্সিলারেটর অনুমান সম্পাদন করতে যে সময় দেয় তার চেয়ে, সম্ভবত প্রসঙ্গ স্যুইচিং দ্বারা বাধাগ্রস্ত হয়।
উদাহরণস্বরূপ, যদি অনুমান 1 শুরু হয়, তাহলে ড্রাইভার অনুমান 2 সম্পাদন করার জন্য কাজ বন্ধ করে দেয়, তারপরে এটি পুনরায় শুরু করে এবং অনুমান 1 সম্পূর্ণ করে, অনুমান 1 এর কার্য সম্পাদনের সময়টি সেই সময়কে অন্তর্ভুক্ত করবে যখন অনুমান 2 সম্পাদন করতে কাজ বন্ধ করা হয়েছিল।
এই সময়ের তথ্য অফলাইন ব্যবহারের জন্য টেলিমেট্রি সংগ্রহ করার জন্য একটি অ্যাপ্লিকেশনের উৎপাদন স্থাপনার জন্য উপযোগী হতে পারে। আপনি উচ্চতর কর্মক্ষমতার জন্য অ্যাপটি সংশোধন করতে টাইমিং ডেটা ব্যবহার করতে পারেন।
এই কার্যকারিতা ব্যবহার করার সময়, নিম্নলিখিত মনে রাখবেন:
- টাইমিং তথ্য সংগ্রহ করার একটি কর্মক্ষমতা খরচ হতে পারে.
- NNAPI রানটাইম এবং IPC-এ কাটানো সময় বাদ দিয়ে শুধুমাত্র একজন ড্রাইভার নিজেই বা এক্সিলারেটরে ব্যয় করা সময় গণনা করতে সক্ষম।
- আপনি এই APIগুলি শুধুমাত্র একটি
ANeuralNetworksExecutionএর সাথে ব্যবহার করতে পারেন যাANeuralNetworksCompilation_createForDevicesnumDevices = 1দিয়ে তৈরি করা হয়েছিল। - কোন ড্রাইভার সময় তথ্য রিপোর্ট করতে সক্ষম হতে হবে.
অ্যান্ড্রয়েড সিস্ট্রেস দিয়ে আপনার অ্যাপ্লিকেশন প্রোফাইল করুন
Android 10 দিয়ে শুরু করে, NNAPI স্বয়ংক্রিয়ভাবে সিস্ট্রেস ইভেন্ট তৈরি করে যা আপনি আপনার অ্যাপ্লিকেশন প্রোফাইল করতে ব্যবহার করতে পারেন।
এনএনএপিআই উত্সটি আপনার অ্যাপ্লিকেশন দ্বারা উত্পাদিত সিরস্ট্রেস ইভেন্টগুলি প্রক্রিয়া করার জন্য একটি parse_systrace ইউটিলিটি সহ আসে এবং মডেল লাইফাইসাইকেলের বিভিন্ন পর্যায়ে ব্যয় করা সময় (ইনস্ট্যান্টেশন, প্রস্তুতি, সংকলন সম্পাদন এবং সমাপ্তি) এবং অ্যাপ্লিকেশনগুলির বিভিন্ন স্তর দেখায় একটি টেবিল ভিউ তৈরি করে। আপনার অ্যাপ্লিকেশনটি বিভক্ত যে স্তরগুলি হ'ল:
-
Application: প্রধান অ্যাপ্লিকেশন কোড -
Runtime: এনএনএপিআই রানটাইম -
IPC: এনএনএপিআই রানটাইম এবং ড্রাইভার কোডের মধ্যে আন্তঃ প্রক্রিয়া যোগাযোগ -
Driver: এক্সিলারেটর ড্রাইভার প্রক্রিয়া।
প্রোফাইলিং অ্যানালাইসিস ডেটা উত্পন্ন করুন
ধরে নিই যে আপনি androwdroid_build_top এ এওএসপি উত্স গাছটি পরীক্ষা করেছেন এবং টার্গেট ইমেজ শ্রেণিবিন্যাসের উদাহরণটি লক্ষ্য অ্যাপ্লিকেশন হিসাবে ব্যবহার করে আপনি নীচের পদক্ষেপগুলি সহ এনএনএপিআই প্রোফাইলিং ডেটা তৈরি করতে পারেন:
- নিম্নলিখিত কমান্ডটি দিয়ে অ্যান্ড্রয়েড সিলস্ট্রেস শুরু করুন:
$ANDROID_BUILD_TOP/external/chromium-trace/systrace.py -o trace.html -a org.tensorflow.lite.examples.classification nnapi hal freq sched idle load binder_driver
-o trace.html প্যারামিটারটি নির্দেশ করে যে ট্রেসগুলি trace.html এ লেখা হবে। নিজের অ্যাপ্লিকেশনটি প্রোফাইল করার সময় আপনাকে org.tensorflow.lite.examples.classification আপনার অ্যাপ্লিকেশন প্রকাশে উল্লিখিত প্রক্রিয়া নাম সহ প্রতিস্থাপন করতে হবে।
এটি আপনার শেল কনসোলকে ব্যস্ত রাখবে, কমান্ডটি পটভূমিতে চালাবেন না কারণ এটি ইন্টারেক্টিভভাবে কোনও enter সমাপ্ত হওয়ার জন্য অপেক্ষা করছে।
- সিস্ট্রেস সংগ্রাহক শুরু হওয়ার পরে, আপনার অ্যাপ্লিকেশনটি শুরু করুন এবং আপনার বেঞ্চমার্ক পরীক্ষা চালান।
আমাদের ক্ষেত্রে আপনি অ্যাপ্লিকেশনটি ইতিমধ্যে ইনস্টল হয়ে গেলে অ্যান্ড্রয়েড স্টুডিও থেকে বা সরাসরি আপনার পরীক্ষার ফোন ইউআই থেকে চিত্র শ্রেণিবদ্ধকরণ অ্যাপ্লিকেশনটি শুরু করতে পারেন। কিছু এনএনএপিআই ডেটা উত্পন্ন করতে আপনাকে অ্যাপ কনফিগারেশন ডায়ালগটিতে এনএনএপিআইকে লক্ষ্য ডিভাইস হিসাবে নির্বাচন করে এনএনএপিআই ব্যবহার করতে অ্যাপ্লিকেশনটি কনফিগার করতে হবে।
পরীক্ষাটি শেষ হয়ে গেলে, পদক্ষেপ 1 থেকে কনসোল টার্মিনাল সক্রিয়
enterটিপুন দিয়ে সিস্ট্রেসটি বন্ধ করুন।systrace_parserইউটিলিটিটি ক্রমবর্ধমান পরিসংখ্যান উত্পন্ন করুন:
$ANDROID_BUILD_TOP/frameworks/ml/nn/tools/systrace_parser/parse_systrace.py --total-times trace.html
পার্সার নিম্নলিখিত প্যারামিটারগুলি গ্রহণ করে: - --total-times : অন্তর্নিহিত স্তরে কল করার জন্য মৃত্যুদন্ডের জন্য অপেক্ষা করা সময় সহ একটি স্তরে ব্যয় করা মোট সময় দেখায় - --print-detail : সমস্ত ইভেন্টগুলি প্রিন্ট করে যা সিস্ট্রেস থেকে সংগ্রহ করা হয়েছে -কেবলমাত্র মৃত্যুদন্ডের জন্য (তার সাব --per-execution (এর সাবফেসগুলি) --json : জেএসএন ফর্ম্যাটে আউটপুট উত্পাদন করে
আউটপুটটির একটি উদাহরণ নীচে দেখানো হয়েছে:
===========================================================================================================================================
NNAPI timing summary (total time, ms wall-clock) Execution
----------------------------------------------------
Initialization Preparation Compilation I/O Compute Results Ex. total Termination Total
-------------- ----------- ----------- ----------- ------------ ----------- ----------- ----------- ----------
Application n/a 19.06 1789.25 n/a n/a 6.70 21.37 n/a 1831.17*
Runtime - 18.60 1787.48 2.93 11.37 0.12 14.42 1.32 1821.81
IPC 1.77 - 1781.36 0.02 8.86 - 8.88 - 1792.01
Driver 1.04 - 1779.21 n/a n/a n/a 7.70 - 1787.95
Total 1.77* 19.06* 1789.25* 2.93* 11.74* 6.70* 21.37* 1.32* 1831.17*
===========================================================================================================================================
* This total ignores missing (n/a) values and thus is not necessarily consistent with the rest of the numbers
সংগৃহীত ইভেন্টগুলি সম্পূর্ণ অ্যাপ্লিকেশন ট্রেসকে উপস্থাপন না করলে পার্সার ব্যর্থ হতে পারে। বিশেষত এটি ব্যর্থ হতে পারে যদি কোনও বিভাগের শেষ চিহ্নিত করার জন্য উত্পন্ন সিস্ট্রেস ইভেন্টগুলি কোনও সম্পর্কিত বিভাগের সূচনা ইভেন্ট ছাড়াই ট্রেসে উপস্থিত থাকে। আপনি যখন সিস্ট্রেস সংগ্রাহক শুরু করেন তখন পূর্ববর্তী প্রোফাইলিং সেশনের কিছু ইভেন্ট তৈরি করা হয় তবে এটি সাধারণত ঘটে। এই ক্ষেত্রে আপনাকে আবার আপনার প্রোফাইলিং চালাতে হবে।
আপনার অ্যাপ্লিকেশন কোডের জন্য পরিসংখ্যান যুক্ত করুন systrace_parser আউটপুট
পার্স_সিস্ট্রেস অ্যাপ্লিকেশনটি অন্তর্নির্মিত অ্যান্ড্রয়েড সিস্ট্রেস কার্যকারিতার উপর ভিত্তি করে। আপনি কাস্টম ইভেন্টের নাম সহ সিস্ট্রেস এপিআই ( জাভা , নেটিভ অ্যাপ্লিকেশনগুলির জন্য ) ব্যবহার করে আপনার অ্যাপ্লিকেশনটিতে নির্দিষ্ট ক্রিয়াকলাপের জন্য ট্রেস যুক্ত করতে পারেন।
আপনার কাস্টম ইভেন্টগুলি অ্যাপ্লিকেশন লাইফসাইকেলের পর্যায়ের সাথে যুক্ত করতে, নিম্নলিখিত স্ট্রিংগুলির একটিতে আপনার ইভেন্টের নামটি প্রস্তুত করুন:
-
[NN_LA_PI]: সূচনার জন্য অ্যাপ্লিকেশন স্তরের ইভেন্ট -
[NN_LA_PP]: প্রস্তুতির জন্য অ্যাপ্লিকেশন স্তরের ইভেন্ট -
[NN_LA_PC]: সংকলনের জন্য অ্যাপ্লিকেশন স্তরের ইভেন্ট -
[NN_LA_PE]: মৃত্যুদন্ড কার্যকর করার জন্য অ্যাপ্লিকেশন স্তরের ইভেন্ট
আপনি কীভাবে Execution পর্বের জন্য একটি runInferenceModel বিভাগ যুক্ত করে এবং এনএনএপিআই ট্রেসগুলিতে বিবেচনা করা হবে না এমন অন্য বিভাগগুলি preprocessBitmap Application স্তর যুক্ত করে কীভাবে টিফ্লাইট চিত্র শ্রেণিবদ্ধকরণ উদাহরণ কোডটি পরিবর্তন করতে পারে তার একটি উদাহরণ এখানে। runInferenceModel বিভাগটি এনএনএপিআই সিস্ট্রেস পার্সার দ্বারা প্রক্রিয়াজাতকরণ করা সিস্ট্রেস ইভেন্টগুলির অংশ হবে:
কোটলিন
/** Runs inference and returns the classification results. */ fun recognizeImage(bitmap: Bitmap): List{ // This section won’t appear in the NNAPI systrace analysis Trace.beginSection("preprocessBitmap") convertBitmapToByteBuffer(bitmap) Trace.endSection() // Run the inference call. // Add this method in to NNAPI systrace analysis. Trace.beginSection("[NN_LA_PE]runInferenceModel") long startTime = SystemClock.uptimeMillis() runInference() long endTime = SystemClock.uptimeMillis() Trace.endSection() ... return recognitions }
জাভা
/** Runs inference and returns the classification results. */ public ListrecognizeImage(final Bitmap bitmap) { // This section won’t appear in the NNAPI systrace analysis Trace.beginSection("preprocessBitmap"); convertBitmapToByteBuffer(bitmap); Trace.endSection(); // Run the inference call. // Add this method in to NNAPI systrace analysis. Trace.beginSection("[NN_LA_PE]runInferenceModel"); long startTime = SystemClock.uptimeMillis(); runInference(); long endTime = SystemClock.uptimeMillis(); Trace.endSection(); ... Trace.endSection(); return recognitions; }
সেবার মান
অ্যান্ড্রয়েড 11 এবং উচ্চতর ক্ষেত্রে, এনএনএপিআই কোনও অ্যাপ্লিকেশনটিকে তার মডেলগুলির আপেক্ষিক অগ্রাধিকারগুলি, প্রদত্ত মডেল প্রস্তুত করার জন্য প্রত্যাশিত সর্বাধিক পরিমাণ এবং প্রদত্ত গণনাটি সম্পূর্ণ করার জন্য প্রত্যাশিত সর্বাধিক পরিমাণের জন্য প্রত্যাশিত সর্বাধিক পরিমাণ সময়কে নির্দেশ করার অনুমতি দিয়ে আরও ভাল মানের পরিষেবা (কিউওএস) সক্ষম করে। অ্যান্ড্রয়েড 11 অতিরিক্ত এনএনএপিআই ফলাফল কোডগুলিও প্রবর্তন করে যা অ্যাপ্লিকেশনগুলি মিস করা কার্যকরকরণের সময়সীমাগুলির মতো ব্যর্থতাগুলি বুঝতে সক্ষম করে।
একটি কাজের চাপের অগ্রাধিকার সেট করুন
এনএনএপিআই কাজের চাপের অগ্রাধিকার নির্ধারণের জন্য, ANeuralNetworksCompilation_setPriority() কল করুন ANeuralNetworksCompilation_finish() কল করার আগে।
সময়সীমা সেট করুন
অ্যাপ্লিকেশনগুলি মডেল সংকলন এবং অনুমান উভয়ের জন্য সময়সীমা সেট করতে পারে।
- সংকলন সময়সীমা সেট করতে,
ANeuralNetworksCompilation_setTimeout()কল করার আগে অ্যানিউরালনেটANeuralNetworksCompilation_finish()কল করুন। - অনুমানের সময়সীমা সেট করতে, সংকলন শুরু করার আগে
ANeuralNetworksExecution_setTimeout()কল করুন।
অপারেন্ডস সম্পর্কে আরও
নিম্নলিখিত বিভাগে অপারেশনগুলি ব্যবহার সম্পর্কে উন্নত বিষয়গুলি অন্তর্ভুক্ত করা হয়েছে।
কোয়ান্টাইজড টেনসর
একটি কোয়ান্টাইজড টেনসর ভাসমান পয়েন্ট মানগুলির একটি এন-মাত্রিক অ্যারে উপস্থাপনের একটি কমপ্যাক্ট উপায়।
এনএনএপিআই 8-বিট অ্যাসিমেট্রিক কোয়ান্টাইজড টেনসর সমর্থন করে। এই টেনারগুলির জন্য, প্রতিটি কোষের মান 8-বিট পূর্ণসংখ্যা দ্বারা প্রতিনিধিত্ব করা হয়। টেনসরের সাথে যুক্ত একটি স্কেল এবং শূন্য পয়েন্ট মান। এগুলি 8-বিট পূর্ণসংখ্যাগুলিকে ভাসমান পয়েন্ট মানগুলিতে রূপান্তর করতে ব্যবহৃত হয় যা প্রতিনিধিত্ব করা হচ্ছে।
সূত্রটি হল:
(cellValue - zeroPoint) * scale
যেখানে জিরোপয়েন্ট মানটি একটি 32-বিট পূর্ণসংখ্যা এবং স্কেল একটি 32-বিট ভাসমান পয়েন্ট মান।
32-বিট ভাসমান পয়েন্টের মানগুলির টেনারগুলির সাথে তুলনা করে, 8-বিট কোয়ান্টাইজড টেনারগুলির দুটি সুবিধা রয়েছে:
- আপনার অ্যাপ্লিকেশনটি আরও ছোট, কারণ প্রশিক্ষিত ওজনগুলি 32-বিট টেনারগুলির আকারের এক চতুর্থাংশ নেয়।
- গণনাগুলি প্রায়শই দ্রুত কার্যকর করা যায়। এটি স্বল্প পরিমাণে ডেটাগুলির কারণে যা মেমরি থেকে আনতে হবে এবং পূর্ণসংখ্যার গণিত করার ক্ষেত্রে ডিএসপিএসের মতো প্রসেসরের দক্ষতার প্রয়োজন।
যদিও একটি ভাসমান পয়েন্ট মডেলকে একটি কোয়ান্টাইজডে রূপান্তর করা সম্ভব, আমাদের অভিজ্ঞতা দেখিয়েছে যে সরাসরি একটি কোয়ান্টাইজড মডেলকে প্রশিক্ষণ দিয়ে আরও ভাল ফলাফল অর্জন করা হয়। বাস্তবে, নিউরাল নেটওয়ার্ক প্রতিটি মানের বর্ধিত গ্রানুলারিটির জন্য ক্ষতিপূরণ দিতে শিখেছে। প্রতিটি কোয়ান্টাইজড টেনসারের জন্য, প্রশিক্ষণ প্রক্রিয়া চলাকালীন স্কেল এবং জিরোপয়েন্ট মানগুলি নির্ধারিত হয়।
এনএনএপিআই -তে, আপনি ANeuralNetworksOperandType ডেটা কাঠামোর টাইপ ক্ষেত্রটি ANEURALNETWORKS_TENSOR_QUANT8_ASYMM এ সেট করে কোয়ান্টাইজড টেনসর প্রকারগুলি সংজ্ঞায়িত করেন। আপনি সেই ডেটা স্ট্রাকচারে টেনসারের স্কেল এবং জেরোপয়েন্ট মানও নির্দিষ্ট করেছেন।
8-বিট অ্যাসিমেট্রিক কোয়ান্টাইজড টেনসর ছাড়াও, এনএনএপিআই নিম্নলিখিতগুলিকে সমর্থন করে:
-
ANEURALNETWORKS_TENSOR_QUANT8_SYMM_PER_CHANNELযা আপনিCONV/DEPTHWISE_CONV/TRANSPOSED_CONVঅপারেশনগুলিতে ওজন উপস্থাপনের জন্য ব্যবহার করতে পারেন। -
ANEURALNETWORKS_TENSOR_QUANT16_ASYMMযা আপনিQUANTIZED_16BIT_LSTMএর অভ্যন্তরীণ অবস্থার জন্য ব্যবহার করতে পারেন। -
ANEURALNETWORKS_TENSOR_QUANT8_SYMMযাANEURALNETWORKS_DEQUANTIZEএকটি ইনপুট হতে পারে।
Al চ্ছিক অপারেন্ডস
ANEURALNETWORKS_LSH_PROJECTION মতো কয়েকটি অপারেশন al চ্ছিক অপারেন্ডস গ্রহণ করে। Option চ্ছিক অপারেন্ডটি বাদ দেওয়া হয়েছে এমন মডেলটিতে নির্দেশ করতে, ANeuralNetworksModel_setOperandValue() ফাংশনটি কল করুন, বাফারের জন্য NULL এবং দৈর্ঘ্যের জন্য 0 পাস করুন।
যদি প্রতিটি এক্সিকিউশনের জন্য অপারেন্ড উপস্থিত থাকে বা না সে সম্পর্কে সিদ্ধান্তটি যদি আপনি নির্দেশ করেন যে অপারেন্ডটি ANeuralNetworksExecution_setInput() বা ANeuralNetworksExecution_setOutput() ফাংশনগুলি ব্যবহার করে বাফারের জন্য NULL এবং দৈর্ঘ্যের জন্য 0 ব্যবহার করে বাদ দেওয়া হয়।
অজানা পদমর্যাদার টেনার
অ্যান্ড্রয়েড 9 (এপিআই স্তর 28) অজানা মাত্রাগুলির মডেল অপারেশনগুলি চালু করেছে তবে পরিচিত র্যাঙ্ক (মাত্রার সংখ্যা)। অ্যান্ড্রয়েড 10 (এপিআই স্তর 29) অজানা র্যাঙ্কের টেনারগুলি প্রবর্তন করেছে, যেমনটি অ্যানারালনেট ওয়ার্কসোপারেন্ডটাইপে দেখানো হয়েছে।
Nnapi বেঞ্চমার্ক
এনএনএপিআই বেঞ্চমার্ক platform/test/mlts/benchmark (বেঞ্চমার্ক অ্যাপ্লিকেশন) এবং platform/test/mlts/models (মডেল এবং ডেটাসেটস) এ এওএসপি -তে উপলব্ধ।
বেঞ্চমার্কটি বিলম্ব এবং নির্ভুলতার মূল্যায়ন করে এবং একই মডেল এবং ডেটাসেটের জন্য সিপিইউতে চলমান টেনসরফ্লো লাইট ব্যবহার করে একই কাজের সাথে ড্রাইভারদের তুলনা করে।
বেঞ্চমার্ক ব্যবহার করতে, নিম্নলিখিতগুলি করুন:
আপনার কম্পিউটারে একটি টার্গেট অ্যান্ড্রয়েড ডিভাইস সংযুক্ত করুন, একটি টার্মিনাল উইন্ডো খুলুন এবং এডিবির মাধ্যমে ডিভাইসটি পৌঁছনীয় কিনা তা নিশ্চিত করুন।
যদি একাধিক অ্যান্ড্রয়েড ডিভাইস সংযুক্ত থাকে তবে টার্গেট ডিভাইসটি
ANDROID_SERIALএনভায়রনমেন্ট ভেরিয়েবলটি রফতানি করুন।অ্যান্ড্রয়েড শীর্ষ-স্তরের উত্স ডিরেক্টরিতে নেভিগেট করুন।
নিম্নলিখিত কমান্ড চালান:
lunch aosp_arm-userdebug # Or aosp_arm64-userdebug if available ./test/mlts/benchmark/build_and_run_benchmark.sh
একটি বেঞ্চমার্ক রান শেষে, এর ফলাফলগুলি
xdg-openপাস করা এইচটিএমএল পৃষ্ঠা হিসাবে উপস্থাপন করা হবে।
Nnapi লগ
এনএনএপিআই সিস্টেম লগগুলিতে দরকারী ডায়াগনস্টিক তথ্য উত্পন্ন করে। লগগুলি বিশ্লেষণ করতে, লগক্যাট ইউটিলিটি ব্যবহার করুন।
সম্পত্তি debug.nn.vlog ( adb shell ব্যবহার করে) স্থান, কোলন বা কমা দ্বারা পৃথক করা মানগুলির তালিকায় সম্পত্তি debug.nn.vlog (এডিবি শেল ব্যবহার করে) সেট করে ভার্বোজ এনএনএপিআই লগিং সক্ষম করুন:
-
model: মডেল বিল্ডিং -
compilation: মডেল এক্সিকিউশন প্ল্যান এবং সংকলনের প্রজন্ম -
execution: মডেল এক্সিকিউশন -
cpuexe: এনএনএপিআই সিপিইউ বাস্তবায়ন ব্যবহার করে অপারেশনগুলি সম্পাদন -
manager: এনএনএপিআই এক্সটেনশনস, উপলব্ধ ইন্টারফেস এবং ক্ষমতা সম্পর্কিত তথ্য -
allবা1: উপরের সমস্ত উপাদান
উদাহরণস্বরূপ, সম্পূর্ণ ভার্বোজ লগিং সক্ষম করতে কমান্ড adb shell setprop debug.nn.vlog all ব্যবহার করুন। ভার্বোজ লগিং অক্ষম করতে, কমান্ড adb shell setprop debug.nn.vlog '""' ব্যবহার করুন।
একবার সক্ষম হয়ে গেলে, ভার্বোজ লগিং ফেজ বা উপাদানগুলির নামের জন্য একটি ট্যাগ সেট সহ তথ্য স্তরে লগ এন্ট্রি তৈরি করে।
debug.nn.vlog নিয়ন্ত্রিত বার্তাগুলির পাশে, এনএনএপিআই এপিআই উপাদানগুলি বিভিন্ন স্তরে অন্যান্য লগ এন্ট্রি সরবরাহ করে, প্রত্যেকে একটি নির্দিষ্ট লগ ট্যাগ ব্যবহার করে।
উপাদানগুলির একটি তালিকা পেতে, নিম্নলিখিত অভিব্যক্তিটি ব্যবহার করে উত্স গাছটি অনুসন্ধান করুন:
grep -R 'define LOG_TAG' | awk -F '"' '{print $2}' | sort -u | egrep -v "Sample|FileTag|test"
এই অভিব্যক্তিটি বর্তমানে নিম্নলিখিত ট্যাগগুলি ফিরিয়ে দেয়:
- বার্সবিল্ডার
- কলব্যাক
- সংকলন বিল্ডার
- সিপিইউএক্সেকিউটার
- এক্সিকিউশনবিল্ডার
- এক্সিকিউশনবার্স্টকন্ট্রোলার
- এক্সিকিউশনবার্স্টার্সার
- এক্সিকিউশনপ্ল্যান
- ফাইবোন্যাকিড্রিভার
- গ্রাফডাম্প
- ইনডেক্সশেপওয়ার্পার
- আয়নওয়াচার
- ম্যানেজার
- স্মৃতি
- মেমরিউটিলস
- মেটামোডেল
- Modeargumentinfo
- মডেল বিল্ডার
- নিউরালনেট ওয়ার্কস
- অপারেশন রিসলভার
- অপারেশন
- অপারেশনস ইউটিলস
- প্যাকেজ তথ্য
- টোকেনহাশার
- টাইপম্যানেজার
- ইউটিলস
- বৈধতা
- সংস্করণযুক্ত ইন্টারফেসস
logcat দ্বারা প্রদর্শিত লগ বার্তাগুলির স্তর নিয়ন্ত্রণ করতে, পরিবেশের পরিবর্তনশীল ANDROID_LOG_TAGS ব্যবহার করুন।
এনএনএপিআই লগ বার্তাগুলির সম্পূর্ণ সেটটি দেখাতে এবং অন্যকে অক্ষম করতে, ANDROID_LOG_TAGS নিম্নলিখিতগুলিতে সেট করুন:
BurstBuilder:V Callbacks:V CompilationBuilder:V CpuExecutor:V ExecutionBuilder:V ExecutionBurstController:V ExecutionBurstServer:V ExecutionPlan:V FibonacciDriver:V GraphDump:V IndexedShapeWrapper:V IonWatcher:V Manager:V MemoryUtils:V Memory:V MetaModel:V ModelArgumentInfo:V ModelBuilder:V NeuralNetworks:V OperationResolver:V OperationsUtils:V Operations:V PackageInfo:V TokenHasher:V TypeManager:V Utils:V ValidateHal:V VersionedInterfaces:V *:S.
আপনি নিম্নলিখিত কমান্ডটি ব্যবহার করে ANDROID_LOG_TAGS সেট করতে পারেন:
export ANDROID_LOG_TAGS=$(grep -R 'define LOG_TAG' | awk -F '"' '{ print $2 ":V" }' | sort -u | egrep -v "Sample|FileTag|test" | xargs echo -n; echo ' *:S')
নোট করুন যে এটি কেবল একটি ফিল্টার যা logcat প্রযোজ্য। ভার্বোজ লগ তথ্য উত্পন্ন করতে আপনাকে এখনও সম্পত্তিটি debug.nn.vlog সেট করতে হবে all