
Die Android Neural Networks API (NNAPI) ist eine Android-C-API, die für die Ausführung rechenintensiver Vorgänge für maschinelles Lernen auf Android-Geräten entwickelt wurde. NNAPI wurde entwickelt, um eine Basisschicht von Funktionen für Machine-Learning-Frameworks auf höherer Ebene wie TensorFlow Lite und Caffe2 bereitzustellen, mit denen neuronale Netzwerke erstellt und trainiert werden. Die API ist auf allen Android-Geräten mit Android 8.1 (API-Level 27) oder höher verfügbar, wurde aber in Android 15 eingestellt.
NNAPI unterstützt die Inferenz, indem Daten von Android-Geräten auf zuvor trainierte, vom Entwickler definierte Modelle angewendet werden. Beispiele für Inferenz sind das Klassifizieren von Bildern, das Vorhersagen des Nutzerverhaltens und das Auswählen geeigneter Antworten auf eine Suchanfrage.
Die Inferenz auf dem Gerät bietet viele Vorteile:
- Latenz: Sie müssen keine Anfrage über eine Netzwerkverbindung senden und auf eine Antwort warten. Dies kann beispielsweise für Videoanwendungen entscheidend sein, die aufeinanderfolgende Frames einer Kamera verarbeiten.
- Verfügbarkeit: Die Anwendung wird auch dann ausgeführt, wenn keine Netzwerkabdeckung besteht.
- Geschwindigkeit: Neue Hardware, die speziell für die Verarbeitung neuronaler Netze entwickelt wurde, ermöglicht eine deutlich schnellere Berechnung als eine herkömmliche CPU.
- Datenschutz: Die Daten verlassen das Android-Gerät nicht.
- Kosten: Da alle Berechnungen auf dem Android-Gerät ausgeführt werden, ist keine Serverfarm erforderlich.
Entwickler sollten auch die folgenden Nachteile berücksichtigen:
- Systemauslastung: Die Auswertung neuronaler Netze erfordert viele Berechnungen, was den Akkuverbrauch erhöhen kann. Wenn der Akkuzustand für Ihre App ein Problem darstellt, sollten Sie ihn im Blick behalten, insbesondere bei rechenintensiven Vorgängen, die lange dauern.
- Anwendungsgröße: Achten Sie auf die Größe Ihrer Modelle. Modelle können mehrere Megabyte Speicherplatz belegen. Wenn das Bündeln großer Modelle in Ihrer APK Ihre Nutzer übermäßig beeinträchtigen würde, sollten Sie in Erwägung ziehen, die Modelle nach der App-Installation herunterzuladen, kleinere Modelle zu verwenden oder Ihre Berechnungen in der Cloud auszuführen. NNAPI bietet keine Funktionen zum Ausführen von Modellen in der Cloud.
Ein Beispiel für die Verwendung der NNAPI finden Sie im Android Neural Networks API-Beispiel.
Laufzeit der Neural Networks API
NNAPI soll von Machine-Learning-Bibliotheken, ‑Frameworks und ‑Tools aufgerufen werden, mit denen Entwickler ihre Modelle auf anderen Geräten trainieren und auf Android-Geräten bereitstellen können. Apps verwenden NNAPI in der Regel nicht direkt, sondern stattdessen Machine-Learning-Frameworks höherer Ebene. Diese Frameworks können wiederum NNAPI verwenden, um hardwarebeschleunigte Inferenzvorgänge auf unterstützten Geräten auszuführen.
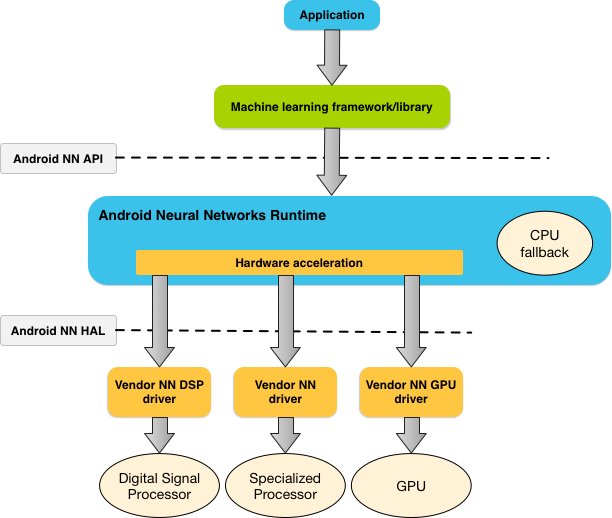
Abhängig von den Anforderungen einer App und den Hardwarefunktionen eines Android-Geräts kann die Neural Network Runtime von Android die Rechenlast effizient auf die verfügbaren Prozessoren auf dem Gerät verteilen, einschließlich dedizierter Hardware für neuronale Netze, Grafikprozessoren (GPUs) und digitalen Signalprozessoren (DSPs).
Auf Android-Geräten, für die kein spezieller Anbieter-Treiber vorhanden ist, führt die NNAPI-Laufzeit die Anfragen auf der CPU aus.
Abbildung 1 zeigt die allgemeine Systemarchitektur für NNAPI.
Programmiermodell der Neural Networks API
Wenn Sie Berechnungen mit NNAPI durchführen möchten, müssen Sie zuerst einen gerichteten Graphen erstellen, der die auszuführenden Berechnungen definiert. Dieses Berechnungsdiagramm bildet zusammen mit Ihren Eingabedaten (z. B. den Gewichten und Bias, die von einem Machine-Learning-Framework übergeben werden) das Modell für die NNAPI-Laufzeitbewertung.
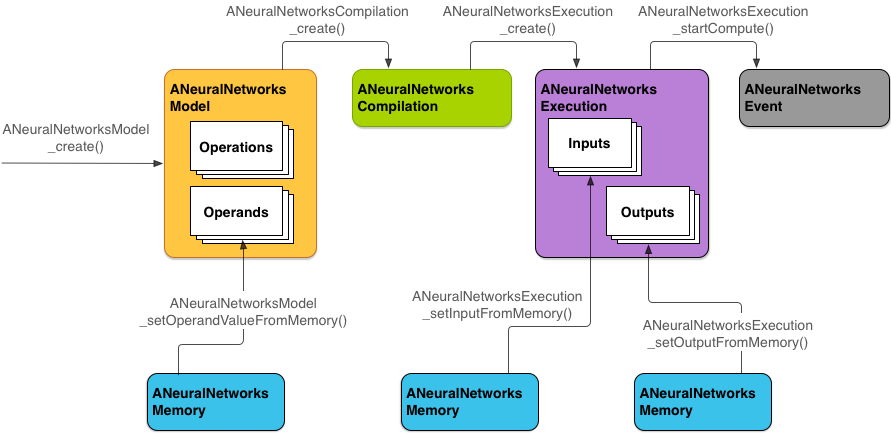
NNAPI verwendet vier Hauptabstraktionen:
- Modell: Ein Berechnungsdiagramm mit mathematischen Operationen und den konstanten Werten, die durch einen Trainingsprozess gelernt wurden. Diese Vorgänge sind spezifisch für neuronale Netze. Dazu gehören die 2-dimensionale (2D) Faltung, die logistische (Sigmoid-)Aktivierung, die rektifizierte lineare (ReLU-)Aktivierung und mehr. Das Erstellen eines Modells ist ein synchroner Vorgang.
Nachdem Sie sie erfolgreich erstellt haben, können Sie sie in mehreren Threads und Zusammenstellungen wiederverwenden.
In NNAPI wird ein Modell als
ANeuralNetworksModel-Instanz dargestellt. - Kompilierung: Stellt eine Konfiguration zum Kompilieren eines NNAPI-Modells in Code auf niedrigerer Ebene dar. Das Erstellen einer Zusammenstellung ist ein synchroner Vorgang. Nachdem sie erfolgreich erstellt wurde, kann sie in mehreren Threads und Ausführungen wiederverwendet werden. In NNAPI wird jede Kompilierung als
ANeuralNetworksCompilation-Instanz dargestellt. - Arbeitsspeicher: Stellt gemeinsam genutzten Arbeitsspeicher, dem Arbeitsspeicher zugeordnete Dateien und ähnliche Arbeitsspeicherpuffer dar. Durch die Verwendung eines Speicherpuffers kann die NNAPI-Laufzeit Daten effizienter an Treiber übertragen. Normalerweise erstellt eine App einen gemeinsamen Speicherpuffer, der alle zum Definieren eines Modells erforderlichen Tensoren enthält. Sie können auch Speicherpuffer verwenden, um die Ein- und Ausgaben für eine Ausführungsinstanz zu speichern. In NNAPI wird jeder Speicherpuffer als
ANeuralNetworksMemory-Instanz dargestellt. Ausführung: Schnittstelle zum Anwenden eines NNAPI-Modells auf eine Reihe von Eingaben und zum Erfassen der Ergebnisse. Die Ausführung kann synchron oder asynchron erfolgen.
Bei der asynchronen Ausführung können mehrere Threads auf dieselbe Ausführung warten. Wenn die Ausführung abgeschlossen ist, werden alle Threads freigegeben.
In NNAPI wird jede Ausführung als
ANeuralNetworksExecution-Instanz dargestellt.
Abbildung 2 zeigt den grundlegenden Programmierablauf.
Im Rest dieses Abschnitts werden die Schritte zum Einrichten Ihres NNAPI-Modells für die Berechnung, zum Kompilieren des Modells und zum Ausführen des kompilierten Modells beschrieben.
Zugriff auf Trainingsdaten gewähren
Die Daten für die trainierten Gewichte und Bias sind wahrscheinlich in einer Datei gespeichert. Damit die NNAPI-Laufzeit effizient auf diese Daten zugreifen kann, erstellen Sie eine ANeuralNetworksMemory-Instanz, indem Sie die Funktion ANeuralNetworksMemory_createFromFd() aufrufen und den Dateideskriptor der geöffneten Datendatei übergeben. Sie geben auch Speicherschutz-Flags und einen Offset an, an dem der freigegebene Speicherbereich in der Datei beginnt.
// Create a memory buffer from the file that contains the trained data
ANeuralNetworksMemory* mem1 = NULL;
int fd = open("training_data", O_RDONLY);
ANeuralNetworksMemory_createFromFd(file_size, PROT_READ, fd, 0, &mem1);
In diesem Beispiel verwenden wir nur eine ANeuralNetworksMemory-Instanz für alle Gewichte. Es ist jedoch möglich, mehrere ANeuralNetworksMemory-Instanzen für mehrere Dateien zu verwenden.
Native Hardwarepuffer verwenden
Sie können native Hardwarepuffer für Modelleingaben, ‑ausgaben und konstante Operandenwerte verwenden. In bestimmten Fällen kann ein NNAPI-Beschleuniger auf AHardwareBuffer-Objekte zugreifen, ohne dass der Treiber die Daten kopieren muss. AHardwareBuffer hat viele verschiedene Konfigurationen und nicht jeder NNAPI-Beschleuniger unterstützt alle diese Konfigurationen. Aufgrund dieser Einschränkung sollten Sie sich die in der ANeuralNetworksMemory_createFromAHardwareBuffer-Referenzdokumentation aufgeführten Einschränkungen ansehen und vorab auf Zielgeräten testen, um sicherzustellen, dass Kompilierungen und Ausführungen, bei denen AHardwareBuffer verwendet wird, wie erwartet funktionieren. Verwenden Sie dazu die Gerätezuweisung, um den Beschleuniger anzugeben.
Damit die NNAPI-Laufzeit auf ein AHardwareBuffer-Objekt zugreifen kann, erstellen Sie eine ANeuralNetworksMemory-Instanz, indem Sie die Funktion ANeuralNetworksMemory_createFromAHardwareBuffer aufrufen und das AHardwareBuffer-Objekt übergeben, wie im folgenden Codebeispiel gezeigt:
// Configure and create AHardwareBuffer object AHardwareBuffer_Desc desc = ... AHardwareBuffer* ahwb = nullptr; AHardwareBuffer_allocate(&desc, &ahwb); // Create ANeuralNetworksMemory from AHardwareBuffer ANeuralNetworksMemory* mem2 = NULL; ANeuralNetworksMemory_createFromAHardwareBuffer(ahwb, &mem2);
Wenn NNAPI nicht mehr auf das AHardwareBuffer-Objekt zugreifen muss, geben Sie die entsprechende ANeuralNetworksMemory-Instanz kostenlos:
ANeuralNetworksMemory_free(mem2);
Hinweis:
- Sie können
AHardwareBuffernur für den gesamten Puffer verwenden, nicht mit dem ParameterARect. - Die NNAPI-Laufzeit leert den Puffer nicht. Sie müssen dafür sorgen, dass die Ein- und Ausgabepuffer vor dem Planen der Ausführung zugänglich sind.
- Synchronisations-Fence-Dateideskriptoren werden nicht unterstützt.
- Bei einem
AHardwareBuffermit anbieterspezifischen Formaten und Nutzungsbits liegt es an der Anbieterimplementierung, ob der Client oder der Treiber für das Leeren des Cache verantwortlich ist.
Modell
Ein Modell ist die Grundeinheit für Berechnungen in NNAPI. Jedes Modell wird durch einen oder mehrere Operanden und Vorgänge definiert.
Operanden
Operanden sind Datenobjekte, die zum Definieren des Diagramms verwendet werden. Dazu gehören die Ein- und Ausgaben des Modells, die Zwischenknoten, die die Daten enthalten, die von einem Vorgang zum nächsten fließen, und die Konstanten, die an diese Vorgänge übergeben werden.
Es gibt zwei Arten von Operanden, die NNAPI-Modellen hinzugefügt werden können: Skalare und Tensoren.
Ein Skalar stellt einen einzelnen Wert dar. NNAPI unterstützt skalare Werte in den Formaten „boolean“, 16-Bit-Gleitkommazahl, 32-Bit-Gleitkommazahl, 32-Bit-Ganzzahl und vorzeichenlose 32-Bit-Ganzzahl.
Die meisten Vorgänge in NNAPI umfassen Tensoren. Tensoren sind n-dimensionale Arrays. NNAPI unterstützt Tensoren mit 16‑Bit-Gleitkommazahlen, 32‑Bit-Gleitkommazahlen, 8‑Bit-quantisierten, 16‑Bit-quantisierten, 32‑Bit-Ganzzahlen und 8‑Bit-Booleschen Werten.
Abbildung 3 zeigt beispielsweise ein Modell mit zwei Operationen: einer Addition, gefolgt von einer Multiplikation. Das Modell verarbeitet einen Eingabetensor und gibt einen Ausgabetensor aus.
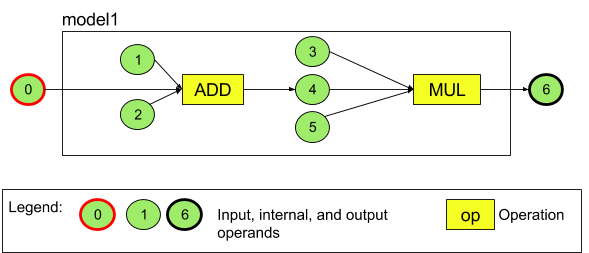
Das Modell oben hat sieben Operanden. Diese Operanden werden implizit durch den Index der Reihenfolge identifiziert, in der sie dem Modell hinzugefügt werden. Der erste hinzugefügte Operand hat den Index 0, der zweite den Index 1 usw. Die Operanden 1, 2, 3 und 5 sind konstante Operanden.
Die Reihenfolge, in der Sie die Operanden hinzufügen, spielt keine Rolle. Der Operand für die Modellausgabe könnte beispielsweise als Erstes hinzugefügt werden. Wichtig ist, dass Sie beim Verweisen auf einen Operanden den richtigen Indexwert verwenden.
Operanden haben Typen. Diese werden beim Hinzufügen zum Modell angegeben.
Ein Operand kann nicht gleichzeitig als Ein- und Ausgabe eines Modells verwendet werden.
Jeder Operand muss entweder eine Modelleingabe, eine Konstante oder der Ausgabeargument einer Operation sein.
Weitere Informationen zur Verwendung von Operanden finden Sie unter Weitere Informationen zu Operanden.
Aufgaben und Ablauf
Eine Operation gibt die auszuführenden Berechnungen an. Jeder Vorgang besteht aus den folgenden Elementen:
- einem Vorgangstyp (z. B. Addition, Multiplikation, Faltung),
- eine Liste der Indexe der Operanden, die der Vorgang als Eingabe verwendet, und
- Eine Liste der Indexe der Operanden, die für die Ausgabe verwendet werden.
Die Reihenfolge in diesen Listen ist wichtig. In der NNAPI-API-Referenz finden Sie die erwarteten Ein- und Ausgaben für jeden Vorgangstyp.
Sie müssen dem Modell die Operanden hinzufügen, die von einem Vorgang verwendet oder erzeugt werden, bevor Sie den Vorgang hinzufügen.
Die Reihenfolge, in der Sie Vorgänge hinzufügen, spielt keine Rolle. NNAPI stützt sich auf die Abhängigkeiten, die durch das Berechnungsdiagramm von Operanden und Vorgängen festgelegt werden, um die Reihenfolge zu bestimmen, in der Vorgänge ausgeführt werden.
Die von NNAPI unterstützten Vorgänge sind in der folgenden Tabelle zusammengefasst:
Bekanntes Problem bei API-Level 28:Wenn Sie ANEURALNETWORKS_TENSOR_QUANT8_ASYMM-Tensoren an den Vorgang ANEURALNETWORKS_PAD übergeben, der ab Android 9 (API-Level 28) verfügbar ist, stimmt die Ausgabe von NNAPI möglicherweise nicht mit der Ausgabe von übergeordneten Frameworks für maschinelles Lernen wie TensorFlow Lite überein. Sie sollten stattdessen nur ANEURALNETWORKS_TENSOR_FLOAT32 übergeben.
Das Problem wurde in Android 10 (API‑Level 29) und höher behoben.
Modelle erstellen
Im folgenden Beispiel erstellen wir das Modell mit zwei Vorgängen aus Abbildung 3.
So erstellen Sie das Modell:
Rufen Sie die Funktion
ANeuralNetworksModel_create()auf, um ein leeres Modell zu definieren.ANeuralNetworksModel* model = NULL; ANeuralNetworksModel_create(&model);
Fügen Sie die Operanden Ihrem Modell hinzu, indem Sie
ANeuralNetworks_addOperand()aufrufen. Ihre Datentypen werden mit der DatenstrukturANeuralNetworksOperandTypedefiniert.// In our example, all our tensors are matrices of dimension [3][4] ANeuralNetworksOperandType tensor3x4Type; tensor3x4Type.type = ANEURALNETWORKS_TENSOR_FLOAT32; tensor3x4Type.scale = 0.f; // These fields are used for quantized tensors tensor3x4Type.zeroPoint = 0; // These fields are used for quantized tensors tensor3x4Type.dimensionCount = 2; uint32_t dims[2] = {3, 4}; tensor3x4Type.dimensions = dims;
// We also specify operands that are activation function specifiers ANeuralNetworksOperandType activationType; activationType.type = ANEURALNETWORKS_INT32; activationType.scale = 0.f; activationType.zeroPoint = 0; activationType.dimensionCount = 0; activationType.dimensions = NULL;
// Now we add the seven operands, in the same order defined in the diagram ANeuralNetworksModel_addOperand(model, &tensor3x4Type); // operand 0 ANeuralNetworksModel_addOperand(model, &tensor3x4Type); // operand 1 ANeuralNetworksModel_addOperand(model, &activationType); // operand 2 ANeuralNetworksModel_addOperand(model, &tensor3x4Type); // operand 3 ANeuralNetworksModel_addOperand(model, &tensor3x4Type); // operand 4 ANeuralNetworksModel_addOperand(model, &activationType); // operand 5 ANeuralNetworksModel_addOperand(model, &tensor3x4Type); // operand 6Verwenden Sie für Operanden mit konstanten Werten, z. B. Gewichte und Bias, die Ihre App aus einem Trainingsprozess erhält, die Funktionen
ANeuralNetworksModel_setOperandValue()undANeuralNetworksModel_setOperandValueFromMemory().Im folgenden Beispiel legen wir konstante Werte aus der Trainingsdatendatei fest, die dem Speicherpuffer entsprechen, den wir in Zugriff auf Trainingsdaten gewähren erstellt haben.
// In our example, operands 1 and 3 are constant tensors whose values were // established during the training process const int sizeOfTensor = 3 * 4 * 4; // The formula for size calculation is dim0 * dim1 * elementSize ANeuralNetworksModel_setOperandValueFromMemory(model, 1, mem1, 0, sizeOfTensor); ANeuralNetworksModel_setOperandValueFromMemory(model, 3, mem1, sizeOfTensor, sizeOfTensor);
// We set the values of the activation operands, in our example operands 2 and 5 int32_t noneValue = ANEURALNETWORKS_FUSED_NONE; ANeuralNetworksModel_setOperandValue(model, 2, &noneValue, sizeof(noneValue)); ANeuralNetworksModel_setOperandValue(model, 5, &noneValue, sizeof(noneValue));Fügen Sie für jeden Vorgang im gerichteten Graphen, den Sie berechnen möchten, den Vorgang Ihrem Modell hinzu, indem Sie die Funktion
ANeuralNetworksModel_addOperation()aufrufen.Ihre App muss die folgenden Parameter für diesen Aufruf bereitstellen:
- Vorgangstyp
- Anzahl der Eingabewerte
- Das Array der Indexe für Eingabeoperanden
- Anzahl der Ausgabewerte
- Das Array der Indexe für Ausgabeargumente
Ein Operand kann nicht gleichzeitig für die Ein- und Ausgabe derselben Operation verwendet werden.
// We have two operations in our example // The first consumes operands 1, 0, 2, and produces operand 4 uint32_t addInputIndexes[3] = {1, 0, 2}; uint32_t addOutputIndexes[1] = {4}; ANeuralNetworksModel_addOperation(model, ANEURALNETWORKS_ADD, 3, addInputIndexes, 1, addOutputIndexes);
// The second consumes operands 3, 4, 5, and produces operand 6 uint32_t multInputIndexes[3] = {3, 4, 5}; uint32_t multOutputIndexes[1] = {6}; ANeuralNetworksModel_addOperation(model, ANEURALNETWORKS_MUL, 3, multInputIndexes, 1, multOutputIndexes);Legen Sie mit der Funktion
ANeuralNetworksModel_identifyInputsAndOutputs()fest, welche Operanden das Modell als Ein- und Ausgaben behandeln soll.// Our model has one input (0) and one output (6) uint32_t modelInputIndexes[1] = {0}; uint32_t modelOutputIndexes[1] = {6}; ANeuralNetworksModel_identifyInputsAndOutputs(model, 1, modelInputIndexes, 1 modelOutputIndexes);
Optional können Sie angeben, ob
ANEURALNETWORKS_TENSOR_FLOAT32mit einem Bereich oder einer Genauigkeit berechnet werden darf, die so niedrig ist wie die des IEEE 754-Gleitkommaformats mit 16 Bit, indem SieANeuralNetworksModel_relaxComputationFloat32toFloat16()aufrufen.Rufen Sie
ANeuralNetworksModel_finish()auf, um die Definition Ihres Modells abzuschließen. Wenn keine Fehler vorhanden sind, gibt diese Funktion den ErgebniscodeANEURALNETWORKS_NO_ERRORzurück.ANeuralNetworksModel_finish(model);
Nachdem Sie ein Modell erstellt haben, können Sie es beliebig oft kompilieren und jede Kompilierung beliebig oft ausführen.
Kontrollfluss
So binden Sie den Kontrollfluss in ein NNAPI-Modell ein:
Erstellen Sie die entsprechenden Ausführungsuntergraphen (
then- undelse-Untergraphen für eineIF-Anweisung,condition- undbody-Untergraphen für eineWHILE-Schleife) als eigenständigeANeuralNetworksModel*-Modelle:ANeuralNetworksModel* thenModel = makeThenModel(); ANeuralNetworksModel* elseModel = makeElseModel();
Erstellen Sie Operanden, die auf diese Modelle verweisen, im Modell mit dem Kontrollfluss:
ANeuralNetworksOperandType modelType = { .type = ANEURALNETWORKS_MODEL, }; ANeuralNetworksModel_addOperand(model, &modelType); // kThenOperandIndex ANeuralNetworksModel_addOperand(model, &modelType); // kElseOperandIndex ANeuralNetworksModel_setOperandValueFromModel(model, kThenOperandIndex, &thenModel); ANeuralNetworksModel_setOperandValueFromModel(model, kElseOperandIndex, &elseModel);
Fügen Sie den Vorgang für den Kontrollfluss hinzu:
uint32_t inputs[] = {kConditionOperandIndex, kThenOperandIndex, kElseOperandIndex, kInput1, kInput2, kInput3}; uint32_t outputs[] = {kOutput1, kOutput2}; ANeuralNetworksModel_addOperation(model, ANEURALNETWORKS_IF, std::size(inputs), inputs, std::size(output), outputs);
Compilation
Im Kompilierungsschritt wird festgelegt, auf welchen Prozessoren Ihr Modell ausgeführt wird. Die entsprechenden Treiber werden aufgefordert, sich auf die Ausführung vorzubereiten. Dazu kann auch die Generierung von Maschinencode gehören, der speziell für die Prozessoren entwickelt wurde, auf denen Ihr Modell ausgeführt wird.
So kompilieren Sie ein Modell:
Rufen Sie die Funktion
ANeuralNetworksCompilation_create()auf, um eine neue Kompilierungsinstanz zu erstellen.// Compile the model ANeuralNetworksCompilation* compilation; ANeuralNetworksCompilation_create(model, &compilation);
Optional können Sie mit der Gerätezuweisung explizit auswählen, auf welchen Geräten der Test ausgeführt werden soll.
Sie können optional beeinflussen, wie die Laufzeit zwischen Akkunutzung und Ausführungsgeschwindigkeit abgewogen wird. Rufen Sie dazu
ANeuralNetworksCompilation_setPreference()auf.// Ask to optimize for low power consumption ANeuralNetworksCompilation_setPreference(compilation, ANEURALNETWORKS_PREFER_LOW_POWER);
Sie können unter anderem folgende Einstellungen angeben:
ANEURALNETWORKS_PREFER_LOW_POWER: Bevorzuge die Ausführung auf eine Weise, die den Akkuverbrauch minimiert. Das ist für Kompilierungen, die häufig ausgeführt werden, wünschenswert.ANEURALNETWORKS_PREFER_FAST_SINGLE_ANSWER: Gibt eine einzelne Antwort so schnell wie möglich zurück, auch wenn dies zu einem höheren Stromverbrauch führt. Das ist die Standardeinstellung.ANEURALNETWORKS_PREFER_SUSTAINED_SPEED: Der Durchsatz aufeinanderfolgender Frames soll maximiert werden, z. B. bei der Verarbeitung aufeinanderfolgender Frames von der Kamera.
Optional können Sie das Zwischenspeichern der Kompilierung einrichten, indem Sie
ANeuralNetworksCompilation_setCachingaufrufen.// Set up compilation caching ANeuralNetworksCompilation_setCaching(compilation, cacheDir, token);
Verwenden Sie
getCodeCacheDir()für diecacheDir. Der angegebenetokenmuss für jedes Modell in der Anwendung eindeutig sein.Schließen Sie die Kompilierungsdefinition ab, indem Sie
ANeuralNetworksCompilation_finish()aufrufen. Wenn keine Fehler vorhanden sind, gibt diese Funktion den ErgebniscodeANEURALNETWORKS_NO_ERRORzurück.ANeuralNetworksCompilation_finish(compilation);
Geräteerkennung und ‑zuweisung
Auf Android-Geräten mit Android 10 (API-Level 29) und höher bietet NNAPI Funktionen, mit denen Bibliotheken und Apps für maschinelles Lernen Informationen zu den verfügbaren Geräten abrufen und Geräte für die Ausführung angeben können. Durch die Bereitstellung von Informationen zu den verfügbaren Geräten können Apps die genaue Version der auf einem Gerät gefundenen Treiber abrufen, um bekannte Inkompatibilitäten zu vermeiden. Wenn Apps angeben können, auf welchen Geräten verschiedene Abschnitte eines Modells ausgeführt werden sollen, können sie für das Android-Gerät optimiert werden, auf dem sie bereitgestellt werden.
Geräteerkennung
Verwenden Sie ANeuralNetworks_getDeviceCount, um die Anzahl der verfügbaren Geräte abzurufen. Verwenden Sie für jedes Gerät ANeuralNetworks_getDevice, um eine ANeuralNetworksDevice-Instanz auf eine Referenz zu diesem Gerät festzulegen.
Sobald Sie eine Gerätereferenz haben, können Sie mit den folgenden Funktionen zusätzliche Informationen zu diesem Gerät abrufen:
ANeuralNetworksDevice_getFeatureLevelANeuralNetworksDevice_getNameANeuralNetworksDevice_getTypeANeuralNetworksDevice_getVersion
Gerätezuweisung
Mit ANeuralNetworksModel_getSupportedOperationsForDevices können Sie herausfinden, welche Vorgänge eines Modells auf bestimmten Geräten ausgeführt werden können.
Wenn Sie steuern möchten, welche Beschleuniger für die Ausführung verwendet werden sollen, rufen Sie ANeuralNetworksCompilation_createForDevices anstelle von ANeuralNetworksCompilation_create auf.
Verwenden Sie das resultierende ANeuralNetworksCompilation-Objekt wie gewohnt.
Die Funktion gibt einen Fehler zurück, wenn das bereitgestellte Modell Vorgänge enthält, die von den ausgewählten Geräten nicht unterstützt werden.
Wenn mehrere Geräte angegeben sind, verteilt die Laufzeit die Arbeit auf die Geräte.
Ähnlich wie bei anderen Geräten wird die NNAPI-CPU-Implementierung durch ein ANeuralNetworksDevice mit dem Namen nnapi-reference und dem Typ ANEURALNETWORKS_DEVICE_TYPE_CPU dargestellt. Beim Aufrufen von ANeuralNetworksCompilation_createForDevices wird die CPU-Implementierung nicht verwendet, um die Fehlerfälle für die Modellkompilierung und -ausführung zu verarbeiten.
Es liegt in der Verantwortung der Anwendung, ein Modell in Untermodelle zu unterteilen, die auf den angegebenen Geräten ausgeführt werden können. Anwendungen, die keine manuelle Partitionierung benötigen, sollten weiterhin die einfachere ANeuralNetworksCompilation_create aufrufen, um alle verfügbaren Geräte (einschließlich der CPU) zur Beschleunigung des Modells zu verwenden. Wenn das Modell von den mit ANeuralNetworksCompilation_createForDevices angegebenen Geräten nicht vollständig unterstützt werden kann, wird ANEURALNETWORKS_BAD_DATA zurückgegeben.
Modellpartitionierung
Wenn mehrere Geräte für das Modell verfügbar sind, verteilt die NNAPI-Laufzeit die Arbeit auf die Geräte. Wenn ANeuralNetworksCompilation_createForDevices beispielsweise mehrere Geräte zur Verfügung gestellt wurden, werden alle angegebenen Geräte bei der Zuweisung der Arbeit berücksichtigt. Wenn das CPU-Gerät nicht in der Liste enthalten ist, wird die CPU-Ausführung deaktiviert. Bei der Verwendung von ANeuralNetworksCompilation_create werden alle verfügbaren Geräte berücksichtigt, einschließlich der CPU.
Die Verteilung erfolgt durch Auswahl des Geräts, das den Vorgang unterstützt und die beste Leistung bietet (d.h. die schnellste Ausführungszeit oder den geringsten Stromverbrauch, je nach der vom Client angegebenen Ausführungspräferenz) aus der Liste der verfügbaren Geräte für jeden Vorgang im Modell. Dieser Partitionierungsalgorithmus berücksichtigt keine möglichen Ineffizienzen, die durch die E/A zwischen den verschiedenen Prozessoren verursacht werden. Wenn Sie also mehrere Prozessoren angeben (entweder explizit mit ANeuralNetworksCompilation_createForDevices oder implizit mit ANeuralNetworksCompilation_create), ist es wichtig, die resultierende Anwendung zu profilieren.
Wenn Sie wissen möchten, wie Ihr Modell von NNAPI partitioniert wurde, suchen Sie in den Android-Logs nach einer Meldung (auf INFO-Ebene mit dem Tag ExecutionPlan):
ModelBuilder::findBestDeviceForEachOperation(op-name): device-index
op-name ist der beschreibende Name des Vorgangs im Diagramm und device-index der Index des infrage kommenden Geräts in der Liste der Geräte.
Diese Liste ist die Eingabe für ANeuralNetworksCompilation_createForDevices. Wenn Sie ANeuralNetworksCompilation_createForDevices verwenden, ist sie die Liste der Geräte, die zurückgegeben werden, wenn Sie alle Geräte mit ANeuralNetworks_getDeviceCount und ANeuralNetworks_getDevice durchlaufen.
Die Meldung (auf INFO-Ebene mit dem Tag ExecutionPlan):
ModelBuilder::partitionTheWork: only one best device: device-name
Diese Meldung weist darauf hin, dass der gesamte Graph auf dem Gerät device-name beschleunigt wurde.
Umsetzung
Im Ausführungsschritt wird das Modell auf eine Reihe von Eingaben angewendet und die Berechnungsausgaben werden in einem oder mehreren Nutzerpuffern oder Speicherbereichen gespeichert, die von Ihrer App zugewiesen wurden.
So führen Sie ein kompiliertes Modell aus:
Rufen Sie die Funktion
ANeuralNetworksExecution_create()auf, um eine neue Ausführungsinstanz zu erstellen.// Run the compiled model against a set of inputs ANeuralNetworksExecution* run1 = NULL; ANeuralNetworksExecution_create(compilation, &run1);
Geben Sie an, wo Ihre App die Eingabewerte für die Berechnung liest. Ihre App kann Eingabewerte entweder aus einem Nutzerpuffer oder aus einem zugewiesenen Speicherbereich lesen, indem sie
ANeuralNetworksExecution_setInput()oderANeuralNetworksExecution_setInputFromMemory()aufruft.// Set the single input to our sample model. Since it is small, we won't use a memory buffer float32 myInput[3][4] = { ...the data... }; ANeuralNetworksExecution_setInput(run1, 0, NULL, myInput, sizeof(myInput));
Geben Sie an, wohin Ihre App die Ausgabewerte schreibt. Ihre App kann Ausgabewerte in einen Nutzerpuffer oder einen zugewiesenen Speicherbereich schreiben, indem sie
ANeuralNetworksExecution_setOutput()bzw.ANeuralNetworksExecution_setOutputFromMemory()aufruft.// Set the output float32 myOutput[3][4]; ANeuralNetworksExecution_setOutput(run1, 0, NULL, myOutput, sizeof(myOutput));
Planen Sie den Start der Ausführung, indem Sie die Funktion
ANeuralNetworksExecution_startCompute()aufrufen. Wenn keine Fehler vorhanden sind, gibt diese Funktion den ErgebniscodeANEURALNETWORKS_NO_ERRORzurück.// Starts the work. The work proceeds asynchronously ANeuralNetworksEvent* run1_end = NULL; ANeuralNetworksExecution_startCompute(run1, &run1_end);
Rufen Sie die Funktion
ANeuralNetworksEvent_wait()auf, um zu warten, bis die Ausführung abgeschlossen ist. Wenn die Ausführung erfolgreich war, gibt diese Funktion den ErgebniscodeANEURALNETWORKS_NO_ERRORzurück. Das Warten kann in einem anderen Thread als dem erfolgen, in dem die Ausführung gestartet wird.// For our example, we have no other work to do and will just wait for the completion ANeuralNetworksEvent_wait(run1_end); ANeuralNetworksEvent_free(run1_end); ANeuralNetworksExecution_free(run1);
Optional können Sie eine andere Gruppe von Eingaben auf das kompilierte Modell anwenden, indem Sie mit derselben Kompilierungsinstanz eine neue
ANeuralNetworksExecution-Instanz erstellen.// Apply the compiled model to a different set of inputs ANeuralNetworksExecution* run2; ANeuralNetworksExecution_create(compilation, &run2); ANeuralNetworksExecution_setInput(run2, ...); ANeuralNetworksExecution_setOutput(run2, ...); ANeuralNetworksEvent* run2_end = NULL; ANeuralNetworksExecution_startCompute(run2, &run2_end); ANeuralNetworksEvent_wait(run2_end); ANeuralNetworksEvent_free(run2_end); ANeuralNetworksExecution_free(run2);
Synchrone Ausführung
Bei der asynchronen Ausführung wird Zeit für das Erstellen und Synchronisieren von Threads benötigt. Außerdem kann die Latenz sehr unterschiedlich sein. Die längsten Verzögerungen betragen bis zu 500 Mikrosekunden zwischen dem Zeitpunkt, zu dem ein Thread benachrichtigt oder reaktiviert wird, und dem Zeitpunkt, zu dem er schließlich an einen CPU-Kern gebunden wird.
Um die Latenz zu verbessern, können Sie eine Anwendung stattdessen anweisen, einen synchronen Inferenzaufruf an die Laufzeit zu senden. Dieser Aufruf wird erst zurückgegeben, wenn eine Inferenz abgeschlossen ist, nicht wenn eine Inferenz gestartet wurde. Anstatt ANeuralNetworksExecution_startCompute für einen asynchronen Inferenzaufruf an die Laufzeit aufzurufen, ruft die Anwendung ANeuralNetworksExecution_compute auf, um einen synchronen Aufruf an die Laufzeit auszuführen. Ein Aufruf von ANeuralNetworksExecution_compute verwendet kein ANeuralNetworksEvent und ist nicht mit einem Aufruf von ANeuralNetworksEvent_wait gekoppelt.
Ausführungen von Bilderserien
Auf Android-Geräten mit Android 10 (API-Level 29) und höher unterstützt die NNAPI die Ausführung von Burst-Vorgängen über das ANeuralNetworksBurst-Objekt. Burst-Ausführungen sind eine Folge von Ausführungen derselben Kompilierung, die in schneller Folge erfolgen, z. B. bei der Verarbeitung von Frames einer Kameraaufnahme oder aufeinanderfolgenden Audio-Samples. Die Verwendung von ANeuralNetworksBurst-Objekten kann zu schnelleren Ausführungen führen, da sie Beschleunigern signalisieren, dass Ressourcen zwischen Ausführungen wiederverwendet werden können und dass Beschleuniger während des Bursts in einem leistungsstarken Zustand bleiben sollten.
ANeuralNetworksBurst führt nur zu einer geringfügigen Änderung des normalen Ausführungspfads. Sie erstellen ein Burst-Objekt mit ANeuralNetworksBurst_create, wie im folgenden Code-Snippet gezeigt:
// Create burst object to be reused across a sequence of executions ANeuralNetworksBurst* burst = NULL; ANeuralNetworksBurst_create(compilation, &burst);
Burst-Ausführungen sind synchron. Anstatt ANeuralNetworksExecution_compute für jede Inferenz zu verwenden, kombinieren Sie die verschiedenen ANeuralNetworksExecution-Objekte mit demselben ANeuralNetworksBurst in Aufrufen der Funktion ANeuralNetworksExecution_burstCompute.
// Create and configure first execution object // ... // Execute using the burst object ANeuralNetworksExecution_burstCompute(execution1, burst); // Use results of first execution and free the execution object // ... // Create and configure second execution object // ... // Execute using the same burst object ANeuralNetworksExecution_burstCompute(execution2, burst); // Use results of second execution and free the execution object // ...
Geben Sie das ANeuralNetworksBurst-Objekt mit ANeuralNetworksBurst_free kostenlos, wenn es nicht mehr benötigt wird.
// Cleanup ANeuralNetworksBurst_free(burst);
Asynchrone Befehlswarteschlangen und eingeschränkte Ausführung
In Android 11 und höher unterstützt die NNAPI eine zusätzliche Möglichkeit, die asynchrone Ausführung über die Methode ANeuralNetworksExecution_startComputeWithDependencies() zu planen. Wenn Sie diese Methode verwenden, wird die Ausführung so lange angehalten, bis alle abhängigen Ereignisse signalisiert wurden, bevor die Auswertung beginnt. Sobald die Ausführung abgeschlossen ist und die Ausgaben verwendet werden können, wird das zurückgegebene Ereignis signalisiert.
Je nachdem, welche Geräte die Ausführung übernehmen, wird das Ereignis möglicherweise durch einen Synchronisationszaun unterstützt. Sie müssen ANeuralNetworksEvent_wait() aufrufen, um auf das Ereignis zu warten und die von der Ausführung verwendeten Ressourcen zurückzugewinnen. Sie können Synchronisations-Fences mit ANeuralNetworksEvent_createFromSyncFenceFd() in ein Ereignisobjekt importieren und mit ANeuralNetworksEvent_getSyncFenceFd() aus einem Ereignisobjekt exportieren.
Dynamisch angepasste Ausgaben
Wenn Sie Modelle unterstützen möchten, bei denen die Größe der Ausgabe von den Eingabedaten abhängt, d. h. bei denen die Größe nicht zur Laufzeit des Modells bestimmt werden kann, verwenden Sie ANeuralNetworksExecution_getOutputOperandRank und ANeuralNetworksExecution_getOutputOperandDimensions.
Das folgende Codebeispiel zeigt, wie das geht:
// Get the rank of the output uint32_t myOutputRank = 0; ANeuralNetworksExecution_getOutputOperandRank(run1, 0, &myOutputRank); // Get the dimensions of the output std::vector<uint32_t> myOutputDimensions(myOutputRank); ANeuralNetworksExecution_getOutputOperandDimensions(run1, 0, myOutputDimensions.data());
Bereinigung
Im Bereinigungsschritt werden die internen Ressourcen freigegeben, die für die Berechnung verwendet wurden.
// Cleanup ANeuralNetworksCompilation_free(compilation); ANeuralNetworksModel_free(model); ANeuralNetworksMemory_free(mem1);
Fehlermanagement und CPU-Fallback
Wenn bei der Partitionierung ein Fehler auftritt, ein Treiber ein (Teil eines) Modell nicht kompilieren kann oder ein Treiber ein kompiliertes (Teil eines) Modell nicht ausführen kann, greift NNAPI möglicherweise auf die eigene CPU-Implementierung der einen oder mehreren Operationen zurück.
Wenn der NNAPI-Client optimierte Versionen des Vorgangs enthält (z. B. TFLite), kann es von Vorteil sein, den CPU-Fallback zu deaktivieren und die Fehler mit der optimierten Implementierung des Vorgangs durch den Client zu beheben.
Wenn in Android 10 die Kompilierung mit ANeuralNetworksCompilation_createForDevices erfolgt, wird der CPU-Fallback deaktiviert.
In Android P wird die NNAPI-Ausführung auf die CPU zurückgesetzt, wenn die Ausführung auf dem Treiber fehlschlägt.
Das gilt auch für Android 10, wenn ANeuralNetworksCompilation_create anstelle von ANeuralNetworksCompilation_createForDevices verwendet wird.
Die erste Ausführung wird für diese einzelne Partition zurückgesetzt. Wenn das immer noch fehlschlägt, wird das gesamte Modell auf der CPU noch einmal ausgeführt.
Wenn die Partitionierung oder Kompilierung fehlschlägt, wird das gesamte Modell auf der CPU ausgeführt.
Es gibt Fälle, in denen einige Vorgänge auf der CPU nicht unterstützt werden. In solchen Situationen schlägt die Kompilierung oder Ausführung fehl, anstatt dass ein Fallback erfolgt.
Auch nach dem Deaktivieren des CPU-Fallbacks kann es sein, dass Vorgänge im Modell auf der CPU geplant werden. Wenn die CPU in der Liste der Prozessoren enthalten ist, die für ANeuralNetworksCompilation_createForDevices bereitgestellt werden, und entweder der einzige Prozessor ist, der diese Vorgänge unterstützt, oder der Prozessor, der die beste Leistung für diese Vorgänge bietet, wird er als primärer (nicht als Fallback-)Executor ausgewählt.
Wenn Sie sichergehen möchten, dass keine CPU-Ausführung erfolgt, verwenden Sie ANeuralNetworksCompilation_createForDevices und schließen Sie nnapi-reference aus der Liste der Geräte aus.
Ab Android P ist es möglich, den Fallback zur Laufzeit in DEBUG-Builds zu deaktivieren, indem Sie die Eigenschaft debug.nn.partition auf 2 setzen.
Erinnerungsdomains
In Android 11 und höher unterstützt NNAPI Speicherbereiche, die Zuweisungsschnittstellen für undurchsichtige Speicher bereitstellen. So können Anwendungen geräteinterne Speicher über Ausführungen hinweg weitergeben, sodass NNAPI Daten nicht unnötig kopiert oder transformiert, wenn aufeinanderfolgende Ausführungen auf demselben Treiber erfolgen.
Die Funktion „Memory Domain“ ist für Tensoren vorgesehen, die hauptsächlich intern im Treiber verwendet werden und auf die nicht häufig auf der Clientseite zugegriffen werden muss. Beispiele für solche Tensoren sind die Status-Tensoren in Sequenzmodellen. Verwenden Sie stattdessen Shared-Memory-Pools für Tensoren, die clientseitig häufigen CPU-Zugriff benötigen.
So weisen Sie einen undurchsichtigen Speicher zu:
Rufen Sie die Funktion
ANeuralNetworksMemoryDesc_create()auf, um einen neuen Speicherdeskriptor zu erstellen:// Create a memory descriptor ANeuralNetworksMemoryDesc* desc; ANeuralNetworksMemoryDesc_create(&desc);
Geben Sie alle gewünschten Eingabe- und Ausgaberollen an, indem Sie
ANeuralNetworksMemoryDesc_addInputRole()undANeuralNetworksMemoryDesc_addOutputRole()aufrufen.// Specify that the memory may be used as the first input and the first output // of the compilation ANeuralNetworksMemoryDesc_addInputRole(desc, compilation, 0, 1.0f); ANeuralNetworksMemoryDesc_addOutputRole(desc, compilation, 0, 1.0f);
Optional können Sie die Arbeitsspeicherdimensionen mit dem Aufruf von
ANeuralNetworksMemoryDesc_setDimensions()angeben.// Specify the memory dimensions uint32_t dims[] = {3, 4}; ANeuralNetworksMemoryDesc_setDimensions(desc, 2, dims);
Schließen Sie die Deskriptordefinition ab, indem Sie
ANeuralNetworksMemoryDesc_finish()aufrufen.ANeuralNetworksMemoryDesc_finish(desc);
Weisen Sie so viele Speicherbereiche wie nötig zu, indem Sie den Deskriptor an
ANeuralNetworksMemory_createFromDesc()übergeben.// Allocate two opaque memories with the descriptor ANeuralNetworksMemory* opaqueMem; ANeuralNetworksMemory_createFromDesc(desc, &opaqueMem);
Geben Sie den Speicherdeskriptor kostenlos, wenn Sie ihn nicht mehr benötigen.
ANeuralNetworksMemoryDesc_free(desc);
Der Client darf das erstellte ANeuralNetworksMemory-Objekt nur mit ANeuralNetworksExecution_setInputFromMemory() oder ANeuralNetworksExecution_setOutputFromMemory() gemäß den im ANeuralNetworksMemoryDesc-Objekt angegebenen Rollen verwenden. Die Argumente „offset“ und „length“ müssen auf 0 gesetzt werden, um anzugeben, dass der gesamte Speicher verwendet wird. Der Client kann den Inhalt des Speichers auch explizit festlegen oder extrahieren, indem er ANeuralNetworksMemory_copy() verwendet.
Sie können undurchsichtige Erinnerungen mit Rollen von nicht angegebenen Dimensionen oder Rängen erstellen.
In diesem Fall schlägt die Erstellung des Speichers möglicherweise mit dem Status ANEURALNETWORKS_OP_FAILED fehl, wenn sie vom zugrunde liegenden Treiber nicht unterstützt wird. Der Client wird aufgefordert, eine Fallback-Logik zu implementieren, indem er einen ausreichend großen Puffer zuweist, der von Ashmem oder AHardwareBuffer im BLOB-Modus unterstützt wird.
Wenn NNAPI nicht mehr auf das undurchsichtige Speicherobjekt zugreifen muss, geben Sie die entsprechende ANeuralNetworksMemory-Instanz kostenlos:
ANeuralNetworksMemory_free(opaqueMem);
Leistungsmessung
Sie können die Leistung Ihrer App bewerten, indem Sie die Ausführungszeit messen oder ein Profil erstellen.
Ausführungszeit
Wenn Sie die Gesamtausführungszeit über die Laufzeit ermitteln möchten, können Sie die API für die synchrone Ausführung verwenden und die für den Aufruf benötigte Zeit messen. Wenn Sie die Gesamtausführungszeit über eine niedrigere Ebene des Softwarestacks ermitteln möchten, können Sie ANeuralNetworksExecution_setMeasureTiming und ANeuralNetworksExecution_getDuration verwenden, um Folgendes zu erhalten:
- Ausführungszeit auf einem Beschleuniger (nicht im Treiber, der auf dem Hostprozessor ausgeführt wird).
- Ausführungszeit im Treiber, einschließlich der Zeit auf dem Beschleuniger.
Die Ausführungszeit im Treiber schließt Overhead aus, z. B. den der Laufzeit selbst und den IPC, der für die Kommunikation der Laufzeit mit dem Treiber erforderlich ist.
Mit diesen APIs wird die Dauer zwischen den Ereignissen „Arbeit eingereicht“ und „Arbeit abgeschlossen“ gemessen und nicht die Zeit, die ein Treiber oder Beschleuniger für die Ausführung der Inferenz benötigt, die möglicherweise durch Kontextwechsel unterbrochen wird.
Wenn beispielsweise die Inferenz 1 beginnt, der Treiber die Arbeit unterbricht, um die Inferenz 2 auszuführen, und dann die Inferenz 1 fortsetzt und abschließt, umfasst die Ausführungszeit für die Inferenz 1 die Zeit, in der die Arbeit unterbrochen wurde, um die Inferenz 2 auszuführen.
Diese Zeitinformationen können für die Produktionsbereitstellung einer Anwendung nützlich sein, um Telemetriedaten für die Offlineverwendung zu erfassen. Anhand der Zeitmessungsdaten können Sie die App für eine höhere Leistung optimieren.
Beachten Sie bei der Verwendung dieser Funktion Folgendes:
- Das Erfassen von Zeitinformationen kann sich auf die Leistung auswirken.
- Nur ein Treiber kann die Zeit berechnen, die in ihm selbst oder auf dem Beschleuniger verbracht wird. Die Zeit, die in der NNAPI-Laufzeit und im IPC verbracht wird, wird dabei nicht berücksichtigt.
- Sie können diese APIs nur mit einem
ANeuralNetworksExecutionverwenden, das mitANeuralNetworksCompilation_createForDevicesundnumDevices = 1erstellt wurde. - Es ist kein Fahrer erforderlich, um Zeitinformationen zu melden.
Anwendung mit Android Systrace profilieren
Ab Android 10 generiert die NNAPI automatisch Systrace-Ereignisse, mit denen Sie Ihre Anwendung profilieren können.
Die NNAPI-Quelle enthält das parse_systrace-Dienstprogramm, mit dem die von Ihrer Anwendung generierten Systrace-Ereignisse verarbeitet und eine Tabellenansicht mit der Zeit generiert werden kann, die in den verschiedenen Phasen des Modelllebenszyklus (Instanziierung, Vorbereitung, Kompilierungsausführung und Beendigung) und den verschiedenen Ebenen der Anwendungen verbracht wurde. Die Ebenen, in die Ihre Anwendung unterteilt ist, sind:
Application: der HauptanwendungscodeRuntime: NNAPI-LaufzeitIPC: Die Interprozesskommunikation zwischen der NNAPI-Laufzeit und dem TreibercodeDriver: Der Prozess des Beschleunigertreibers.
Profildaten generieren
Angenommen, Sie haben den AOSP-Quellbaum unter $ANDROID_BUILD_TOP ausgecheckt und verwenden das TFLite-Beispiel für die Bildklassifizierung als Zielanwendung. Dann können Sie die NNAPI-Profildaten mit den folgenden Schritten generieren:
- Starten Sie den Android-Systrace mit dem folgenden Befehl:
$ANDROID_BUILD_TOP/external/chromium-trace/systrace.py -o trace.html -a org.tensorflow.lite.examples.classification nnapi hal freq sched idle load binder_driver
Der Parameter -o trace.html gibt an, dass die Traces in trace.html geschrieben werden. Wenn Sie Ihre eigene Anwendung profilieren, müssen Sie org.tensorflow.lite.examples.classification durch den Prozessnamen ersetzen, der in Ihrem App-Manifest angegeben ist.
Dadurch wird eine Ihrer Shell-Konsolen belegt. Führen Sie den Befehl nicht im Hintergrund aus, da er interaktiv auf ein enter wartet, um beendet zu werden.
- Nachdem der Systrace-Collector gestartet wurde, starten Sie Ihre App und führen Sie den Benchmarktest aus.
In unserem Fall können Sie die App Image Classification (Bildklassifizierung) über Android Studio oder direkt über die Benutzeroberfläche Ihres Testsmartphones starten, wenn die App bereits installiert wurde. Damit NNAPI-Daten generiert werden, müssen Sie die App so konfigurieren, dass NNAPI verwendet wird. Wählen Sie dazu im Dialogfeld für die App-Konfiguration NNAPI als Zielgerät aus.
Wenn der Test abgeschlossen ist, beenden Sie den Systrace, indem Sie im Konsolenterminal, das seit Schritt 1 aktiv ist,
enterdrücken.Führen Sie das Dienstprogramm
systrace_parseraus, um kumulative Statistiken zu generieren:
$ANDROID_BUILD_TOP/frameworks/ml/nn/tools/systrace_parser/parse_systrace.py --total-times trace.html
Der Parser akzeptiert die folgenden Parameter:
- --total-times: Zeigt die Gesamtzeit an, die in einer Ebene verbracht wurde, einschließlich der Wartezeit für die Ausführung bei einem Aufruf einer zugrunde liegenden Ebene.
- --print-detail: Gibt alle Ereignisse aus, die aus systrace erfasst wurden.
- --per-execution: Gibt nur die Ausführung und ihre Unterphasen (als Ausführungszeiten) anstelle von Statistiken für alle Phasen aus.
- --json: Gibt die Ausgabe im JSON-Format aus.
Ein Beispiel für die Ausgabe ist unten zu sehen:
===========================================================================================================================================
NNAPI timing summary (total time, ms wall-clock) Execution
----------------------------------------------------
Initialization Preparation Compilation I/O Compute Results Ex. total Termination Total
-------------- ----------- ----------- ----------- ------------ ----------- ----------- ----------- ----------
Application n/a 19.06 1789.25 n/a n/a 6.70 21.37 n/a 1831.17*
Runtime - 18.60 1787.48 2.93 11.37 0.12 14.42 1.32 1821.81
IPC 1.77 - 1781.36 0.02 8.86 - 8.88 - 1792.01
Driver 1.04 - 1779.21 n/a n/a n/a 7.70 - 1787.95
Total 1.77* 19.06* 1789.25* 2.93* 11.74* 6.70* 21.37* 1.32* 1831.17*
===========================================================================================================================================
* This total ignores missing (n/a) values and thus is not necessarily consistent with the rest of the numbers
Der Parser schlägt möglicherweise fehl, wenn die erfassten Ereignisse keinen vollständigen Anwendungs-Trace darstellen. Das kann insbesondere dann passieren, wenn im Trace Systrace-Ereignisse vorhanden sind, die das Ende eines Abschnitts markieren, aber kein zugehöriges Ereignis zum Start des Abschnitts. Das passiert in der Regel, wenn beim Starten des Systrace-Collectors einige Ereignisse aus einer vorherigen Profiling-Sitzung generiert werden. In diesem Fall müssen Sie das Profiling noch einmal ausführen.
Statistiken für Ihren Anwendungscode zur Ausgabe von systrace_parser hinzufügen
Die Anwendung „parse_systrace“ basiert auf der integrierten Android-Systrace-Funktion. Mit der Systrace API (für Java, für native Anwendungen) können Sie Traces für bestimmte Vorgänge in Ihrer App mit benutzerdefinierten Ereignisnamen hinzufügen.
Wenn Sie Ihre benutzerdefinierten Ereignisse mit Phasen des Anwendungslebenszyklus verknüpfen möchten, stellen Sie dem Ereignisnamen einen der folgenden Strings voran:
[NN_LA_PI]: Ereignis auf Anwendungsebene für die Initialisierung[NN_LA_PP]: Ereignis auf Anwendungsebene für die Vorbereitung[NN_LA_PC]: Ereignis auf Anwendungsebene für die Kompilierung[NN_LA_PE]: Ereignis auf Anwendungsebene für die Ausführung
Hier sehen Sie ein Beispiel dafür, wie Sie den Beispielcode für die TFLite-Bildklassifizierung ändern können, indem Sie einen runInferenceModel-Abschnitt für die Execution-Phase und die Application-Ebene mit anderen Abschnitten preprocessBitmap hinzufügen, die in NNAPI-Traces nicht berücksichtigt werden. Der Abschnitt runInferenceModel ist Teil der Systrace-Ereignisse, die vom NNAPI-Systrace-Parser verarbeitet werden:
Kotlin
/** Runs inference and returns the classification results. */ fun recognizeImage(bitmap: Bitmap): List{ // This section won’t appear in the NNAPI systrace analysis Trace.beginSection("preprocessBitmap") convertBitmapToByteBuffer(bitmap) Trace.endSection() // Run the inference call. // Add this method in to NNAPI systrace analysis. Trace.beginSection("[NN_LA_PE]runInferenceModel") long startTime = SystemClock.uptimeMillis() runInference() long endTime = SystemClock.uptimeMillis() Trace.endSection() ... return recognitions }
Java
/** Runs inference and returns the classification results. */ public ListrecognizeImage(final Bitmap bitmap) { // This section won’t appear in the NNAPI systrace analysis Trace.beginSection("preprocessBitmap"); convertBitmapToByteBuffer(bitmap); Trace.endSection(); // Run the inference call. // Add this method in to NNAPI systrace analysis. Trace.beginSection("[NN_LA_PE]runInferenceModel"); long startTime = SystemClock.uptimeMillis(); runInference(); long endTime = SystemClock.uptimeMillis(); Trace.endSection(); ... Trace.endSection(); return recognitions; }
Dienstqualität
In Android 11 und höher ermöglicht die NNAPI eine bessere Dienstqualität (QoS), da eine Anwendung die relativen Prioritäten ihrer Modelle, die maximale Zeit, die für die Vorbereitung eines bestimmten Modells benötigt wird, und die maximale Zeit, die für die Ausführung einer bestimmten Berechnung benötigt wird, angeben kann. In Android 11 werden auch zusätzliche NNAPI-Ergebniscodes eingeführt, mit denen Anwendungen Fehler wie verpasste Ausführungsfristen erkennen können.
Priorität einer Arbeitslast festlegen
Wenn Sie die Priorität einer NNAPI-Arbeitslast festlegen möchten, rufen Sie ANeuralNetworksCompilation_setPriority() vor dem Aufrufen von ANeuralNetworksCompilation_finish() auf.
Fristen festlegen
Anwendungen können Fristen für die Modellkompilierung und ‑inferenz festlegen.
- Um das Zeitlimit für die Kompilierung festzulegen, rufen Sie
ANeuralNetworksCompilation_setTimeout()vor dem Aufrufen vonANeuralNetworksCompilation_finish()auf. - Rufen Sie
ANeuralNetworksExecution_setTimeout()vor Beginn der Kompilierung auf, um das Zeitlimit für die Inferenz festzulegen.
Weitere Informationen zu Operanden
Im folgenden Abschnitt werden erweiterte Themen zur Verwendung von Operanden behandelt.
Quantisierte Tensoren
Ein quantisierter Tensor ist eine kompakte Möglichkeit, ein n-dimensionales Array von Gleitkommawerten darzustellen.
NNAPI unterstützt asymmetrisch quantisierte 8-Bit-Tensoren. Bei diesen Tensoren wird der Wert jeder Zelle durch eine 8‑Bit-Ganzzahl dargestellt. Dem Tensor ist ein Skalierungs- und ein Nullpunktwert zugeordnet. Sie werden verwendet, um die 8‑Bit-Ganzzahlen in die dargestellten Gleitkommawerte umzuwandeln.
Die Formel lautet:
(cellValue - zeroPoint) * scale
Dabei ist der zeroPoint-Wert eine 32-Bit-Ganzzahl und der scale-Wert ein 32-Bit-Gleitkommawert.
Im Vergleich zu Tensoren mit 32-Bit-Gleitkommawerten haben 8-Bit-quantisierte Tensoren zwei Vorteile:
- Ihre Anwendung ist kleiner, da die trainierten Gewichte nur ein Viertel der Größe von 32-Bit-Tensoren haben.
- Berechnungen können oft schneller ausgeführt werden. Das liegt an der geringeren Menge an Daten, die aus dem Arbeitsspeicher abgerufen werden müssen, und an der Effizienz von Prozessoren wie DSPs bei der Durchführung von Ganzzahlberechnungen.
Es ist zwar möglich, ein Gleitkommamodell in ein quantisiertes Modell zu konvertieren, aber unsere Erfahrung hat gezeigt, dass bessere Ergebnisse erzielt werden, wenn ein quantisiertes Modell direkt trainiert wird. Das neuronale Netzwerk lernt, die erhöhte Granularität der einzelnen Werte auszugleichen. Für jeden quantisierten Tensor werden die Werte für „scale“ und „zeroPoint“ während des Trainingsprozesses bestimmt.
In NNAPI definieren Sie quantisierte Tensortypen, indem Sie das Typfeld der Datenstruktur ANeuralNetworksOperandType auf ANEURALNETWORKS_TENSOR_QUANT8_ASYMM setzen.
Sie geben auch den Skalierungs- und zeroPoint-Wert des Tensors in dieser Datenstruktur an.
Zusätzlich zu asymmetrischen quantisierten 8-Bit-Tensoren unterstützt NNAPI Folgendes:
ANEURALNETWORKS_TENSOR_QUANT8_SYMM_PER_CHANNEL, mit dem Sie Gewichte fürCONV/DEPTHWISE_CONV/TRANSPOSED_CONV-Vorgänge darstellen können.ANEURALNETWORKS_TENSOR_QUANT16_ASYMMdie Sie für den internen Status vonQUANTIZED_16BIT_LSTMverwenden können.ANEURALNETWORKS_TENSOR_QUANT8_SYMMkann eine Eingabe fürANEURALNETWORKS_DEQUANTIZEsein.
Optionale Operanden
Einige Vorgänge, z. B. ANEURALNETWORKS_LSH_PROJECTION, verwenden optionale Operanden. Wenn Sie dem Modell mitteilen möchten, dass der optionale Operand ausgelassen wird, rufen Sie die Funktion ANeuralNetworksModel_setOperandValue() auf und übergeben Sie NULL für den Puffer und 0 für die Länge.
Wenn die Entscheidung, ob der Operand vorhanden ist oder nicht, für jede Ausführung variiert, geben Sie an, dass der Operand ausgelassen wird, indem Sie die Funktionen ANeuralNetworksExecution_setInput() oder ANeuralNetworksExecution_setOutput() verwenden und NULL für den Puffer und 0 für die Länge übergeben.
Tensoren mit unbekanntem Rang
Mit Android 9 (API-Level 28) wurden Modelloperanden mit unbekannten Dimensionen, aber bekanntem Rang (Anzahl der Dimensionen) eingeführt. Mit Android 10 (API-Level 29) wurden Tensoren mit unbekanntem Rang eingeführt, wie in ANeuralNetworksOperandType gezeigt.
NNAPI-Benchmark
Der NNAPI-Benchmark ist in AOSP unter platform/test/mlts/benchmark (Benchmark-App) und platform/test/mlts/models (Modelle und Datasets) verfügbar.
Der Benchmark bewertet Latenz und Genauigkeit und vergleicht Treiber mit derselben Arbeit, die mit TensorFlow Lite auf der CPU für dieselben Modelle und Datasets ausgeführt wird.
So verwenden Sie den Benchmark:
Schließen Sie ein Android-Zielgerät an Ihren Computer an, öffnen Sie ein Terminalfenster und prüfen Sie, ob das Gerät über ADB erreichbar ist.
Wenn mehrere Android-Geräte verbunden sind, exportieren Sie die Umgebungsvariable
ANDROID_SERIALdes Zielgeräts.Wechseln Sie zum Android-Quellverzeichnis der obersten Ebene.
Führen Sie folgende Befehle aus:
lunch aosp_arm-userdebug # Or aosp_arm64-userdebug if available ./test/mlts/benchmark/build_and_run_benchmark.sh
Am Ende eines Benchmark-Laufs werden die Ergebnisse als HTML-Seite dargestellt, die an
xdg-openübergeben wird.
NNAPI-Logs
NNAPI generiert nützliche Diagnoseinformationen in den Systemprotokollen. Verwenden Sie das logcat-Dienstprogramm, um die Logs zu analysieren.
Aktivieren Sie die ausführliche NNAPI-Protokollierung für bestimmte Phasen oder Komponenten, indem Sie die Eigenschaft debug.nn.vlog (mit adb shell) auf die folgende Liste von Werten setzen, die durch Leerzeichen, Doppelpunkt oder Komma getrennt sind:
model: Modell erstellencompilation: Generierung des Modell-Ausführungsplans und Kompilierungexecution: Modellausführungcpuexe: Ausführung von Vorgängen mit der NNAPI-CPU-Implementierungmanager: Informationen zu NNAPI-Erweiterungen, verfügbaren Schnittstellen und Funktionenalloder1: Alle oben genannten Elemente
Wenn Sie beispielsweise das vollständige ausführliche Logging aktivieren möchten, verwenden Sie den Befehl adb shell setprop debug.nn.vlog all. Verwenden Sie den Befehl adb shell setprop debug.nn.vlog '""', um das ausführliche Logging zu deaktivieren.
Wenn die ausführliche Protokollierung aktiviert ist, werden Logeinträge auf INFO-Ebene mit einem Tag generiert, das auf den Namen der Phase oder Komponente festgelegt ist.
Neben den von debug.nn.vlog gesteuerten Nachrichten stellen die NNAPI-API-Komponenten andere Logeinträge auf verschiedenen Ebenen bereit, die jeweils ein bestimmtes Log-Tag verwenden.
Wenn Sie eine Liste der Komponenten abrufen möchten, suchen Sie im Quellbaum mit dem folgenden Ausdruck:
grep -R 'define LOG_TAG' | awk -F '"' '{print $2}' | sort -u | egrep -v "Sample|FileTag|test"
Dieser Ausdruck gibt derzeit die folgenden Tags zurück:
- BurstBuilder
- Callbacks
- CompilationBuilder
- CpuExecutor
- ExecutionBuilder
- ExecutionBurstController
- ExecutionBurstServer
- ExecutionPlan
- FibonacciDriver
- GraphDump
- IndexedShapeWrapper
- IonWatcher
- Managerin/Manager
- Arbeitsspeicher
- MemoryUtils
- MetaModel
- ModelArgumentInfo
- ModelBuilder
- NeuralNetworks
- OperationResolver
- Aufgaben und Ablauf
- OperationsUtils
- PackageInfo
- TokenHasher
- TypeManager
- Utils
- ValidateHal
- VersionedInterfaces
Wenn Sie die Ebene der von logcat angezeigten Log-Nachrichten steuern möchten, verwenden Sie die Umgebungsvariable ANDROID_LOG_TAGS.
Wenn Sie alle NNAPI-Logmeldungen anzeigen und alle anderen deaktivieren möchten, legen Sie ANDROID_LOG_TAGS auf Folgendes fest:
BurstBuilder:V Callbacks:V CompilationBuilder:V CpuExecutor:V ExecutionBuilder:V ExecutionBurstController:V ExecutionBurstServer:V ExecutionPlan:V FibonacciDriver:V GraphDump:V IndexedShapeWrapper:V IonWatcher:V Manager:V MemoryUtils:V Memory:V MetaModel:V ModelArgumentInfo:V ModelBuilder:V NeuralNetworks:V OperationResolver:V OperationsUtils:V Operations:V PackageInfo:V TokenHasher:V TypeManager:V Utils:V ValidateHal:V VersionedInterfaces:V *:S.
Mit dem folgenden Befehl können Sie ANDROID_LOG_TAGS festlegen:
export ANDROID_LOG_TAGS=$(grep -R 'define LOG_TAG' | awk -F '"' '{ print $2 ":V" }' | sort -u | egrep -v "Sample|FileTag|test" | xargs echo -n; echo ' *:S')
Beachten Sie, dass dies nur ein Filter ist, der auf logcat angewendet wird. Sie müssen die Eigenschaft debug.nn.vlog weiterhin auf all festlegen, um ausführliche Protokollinformationen zu generieren.