


ใน Android 17 แอปที่กำหนดเป้าหมายเป็น SDK 37 ขึ้นไปจะได้รับการติดตั้งใช้งาน MessageQueue ใหม่ซึ่งไม่มีการล็อก การติดตั้งใช้งานใหม่นี้ช่วยปรับปรุงประสิทธิภาพและลดเฟรมที่พลาดไป แต่ก็อาจทำให้ไคลเอ็นต์ที่ใช้ฟิลด์และเมธอดส่วนตัวของ MessageQueue ใช้งานไม่ได้ ดูข้อมูลเพิ่มเติมเกี่ยวกับการเปลี่ยนแปลงลักษณะการทำงานและวิธีลดผลกระทบได้ที่เอกสารประกอบเกี่ยวกับการเปลี่ยนแปลงลักษณะการทำงานของ MessageQueue บล็อกโพสต์ทางเทคนิคนี้จะให้ภาพรวมของการปรับโครงสร้าง MessageQueue และวิธีวิเคราะห์ปัญหาการแย่งชิงล็อกโดยใช้ Perfetto
Looper จะขับเคลื่อนเทรด UI ของแอปพลิเคชัน Android ทุกแอป โดยจะดึงงานจาก MessageQueue ส่งไปยัง Handler แล้วทำซ้ำ เป็นเวลา 2 ทศวรรษที่ MessageQueue ใช้การล็อกจอภาพเดียว (เช่น โค้ดบล็อก synchronized) เพื่อปกป้องสถานะของตน
Android 17 มีการอัปเดตที่สำคัญสำหรับคอมโพเนนต์นี้ ซึ่งเป็นการใช้งานแบบไม่ต้องล็อกที่ชื่อ DeliQueue
โพสต์นี้อธิบายว่าการล็อกส่งผลต่อประสิทธิภาพ UI อย่างไร วิธีวิเคราะห์ปัญหาเหล่านี้ด้วย Perfetto รวมถึงอัลกอริทึมและการเพิ่มประสิทธิภาพที่เฉพาะเจาะจงซึ่งใช้เพื่อปรับปรุงเทรดหลักของ Android
ปัญหา: การแย่งชิงล็อกและการกลับลำดับความสำคัญ
MessageQueue รุ่นเดิมทำหน้าที่เป็นคิวลำดับความสำคัญที่ได้รับการปกป้องด้วยการล็อกเดียว หากเธรดเบื้องหลังโพสต์ข้อความขณะที่เธรดหลักกำลังบำรุงรักษาคิว เธรดเบื้องหลังจะบล็อกเธรดหลัก
เมื่อเธรด 2 รายการขึ้นไปแข่งขันกันเพื่อใช้ล็อกเดียวกันแต่เพียงผู้เดียว เราจะเรียกเหตุการณ์นี้ว่าการแย่งชิงล็อก การแย่งชิงนี้อาจทำให้เกิดการกลับลำดับความสำคัญ ซึ่งนำไปสู่การกระตุกของ UI และปัญหาด้านประสิทธิภาพอื่นๆ
การผกผันลำดับความสำคัญอาจเกิดขึ้นเมื่อมีการทำให้เธรดที่มีลำดับความสำคัญสูง (เช่น เธรด UI) ต้องรอเธรดที่มีลำดับความสำคัญต่ำ ลองพิจารณาลำดับต่อไปนี้
- เธรดพื้นหลังที่มีลำดับความสำคัญต่ำจะรับล็อก
MessageQueueเพื่อโพสต์ผลลัพธ์ของงานที่ทำ - เทรดที่มีลำดับความสำคัญปานกลางจะพร้อมทำงาน และตัวจัดกำหนดการของเคอร์เนลจะจัดสรรเวลา CPU ให้กับเทรดดังกล่าว โดยจะขัดจังหวะเทรดที่มีลำดับความสำคัญต่ำ
- เธรด UI ลำดับความสำคัญสูงจะทำงานปัจจุบันให้เสร็จและพยายามอ่านจากคิว แต่ถูกบล็อกเนื่องจากเธรดลำดับความสำคัญต่ำถือล็อกอยู่
เทรดที่มีลำดับความสำคัญต่ำจะบล็อกเทรด UI และงานที่มีลำดับความสำคัญปานกลางจะทำให้เกิดความล่าช้ามากยิ่งขึ้น

การวิเคราะห์การแย่งชิงด้วย Perfetto
คุณสามารถวินิจฉัยปัญหาเหล่านี้ได้โดยใช้ Perfetto ในการติดตามมาตรฐาน เธรดที่ถูกบล็อกในมอนิเตอร์ล็อกจะเข้าสู่สถานะพัก และ Perfetto จะแสดงสไลซ์ที่ระบุเจ้าของล็อก
เมื่อค้นหาข้อมูลการติดตาม ให้มองหาสไลซ์ที่มีชื่อว่า “ตรวจสอบการแย่งชิงด้วย …” ตามด้วยชื่อของเทรดที่เป็นเจ้าของล็อกและโค้ดไซต์ที่ได้ล็อก
กรณีศึกษา: ความกระตุกของ Launcher
เพื่อเป็นตัวอย่าง ลองวิเคราะห์การติดตามที่ผู้ใช้พบปัญหาการกระตุกขณะไปยังหน้าแรกในโทรศัพท์ Pixel ทันทีหลังจากถ่ายรูปในแอปกล้อง ภาพหน้าจอด้านล่างแสดง Perfetto ที่แสดงเหตุการณ์ที่นำไปสู่เฟรมที่พลาดไป

- อาการ: เทรดหลักของ Launcher ไม่ทันกำหนดเวลาเฟรม โดยบล็อกเป็นเวลา 18 มิลลิวินาที ซึ่งเกินกำหนดเวลา 16 มิลลิวินาทีที่จำเป็นสำหรับการแสดงผล 60Hz
- การวินิจฉัย: Perfetto แสดงให้เห็นว่าเทรดหลักถูกบล็อกในล็อก
MessageQueueเทรด "BackgroundExecutor" เป็นเจ้าของล็อก - สาเหตุหลัก: BackgroundExecutor ทำงานที่ Process.THREAD_PRIORITY_BACKGROUND (ลำดับความสำคัญต่ำมาก) โดยดำเนินการที่ไม่เร่งด่วน (ตรวจสอบโควต้าการใช้งานแอป) ในขณะเดียวกัน เธรดที่มีลำดับความสำคัญปานกลางก็ใช้เวลา CPU ในการประมวลผลข้อมูลจากกล้อง ตัวจัดตารางเวลาของระบบปฏิบัติการขัดจังหวะเธรด BackgroundExecutor เพื่อเรียกใช้เธรดของกล้อง
ลำดับนี้ทำให้เธรด UI ของ Launcher (ลำดับความสำคัญสูง) ถูกบล็อกโดยอ้อมจากเทรดผู้ปฏิบัติงานของกล้อง (ลำดับความสำคัญปานกลาง) ซึ่งทำให้เธรดพื้นหลังของ Launcher (ลำดับความสำคัญต่ำ) ไม่สามารถปลดล็อกได้
การค้นหาร่องรอยด้วย PerfettoSQL
คุณใช้ PerfettoSQL เพื่อค้นหาข้อมูลการติดตามสำหรับรูปแบบที่เฉพาะเจาะจงได้ ซึ่งจะมีประโยชน์หากคุณมีบันทึกการติดตามจำนวนมากจากอุปกรณ์ของผู้ใช้หรือการทดสอบ และกำลังค้นหาบันทึกการติดตามที่เฉพาะเจาะจงซึ่งแสดงให้เห็นปัญหา
ตัวอย่างเช่น การค้นหานี้จะพบการMessageQueueที่เกิดขึ้นพร้อมกับเฟรมที่หลุด (ความกระตุก)
INCLUDE PERFETTO MODULE android.monitor_contention; INCLUDE PERFETTO MODULE android.frames.jank_type; SELECT process_name, -- Convert duration from nanoseconds to milliseconds SUM(dur) / 1000000 AS sum_dur_ms, COUNT(*) AS count_contention FROM android_monitor_contention WHERE is_blocked_thread_main AND short_blocked_method LIKE "%MessageQueue%" -- Only look at app processes that had jank AND upid IN ( SELECT DISTINCT(upid) FROM actual_frame_timeline_slice WHERE android_is_app_jank_type(jank_type) = TRUE ) GROUP BY process_name ORDER BY SUM(dur) DESC;
ในตัวอย่างที่ซับซ้อนขึ้นนี้ ให้รวมข้อมูลการติดตามที่ครอบคลุมหลายตารางเพื่อระบุการแย่งชิง MessageQueue ระหว่างการเริ่มต้นแอป
INCLUDE PERFETTO MODULE android.monitor_contention; INCLUDE PERFETTO MODULE android.startup.startups; -- Join package and process information for startups DROP VIEW IF EXISTS startups; CREATE VIEW startups AS SELECT startup_id, ts, dur, upid FROM android_startups JOIN android_startup_processes USING(startup_id); -- Intersect monitor contention with startups in the same process. DROP TABLE IF EXISTS monitor_contention_during_startup; CREATE VIRTUAL TABLE monitor_contention_during_startup USING SPAN_JOIN(android_monitor_contention PARTITIONED upid, startups PARTITIONED upid); SELECT process_name, SUM(dur) / 1000000 AS sum_dur_ms, COUNT(*) AS count_contention FROM monitor_contention_during_startup WHERE is_blocked_thread_main AND short_blocked_method LIKE "%MessageQueue%" GROUP BY process_name ORDER BY SUM(dur) DESC;
คุณใช้ LLM ที่ชื่นชอบเพื่อเขียนการค้นหา PerfettoSQL เพื่อค้นหารูปแบบอื่นๆ ได้
ที่ Google เราใช้ BigTrace เพื่อเรียกใช้การค้นหา PerfettoSQL ในการติดตามหลายล้านรายการ การดำเนินการดังกล่าวช่วยยืนยันว่าสิ่งที่เราเห็นเป็นเพียงเรื่องเล่าที่แท้จริงแล้วเป็นปัญหาในระบบ ข้อมูลแสดงให้เห็นว่าMessageQueueการแย่งชิงล็อกส่งผลกระทบต่อผู้ใช้ทั่วทั้งระบบนิเวศ ซึ่งเป็นการยืนยันถึงความจำเป็นในการเปลี่ยนแปลงสถาปัตยกรรมพื้นฐาน
โซลูชัน: การทำงานพร้อมกันแบบไม่ล็อก
เราได้แก้ไขปัญหาMessageQueueการแย่งชิงทรัพยากรโดยการใช้โครงสร้างข้อมูลแบบไม่ต้องล็อก โดยใช้การดำเนินการหน่วยความจำแบบอะตอมแทนการล็อกเฉพาะเพื่อซิงค์การเข้าถึงสถานะที่แชร์ โครงสร้างข้อมูลหรืออัลกอริทึมจะไม่มีการล็อกหากมีเธรดอย่างน้อย 1 รายการที่สามารถดำเนินการต่อได้เสมอ ไม่ว่าลักษณะการจัดกำหนดการของเธรดอื่นๆ จะเป็นอย่างไรก็ตาม โดยทั่วไปแล้วพร็อพเพอร์ตี้นี้ทำได้ยาก และมักจะไม่คุ้มค่าที่จะทำสำหรับโค้ดส่วนใหญ่
องค์ประกอบพื้นฐาน
ซอฟต์แวร์ที่ไม่มีการล็อกมักจะใช้การดำเนินการแบบอะตอมมิก Read-Modify-Write ที่ฮาร์ดแวร์มีให้
ใน CPU ARM64 รุ่นเก่ากว่านั้น Atomics จะใช้ลูป Load-Link/Store-Conditional (LL/SC) CPU จะโหลดค่าและทำเครื่องหมายที่อยู่ หากเธรดอื่นเขียนไปยังที่อยู่นั้น การจัดเก็บจะล้มเหลวและลูปจะลองอีกครั้ง เนื่องจากเทรดสามารถลองต่อไปและสำเร็จได้โดยไม่ต้องรอเทรดอื่น การดำเนินการนี้จึงไม่มีการล็อก
ARM64 LL/SC loop example
retry:
ldxr x0, [x1] // Load exclusive from address x1 to x0
add x0, x0, #1 // Increment value by 1
stxr w2, x0, [x1] // Store exclusive.
// w2 gets 0 on success, 1 on failure
cbnz w2, retry // If w2 is non-zero (failed), branch to retrสถาปัตยกรรม ARM รุ่นใหม่ (ARMv8.1) รองรับส่วนขยายระบบขนาดใหญ่ (LSE) ซึ่งรวมถึงคำสั่งในรูปแบบของ Compare-And-Swap (CAS) หรือ Load-And-Add (แสดงด้านล่าง) ใน Android 17 เราได้เพิ่มการรองรับคอมไพเลอร์ Android Runtime (ART) เพื่อตรวจหาเมื่อมีการรองรับ LSE และส่งคำสั่งที่เพิ่มประสิทธิภาพแล้ว
/ ARMv8.1 LSE atomic example
ldadd x0, x1, [x2] // Atomic load-add.
// Faster, no loop required.ในการทดสอบของเรา โค้ดที่มีการแย่งชิงสูงซึ่งใช้ CAS จะเร็วกว่าตัวแปร LL/SC ประมาณ 3 เท่า
ภาษาโปรแกรม Java มีองค์ประกอบพื้นฐานแบบอะตอมผ่าน java.util.concurrent.atomic ซึ่งอาศัยคำสั่ง CPU เหล่านี้และคำสั่งอื่นๆ ที่เฉพาะเจาะจง
โครงสร้างข้อมูล: DeliQueue
วิศวกรของเราได้ออกแบบโครงสร้างข้อมูลใหม่ที่เรียกว่า DeliQueue เพื่อลดการแย่งชิงล็อกจาก MessageQueue DeliQueue แยกMessageการแทรกออกจากMessageการประมวลผล ดังนี้
- รายการ
Messages(สแต็ก Treiber): สแต็กที่ไม่มีการล็อก เธรดใดๆ ก็สามารถส่งMessagesใหม่ที่นี่ได้โดยไม่มีการแย่งชิง - คิวลำดับความสำคัญ (Min-heap): Heap ของ
Messagesที่จะจัดการ ซึ่งเป็นของเธรด Looper โดยเฉพาะ (จึงไม่จำเป็นต้องมีการซิงค์หรือล็อกเพื่อเข้าถึง)
Enqueue: pushing to a Treiber stack
รายการของ Messages จะอยู่ในสแต็ก Treiber [1] ซึ่งเป็นสแต็กแบบไม่ล็อกที่ใช้ลูป CAS เพื่ออัปเดตพอยน์เตอร์ส่วนหัว
public class TreiberStack <E> {
AtomicReference<Node<E>> top =
new AtomicReference<Node<E>>();
public void push(E item) {
Node<E> newHead = new Node<E>(item);
Node<E> oldHead;
do {
oldHead = top.get();
newHead.next = oldHead;
} while (!top.compareAndSet(oldHead, newHead));
}
public E pop() {
Node<E> oldHead;
Node<E> newHead;
do {
oldHead = top.get();
if (oldHead == null) return null;
newHead = oldHead.next;
} while (!top.compareAndSet(oldHead, newHead));
return oldHead.item;
}
}ซอร์สโค้ดที่อิงตาม Java Concurrency in Practice [2] พร้อมใช้งานทางออนไลน์และเผยแพร่ต่อสาธารณะ
โปรดิวเซอร์ทุกคนสามารถส่งMessageใหม่ๆ ไปยังสแต็กได้ทุกเมื่อ ซึ่งก็เหมือนกับการดึงบัตรคิวที่เคาน์เตอร์ขายอาหารสำเร็จรูป โดยหมายเลขของคุณจะกำหนดตามเวลาที่คุณมาถึง แต่ลำดับที่คุณได้รับอาหารไม่จำเป็นต้องตรงกัน เนื่องจากเป็นสแต็กที่ลิงก์กัน Message ทุกรายการจึงเป็นสแต็กย่อย คุณจะดูคิว Message ได้ทุกเมื่อโดยการติดตามส่วนหัวและวนซ้ำไปข้างหน้า คุณจะไม่เห็น Message ใหม่ๆ ที่พุชขึ้นไปด้านบน แม้ว่าจะมีการเพิ่มในระหว่างการข้ามผ่านก็ตาม
Dequeue: โอนไปยังกองขั้นต่ำทีละหลายรายการ
หากต้องการค้นหา Message ถัดไปที่จะจัดการ Looper จะประมวลผล Message ใหม่จากสแต็ก Treiber โดยการเดินสแต็กจากด้านบนและทำซ้ำจนกว่าจะพบ Message สุดท้ายที่ประมวลผลก่อนหน้านี้ ขณะที่ Looper เดินทางลงไปในสแต็ก ระบบจะแทรก Message ลงในมินฮีปที่เรียงตามกำหนดเวลา เนื่องจาก Looper เป็นเจ้าของฮีปแต่เพียงผู้เดียว จึงสามารถจัดลำดับและประมวลผล Message โดยไม่ต้องใช้การล็อกหรือการดำเนินการแบบอะตอม

เมื่อเดินลงไปในสแต็ก Looper จะสร้างลิงก์จาก Message ที่ซ้อนกันกลับไปยังรายการก่อนหน้า ซึ่งจะทำให้เกิดรายการที่ลิงก์สองครั้ง การสร้างรายการที่ลิงก์นั้นปลอดภัยเนื่องจากลิงก์ที่ชี้ลงในสแต็กจะได้รับการเพิ่มผ่านอัลกอริทึมสแต็ก Treiber ด้วย CAS และลิงก์ที่ชี้ขึ้นในสแต็กจะได้รับการอ่านและแก้ไขโดยเธรด Looper เท่านั้น จากนั้นจะใช้ลิงก์ย้อนกลับเหล่านี้เพื่อนำ Message ออกจากจุดใดก็ได้ในสแต็กในเวลา O(1)
การออกแบบนี้ช่วยให้การแทรกข้อมูลสำหรับผู้ผลิต(เธรดที่โพสต์งานไปยังคิว) เป็น O (1) และการประมวลผลสำหรับผู้บริโภค(Looper) เป็น O (log N)
การใช้กองแบบมินฮีปเพื่อจัดลำดับ Message ยังช่วยแก้ไขข้อบกพร่องพื้นฐานใน MessageQueue รุ่นเดิม ซึ่งมีการเก็บ Message ไว้ในรายการที่ลิงก์เดียว (อยู่ที่ด้านบน) ในการใช้งานเดิม การนำออกจากส่วนหัวมีค่าเป็น O(1) แต่การแทรกมีค่าในกรณีที่แย่ที่สุดเป็น O(N) ซึ่งปรับขนาดได้ไม่ดีสำหรับคิวที่โอเวอร์โหลด ในทางกลับกัน การแทรกและการนำออกจากกองข้อมูลขั้นต่ำจะปรับขนาดแบบลอการิทึม ซึ่งให้ประสิทธิภาพเฉลี่ยที่แข่งขันได้ แต่จะโดดเด่นอย่างแท้จริงในส่วนของเวลาในการตอบสนองที่หาง
เดิม (ล็อก) MessageQueue | DeliQueue | |
| แทรก | O(N) | O(1) สำหรับการเรียกใช้ Thread O(logN) สำหรับ |
| นำออกจากส่วนหัว | O(1) | O(logN) |
ในการใช้งานคิวแบบเดิม ผู้ผลิตและผู้บริโภคใช้การล็อกเพื่อประสานงานการเข้าถึงแบบพิเศษไปยังรายการที่ลิงก์เดียวพื้นฐาน ใน DeliQueue สแต็ก Treiber จะจัดการการเข้าถึงพร้อมกัน และผู้ใช้รายเดียวจะจัดการการจัดลำดับคิวงาน
การนำออก: ความสอดคล้องผ่านการฝัง
DeliQueue เป็นโครงสร้างข้อมูลแบบไฮบริดที่รวมสแต็ก Treiber แบบไม่มีการล็อกเข้ากับกองขั้นต่ำแบบเธรดเดียว การซิงค์โครงสร้างทั้ง 2 นี้โดยไม่มีการล็อกส่วนกลางถือเป็นความท้าทายที่ไม่เหมือนใคร เนื่องจากข้อความอาจอยู่ในสแต็กจริง แต่ถูกนำออกจากคิวโดยตรรกะ
DeliQueue ใช้เทคนิคที่เรียกว่า "การฝัง" เพื่อแก้ปัญหานี้ โดยแต่ละ Message จะติดตามตำแหน่งของตัวเองในสแต็กผ่านตัวชี้แบบย้อนกลับและไปข้างหน้า ดัชนีในอาร์เรย์ของฮีป และค่าสถานะบูลีนที่ระบุว่ามีการนำออกหรือไม่ เมื่อ Message พร้อมที่จะเรียกใช้ เธรด Looper จะ CAS แฟล็กที่นำออก จากนั้นนำออกจากฮีปและสแต็ก
เมื่อเธรดอื่นต้องการนำ Message ออก ระบบจะไม่นำออกจากโครงสร้างข้อมูลทันที แต่จะทำตามขั้นตอนต่อไปนี้แทน
- การนำออกเชิงตรรกะ: เธรดใช้ CAS เพื่อตั้งค่าแฟล็กการนำออกของ
Messageจากเท็จเป็นจริงโดยอัตโนมัติMessageจะยังคงอยู่ในโครงสร้างข้อมูลเพื่อเป็นหลักฐานว่ามีการนำออกที่รอดำเนินการ ซึ่งเรียกว่า "เครื่องหมายหลุมศพ" เมื่อมีการแจ้งว่าให้นำMessageออก DeliQueue จะถือว่าMessageนั้นไม่มีอยู่ในคิวอีกต่อไปเมื่อใดก็ตามที่พบ - การล้างข้อมูลที่เลื่อนออกไป: การนำออกจากโครงสร้างข้อมูลจริงเป็นหน้าที่ของ
Looperเธรด และจะเลื่อนออกไปจนกว่าจะถึงเวลา แทนที่จะแก้ไขสแต็กหรือฮีป เธรดการนำออกจะเพิ่มMessageลงในสแต็กรายการอิสระแบบไม่มีการล็อกอีกรายการหนึ่ง - การนำออกเชิงโครงสร้าง: มีเพียง
Looperเท่านั้นที่โต้ตอบกับฮีปหรือนำองค์ประกอบออกจากสแต็กได้ เมื่อตื่นขึ้นมา ระบบจะล้างรายการอิสระและประมวลผลMessageที่มีอยู่ จากนั้นระบบจะยกเลิกการลิงก์Messageแต่ละรายการออกจากสแต็กและนำออกจากฮีป
วิธีนี้จะทำให้การจัดการฮีปทั้งหมดเป็นแบบ Single-Thread ซึ่งจะช่วยลดจำนวนการดำเนินการพร้อมกันและอุปสรรคด้านหน่วยความจำที่จำเป็น ทำให้เส้นทางวิกฤตเร็วขึ้นและง่ายขึ้น
การข้าม: การแข่งขันด้านข้อมูลในโมเดลหน่วยความจำ Java ที่ไม่เป็นอันตราย
API การทำงานพร้อมกันส่วนใหญ่ เช่น Future ในไลบรารีมาตรฐานของ Java หรือ Job และ Deferred ของ Kotlin มีกลไกในการยกเลิกงานก่อนที่จะเสร็จสมบูรณ์ อินสแตนซ์ของคลาสเหล่านี้อย่างใดอย่างหนึ่งจะตรงกับหน่วยของงานพื้นฐานแบบ 1:1 และการเรียกใช้ cancel ในออบเจ็กต์จะยกเลิกการดำเนินการที่เฉพาะเจาะจงซึ่งเชื่อมโยงกับออบเจ็กต์นั้น
อุปกรณ์ Android ในปัจจุบันมี CPU แบบหลายคอร์และมีการระบบจัดการหน่วยความจำที่ไม่ใช้แล้วแบบรุ่นต่อรุ่นพร้อมกัน แต่เมื่อเริ่มพัฒนา Android นั้น การจัดสรรออบเจ็กต์ 1 รายการสำหรับหน่วยงานแต่ละหน่วยมีค่าใช้จ่ายสูงเกินไป ดังนั้น Android จึงHandlerรองรับการยกเลิกผ่านการโอเวอร์โหลดหลายรายการของ removeMessages แทนที่จะนำ Messageที่เฉพาะเจาะจงออก ระบบจะนำ Message ทั้งหมดที่ตรงกับเกณฑ์ที่ระบุออก ในทางปฏิบัติ คุณต้องวนซ้ำผ่าน Messageทั้งหมดที่แทรกก่อนเรียกใช้ removeMessages และนำรายการที่ตรงกันออก
เมื่อวนซ้ำไปข้างหน้า เธรดจะต้องการการดำเนินการแบบอะตอมิกที่เรียงลำดับเพียงรายการเดียวเพื่ออ่านส่วนหัวปัจจุบันของสแต็ก หลังจากนั้น ระบบจะใช้การอ่านฟิลด์ปกติเพื่อค้นหา Message รายการถัดไป หากเธรด Looper แก้ไขฟิลด์ next ขณะนำ Message ออก การเขียนของ Looper และการอ่านของเธรดอื่นจะไม่ได้ซิงค์กัน ซึ่งถือเป็นการแข่งขันด้านข้อมูล โดยปกติแล้ว การแข่งขันของข้อมูลเป็นข้อบกพร่องร้ายแรงที่อาจทำให้เกิดปัญหาใหญ่ในแอป เช่น การรั่วไหล ลูปที่ไม่มีที่สิ้นสุด การขัดข้อง การหยุดทำงาน และอื่นๆ อย่างไรก็ตาม ภายใต้เงื่อนไขที่จำกัดบางประการ การแข่งขันของข้อมูลอาจไม่เป็นอันตรายภายในโมเดลหน่วยความจำของ Java สมมติว่าเราเริ่มต้นด้วยกองซ้อนของ

เราจะอ่านส่วนหัวแบบอะตอมและเห็น A พอยน์เตอร์ถัดไปของ A ชี้ไปที่ B ในขณะที่เราประมวลผล B ตัววนซ้ำอาจนำ B และ C ออกโดยอัปเดต A ให้ชี้ไปที่ C แล้วจึงชี้ไปที่ D

แม้ว่าระบบจะนำ B และ C ออกตามตรรกะ แต่ B ยังคงมีตัวชี้ถัดไปไปยัง C และ C ไปยัง D เธรดการอ่านจะยังคงเคลื่อนที่ผ่านโหนดที่แยกออกและถูกนำออกไป และในที่สุดก็จะกลับเข้าร่วมสแต็กที่ใช้งานจริงที่ D
การออกแบบ DeliQueue ให้จัดการการแข่งขันระหว่างการข้ามและการนำออกช่วยให้เราสามารถทำซ้ำได้อย่างปลอดภัยโดยไม่ต้องล็อก
การออก: Native refcount
Looper ได้รับการสนับสนุนโดยการจัดสรรเนทีฟที่ต้องปล่อยด้วยตนเองเมื่อ Looper ออก หากเธรดอื่นกำลังเพิ่ม Message ขณะที่ Looper กำลังออก ก็อาจใช้การจัดสรรดั้งเดิมหลังจากที่ระบบปล่อยแล้ว ซึ่งเป็นการละเมิดความปลอดภัยของหน่วยความจำ เราป้องกันปัญหานี้โดยใช้ tagged refcount ซึ่งใช้บิตหนึ่งของอะตอมเพื่อระบุว่า Looper กำลังจะออกหรือไม่
ก่อนใช้การจัดสรรดั้งเดิม เธรดจะอ่านการอ้างอิงแบบอะตอม หากตั้งค่าบิตการออก ระบบจะแสดงว่า Looper กำลังออกและต้องไม่ใช้การจัดสรรดั้งเดิม หากไม่เป็นเช่นนั้น ระบบจะพยายามใช้ CAS เพื่อเพิ่มจำนวนเธรดที่ใช้งานอยู่โดยใช้การจัดสรรดั้งเดิม หลังจากดำเนินการตามที่จำเป็นแล้ว ฟังก์ชันจะลดจำนวนลง หากตั้งค่าบิตการออกหลังจากเพิ่มค่าแต่ก่อนที่จะลดค่า และตอนนี้ค่าเป็น 0 แล้ว ระบบจะปลุกเธรด Looper
เมื่อเธรด Looper พร้อมที่จะออกแล้ว เธรดจะใช้ CAS เพื่อตั้งค่าบิตการออกในอะตอม หาก refcount เป็น 0 ก็จะดำเนินการจัดสรรหน่วยความจำดั้งเดิมได้ ไม่เช่นนั้นก็จะหยุดทำงานโดยรู้ว่าระบบจะเรียกให้ทำงานอีกครั้งเมื่อผู้ใช้คนสุดท้ายของการจัดสรรดั้งเดิมลดจำนวนการอ้างอิง แนวทางนี้หมายความว่าLooperเทรดจะรอความคืบหน้าของเทรดอื่นๆ แต่เฉพาะเมื่อจะออกเท่านั้น ซึ่งจะเกิดขึ้นเพียงครั้งเดียวและไม่ส่งผลต่อประสิทธิภาพ และจะทำให้โค้ดอื่นๆ ที่ใช้การจัดสรรเนทีฟไม่ต้องล็อกอย่างสมบูรณ์

นอกจากนี้ ยังมีกลเม็ดและความซับซ้อนอื่นๆ อีกมากมายในการใช้งาน ดูข้อมูลเพิ่มเติมเกี่ยวกับ DeliQueue ได้โดยตรวจสอบซอร์สโค้ด
การเพิ่มประสิทธิภาพ: การเขียนโปรแกรมแบบไม่มีกิ่งก้าน
ในระหว่างการพัฒนาและทดสอบ DeliQueue ทีมได้ทำการทดสอบประสิทธิภาพหลายครั้งและสร้างโปรไฟล์โค้ดใหม่อย่างละเอียด ปัญหาอย่างหนึ่งที่ระบุโดยใช้เครื่องมือ simpleperf คือการล้างข้อมูลไปป์ไลน์ที่เกิดจากโค้ดตัวเปรียบเทียบ Message
ตัวเปรียบเทียบมาตรฐานใช้การข้ามแบบมีเงื่อนไข โดยมีเงื่อนไขในการตัดสินว่า Message ใดมาก่อนดังนี้
static int compareMessages(@NonNull Message m1, @NonNull Message m2) {
if (m1 == m2) {
return 0;
}
// Primary queue order is by when.
// Messages with an earlier when should come first in the queue.
final long whenDiff = m1.when - m2.when;
if (whenDiff > 0) return 1;
if (whenDiff < 0) return -1;
// Secondary queue order is by insert sequence.
// If two messages were inserted with the same `when`, the one inserted
// first should come first in the queue.
final long insertSeqDiff = m1.insertSeq - m2.insertSeq;
if (insertSeqDiff > 0) return 1;
if (insertSeqDiff < 0) return -1;
return 0;
}โค้ดนี้จะคอมไพล์เป็นการข้ามแบบมีเงื่อนไข (คำสั่ง b.le และ cbnz) เมื่อ CPU พบการแยกสาขาแบบมีเงื่อนไข CPU จะไม่ทราบว่ามีการแยกสาขาหรือไม่จนกว่าจะมีการคำนวณเงื่อนไข จึงไม่ทราบว่าจะอ่านคำสั่งใดต่อไปและต้องคาดเดาโดยใช้เทคนิคที่เรียกว่าการคาดคะเนการแยกสาขา ในกรณีเช่นการค้นหาแบบไบนารี ทิศทางของกิ่งก้านจะแตกต่างกันอย่างคาดเดาไม่ได้ในแต่ละขั้นตอน ดังนั้นจึงมีแนวโน้มที่การคาดคะเนครึ่งหนึ่งจะผิด การคาดการณ์กิ่งมักจะไม่มีประสิทธิภาพในอัลกอริทึมการค้นหาและการจัดเรียง (เช่น อัลกอริทึมที่ใช้ในกองแบบมิน) เนื่องจากต้นทุนของการคาดการณ์ที่ผิดนั้นสูงกว่าการปรับปรุงจากการคาดการณ์ที่ถูกต้อง เมื่อตัวคาดการณ์กิ่งก้านคาดการณ์ผิด จะต้องทิ้งงานที่ทำหลังจากสมมติค่าที่คาดการณ์ไว้ และเริ่มใหม่จากเส้นทางที่ใช้จริง ซึ่งเรียกว่าการล้างไปป์ไลน์
ในการค้นหาปัญหานี้ เราได้สร้างโปรไฟล์การทดสอบประสิทธิภาพโดยใช้ตัวนับประสิทธิภาพ branch-misses ซึ่งบันทึก Stack Trace ที่ตัวคาดการณ์กิ่งก้านคาดการณ์ผิด จากนั้นเราได้แสดงผลลัพธ์ด้วย Google pprof ดังที่แสดงด้านล่าง
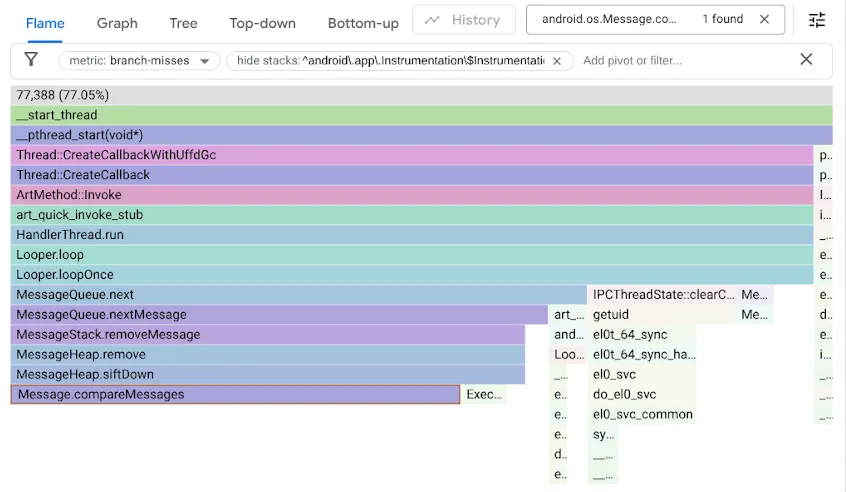
โปรดจำไว้ว่าโค้ด MessageQueue เดิมใช้รายการที่ลิงก์เดียวสำหรับคิวที่เรียงลำดับ การแทรกจะข้ามรายการตามลำดับที่จัดเรียงเป็นการค้นหาเชิงเส้น โดยหยุดที่องค์ประกอบแรกที่อยู่หลังจุดแทรกและลิงก์ Message ใหม่ไว้ข้างหน้า การนำออกจากส่วนหัวเพียงแค่ต้องยกเลิกการลิงก์ส่วนหัว ในขณะที่ DeliQueue ใช้กองแบบมิน ซึ่งการเปลี่ยนแปลงต้องมีการจัดเรียงองค์ประกอบบางอย่างใหม่ (การกรองขึ้นหรือลง) โดยมีความซับซ้อนแบบลอการิทึมในโครงสร้างข้อมูลที่สมดุล ซึ่งการเปรียบเทียบใดๆ ก็มีโอกาสเท่ากันที่จะนำการข้ามไปยังองค์ประกอบย่อยทางซ้ายหรือองค์ประกอบย่อยทางขวา อัลกอริทึมใหม่นี้เร็วกว่าแบบเดิม แต่ก็ทำให้เกิดคอขวดใหม่เนื่องจากรหัสค้นหาจะหยุดทำงานเมื่อมีการข้ามกิ่งครึ่งหนึ่งของเวลา
เราตระหนักว่าการคาดการณ์กิ่งก้านที่ไม่ถูกต้องทำให้โค้ดฮีปทำงานช้าลง จึงเพิ่มประสิทธิภาพโค้ดโดยใช้การเขียนโปรแกรมแบบไม่มีกิ่งก้าน
// Branchless Logic
static int compareMessages(@NonNull Message m1, @NonNull Message m2) {
final long when1 = m1.when;
final long when2 = m2.when;
final long insertSeq1 = m1.insertSeq;
final long insertSeq2 = m2.insertSeq;
// signum returns the sign (-1, 0, 1) of the argument,
// and is implemented as pure arithmetic:
// ((num >> 63) | (-num >>> 63))
final int whenSign = Long.signum(when1 - when2);
final int insertSeqSign = Long.signum(insertSeq1 - insertSeq2);
// whenSign takes precedence over insertSeqSign,
// so the formula below is such that insertSeqSign only matters
// as a tie-breaker if whenSign is 0.
return whenSign * 2 + insertSeqSign;
}หากต้องการทำความเข้าใจการเพิ่มประสิทธิภาพ ให้แยกตัวอย่างทั้ง 2 รายการใน Compiler Explorer และใช้ LLVM-MCA ซึ่งเป็นโปรแกรมจำลอง CPU ที่สร้างไทม์ไลน์รอบ CPU โดยประมาณได้
The original code: Index 01234567890123 [0,0] DeER . . . sub x0, x2, x3 [0,1] D=eER. . . cmp x0, #0 [0,2] D==eER . . cset w0, ne [0,3] .D==eER . . cneg w0, w0, lt [0,4] .D===eER . . cmp w0, #0 [0,5] .D====eER . . b.le #12 [0,6] . DeE---R . . mov w1, #1 [0,7] . DeE---R . . b #48 [0,8] . D==eE-R . . tbz w0, #31, #12 [0,9] . DeE--R . . mov w1, #-1 [0,10] . DeE--R . . b #36 [0,11] . D=eE-R . . sub x0, x4, x5 [0,12] . D=eER . . cmp x0, #0 [0,13] . D==eER. . cset w0, ne [0,14] . D===eER . cneg w0, w0, lt [0,15] . D===eER . cmp w0, #0 [0,16] . D====eER. csetm w1, lt [0,17] . D===eE-R. cmp w0, #0 [0,18] . .D===eER. csinc w1, w1, wzr, le [0,19] . .D====eER mov x0, x1 [0,20] . .DeE----R ret
โปรดสังเกตสาขาแบบมีเงื่อนไข b.le ซึ่งหลีกเลี่ยงการเปรียบเทียบฟิลด์ insertSeq หากทราบผลลัพธ์อยู่แล้วจากการเปรียบเทียบฟิลด์ when
The branchless code: Index 012345678 [0,0] DeER . . sub x0, x2, x3 [0,1] DeER . . sub x1, x4, x5 [0,2] D=eER. . cmp x0, #0 [0,3] .D=eER . cset w0, ne [0,4] .D==eER . cneg w0, w0, lt [0,5] .DeE--R . cmp x1, #0 [0,6] . DeE-R . cset w1, ne [0,7] . D=eER . cneg w1, w1, lt [0,8] . D==eeER add w0, w1, w0, lsl #1 [0,9] . DeE--R ret
ในกรณีนี้ การใช้งานแบบไม่มีการแยกสาขาจะใช้รอบและคำสั่งน้อยกว่าแม้แต่เส้นทางที่สั้นที่สุดผ่านโค้ดที่มีการแยกสาขา ซึ่งดีกว่าในทุกกรณี การติดตั้งใช้งานที่เร็วขึ้นและการกำจัดกิ่งก้านที่คาดการณ์ผิดส่งผลให้การทดสอบประสิทธิภาพบางอย่างของเราดีขึ้นถึง 5 เท่า
อย่างไรก็ตาม เทคนิคนี้อาจใช้ไม่ได้เสมอไป โดยทั่วไปแล้ว วิธีการแบบไม่แยกสาขาจำเป็นต้องทำงานที่ต้องทิ้ง และหากคาดการณ์สาขาได้เกือบตลอดเวลา งานที่เสียไปนั้นอาจทำให้โค้ดทำงานช้าลง นอกจากนี้ การนำสาขาออกมักจะทำให้เกิดการอิงตามข้อมูล CPU สมัยใหม่จะดำเนินการหลายอย่างต่อรอบ แต่จะดำเนินการตามคำสั่งไม่ได้จนกว่าอินพุตจากคำสั่งก่อนหน้าจะพร้อม ในทางตรงกันข้าม CPU สามารถคาดเดาเกี่ยวกับข้อมูลในกิ่งก้าน และทำงานล่วงหน้าได้หากคาดการณ์กิ่งก้านได้อย่างถูกต้อง
การทดสอบและการตรวจสอบ
การตรวจสอบความถูกต้องของอัลกอริทึมแบบไม่ล็อกนั้นเป็นเรื่องยากอย่างยิ่ง
นอกเหนือจากการทดสอบหน่วยมาตรฐานสำหรับการตรวจสอบอย่างต่อเนื่องในระหว่างการพัฒนาแล้ว เรายังเขียนการทดสอบความเครียดอย่างเข้มงวดเพื่อตรวจสอบตัวแปรคิวและพยายามทำให้เกิดการแข่งขันของข้อมูลหากมี ในห้องทดลอง เราสามารถเรียกใช้การทดสอบหลายล้านอินสแตนซ์บนอุปกรณ์จำลองและฮาร์ดแวร์จริง
การวัดผล Java ThreadSanitizer (JTSan) ช่วยให้เราใช้การทดสอบเดียวกันเพื่อตรวจหาการแข่งขันของข้อมูลบางอย่างในโค้ดได้ด้วย JTSan ไม่พบการแข่งขันของข้อมูลที่เป็นปัญหาใน DeliQueue แต่กลับตรวจพบข้อบกพร่องด้านการทำงานพร้อมกัน 2 รายการในเฟรมเวิร์ก Robolectric ซึ่งเราได้แก้ไขอย่างรวดเร็ว
เราได้สร้างเครื่องมือวิเคราะห์ใหม่เพื่อปรับปรุงความสามารถในการแก้ไขข้อบกพร่อง ด้านล่างนี้คือตัวอย่างที่แสดงปัญหาในโค้ดแพลตฟอร์ม Android ซึ่งมีเธรดหนึ่งโอเวอร์โหลดเธรดอื่นด้วย Message ทำให้เกิดงานค้างจำนวนมาก ซึ่งมองเห็นได้ใน Perfetto ด้วยฟีเจอร์การวัดประสิทธิภาพ MessageQueue ที่เราเพิ่มเข้ามา

หากต้องการเปิดใช้การติดตาม MessageQueue ในกระบวนการ system_server ให้รวมข้อมูลต่อไปนี้ในการกำหนดค่า Perfetto
data_sources {
config {
name: "track_event"
target_buffer: 0 # Change this per your buffers configuration
track_event_config {
enabled_categories: "mq"
}
}
}ผลกระทบ
DeliQueue ช่วยปรับปรุงประสิทธิภาพของระบบและแอปโดยการนำการล็อกออกจาก MessageQueue
- การทดสอบประสิทธิภาพสังเคราะห์: การแทรกแบบหลายเทรดลงในคิวที่มีการใช้งานสูงเร็วกว่า
MessageQueueรุ่นเดิมถึง 5,000 เท่า เนื่องจากมีการปรับปรุงการทำงานพร้อมกัน (สแต็ก Treiber) และการแทรกที่เร็วขึ้น (ฮีปขั้นต่ำ) - ในการติดตาม Perfetto ที่ได้จากผู้ทดสอบเบต้าภายใน เราพบว่าเวลาของเทรดหลักของแอปที่ใช้ในการแย่งชิงล็อกลดลง 15%
- ในอุปกรณ์ทดสอบเดียวกัน การลดการแย่งชิงล็อกจะช่วยปรับปรุงประสบการณ์ของผู้ใช้ได้อย่างมาก เช่น
- เฟรมที่พลาดในแอป -4%
- เฟรมที่พลาดไป 7.7% ในการโต้ตอบ UI ของระบบและ Launcher
- -9.1% ในเวลาตั้งแต่ตอนที่แอปเริ่มต้นจนถึงตอนที่วาดเฟรมแรกที่เปอร์เซ็นไทล์ที่ 95
ขั้นตอนถัดไป
DeliQueue จะเปิดตัวในแอปใน Android 17 นักพัฒนาแอปควรอ่านการเตรียมแอปสำหรับฟีเจอร์ใหม่ที่ไม่มีการล็อกMessageQueueในบล็อกของนักพัฒนาแอป Android เพื่อดูวิธีทดสอบแอป
ข้อมูลอ้างอิง
[1] Treiber, R.K., 1986 การเขียนโปรแกรมระบบ: การรับมือกับความขนาน International Business Machines Incorporated, Thomas J. ศูนย์วิจัย Watson
[2] Goetz, B., Peierls, T., Bloch, J., Bowbeer, J., Holmes, D., & Lea, D. (2006) Java Concurrency in Practice Addison-Wesley Professional
เขียนโดย
อ่านต่อ
-


ข่าวสารผลิตภัณฑ์
ในงาน Google I/O 2026 เราได้เปิดตัวการเปลี่ยนแปลงของ Android จากระบบปฏิบัติการไปเป็นระบบอัจฉริยะ นอกจากนี้ เรายังได้แสดงให้เห็นวิธีสร้างประสบการณ์อัจฉริยะในระบบโดยตรง และนำความสามารถของ AI ของ Google มาไว้ในแอปของคุณ
Jingyu Shi • ใช้เวลาอ่าน 2 นาที
-



ข่าวสารผลิตภัณฑ์
เรายินดีที่จะประกาศว่า Android XR รองรับ Unreal Engine และ Godot อย่างเป็นทางการแล้ว นอกจากนี้ เรายังเปิดตัวเครื่องมือใหม่ที่ออกแบบมาเพื่อเพิ่มประสิทธิภาพการทำงานและเปิดใช้ความสามารถใหม่ๆ ของ XR ได้แก่ Android XR Engine Hub และ Android XR Interaction Framework
Luke Hopkins, Ryan Bartley • ใช้เวลาอ่าน 4 นาที
-


ข่าวสารผลิตภัณฑ์
เมื่อเปิดตัว Android 17 เราจะเปลี่ยนไปใช้มาตรฐานการพัฒนาแบบปรับได้เป็นอันดับแรก ผู้ใช้ไม่ได้ใช้อุปกรณ์เพียงรูปแบบเดียวอีกต่อไป แต่จะสลับการใช้งานระหว่างโทรศัพท์ อุปกรณ์พับได้ แท็บเล็ต แล็ปท็อป จอแสดงผลในรถยนต์ และสภาพแวดล้อม XR ที่สมจริงตลอดทั้งวัน
Fahd Imtiaz • ใช้เวลาอ่าน 4 นาที
รับข่าวสาร
รับข้อมูลเชิงลึกด้านการพัฒนาแอป Android ล่าสุดส่งตรงถึงกล่องจดหมายของคุณทุกสัปดาห์
