


অ্যান্ড্রয়েড রানটাইম (ART) টিম কম্পাইল করা কোডের গুণমান বা মেমোরি ব্যবহারের কোনো অবনতি না ঘটিয়েই কম্পাইল টাইম ১৮% কমিয়েছে। মেমোরি ব্যবহার বা কম্পাইল করা কোডের গুণমানের সাথে আপোস না করে কম্পাইল টাইম উন্নত করার লক্ষ্যে আমাদের ২০২৫ উদ্যোগের একটি অংশ ছিল এই উন্নতি।
ART-এর জন্য কম্পাইল-টাইম স্পিড অপ্টিমাইজ করা অত্যন্ত গুরুত্বপূর্ণ। উদাহরণস্বরূপ, জাস্ট-ইন-টাইম (JIT) কম্পাইলিং অ্যাপ্লিকেশনগুলির কার্যকারিতা এবং ডিভাইসের সামগ্রিক পারফরম্যান্সকে সরাসরি প্রভাবিত করে। দ্রুততর কম্পাইলেশন অপ্টিমাইজেশনগুলি কার্যকর হওয়ার আগের সময় কমিয়ে দেয়, যার ফলে ব্যবহারকারীর অভিজ্ঞতা আরও মসৃণ এবং প্রতিক্রিয়াশীল হয়। অধিকন্তু, JIT এবং অ্যাহেড-অফ-টাইম (AOT) উভয় ক্ষেত্রেই, কম্পাইল-টাইম স্পিডের উন্নতি কম্পাইলেশন প্রক্রিয়া চলাকালীন রিসোর্স ব্যবহার কমিয়ে দেয়, যা ব্যাটারির আয়ু এবং ডিভাইসের তাপীয় অবস্থার জন্য উপকারী, বিশেষ করে কম দামি ডিভাইসগুলিতে।
এই কম্পাইল-টাইম স্পিড উন্নতিগুলোর কয়েকটি জুন ২০২৫-এর অ্যান্ড্রয়েড রিলিজে চালু করা হয়েছে এবং বাকিগুলো অ্যান্ড্রয়েডের বছর শেষের রিলিজে পাওয়া যাবে। এছাড়াও, অ্যান্ড্রয়েড ১২ এবং তার উপরের ভার্সনের সকল ব্যবহারকারী মেইনলাইন আপডেটের মাধ্যমে এই উন্নতিগুলো পাওয়ার যোগ্য।
অপ্টিমাইজিং কম্পাইলারকে অপ্টিমাইজ করা
একটি কম্পাইলারকে অপ্টিমাইজ করা সবসময়ই কিছু ছাড় দেওয়ার খেলা। আপনি এমনি এমনি গতি পেতে পারেন না; আপনাকে কিছু না কিছু ছাড়তে হবে। আমরা নিজেদের জন্য একটি খুব স্পষ্ট এবং কঠিন লক্ষ্য নির্ধারণ করেছি: কম্পাইলারকে আরও দ্রুত করা, কিন্তু তা এমনভাবে করা যাতে মেমরি রিগ্রেশন না ঘটে এবং সবচেয়ে গুরুত্বপূর্ণ হলো, এর দ্বারা উৎপাদিত কোডের গুণমান যেন নষ্ট না হয়। যদি কম্পাইলার দ্রুততর হয় কিন্তু অ্যাপগুলো ধীরগতিতে চলে, তাহলে আমরা ব্যর্থ।
এই কঠোর মানদণ্ডগুলো পূরণ করে এমন বুদ্ধিদীপ্ত সমাধান খুঁজে বের করার জন্য আমরা যে একটিমাত্র সম্পদ ব্যয় করতে ইচ্ছুক ছিলাম, তা হলো আমাদের নিজস্ব উন্নয়নমূলক সময়। চলুন, উন্নতির ক্ষেত্রগুলো খুঁজে বের করার পাশাপাশি বিভিন্ন সমস্যার সঠিক সমাধান খুঁজে পেতে আমরা কীভাবে কাজ করি, তা আরও কাছ থেকে দেখা যাক।
সার্থক সম্ভাব্য অপ্টিমাইজেশন খুঁজে বের করা
কোনো মেট্রিক অপ্টিমাইজ করা শুরু করার আগে, আপনাকে সেটি পরিমাপ করতে সক্ষম হতে হবে। অন্যথায়, আপনি এটির উন্নতি করতে পেরেছেন কি না, সে বিষয়ে কখনোই নিশ্চিত হতে পারবেন না। সৌভাগ্যবশত, কম্পাইল টাইমের গতি বেশ সামঞ্জস্যপূর্ণ থাকে, যদি আপনি কিছু সতর্কতা অবলম্বন করেন; যেমন কোনো পরিবর্তনের আগে ও পরে পরিমাপের জন্য একই ডিভাইস ব্যবহার করা এবং আপনার ডিভাইসটি যেন থার্মাল থ্রটল না করে তা নিশ্চিত করা। এর পাশাপাশি, আমাদের কাছে কম্পাইলার স্ট্যাটিস্টিকসের মতো ডিটারমিনিস্টিক পরিমাপও রয়েছে, যা আমাদের বুঝতে সাহায্য করে যে আড়ালে কী ঘটছে।
যেহেতু এই উন্নতিগুলোর জন্য আমরা আমাদের ডেভেলপমেন্টের সময় উৎসর্গ করছিলাম, তাই আমরা যত দ্রুত সম্ভব পুনরাবৃত্তি করতে চেয়েছিলাম। এর মানে হলো, আমরা সমাধানগুলোর প্রোটোটাইপ তৈরির জন্য কয়েকটি প্রতিনিধিত্বমূলক অ্যাপ (ফার্স্ট-পার্টি অ্যাপ, থার্ড-পার্টি অ্যাপ এবং স্বয়ং অ্যান্ড্রয়েড অপারেটিং সিস্টেমের মিশ্রণ) বেছে নিয়েছিলাম। পরবর্তীতে, আমরা ব্যাপকভাবে ম্যানুয়াল এবং স্বয়ংক্রিয় উভয় পরীক্ষার মাধ্যমে যাচাই করে দেখেছি যে চূড়ান্ত বাস্তবায়নটি সার্থক ছিল।
বিশেষভাবে বাছাই করা সেই এপিকে ফাইলগুলো দিয়ে আমরা স্থানীয়ভাবে ম্যানুয়ালি কম্পাইল শুরু করতাম, কম্পাইলেশনের একটি প্রোফাইল নিতাম এবং কোথায় আমাদের সময় ব্যয় হচ্ছে তা দেখার জন্য পিপিআরএফ (pprof) ব্যবহার করতাম।

pprof-এ একটি প্রোফাইলের ফ্লেম গ্রাফের উদাহরণ
pprof টুলটি খুবই শক্তিশালী এবং এটি আমাদেরকে ডেটা স্লাইস, ফিল্টার এবং সর্ট করার সুযোগ দেয়, যার মাধ্যমে আমরা দেখতে পারি যে, উদাহরণস্বরূপ, কোন কম্পাইলার ফেজ বা মেথডগুলো সবচেয়ে বেশি সময় নিচ্ছে। আমরা pprof সম্পর্কে বিস্তারিত আলোচনা করব না; শুধু এটুকু জেনে রাখুন যে, যদি বারটি বড় হয়, তার মানে হলো কম্পাইলেশনে বেশি সময় লেগেছে।
এই ভিউগুলোর মধ্যে একটি হলো “বটম আপ” ভিউ, যার মাধ্যমে আপনি দেখতে পারেন কোন মেথডগুলো সবচেয়ে বেশি সময় নিচ্ছে। নিচের ছবিতে আমরা Kill নামক একটি মেথড দেখতে পাচ্ছি, যা কম্পাইল টাইমের ১%-এরও বেশি সময় নিচ্ছে। অন্যান্য শীর্ষস্থানীয় মেথডগুলো নিয়েও এই ব্লগ পোস্টের পরবর্তী অংশে আলোচনা করা হবে।
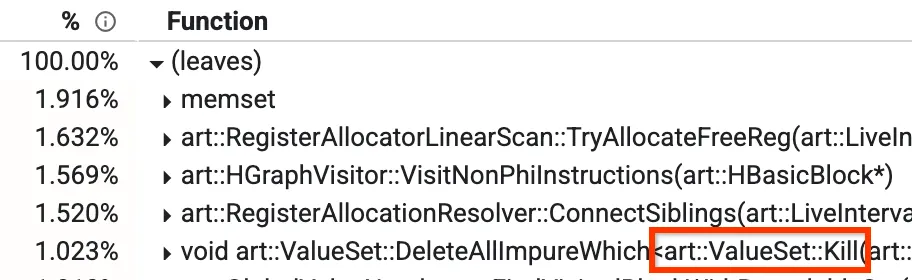
প্রোফাইলের নিচ থেকে উপরের দৃশ্য
আমাদের অপটিমাইজিং কম্পাইলারে গ্লোবাল ভ্যালু নাম্বারিং (GVN) নামে একটি পর্যায় রয়েছে। এটি সামগ্রিকভাবে কী করে তা নিয়ে আপনার চিন্তা করার দরকার নেই, তবে প্রাসঙ্গিক অংশটি হলো এটি জানা যে, এর `Kill` নামে একটি মেথড আছে যা একটি ফিল্টার অনুযায়ী কিছু নোড ডিলিট করে দেয়। এটি সময়সাপেক্ষ, কারণ এটিকে সমস্ত নোডের মধ্যে দিয়ে পুনরাবৃত্তি করতে হয় এবং এক এক করে পরীক্ষা করতে হয়। আমরা লক্ষ্য করেছি যে, এমন কিছু ক্ষেত্র আছে যেখানে আমরা আগে থেকেই জানি যে পরীক্ষাটি ভুল হবে, সেই মুহূর্তে আমাদের যতগুলো নোডই জীবিত থাকুক না কেন। এই ক্ষেত্রগুলোতে, আমরা পুনরাবৃত্তি করা পুরোপুরি বাদ দিতে পারি, যা এটিকে ১.০২৩% থেকে কমিয়ে প্রায় ০.৩%-এ নামিয়ে আনে এবং GVN-এর রানটাইম প্রায় ১৫% উন্নত করে।
সার্থক অপ্টিমাইজেশন বাস্তবায়ন করা
সময় কোথায় ব্যয় হচ্ছে তা কীভাবে পরিমাপ ও শনাক্ত করতে হয়, তা আমরা আলোচনা করেছি, কিন্তু এটি কেবল শুরু। পরবর্তী ধাপ হলো সংকলনে ব্যয়িত সময়কে কীভাবে সর্বোত্তমভাবে ব্যবহার করা যায়।
সাধারণত, উপরের 'Kill' এর মতো ক্ষেত্রে আমরা নোডগুলোর মধ্যে দিয়ে কীভাবে পুনরাবৃত্তি করি তা খতিয়ে দেখতাম এবং উদাহরণস্বরূপ, কাজগুলো সমান্তরালভাবে করে বা অ্যালগরিদমটিকেই উন্নত করে এটিকে আরও দ্রুত করার চেষ্টা করতাম। প্রকৃতপক্ষে, আমরা প্রথমে সেটাই চেষ্টা করেছিলাম এবং যখন করার মতো কিছুই খুঁজে পেলাম না, তখনই আমাদের মনে হলো, “এক মিনিট দাঁড়াও…” এবং আমরা দেখলাম যে সমাধানটি ছিল (কিছু ক্ষেত্রে) একেবারেই পুনরাবৃত্তি না করা! এই ধরনের অপ্টিমাইজেশন করার সময়, ছোটখাটো বিষয় নিয়ে ব্যস্ত থাকায় মূল বিষয়টি সহজেই চোখ এড়িয়ে যেতে পারে।
অন্যান্য ক্ষেত্রে, আমরা কয়েকটি ভিন্ন কৌশল ব্যবহার করেছি, যার মধ্যে অন্তর্ভুক্ত ছিল:
- কোনো অপ্টিমাইজেশন উল্লেখযোগ্য ফলাফল দিতে ব্যর্থ হবে কিনা এবং সেই কারণে তা বাদ দেওয়া যেতে পারে কিনা, তা নির্ধারণ করতে হিউরিস্টিকস ব্যবহার করা।
- গণনাকৃত ডেটা ক্যাশ করার জন্য অতিরিক্ত ডেটা স্ট্রাকচার ব্যবহার করা
- গতি বাড়ানোর জন্য বর্তমান ডেটা কাঠামো পরিবর্তন করা
- কিছু ক্ষেত্রে চক্র এড়াতে অলসভাবে ফলাফল গণনা করা
- সঠিক অ্যাবস্ট্রাকশন ব্যবহার করুন - অপ্রয়োজনীয় ফিচার কোডের গতি কমিয়ে দিতে পারে।
- অনেক লোডের মধ্য দিয়ে ঘন ঘন ব্যবহৃত একটি পয়েন্টারকে অনুসরণ করা এড়িয়ে চলুন
আমরা কীভাবে জানব যে এই অপ্টিমাইজেশনগুলো অনুসরণ করার যোগ্য কিনা?
মজার ব্যাপার হলো, আপনি পারেন না। কোনো একটি অংশ অনেক বেশি কম্পাইল টাইম নিচ্ছে এটা শনাক্ত করার পর এবং সেটিকে উন্নত করার জন্য ডেভেলপমেন্টে সময় দেওয়ার পরেও, কখনও কখনও আপনি কোনো সমাধান খুঁজে পান না। হয়তো কিছুই করার নেই, এটি বাস্তবায়ন করতে অনেক বেশি সময় লাগবে, এটি অন্য কোনো মেট্রিককে উল্লেখযোগ্যভাবে খারাপ করে দেবে, কোডবেসের জটিলতা বাড়িয়ে দেবে, ইত্যাদি। এই ব্লগ পোস্টে আপনি প্রতিটি সফল অপটিমাইজেশনের জন্য যা দেখতে পাচ্ছেন, জেনে রাখুন যে আরও অগণিত অপটিমাইজেশন রয়েছে যা সফলই হয়নি।
আপনি যদি একই রকম পরিস্থিতিতে থাকেন, তাহলে যতটা সম্ভব কম কাজ করে মেট্রিকটি কতটা উন্নত করতে পারবেন তা অনুমান করার চেষ্টা করুন। এর মানে হলো, ক্রমানুসারে:
- আপনার ইতিমধ্যে সংগৃহীত মেট্রিক্সের সাহায্যে অনুমান করা, অথবা কেবল একটি স্বজ্ঞা।
- দ্রুত ও অপরিশোধিত প্রোটোটাইপ দিয়ে অনুমান করা
- একটি সমাধান বাস্তবায়ন করুন।
আপনার সমাধানের সম্ভাব্য অসুবিধাগুলো অনুমান করার বিষয়টি বিবেচনা করতে ভুলবেন না। উদাহরণস্বরূপ, আপনি যদি অতিরিক্ত ডেটা স্ট্রাকচারের উপর নির্ভর করতে যান, তাহলে আপনি কী পরিমাণ মেমরি ব্যবহার করতে ইচ্ছুক?
আরও গভীরে ডুব দেওয়া
আর দেরি না করে, চলুন আমাদের বাস্তবায়িত কিছু পরিবর্তন দেখে নেওয়া যাক।
আমরা FindReferenceInfoOf নামক একটি মেথডকে অপ্টিমাইজ করার জন্য একটি পরিবর্তন প্রয়োগ করেছি। এই মেথডটি একটি এন্ট্রি খুঁজে বের করার জন্য একটি ভেক্টরে লিনিয়ার সার্চ করত। আমরা সেই ডেটা স্ট্রাকচারটিকে ইনস্ট্রাকশনের আইডি দ্বারা ইনডেক্স করার জন্য আপডেট করেছি, যাতে FindReferenceInfoOf O(n)-এর পরিবর্তে O(1) হয়। এছাড়াও, রিসাইজ এড়ানোর জন্য আমরা ভেক্টরটি প্রি-অ্যালোকেট করেছি। আমাদের একটি অতিরিক্ত ফিল্ড যোগ করতে হয়েছিল যা ভেক্টরে কতগুলো এন্ট্রি ঢোকানো হয়েছে তা গণনা করত, যার ফলে মেমরি সামান্য বৃদ্ধি পেয়েছে, কিন্তু এটি একটি ছোট ত্যাগ ছিল কারণ সর্বোচ্চ মেমরি ব্যবহার বাড়েনি। এটি আমাদের LoadStoreAnalysis পর্যায়কে ৩৪-৬৬% দ্রুততর করেছে, যা ফলস্বরূপ কম্পাইল টাইমে প্রায় ০.৫-১.৮% উন্নতি এনেছে।
আমাদের হ্যাশসেটের একটি নিজস্ব ইমপ্লিমেন্টেশন আছে যা আমরা বিভিন্ন জায়গায় ব্যবহার করি। এই ডেটা স্ট্রাকচারটি তৈরি করতে বেশ অনেকটা সময় লাগছিল এবং আমরা এর কারণ খুঁজে পেয়েছি। অনেক বছর আগে, এই ডেটা স্ট্রাকচারটি শুধুমাত্র এমন কিছু জায়গায় ব্যবহৃত হতো যেখানে খুব বড় হ্যাশসেট ব্যবহার করা হতো এবং সেটির জন্য এটিকে অপ্টিমাইজ করতে কিছু পরিবর্তন করা হয়েছিল। কিন্তু আজকাল, এটি বিপরীতভাবে ব্যবহৃত হচ্ছিল, যেখানে মাত্র কয়েকটি এন্ট্রি থাকত এবং এর জীবনকালও ছিল সংক্ষিপ্ত। এর মানে হলো, এই বিশাল হ্যাশসেটটি তৈরি করে আমরা সাইকেল নষ্ট করছিলাম, কারণ আমরা এটিকে বাতিল করার আগে মাত্র কয়েকটি এন্ট্রির জন্যই ব্যবহার করতাম। এই পরিবর্তনের ফলে, আমরা কম্পাইল টাইম প্রায় ১.৩-২% উন্নত করেছি। বাড়তি সুবিধা হিসেবে, মেমোরি ব্যবহারও প্রায় ০.৫-১% কমেছে, কারণ আমরা আগের মতো বড় ডেটা স্ট্রাকচার ব্যবহার করছিলাম না।
ডেটা স্ট্রাকচারগুলোকে বারবার কপি করার ঝামেলা এড়াতে, ল্যাম্বডাতে রেফারেন্স হিসেবে পাস করার মাধ্যমে আমরা কম্পাইল টাইম প্রায় ০.৫-১% উন্নত করেছি। এটি এমন একটি বিষয় ছিল যা মূল পর্যালোচনায় বাদ পড়ে গিয়েছিল এবং বছরের পর বছর ধরে আমাদের কোডবেসে রয়ে গিয়েছিল। pprof-এর প্রোফাইলগুলো খতিয়ে দেখার ফলেই আমরা লক্ষ্য করি যে এই মেথডগুলো প্রচুর ডেটা স্ট্রাকচার তৈরি এবং ধ্বংস করছিল, যা আমাদের এগুলো নিয়ে তদন্ত করতে এবং অপ্টিমাইজ করতে উৎসাহিত করে।
আমরা কম্পিউটেড ভ্যালুগুলো ক্যাশ করার মাধ্যমে কম্পাইল করা আউটপুট লেখার পর্যায়টির গতি বাড়িয়েছিলাম, যার ফলে মোট কম্পাইল টাইমে প্রায় ১.৩-২.৮% উন্নতি হয়েছিল। দুর্ভাগ্যবশত, এই অতিরিক্ত হিসাব রাখার কাজটি খুব বেশি হয়ে গিয়েছিল এবং আমাদের স্বয়ংক্রিয় টেস্টিং মেমরি রিগ্রেশনের বিষয়ে সতর্ক করে দেয়। পরে, আমরা একই কোডটি আবার খতিয়ে দেখি এবং একটি নতুন সংস্করণ তৈরি করি, যা শুধু মেমরি রিগ্রেশনেরই সমাধান করেনি, বরং কম্পাইল টাইমকে আরও প্রায় ০.৫-১.৮% উন্নত করেছে! এই দ্বিতীয় পরিবর্তনে, দুটি ডেটা স্ট্রাকচারের মধ্যে একটিকে বাদ দেওয়ার জন্য আমাদের এই পর্যায়টি কীভাবে কাজ করবে তা রিফ্যাক্টর এবং নতুন করে ভাবতে হয়েছিল।
আমাদের অপটিমাইজিং কম্পাইলারে একটি পর্যায় রয়েছে যা আরও ভালো পারফরম্যান্স পাওয়ার জন্য ফাংশন কলগুলোকে ইনলাইন করে। কোন মেথডগুলো ইনলাইন করা হবে তা বেছে নেওয়ার জন্য, আমরা যেকোনো গণনা করার আগে হিউরিস্টিকস (heuristics) এবং কাজ শেষ হওয়ার পর কিন্তু ইনলাইনিং চূড়ান্ত করার ঠিক আগে চূড়ান্ত যাচাই—উভয়ই ব্যবহার করি। যদি এর কোনোটি শনাক্ত করে যে ইনলাইনিং করাটা লাভজনক নয় (উদাহরণস্বরূপ, অনেক বেশি নতুন ইনস্ট্রাকশন যুক্ত হবে), তাহলে আমরা সেই মেথড কলটি ইনলাইন করি না।
যেকোনো সময়সাপেক্ষ গণনা করার আগে, একটি ইনলাইনিং সফল হবে কি না তা অনুমান করার জন্য আমরা দুটি চেককে “চূড়ান্ত যাচাই” বিভাগ থেকে “হিউরিস্টিক” বিভাগে স্থানান্তর করেছি। যেহেতু এটি একটি অনুমান, তাই এটি নিখুঁত নয়, কিন্তু আমরা যাচাই করে দেখেছি যে আমাদের নতুন হিউরিস্টিকগুলো পারফরম্যান্সকে প্রভাবিত না করেই পূর্বে যা ইনলাইন করা হতো তার ৯৯.৯% কভার করে। এই নতুন হিউরিস্টিকগুলোর মধ্যে একটি ছিল প্রয়োজনীয় DEX রেজিস্টার সম্পর্কিত (~০.২-১.৩% উন্নতি), এবং অন্যটি ছিল ইনস্ট্রাকশনের সংখ্যা সম্পর্কিত (~২% উন্নতি)।
আমাদের BitVector-এর একটি নিজস্ব ইমপ্লিমেন্টেশন আছে যা আমরা বিভিন্ন জায়গায় ব্যবহার করি। নির্দিষ্ট কিছু ফিক্সড-সাইজ বিট ভেক্টরের জন্য আমরা রিসাইজযোগ্য BitVector ক্লাসটিকে একটি সরল BitVectorView দিয়ে প্রতিস্থাপন করেছি। এর ফলে কিছু ইনডিরেকশন ও রান-টাইম রেঞ্জ চেকের প্রয়োজন কমে যায় এবং বিট ভেক্টর অবজেক্ট তৈরির গতি বাড়ে।
এছাড়াও, BitVectorView ক্লাসটিকে অন্তর্নিহিত স্টোরেজ টাইপের উপর ভিত্তি করে টেমপ্লেটাইজ করা হয়েছে (পুরানো BitVector-এর মতো সর্বদা uint32_t ব্যবহার করার পরিবর্তে)। এটি কিছু অপারেশনকে, উদাহরণস্বরূপ Union(), ৬৪-বিট প্ল্যাটফর্মে দ্বিগুণ সংখ্যক বিট একসাথে প্রসেস করার সুযোগ দেয়। অ্যান্ড্রয়েড ওএস কম্পাইল করার সময় প্রভাবিত ফাংশনগুলির স্যাম্পল মোট ১%-এর বেশি কমানো হয়েছে। এটি বেশ কয়েকটি পরিবর্তনের মাধ্যমে করা হয়েছে [ 1 , 2 , 3 , 4 , 5 , 6 ]
সমস্ত অপ্টিমাইজেশন নিয়ে বিস্তারিত আলোচনা করতে গেলে আমাদের সারাদিন লেগে যাবে! আপনি যদি আরও কিছু অপ্টিমাইজেশন সম্পর্কে জানতে আগ্রহী হন, তবে আমাদের করা অন্যান্য পরিবর্তনগুলো দেখে নিন:
- হিসাবরক্ষণ যোগ করলে সংকলনের সময় প্রায় ০.৬-১.৬% উন্নত হয়।
- সম্ভব হলে, পুনরাবৃত্তি এড়াতে ডেটা অলস পদ্ধতিতে গণনা করুন ।
- আমাদের কোড রিফ্যাক্টর করুন যাতে অপ্রয়োজনীয় প্রি-কম্পিউটিং কাজ বাদ দেওয়া হয়।
- যখন অ্যালোকেটরটি অন্য জায়গা থেকে সহজেই পাওয়া যায়, তখন কিছু নির্ভরশীল লোড চেইন এড়িয়ে চলুন ।
- অপ্রয়োজনীয় কাজ এড়ানোর জন্য চেক যুক্ত করার আরেকটি উদাহরণ।
- রেজিস্টার অ্যালোকেটরে রেজিস্টারের ধরন (কোর/এফপি) অনুযায়ী ঘন ঘন ব্রাঞ্চিং পরিহার করুন ।
- নিশ্চিত করুন যেন কিছু অ্যারে কম্পাইল টাইমে ইনিশিয়ালাইজ করা হয় । এই কাজটি করার জন্য ক্ল্যাং-এর উপর নির্ভর করবেন না।
- কিছু লুপ পরিপাটি করুন । রেঞ্জ লুপ ব্যবহার করুন যা ক্ল্যাং আরও ভালোভাবে অপ্টিমাইজ করতে পারে, কারণ লুপের সাইড এফেক্টের জন্য কন্টেইনারের অভ্যন্তরীণ পয়েন্টারগুলো পুনরায় লোড করার প্রয়োজন হয় না। প্রতিটি ইনপুটের জন্য ইনলাইন করা `InputAt(.)`-এর মাধ্যমে লুপের মধ্যে ভার্চুয়াল ফাংশন `HInstruction::GetInputRecords()` কল করা থেকে বিরত থাকুন।
- একটি কম্পাইলার অপটিমাইজেশন কাজে লাগিয়ে ভিজিটর প্যাটার্নের জন্য Accept() ফাংশন পরিহার করুন ।
উপসংহার
ART-এর কম্পাইল-টাইম গতি উন্নত করার প্রতি আমাদের নিষ্ঠা উল্লেখযোগ্য উন্নতি এনেছে, যা অ্যান্ড্রয়েডকে আরও সাবলীল ও কার্যকর করার পাশাপাশি ব্যাটারির আয়ু এবং ডিভাইসের তাপীয় অবস্থা উন্নত করতেও অবদান রাখে। যত্নসহকারে অপটিমাইজেশন শনাক্ত ও প্রয়োগ করার মাধ্যমে আমরা দেখিয়েছি যে, মেমোরি ব্যবহার বা কোডের মানের সাথে আপোস না করেই কম্পাইল-টাইমে যথেষ্ট উন্নতি করা সম্ভব।
আমাদের এই যাত্রাপথে pprof-এর মতো টুল ব্যবহার করে প্রোফাইলিং, বারবার চেষ্টা করার মানসিকতা এবং কখনও কখনও কম ফলপ্রসূ পথ পরিত্যাগ করার মতো বিষয়গুলোও অন্তর্ভুক্ত ছিল। ART টিমের সম্মিলিত প্রচেষ্টা শুধু যে কম্পাইল টাইম উল্লেখযোগ্য পরিমাণে কমিয়েছে তাই নয়, বরং ভবিষ্যৎ অগ্রগতির ভিত্তিও স্থাপন করেছে।
এই সমস্ত উন্নতি ২০২৫ সালের শেষ প্রান্তিকের অ্যান্ড্রয়েড আপডেটে এবং অ্যান্ড্রয়েড ১২ ও তার পরবর্তী সংস্করণগুলোর জন্য মূল আপডেটের মাধ্যমে পাওয়া যাবে। আমরা আশা করি, আমাদের অপটিমাইজেশন প্রক্রিয়ার এই বিশদ বিশ্লেষণ কম্পাইলার ইঞ্জিনিয়ারিংয়ের জটিলতা ও সুফল সম্পর্কে মূল্যবান অন্তর্দৃষ্টি প্রদান করবে!

 পণ্যের খবর
পণ্যের খবরগত মার্চ মাসে, আমরা অ্যান্ড্রয়েড বেঞ্চ চালু করেছিলাম—বাস্তব অ্যান্ড্রয়েড ডেভেলপমেন্ট টাস্কের জন্য আমাদের এলএলএম লিডারবোর্ড। তারপর থেকে, আমরা আপনাদের মতামতের ভিত্তিতে বেঞ্চমার্কটিকে আরও উন্নত করেছি, যার মধ্যে ওপেন-ওয়েট মডেল মূল্যায়ন এবং লিডারবোর্ডে খরচ ও দক্ষতার মাত্রা যোগ করা অন্তর্ভুক্ত।
Zoe Lopez-Latorre • 3 মিনিট পড়া
 পণ্যের খবর
পণ্যের খবরগুগল প্লে-তে আমরা ব্যবহারকারীদের সর্বোত্তম অভিজ্ঞতা প্রদানে প্রতিশ্রুতিবদ্ধ, এবং একই সাথে ডেভেলপারদের সফল হওয়ার জন্য প্রয়োজনীয় সরঞ্জাম ও অভিযোজন ক্ষমতা নিশ্চিত করি।
Paul Feng • পড়তে ৩ মিনিট
 পণ্যের খবর
পণ্যের খবরগত বছর, আমরা ইকোসিস্টেমের নিরাপত্তা জোরদার করতে এবং অসাধু চক্রকে বেনামির আড়ালে থেকে ক্ষতিকারক অ্যাপ প্রকাশ করা থেকে বিরত রাখতে অ্যান্ড্রয়েড ডেভেলপার ভেরিফিকেশন চালু করেছি।
Matthew Forsythe • পড়তে ২ মিনিট
অ্যান্ড্রয়েড ডেভেলপমেন্টের সর্বশেষ তথ্য প্রতি সপ্তাহে আপনার ইনবক্সে পান।
