


Das Android Runtime (ART)-Team hat die Kompilierungszeit um 18% verkürzt, ohne den kompilierten Code oder Spitzenwerte des Arbeitsspeichers zu beeinträchtigen. Diese Verbesserung war Teil unserer Initiative für 2025, die Kompilierungszeit zu verkürzen, ohne die Arbeitsspeichernutzung oder die Qualität des kompilierten Codes zu beeinträchtigen.
Die Optimierung der Kompilierungsgeschwindigkeit ist für ART von entscheidender Bedeutung. Wenn beispielsweise eine Just-in-Time-Kompilierung (JIT) erfolgt, wirkt sich das direkt auf die Effizienz von Anwendungen und die Gesamtleistung des Geräts aus. Schnellere Kompilierungen verkürzen die Zeit, bis die Optimierungen wirksam werden, was zu einer flüssigeren und reaktionsschnelleren Nutzererfahrung führt. Außerdem führt eine höhere Kompilierungsgeschwindigkeit sowohl bei JIT als auch bei AOT zu einem geringeren Ressourcenverbrauch während des Kompilierungsprozesses, was sich positiv auf die Akkulaufzeit und die Wärmeentwicklung des Geräts auswirkt, insbesondere bei Geräten der unteren Preisklasse.
Einige dieser Verbesserungen der Kompilierungsgeschwindigkeit wurden im Juni 2025 in Android eingeführt. Die restlichen Verbesserungen werden in der Android-Version zum Jahresende verfügbar sein. Außerdem können alle Android-Nutzer mit Version 12 und höher diese Verbesserungen über Mainline-Updates erhalten.
Optimierungs-Compiler optimieren
Die Optimierung eines Compilers ist immer ein Abwägen von Kompromissen. Geschwindigkeit gibt es nicht kostenlos. Sie müssen etwas dafür aufgeben. Wir haben uns ein sehr klares und anspruchsvolles Ziel gesetzt: den Compiler schneller zu machen, ohne dass es zu Speicherregressionen kommt und vor allem ohne die Qualität des generierten Codes zu beeinträchtigen. Wenn der Compiler schneller ist, die Apps aber langsamer ausgeführt werden, haben wir unser Ziel nicht erreicht.
Die einzige Ressource, die wir bereit waren zu investieren, war unsere eigene Entwicklungszeit, um uns intensiv mit dem Thema zu beschäftigen, es zu untersuchen und clevere Lösungen zu finden, die diesen strengen Kriterien entsprechen. Sehen wir uns genauer an, wie wir Bereiche für Verbesserungen finden und die richtigen Lösungen für die verschiedenen Probleme ermitteln.
Lohnende mögliche Optimierungen finden
Bevor Sie einen Messwert optimieren können, müssen Sie ihn messen können. Andernfalls können Sie nie sicher sein, ob Sie es verbessert haben oder nicht. Glücklicherweise ist die Kompilierungszeit relativ konstant, solange Sie einige Vorsichtsmaßnahmen treffen, z. B. dass Sie vor und nach einer Änderung dasselbe Gerät verwenden und darauf achten, dass Ihr Gerät nicht durch Überhitzung gedrosselt wird. Außerdem haben wir deterministische Messungen wie Compilerstatistiken, die uns helfen, die Vorgänge im Hintergrund zu verstehen.
Da wir für diese Verbesserungen Entwicklungszeit opfern mussten, wollten wir so schnell wie möglich iterieren. Wir haben uns also eine Handvoll repräsentativer Apps (eine Mischung aus eigenen Apps, Drittanbieter-Apps und dem Android-Betriebssystem selbst) geschnappt, um Lösungen zu entwickeln. Später haben wir durch manuelle und automatisierte Tests umfassend überprüft, ob sich die endgültige Implementierung gelohnt hat.
Mit dieser Auswahl an APKs haben wir lokal eine manuelle Kompilierung ausgelöst, ein Profil der Kompilierung erstellt und mit pprof visualisiert, wo wir unsere Zeit verbringen.
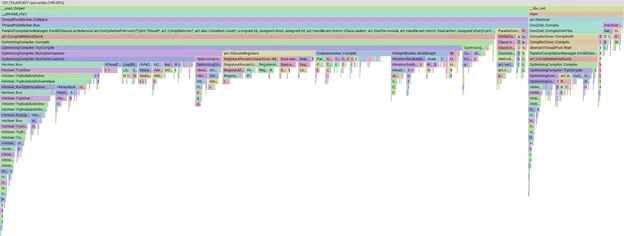
Beispiel für das Flame-Diagramm eines Profils in pprof
Das pprof-Tool ist sehr leistungsstark und ermöglicht es uns, die Daten zu segmentieren, zu filtern und zu sortieren, um beispielsweise zu sehen, welche Compilerphasen oder Methoden am meisten Zeit in Anspruch nehmen. Wir werden nicht ins Detail gehen, was pprof ist. Sie müssen nur wissen, dass ein größerer Balken bedeutet, dass die Kompilierung mehr Zeit in Anspruch genommen hat.
Eine dieser Ansichten ist die „Bottom-up“-Ansicht, in der Sie sehen können, welche Methoden am meisten Zeit in Anspruch nehmen. Im Bild unten sehen wir eine Methode namens „Kill“, die über 1% der Kompilierungszeit ausmacht. Einige der anderen Top-Methoden werden später im Blogpost ebenfalls behandelt.

Profilansicht von unten nach oben
In unserem optimierenden Compiler gibt es eine Phase namens „Global Value Numbering“ (GVN). Sie müssen sich keine Gedanken darüber machen, was es als Ganzes tut. Wichtig ist nur, dass es eine Methode namens „Kill“ hat, mit der einige Knoten gemäß einem Filter gelöscht werden. Das ist zeitaufwendig, da alle Knoten durchlaufen und einzeln geprüft werden müssen. Wir haben festgestellt, dass es einige Fälle gibt, in denen wir im Voraus wissen, dass die Prüfung falsch sein wird, unabhängig davon, welche Knoten zu diesem Zeitpunkt aktiv sind. In diesen Fällen können wir die Iteration ganz überspringen, wodurch die Anzahl der Iterationen von 1,023% auf etwa 0,3% sinkt und die Laufzeit von GVN um etwa 15 % verkürzt wird.
Sinnvolle Optimierungen implementieren
Wir haben uns angesehen, wie Sie messen und erkennen können, wo die Zeit verbracht wird. Das ist aber erst der Anfang. Im nächsten Schritt geht es darum, wie Sie die für die Kompilierung benötigte Zeit optimieren können.
Normalerweise würden wir in einem Fall wie dem oben genannten `Kill` untersuchen, wie wir die Knoten durchlaufen, und den Prozess beschleunigen, indem wir beispielsweise Dinge parallel ausführen oder den Algorithmus selbst verbessern. Tatsächlich haben wir das zuerst versucht. Erst als wir nichts mehr tun konnten, hatten wir einen „Moment mal…“-Moment und stellten fest, dass die Lösung darin bestand, (in einigen Fällen) überhaupt nicht zu iterieren. Bei solchen Optimierungen kann es leicht passieren, dass man den Wald vor lauter Bäumen nicht mehr sieht.
In anderen Fällen haben wir verschiedene Techniken verwendet, darunter:
- Heuristiken verwenden, um zu entscheiden, ob eine Optimierung keine lohnenden Ergebnisse liefert und daher übersprungen werden kann
- Zusätzliche Datenstrukturen zum Zwischenspeichern berechneter Daten verwenden
- die aktuellen Datenstrukturen ändern, um die Geschwindigkeit zu erhöhen
- Ergebnisse werden verzögert berechnet, um in einigen Fällen Zyklen zu vermeiden.
- die richtige Abstraktion verwenden – unnötige Funktionen können den Code verlangsamen
- Vermeiden Sie es, einen häufig verwendeten Zeiger durch viele Ladevorgänge zu verfolgen.
Woher wissen wir, ob sich die Optimierungen lohnen?
Das ist das Schöne daran: Sie müssen es nicht. Wenn Sie feststellen, dass ein Bereich viel Kompilierzeit in Anspruch nimmt, und Sie Entwicklungszeit darauf verwenden, ihn zu optimieren, finden Sie manchmal einfach keine Lösung. Vielleicht gibt es nichts zu tun, die Implementierung dauert zu lange, ein anderer Messwert wird dadurch deutlich schlechter, die Codebasis wird komplexer usw. Für jede erfolgreiche Optimierung, die Sie in diesem Blogpost sehen, gibt es unzählige andere, die einfach nicht zustande gekommen sind.
Wenn Sie sich in einer ähnlichen Situation befinden, versuchen Sie, den Messwert mit möglichst wenig Aufwand zu verbessern. Das bedeutet in der Reihenfolge:
- Schätzungen auf Grundlage von Messwerten, die Sie bereits erfasst haben, oder einfach nur auf Grundlage eines Bauchgefühls
- Schätzung mit einem einfachen Prototyp
- Implementieren Sie eine Lösung.
Vergessen Sie nicht, die Nachteile Ihrer Lösung zu berücksichtigen. Wenn Sie beispielsweise zusätzliche Datenstrukturen verwenden möchten, wie viel Arbeitsspeicher sind Sie bereit zu nutzen?
Weitere Informationen
Sehen wir uns einige der Änderungen an, die wir vorgenommen haben.
Wir haben eine Änderung zur Optimierung der Methode „FindReferenceInfoOf“ vorgenommen. Bei dieser Methode wurde ein Vektor linear durchsucht, um einen Eintrag zu finden. Wir haben die Datenstruktur so aktualisiert, dass sie nach der ID der Anleitung indexiert wird. Dadurch ist FindReferenceInfoOf O(1) statt O(n). Außerdem haben wir den Vektor vorab zugewiesen, um eine Größenänderung zu vermeiden. Wir haben den Arbeitsspeicher leicht erhöht, da wir ein zusätzliches Feld hinzufügen mussten, das zählte, wie viele Einträge wir in den Vektor eingefügt haben. Das war jedoch ein geringes Opfer, da der maximale Arbeitsspeicher nicht gestiegen ist. Dadurch wurde die Phase „LoadStoreAnalysis“ um 34–66% beschleunigt, was zu einer Verbesserung der Kompilierungszeit von etwa 0,5–1,8% führt.
Wir haben eine benutzerdefinierte Implementierung von HashSet, die wir an mehreren Stellen verwenden. Das Erstellen dieser Datenstruktur hat viel Zeit in Anspruch genommen. Wir haben herausgefunden, warum. Vor vielen Jahren wurde diese Datenstruktur nur an wenigen Stellen verwendet, an denen sehr große HashSets zum Einsatz kamen. Sie wurde so angepasst, dass sie für diesen Zweck optimiert ist. Heutzutage wird es jedoch in die entgegengesetzte Richtung verwendet, mit nur wenigen Einträgen und einer kurzen Lebensdauer. Das bedeutete, dass wir Zyklen verschwendeten, indem wir dieses riesige HashSet erstellten, es aber nur für einige Einträge verwendeten, bevor wir es verworfen haben. Mit dieser Änderung haben wir die Kompilierungszeit um etwa 1, 3 bis 2% verkürzt. Außerdem sank die Speichernutzung um etwa 0,5 bis 1 %, da wir nicht mehr so große Datenstrukturen verwendeten.
Wir haben die Kompilierungszeit um etwa 0,5 bis 1% verbessert, indem wir Datenstrukturen per Referenz an das Lambda übergeben haben, um das Kopieren zu vermeiden. Das wurde bei der ursprünglichen Überprüfung übersehen und war jahrelang in unserem Code vorhanden. Erst durch die Analyse der Profile in pprof haben wir bemerkt, dass diese Methoden viele Datenstrukturen erstellen und wieder löschen. Deshalb haben wir sie genauer untersucht und optimiert.
Wir haben die Phase, in der die kompilierte Ausgabe geschrieben wird, durch Zwischenspeichern berechneter Werte beschleunigt. Das hat zu einer Verbesserung der gesamten Kompilierungszeit von etwa 1,3 bis 2,8% geführt. Leider war der zusätzliche Aufwand zu hoch und unsere automatisierten Tests haben uns auf die Speicherregression aufmerksam gemacht. Später haben wir uns denselben Code noch einmal angesehen und eine neue Version implementiert, die nicht nur die Speicherregression behoben, sondern auch die Kompilierungszeit um weitere 0,5–1,8 % verbessert hat. Bei dieser zweiten Änderung mussten wir die Funktionsweise dieser Phase neu gestalten, um eine der beiden Datenstrukturen zu entfernen.
Unser optimierender Compiler hat eine Phase, in der Funktionsaufrufe inline eingefügt werden, um die Leistung zu verbessern. Um auszuwählen, welche Methoden inline eingefügt werden sollen, verwenden wir sowohl Heuristiken, bevor wir Berechnungen durchführen, als auch endgültige Prüfungen, nachdem wir die Arbeit erledigt haben, aber kurz bevor wir das Inlining abschließen. Wenn eine dieser Heuristiken feststellt, dass sich das Inlining nicht lohnt (z. B. weil zu viele neue Anweisungen hinzugefügt würden), wird der Methodenaufruf nicht inline ausgeführt.
Wir haben zwei Prüfungen aus der Kategorie „Abschließende Prüfungen“ in die Kategorie „Heuristisch“ verschoben, um vor zeitaufwendigen Berechnungen schätzen zu können, ob das Inlining erfolgreich sein wird. Da es sich um eine Schätzung handelt, ist sie nicht perfekt.Wir haben jedoch überprüft, dass unsere neuen Heuristiken 99,9% der zuvor inline eingefügten Inhalte abdecken, ohne die Leistung zu beeinträchtigen. Eine dieser neuen Heuristiken betraf die erforderlichen DEX-Register (Verbesserung von ca.0,2–1,3 %) und die andere die Anzahl der Anweisungen (Verbesserung von ca.2 %).
Wir haben eine benutzerdefinierte Implementierung eines BitVector, die wir an mehreren Stellen verwenden. Wir haben die BitVector-Klasse mit variabler Größe durch eine einfachere BitVectorView-Klasse für bestimmte Bitvektoren mit fester Größe ersetzt. Dadurch werden einige Umleitungen und Laufzeitbereichsprüfungen vermieden und die Erstellung der Bitvektorobjekte beschleunigt.
Außerdem wurde die BitVectorView-Klasse für den zugrunde liegenden Speichertyp templatisiert (anstatt wie beim alten BitVector immer uint32_t zu verwenden). Dadurch können einige Vorgänge, z. B. Union(), auf 64-Bit-Plattformen doppelt so viele Bits gleichzeitig verarbeiten. Die Stichproben der betroffenen Funktionen wurden beim Kompilieren des Android-Betriebssystems um insgesamt mehr als 1% reduziert. Dies wurde in mehreren Änderungen vorgenommen [1, 2, 3, 4, 5, 6].
Wenn wir alle Optimierungen im Detail besprechen würden, wären wir den ganzen Tag beschäftigt. Wenn Sie an weiteren Optimierungen interessiert sind, sehen Sie sich einige andere Änderungen an, die wir vorgenommen haben:
- Buchhaltung hinzufügen, um die Kompilierungszeiten um etwa 0,6–1,6 % zu verkürzen.
- Daten nach Bedarf berechnen, um Zyklen zu vermeiden, sofern möglich.
- Code umgestalten, um die Vorberechnung zu überspringen, wenn sie nicht verwendet wird.
- Vermeiden Sie einige abhängige Ladeketten, wenn der Zuweisungsmechanismus problemlos an anderen Stellen abgerufen werden kann.
- Ein weiteres Beispiel für das Hinzufügen einer Prüfung, um unnötige Arbeit zu vermeiden.
- Häufige Verzweigungen für den Registriertyp (Core/FP) im Register-Allocator vermeiden.
- Achten Sie darauf, dass einige Arrays zur Kompilierzeit initialisiert werden. Verlassen Sie sich nicht auf clang.
- Einige Loops bereinigen: Verwenden Sie Bereichsschleifen, die von Clang besser optimiert werden können, da die internen Zeiger des Containers aufgrund von Schleifennebeneffekten nicht neu geladen werden müssen. Vermeiden Sie es, die virtuelle Funktion „HInstruction::GetInputRecords()“ in der Schleife über das inline eingefügte „InputAt(.)“ für jede Eingabe aufzurufen.
- Accept()-Funktionen für das Besuchermuster vermeiden: Nutzen Sie eine Compiler-Optimierung.
Fazit
Wir haben die Kompilierungsgeschwindigkeit von ART deutlich verbessert, wodurch Android flüssiger und effizienter geworden ist. Außerdem hat sich die Akkulaufzeit verbessert und die Geräte werden weniger heiß. Durch die sorgfältige Ermittlung und Implementierung von Optimierungen haben wir gezeigt, dass erhebliche Verbesserungen der Kompilierungszeit möglich sind, ohne dass der Speicherverbrauch oder die Codequalität beeinträchtigt werden.
Wir haben Tools wie pprof verwendet, waren bereit, Iterationen durchzuführen, und haben manchmal sogar weniger erfolgversprechende Ansätze aufgegeben. Durch die gemeinsamen Bemühungen des ART-Teams konnte die Kompilierungszeit nicht nur um einen bemerkenswerten Prozentsatz verkürzt werden, sondern es wurde auch die Grundlage für zukünftige Verbesserungen geschaffen.
Alle diese Verbesserungen sind im Android-Update zum Jahresende 2025 und für Android 12 und höher über Mainline-Updates verfügbar. Wir hoffen, dass dieser detaillierte Einblick in unseren Optimierungsprozess wertvolle Informationen über die Komplexität und die Vorteile der Compilerentwicklung bietet.
-

 Produktneuheiten
ProduktneuheitenIm März haben wir Android Bench eingeführt, unsere LLM-Rangliste für reale Android-Entwicklungsaufgaben. Seitdem haben wir den Benchmark auf Grundlage Ihres Feedbacks weiterentwickelt. Dazu gehört die Bewertung von Open-Weight-Modellen und das Hinzufügen von Kosten- und Effizienzdimensionen zur Bestenliste.
Zoe Lopez-Latorre • Lesezeit: 3 Minuten -

 Produktneuheiten
ProduktneuheitenBei Google Play ist es uns wichtig, Nutzern die bestmögliche Nutzerfreundlichkeit zu bieten. Gleichzeitig möchten wir dafür sorgen, dass Entwickler die notwendigen Tools und die Flexibilität haben, um erfolgreich zu sein.
Paul Feng • Lesezeit: 3 Minuten -

 Produktneuheiten
ProduktneuheitenLetztes Jahr haben wir die Entwicklerbestätigung für Android eingeführt, um die Sicherheit des Ökosystems zu erhöhen und böswillige Akteure daran zu hindern, schädliche Apps zu veröffentlichen, ohne dass ihre Identität bekannt ist.
Matthew Forsythe • 2 Minuten Lesezeit
Lassen Sie sich Woche für Woche die neuesten Informationen zur Android-Entwicklung zusenden.
