


Zespół Android Runtime (ART) skrócił czas kompilacji o 18% bez pogorszenia jakości skompilowanego kodu i bez regresji w zakresie maksymalnego wykorzystania pamięci. Ta poprawa była częścią naszej inicjatywy z 2025 r., której celem było skrócenie czasu kompilacji bez pogorszenia jakości skompilowanego kodu i bez zwiększenia zużycia pamięci.
Optymalizacja szybkości kompilacji jest kluczowa dla ART. Na przykład w przypadku kompilacji JIT (just-in-time) ma ona bezpośredni wpływ na wydajność aplikacji i ogólną wydajność urządzenia. Szybsze kompilacje skracają czas, zanim zaczną działać optymalizacje, co przekłada się na płynniejsze i bardziej responsywne działanie aplikacji. Ponadto zarówno w przypadku kompilacji JIT, jak i AOT (ahead-of-time) poprawa szybkości kompilacji przekłada się na mniejsze zużycie zasobów podczas kompilacji, co korzystnie wpływa na żywotność baterii i temperaturę urządzenia, zwłaszcza w przypadku urządzeń z niższej półki.
Niektóre z tych ulepszeń dotyczących szybkości kompilacji zostały wprowadzone w czerwcu 2025 r. w wersji Androida, a pozostałe będą dostępne w wersji Androida na koniec roku. Ponadto wszyscy użytkownicy Androida w wersji 12 i nowszej mogą korzystać z tych ulepszeń dzięki aktualizacjom mainline.
Optymalizacja kompilatora optymalizującego
Optymalizacja kompilatora to zawsze gra kompromisów. Nie można po prostu uzyskać większej szybkości bez poświęcenia czegoś innego. Postawiliśmy sobie bardzo jasny i ambitny cel: przyspieszyć kompilator, ale bez regresji w zakresie wykorzystania pamięci i, co najważniejsze, bez pogorszenia jakości generowanego kodu. Jeśli kompilator będzie szybszy, ale aplikacje będą działać wolniej, to znaczy, że nam się nie udało.
Jedynym zasobem, który byliśmy gotowi poświęcić, był nasz czas na opracowywanie rozwiązań. Chcieliśmy dokładnie zbadać problem i znaleźć sprytne rozwiązania, które spełniałyby te rygorystyczne kryteria. Przyjrzyjmy się bliżej temu, jak pracujemy nad znajdowaniem obszarów do poprawy i odpowiednich rozwiązań różnych problemów.
Znajdowanie możliwych optymalizacji
Zanim zaczniesz optymalizować dany wskaźnik, musisz mieć możliwość jego pomiaru. W przeciwnym razie nigdy nie będziesz mieć pewności, czy udało Ci się go poprawić. Na szczęście szybkość kompilacji jest dość stała, o ile zachowasz pewne środki ostrożności, takie jak używanie tego samego urządzenia do pomiarów przed i po zmianie oraz upewnienie się, że nie dochodzi do ograniczenia wydajności urządzenia z powodu przegrzania. Oprócz tego mamy też pomiary deterministyczne, takie jak statystyki kompilatora, które pomagają nam zrozumieć, co się dzieje w tle.
Ponieważ zasobem, który poświęciliśmy na te ulepszenia, był nasz czas na opracowywanie rozwiązań, chcieliśmy móc jak najszybciej wprowadzać zmiany. W tym celu wybraliśmy kilka reprezentatywnych aplikacji (mieszankę aplikacji własnych, aplikacji innych firm i samego systemu operacyjnego Android) do prototypowania rozwiązań. Później sprawdziliśmy, czy ostateczna implementacja jest tego warta, przeprowadzając ręczne i automatyczne testy na szeroką skalę.
W przypadku tego zestawu wybranych plików APK ręcznie uruchamialiśmy kompilację lokalnie, uzyskiwaliśmy profil kompilacji i używaliśmy narzędzia pprof do wizualizacji, gdzie spędzamy najwięcej czasu.

Przykład wykresu płomieniowego profilu w pprof
Narzędzie pprof jest bardzo wydajne i pozwala nam dzielić, filtrować i sortować dane, aby zobaczyć na przykład, które fazy lub metody kompilatora zajmują najwięcej czasu. Nie będziemy szczegółowo omawiać samego narzędzia pprof. Wystarczy, że wiesz, że im większy pasek, tym więcej czasu zajęła kompilacja.
Jednym z tych widoków jest widok „od dołu do góry”, w którym możesz zobaczyć, które metody zajmują najwięcej czasu. Na obrazie poniżej widzimy metodę o nazwie Kill, która zajmuje ponad 1% czasu kompilacji. Niektóre z innych najczęściej używanych metod omówimy później w tym poście.
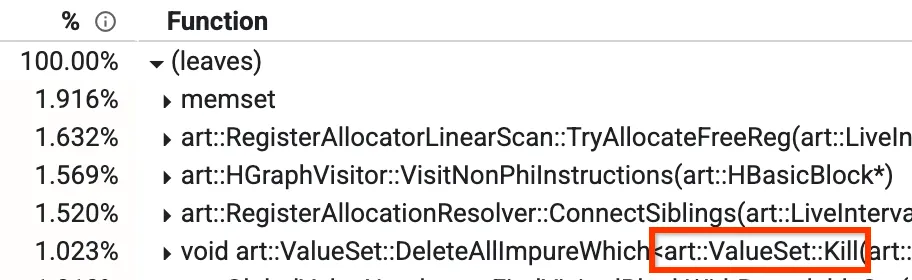
Widok profilu od dołu do góry
W naszym kompilatorze optymalizującym jest faza o nazwie Global Value Numbering (GVN). Nie musisz się martwić, co ona robi jako całość, ale istotne jest, aby wiedzieć, że ma metodę o nazwie `Kill`, która usuwa niektóre węzły zgodnie z filtrem. Jest to czasochłonne, ponieważ trzeba przejść przez wszystkie węzły i sprawdzić je jeden po drugim. Zauważyliśmy, że w niektórych przypadkach z góry wiemy, że sprawdzenie będzie fałszywe, niezależnie od tego, które węzły są w danym momencie aktywne. W takich przypadkach możemy całkowicie pominąć iterację, co zmniejsza czas kompilacji z 1,023% do ok.0,3% i poprawia czas działania GVN o ok.15%.
Wdrażanie optymalizacji
Omówiliśmy, jak mierzyć i jak wykrywać, gdzie jest spędzany czas, ale to dopiero początek. Następnym krokiem jest optymalizacja czasu spędzanego na kompilacji.
Zazwyczaj w przypadku takim jak opisany powyżej `Kill` sprawdzamy, jak iterujemy przez węzły, i przyspieszamy ten proces, na przykład przez równoległe wykonywanie działań lub ulepszanie samego algorytmu. W rzeczywistości to właśnie zrobiliśmy na początku. Dopiero gdy nie mogliśmy znaleźć niczego do zrobienia, mieliśmy moment „Zaraz, zaraz…” i zobaczyliśmy, że rozwiązaniem jest (w niektórych przypadkach) całkowite pominięcie iteracji. Podczas wykonywania tego typu optymalizacji łatwo jest nie dostrzec całości obrazu.
W innych przypadkach stosowaliśmy różne techniki, w tym:
- używanie heurystyki do określania, czy optymalizacja przyniesie wymierne korzyści, i w związku z tym można ją pominąć;
- używanie dodatkowych struktur danych do buforowania obliczonych danych;
- zmienianie bieżących struktur danych w celu zwiększenia szybkości;
- leniwe obliczanie wyników, aby w niektórych przypadkach uniknąć cykli;
- używanie odpowiedniej abstrakcji – niepotrzebne funkcje mogą spowolnić kod;
- unikanie śledzenia często używanego wskaźnika przez wiele wczytań.
Skąd wiemy, czy warto kontynuować optymalizację?
To jest najciekawsze – nie wiemy. Po wykryciu, że dany obszar zajmuje dużo czasu kompilacji, i po poświęceniu czasu na opracowywanie rozwiązań, aby go poprawić, czasami nie można po prostu znaleźć rozwiązania. Może nie ma nic do zrobienia, implementacja zajmie zbyt dużo czasu, spowoduje znaczną regresję innego wskaźnika, zwiększy złożoność bazy kodu itp. Pamiętaj, że na każdą udaną optymalizację, którą widzisz w tym poście, przypada niezliczona liczba innych, które nie przyniosły oczekiwanych rezultatów.
Jeśli jesteś w podobnej sytuacji, spróbuj oszacować, o ile poprawisz dany wskaźnik, wykonując jak najmniej pracy. Oznacza to, że w kolejności:
- oszacuj na podstawie zebranych już danych lub po prostu na podstawie intuicji;
- oszacuj na podstawie szybkiego i niedokładnego prototypu;
- wdroż rozwiązanie.
Nie zapomnij oszacować wad swojego rozwiązania. Na przykład jeśli zamierzasz korzystać z dodatkowych struktur danych, ile pamięci jesteś gotów użyć?
Szczegółowe informacje
Bez zbędnych ceregieli przyjrzyjmy się niektórym wprowadzonym przez nas zmianom.
Wprowadziliśmy zmianę, aby zoptymalizować metodę o nazwie FindReferenceInfoOf. Ta metoda wykonywała liniowe wyszukiwanie wektora w celu znalezienia wpisu. Zaktualizowaliśmy tę strukturę danych, aby była indeksowana według identyfikatora instrukcji, dzięki czemu metoda FindReferenceInfoOf będzie miała złożoność O(1) zamiast O(n). Ponadto wstępnie przydzieliliśmy wektor, aby uniknąć zmiany jego rozmiaru. Nieznacznie zwiększyliśmy ilość pamięci, ponieważ musieliśmy dodać dodatkowe pole, które zliczało liczbę wpisów wstawionych do wektora, ale było to niewielkie poświęcenie, ponieważ maksymalne wykorzystanie pamięci nie wzrosło. Dzięki temu przyspieszyliśmy fazę LoadStoreAnalysis o 34–66%, co z kolei daje ok. 0,5–1,8% poprawy czasu kompilacji.
W kilku miejscach używamy niestandardowej implementacji HashSet. Tworzenie tej struktury danych zajmowało sporo czasu i odkryliśmy dlaczego. Wiele lat temu ta struktura danych była używana tylko w kilku miejscach, w których używano bardzo dużych zbiorów HashSet, i została dostosowana do optymalizacji pod tym kątem. Obecnie jednak była używana w przeciwnym kierunku – tylko z kilkoma wpisami i krótkim czasem życia. Oznaczało to, że marnowaliśmy cykle, tworząc ten ogromny zbiór HashSet, ale używaliśmy go tylko do kilku wpisów, zanim go odrzuciliśmy. Dzięki tej zmianie poprawiliśmy czas kompilacji o ok.1, 3–2%. Dodatkowo zużycie pamięci zmniejszyło się o ok.0,5–1%, ponieważ nie używaliśmy już tak dużych struktur danych jak wcześniej.
Poprawiliśmy czas kompilacji o ok.0,5–1%, przekazując struktury danych przez odwołanie do lambdy, aby uniknąć ich kopiowania. To było coś, co zostało pominięte w pierwotnej recenzji i przez lata znajdowało się w naszej bazie kodu. Dzięki przyjrzeniu się profilom w pprof zauważyliśmy, że te metody tworzyły i niszczyły wiele struktur danych, co skłoniło nas do zbadania i zoptymalizowania ich.
Przyspieszyliśmy fazę, która zapisuje skompilowane dane wyjściowe, przez buforowanie obliczonych wartości, co przełożyło się na ok. 1,3–2,8% poprawy całkowitego czasu kompilacji. Niestety dodatkowe księgowanie było zbyt duże i nasze automatyczne testy ostrzegły nas o regresji w zakresie wykorzystania pamięci. Później ponownie przyjrzeliśmy się temu samemu kodowi i wdrożyliśmy nową wersję, która nie tylko rozwiązała problem regresji w zakresie wykorzystania pamięci, ale też dodatkowo poprawiła czas kompilacji o ok.0,5–1,8%. W tej drugiej zmianie musieliśmy przeprowadzić refaktoryzację i ponownie przemyśleć, jak ta faza powinna działać, aby pozbyć się jednej z dwóch struktur danych.
W naszym kompilatorze optymalizującym mamy fazę, która wstawia wywołania funkcji, aby uzyskać lepszą wydajność. Aby wybrać metody do wstawienia, używamy zarówno heurystyki przed wykonaniem jakichkolwiek obliczeń, jak i ostatecznych sprawdzeń po wykonaniu pracy, ale tuż przed sfinalizowaniem wstawienia. Jeśli którekolwiek z tych sprawdzeń wykryje, że wstawienie nie jest opłacalne (np. zostanie dodanych zbyt wiele nowych instrukcji), nie wstawiamy wywołania metody.
Przenieśliśmy 2 sprawdzenia z kategorii „sprawdzenia końcowe” do kategorii „heurystyka”, aby oszacować, czy wstawienie się powiedzie, zanim wykonamy jakiekolwiek czasochłonne obliczenia. Ponieważ jest to szacunek, nie jest on idealny, ale sprawdziliśmy, że nasza nowa heurystyka obejmuje 99,9% tego, co było wcześniej wstawiane, bez wpływu na wydajność. Jedna z tych nowych heurystyk dotyczyła potrzebnych rejestrów DEX (poprawa o ok.0,2–1,3%), a druga – liczby instrukcji (poprawa o ok.2%).
W kilku miejscach używamy niestandardowej implementacji BitVector. W przypadku niektórych wektorów bitowych o stałym rozmiarze zastąpiliśmy klasę BitVector z możliwością zmiany rozmiaru prostszą klasą BitVectorView. Eliminuje to niektóre pośrednie odwołania i sprawdzanie zakresu w czasie działania oraz przyspiesza tworzenie obiektów wektorów bitowych.
Ponadto klasa BitVectorView została sparametryzowana na podstawie bazowego typu pamięci (zamiast zawsze używać typu uint32_t jak w przypadku starej klasy BitVector). Dzięki temu niektóre operacje, np. Union(), mogą przetwarzać 2 razy więcej bitów jednocześnie na platformach 64-bitowych. Podczas kompilowania systemu operacyjnego Android próbki funkcji, których dotyczy problem, zostały zmniejszone o ponad 1% w sumie. Zostało to zrobione w ramach kilku zmian [1, 2, 3, 4, 5, 6]
Gdybyśmy szczegółowo omówili wszystkie optymalizacje, spędzilibyśmy tu cały dzień. Jeśli interesują Cię inne optymalizacje, zapoznaj się z innymi wprowadzonymi przez nas zmianami:
- Dodaj księgowanie, aby skrócić czas kompilacji o ok. 0,6–1,6%.
- W miarę możliwości leniwie obliczaj dane, aby uniknąć cykli.
- Przeprowadź refaktoryzację kodu, aby pominąć wstępne obliczenia, gdy nie będą używane.
- Unikaj niektórych łańcuchów wczytywania zależnych gdy alokator można łatwo uzyskać z innych miejsc.
- Kolejny przypadek dodania sprawdzenia, aby uniknąć niepotrzebnej pracy.
- Unikaj częstego rozgałęziania się na typ rejestru (core/FP) w alokatorze rejestrów.
- Upewnij się, że niektóre tablice są inicjowane w czasie kompilacji. Nie polegaj na clang.
- Wyczyść niektóre pętle. Używaj pętli zakresowych, które clang może lepiej optymalizować, ponieważ nie musi ponownie wczytywać wewnętrznych wskaźników kontenera z powodu efektów ubocznych pętli. Unikaj wywoływania funkcji wirtualnej `HInstruction::GetInputRecords()` w pętli za pomocą wstawionej funkcji `InputAt(.)` dla każdego wejścia.
- Unikaj funkcji Accept() w przypadku wzorca odwiedzającego, wykorzystując optymalizację kompilatora.
Podsumowanie
Nasze zaangażowanie w poprawę szybkości kompilacji ART przyniosło znaczące ulepszenia, dzięki czemu Android działa płynniej i wydajniej, a także przyczynia się do wydłużenia czasu pracy na baterii i zmniejszenia temperatury urządzenia. Dzięki starannemu identyfikowaniu i wdrażaniu optymalizacji pokazaliśmy, że można uzyskać znaczne oszczędności czasu kompilacji bez pogorszenia jakości kodu i bez zwiększenia zużycia pamięci.
Nasza praca obejmowała profilowanie za pomocą narzędzi takich jak pprof, gotowość do wprowadzania zmian, a czasami nawet porzucanie mniej obiecujących rozwiązań. Wspólne wysiłki zespołu ART nie tylko skróciły czas kompilacji o znaczący procent, ale też stworzyły podstawy do przyszłych ulepszeń.
Wszystkie te ulepszenia są dostępne w aktualizacji Androida na koniec 2025 r. oraz w Androidzie 12 i nowszym dzięki aktualizacjom mainline. Mamy nadzieję, że to szczegółowe omówienie naszego procesu optymalizacji dostarczy Ci cennych informacji o złożoności i korzyściach związanych z inżynierią kompilatorów.
-
 Nowości dotyczące produktów
Nowości dotyczące produktówW marcu wprowadziliśmy Android Bench – nasz ranking LLM dla rzeczywistych zadań związanych z tworzeniem aplikacji na Androida. Od tego czasu ulepszyliśmy test porównawczy na podstawie Waszych opinii, m.in. dodając ocenę modeli o otwartych wagach oraz wymiary kosztów i wydajności do rankingu.
Czas czytania: 3 min -

 Nowości dotyczące produktów
Nowości dotyczące produktówW Google Play dokładamy wszelkich starań, aby zapewnić użytkownikom jak najlepsze wrażenia, a deweloperom – narzędzia i elastyczność, które pozwolą im odnieść sukces.
Paul Feng • Czas czytania: 3 min -

 Nowości dotyczące produktów
Nowości dotyczące produktówW zeszłym roku wprowadziliśmy weryfikację deweloperów aplikacji na Androida, aby zwiększyć bezpieczeństwo ekosystemu i uniemożliwić złośliwym podmiotom ukrywanie się za anonimowością w celu publikowania szkodliwych aplikacji.
Matthew Forsythe • Czas czytania: 2 min
Otrzymuj co tydzień najnowsze informacje o tworzeniu aplikacji na Androida na swoją skrzynkę odbiorczą.
