


In Android 17, le app che hanno come target l'SDK 37 o versioni successive riceveranno una nuova implementazione di MessageQueue in cui l'implementazione è senza blocchi. La nuova implementazione migliora le prestazioni e riduce i frame mancanti, ma potrebbe interrompere i client che riflettono su campi e metodi privati di MessageQueue. Per scoprire di più sulla modifica del comportamento e su come mitigarne l'impatto, consulta la documentazione relativa alla modifica del comportamento di MessageQueue. Questo post del blog tecnico fornisce una panoramica della riarchitettura di MessageQueue e di come analizzare i problemi di contesa dei blocchi utilizzando Perfetto.
Il Looper gestisce il thread dell'interfaccia utente di ogni app per Android. Estrae il lavoro da una MessageQueue, lo invia a un Handler e ripete l'operazione. Per due decenni, MessageQueue ha utilizzato un unico blocco monitor (ovvero un blocco di codice synchronized) per proteggere il proprio stato.
Android 17 introduce un aggiornamento significativo di questo componente: un'implementazione senza blocchi denominata DeliQueue.
Questo post spiega in che modo i blocchi influiscono sulle prestazioni della UI, come analizzare questi problemi con Perfetto e gli algoritmi e le ottimizzazioni specifici utilizzati per migliorare il thread principale di Android.
Il problema: contesa di blocchi e inversione di priorità
La funzione legacy MessageQueue funzionava come una coda con priorità protetta da un unico blocco. Se un thread in background pubblica un messaggio mentre il thread principale esegue la manutenzione della coda, il thread in background blocca il thread principale.
Quando due o più thread competono per l'utilizzo esclusivo della stessa risorsa, si parla di contesa di blocco. Questo conflitto può causare un'inversione di priorità, con conseguente jank dell'interfaccia utente e altri problemi di prestazioni.
L'inversione della priorità può verificarsi quando un thread con priorità elevata (come il thread dell'interfaccia utente) viene messo in attesa di un thread con priorità bassa. Considera questa sequenza:
- Un thread in background con priorità bassa acquisisce il blocco
MessageQueueper pubblicare il risultato del lavoro svolto. - Un thread con priorità media diventa eseguibile e lo scheduler del kernel gli assegna tempo CPU, interrompendo il thread con priorità bassa.
- Il thread dell'interfaccia utente con priorità alta termina l'attività corrente e tenta di leggere dalla coda, ma viene bloccato perché il thread con priorità bassa mantiene il blocco.
Il thread a bassa priorità blocca il thread dell'interfaccia utente e il lavoro a media priorità lo ritarda ulteriormente.

Analisi della contesa con Perfetto
Puoi diagnosticare questi problemi utilizzando Perfetto. In una traccia standard, un thread bloccato su un blocco del monitor entra nello stato di sospensione e Perfetto mostra una sezione che indica il proprietario del blocco.
Quando esegui query sui dati di traccia, cerca le sezioni denominate "monitor contention with …" (monitora la contesa con…) seguite dal nome del thread proprietario del blocco e dal sito di codice in cui è stato acquisito il blocco.
Case study: Launcher jank
Per fare un esempio, analizziamo una traccia in cui un utente ha riscontrato un problema di jank durante la navigazione nella home page su uno smartphone Pixel subito dopo aver scattato una foto nell'app Fotocamera. Di seguito è riportato uno screenshot di Perfetto che mostra gli eventi che hanno portato al frame mancante:

- Sintomo: il thread principale di Launcher non ha rispettato la scadenza del frame. È stato bloccato per 18 ms, superando il limite di 16 ms richiesto per il rendering a 60 Hz.
- Diagnosi:Perfetto ha mostrato il thread principale bloccato sul blocco
MessageQueue. Un thread "BackgroundExecutor" possedeva il blocco. - Causa principale: BackgroundExecutor viene eseguito con Process.THREAD_PRIORITY_BACKGROUND (priorità molto bassa). Ha eseguito un'attività non urgente (controllo dei limiti di utilizzo delle app). Contemporaneamente, i thread a priorità media utilizzavano il tempo della CPU per elaborare i dati della videocamera. Lo scheduler del sistema operativo ha interrotto il thread BackgroundExecutor per eseguire i thread della videocamera.
Questa sequenza ha causato il blocco indiretto del thread dell'interfaccia utente di Launcher (priorità alta) da parte del thread di lavoro della fotocamera (priorità media), che impediva al thread in background di Launcher (priorità bassa) di rilasciare il blocco.
Eseguire query sulle tracce con PerfettoSQL
Puoi utilizzare PerfettoSQL per interrogare i dati di traccia per pattern specifici. Questa operazione è utile se hai un grande numero di tracce provenienti da dispositivi o test degli utenti e stai cercando tracce specifiche che dimostrino un problema.
Ad esempio, questa query trova la contesa di MessageQueue in concomitanza con i frame eliminati (jank):
INCLUDE PERFETTO MODULE android.monitor_contention; INCLUDE PERFETTO MODULE android.frames.jank_type; SELECT process_name, -- Convert duration from nanoseconds to milliseconds SUM(dur) / 1000000 AS sum_dur_ms, COUNT(*) AS count_contention FROM android_monitor_contention WHERE is_blocked_thread_main AND short_blocked_method LIKE "%MessageQueue%" -- Only look at app processes that had jank AND upid IN ( SELECT DISTINCT(upid) FROM actual_frame_timeline_slice WHERE android_is_app_jank_type(jank_type) = TRUE ) GROUP BY process_name ORDER BY SUM(dur) DESC;
In questo esempio più complesso, unisci i dati di tracciamento che si estendono su più tabelle per identificare la contesa di MessageQueue durante l'avvio dell'app:
INCLUDE PERFETTO MODULE android.monitor_contention; INCLUDE PERFETTO MODULE android.startup.startups; -- Join package and process information for startups DROP VIEW IF EXISTS startups; CREATE VIEW startups AS SELECT startup_id, ts, dur, upid FROM android_startups JOIN android_startup_processes USING(startup_id); -- Intersect monitor contention with startups in the same process. DROP TABLE IF EXISTS monitor_contention_during_startup; CREATE VIRTUAL TABLE monitor_contention_during_startup USING SPAN_JOIN(android_monitor_contention PARTITIONED upid, startups PARTITIONED upid); SELECT process_name, SUM(dur) / 1000000 AS sum_dur_ms, COUNT(*) AS count_contention FROM monitor_contention_during_startup WHERE is_blocked_thread_main AND short_blocked_method LIKE "%MessageQueue%" GROUP BY process_name ORDER BY SUM(dur) DESC;
Puoi utilizzare il tuo LLM preferito per scrivere query PerfettoSQL per trovare altri pattern.
In Google utilizziamo BigTrace per eseguire query PerfettoSQL su milioni di tracce. In questo modo, abbiamo confermato che ciò che abbiamo osservato in modo aneddotico era, di fatto, un problema sistemico. I dati hanno rivelato che MessageQueue la contesa dei blocchi influisce sugli utenti dell'intero ecosistema, confermando la necessità di una modifica architettonica fondamentale.
Soluzione: concorrenza senza blocchi
Abbiamo risolto il problema di contesa MessageQueue implementando una struttura di dati senza blocchi, utilizzando operazioni di memoria atomiche anziché blocchi esclusivi per sincronizzare l'accesso allo stato condiviso. Una struttura di dati o un algoritmo è lock-free se almeno un thread può sempre progredire indipendentemente dal comportamento di pianificazione degli altri thread. Questa proprietà è generalmente difficile da ottenere e di solito non vale la pena di perseguirla per la maggior parte del codice.
Primitive atomiche
Il software senza blocchi spesso si basa su primitive atomiche di lettura-modifica-scrittura fornite dall'hardware.
Sulle CPU ARM64 di vecchia generazione, gli atomici utilizzavano un ciclo Load-Link/Store-Conditional (LL/SC). La CPU carica un valore e contrassegna l'indirizzo. Se un altro thread scrive a questo indirizzo, l'archivio non funziona e il ciclo viene ritentato. Poiché i thread possono continuare a riprovare e riuscire senza attendere un altro thread, questa operazione è senza blocchi.
ARM64 LL/SC loop example
retry:
ldxr x0, [x1] // Load exclusive from address x1 to x0
add x0, x0, #1 // Increment value by 1
stxr w2, x0, [x1] // Store exclusive.
// w2 gets 0 on success, 1 on failure
cbnz w2, retry // If w2 is non-zero (failed), branch to retr(visualizza in Compiler Explorer)
Le architetture ARM più recenti (ARMv8.1) supportano le estensioni di sistema di grandi dimensioni (LSE), che includono istruzioni sotto forma di Compare-And-Swap (CAS) o Load-And-Add (illustrate di seguito). In Android 17 abbiamo aggiunto il supporto al compilatore Android Runtime (ART) per rilevare quando LSE è supportato ed emettere istruzioni ottimizzate:
/ ARMv8.1 LSE atomic example
ldadd x0, x1, [x2] // Atomic load-add.
// Faster, no loop required.Nei nostri benchmark, il codice con elevata contesa che utilizza CAS ottiene una velocità circa tre volte superiore rispetto alla variante LL/SC.
Il linguaggio di programmazione Java offre primitive atomiche tramite java.util.concurrent.atomic che si basano su queste e altre istruzioni CPU specializzate.
La struttura dei dati: DeliQueue
Per rimuovere la contesa di blocco da MessageQueue, i nostri ingegneri hanno progettato una nuova struttura di dati chiamata DeliQueue. DeliQueue separa l'inserimento di Message dall'elaborazione di Message:
- L'elenco di
Messages(stack Treiber): uno stack senza blocchi. Qualsiasi thread può inserire nuoviMessagesqui senza contesa. - La coda con priorità (min-heap): un heap di
Messagesda gestire, di proprietà esclusiva del thread Looper (quindi non sono necessarie sincronizzazione o blocchi per l'accesso).
Enqueue: pushing to a Treiber stack
L'elenco di Messages viene conservato in uno stack Treiber [1], uno stack senza blocchi che utilizza un ciclo CAS per aggiornare il puntatore di testa.
public class TreiberStack <E> {
AtomicReference<Node<E>> top =
new AtomicReference<Node<E>>();
public void push(E item) {
Node<E> newHead = new Node<E>(item);
Node<E> oldHead;
do {
oldHead = top.get();
newHead.next = oldHead;
} while (!top.compareAndSet(oldHead, newHead));
}
public E pop() {
Node<E> oldHead;
Node<E> newHead;
do {
oldHead = top.get();
if (oldHead == null) return null;
newHead = oldHead.next;
} while (!top.compareAndSet(oldHead, newHead));
return oldHead.item;
}
}Codice sorgente basato su Java Concurrency in Practice [2], disponibile online e rilasciato al pubblico dominio
Qualsiasi produttore può inserire nuovi Messagenello stack in qualsiasi momento. È come prendere un biglietto al banco di un negozio di alimentari: il tuo numero è determinato dal momento in cui ti presenti, ma l'ordine in cui ricevi il cibo non deve corrispondere. Poiché si tratta di uno stack collegato, ogni Message è uno stack secondario. Puoi vedere com'era la coda Message in qualsiasi momento monitorando la testa e scorrendo in avanti. Non vedrai nuovi Message inseriti in cima, anche se vengono aggiunti durante la traversata.
Dequeue: trasferimento collettivo a un min-heap
Per trovare il successivo Message da gestire, il Looper elabora i nuovi Message dallo stack Treiber scorrendo lo stack dall'alto e iterando fino a quando non trova l'ultimo Message elaborato in precedenza. Man mano che Looper attraversa lo stack, inserisce Message nel min-heap ordinato in base alla scadenza. Poiché Looper possiede esclusivamente l'heap, ordina ed elabora Message senza blocchi o atomicità.

Scendendo lungo lo stack, Looper crea anche link dagli Message impilati ai loro predecessori, formando così un elenco a doppio collegamento. La creazione dell'elenco collegato è sicura perché i link che puntano verso il basso dello stack vengono aggiunti tramite l'algoritmo dello stack Treiber con CAS, mentre i link verso l'alto dello stack vengono letti e modificati solo dal thread Looper. Questi link di ritorno vengono poi utilizzati per rimuovere Message da punti arbitrari nello stack in tempo O(1).
Questo design fornisce un inserimento O(1) per i producer (thread che pubblicano il lavoro nella coda) e un'elaborazione ammortizzata O(log N) per il consumer (il Looper).
L'utilizzo di un min-heap per ordinare le Message risolve anche un difetto fondamentale del precedente MessageQueue, in cui le Message venivano mantenute in un elenco a collegamento singolo (con radice in alto). Nell'implementazione precedente, la rimozione dalla testa era O(1), ma l'inserimento aveva uno scenario peggiore di O(N), con una scalabilità scarsa per le code sovraccariche. Al contrario, l'inserimento e la rimozione dal min-heap vengono scalati in modo logaritmico, offrendo prestazioni medie competitive, ma eccellenti in termini di latenza finale.
Legacy (bloccato) MessageQueue | DeliQueue | |
| Inserisci | O(N) | O(1) per chiamare il thread O(logN) per il thread |
| Rimuovi dalla testa | O(1) | O(logN) |
Nell'implementazione della coda precedente, i producer e il consumer utilizzavano un blocco per coordinare l'accesso esclusivo all'elenco a collegamento singolo sottostante. In DeliQueue, lo stack Treiber gestisce l'accesso simultaneo e il singolo consumer gestisce l'ordinamento della coda di lavoro.
Rimozione: coerenza tramite indicatori di eliminazione
DeliQueue è una struttura di dati ibrida che unisce uno stack Treiber senza blocchi a un min-heap a un solo thread. Mantenere sincronizzate queste due strutture senza un blocco globale presenta una sfida unica: un messaggio potrebbe essere fisicamente presente nello stack, ma rimosso logicamente dalla coda.
Per risolvere questo problema, DeliQueue utilizza una tecnica chiamata "tombstoning". Ogni Message tiene traccia della sua posizione nello stack tramite i puntatori indietro e avanti, del suo indice nell'array dell'heap e di un flag booleano che indica se è stato rimosso. Quando un Message è pronto per l'esecuzione, il thread Looper CAS il relativo flag di rimozione, quindi lo rimuove dall'heap e dallo stack.
Quando un altro thread deve rimuovere un Message, non lo estrae immediatamente dalla struttura dei dati. Esegue, invece, i seguenti passaggi:
- Rimozione logica: il thread utilizza un CAS per impostare in modo atomico il flag di rimozione di
Messageda false a true.Messagerimane nella struttura dei dati come prova della sua rimozione in attesa, una cosiddetta "lapide". Una volta contrassegnato per la rimozione, DeliQueue consideraMessagecome se non esistesse più nella coda ogni volta che viene trovato. - Pulizia posticipata: la rimozione effettiva dalla struttura dei dati è responsabilità del thread
Loopere viene posticipata. Anziché modificare lo stack o l'heap, il thread di rimozione aggiungeMessagea un altro stack freelist senza blocchi. - Rimozione strutturale: solo l'
Looperpuò interagire con l'heap o rimuovere elementi dallo stack. Quando si riattiva, cancella la lista libera ed elabora iMessageche contiene. OgniMessageviene quindi scollegato dallo stack e rimosso dall'heap.
Questo approccio mantiene tutta la gestione dell'heap single-threaded. Riduce al minimo il numero di operazioni simultanee e le barriere di memoria richieste, rendendo il percorso critico più veloce e semplice.
Attraversamento: data race benigni del modello di memoria Java
La maggior parte delle API di concorrenza, come Future nella libreria standard Java o Job e Deferred di Kotlin, include un meccanismo per annullare il lavoro prima che venga completato. Un'istanza di una di queste classi corrisponde 1:1 a un'unità di lavoro sottostante e la chiamata di cancel su un oggetto annulla le operazioni specifiche associate.
I dispositivi Android di oggi hanno CPU multi-core e garbage collection simultanea e generazionale. Tuttavia, quando è stato sviluppato Android, era troppo costoso allocare un oggetto per ogni unità di lavoro. Di conseguenza, Handler di Android supporta l'annullamento tramite numerosi overload di removeMessages. Invece di rimuovere un Message specifico, rimuove tutti i Message che corrispondono ai criteri specificati. In pratica, ciò richiede di scorrere tutti i Message inseriti prima della chiamata di removeMessages e rimuovere quelli corrispondenti.
Quando si itera in avanti, un thread richiede una sola operazione atomica ordinata per leggere la testa corrente dello stack. Dopodiché, vengono utilizzate le letture dei campi ordinari per trovare il successivo Message. Se il thread Looper modifica i campi next durante la rimozione di Message, la scrittura di Looper e la lettura di un altro thread non sono sincronizzate, il che comporta una data race. Normalmente, una competizione tra dati è un bug grave che può causare enormi problemi nella tua app: perdite, loop infiniti, arresti anomali, blocchi e altro ancora. Tuttavia, in determinate condizioni ristrette, le competizioni di dati possono essere benigne all'interno del modello di memoria Java. Supponiamo di iniziare con uno stack di:

Eseguiamo una lettura atomica dell'intestazione e vediamo A. Il puntatore successivo di A punta a B. Contemporaneamente all'elaborazione di B, il looper potrebbe rimuovere B e C aggiornando A in modo che punti a C e poi a D.

Anche se B e C vengono rimossi logicamente, B mantiene il puntatore successivo a C e C a D. Il thread di lettura continua a scorrere attraverso i nodi rimossi e alla fine si ricongiunge allo stack live in corrispondenza di D.
Progettando DeliQueue per gestire le competizioni tra attraversamento e rimozione, consentiamo un'iterazione sicura e senza blocchi.
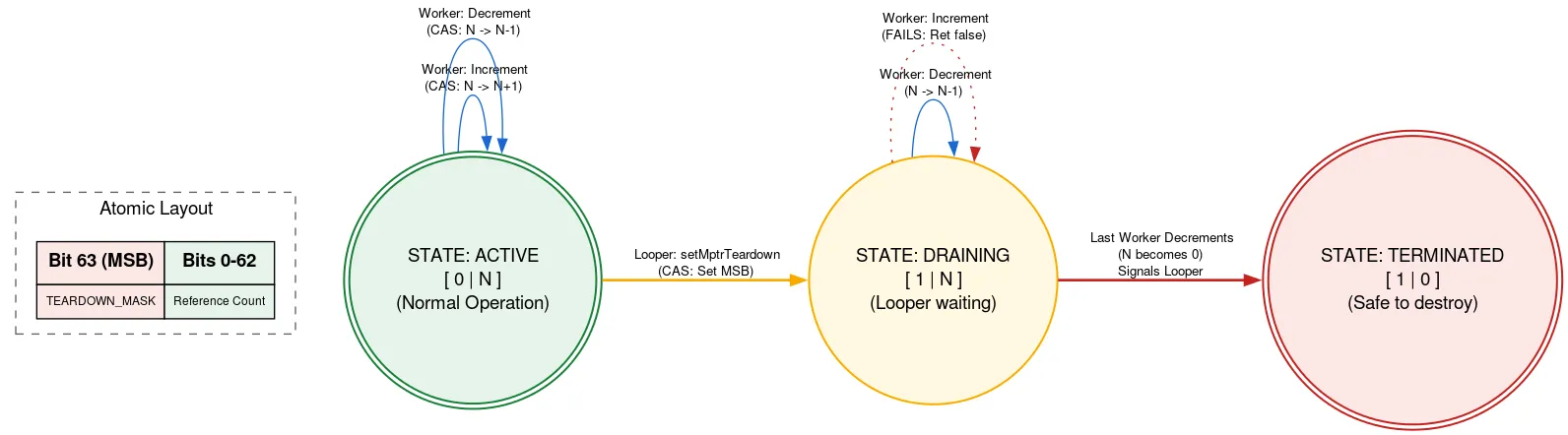
Chiusura: conteggio dei riferimenti nativo
Looper è supportato da un'allocazione nativa che deve essere liberata manualmente una volta chiuso Looper. Se un altro thread aggiunge Message mentre Looper è in chiusura, potrebbe utilizzare l'allocazione nativa dopo che è stata liberata, una violazione della sicurezza della memoria. Per evitare questo problema, utilizziamo un conteggio dei riferimenti con tag, in cui un bit dell'atomico viene utilizzato per indicare se Looper è in chiusura.
Prima di utilizzare l'allocazione nativa, un thread legge l'atomic refcount. Se il bit di chiusura è impostato, viene restituito che Looper si sta chiudendo e l'allocazione nativa non deve essere utilizzata. In caso contrario, tenta un CAS per incrementare il numero di thread attivi utilizzando l'allocazione nativa. Dopo aver fatto ciò che deve, decrementa il conteggio. Se il bit di uscita è stato impostato dopo l'incremento ma prima del decremento e il conteggio è ora pari a zero, il thread Looper viene riattivato.
Quando il thread Looper è pronto per uscire, utilizza CAS per impostare il bit di uscita nell'atomico. Se il conteggio dei riferimenti era 0, può procedere alla liberazione dell'allocazione nativa. In caso contrario, si parcheggia, sapendo che verrà riattivato quando l'ultimo utente dell'allocazione nativa decrementa il conteggio dei riferimenti. Questo approccio implica che il thread Looper attende l'avanzamento degli altri thread, ma solo quando viene chiuso. Questa operazione viene eseguita una sola volta e non è sensibile alle prestazioni. Inoltre, mantiene l'altro codice per l'utilizzo dell'allocazione nativa completamente privo di blocchi.
L'implementazione presenta molti altri trucchi e complessità. Per saperne di più su DeliQueue, consulta il codice sorgente.
Ottimizzazione: programmazione senza rami
Durante lo sviluppo e il test di DeliQueue, il team ha eseguito molti benchmark e ha profilato attentamente il nuovo codice. Un problema identificato utilizzando lo strumento simpleperf è stato lo svuotamento della pipeline causato dal codice del comparatore Message.
Un comparatore standard utilizza salti condizionali, con la condizione per decidere quale Message viene prima semplificata di seguito:
static int compareMessages(@NonNull Message m1, @NonNull Message m2) {
if (m1 == m2) {
return 0;
}
// Primary queue order is by when.
// Messages with an earlier when should come first in the queue.
final long whenDiff = m1.when - m2.when;
if (whenDiff > 0) return 1;
if (whenDiff < 0) return -1;
// Secondary queue order is by insert sequence.
// If two messages were inserted with the same `when`, the one inserted
// first should come first in the queue.
final long insertSeqDiff = m1.insertSeq - m2.insertSeq;
if (insertSeqDiff > 0) return 1;
if (insertSeqDiff < 0) return -1;
return 0;
}Questo codice viene compilato in salti condizionali (istruzioni b.le e cbnz). Quando la CPU incontra un ramo condizionale, non può sapere se il ramo viene eseguito finché la condizione non viene calcolata, quindi non sa quale istruzione leggere successivamente e deve indovinare, utilizzando una tecnica chiamata previsione dei rami. In un caso come la ricerca binaria, la direzione del ramo sarà imprevedibilmente diversa a ogni passaggio, quindi è probabile che la metà delle previsioni sia errata. La previsione dei rami è spesso inefficace negli algoritmi di ricerca e ordinamento (come quello utilizzato in un min-heap), perché il costo di un'ipotesi errata è maggiore del miglioramento derivante da un'ipotesi corretta. Quando il branch predictor indovina in modo errato, deve eliminare il lavoro svolto dopo aver assunto il valore previsto e ricominciare dal percorso effettivamente intrapreso. Questa operazione è chiamata svuotamento della pipeline.
Per trovare questo problema, abbiamo profilato i nostri benchmark utilizzando il contatore delle prestazioni branch-misses, che registra le tracce dello stack in cui il branch predictor fa una stima errata. Abbiamo quindi visualizzato i risultati con Google pprof, come mostrato di seguito:
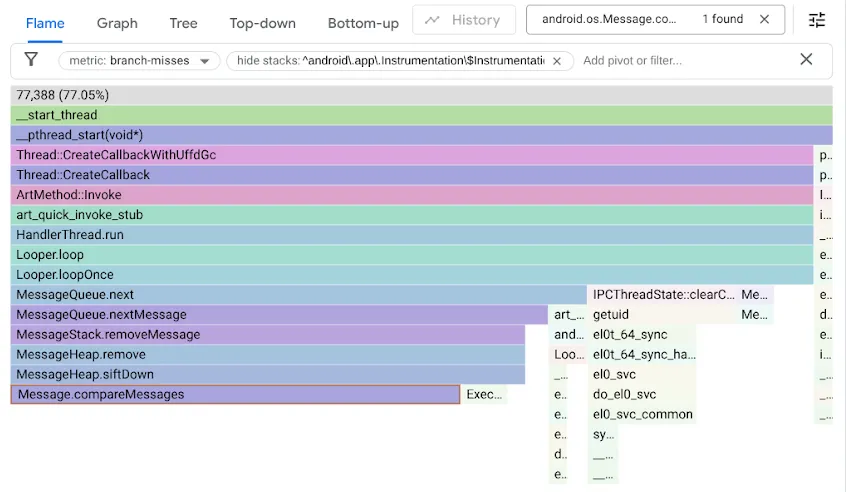
Ricorda che il codice MessageQueue originale utilizzava un elenco a collegamento singolo per la coda ordinata. L'inserimento attraverserebbe l'elenco in ordine ordinato come ricerca lineare, fermandosi al primo elemento successivo al punto di inserimento e collegando il nuovo Message prima di questo. La rimozione dalla testa richiedeva semplicemente lo scollegamento della testa. DeliQueue utilizza un min-heap, in cui le mutazioni richiedono il riordino di alcuni elementi (sift up o down) con complessità logaritmica in una struttura di dati bilanciata, in cui qualsiasi confronto ha la stessa probabilità di indirizzare l'attraversamento a un figlio sinistro o a un figlio destro. Il nuovo algoritmo è asintoticamente più veloce, ma espone un nuovo collo di bottiglia poiché il codice di ricerca si blocca sui mancati rami la metà del tempo.
Rendendoci conto che gli errori di ramificazione rallentavano il nostro codice heap, abbiamo ottimizzato il codice utilizzando la programmazione senza ramificazioni:
// Branchless Logic
static int compareMessages(@NonNull Message m1, @NonNull Message m2) {
final long when1 = m1.when;
final long when2 = m2.when;
final long insertSeq1 = m1.insertSeq;
final long insertSeq2 = m2.insertSeq;
// signum returns the sign (-1, 0, 1) of the argument,
// and is implemented as pure arithmetic:
// ((num >> 63) | (-num >>> 63))
final int whenSign = Long.signum(when1 - when2);
final int insertSeqSign = Long.signum(insertSeq1 - insertSeq2);
// whenSign takes precedence over insertSeqSign,
// so the formula below is such that insertSeqSign only matters
// as a tie-breaker if whenSign is 0.
return whenSign * 2 + insertSeqSign;
}Per comprendere l'ottimizzazione, smonta i due esempi in Compiler Explorer e utilizza LLVM-MCA, un simulatore di CPU che può generare una cronologia stimata dei cicli della CPU.
The original code: Index 01234567890123 [0,0] DeER . . . sub x0, x2, x3 [0,1] D=eER. . . cmp x0, #0 [0,2] D==eER . . cset w0, ne [0,3] .D==eER . . cneg w0, w0, lt [0,4] .D===eER . . cmp w0, #0 [0,5] .D====eER . . b.le #12 [0,6] . DeE---R . . mov w1, #1 [0,7] . DeE---R . . b #48 [0,8] . D==eE-R . . tbz w0, #31, #12 [0,9] . DeE--R . . mov w1, #-1 [0,10] . DeE--R . . b #36 [0,11] . D=eE-R . . sub x0, x4, x5 [0,12] . D=eER . . cmp x0, #0 [0,13] . D==eER. . cset w0, ne [0,14] . D===eER . cneg w0, w0, lt [0,15] . D===eER . cmp w0, #0 [0,16] . D====eER. csetm w1, lt [0,17] . D===eE-R. cmp w0, #0 [0,18] . .D===eER. csinc w1, w1, wzr, le [0,19] . .D====eER mov x0, x1 [0,20] . .DeE----R ret
Tieni presente il ramo condizionale b.le, che evita di confrontare i campi insertSeq se il risultato è già noto dal confronto dei campi when.
The branchless code: Index 012345678 [0,0] DeER . . sub x0, x2, x3 [0,1] DeER . . sub x1, x4, x5 [0,2] D=eER. . cmp x0, #0 [0,3] .D=eER . cset w0, ne [0,4] .D==eER . cneg w0, w0, lt [0,5] .DeE--R . cmp x1, #0 [0,6] . DeE-R . cset w1, ne [0,7] . D=eER . cneg w1, w1, lt [0,8] . D==eeER add w0, w1, w0, lsl #1 [0,9] . DeE--R ret
In questo caso, l'implementazione senza rami richiede meno cicli e istruzioni anche del percorso più breve nel codice con rami, quindi è migliore in tutti i casi. L'implementazione più rapida e l'eliminazione dei rami previsti in modo errato hanno comportato un miglioramento di 5 volte in alcuni dei nostri benchmark.
Tuttavia, questa tecnica non è sempre applicabile. Gli approcci senza rami in genere richiedono di svolgere un lavoro che verrà eliminato e, se il ramo è prevedibile la maggior parte delle volte, questo lavoro sprecato può rallentare il codice. Inoltre, la rimozione di un ramo spesso introduce una dipendenza dai dati. Le CPU moderne eseguono più operazioni per ciclo, ma non possono eseguire un'istruzione finché gli input di un'istruzione precedente non sono pronti. Al contrario, una CPU può speculare sui dati nelle diramazioni e lavorare in anticipo se una diramazione viene prevista correttamente.
Test e convalida
Convalidare la correttezza degli algoritmi senza blocchi è notoriamente difficile.
Oltre ai test unitari standard per la convalida continua durante lo sviluppo, abbiamo anche scritto rigorosi stress test per verificare gli invarianti della coda e per tentare di indurre race condition dei dati, se esistenti. Nei nostri laboratori di test abbiamo potuto eseguire milioni di istanze di test su dispositivi emulati e su hardware reale.
Con la strumentazione Java ThreadSanitizer (JTSan), abbiamo potuto utilizzare gli stessi test per rilevare anche alcune competizioni per i dati nel nostro codice. JTSan non ha rilevato alcuna condizione di competizione problematica in DeliQueue, ma, sorprendentemente, ha rilevato due bug di concorrenza nel framework Robolectric, che abbiamo prontamente corretto.
Per migliorare le nostre funzionalità di debug, abbiamo creato nuovi strumenti di analisi. Di seguito è riportato un esempio che mostra un problema nel codice della piattaforma Android in cui un thread sovraccarica un altro thread con Message, causando un backlog di grandi dimensioni, visibile in Perfetto grazie alla funzionalità di strumentazione MessageQueue che abbiamo aggiunto.
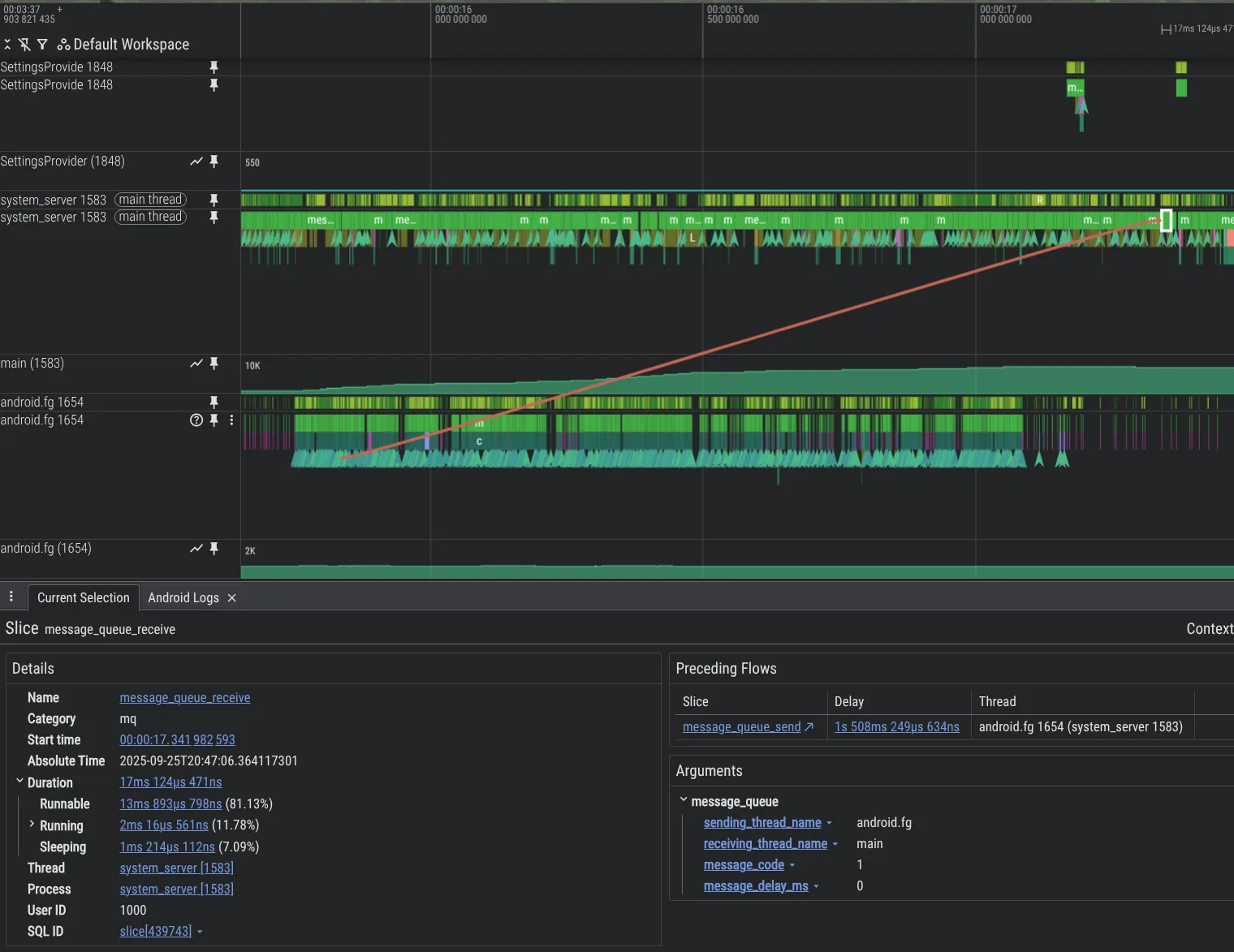
Per attivare la tracciatura di MessageQueue nel processo system_server, includi quanto segue nella configurazione di Perfetto:
data_sources {
config {
name: "track_event"
target_buffer: 0 # Change this per your buffers configuration
track_event_config {
enabled_categories: "mq"
}
}
}Impatto
DeliQueue migliora le prestazioni del sistema e delle app eliminando i blocchi da MessageQueue.
- Benchmark sintetici:gli inserimenti multithread in code occupate sono fino a 5000 volte più veloci rispetto a
MessageQueuelegacy, grazie a una migliore concorrenza (lo stack Treiber) e a inserimenti più rapidi (l'heap minimo). - Nei Perfetto traces acquisiti dai beta tester interni, osserviamo una riduzione del 15% del tempo del thread principale dell'app trascorso in contesa di blocco.
- Sugli stessi dispositivi di test, la riduzione della contesa di blocco comporta miglioramenti significativi dell'esperienza utente, ad esempio:
- -4% di frame mancanti nelle app.
- -7,7% di frame mancanti nelle interazioni con la UI di sistema e l'Avvio app.
- -9,1% nel tempo dall'avvio dell'app al disegno del primo frame, al 95° percentile.
Passaggi successivi
DeliQueue verrà implementato nelle app in Android 17. Gli sviluppatori di app devono esaminare la preparazione dell'app per il nuovo MessageQueue senza blocco sul blog per sviluppatori Android per scoprire come testare le proprie app.
Riferimenti
[1] Treiber, R.K., 1986. Programmazione di sistemi: gestire il parallelismo. International Business Machines Incorporated, Thomas J. Watson Research Center.
[2] Goetz, B., Peierls, T., Bloch, J., Bowbeer, J., Holmes, D., & Lea, D. (2006). Java Concurrency in Practice. Addison-Wesley Professional.
Scritto da:
Continua a leggere
-


Novità sul prodotto
Al Google I/O 2026, abbiamo presentato il passaggio di Android da sistema operativo a sistema intelligente. Abbiamo anche mostrato come creare esperienze intelligenti in modo nativo con il sistema e portare la potenza dell'AI di Google nelle tue app.
Jingyu Shi • Lettura di 2 minuti
-



Novità sul prodotto
Siamo felici di annunciare che è stato aggiunto il supporto ufficiale per Unreal Engine e Godot per Android XR. Stiamo anche lanciando nuovi strumenti progettati per aumentare la produttività e abilitare nuove funzionalità XR: l'hub del motore Android XR e il framework di interazione Android XR.
Luke Hopkins, Ryan Bartley • Lettura di 4 minuti
-


Novità sul prodotto
Con il rilascio di Android 17, stiamo passando a uno standard di sviluppo iniziale adattivo. I tuoi utenti non si affidano più a un unico fattore di forma, ma passano da smartphone, pieghevoli, tablet, laptop, display per auto e ambienti XR immersivi durante la giornata.
Fahd Imtiaz • Lettura di 4 minuti
Resta al passo con le novità
Ricevi ogni settimana gli ultimi approfondimenti sullo sviluppo per Android direttamente nella tua casella di posta.
