

در اندروید ۱۷، برنامههایی که SDK 37 یا بالاتر را هدف قرار میدهند، پیادهسازی جدیدی از MessageQueue را دریافت خواهند کرد که در آن پیادهسازی بدون قفل است. پیادهسازی جدید عملکرد را بهبود میبخشد و فریمهای از دست رفته را کاهش میدهد، اما ممکن است کلاینتهایی را که روی فیلدها و متدهای خصوصی MessageQueue تأمل میکنند، خراب کند. برای کسب اطلاعات بیشتر در مورد تغییر رفتار و نحوه کاهش تأثیر آن، مستندات تغییر رفتار MessageQueue را بررسی کنید . این پست وبلاگ فنی، مروری بر معماری مجدد MessageQueue و نحوه تجزیه و تحلیل مشکلات مربوط به قفل با استفاده از Perfetto ارائه میدهد.
Looper نخ رابط کاربری (UI thread) هر برنامه اندروید را هدایت میکند. این حلقه کار را از MessageQueue میگیرد، آن را به Handler ارسال میکند و این کار را تکرار میکند. به مدت دو دهه، MessageQueue از یک قفل مانیتور واحد (یعنی یک بلوک کد synchronized ) برای محافظت از وضعیت خود استفاده میکرد.
اندروید ۱۷ بهروزرسانی قابل توجهی را برای این کامپوننت معرفی میکند: یک پیادهسازی بدون قفل به نام DeliQueue .
این پست توضیح میدهد که چگونه قفلها بر عملکرد رابط کاربری تأثیر میگذارند، چگونه میتوان این مشکلات را با Perfetto تجزیه و تحلیل کرد، و الگوریتمها و بهینهسازیهای خاصی که برای بهبود نخ اصلی اندروید استفاده میشوند، شرح داده شده است.
مشکل: رقابت قفل و وارونگی اولویت
MessageQueue قدیمی به عنوان یک صف اولویتدار که توسط یک قفل واحد محافظت میشد، عمل میکرد. اگر یک نخ پسزمینه پیامی را ارسال کند در حالی که نخ اصلی در حال تعمیر و نگهداری صف است، نخ پسزمینه نخ اصلی را مسدود میکند.
وقتی دو یا چند نخ برای استفاده انحصاری از یک قفل با هم رقابت میکنند، به این حالت رقابت قفل میگویند. این رقابت میتواند باعث وارونگی اولویت شود که منجر به اختلال در رابط کاربری و سایر مشکلات عملکردی میشود.
وارونگی اولویت میتواند زمانی اتفاق بیفتد که یک نخ با اولویت بالا (مانند نخ رابط کاربری) مجبور شود منتظر یک نخ با اولویت پایین بماند. این توالی را در نظر بگیرید:
- یک نخ پسزمینه با اولویت پایین، قفل
MessageQueueرا برای ارسال نتیجه کاری که انجام داده است، به دست میآورد. - یک نخ با اولویت متوسط قابل اجرا میشود و زمانبند هسته، زمان پردازنده را به آن اختصاص میدهد و نخ با اولویت پایین را قبضه میکند.
- نخ رابط کاربری با اولویت بالا، وظیفه فعلی خود را تمام میکند و سعی در خواندن از صف دارد، اما مسدود میشود زیرا نخ با اولویت پایین قفل را نگه میدارد.
نخ با اولویت پایین، نخ رابط کاربری را مسدود میکند و کار با اولویت متوسط، آن را بیشتر به تأخیر میاندازد.

تحلیل مجادله با پرفتو
شما میتوانید این مشکلات را با استفاده ازPerfetto تشخیص دهید. در یک ردیابی استاندارد، یک رشته مسدود شده روی قفل مانیتور وارد حالت خواب میشود و Perfetto برشی را نشان میدهد که مالک قفل را نشان میدهد.
هنگام جستجوی دادههای ردیابی، به دنبال برشهایی با نام «monitor contention with …” باشید که به دنبال آن نام رشتهای که مالک قفل است و کد سایتی که قفل از آنجا به دست آمده است، قرار میگیرد.
مطالعه موردی: لانچر جانک
برای روشن شدن موضوع، بیایید ردپایی را بررسی کنیم که در آن یک کاربر هنگام پیمایش به خانه در تلفن پیکسل بلافاصله پس از گرفتن عکس در برنامه دوربین، با مشکل مواجه شد. در زیر تصویری از Perfetto را مشاهده میکنیم که وقایع منتهی به از دست رفتن فریم را نشان میدهد:

- نشانه: رشته اصلی Launcher مهلت فریم خود را از دست داد. به مدت ۱۸ میلیثانیه مسدود شد که از مهلت ۱۶ میلیثانیهای مورد نیاز برای رندر ۶۰ هرتز بیشتر است.
- تشخیص: Perfetto نشان داد که نخ اصلی روی قفل
MessageQueueمسدود شده است. یک نخ "BackgroundExecutor" قفل را در اختیار داشت. - علت ریشهای: BackgroundExecutor در Process.THREAD_PRIORITY_BACKGROUND (با اولویت بسیار پایین) اجرا میشود. این برنامه یک کار غیر فوری (بررسی محدودیتهای استفاده از برنامه ) را انجام میداد. همزمان، رشتههای با اولویت متوسط از زمان CPU برای پردازش دادههای دوربین استفاده میکردند. زمانبند سیستم عامل، رشته BackgroundExecutor را برای اجرای رشتههای دوربین از حالت پیشفرض خارج کرد.
این توالی باعث شد که نخ رابط کاربری لانچر (با اولویت بالا) به طور غیرمستقیم توسط نخ دوربین (با اولویت متوسط) مسدود شود، که مانع از آزاد شدن قفل توسط نخ پسزمینه لانچر (با اولویت پایین) میشد.
کوئری کردن ردپاها با PerfettoSQL
شما میتوانید از PerfettoSQL برای جستجوی دادههای ردیابی برای الگوهای خاص استفاده کنید. این امر در صورتی مفید است که بانک بزرگی از ردیابیها از دستگاههای کاربر یا آزمایشها داشته باشید و به دنبال ردیابیهای خاصی باشید که نشاندهنده یک مشکل هستند.
برای مثال، این پرسوجو، تداخل MessageQueue را همزمان با فریمهای از دست رفته (jank) مییابد:
INCLUDE PERFETTO MODULE android.monitor_contention; INCLUDE PERFETTO MODULE android.frames.jank_type; SELECT process_name, -- Convert duration from nanoseconds to milliseconds SUM(dur) / 1000000 AS sum_dur_ms, COUNT(*) AS count_contention FROM android_monitor_contention WHERE is_blocked_thread_main AND short_blocked_method LIKE "%MessageQueue%" -- Only look at app processes that had jank AND upid IN ( SELECT DISTINCT(upid) FROM actual_frame_timeline_slice WHERE android_is_app_jank_type(jank_type) = TRUE ) GROUP BY process_name ORDER BY SUM(dur) DESC;
در این مثال پیچیدهتر، دادههای ردیابی شدهای را که چندین جدول را در بر میگیرند، به هم متصل کنید تا تداخل MessageQueue را در هنگام راهاندازی برنامه شناسایی کنید:
INCLUDE PERFETTO MODULE android.monitor_contention; INCLUDE PERFETTO MODULE android.startup.startups; -- Join package and process information for startups DROP VIEW IF EXISTS startups; CREATE VIEW startups AS SELECT startup_id, ts, dur, upid FROM android_startups JOIN android_startup_processes USING(startup_id); -- Intersect monitor contention with startups in the same process. DROP TABLE IF EXISTS monitor_contention_during_startup; CREATE VIRTUAL TABLE monitor_contention_during_startup USING SPAN_JOIN(android_monitor_contention PARTITIONED upid, startups PARTITIONED upid); SELECT process_name, SUM(dur) / 1000000 AS sum_dur_ms, COUNT(*) AS count_contention FROM monitor_contention_during_startup WHERE is_blocked_thread_main AND short_blocked_method LIKE "%MessageQueue%" GROUP BY process_name ORDER BY SUM(dur) DESC;
شما میتوانید از LLM مورد علاقه خود برای نوشتن کوئریهای PerfettoSQL جهت یافتن الگوهای دیگر استفاده کنید.
در گوگل، ما از BigTrace برای اجرای کوئریهای PerfettoSQL در میلیونها ردپا استفاده میکنیم. با انجام این کار، تأیید کردیم که آنچه به صورت غیرمستقیم دیدیم، در واقع یک مشکل سیستمی بوده است. دادهها نشان داد که مشکل قفل MessageQueue بر کاربران در کل اکوسیستم تأثیر میگذارد و نیاز به یک تغییر اساسی در معماری را اثبات میکند.
راه حل: همزمانی بدون قفل
ما با پیادهسازی یک ساختار دادهی بدون قفل ، با استفاده از عملیات حافظهی اتمی به جای قفلهای انحصاری برای همگامسازی دسترسی به حالت مشترک، مشکل رقابت MessageQueue را برطرف کردیم. یک ساختار داده یا الگوریتم در صورتی قفلناپذیر است که حداقل یک نخ بتواند صرف نظر از رفتار زمانبندی نخهای دیگر، همیشه پیشرفت کند. دستیابی به این ویژگی عموماً دشوار است و معمولاً برای اکثر کدها ارزش دنبال کردن ندارد .
اصول اولیه اتمی
نرمافزارهای بدون قفل اغلب به توابع اولیه خواندن-تغییر-نوشتن اتمی که سختافزار ارائه میدهد، متکی هستند.
در پردازندههای ARM64 نسل قدیمیتر، پردازندههای اتمی از یک حلقهی Load-Link/Store-Conditional (LL/SC) استفاده میکردند. پردازنده یک مقدار را بارگذاری کرده و آدرس را علامتگذاری میکند. اگر نخ دیگری در آن آدرس بنویسد، ذخیره با شکست مواجه میشود و حلقه دوباره امتحان میشود. از آنجا که نخها میتوانند بدون انتظار برای نخ دیگر به تلاش ادامه دهند و موفق شوند، این عملیات بدون قفل است.
ARM64 LL/SC loop example
retry:
ldxr x0, [x1] // Load exclusive from address x1 to x0
add x0, x0, #1 // Increment value by 1
stxr w2, x0, [x1] // Store exclusive.
// w2 gets 0 on success, 1 on failure
cbnz w2, retry // If w2 is non-zero (failed), branch to retr( مشاهده در کامپایلر اکسپلورر )
معماریهای جدیدتر ARM (ARMv8.1) از افزونههای سیستم بزرگ (LSE) پشتیبانی میکنند که شامل دستورالعملهایی به شکل مقایسه و تعویض (CAS) یا بارگذاری و اضافه کردن (در زیر نشان داده شده است) هستند. در اندروید ۱۷، ما پشتیبانی از کامپایلر Android Runtime (ART) را اضافه کردیم تا تشخیص دهد چه زمانی از LSE پشتیبانی میشود و دستورالعملهای بهینه شده را منتشر کند:
/ ARMv8.1 LSE atomic example
ldadd x0, x1, [x2] // Atomic load-add.
// Faster, no loop required.در معیارهای ما، کد با رقابت بالا که از CAS استفاده میکند، تقریباً ۳ برابر نسبت به نوع LL/SC سرعت بیشتری کسب میکند.
زبان برنامهنویسی جاوا از طریق java.util.concurrent.atomic اصول اولیه اتمی را ارائه میدهد که به این دستورالعملها و سایر دستورالعملهای تخصصی CPU متکی هستند.
ساختار داده: DeliQueue
برای حذف تداخل قفل از MessageQueue ، مهندسان ما یک ساختار داده جدید به نام DeliQueue طراحی کردند. DeliQueue درج Message را از پردازش Message جدا میکند:
- فهرست
Messages(پشته Treiber): یک پشته بدون قفل. هر نخی میتواندMessagesجدید را بدون اختلاف به اینجا ارسال کند. - صف اولویتدار (Min-heap): مجموعهای از
Messagesبرای مدیریت، که منحصراً متعلق به نخ Looper است (از این رو برای دسترسی به آن نیازی به همگامسازی یا قفل نیست).
Enqueue: ارسال به یک پشته Treiber
فهرست Messages در یک پشته Treiber [1] نگهداری میشود، یک پشته بدون قفل که از یک حلقه CAS برای بهروزرسانی اشارهگر رأس استفاده میکند.
public class TreiberStack <E> {
AtomicReference<Node<E>> top =
new AtomicReference<Node<E>>();
public void push(E item) {
Node<E> newHead = new Node<E>(item);
Node<E> oldHead;
do {
oldHead = top.get();
newHead.next = oldHead;
} while (!top.compareAndSet(oldHead, newHead));
}
public E pop() {
Node<E> oldHead;
Node<E> newHead;
do {
oldHead = top.get();
if (oldHead == null) return null;
newHead = oldHead.next;
} while (!top.compareAndSet(oldHead, newHead));
return oldHead.item;
}
}کد منبع مبتنی بر Java Concurrency in Practice [2]، به صورت آنلاین در دسترس و در مالکیت عمومی منتشر شده است.
هر تولیدکنندهای میتواند در هر زمانی Message جدید را به پشته اضافه کند. این مانند کشیدن بلیط در پیشخوان اغذیهفروشی است - شماره شما با زمان حضورتان تعیین میشود، اما ترتیب دریافت غذایتان لازم نیست با آن مطابقت داشته باشد. از آنجا که این یک پشته پیوندی است، هر Message یک زیرپشته است - میتوانید با ردیابی سر صف و تکرار رو به جلو، ببینید که صف Message در هر نقطه از زمان چگونه بوده است - هیچ Message جدیدی را که در بالا قرار گرفته باشد، نخواهید دید، حتی اگر در طول پیمایش شما اضافه شوند.
صفزدایی: انتقال انبوه به یک حداقل-هیپ
برای یافتن Message بعدی که باید مدیریت شود، Looper Message جدید را از پشته Treiber با پیمایش پشته از بالا و تکرار تا زمانی که آخرین Message که قبلاً پردازش کرده است پیدا کند، پردازش میکند. همانطور که Looper در پشته حرکت میکند، Message را در min-heap با ترتیب مهلت قرار میدهد. از آنجایی که Looper منحصراً مالک پشته است، Message را بدون قفل یا اتمی سفارش میدهد و پردازش میکند.

در حین پیمایش در پشته، Looper همچنین پیوندهایی از Message انباشته شده به پیامهای قبلی آنها ایجاد میکند و بدین ترتیب یک لیست پیوندی مضاعف تشکیل میدهد. ایجاد لیست پیوندی ایمن است زیرا پیوندهایی که به سمت پایین پشته اشاره میکنند از طریق الگوریتم پشته Treiber با CAS اضافه میشوند و پیوندهای بالای پشته فقط توسط نخ Looper خوانده و اصلاح میشوند. سپس از این پیوندهای برگشتی برای حذف Message ها از نقاط دلخواه در پشته در زمان O(1) استفاده میشود.
این طراحی، پردازش درج O (1) را برای تولیدکنندگان (رشتههایی که کار را به صف ارسال میکنند) و پردازش سرشکن O (log N) را برای مصرفکننده ( Looper ) فراهم میکند.
استفاده از یک min-heap برای مرتبسازی Message همچنین یک نقص اساسی در MessageQueue قدیمی را برطرف میکند، که در آن Message در یک لیست تک پیوندی (با ریشه در بالا) نگهداری میشدند. در پیادهسازی قدیمی، حذف از سر صف O (1) بود، اما درج در بدترین حالت O(N) بود - مقیاسپذیری ضعیفی برای صفهای پربار داشت! برعکس، درج در min-heap و حذف از آن به صورت لگاریتمی مقیاسبندی میشوند و عملکرد متوسط رقابتی ارائه میدهند اما در تأخیرهای انتهایی واقعاً عالی هستند.
صف MessageQueue قدیمی (قفل شده) | دلیکویو | |
| درج | O(N) | O (1) برای فراخوانی نخ O(logN) برای نخ |
| از روی سر بردارید | ای (1) | O(logN) |
در پیادهسازی صف قدیمی، تولیدکنندگان و مصرفکننده از یک قفل برای هماهنگی دسترسی انحصاری به لیست تکپیوندی زیربنایی استفاده میکردند. در DeliQueue، پشته Treiber دسترسی همزمان را مدیریت میکند و مصرفکننده واحد، مرتبسازی صف کاری خود را مدیریت میکند.
حذف: سازگاری از طریق سنگ قبرها
DeliQueue یک ساختار داده ترکیبی است که یک پشته Treiber بدون قفل را با یک min-heap تک رشتهای پیوند میدهد. همگامسازی این دو ساختار بدون قفل سراسری، چالش منحصر به فردی را ایجاد میکند: یک پیام ممکن است از نظر فیزیکی در پشته وجود داشته باشد اما از نظر منطقی از صف حذف شود.
برای حل این مشکل، DeliQueue از تکنیکی به نام «tombstoning» استفاده میکند. هر Message موقعیت خود را در پشته از طریق اشارهگرهای عقب و جلو، اندیس خود در آرایه هیپ و یک پرچم بولی که نشان میدهد آیا حذف شده است یا خیر، ردیابی میکند. هنگامی که یک Message آماده اجرا است، نخ Looper پرچم حذف شده آن را CAS میکند، سپس آن را از هیپ و پشته حذف میکند.
وقتی نخ دیگری نیاز به حذف یک Message دارد، آن را بلافاصله از ساختار داده استخراج نمیکند. در عوض، مراحل زیر را انجام میدهد:
- حذف منطقی: رشته از یک CAS برای تنظیم خودکار پرچم حذف
Messageاز false به true استفاده میکند.Messageدر ساختار داده به عنوان مدرکی از حذف در انتظار آن، به اصطلاح "سنگ قبر" باقی میماند. هنگامی که یکMessageبرای حذف علامتگذاری میشود، DeliQueue با آن طوری رفتار میکند که انگار دیگر در صف وجود ندارد، هر زمان که آن را پیدا کند. - پاکسازی معوق: حذف واقعی از ساختار داده بر عهده نخ
Looperاست و به بعد موکول میشود. نخ remover به جای تغییر پشته یا هیپ،Messageبه یک پشته لیست آزاد بدون قفل دیگر اضافه میکند. - حذف ساختاری: فقط
Looperمیتواند با هیپ تعامل داشته باشد یا عناصر را از پشته حذف کند. وقتی از خواب بیدار میشود، لیست آزاد را پاک میکند وMessageرا که در آن قرار دارد پردازش میکند. سپس هرMessageاز پشته جدا شده و از هیپ حذف میشود.
این رویکرد، مدیریت کل پشته را به صورت تکرشتهای نگه میدارد. این امر تعداد عملیات همزمان و موانع حافظه مورد نیاز را به حداقل میرساند و مسیر بحرانی را سریعتر و سادهتر میکند.
پیمایش: مسابقات دادهای بیخطر مدل حافظه جاوا
اکثر APIهای همزمانی، مانند Future در کتابخانه استاندارد جاوا، یا Job و Deferred کاتلین، شامل مکانیزمی برای لغو کار قبل از اتمام آن هستند. یک نمونه از یکی از این کلاسها به صورت ۱:۱ با یک واحد کار اساسی مطابقت دارد و فراخوانی cancel روی یک شیء، عملیات خاص مرتبط با آنها را لغو میکند.
دستگاههای اندروید امروزی دارای پردازندههای چند هستهای و جمعآوری زباله همزمان و نسلی هستند. اما وقتی اندروید برای اولین بار توسعه داده شد، اختصاص یک شیء برای هر واحد کاری بسیار پرهزینه بود. در نتیجه، Handler اندروید از لغو از طریق بارگذاریهای متعدد removeMessages پشتیبانی میکند - به جای حذف یک Message خاص ، تمام Message هایی را که با معیارهای مشخص شده مطابقت دارند حذف میکند. در عمل، این امر مستلزم تکرار تمام Message هایی است که قبل از فراخوانی removeMessages درج شدهاند و حذف آنهایی که مطابقت دارند.
هنگام تکرار رو به جلو، یک نخ فقط به یک عملیات اتمی مرتب نیاز دارد تا سر فعلی پشته را بخواند. پس از آن، از خواندن فیلدهای معمولی برای یافتن Message بعدی استفاده میشود. اگر نخ Looper فیلدهای next را هنگام حذف Message تغییر دهد، نوشتن Looper و خواندن نخ دیگر هماهنگ نمیشوند - این یک مسابقه داده است. معمولاً، مسابقه داده یک اشکال جدی است که میتواند مشکلات بزرگی در برنامه شما ایجاد کند - نشت، حلقههای بینهایت، خرابی، توقف و موارد دیگر. با این حال، تحت شرایط خاص و محدود، مسابقه داده میتواند در مدل حافظه جاوا بیخطر باشد. فرض کنید با پشتهای از موارد زیر شروع میکنیم:

ما یک خواندن اتمی از هد انجام میدهیم و میبینیم که A. اشارهگر بعدی A به B اشاره میکند. همزمان با پردازش B، حلقهزن ممکن است B و C را حذف کند، با بهروزرسانی A برای اشاره به C و سپس D.

اگرچه B و C به صورت منطقی حذف شدهاند، B اشارهگر بعدی خود به C و C به D را حفظ میکند. رشته خواندن به پیمایش از طریق گرههای حذفشدهی جدا شده ادامه میدهد و در نهایت دوباره به پشته زنده در D میپیوندد.
با طراحی DeliQueue برای مدیریت رقابت بین پیمایش و حذف، امکان تکرار ایمن و بدون قفل را فراهم میکنیم.
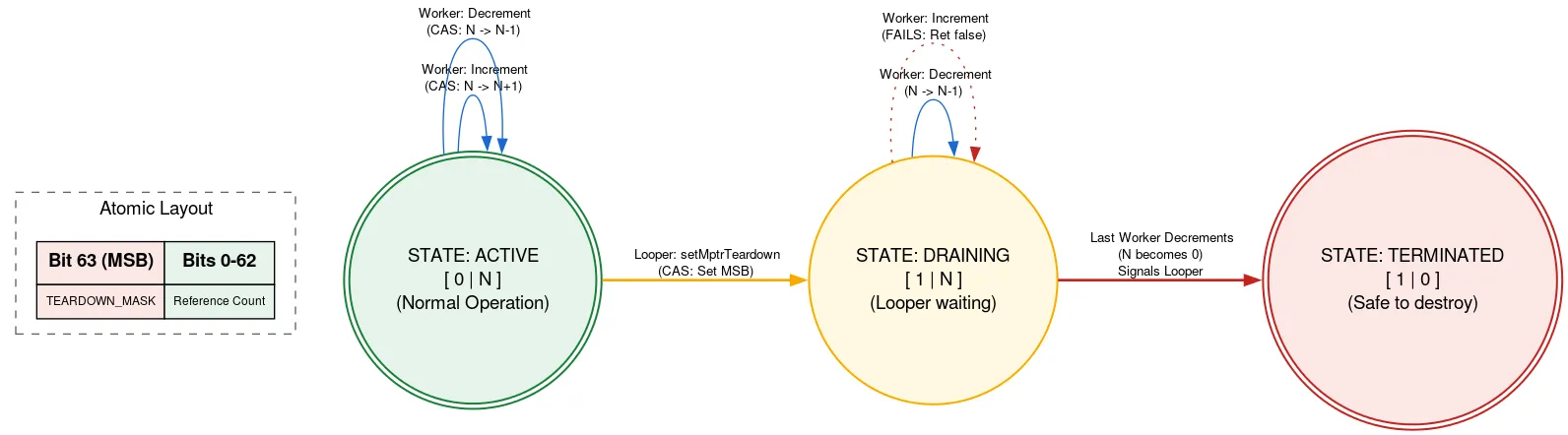
ترک: شمارش مجدد بومی
Looper توسط یک تخصیص محلی پشتیبانی میشود که باید پس از خروج Looper به صورت دستی آزاد شود. اگر نخ دیگری در حین خروج Looper در حال اضافه کردن Message باشد، میتواند پس از آزاد شدن از تخصیص محلی استفاده کند، که نقض ایمنی حافظه است. ما با استفاده از یک refcount برچسبگذاری شده از این امر جلوگیری میکنیم، که در آن یک بیت از atomic برای نشان دادن خروج Looper استفاده میشود.
قبل از استفاده از تخصیص بومی، یک نخ، refcount atomic را میخواند. اگر بیت خروج تنظیم شده باشد، برمیگرداند که Looper در حال خروج است و تخصیص بومی نباید استفاده شود. در غیر این صورت، سعی میکند با استفاده از تخصیص بومی، تعداد نخهای فعال را افزایش دهد. پس از انجام کارهای لازم، تعداد را کاهش میدهد. اگر بیت خروج بعد از افزایش اما قبل از کاهش تنظیم شده باشد و تعداد اکنون صفر باشد، نخ Looper را بیدار میکند.
وقتی نخ Looper آمادهی خروج باشد، از CAS برای تنظیم بیت خروج در atomic استفاده میکند. اگر مقدار refcount برابر با 0 باشد، میتواند تخصیص native خود را آزاد کند. در غیر این صورت، خودش را پارک میکند، با این آگاهی که وقتی آخرین کاربر تخصیص native، مقدار refcount را کاهش دهد، بیدار خواهد شد. این رویکرد به این معنی است که نخ Looper منتظر پیشرفت سایر نخها میماند، اما فقط زمانی که در حال خروج است. این اتفاق فقط یک بار میافتد و به عملکرد حساس نیست و کد دیگر را برای استفاده از تخصیص native کاملاً بدون قفل نگه میدارد.
کلی ترفند و پیچیدگی دیگه هم توی پیادهسازیش هست. میتونید با بررسی کد منبع DeliQueue بیشتر در موردش اطلاعات کسب کنید.
بهینهسازی: برنامهنویسی بدون شاخه
تیم توسعهدهنده در حین توسعه و آزمایش DeliQueue، بنچمارکهای زیادی را اجرا کرد و کد جدید را با دقت بررسی کرد. یکی از مشکلاتی که با استفاده از ابزار simpleperf شناسایی شد، مشکل تخلیه خط لوله (pipeline flushing) ناشی از کد مقایسهگر Message بود.
یک مقایسهگر استاندارد از پرشهای شرطی استفاده میکند، و شرط تصمیمگیری برای اینکه کدام Message ابتدا بیاید، به صورت سادهشده در زیر آمده است:
static int compareMessages(@NonNull Message m1, @NonNull Message m2) {
if (m1 == m2) {
return 0;
}
// Primary queue order is by when.
// Messages with an earlier when should come first in the queue.
final long whenDiff = m1.when - m2.when;
if (whenDiff > 0) return 1;
if (whenDiff < 0) return -1;
// Secondary queue order is by insert sequence.
// If two messages were inserted with the same `when`, the one inserted
// first should come first in the queue.
final long insertSeqDiff = m1.insertSeq - m2.insertSeq;
if (insertSeqDiff > 0) return 1;
if (insertSeqDiff < 0) return -1;
return 0;
} این کد به پرشهای شرطی (دستورالعملهای b.le و cbnz ) کامپایل میشود. وقتی CPU با یک پرش شرطی مواجه میشود، تا زمانی که شرط محاسبه نشود، نمیتواند بداند که آیا پرش انجام شده است یا خیر، بنابراین نمیداند کدام دستورالعمل را باید در مرحله بعد بخواند و باید با استفاده از تکنیکی به نام پیشبینی پرش ، حدس بزند. در حالتی مانند جستجوی دودویی، جهت پرش در هر مرحله به طور غیرقابل پیشبینی متفاوت خواهد بود، بنابراین احتمال دارد نیمی از پیشبینیها اشتباه باشند. پیشبینی پرش اغلب در الگوریتمهای جستجو و مرتبسازی (مانند الگوریتمی که در min-heap استفاده میشود) بیاثر است، زیرا هزینه حدس اشتباه بیشتر از بهبود حاصل از حدس درست است. وقتی پیشبینیکننده پرش اشتباه حدس میزند، باید کاری را که پس از فرض مقدار پیشبینیشده انجام داده است، دور بریزد و دوباره از مسیری که واقعاً طی شده است شروع کند - به این کار پاکسازی خط لوله میگویند.
برای یافتن این مشکل، ما معیارهای خود را با استفاده از شمارنده عملکرد branch-misses ، که رد پشتههایی را که پیشبینیکننده پرش در آنها اشتباه حدس میزند، ثبت میکند، نمایهسازی کردیم. سپس نتایج را با Google pprof ، همانطور که در زیر نشان داده شده است، تجسم کردیم:
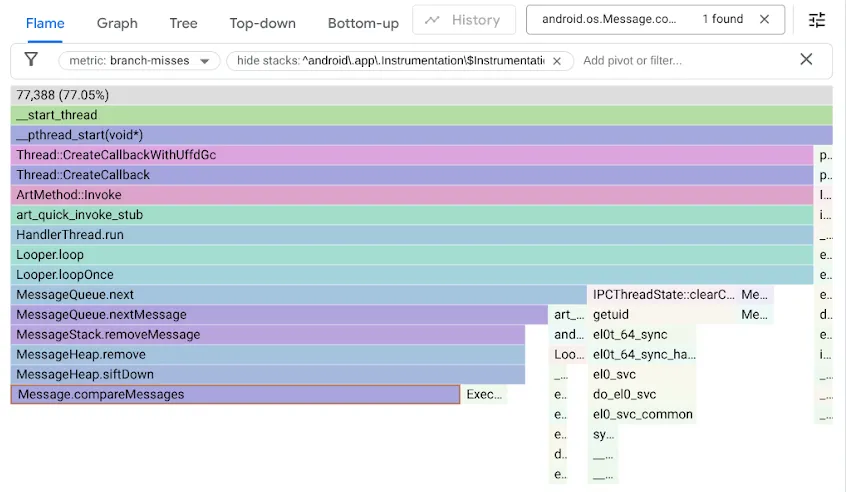
به یاد بیاورید که کد اصلی MessageQueue از یک لیست تک پیوندی برای صف مرتب استفاده میکرد. درج، لیست را به صورت مرتب شده به عنوان یک جستجوی خطی پیمایش میکرد و در اولین عنصری که از نقطه درج گذشته است متوقف میشد و Message جدید را به قبل از آن پیوند میداد. حذف از سر صف به سادگی نیاز به جدا کردن سر صف داشت. در حالی که DeliQueue از یک min-heap استفاده میکند، که در آن جهشها نیاز به مرتبسازی مجدد برخی عناصر (غربال کردن به بالا یا پایین) با پیچیدگی لگاریتمی در یک ساختار داده متعادل دارند، که در آن هر مقایسهای شانس یکسانی برای هدایت پیمایش به فرزند چپ یا فرزند راست دارد. الگوریتم جدید به صورت مجانبی سریعتر است، اما یک تنگنای جدید را آشکار میکند زیرا کد جستجو در نیمی از مواقع در پرش ناموفق متوقف میشود.
با درک اینکه پرشهای ناموفق باعث کند شدن کد heap ما میشوند، کد را با استفاده از برنامهنویسی بدون شاخه بهینه کردیم:
// Branchless Logic
static int compareMessages(@NonNull Message m1, @NonNull Message m2) {
final long when1 = m1.when;
final long when2 = m2.when;
final long insertSeq1 = m1.insertSeq;
final long insertSeq2 = m2.insertSeq;
// signum returns the sign (-1, 0, 1) of the argument,
// and is implemented as pure arithmetic:
// ((num >> 63) | (-num >>> 63))
final int whenSign = Long.signum(when1 - when2);
final int insertSeqSign = Long.signum(insertSeq1 - insertSeq2);
// whenSign takes precedence over insertSeqSign,
// so the formula below is such that insertSeqSign only matters
// as a tie-breaker if whenSign is 0.
return whenSign * 2 + insertSeqSign;
}برای درک بهینهسازی، دو مثال را در Compiler Explorer از هم جدا کنید و از LLVM-MCA ، یک شبیهساز CPU که میتواند یک جدول زمانی تخمینی از چرخههای CPU ایجاد کند، استفاده کنید.
The original code: Index 01234567890123 [0,0] DeER . . . sub x0, x2, x3 [0,1] D=eER. . . cmp x0, #0 [0,2] D==eER . . cset w0, ne [0,3] .D==eER . . cneg w0, w0, lt [0,4] .D===eER . . cmp w0, #0 [0,5] .D====eER . . b.le #12 [0,6] . DeE---R . . mov w1, #1 [0,7] . DeE---R . . b #48 [0,8] . D==eE-R . . tbz w0, #31, #12 [0,9] . DeE--R . . mov w1, #-1 [0,10] . DeE--R . . b #36 [0,11] . D=eE-R . . sub x0, x4, x5 [0,12] . D=eER . . cmp x0, #0 [0,13] . D==eER. . cset w0, ne [0,14] . D===eER . cneg w0, w0, lt [0,15] . D===eER . cmp w0, #0 [0,16] . D====eER. csetm w1, lt [0,17] . D===eE-R. cmp w0, #0 [0,18] . .D===eER. csinc w1, w1, wzr, le [0,19] . .D====eER mov x0, x1 [0,20] . .DeE----R ret
به یک شاخه شرطی، b.le ، توجه کنید که اگر نتیجه از مقایسه فیلدهای when از قبل مشخص باشد، از مقایسه فیلدهای insertSeq خودداری میکند.
The branchless code: Index 012345678 [0,0] DeER . . sub x0, x2, x3 [0,1] DeER . . sub x1, x4, x5 [0,2] D=eER. . cmp x0, #0 [0,3] .D=eER . cset w0, ne [0,4] .D==eER . cneg w0, w0, lt [0,5] .DeE--R . cmp x1, #0 [0,6] . DeE-R . cset w1, ne [0,7] . D=eER . cneg w1, w1, lt [0,8] . D==eeER add w0, w1, w0, lsl #1 [0,9] . DeE--R ret
در اینجا، پیادهسازی بدون شاخه، چرخهها و دستورالعملهای کمتری نسبت به حتی کوتاهترین مسیر از طریق کد شاخهای نیاز دارد - در همه موارد بهتر است. پیادهسازی سریعتر به علاوه حذف شاخههای پیشبینی نشده منجر به بهبود ۵ برابری در برخی از معیارهای ما شد!
با این حال، این تکنیک همیشه قابل اجرا نیست. رویکردهای بدون شاخه عموماً نیاز به انجام کارهایی دارند که دور ریخته میشوند و اگر شاخه در بیشتر مواقع قابل پیشبینی باشد، آن کار تلفشده میتواند کد شما را کند کند. علاوه بر این، حذف یک شاخه اغلب وابستگی دادهای ایجاد میکند. پردازندههای مدرن چندین عملیات را در هر چرخه اجرا میکنند، اما نمیتوانند یک دستورالعمل را تا زمانی که ورودیهای آن از یک دستورالعمل قبلی آماده نشده باشد، اجرا کنند. در مقابل، یک پردازنده میتواند در مورد دادهها در شاخهها حدس بزند و اگر یک شاخه به درستی پیشبینی شود، کار را ادامه دهد.
آزمایش و اعتبارسنجی
اعتبارسنجی درستی الگوریتمهای بدون قفل به طور مشهوری دشوار است!
علاوه بر تستهای واحد استاندارد برای اعتبارسنجی مداوم در طول توسعه، ما همچنین تستهای استرس دقیقی نوشتیم تا ثابتهای صف را تأیید کنیم و در صورت وجود، سعی در ایجاد رقابتهای دادهای داشته باشیم. در آزمایشگاههای تست خود توانستیم میلیونها نمونه تست را روی دستگاههای شبیهسازی شده و سختافزار واقعی اجرا کنیم.
با استفاده از ابزار Java ThreadSanitizer (JTSan)، میتوانیم از همین تستها برای تشخیص برخی از data raceها در کد خود نیز استفاده کنیم. JTSan هیچ data race مشکلسازی در DeliQueue پیدا نکرد، اما - در کمال تعجب - در واقع دو اشکال همزمانی را در چارچوب Robolectric شناسایی کرد که ما به سرعت آنها را برطرف کردیم.
برای بهبود قابلیتهای اشکالزدایی، ابزارهای تحلیل جدیدی ساختهایم. در زیر مثالی آورده شده است که مشکلی را در کد پلتفرم اندروید نشان میدهد که در آن یک نخ، نخ دیگری را با Message بارگذاری میکند و باعث ایجاد یک انباشتگی بزرگ میشود که به لطف ویژگی ابزار MessageQueue که اضافه کردهایم، در Perfetto قابل مشاهده است.

برای فعال کردن ردیابی MessageQueue در فرآیند system_server ، موارد زیر را در پیکربندی Perfetto خود وارد کنید:
data_sources {
config {
name: "track_event"
target_buffer: 0 # Change this per your buffers configuration
track_event_config {
enabled_categories: "mq"
}
}
}تأثیر
DeliQueue با حذف قفلها از MessageQueue عملکرد سیستم و برنامه را بهبود میبخشد.
- معیارهای مصنوعی: درج چند رشتهای در صفهای شلوغ تا ۵۰۰۰ برابر سریعتر از
MessageQueueقدیمی است، به لطف همزمانی بهبود یافته (پشته Treiber) و درج سریعتر (min-heap). - در ردیابیهای Perfetto که از آزمایشکنندگان بتای داخلی به دست آمده است ، شاهد کاهش ۱۵ درصدی زمان صرف شده در ترد اصلی برنامه برای قفل کردن هستیم.
- در همان دستگاههای آزمایشی، کاهش درگیری قفل منجر به بهبودهای قابل توجهی در تجربه کاربری میشود، مانند:
- -۴٪ فریمها در برنامهها از دست رفتهاند.
- ۷.۷٪ فریمهای از دست رفته در تعاملات رابط کاربری سیستم و لانچر.
- -۹.۱٪ زمان از زمان راهاندازی برنامه تا اولین فریم ترسیم شده، در حالت ۹۵٪.
مراحل بعدی
DeliQueue در اندروید ۱۷ برای برنامهها عرضه میشود. توسعهدهندگان برنامه باید آمادهسازی برنامه خود را برای MessageQueue جدید و بدون قفل در وبلاگ توسعهدهندگان اندروید بررسی کنند تا نحوه آزمایش برنامههای خود را بیاموزند.
منابع
[1] تریبر، آر کی، 1986. برنامهنویسی سیستمها: مقابله با موازیسازی. شرکت بینالمللی ماشینهای تجاری، مرکز تحقیقات توماس جی. واتسون.
[2] گوتز، ب.، پیرلز، ت.، بلاچ، ج.، بوبیر، ج.، هولمز، د.، و لیا، د. (2006). همزمانی جاوا در عمل. آدیسون-وسلی پروفشنال.
نوشته شده توسط:
ادامه مطلب


اخبار محصول
در کنفرانس Google I/O 2026، ما تغییر اندروید از یک سیستم عامل به یک سیستم هوشمند را معرفی کردیم. همچنین نشان دادیم که چگونه میتوانید با این سیستم، تجربیات هوشمند بومی بسازید و قدرت هوش مصنوعی گوگل را به برنامههای خود بیاورید.
Jingyu Shi • 2 دقیقه مطالعه کنید



اخبار محصول
ما مفتخریم اعلام کنیم که پشتیبانی رسمی از موتور Unreal و Godot برای اندروید XR آغاز شده است. ما همچنین ابزارهای جدیدی را برای افزایش بهرهوری شما و فعال کردن قابلیتهای جدید XR راهاندازی میکنیم: مرکز موتور Android XR و چارچوب تعامل Android XR.
Luke Hopkins , Ryan Bartley • ۴ دقیقه مطالعه


اخبار محصول
با انتشار اندروید ۱۷، ما در حال گذار به یک استاندارد توسعه تطبیقی اولیه هستیم. کاربران شما دیگر به یک فرم فاکتور واحد متکی نیستند؛ آنها در طول روز بین تلفنها، دستگاههای تاشو، تبلتها، لپتاپها، نمایشگرهای خودرو و محیطهای فراگیر واقعیت افزوده (XR) جابجا میشوند.
Fahd Imtiaz • ۴ دقیقه مطالعه
در جریان باشید
جدیدترین بینشهای توسعه اندروید را به صورت هفتگی در صندوق ورودی خود دریافت کنید.
