
Android Neural Networks API (NNAPI), Android cihazlarda makine öğrenimi için hesaplama açısından yoğun işlemlerin çalıştırılması amacıyla tasarlanmış bir Android C API'sidir. NNAPI, sinir ağları oluşturan ve eğiten TensorFlow Lite ve Caffe2 gibi üst düzey makine öğrenimi çerçeveleri için temel bir işlevsellik katmanı sağlamak üzere tasarlanmıştır. API, Android 8.1 (API düzeyi 27) veya sonraki sürümlerin yüklü olduğu tüm Android cihazlarda kullanılabilir ancak Android 15'te desteği sonlandırılmıştır.
NNAPI, Android cihazlardaki verileri daha önce eğitilmiş ve geliştiriciler tarafından tanımlanmış modellere uygulayarak çıkarım işlemini destekler. Çıkarım örnekleri arasında görüntüleri sınıflandırma, kullanıcı davranışını tahmin etme ve arama sorgusuna uygun yanıtları seçme yer alır.
Cihaz üzerinde çıkarım yapmanın birçok avantajı vardır:
- Gecikme: Ağ bağlantısı üzerinden istek göndermeniz ve yanıt beklemeniz gerekmez. Örneğin, bu durum kameradan gelen ardışık kareleri işleyen video uygulamaları için kritik olabilir.
- Kullanılabilirlik: Uygulama, ağ kapsamı dışında olsa bile çalışır.
- Hız: Nöral ağ işlemeye özel yeni donanım, tek başına genel amaçlı bir CPU'ya kıyasla önemli ölçüde daha hızlı hesaplama sağlar.
- Gizlilik: Veriler Android cihazdan ayrılmaz.
- Maliyet: Tüm hesaplamalar Android cihazda yapıldığında sunucu grubu gerekmez.
Geliştiricilerin göz önünde bulundurması gereken bazı dezavantajlar da vardır:
- Sistem kullanımı: Sinir ağlarının değerlendirilmesi çok fazla hesaplama içerir ve bu da pil gücü kullanımını artırabilir. Uygulamanız için önemli bir sorunsa, özellikle uzun süren hesaplamalarda pil sağlığını izlemeyi düşünebilirsiniz.
- Uygulama boyutu: Modellerinizin boyutuna dikkat edin. Modeller birkaç megabayt yer kaplayabilir. APK'nıza büyük modelleri paketlemenin kullanıcılarınızı gereksiz yere etkileyeceğini düşünüyorsanız modelleri uygulama yüklemesinden sonra indirmeyi, daha küçük modeller kullanmayı veya hesaplamalarınızı bulutta yapmayı düşünebilirsiniz. NNAPI, modelleri bulutta çalıştırma işlevi sağlamaz.
NNAPI'nin nasıl kullanılacağına dair bir örnek görmek için Android Neural Networks API örneğine bakın.
Neural Networks API çalışma zamanını anlama
NNAPI, geliştiricilerin modellerini cihaz dışında eğitmesine ve Android cihazlarda dağıtmasına olanak tanıyan makine öğrenimi kitaplıkları, çerçeveler ve araçlar tarafından çağrılmak üzere tasarlanmıştır. Uygulamalar genellikle NNAPI'yi doğrudan kullanmaz, bunun yerine daha üst düzey makine öğrenimi çerçevelerini kullanır. Bu çerçeveler de desteklenen cihazlarda donanım hızlandırmalı çıkarım işlemleri gerçekleştirmek için NNAPI'yi kullanabilir.
Android'in sinir ağı çalışma zamanı, bir uygulamanın gereksinimlerine ve Android cihazdaki donanım özelliklerine bağlı olarak hesaplama iş yükünü, özel sinir ağı donanımı, grafik işlem birimleri (GPU'lar) ve dijital sinyal işlemcileri (DSP'ler) dahil olmak üzere cihazdaki kullanılabilir işlemciler arasında verimli bir şekilde dağıtabilir.
Özel bir tedarikçi sürücüsü olmayan Android cihazlarda NNAPI çalışma zamanı, istekleri CPU üzerinde yürütür.
Şekil 1'de NNAPI'nin üst düzey sistem mimarisi gösterilmektedir.
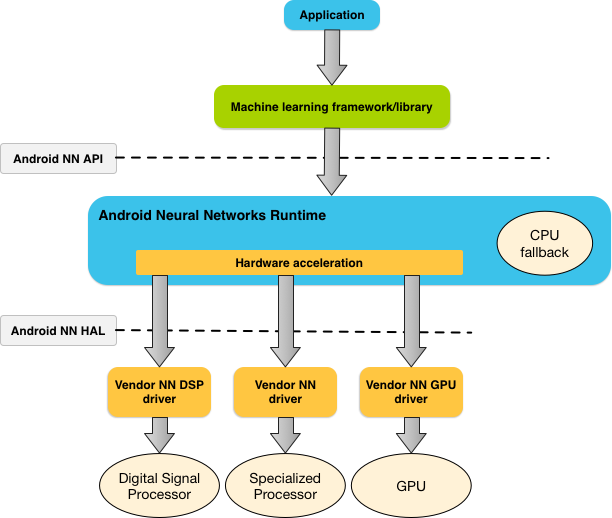
Neural Networks API programlama modeli
NNAPI kullanarak hesaplamalar yapmak için öncelikle gerçekleştirilecek hesaplamaları tanımlayan yönlendirilmiş bir grafik oluşturmanız gerekir. Bu hesaplama grafiği, giriş verilerinizle (örneğin, bir makine öğrenimi çerçevesinden aktarılan ağırlıklar ve önyargılar) birleştirilerek NNAPI çalışma zamanı değerlendirmesi için modeli oluşturur.
NNAPI dört ana soyutlama kullanır:
- Model: Matematiksel işlemlerin ve eğitim süreciyle öğrenilen sabit değerlerin hesaplama grafiği. Bu işlemler sinir ağlarına özeldir. Bunlar arasında 2 boyutlu (2D) evrişim, lojistik (sigmoid) etkinleştirme, düzeltilmiş doğrusal (ReLU) etkinleştirme ve daha fazlası yer alır. Model oluşturma eşzamanlı bir işlemdir.
Başarıyla oluşturulduktan sonra, iş parçacıklarında ve derlemelerde yeniden kullanılabilir.
NNAPI'de bir model,
ANeuralNetworksModelörneği olarak gösterilir. - Derleme: NNAPI modelini daha düşük düzeyli koda derlemeye yönelik bir yapılandırmayı temsil eder. Derleme oluşturma işlemi eşzamanlıdır. Başarıyla oluşturulduktan sonra, farklı iş parçacıkları ve yürütmelerde yeniden kullanılabilir. NNAPI'de her derleme bir
ANeuralNetworksCompilationörneği olarak gösterilir. - Bellek: Paylaşılan belleği, belleğe eşlenmiş dosyaları ve benzer bellek arabelleklerini temsil eder. Bellek arabelleği kullanmak, NNAPI çalışma zamanının verileri sürücülere daha verimli bir şekilde aktarmasını sağlar. Bir uygulama genellikle modeli tanımlamak için gereken tüm tensörleri içeren tek bir paylaşılan bellek arabelleği oluşturur. Yürütme örneğinin giriş ve çıkışlarını depolamak için bellek arabelleklerini de kullanabilirsiniz. NNAPI'de her bellek arabelleği bir
ANeuralNetworksMemoryörneği olarak gösterilir. Yürütme: NNAPI modelini bir dizi girişe uygulamak ve sonuçları toplamak için kullanılan arayüz. Yürütme eşzamanlı veya eşzamansız olarak gerçekleştirilebilir.
Eşzamansız yürütmede, birden fazla iş parçacığı aynı yürütmeyi bekleyebilir. Bu yürütme tamamlandığında tüm iş parçacıkları serbest bırakılır.
NNAPI'de her yürütme bir
ANeuralNetworksExecutionörneği olarak gösterilir.
Şekil 2'de temel programlama akışı gösterilmektedir.
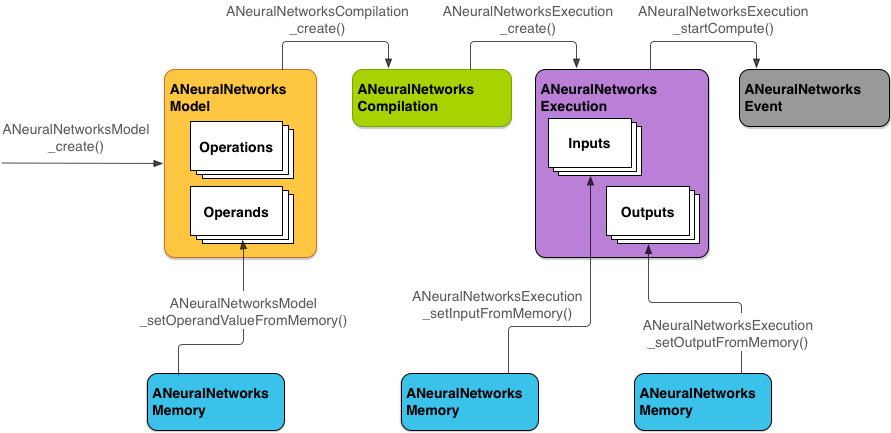
Bu bölümün geri kalanında, NNAPI modelinizi hesaplama yapacak, modeli derleyecek ve derlenen modeli yürütecek şekilde ayarlama adımları açıklanmaktadır.
Eğitim verilerine erişim sağlama
Eğitilmiş ağırlıklarınız ve önyargı verileriniz büyük olasılıkla bir dosyada saklanır. NNAPI çalışma zamanına bu verilere verimli bir şekilde erişim sağlamak için ANeuralNetworksMemory_createFromFd() işlevini çağırıp açılan veri dosyasının dosya tanımlayıcısını ileterek ANeuralNetworksMemory örneği oluşturun. Ayrıca, paylaşılan bellek bölgesinin dosyada başladığı yeri belirten bellek koruma işaretleri ve bir ofset de belirtirsiniz.
// Create a memory buffer from the file that contains the trained data
ANeuralNetworksMemory* mem1 = NULL;
int fd = open("training_data", O_RDONLY);
ANeuralNetworksMemory_createFromFd(file_size, PROT_READ, fd, 0, &mem1);
Bu örnekte tüm ağırlıklarımız için yalnızca bir ANeuralNetworksMemory örneği kullanmamıza rağmen, birden fazla dosya için birden fazla ANeuralNetworksMemory örneği kullanmak mümkündür.
Yerel donanım arabelleklerini kullanma
Model girişleri, çıkışları ve sabit işlenen değerleri için yerel donanım arabelleklerini kullanabilirsiniz. Bazı durumlarda, NNAPI hızlandırıcı, sürücünün verileri kopyalamasına gerek kalmadan AHardwareBuffer nesnelerine erişebilir. AHardwareBuffer çok sayıda farklı yapılandırmaya sahiptir ve her NNAPI hızlandırıcı bu yapılandırmaların tümünü desteklemeyebilir. Bu sınırlama nedeniyle, ANeuralNetworksMemory_createFromAHardwareBuffer referans belgelerinde listelenen kısıtlamalara bakın ve AHardwareBuffer kullanan derlemelerin ve yürütmelerin beklendiği gibi çalıştığından emin olmak için hedef cihazlarda önceden test edin. Hızlandırıcıyı belirtmek için cihaz atamayı kullanın.
NNAPI çalışma zamanının bir AHardwareBuffer nesnesine erişmesine izin vermek için aşağıdaki kod örneğinde gösterildiği gibi ANeuralNetworksMemory_createFromAHardwareBuffer işlevini çağırıp AHardwareBuffer nesnesini ileterek bir ANeuralNetworksMemory örneği oluşturun:
// Configure and create AHardwareBuffer object AHardwareBuffer_Desc desc = ... AHardwareBuffer* ahwb = nullptr; AHardwareBuffer_allocate(&desc, &ahwb); // Create ANeuralNetworksMemory from AHardwareBuffer ANeuralNetworksMemory* mem2 = NULL; ANeuralNetworksMemory_createFromAHardwareBuffer(ahwb, &mem2);
NNAPI'nin artık AHardwareBuffer nesnesine erişmesi gerekmediğinde ilgili ANeuralNetworksMemory örneğini serbest bırakın:
ANeuralNetworksMemory_free(mem2);
Not:
AHardwareBufferyalnızca arabelleğin tamamı için kullanılabilir.ARectparametresiyle kullanılamaz.- NNAPI çalışma zamanı arabelleği temizlemez. Yürütmeyi planlamadan önce giriş ve çıkış arabelleklerine erişilebildiğinden emin olmanız gerekir.
- Senkronizasyon bariyeri dosya tanımlayıcıları desteklenmez.
- Tedarikçiye özel biçimler ve kullanım bitleri içeren bir
AHardwareBufferiçin, önbelleğin temizlenmesinden istemcinin mi yoksa sürücünün mü sorumlu olduğunu belirlemek tedarikçi uygulamasına bağlıdır.
Model
Model, NNAPI'deki temel hesaplama birimidir. Her model bir veya daha fazla işlenen ve işlemle tanımlanır.
İşlenenler
İşlenenler, grafiği tanımlarken kullanılan veri nesneleridir. Bunlar arasında modelin giriş ve çıkışları, bir işlemden diğerine akan verileri içeren ara düğümler ve bu işlemlere aktarılan sabitler yer alır.
NNAPI modellerine eklenebilecek iki tür işlenen vardır: skalerler ve tensörler.
Skalar, tek bir değeri temsil eder. NNAPI, Boole, 16 bit kayan nokta, 32 bit kayan nokta, 32 bit tam sayı ve işaretsiz 32 bit tam sayı biçimlerindeki skaler değerleri destekler.
NNAPI'deki çoğu işlem tensörleri içerir. Tensörler, n boyutlu dizilerdir. NNAPI, 16 bit kayan nokta, 32 bit kayan nokta, 8 bit nicelendirilmiş, 16 bit nicelendirilmiş, 32 bit tam sayı ve 8 bit boole değerlerine sahip tensörleri destekler.
Örneğin, Şekil 3'te iki işlemli bir model gösterilmektedir: önce toplama, ardından çarpma. Model, giriş tensörü alıp bir çıkış tensörü oluşturur.
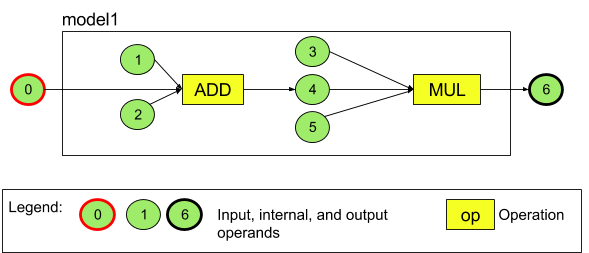
Yukarıdaki modelde yedi işlenen vardır. Bu işlenenler, modele eklendikleri sıranın diziniyle örtülü olarak tanımlanır. Eklenen ilk işlenenin dizini 0, ikincisinin dizini 1 vb. olur. 1, 2, 3 ve 5 numaralı işlenenler sabit işlenenlerdir.
İşlenenleri ekleme sıranız önemli değildir. Örneğin, model çıktısı işleneni ilk eklenen olabilir. Önemli olan, bir işlenene atıfta bulunurken doğru dizin değerini kullanmaktır.
İşlenenlerin türleri vardır. Bunlar, modele eklendiklerinde belirtilir.
Bir işlenen, modelin hem girişi hem de çıkışı olarak kullanılamaz.
Her işlenen, model girişi, sabit değer veya tam olarak bir işlemin çıkış işleneni olmalıdır.
İşlenenleri kullanma hakkında daha fazla bilgi için İşlenenler hakkında daha fazla bilgi başlıklı makaleye bakın.
İşlemler
İşlem, gerçekleştirilecek hesaplamaları belirtir. Her işlem şu öğelerden oluşur:
- işlem türü (örneğin, toplama, çarpma, konvolüsyon),
- işlemin giriş için kullandığı işlenenlerin dizinlerinin listesi ve
- İşlemin çıkış için kullandığı işlenenlerin dizinlerinin listesi.
Bu listelerdeki sıra önemlidir. Her işlem türünün beklenen giriş ve çıkışları için NNAPI API referansına bakın.
Bir işlemi eklemeden önce, işlemin kullandığı veya ürettiği işlenenleri modele eklemeniz gerekir.
İşlemleri ekleme sıranız önemli değildir. NNAPI, işlemleri hangi sırayla yürüteceğini belirlemek için işlenenlerin ve işlemlerin hesaplama grafiği tarafından oluşturulan bağımlılıklardan yararlanır.
NNAPI'nin desteklediği işlemler aşağıdaki tabloda özetlenmiştir:
API düzeyi 28'deki bilinen sorun: Android 9 (API düzeyi 28) ve sonraki sürümlerde kullanılabilen ANEURALNETWORKS_TENSOR_QUANT8_ASYMM
tensörleri ANEURALNETWORKS_PAD
işlemine iletirken NNAPI'nin çıkışı, TensorFlow Lite gibi daha üst düzey makine öğrenimi çerçevelerinin çıkışıyla eşleşmeyebilir. Bunun yerine yalnızca ANEURALNETWORKS_TENSOR_FLOAT32 değerini iletmeniz gerekir.
Bu sorun, Android 10 (API düzeyi 29) ve sonraki sürümlerde giderilmiştir.
Model oluşturma
Aşağıdaki örnekte, Şekil 3'te bulunan iki işlemli modeli oluşturuyoruz.
Modeli oluşturmak için aşağıdaki adımları uygulayın:
Boş bir model tanımlamak için
ANeuralNetworksModel_create()işlevini çağırın.ANeuralNetworksModel* model = NULL; ANeuralNetworksModel_create(&model);
ANeuralNetworks_addOperand()işlevini çağırarak işlenenleri modelinize ekleyin. Veri türleri,ANeuralNetworksOperandTypeveri yapısı kullanılarak tanımlanır.// In our example, all our tensors are matrices of dimension [3][4] ANeuralNetworksOperandType tensor3x4Type; tensor3x4Type.type = ANEURALNETWORKS_TENSOR_FLOAT32; tensor3x4Type.scale = 0.f; // These fields are used for quantized tensors tensor3x4Type.zeroPoint = 0; // These fields are used for quantized tensors tensor3x4Type.dimensionCount = 2; uint32_t dims[2] = {3, 4}; tensor3x4Type.dimensions = dims;
// We also specify operands that are activation function specifiers ANeuralNetworksOperandType activationType; activationType.type = ANEURALNETWORKS_INT32; activationType.scale = 0.f; activationType.zeroPoint = 0; activationType.dimensionCount = 0; activationType.dimensions = NULL;
// Now we add the seven operands, in the same order defined in the diagram ANeuralNetworksModel_addOperand(model, &tensor3x4Type); // operand 0 ANeuralNetworksModel_addOperand(model, &tensor3x4Type); // operand 1 ANeuralNetworksModel_addOperand(model, &activationType); // operand 2 ANeuralNetworksModel_addOperand(model, &tensor3x4Type); // operand 3 ANeuralNetworksModel_addOperand(model, &tensor3x4Type); // operand 4 ANeuralNetworksModel_addOperand(model, &activationType); // operand 5 ANeuralNetworksModel_addOperand(model, &tensor3x4Type); // operand 6Uygulamanızın bir eğitim sürecinden elde ettiği ağırlıklar ve önyargılar gibi sabit değerlere sahip işlenenler için
ANeuralNetworksModel_setOperandValue()veANeuralNetworksModel_setOperandValueFromMemory()işlevlerini kullanın.Aşağıdaki örnekte, Eğitim verilerine erişim sağlama bölümünde oluşturduğumuz bellek arabelleğine karşılık gelen eğitim verileri dosyasından sabit değerler ayarlıyoruz.
// In our example, operands 1 and 3 are constant tensors whose values were // established during the training process const int sizeOfTensor = 3 * 4 * 4; // The formula for size calculation is dim0 * dim1 * elementSize ANeuralNetworksModel_setOperandValueFromMemory(model, 1, mem1, 0, sizeOfTensor); ANeuralNetworksModel_setOperandValueFromMemory(model, 3, mem1, sizeOfTensor, sizeOfTensor);
// We set the values of the activation operands, in our example operands 2 and 5 int32_t noneValue = ANEURALNETWORKS_FUSED_NONE; ANeuralNetworksModel_setOperandValue(model, 2, &noneValue, sizeof(noneValue)); ANeuralNetworksModel_setOperandValue(model, 5, &noneValue, sizeof(noneValue));Yönlendirilmiş grafikte hesaplamak istediğiniz her işlem için
ANeuralNetworksModel_addOperation()işlevini çağırarak işlemi modelinize ekleyin.Uygulamanız, bu çağrıya parametre olarak şunları sağlamalıdır:
- İşlem türü
- giriş değerlerinin sayısı
- giriş işlenenleri için dizin dizisi
- çıkış değerlerinin sayısı
- Çıkış işlenenleri için dizin dizisi
Bir işlenenin aynı işlemin hem girişi hem de çıkışı için kullanılamayacağını unutmayın.
// We have two operations in our example // The first consumes operands 1, 0, 2, and produces operand 4 uint32_t addInputIndexes[3] = {1, 0, 2}; uint32_t addOutputIndexes[1] = {4}; ANeuralNetworksModel_addOperation(model, ANEURALNETWORKS_ADD, 3, addInputIndexes, 1, addOutputIndexes);
// The second consumes operands 3, 4, 5, and produces operand 6 uint32_t multInputIndexes[3] = {3, 4, 5}; uint32_t multOutputIndexes[1] = {6}; ANeuralNetworksModel_addOperation(model, ANEURALNETWORKS_MUL, 3, multInputIndexes, 1, multOutputIndexes);ANeuralNetworksModel_identifyInputsAndOutputs()işlevini çağırarak modelin hangi işlenenleri giriş ve çıkış olarak ele alması gerektiğini belirleyin.// Our model has one input (0) and one output (6) uint32_t modelInputIndexes[1] = {0}; uint32_t modelOutputIndexes[1] = {6}; ANeuralNetworksModel_identifyInputsAndOutputs(model, 1, modelInputIndexes, 1 modelOutputIndexes);
İsteğe bağlı olarak,
ANeuralNetworksModel_relaxComputationFloat32toFloat16()çağrılarakANEURALNETWORKS_TENSOR_FLOAT32'ın IEEE 754 16 bit kayan nokta biçiminin aralığı veya hassasiyeti kadar düşük bir aralık ya da hassasiyetle hesaplanmasına izin verilip verilmeyeceğini belirtin.Modelinizin tanımını tamamlamak için
ANeuralNetworksModel_finish()numaralı telefonu arayın. Hata yoksa bu işlevANEURALNETWORKS_NO_ERRORsonuç kodunu döndürür.ANeuralNetworksModel_finish(model);
Model oluşturduktan sonra istediğiniz kadar derleyebilir ve her derlemeyi istediğiniz kadar çalıştırabilirsiniz.
Kontrol akışı
NNAPI modeline kontrol akışı eklemek için aşağıdakileri yapın:
İlgili yürütme alt grafikleri (
IFifadesi içinthenveelsealt grafikleri,WHILEdöngüsü içinconditionvebodyalt grafikleri) bağımsızANeuralNetworksModel*modelleri olarak oluşturun:ANeuralNetworksModel* thenModel = makeThenModel(); ANeuralNetworksModel* elseModel = makeElseModel();
Kontrol akışını içeren modelde bu modellere referans veren işlenenler oluşturun:
ANeuralNetworksOperandType modelType = { .type = ANEURALNETWORKS_MODEL, }; ANeuralNetworksModel_addOperand(model, &modelType); // kThenOperandIndex ANeuralNetworksModel_addOperand(model, &modelType); // kElseOperandIndex ANeuralNetworksModel_setOperandValueFromModel(model, kThenOperandIndex, &thenModel); ANeuralNetworksModel_setOperandValueFromModel(model, kElseOperandIndex, &elseModel);
Kontrol akışı işlemini ekleyin:
uint32_t inputs[] = {kConditionOperandIndex, kThenOperandIndex, kElseOperandIndex, kInput1, kInput2, kInput3}; uint32_t outputs[] = {kOutput1, kOutput2}; ANeuralNetworksModel_addOperation(model, ANEURALNETWORKS_IF, std::size(inputs), inputs, std::size(output), outputs);
Derleme
Derleme adımı, modelinizin hangi işlemcilerde yürütüleceğini belirler ve ilgili sürücülerden yürütmeye hazırlanmalarını ister. Bu, modelinizin üzerinde çalışacağı işlemcilere özel makine kodunun oluşturulmasını içerebilir.
Bir modeli derlemek için aşağıdaki adımları uygulayın:
Yeni bir derleme örneği oluşturmak için
ANeuralNetworksCompilation_create()işlevini çağırın.// Compile the model ANeuralNetworksCompilation* compilation; ANeuralNetworksCompilation_create(model, &compilation);
İsteğe bağlı olarak, hangi cihazlarda yürütüleceğini açıkça seçmek için cihaz atama özelliğini kullanabilirsiniz.
İsteğe bağlı olarak, çalışma zamanının pil gücü kullanımı ile yürütme hızı arasında nasıl bir denge kuracağını etkileyebilirsiniz. Bunu yapmak için
ANeuralNetworksCompilation_setPreference()işlevini çağırabilirsiniz.// Ask to optimize for low power consumption ANeuralNetworksCompilation_setPreference(compilation, ANEURALNETWORKS_PREFER_LOW_POWER);
Belirtebileceğiniz tercihler şunlardır:
ANEURALNETWORKS_PREFER_LOW_POWER: Pilin hızlı tükenmesini en aza indirecek şekilde yürütmeyi tercih edin. Bu, sık sık yürütülen derlemeler için tercih edilir.ANEURALNETWORKS_PREFER_FAST_SINGLE_ANSWER: Daha fazla güç tüketimine neden olsa bile tek bir yanıtı mümkün olduğunca hızlı döndürmeyi tercih edin. Bu, varsayılan seçenektir.ANEURALNETWORKS_PREFER_SUSTAINED_SPEED: Kameradan gelen ardışık kareleri işlerken olduğu gibi, ardışık karelerin işleme hızını en üst düzeye çıkarmayı tercih edin.
İsteğe bağlı olarak,
ANeuralNetworksCompilation_setCachingişlevini çağırarak derleme önbelleğe almayı ayarlayabilirsiniz.// Set up compilation caching ANeuralNetworksCompilation_setCaching(compilation, cacheDir, token);
cacheDiriçingetCodeCacheDir()kullanın. Belirtilentoken, uygulamadaki her model için benzersiz olmalıdır.ANeuralNetworksCompilation_finish()işlevini çağırarak derleme tanımını tamamlayın. Hata yoksa bu işlevANEURALNETWORKS_NO_ERRORsonuç kodunu döndürür.ANeuralNetworksCompilation_finish(compilation);
Cihaz bulma ve atama
Android 10 (API düzeyi 29) ve sonraki sürümleri çalıştıran Android cihazlarda NNAPI, makine öğrenimi çerçevesi kitaplıklarının ve uygulamalarının kullanılabilir cihazlar hakkında bilgi edinmesine ve yürütme için kullanılacak cihazları belirtmesine olanak tanıyan işlevler sağlar. Kullanılabilir cihazlar hakkında bilgi sağlamak, uygulamaların bilinen uyumsuzlukları önlemek için cihazda bulunan sürücülerin tam sürümünü almasına olanak tanır. Uygulamalara, bir modelin farklı bölümlerinin hangi cihazlarda yürütüleceğini belirtme olanağı tanıyarak uygulamalar, dağıtıldıkları Android cihaz için optimize edilebilir.
Cihaz bulma
Kullanılabilir cihaz sayısını almak için
ANeuralNetworks_getDeviceCount
kullanın. Her cihaz için ANeuralNetworksDevice örneğini söz konusu cihaza referans olarak ayarlamak üzere ANeuralNetworks_getDevice kullanın.
Cihaz referansınız olduğunda aşağıdaki işlevleri kullanarak söz konusu cihaz hakkında ek bilgiler edinebilirsiniz:
ANeuralNetworksDevice_getFeatureLevelANeuralNetworksDevice_getNameANeuralNetworksDevice_getTypeANeuralNetworksDevice_getVersion
Cihaz atama
Bir modelin hangi işlemlerinin belirli cihazlarda çalıştırılabileceğini öğrenmek için ANeuralNetworksModel_getSupportedOperationsForDevices öğesini kullanın.
Yürütme için hangi hızlandırıcıların kullanılacağını kontrol etmek üzere ANeuralNetworksCompilation_create yerine ANeuralNetworksCompilation_createForDevices çağrısı yapın.
Elde edilen ANeuralNetworksCompilation nesnesini normal şekilde kullanın.
Sağlanan model, seçili cihazlar tarafından desteklenmeyen işlemler içeriyorsa işlev hata döndürür.
Birden fazla cihaz belirtilirse çalışma zamanı, işi cihazlara dağıtmaktan sorumludur.
Diğer cihazlara benzer şekilde, NNAPI CPU uygulaması nnapi-reference adlı ve ANEURALNETWORKS_DEVICE_TYPE_CPU türünde bir ANeuralNetworksDevice ile temsil edilir. ANeuralNetworksCompilation_createForDevices çağrıldığında, model derleme ve yürütme ile ilgili hata durumlarını işlemek için CPU uygulaması kullanılmaz.
Bir modeli, belirtilen cihazlarda çalışabilecek alt modellere bölmek uygulamanın sorumluluğundadır. Manuel bölümleme yapması gerekmeyen uygulamalar, modeli hızlandırmak için mevcut tüm cihazları (CPU dahil) kullanmak üzere daha basit olan ANeuralNetworksCompilation_create işlevini çağırmaya devam etmelidir. Model, ANeuralNetworksCompilation_createForDevices kullanılarak belirttiğiniz cihazlar tarafından tam olarak desteklenemiyorsa
ANEURALNETWORKS_BAD_DATA
değeri döndürülür.
Model bölümlendirme
Model için birden fazla cihaz kullanılabiliyorsa NNAPI çalışma zamanı, işi cihazlar arasında dağıtır. Örneğin, ANeuralNetworksCompilation_createForDevices kullanıcısına birden fazla cihaz sağlandıysa işi atarken belirtilen tüm cihazlar dikkate alınır. CPU cihazı listede yoksa CPU yürütme işleminin devre dışı bırakılacağını unutmayın. ANeuralNetworksCompilation_create kullanılırken CPU da dahil olmak üzere tüm kullanılabilir cihazlar dikkate alınır.
Dağıtım, modeldeki işlemlerin her biri için kullanılabilir cihazlar listesinden seçim yapılarak gerçekleştirilir. Bu seçimde, işlemi destekleyen ve en iyi performansı (yani, istemci tarafından belirtilen yürütme tercihine bağlı olarak en hızlı yürütme süresi veya en düşük güç tüketimi) sağlayan cihaz dikkate alınır. Bu bölümlendirme algoritması, farklı işlemciler arasındaki G/Ç'den kaynaklanan olası verimsizlikleri hesaba katmaz. Bu nedenle, birden fazla işlemci belirtirken (ANeuralNetworksCompilation_createForDevices kullanılırken açıkça veya ANeuralNetworksCompilation_create kullanılırken örtülü olarak) ortaya çıkan uygulamanın profilini oluşturmak önemlidir.
Modelinizin NNAPI tarafından nasıl bölümlendirildiğini anlamak için Android günlüklerinde şu etikete sahip bir mesajı (INFO düzeyinde) kontrol edin:ExecutionPlan
ModelBuilder::findBestDeviceForEachOperation(op-name): device-index
op-name, grafikteki işlemin açıklayıcı adıdır ve device-index, cihaz listesindeki aday cihazın dizinidir.
Bu liste, ANeuralNetworksCompilation_createForDevices için sağlanan giriş veya ANeuralNetworksCompilation_createForDevices kullanılıyorsa ANeuralNetworks_getDeviceCount ve ANeuralNetworks_getDevice kullanılarak tüm cihazlar üzerinde yineleme yapıldığında döndürülen cihaz listesidir.
İleti (ExecutionPlan etiketiyle INFO düzeyinde):
ModelBuilder::partitionTheWork: only one best device: device-name
Bu mesaj, grafiğin tamamının cihazda hızlandırıldığını gösterir
device-name.
Yürütme
Yürütme adımı, modeli bir dizi girişe uygular ve hesaplama çıkışlarını uygulamanızın ayırdığı bir veya daha fazla kullanıcı arabelleğinde ya da bellek alanında saklar.
Derlenmiş bir modeli çalıştırmak için aşağıdaki adımları uygulayın:
Yeni bir yürütme örneği oluşturmak için
ANeuralNetworksExecution_create()işlevini çağırın.// Run the compiled model against a set of inputs ANeuralNetworksExecution* run1 = NULL; ANeuralNetworksExecution_create(compilation, &run1);
Uygulamanızın hesaplama için giriş değerlerini nereden okuduğunu belirtin. Uygulamanız, sırasıyla
ANeuralNetworksExecution_setInput()veyaANeuralNetworksExecution_setInputFromMemory()çağrılarını yaparak giriş değerlerini kullanıcı arabelleğinden ya da ayrılmış bir bellek alanından okuyabilir.// Set the single input to our sample model. Since it is small, we won't use a memory buffer float32 myInput[3][4] = { ...the data... }; ANeuralNetworksExecution_setInput(run1, 0, NULL, myInput, sizeof(myInput));
Uygulamanızın çıkış değerlerini nereye yazdığını belirtin. Uygulamanız, sırasıyla
ANeuralNetworksExecution_setOutput()veyaANeuralNetworksExecution_setOutputFromMemory()çağırarak çıkış değerlerini kullanıcı arabelleğine ya da ayrılmış bir bellek alanına yazabilir.// Set the output float32 myOutput[3][4]; ANeuralNetworksExecution_setOutput(run1, 0, NULL, myOutput, sizeof(myOutput));
ANeuralNetworksExecution_startCompute()işlevini çağırarak yürütmenin başlatılmasını planlayın. Hata yoksa bu işlevANEURALNETWORKS_NO_ERRORsonuç kodunu döndürür.// Starts the work. The work proceeds asynchronously ANeuralNetworksEvent* run1_end = NULL; ANeuralNetworksExecution_startCompute(run1, &run1_end);
Yürütmenin tamamlanmasını beklemek için
ANeuralNetworksEvent_wait()işlevini çağırın. Yürütme başarılı olursa bu işlevANEURALNETWORKS_NO_ERRORsonuç kodunu döndürür. Bekleme, yürütmeyi başlatan iş parçacığından farklı bir iş parçacığında yapılabilir.// For our example, we have no other work to do and will just wait for the completion ANeuralNetworksEvent_wait(run1_end); ANeuralNetworksEvent_free(run1_end); ANeuralNetworksExecution_free(run1);
İsteğe bağlı olarak, yeni bir
ANeuralNetworksExecutionörneği oluşturmak için aynı derleme örneğini kullanarak derlenmiş modele farklı bir giriş grubu uygulayabilirsiniz.// Apply the compiled model to a different set of inputs ANeuralNetworksExecution* run2; ANeuralNetworksExecution_create(compilation, &run2); ANeuralNetworksExecution_setInput(run2, ...); ANeuralNetworksExecution_setOutput(run2, ...); ANeuralNetworksEvent* run2_end = NULL; ANeuralNetworksExecution_startCompute(run2, &run2_end); ANeuralNetworksEvent_wait(run2_end); ANeuralNetworksEvent_free(run2_end); ANeuralNetworksExecution_free(run2);
Eşzamanlı yürütme
Eşzamansız yürütme, iş parçacıklarını oluşturmak ve senkronize etmek için zaman harcar. Ayrıca, gecikme çok değişken olabilir. Bir iş parçacığına bildirim gönderildiği veya iş parçacığı uyandırıldığı zaman ile iş parçacığının sonunda bir CPU çekirdeğine bağlandığı zaman arasında en uzun gecikmeler 500 mikrosaniyeye kadar çıkabilir.
Gecikmeyi azaltmak için bunun yerine bir uygulamayı, çalışma zamanına senkron çıkarım çağrısı yapmaya yönlendirebilirsiniz. Bu çağrı, çıkarım başlatıldıktan sonra değil, yalnızca çıkarım tamamlandıktan sonra döndürülür. Uygulama, çalışma zamanına eşzamansız çıkarım çağrısı yapmak için ANeuralNetworksExecution_startCompute yerine çalışma zamanına eşzamanlı çağrı yapmak için ANeuralNetworksExecution_compute yöntemini çağırır. ANeuralNetworksExecution_compute numarasına yapılan bir çağrı ANeuralNetworksEvent almaz ve ANeuralNetworksEvent_wait numarasına yapılan bir çağrı ile eşleştirilmez.
Ani yürütmeler
Android 10 (API düzeyi 29) ve sonraki sürümleri çalıştıran Android cihazlarda NNAPI, ANeuralNetworksBurst nesnesi aracılığıyla toplu yürütmeleri destekler. Patlama yürütmeleri, aynı derlemenin hızlı bir şekilde gerçekleşen yürütme dizileridir. Örneğin, kamera çekiminin kareleri veya ardışık ses örnekleri üzerinde çalışanlar. ANeuralNetworksBurst nesnelerinin kullanılması, hızlandırıcıların kaynakların yürütmeler arasında yeniden kullanılabileceğini ve hızlandırıcıların patlama süresi boyunca yüksek performans durumunda kalması gerektiğini belirtmesi nedeniyle daha hızlı yürütmelere yol açabilir.
ANeuralNetworksBurst normal yürütme yolunda yalnızca küçük bir değişiklik yapar. Aşağıdaki kod snippet'inde gösterildiği gibi, ANeuralNetworksBurst_create kullanarak bir patlama nesnesi oluşturursunuz:
// Create burst object to be reused across a sequence of executions ANeuralNetworksBurst* burst = NULL; ANeuralNetworksBurst_create(compilation, &burst);
Toplu yürütmeler eşzamanlıdır. Ancak her çıkarımı gerçekleştirmek için
ANeuralNetworksExecution_compute
kullanmak yerine, çeşitli
ANeuralNetworksExecution
nesneleri ANeuralNetworksBurst ile aynı ANeuralNetworksBurst ile eşleştirirsiniz.ANeuralNetworksExecution_burstCompute
// Create and configure first execution object // ... // Execute using the burst object ANeuralNetworksExecution_burstCompute(execution1, burst); // Use results of first execution and free the execution object // ... // Create and configure second execution object // ... // Execute using the same burst object ANeuralNetworksExecution_burstCompute(execution2, burst); // Use results of second execution and free the execution object // ...
Artık ihtiyaç duyulmadığında ANeuralNetworksBurst nesnesini ANeuralNetworksBurst_free ile serbest bırakın.
// Cleanup ANeuralNetworksBurst_free(burst);
Eşzamansız komut sıraları ve sınırlı yürütme
Android 11 ve sonraki sürümlerde NNAPI, ANeuralNetworksExecution_startComputeWithDependencies() yöntemiyle eşzamansız yürütmeyi zamanlamak için ek bir yol sunar. Bu yöntemi kullandığınızda yürütme, değerlendirmeye başlamadan önce bağımlı tüm etkinliklerin sinyal vermesini bekler. Yürütme tamamlandıktan ve çıkışlar tüketilmeye hazır olduktan sonra döndürülen etkinlik işaretlenir.
Etkinliğin yürütülmesini hangi cihazların işlediğine bağlı olarak, etkinlik bir senkronizasyon bariyeri ile desteklenebilir. Etkinliğin beklenmesi ve yürütme sırasında kullanılan kaynakların geri alınması için ANeuralNetworksEvent_wait() numaralı telefonu aramanız gerekir. ANeuralNetworksEvent_createFromSyncFenceFd() kullanarak senkronizasyon çitlerini bir etkinlik nesnesine aktarabilir ve ANeuralNetworksEvent_getSyncFenceFd() kullanarak senkronizasyon çitlerini bir etkinlik nesnesinden dışa aktarabilirsiniz.
Dinamik olarak boyutlandırılmış çıkışlar
Çıkış boyutunun giriş verilerine bağlı olduğu (yani boyutun model yürütme sırasında belirlenemediği) modelleri desteklemek için ANeuralNetworksExecution_getOutputOperandRank ve ANeuralNetworksExecution_getOutputOperandDimensions kullanın.
Aşağıdaki kod örneğinde bu işlemin nasıl yapılacağı gösterilmektedir:
// Get the rank of the output uint32_t myOutputRank = 0; ANeuralNetworksExecution_getOutputOperandRank(run1, 0, &myOutputRank); // Get the dimensions of the output std::vector<uint32_t> myOutputDimensions(myOutputRank); ANeuralNetworksExecution_getOutputOperandDimensions(run1, 0, myOutputDimensions.data());
Temizleme
Temizleme adımı, hesaplamanız için kullanılan dahili kaynakların serbest bırakılmasını sağlar.
// Cleanup ANeuralNetworksCompilation_free(compilation); ANeuralNetworksModel_free(model); ANeuralNetworksMemory_free(mem1);
Hata yönetimi ve CPU yedeklemesi
Bölümleme sırasında hata oluşursa, bir sürücü bir modeli (bir bölümünü) derleyemezse veya bir sürücü derlenmiş bir modeli (bir bölümünü) yürütemezse NNAPI, bir veya daha fazla işlemin kendi CPU uygulamasına geri dönebilir.
NNAPI istemcisi, işlemin optimize edilmiş sürümlerini (ör. TFLite) içeriyorsa CPU geri dönüşünü devre dışı bırakmak ve hataları istemcinin optimize edilmiş işlem uygulamasıyla ele almak avantajlı olabilir.
Android 10'da derleme ANeuralNetworksCompilation_createForDevices kullanılarak gerçekleştirilirse CPU geri dönüşü devre dışı bırakılır.
Android P'de, sürücüde yürütme başarısız olursa NNAPI yürütmesi CPU'ya geri döner.
Bu durum, Android 10'da ANeuralNetworksCompilation_createForDevices yerine ANeuralNetworksCompilation_create kullanıldığında da geçerlidir.
İlk yürütme, söz konusu tek bölüm için geri döner ve bu işlem yine başarısız olursa modelin tamamı CPU'da yeniden denenir.
Bölümleme veya derleme başarısız olursa modelin tamamı CPU'da denenir.
Bazı işlemlerin CPU'da desteklenmediği durumlar vardır. Bu gibi durumlarda, geri dönüş yapmak yerine derleme veya yürütme işlemi başarısız olur.
CPU yedeklemesi devre dışı bırakıldıktan sonra bile modelde CPU'da planlanan işlemler olabilir. CPU, ANeuralNetworksCompilation_createForDevices'ya sağlanan işlemciler listesinde yer alıyorsa ve bu işlemleri destekleyen tek işlemciyse veya bu işlemler için en iyi performansı sağladığı iddia edilen işlemciyse birincil (yedek olmayan) yürütücü olarak seçilir.
CPU yürütülmediğinden emin olmak için ANeuralNetworksCompilation_createForDevices kullanın ve nnapi-reference cihaz listesinden çıkarın.
Android P'den itibaren, debug.nn.partition özelliği 2 olarak ayarlanarak DEBUG derlemelerinde yürütme sırasında geri dönüş devre dışı bırakılabilir.
Anı alanları
Android 11 ve sonraki sürümlerde NNAPI, opak bellekler için ayırıcı arayüzleri sağlayan bellek alanlarını destekler. Bu, uygulamaların cihazda yerel bellekleri yürütmeler arasında aktarmasına olanak tanır. Böylece NNAPI, aynı sürücüde art arda yürütmeler gerçekleştirirken verileri gereksiz yere kopyalamaz veya dönüştürmez.
Bellek alanı özelliği, çoğunlukla sürücüye ait olan ve istemci tarafına sık erişim gerektirmeyen tensörler için tasarlanmıştır. Bu tür tensörlere örnek olarak, sıralı modellerdeki durum tensörleri verilebilir. İstemci tarafında sık sık CPU erişimi gerektiren tensörler için bunun yerine paylaşılan bellek havuzlarını kullanın.
Opak bellek ayırmak için aşağıdaki adımları uygulayın:
Yeni bir bellek tanımlayıcısı oluşturmak için
ANeuralNetworksMemoryDesc_create()işlevini çağırın:// Create a memory descriptor ANeuralNetworksMemoryDesc* desc; ANeuralNetworksMemoryDesc_create(&desc);
ANeuralNetworksMemoryDesc_addInputRole()veANeuralNetworksMemoryDesc_addOutputRole()çağırarak amaçlanan tüm giriş ve çıkış rollerini belirtin.// Specify that the memory may be used as the first input and the first output // of the compilation ANeuralNetworksMemoryDesc_addInputRole(desc, compilation, 0, 1.0f); ANeuralNetworksMemoryDesc_addOutputRole(desc, compilation, 0, 1.0f);
İsteğe bağlı olarak,
ANeuralNetworksMemoryDesc_setDimensions()işlevini çağırarak bellek boyutlarını belirtebilirsiniz.// Specify the memory dimensions uint32_t dims[] = {3, 4}; ANeuralNetworksMemoryDesc_setDimensions(desc, 2, dims);
ANeuralNetworksMemoryDesc_finish()numaralı telefonu arayarak tanımlayıcı tanımını tamamlayın.ANeuralNetworksMemoryDesc_finish(desc);
Tanımlayıcıyı
ANeuralNetworksMemory_createFromDesc()işlevine ileterek istediğiniz kadar bellek ayırın.// Allocate two opaque memories with the descriptor ANeuralNetworksMemory* opaqueMem; ANeuralNetworksMemory_createFromDesc(desc, &opaqueMem);
Artık ihtiyacınız kalmadığında bellek tanımlayıcısını serbest bırakın.
ANeuralNetworksMemoryDesc_free(desc);
Müşteri, oluşturulan ANeuralNetworksMemory nesnesini yalnızca ANeuralNetworksMemoryDesc nesnesinde belirtilen roller uyarınca ANeuralNetworksExecution_setInputFromMemory() veya ANeuralNetworksExecution_setOutputFromMemory() ile birlikte kullanabilir. Belleğin tamamının kullanıldığını belirtmek için uzaklık ve uzunluk bağımsız değişkenleri 0 olarak ayarlanmalıdır. İstemci, ANeuralNetworksMemory_copy() kullanarak belleğin içeriğini açıkça ayarlayabilir veya çıkarabilir.
Belirtilmemiş boyut veya sıralamaya sahip rollerle opak anılar oluşturabilirsiniz.
Bu durumda, temel sürücü tarafından desteklenmiyorsa bellek oluşturma işlemi ANEURALNETWORKS_OP_FAILED durumuyla başarısız olabilir. İstemcinin, Ashmem veya BLOB modu AHardwareBuffer tarafından desteklenen yeterince büyük bir arabellek ayırarak yedek mantığı uygulaması önerilir.
NNAPI'nin artık opak bellek nesnesine erişmesi gerekmediğinde ilgili ANeuralNetworksMemory örneğini serbest bırakın:
ANeuralNetworksMemory_free(opaqueMem);
Performans ölçme
Yürütme süresini ölçerek veya profil oluşturarak uygulamanızın performansını değerlendirebilirsiniz.
Yürütme süresi
Toplam yürütme süresini çalışma zamanı üzerinden belirlemek istediğinizde senkron yürütme API'sini kullanabilir ve çağrının ne kadar sürdüğünü ölçebilirsiniz. Yazılım yığını daha düşük bir seviyesinde toplam yürütme süresini belirlemek istediğinizde aşağıdakileri elde etmek için ANeuralNetworksExecution_setMeasureTiming ve ANeuralNetworksExecution_getDuration kullanabilirsiniz:
- Hızlandırıcıda yürütme süresi (ana makine işlemcisinde çalışan sürücüde değil).
- Hızlandırıcıda geçen süre dahil olmak üzere sürücüdeki yürütme süresi.
Sürücüdeki yürütme süresine, çalışma zamanının kendisi ve çalışma zamanının sürücüyle iletişim kurması için gereken IPC gibi ek yükler dahil değildir.
Bu API'ler, sürücü veya hızlandırıcının çıkarım gerçekleştirmek için ayırdığı ve bağlam değiştirme nedeniyle kesintiye uğrayabilen süreyi değil, gönderilen çalışma ile tamamlanan çalışma etkinlikleri arasındaki süreyi ölçer.
Örneğin, 1. çıkarım başlatılırsa sürücü 2. çıkarımı gerçekleştirmek için çalışmayı durdurur, ardından 1. çıkarımı devam ettirip tamamlar. Bu durumda, 1. çıkarımın yürütme süresine 2. çıkarımı gerçekleştirmek için çalışmanın durdurulduğu süre de dahil edilir.
Bu zamanlama bilgileri, çevrimdışı kullanım için telemetri verileri toplayan bir uygulamanın üretim dağıtımı için yararlı olabilir. Zamanlama verilerini, uygulamayı daha yüksek performans için değiştirmek üzere kullanabilirsiniz.
Bu işlevi kullanırken aşağıdakileri göz önünde bulundurun:
- Zamanlama bilgilerinin toplanması performans maliyetine neden olabilir.
- NNAPI çalışma zamanında ve IPC'de harcanan süre hariç olmak üzere, kendi içinde veya hızlandırıcıda harcanan süreyi yalnızca bir sürücü hesaplayabilir.
- Bu API'leri yalnızca
numDevices = 1ileANeuralNetworksCompilation_createForDeviceskullanılarak oluşturulmuş birANeuralNetworksExecutionile kullanabilirsiniz. - Zamanlama bilgilerini bildirmek için sürücü gerekmez.
Android Systrace ile uygulamanızın profilini oluşturma
Android 10'dan itibaren NNAPI, uygulamanızın profilini oluşturmak için kullanabileceğiniz systrace etkinliklerini otomatik olarak oluşturur.
NNAPI Kaynağı, uygulamanız tarafından oluşturulan systrace etkinliklerini işlemek ve model yaşam döngüsünün farklı aşamalarında (örneği oluşturma, hazırlama, derleme yürütme ve sonlandırma) ve uygulamaların farklı katmanlarında harcanan süreyi gösteren bir tablo görünümü oluşturmak için parse_systrace yardımcı programıyla birlikte gelir. Uygulamanızın bölündüğü katmanlar şunlardır:
Application: ana uygulama koduRuntime: NNAPI Çalışma ZamanıIPC: NNAPI Çalışma Zamanı ile Sürücü kodu arasındaki süreçler arası iletişimDriver: hızlandırıcı sürücü süreci.
Profillendirme analizi verilerini oluşturma
AOSP kaynak ağacını $ANDROID_BUILD_TOP konumunda kontrol ettiğinizi ve hedef uygulama olarak TFLite görüntü sınıflandırma örneğini kullandığınızı varsayarsak aşağıdaki adımları uygulayarak NNAPI profil oluşturma verilerini oluşturabilirsiniz:
- Aşağıdaki komutla Android systrace'i başlatın:
$ANDROID_BUILD_TOP/external/chromium-trace/systrace.py -o trace.html -a org.tensorflow.lite.examples.classification nnapi hal freq sched idle load binder_driver
-o trace.html parametresi, izlerin trace.html içine yazılacağını gösterir. Kendi uygulamanızın profilini oluştururken org.tensorflow.lite.examples.classification yerine uygulama manifestinizde belirtilen işlem adını girmeniz gerekir.
Bu işlem, kabuk konsolunuzdan birini meşgul eder. Komut, enter tuşuna basılmasını beklediği için komutu arka planda çalıştırmayın.
- Systrace toplayıcı başlatıldıktan sonra uygulamanızı başlatın ve karşılaştırma testinizi çalıştırın.
Bizim örneğimizde, uygulama zaten yüklüyse Görüntü Sınıflandırma uygulamasını Android Studio'dan veya doğrudan test telefonunuzun kullanıcı arayüzünden başlatabilirsiniz. Bazı NNAPI verilerini oluşturmak için uygulama yapılandırma iletişim kutusunda hedef cihaz olarak NNAPI'yi seçerek uygulamayı NNAPI kullanacak şekilde yapılandırmanız gerekir.
Test tamamlandığında, 1. adımdan beri etkin olan konsol terminalinde
entertuşuna basarak systrace'i sonlandırın.systrace_parseryardımcı programını çalıştırarak kümülatif istatistikler oluşturun:
$ANDROID_BUILD_TOP/frameworks/ml/nn/tools/systrace_parser/parse_systrace.py --total-times trace.html
Ayrıştırıcı aşağıdaki parametreleri kabul eder:
- --total-times: Bir katmanda harcanan toplam süreyi gösterir. Bu süreye, temel katmana yapılan bir çağrıda yürütme için bekleme süresi de dahildir.
- --print-detail: systrace'ten toplanan tüm etkinlikleri yazdırır.
- --per-execution: Tüm aşamalarla ilgili istatistikler yerine yalnızca yürütmeyi ve alt aşamalarını (yürütme başına süreler olarak) yazdırır.
- --json: Çıkışı JSON biçiminde oluşturur.
Çıkış örneği aşağıda gösterilmiştir:
===========================================================================================================================================
NNAPI timing summary (total time, ms wall-clock) Execution
----------------------------------------------------
Initialization Preparation Compilation I/O Compute Results Ex. total Termination Total
-------------- ----------- ----------- ----------- ------------ ----------- ----------- ----------- ----------
Application n/a 19.06 1789.25 n/a n/a 6.70 21.37 n/a 1831.17*
Runtime - 18.60 1787.48 2.93 11.37 0.12 14.42 1.32 1821.81
IPC 1.77 - 1781.36 0.02 8.86 - 8.88 - 1792.01
Driver 1.04 - 1779.21 n/a n/a n/a 7.70 - 1787.95
Total 1.77* 19.06* 1789.25* 2.93* 11.74* 6.70* 21.37* 1.32* 1831.17*
===========================================================================================================================================
* This total ignores missing (n/a) values and thus is not necessarily consistent with the rest of the numbers
Toplanan etkinlikler tam bir uygulama izini temsil etmiyorsa ayrıştırıcı başarısız olabilir. Özellikle, bir bölümün sonunu işaretlemek için oluşturulan systrace etkinlikleri, izde ilişkili bir bölüm başlangıç etkinliği olmadan bulunuyorsa bu işlem başarısız olabilir. Bu durum genellikle, systrace toplayıcıyı başlattığınızda önceki bir profilleme oturumundaki bazı etkinlikler oluşturuluyorsa ortaya çıkar. Bu durumda, profil oluşturma işlemini tekrar çalıştırmanız gerekir.
Uygulama kodunuzla ilgili istatistikleri systrace_parser çıkışına ekleme
parse_systrace uygulaması, yerleşik Android systrace işlevine dayanır. Uygulamanızdaki belirli işlemler için özel etkinlik adlarıyla birlikte systrace API'sini (Java için , yerel uygulamalar için ) kullanarak izlemeler ekleyebilirsiniz.
Özel etkinliklerinizi uygulama yaşam döngüsünün aşamalarıyla ilişkilendirmek için etkinlik adınızın başına aşağıdaki dizelerden birini ekleyin:
[NN_LA_PI]: Başlatma için uygulama düzeyinde etkinlik[NN_LA_PP]: Hazırlık için uygulama düzeyinde etkinlik[NN_LA_PC]: Derleme için uygulama düzeyinde etkinlik[NN_LA_PE]: Yürütme için uygulama düzeyinde etkinlik
Aşağıda, TFLite görüntü sınıflandırma örneği kodunu runInferenceModel bölümünü Execution aşaması için ve Application katmanını diğer bölümleri preprocessBitmap içerecek şekilde değiştirme örneği verilmiştir. Bu bölümler NNAPI izlerinde dikkate alınmaz. runInferenceModel bölümü, nnapi systrace ayrıştırıcısı tarafından işlenen systrace etkinliklerinin bir parçası olur:
Kotlin
/** Runs inference and returns the classification results. */ fun recognizeImage(bitmap: Bitmap): List{ // This section won’t appear in the NNAPI systrace analysis Trace.beginSection("preprocessBitmap") convertBitmapToByteBuffer(bitmap) Trace.endSection() // Run the inference call. // Add this method in to NNAPI systrace analysis. Trace.beginSection("[NN_LA_PE]runInferenceModel") long startTime = SystemClock.uptimeMillis() runInference() long endTime = SystemClock.uptimeMillis() Trace.endSection() ... return recognitions }
Java
/** Runs inference and returns the classification results. */ public ListrecognizeImage(final Bitmap bitmap) { // This section won’t appear in the NNAPI systrace analysis Trace.beginSection("preprocessBitmap"); convertBitmapToByteBuffer(bitmap); Trace.endSection(); // Run the inference call. // Add this method in to NNAPI systrace analysis. Trace.beginSection("[NN_LA_PE]runInferenceModel"); long startTime = SystemClock.uptimeMillis(); runInference(); long endTime = SystemClock.uptimeMillis(); Trace.endSection(); ... Trace.endSection(); return recognitions; }
Hizmet kalitesi
Android 11 ve sonraki sürümlerde NNAPI, bir uygulamanın modellerinin göreceli önceliklerini, belirli bir modeli hazırlamak için gereken maksimum süreyi ve belirli bir hesaplamayı tamamlamak için gereken maksimum süreyi belirtmesine olanak tanıyarak daha iyi hizmet kalitesi (HK) sağlar. Android 11 ayrıca uygulamaların, yürütme son tarihlerinin kaçırılması gibi hataları anlamasını sağlayan ek NNAPI sonuç kodları sunar.
İş yükünün önceliğini ayarlama
Bir NNAPI iş yükünün önceliğini ayarlamak için ANeuralNetworksCompilation_finish() işlevini çağırmadan önce ANeuralNetworksCompilation_setPriority() işlevini çağırın.
Teslim tarihleri belirleme
Uygulamalar, hem model derleme hem de çıkarım için son tarihler belirleyebilir.
- Derleme zaman aşımını ayarlamak için
ANeuralNetworksCompilation_finish()işlevini çağırmadan önceANeuralNetworksCompilation_setTimeout()işlevini çağırın. - Çıkarım zaman aşımını ayarlamak için derlemeyi başlatmadan önce
ANeuralNetworksExecution_setTimeout()işlevini çağırın.
İşlenenler hakkında daha fazla bilgi
Aşağıdaki bölümde, işlenenlerin kullanımıyla ilgili ileri düzey konular ele alınmaktadır.
Kuantize edilmiş tensörler
Kuantize edilmiş tensör, kayan noktalı değerlerden oluşan n boyutlu bir diziyi kompakt bir şekilde temsil etmenin bir yoludur.
NNAPI, 8 bitlik asimetrik kuantize edilmiş tensörleri destekler. Bu tensörlerde her hücrenin değeri 8 bitlik bir tam sayıyla gösterilir. Tensörle ilişkili bir ölçek ve sıfır puan değeri vardır. Bunlar, 8 bitlik tam sayıları temsil edilen kayan nokta değerlerine dönüştürmek için kullanılır.
Formül şöyledir:
(cellValue - zeroPoint) * scale
Burada zeroPoint değeri 32 bitlik bir tam sayı, ölçek ise 32 bitlik bir kayan nokta değeridir.
32 bit kayan nokta değerlerine sahip tensörlerle karşılaştırıldığında, 8 bit nicelenmiş tensörlerin iki avantajı vardır:
- Eğitilmiş ağırlıklar, 32 bit tensörlerin boyutunun dörtte biri kadar olduğundan uygulamanız daha küçüktür.
- Hesaplamalar genellikle daha hızlı yürütülebilir. Bunun nedeni, bellekten getirilmesi gereken veri miktarının daha az olması ve işlemcilerin (ör. DSP'ler) tam sayı matematik işlemlerinde verimli olmasıdır.
Kayan nokta modelini nicemlenmiş bir modele dönüştürmek mümkün olsa da deneyimlerimiz, nicemlenmiş bir modelin doğrudan eğitilmesiyle daha iyi sonuçlar elde edildiğini göstermiştir. Bu sayede, nöral ağ her değerin artan ayrıntı düzeyini telafi etmeyi öğrenir. Her nicelenmiş tensör için ölçek ve sıfır noktası değerleri eğitim sürecinde belirlenir.
NNAPI'de, ANeuralNetworksOperandType veri yapısının tür alanını ANEURALNETWORKS_TENSOR_QUANT8_ASYMM olarak ayarlayarak nicelenmiş tensör türlerini tanımlarsınız.
Ayrıca, bu veri yapısındaki tensörün ölçeğini ve sıfır noktası değerini de belirtirsiniz.
NNAPI, 8 bitlik asimetrik nicemlenmiş tensörlere ek olarak aşağıdakileri de destekler:
ANEURALNETWORKS_TENSOR_QUANT8_SYMM_PER_CHANNELCONV/DEPTHWISE_CONV/TRANSPOSED_CONVişlemlerine ağırlık atamak için kullanabilirsiniz.ANEURALNETWORKS_TENSOR_QUANT16_ASYMMQUANTIZED_16BIT_LSTM'in dahili durumu için kullanabilirsiniz.ANEURALNETWORKS_TENSOR_QUANT8_SYMMANEURALNETWORKS_DEQUANTIZEiçin giriş olarak kullanılabilir.
İsteğe bağlı işlenenler
ANEURALNETWORKS_LSH_PROJECTION gibi birkaç işlem isteğe bağlı işlenenler alır. İsteğe bağlı işlenenin modelde atlandığını belirtmek için ANeuralNetworksModel_setOperandValue() işlevini çağırın, arabellek için NULL ve uzunluk için 0 değerini iletin.
İşlenenin mevcut olup olmadığına ilişkin karar her yürütme için değişiyorsa arabellek için NULL, uzunluk için 0 değerini ileterek ANeuralNetworksExecution_setInput() veya ANeuralNetworksExecution_setOutput() işlevlerini kullanarak işlenenin atlandığını belirtirsiniz.
Bilinmeyen sıralı tensörler
Android 9 (API düzeyi 28), bilinmeyen boyutlara ancak bilinen sıralamaya (boyut sayısı) sahip model işlenenlerini kullanıma sundu. Android 10 (API düzeyi 29), ANeuralNetworksOperandType'ta gösterildiği gibi bilinmeyen sıralı tensörleri kullanıma sundu.
NNAPI karşılaştırması
NNAPI karşılaştırması, AOSP'de platform/test/mlts/benchmark
(karşılaştırma uygulaması) ve platform/test/mlts/models (modeller ve veri kümeleri) olarak kullanılabilir.
Karşılaştırma testi, gecikme süresini ve doğruluğu değerlendirir. Ayrıca, sürücüleri aynı modeller ve veri kümeleri için CPU'da çalışan Tensorflow Lite kullanılarak yapılan aynı işlerle karşılaştırır.
Karşılaştırmayı kullanmak için aşağıdakileri yapın:
Hedef Android cihazı bilgisayarınıza bağlayın, bir terminal penceresi açın ve cihaza adb üzerinden erişilebildiğinden emin olun.
Birden fazla Android cihaz bağlıysa hedef cihazın ortam değişkenini dışa aktarın.
ANDROID_SERIALAndroid'in üst düzey kaynak dizinine gidin.
Aşağıdaki komutları çalıştırın:
lunch aosp_arm-userdebug # Or aosp_arm64-userdebug if available ./test/mlts/benchmark/build_and_run_benchmark.sh
Bir karşılaştırma çalıştırmasının sonunda sonuçları,
xdg-open'ya iletilen bir HTML sayfası olarak sunulur.
NNAPI günlükleri
NNAPI, sistem günlüklerinde yararlı teşhis bilgileri oluşturur. Günlükleri analiz etmek için logcat yardımcı programını kullanın.
debug.nn.vlog özelliğini (adb shell kullanarak) boşluk, iki nokta üst üste veya virgülle ayrılmış aşağıdaki değerler listesine ayarlayarak belirli aşamalar veya bileşenler için ayrıntılı NNAPI günlük kaydını etkinleştirin:
model: Model oluşturmacompilation: Model yürütme planının oluşturulması ve derlenmesiexecution: Model yürütmecpuexe: NNAPI CPU uygulaması kullanılarak işlemlerin yürütülmesimanager: NNAPI uzantıları, kullanılabilir arayüzler ve özelliklerle ilgili bilgilerallveya1: Yukarıdaki tüm öğeler
Örneğin, tam ayrıntılı günlük kaydını etkinleştirmek için adb shell setprop debug.nn.vlog all komutunu kullanın. Ayrıntılı günlük kaydını devre dışı bırakmak için adb shell setprop debug.nn.vlog '""' komutunu kullanın.
Ayrıntılı günlük kaydı etkinleştirildikten sonra, INFO düzeyinde günlük girişleri oluşturulur. Bu girişlerde, etiket aşama veya bileşen adına ayarlanır.
debug.nn.vlog denetimli mesajların yanı sıra NNAPI API bileşenleri, çeşitli düzeylerde başka günlük girişleri de sağlar. Bu girişlerin her biri belirli bir günlük etiketi kullanır.
Bileşenlerin listesini almak için kaynak ağacında aşağıdaki ifadeyi kullanarak arama yapın:
grep -R 'define LOG_TAG' | awk -F '"' '{print $2}' | sort -u | egrep -v "Sample|FileTag|test"
Bu ifade şu anda aşağıdaki etiketleri döndürüyor:
- BurstBuilder
- Geri çağırma işlevleri
- CompilationBuilder
- CpuExecutor
- ExecutionBuilder
- ExecutionBurstController
- ExecutionBurstServer
- ExecutionPlan
- FibonacciDriver
- GraphDump
- IndexedShapeWrapper
- IonWatcher
- Yönetici
- Bellek
- MemoryUtils
- MetaModel
- ModelArgumentInfo
- ModelBuilder
- NeuralNetworks
- OperationResolver
- İşlemler
- OperationsUtils
- PackageInfo
- TokenHasher
- TypeManager
- Utils
- ValidateHal
- VersionedInterfaces
logcat tarafından gösterilen günlük mesajlarının düzeyini kontrol etmek için ANDROID_LOG_TAGS ortam değişkenini kullanın.
NNAPI günlük iletilerinin tamamını göstermek ve diğerlerini devre dışı bırakmak için ANDROID_LOG_TAGS değerini aşağıdakilerden biri olarak ayarlayın:
BurstBuilder:V Callbacks:V CompilationBuilder:V CpuExecutor:V ExecutionBuilder:V ExecutionBurstController:V ExecutionBurstServer:V ExecutionPlan:V FibonacciDriver:V GraphDump:V IndexedShapeWrapper:V IonWatcher:V Manager:V MemoryUtils:V Memory:V MetaModel:V ModelArgumentInfo:V ModelBuilder:V NeuralNetworks:V OperationResolver:V OperationsUtils:V Operations:V PackageInfo:V TokenHasher:V TypeManager:V Utils:V ValidateHal:V VersionedInterfaces:V *:S.
ANDROID_LOG_TAGS değerini aşağıdaki komutu kullanarak ayarlayabilirsiniz:
export ANDROID_LOG_TAGS=$(grep -R 'define LOG_TAG' | awk -F '"' '{ print $2 ":V" }' | sort -u | egrep -v "Sample|FileTag|test" | xargs echo -n; echo ' *:S')
Bunun yalnızca logcat için geçerli olan bir filtre olduğunu unutmayın. Ayrıntılı günlük bilgileri oluşturmak için mülkü debug.nn.vlog olarak ayarlamanız gerekir.all