
L'outil de Rendu GPU du profil indique la durée nécessaire à chaque étape du pipeline de rendu pour afficher l'image précédente. Ces connaissances peuvent vous aider à identifier les goulots d'étranglement dans le pipeline, et donc les éléments à optimiser pour améliorer les performances d'affichage de votre application.
Cette page décrit brièvement ce qui se passe à chaque étape du pipeline et évoque les problèmes qui peuvent causer des goulots d'étranglement. Avant de lire cette page, vous devez avoir pris connaissance des informations présentées dans la section Rendu GPU du profil. En outre, pour comprendre l'interaction entre toutes les étapes, il peut être utile d'examiner le fonctionnement du pipeline de rendu.
Représentation visuelle
L'outil de rendu GPU du profil affiche les étapes et les durées associées sous la forme d'un graphique : un histogramme doté d'un code couleur. La figure 1 est un exemple de ce type d'affichage.
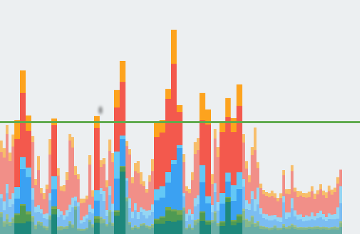
Figure 1 : Graphique du rendu GPU du profil
Les différents segments des barres verticales affichées dans le graphique de rendu GPU du profil représentent une étape du pipeline et sont mis en évidence à l'aide d'une couleur spécifique dans le graphique à barres. La figure 2 illustre la signification de chaque couleur affichée.

Figure 2 : Légende du graphique de rendu GPU du profil
Une fois que vous avez compris la signification de chaque couleur, vous pouvez cibler des aspects spécifiques de votre application pour essayer d'optimiser ses performances d'affichage.
Les étapes et leur signification
Cette section explique ce qui se passe à chaque étape correspondant à une couleur de la figure 2, ainsi que les causes des goulots d'étranglement.
Traitement des entrées
L'étape de traitement des entrées du pipeline mesure la durée pendant laquelle l'application a traité les événements d'entrée. Cette métrique indique la durée pendant laquelle l'application a exécuté du code appelé à la suite de rappels d'événements d'entrée.
Lorsque ce segment est volumineux
Les valeurs élevées dans cette zone sont généralement le résultat d'un travail trop important ou trop complexe dans les rappels d'événement du gestionnaire d'entrées. Étant donné que ces rappels se produisent toujours sur le thread principal, les solutions à ce problème se concentrent sur l'optimisation directe du travail ou sur le déchargement du travail dans un autre thread.
Notez que le défilement de la RecyclerView peut apparaître à cette étape.
RecyclerView défile immédiatement lorsqu'elle utilise l'événement tactile. Par conséquent, elle peut gonfler ou afficher de nouvelles vues d'éléments. Il est donc important que cette opération soit aussi rapide que possible. Des outils de profilage comme Traceview ou Systrace peuvent vous aider à approfondir vos recherches.
Animation
La phase d'animations vous indique la durée nécessaire pour évaluer tous les animateurs exécutés dans ce cadre. Les animateurs les plus courants sont ObjectAnimator, ViewPropertyAnimator et Transitions.
Lorsque ce segment est volumineux
Les valeurs élevées dans cette zone sont généralement le résultat d'un travail d'exécution en raison d'une modification des propriétés de l'animation. Par exemple, une animation de déplacement qui fait défiler votre ListView ou votre RecyclerView entraîne de nombreux gonflages et insertions.
Mesure/Mise en page
Pour qu'Android dessine vos éléments à afficher à l'écran, deux opérations spécifiques sont exécutées sur l'ensemble des mises en page et des vues dans la hiérarchie de vues.
D'abord, le système mesure les éléments à afficher. Chaque vue et chaque mise en page comporte des données spécifiques décrivant la taille de l'objet à l'écran. Certaines vues peuvent avoir une taille spécifique. D'autres ont une taille qui s'adapte à celle du conteneur de mise en page parent.
Ensuite, le système affiche les éléments à afficher. Une fois que le système a calculé la taille des vues enfants, il peut procéder à la mise en page, au dimensionnement et au positionnement des vues à l'écran.
Le système effectue des mesures et une mise en page non seulement pour les vues à dessiner, mais aussi pour les hiérarchies parentes de ces vues, jusqu'à la vue racine.
Lorsque ce segment est volumineux
Si votre application passe beaucoup de temps par cadre dans cette zone, cela est généralement dû au volume important de vues à corriger, ou à des problèmes tels que la double imposition au mauvais endroit de la hiérarchie. Dans les deux cas, l'optimisation des performances implique l'amélioration des performances de vos hiérarchies de vues.
Le code que vous avez ajouté dans onLayout(boolean, int, int, int, int) ou onMeasure(int, int) peut également engendrer des problèmes de performances. Traceview et Systrace peuvent vous aider à examiner les piles d'appels pour identifier les problèmes liés à votre code.
Dessiner
L'étape du dessin traduit les opérations à réaliser pour afficher une vue, comme le dessin d'un arrière-plan ou d'un texte, en une séquence de commandes de dessin natives. Le système enregistre ces commandes dans une liste d'affichage.
La barre de dessin enregistre la durée nécessaire pour capturer les commandes dans la liste d'affichage, pour toutes les vues à mettre à jour dans le cadre à l'écran. La durée mesurée s'applique à tout code que vous avez ajouté aux objets de l'interface utilisateur de votre application. Ce type de code peut être onDraw(), dispatchDraw() ou les différentes draw ()methods appartenant aux sous-classes de la classe Drawable.
Lorsque ce segment est volumineux
Pour faire simple, cette métrique indique la durée nécessaire pour exécuter tous les appels à onDraw() pour chaque vue invalidée. Cette mesure inclut le temps passé à envoyer des commandes de dessin aux enfants et aux drawables éventuellement présents. Par conséquent, lorsque vous voyez un pic de barre, il est possible qu'un grand nombre de vues ait soudainement été invalidé. L'invalidation permet de générer à nouveau les listes d'affichage des vues. Une durée longue peut également être le résultat de quelques vues personnalisées dont la méthode onDraw() comporte une logique extrêmement complexe.
Synchroniser/Importer
La métrique de synchronisation et d'importation représente le temps nécessaire pour transférer des objets bitmap de la mémoire du processeur vers la mémoire du GPU concernant le cadre actuel.
En tant que processeurs distincts, le processeur et le GPU disposent de différentes zones RAM dédiées au traitement. Lorsque vous dessinez un bitmap sur Android, le système le transfère dans la mémoire du GPU avant que celui-ci ne s'affiche à l'écran. Ensuite, le GPU met en cache le bitmap pour éviter au système de transférer à nouveau les données, sauf si la texture est exclue du cache de texture du GPU.
Remarque : Sur les appareils Lollipop, cette étape est en violet.
Lorsque ce segment est volumineux
Toutes les ressources d'un cadre doivent se trouver dans la mémoire GPU avant de pouvoir être utilisées pour dessiner une cadre. Cela signifie qu'une valeur élevée pour cette métrique peut indiquer un grand nombre de charges de petite taille ou un petit nombre de très grandes ressources. C'est le cas lorsqu'une application affiche un seul bitmap dont la taille avoisine celle de l'écran. C'est aussi le cas lorsqu'une application affiche un grand nombre de vignettes.
Pour réduire cette barre, vous pouvez utiliser les techniques suivantes :
- Assurez-vous que vos résolutions bitmap ne sont pas plus grandes que leur taille d'affichage. Par exemple, votre application doit éviter d'afficher une image dont la taille est 1 024 x 1 024 au format 48 x 48.
-
Utilisez
prepareToDraw()pour préimporter un bitmap de manière asynchrone avant la phase de synchronisation suivante.
Émission de commandes
Le segment Émission de commandes représente la durée nécessaire pour exécuter toutes les commandes nécessaires à l'affichage des listes d'affichage.
Pour que le système trace des listes à l'écran, il envoie les commandes nécessaires au GPU. En règle générale, il effectue cette action via l'API OpenGL ES.
Ce processus prend un certain temps, car le système effectue la transformation finale et le bornement de chaque commande avant de l'envoyer au GPU. Des frais généraux supplémentaires sont ensuite produits du côté du GPU, qui calcule les commandes finales. Ces commandes incluent des transformations finales et des bornements supplémentaires.
Lorsque ce segment est volumineux
Le temps passé pour cette étape est une mesure directe de la complexité et de la quantité des listes d'affichage que le système affiche dans un cadre donné. Cette durée peut être allongée en présence de nombreuses opérations de tracé, en particulier dans les cas où chaque primitive de dessin a un faible coût, par exemple. Exemple :
Kotlin
for (i in 0 until 1000) { canvas.drawPoint() }
Java
for (int i = 0; i < 1000; i++) { canvas.drawPoint() }
est bien plus coûteux que :
Kotlin
canvas.drawPoints(thousandPointArray)
Java
canvas.drawPoints(thousandPointArray);
Il n'y a pas toujours de corrélation directe entre l'émission de commandes et l'affichage de listes d'affichage. Contrairement aux commandes d'émission, qui capturent la durée nécessaire pour envoyer des commandes de dessin au GPU, la métrique Draw représente la durée nécessaire pour capturer les commandes émises dans la liste d'affichage.
Cette différence est due au fait que les listes d'affichage sont mises en cache par le système dans la mesure du possible. Par conséquent, il peut arriver que le défilement, la transformation ou l'animation nécessitent que le système renvoie une liste d'affichage, mais qu'ils n'aient pas à la recréer complètement (capturer à nouveau les commandes de dessin). Par conséquent, il est possible que vous voyiez une barre élevée "Commandes d'émission", mais qu'aucune barre Commandes de dessin ne s'affiche.
Traiter/Intervertir les tampons
Une fois qu'Android a terminé d'envoyer toute sa liste d'affichage au GPU, le système envoie une dernière commande pour indiquer au pilote graphique que le cadre actuel est traité. À ce stade, le pilote peut enfin présenter l'image mise à jour à l'écran.
Lorsque ce segment est volumineux
Il est important de comprendre que le GPU exécute le travail en parallèle avec le processeur. Le système Android émet des commandes de dessin sur le GPU, puis passe à la tâche suivante. Le GPU lit ces commandes de dessin à partir d'une file d'attente et les traite.
Dans les cas où le processeur émet des commandes plus rapidement que le GPU, la file d'attente des communications entre les processeurs peut être saturée. Dans ce cas, le processeur se bloque et attend qu'il y ait suffisamment d'espace dans la file d'attente pour placer la commande suivante. Cet état de mise en file d'attente apparaît souvent pendant l'étape Intervertir les tampons, car à ce moment-là, tout un frame de commandes a été envoyé.
La solution à ce problème consiste à réduire la complexité du travail qui se produit sur le GPU, de la même manière que pour la phase "Commandes d'émission".
Divers
Outre la durée nécessaire pour que le système de rendu effectue son travail, un autre ensemble de travaux se produit sur le thread principal, qui n'a rien à voir avec l'affichage. La durée nécessaire pour exécuter ce travail est signalée par la légende temps divers. Le temps divers représente généralement le travail qui peut se produire sur le thread UI entre deux cadres de rendu consécutifs.
Lorsque ce segment est volumineux
Si cette valeur est élevée, il est probable que votre application présente des rappels, des intents ou d'autres tâches qui devraient se produire sur un autre thread. Des outils tels que le traçage de méthodes ou Systrace peuvent offrir une visibilité sur les tâches en cours d'exécution sur le thread principal. Ces informations peuvent vous aider à améliorer vos performances.