
使用 ProfilingManager 收集多个轨迹后,逐个探索这些轨迹以查找性能问题变得不切实际。借助批量轨迹分析,您可以同时查询轨迹数据集,以:
- 识别常见的性能回归问题。
- 计算统计分布(例如,P50、P90、P99 延迟时间)。
- 查找多个轨迹中的模式。
- 查找离群轨迹,以了解和调试性能问题。
本部分演示了如何使用 Perfetto Python 批量轨迹 处理器分析一组本地存储的轨迹中的启动指标 并找到离群轨迹以进行更深入的分析。
设计查询
执行批量分析的第一步是创建 PerfettoSQL 查询。
在本部分中,我们将提供一个用于衡量应用启动延迟时间的示例查询。
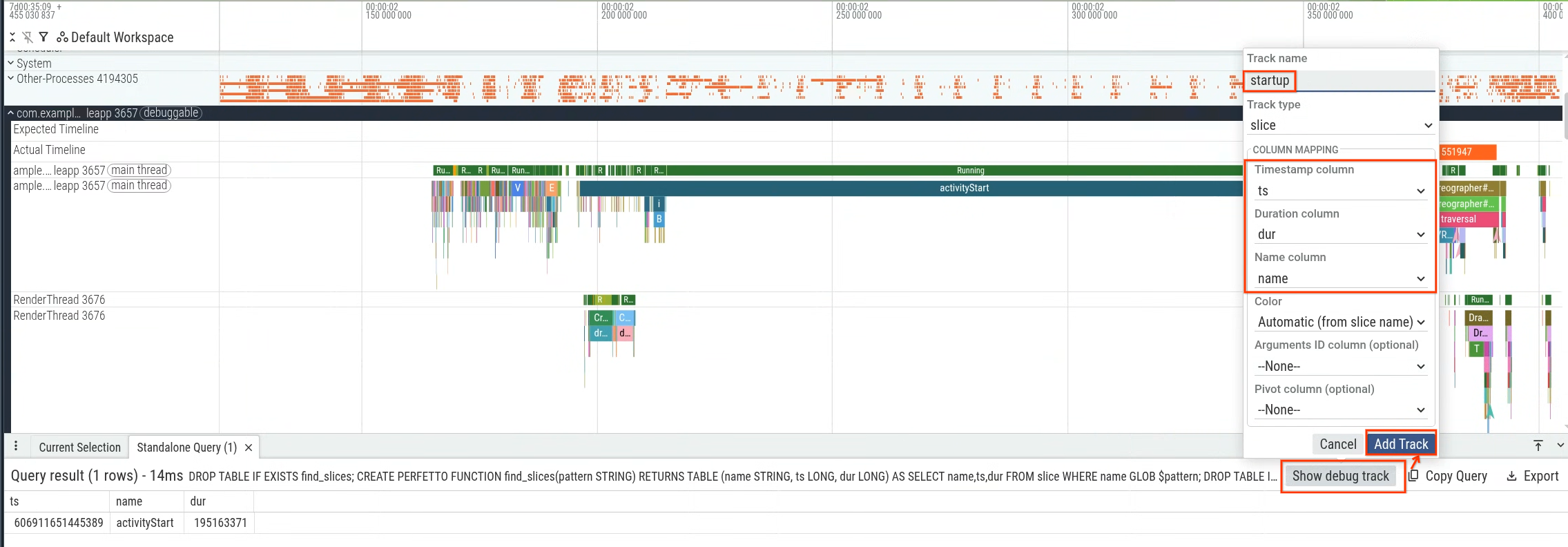
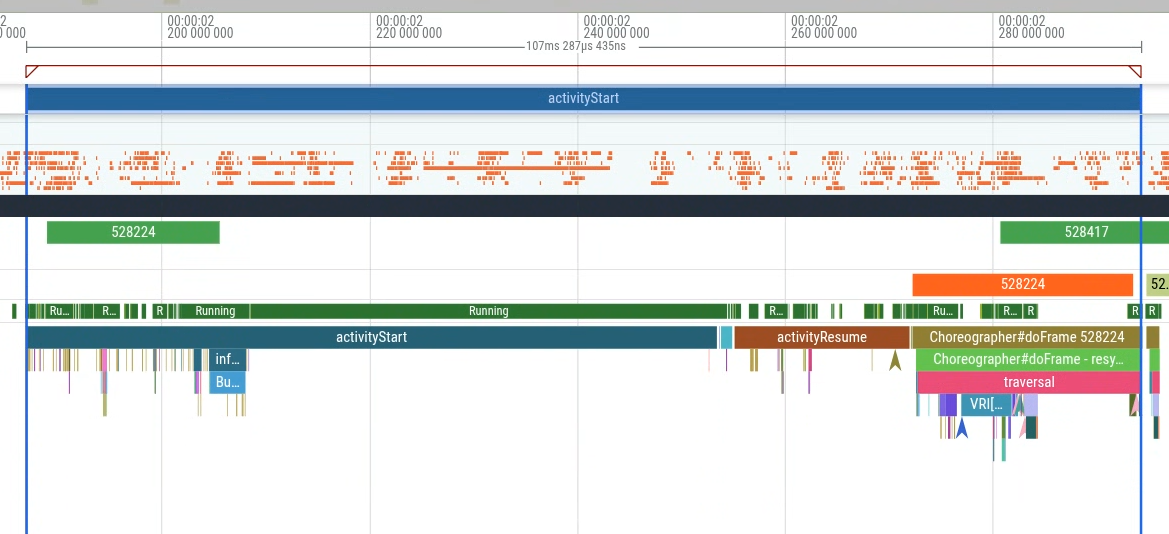
具体而言,您可以衡量从 activityStart 到生成第一帧(首次出现 Choreographer#doFrame 切片)的时长,以衡量应用启动延迟时间(在应用控制范围内)。图 1 显示了要查询的部分。

CREATE OR REPLACE PERFETTO FUNCTION find_slices(pattern STRING) RETURNS
TABLE (name STRING, ts LONG, dur LONG) AS
SELECT name,ts,dur FROM slice WHERE name GLOB $pattern;
CREATE OR REPLACE PERFETTO FUNCTION generate_start_to_end_slices(startSlicePattern STRING, endSlicePattern STRING, inclusive BOOL) RETURNS
TABLE(name STRING, ts LONG, dur LONG) AS
SELECT name, ts, MIN(startToEndDur) as dur
FROM
(SELECT S.name as name, S.ts as ts, E.ts + IIF($inclusive, E.dur, 0) - S.ts as startToEndDur
FROM find_slices($startSlicePattern) as S CROSS JOIN find_slices($endSlicePattern) as E
WHERE startToEndDur > 0)
GROUP BY name, ts;
SELECT ts,name,dur from generate_start_to_end_slices('activityStart','*Choreographer#doFrame [0-9]*', true)
您可以在 Perfetto 界面中执行查询,然后使用查询 结果生成调试轨迹(图 2)并在 时间轴内直观呈现(图 3)。

设置 Python 环境
在本地机器上安装 Python 及其必需的库:
pip install perfetto pandas plotly
创建批量轨迹分析脚本
以下示例脚本使用
Perfetto 的 Python BatchTraceProcessor在多个轨迹中执行查询。
from perfetto.batch_trace_processor import BatchTraceProcessor
import glob
import plotly.express as px
# Collect all trace files in the local directory
traces = glob.glob('*.perfetto-trace')
if not traces:
print("No .perfetto-trace files found in the current directory.")
exit(1)
if __name__ == '__main__':
# Process all traces in parallel to aggregate metrics across runs
with BatchTraceProcessor(traces) as btp:
query = """
CREATE OR REPLACE PERFETTO FUNCTION find_slices(pattern STRING) RETURNS
TABLE (name STRING, ts LONG, dur LONG) AS
SELECT name,ts,dur FROM slice WHERE name GLOB $pattern;
CREATE OR REPLACE PERFETTO FUNCTION generate_start_to_end_slices(startSlicePattern STRING, endSlicePattern STRING, inclusive BOOL) RETURNS
TABLE(name STRING, ts LONG, dur LONG) AS
SELECT name, ts, MIN(startToEndDur) as dur
FROM
(SELECT S.name as name, S.ts as ts, E.ts + IIF($inclusive, E.dur, 0) - S.ts as startToEndDur
FROM find_slices($startSlicePattern) as S CROSS JOIN find_slices($endSlicePattern) as E
WHERE startToEndDur > 0)
GROUP BY name, ts;
SELECT ts,name,dur / 1000000 as dur_ms from generate_start_to_end_slices('activityStart','*Choreographer#doFrame [0-9]*', true)
"""
df = btp.query_and_flatten(query)
# Plot the distribution of startup times, tracking trace file paths on
# hover
violin = px.violin(df, x='dur_ms', hover_data='_path', title='startup time', points='all')
violin.show()
了解脚本
运行 Python 脚本时,它会执行以下操作:
- 该脚本会在本地目录中搜索所有以
.perfetto-trace为后缀的 Perfetto 轨迹,并将它们用作分析的源轨迹。 - 它会运行批量轨迹查询,以计算与从
activityStart轨迹切片到应用生成的第一帧的时间对应的启动时间子集。 - 它会使用小提琴图绘制以毫秒为单位的延迟时间,以直观呈现启动时间的分布情况。
解释结果

执行脚本后,该脚本会生成一个图。在本例中,该图显示了具有两个不同峰值的双峰分布(图 4)。
接下来,找出这两个群体之间的差异。这有助于您更详细地检查各个轨迹。在本示例中,该图的设置方式是,当您将鼠标悬停在数据点(延迟时间)上时,可以识别轨迹文件名。然后,您可以打开属于高延迟时间组的其中一个轨迹。
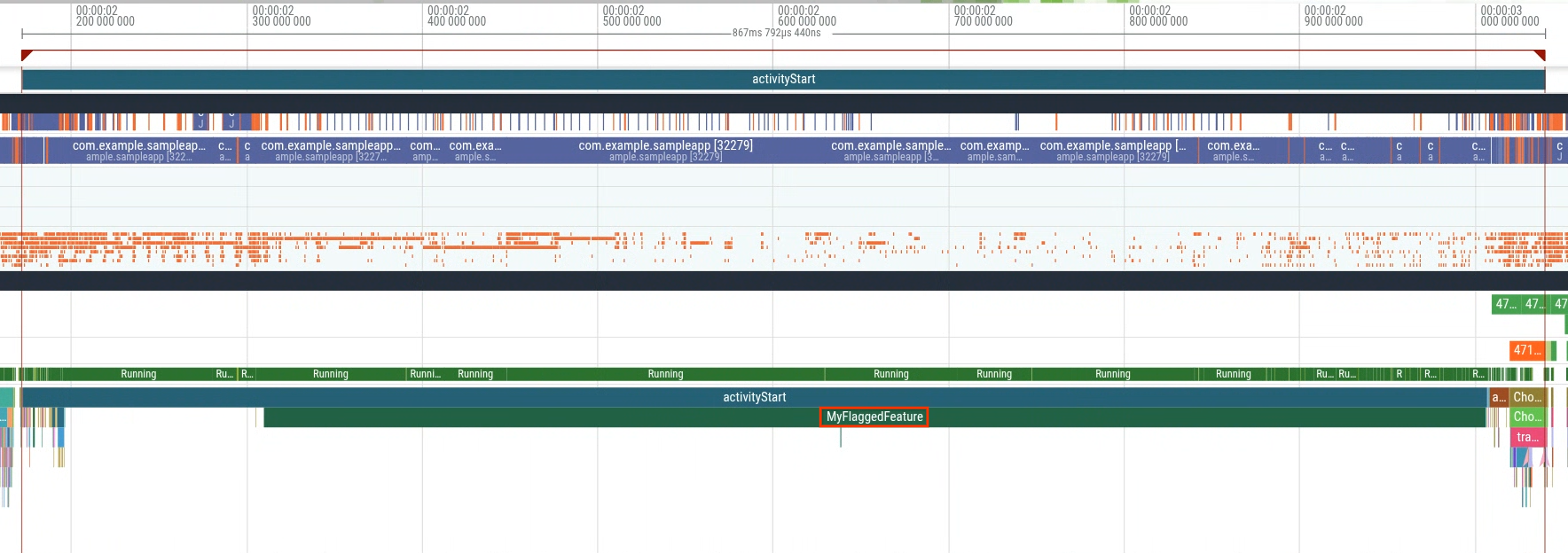
当您打开高延迟时间组中的轨迹(图 5)时,您会发现一个名为 MyFlaggedFeature 的额外切片在启动期间运行(图 6)。
相反,从低延迟时间群体(最左侧的峰值)中选择轨迹会确认缺少相同的切片(图 7)。此比较表明,为部分用户启用的特定功能标志会触发回归。

此示例演示了使用批量轨迹分析的众多方法之一。 其他用例包括从字段中提取统计信息以衡量影响、检测回归等。