
本文档可帮助您确定并修复应用中的关键性能问题。
关键性能问题
有很多问题都会导致应用性能不佳,但您应特别留意应用中的以下一些常见问题:
- 启动延迟时间
启动延迟时间是指从点按应用图标、通知或其他入口点到屏幕上显示用户的数据所需的时间。
争取在应用中实现以下启动目标:
冷启动时间少于 500 毫秒。当正在启动的应用不存在于系统内存中时,就会发生“冷启动”。应用在系统重新启动后或应用进程被用户/系统停止后首次启动时,就会进行冷启动。
相反的,如果应用已在后台运行,则为“温启动”。冷启动需要系统完成大部分工作,因为系统必须从存储空间加载所有内容并初始化应用。因此,请尽量让冷启动耗时不超过 500 毫秒。
让 P95 和 P99 延迟时间非常接近延迟时间中值。如果应用需要很长时间才能启动,用户体验会很糟糕。应用启动关键路径中的进程间通信 (IPC) 和不必要的 I/O 可能会遇到锁争用,进而造成不一致的情况。
- 滚动卡顿
“卡顿”一词是指画面在以下时候出现断断续续的情况:系统无法及时构建和提供帧,以致无法以请求的频率(60hz 或更高)将其绘制到屏幕上。卡顿问题在滚动操作期间最为明显:本应流畅播放的动画流会出现断断续续的情况。由于应用渲染内容所需的时间超过了相应帧在系统上显示的时长,所以画面移动时就会在一帧或多帧中暂停,导致出现卡顿。
应用的刷新率目标必须定在 90Hz。传统的渲染速率为 60Hz,但许多新型设备在用户互动(如滚动)期间会以 90Hz 模式运行。有些设备甚至支持更高的速率,最高可达 120Hz。
如需查看设备在特定时间所用的刷新率,请使用 Debugging 部分的 Developer Options > Show refresh rate 启用叠加层。
- 转换不顺畅
这个问题会出现在互动期间,例如在标签页之间切换或加载新的 activity 时。此类转换的动画必须自然流畅,没有延迟或画面抖动。
- 电源效率低下
执行工作会消耗电池电量,而执行不必要的工作会缩短电池续航时间。
因在代码中创建新对象而导致的内存分配可能是致使系统中产生大量工作的原因。这是因为,不仅内存分配本身需要在 Android 运行时 (ART) 中完成工作,稍后释放这些对象(即“垃圾回收”)也需要耗费时间和工作量。不过,分配和回收的速度更快,效率也更高,尤其是对临时对象而言。因此,尽管过去的最佳实践是尽可能避免分配对象,现在我们会建议您执行最适合应用和架构的操作。考虑到 ART 的能力,冒着无法维护代码的风险来减少分配并不是最佳实践。
不过,这种实践需要投入精力,因此请注意,如果您在内部循环中分配了许多对象,可能会导致性能问题。
确定问题
我们建议采用以下工作流程来确定和解决性能问题:
- 确定并检查以下关键用户历程:
- 常用的启动工作流,包括从启动器启动和从通知启动。
- 用户滚动浏览其中数据的屏幕。
- 在屏幕之间切换。
- 长时间运行的工作流,例如导航或播放音乐。
- 使用以下调试工具检查上述工作流中发生的情况:
- Perfetto:可让您根据准确的计时数据,确切了解整个设备中的运作情况。
- 内存分析器:可让您了解堆上正在发生的内存分配。
- Simpleperf:显示有关特定时间段内哪些函数调用占用最多 CPU 的火焰图。当您在 Systrace 中发现有些操作用时很长但又不知道什么原因时,Simpleperf 可以提供额外的信息。
如需了解和调试这些性能问题,手动调试各个测试运行至关重要。您无法通过分析汇总数据来取代前面的步骤。不过,若想了解用户实际看到的内容并确定可能发生性能下降的情况,请务必为自动测试以及实际运行设置指标收集:
- 启动工作流
- 实际运行指标:Play 管理中心启动时间
- 实验室测试:使用 Macrobenchmark 来测试启动
- 卡顿
- 实际运行指标
- Play 管理中心框架要点:在 Play 管理中心内,您无法将指标的收集范围缩小到某个特定的用户体验历程,因为它仅报告整个应用的整体卡顿情况。
- 使用
FrameMetricsAggregator进行自定义测量:您可以使用FrameMetricsAggregator记录特定工作流期间的卡顿指标。
- 实验室测试
- 使用 Macrobenchmark 滚动。
- Macrobenchmark 使用只包含单个用户体验历程的
dumpsys gfxinfo命令来收集帧时间。您可以通过这种方式了解卡顿问题在特定用户体验历程期间的变化。RenderTime指标重点衡量绘制帧所需的时间,在发现性能下降问题或确定改进措施方面,该指标比“卡顿帧数量”更重要。
- 实际运行指标
应用链接验证问题
应用链接是一种深层链接,它们基于已验证属于您网站的网站网址。以下是可能导致应用链接验证失败的原因。
- intent 过滤器范围:仅向您的应用可以响应的网址的 intent 过滤器添加
autoVerify。 - 未经验证的协议切换:未经验证的服务器端重定向和子网域重定向会被视为安全风险,并且无法通过验证。它们会导致所有
autoVerify链接失败。例如,将链接从 HTTP 重定向到 HTTPS(例如从 example.com 重定向到 www.example.com),而不验证 HTTPS 链接可能会导致验证失败。请务必通过添加 intent 过滤器来验证应用链接。 - 无法验证的链接:添加无法验证的链接以进行测试可能会导致系统无法验证您应用的应用链接。
- 服务器不可靠:确保服务器可以连接到客户端应用。
设置应用以进行性能分析
请务必进行正确设置,以便从应用获取准确、可重复、可操作的基准测试结果。请在尽可能接近生产环境的系统上进行测试,同时抑制噪声来源。下面几部分将介绍一些 APK 和系统特有的测试设置准备步骤,其中部分是特定于用例的步骤。
跟踪点
应用可以利用自定义轨迹事件在代码中插桩。
在捕获轨迹时,每个部分的跟踪确实会产生少量开销(约 5 微秒),因此请勿在每个方法中都使用跟踪。跟踪较大的工作块(> 0.1 毫秒)可以提供关于瓶颈的重要洞察。
APK 注意事项
调试变体对于排查堆栈样本的问题和对其进行符号化处理非常实用,但它们会对性能产生严重影响。搭载 Android 10(API 级别 29)及更高版本的设备可以在其清单中使用 profileable android:shell="true",以在发布 build 中启用性能剖析。
使用生产级代码缩减配置。根据应用所使用的资源,这可能会对性能产生重大影响。某些 ProGuard 配置会移除跟踪点,因此请考虑针对要运行测试的配置移除这些规则。
编译
将设备上的应用编译为已知状态(通常是 speed,以简化操作;也可以是 speed-profile,以更贴近实际生产环境中的性能,不过这需要预热应用并转储配置文件,或者编译应用的基准配置文件)。
speed 和 speed-profile 都会减少从 DEX 解释运行的代码量,从而减少可能造成严重干扰的后台即时 (JIT) 编译量。只有 speed-profile 会减少运行时从 dex 加载类的影响。
以下命令使用 speed 模式编译应用:
adb shell cmd package compile -m speed -f com.example.packagename
speed 编译模式会彻底编译应用的方法;speed-profile 模式会根据在应用使用过程中收集的所用代码路径的配置文件来编译应用的方法和类。以一致的方式正确收集配置文件可能比较困难,因此如果您决定使用它们,请确认它们收集的是您希望收集的内容。这些配置文件位于以下位置:
/data/misc/profiles/ref/[package-name]/primary.prof
系统注意事项
若要进行高度准确的低级别测量,请校准您的设备。在同一设备和同一操作系统版本中运行 A/B 比较。即使是在同一种设备类型中,不同设备上的性能也可能存在显著差异。
在已取得 root 权限的设备上,请考虑使用 lockClocks 脚本进行 Microbenchmark 测试。除发挥其他作用外,这些脚本还会执行以下操作:
- 将 CPU 设为固定频率。
- 停用小核心,配置 GPU。
- 停用温控调频。
我们不建议在以用户体验为重点的测试(例如应用启动、DoU 测试和卡顿测试)中使用 lockClocks 脚本,但它对于减少 Microbenchmark 测试中的噪声至关重要。
如有可能,请考虑使用 Macrobenchmark 等测试框架,因为此类测试框架可以减少测量中的噪声并防止测量结果不准。
应用启动缓慢:不必要的 trampoline activity
trampoline activity 会无端延长应用启动时间,因此您必须弄清楚您的应用是否存在这种情况。如以下示例轨迹所示,一个 activityStart 紧跟在另一个 activityStart 之后,且第一个 activity 没有绘制任何帧。
 图 1. 显示 trampoline activity 的轨迹。
图 1. 显示 trampoline activity 的轨迹。
这种情况在通知入口点和常规应用启动入口点都有可能发生,您一般可以通过重构来解决该问题。例如,如果您要使用这个 activity 在另一个 activity 运行之前执行设置,请将该代码分解到可重复使用的组件或库中。
触发频繁 GC 的不必要分配
您可能会在 Systrace 中发现,垃圾回收 (GC) 的频率高于您的预期。
以下示例显示,在长时间运行的操作期间,每 10 秒就出现一次垃圾回收,表示应用可能遭到不必要地分配,但一直在持续进行:
 图 2. 显示 GC 事件间隔的轨迹。
图 2. 显示 GC 事件间隔的轨迹。
您可能还会注意到,在使用内存分析器时,绝大部分的分配都源于某个特定的调用堆栈。您不需要激进地消除所有分配,因为这样做可能会使代码维护起来更加困难。不妨改为从分配热点着手。
卡顿帧
形流水线相对复杂一些,在确定用户最终是否会看到丢失的帧方面可能存在一些细微差别;在某些情况下,平台可能会使用缓冲来“救援”帧。不过,您可以忽略其中的大部分细微差别,从应用的角度识别有问题的帧。
在绘制帧时几乎不需要应用完成什么工作的情况下,Choreographer.doFrame() 跟踪点的间隔在帧速率为 60 帧/秒的设备上是 16.7 毫秒:
 图 3. 显示频繁出现的快速帧的轨迹。
图 3. 显示频繁出现的快速帧的轨迹。
如果缩小并浏览轨迹,有时会看到一些帧需要稍长时间才能完成,但这种情况仍然没有问题,因为这些帧的用时并未超过分配给它们的 16.7 毫秒时间:
 图 4. 显示频繁出现的快速帧且定期出现工作量爆发的轨迹。
图 4. 显示频繁出现的快速帧且定期出现工作量爆发的轨迹。
如果您在这种规律的间隔中看到一处中断,那就是卡顿帧,如图 5 所示:
 图 5. 显示卡顿帧的轨迹。
图 5. 显示卡顿帧的轨迹。
您可以练习识别卡顿帧。
 图 6. 显示更多卡顿帧的轨迹。
图 6. 显示更多卡顿帧的轨迹。
在某些情况下,您需要放大跟踪点,才能详细了解哪些视图正在膨胀或 RecyclerView 正在执行什么操作。在其他情况下,您可能必须进一步检查。
如需详细了解如何识别卡顿帧、调试并找出原因,请参阅渲染速度缓慢。
常见的 RecyclerView 错误
在不必要的情况下,让 RecyclerView 的整个后备数据失效可能会导致帧的渲染时间较长,造成卡顿。您应当仅让更改的数据失效,从而最大限度地减少需要更新的视图数量。
请参阅呈现动态数据,了解避免高开销 notifyDatasetChanged() 调用的方式,这些方式会更新内容,而不是完全替换内容。
如果您无法正确支持每个嵌套的 RecyclerView,就会导致内部 RecyclerView 每次都要完全重新创建。每个嵌套的内部 RecyclerView 都必须设置一个 RecycledViewPool,以便确保能够在每个内部 RecyclerView 之间回收视图。
如果未预提取足够的数据,或未及时预提取,用户可能就需要等待从服务器提取更多数据,才能顺畅滚动到列表底部。尽管从技术角度而言这并不属于卡顿,因为并没有错过任何帧的截止时间,但如果您能修改预提取的时间和数量,让用户不必等待数据,用户体验就能得到显著提升。
调试应用
以下是调试应用性能的不同方法。如需简要了解系统跟踪和使用 Android Studio 性能分析器,请观看以下视频。
使用 Systrace 调试应用启动
如需简要了解应用启动流程,请参阅应用启动时间;如需简要了解系统轨迹,请观看以下视频。
您可以在以下阶段消除启动类型歧义:
- 冷启动:从创建没有已保存状态的新进程开始。
- 温启动:重新使用进程时重新创建 activity,或使用已保存的状态重新创建进程。
- 热启动:重启 activity 并从膨胀开始。
建议您使用设备上的“系统跟踪”应用捕获 Systrace。对于 Android 10 及更高版本,请使用 Perfetto。对于 Android 9 及更低版本,请使用 Systrace。我们还建议使用网页版 Perfetto 轨迹查看器查看轨迹文件。如需了解详情,请参阅系统跟踪概览。
以下是一些需要注意的事项:
- 监控争用:争用受监视器保护的资源可能会导致应用的启动出现明显的延迟。
同步 binder 事务:在应用的关键路径中查找不必要的事务。如果必要的交易成本较高,请考虑与相关平台团队合作进行改进。
并发 GC:这很常见且影响相对较小,但如果您经常遇到这种情况,建议使用 Android Studio 内存性能分析器对其进行分析。
I/O:检查启动期间执行的 I/O,并确认是否存在长时间停顿。
其他线程上的重要 activity:这些 activity 可能会干扰界面线程,因此请留意启动期间的后台工作。
我们建议您在从应用角度看已完成启动后调用 reportFullyDrawn,以改进应用启动指标报告。如需详细了解如何使用 reportFullyDrawn,请参阅完全显示时间部分。
您可以通过 Perfetto 轨迹处理器提取 RFD 定义的开始时间,并发出用户可见的轨迹事件。
在设备上使用系统跟踪
您可以使用名为“系统跟踪”的系统级应用来捕获设备上的系统轨迹。借助此应用,您可以直接从设备录制轨迹,而无需插入设备或将其连接到 adb。
使用 Android Studio 内存分析器
您可以使用 Android Studio 内存分析器来检查可能由内存泄漏或使用模式不当引起的内存压力。您可以通过该工具实时查看对象分配情况。
您可以按照内存分析器提供的信息来修复应用中的内存问题,这些信息可用于跟踪垃圾回收的原因和频率。
如需分析应用内存,请执行以下步骤:
检测内存问题。
记录您要重点关注的用户历程的内存性能分析会话。查找不断增加的对象数量(如图 7 所示),这最终会导致发生 GC(如图 8 所示)。
 图 7.增加的对象数。
图 7.增加的对象数。 图 8. 垃圾回收。
图 8. 垃圾回收。确定会增加内存压力的用户历程后,分析内存压力的根本原因。
诊断内存压力热点。
在时间轴中选择一个范围,以直观呈现分配情况和浅层大小,如图 9 所示。
 图 9. 分配和浅层大小的值。
图 9. 分配和浅层大小的值。您可以通过多种方式对这些数据进行排序。以下是一些示例,说明了每个视图如何帮助您分析问题。
按类排列:如果您想查找哪些类正在生成本应从内存池中缓存或重用的对象,此选项非常有用。
例如,如果您看到某个应用每秒会使用名为“Vertex”的类创建 2,000 个对象,则分配数每秒会增加 2,000 个,按类排序时,您会看到这一数值。如果您想重用这些对象以避免生成垃圾,请实现内存池。
按调用堆栈排列:如果您想查找用于分配内存的热路径(例如,在循环内或执行大量分配工作的特定函数内),此选项非常有用。
Shallow Size:仅跟踪对象本身的内存。它适用于跟踪主要仅由基元值组成的简单类。
Retained Size:显示对象和仅由该对象引用的引用所占用的总内存。它有助于跟踪因复杂对象导致的内存压力。如需获取此值,请进行完整内存转储,如图 10 所示,并添加“保留大小”作为列,如图 11 所示。
 图 10. 完整内存转储。
图 10. 完整内存转储。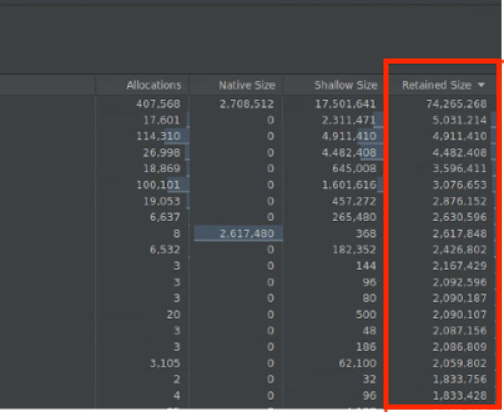
图 11. Retained Size 列。
衡量优化的影响。
GC 更明显,更容易衡量内存优化带来的影响。如果优化可减小内存压力,您会发现 GC 量变少。
如需衡量优化效果,请在性能分析器时间轴中衡量垃圾回收之间的时间间隔。然后,您会发现垃圾回收之间的间隔时间变长。
内存改进的最终影响如下:
- 如果应用不常导致内存压力,因内存不足而导致应用终止运行的频率将降低。
- 减少垃圾回收次数可以优化卡顿指标,尤其是在 P99 中。这是因为垃圾回收会导致 CPU 争用,从而导致渲染任务在垃圾回收时出现延迟。
为您推荐
- 注意:当 JavaScript 处于关闭状态时,系统会显示链接文字
- 应用启动分析和优化 {:#app-startup-analysis-optimization}
- 冻结的帧
- 编写 Macrobenchmark