
ProfilingManager का इस्तेमाल करके कई ट्रेस इकट्ठा करने के बाद, परफ़ॉर्मेंस से जुड़ी समस्याओं का पता लगाने के लिए, उन्हें अलग-अलग एक्सप्लोर करना मुश्किल हो जाता है. एक साथ कई ट्रेस का विश्लेषण करने की सुविधा की मदद से, एक साथ कई ट्रेस के डेटासेट से ये काम किए जा सकते हैं:
- परफ़ॉर्मेंस में होने वाली सामान्य गिरावट की पहचान करें.
- आंकड़ों के डिस्ट्रिब्यूशन का हिसाब लगाएं. उदाहरण के लिए, P50, P90, P99 लेटेंसी.
- कई ट्रेस में पैटर्न ढूंढें.
- परफ़ॉर्मेंस से जुड़ी समस्याओं को समझने और उन्हें डीबग करने के लिए, आउटलायर ट्रेस ढूंढें.
इस सेक्शन में, Perfetto Python Batch Trace Processor का इस्तेमाल करके, स्टार्टअप मीट्रिक का विश्लेषण करने का तरीका बताया गया है. इसके लिए, स्थानीय तौर पर सेव किए गए ट्रेस के सेट का इस्तेमाल किया जाता है. साथ ही, इसमें ज़्यादा बारीकी से विश्लेषण करने के लिए, आउटलायर ट्रेस का पता लगाने का तरीका भी बताया गया है.
क्वेरी डिज़ाइन करना
एक साथ कई फ़ाइलों का विश्लेषण करने के लिए, सबसे पहले PerfettoSQL क्वेरी बनाएं.
इस सेक्शन में, हम ऐप्लिकेशन के चालू होने में लगने वाले समय का पता लगाने वाली क्वेरी का एक उदाहरण देते हैं.
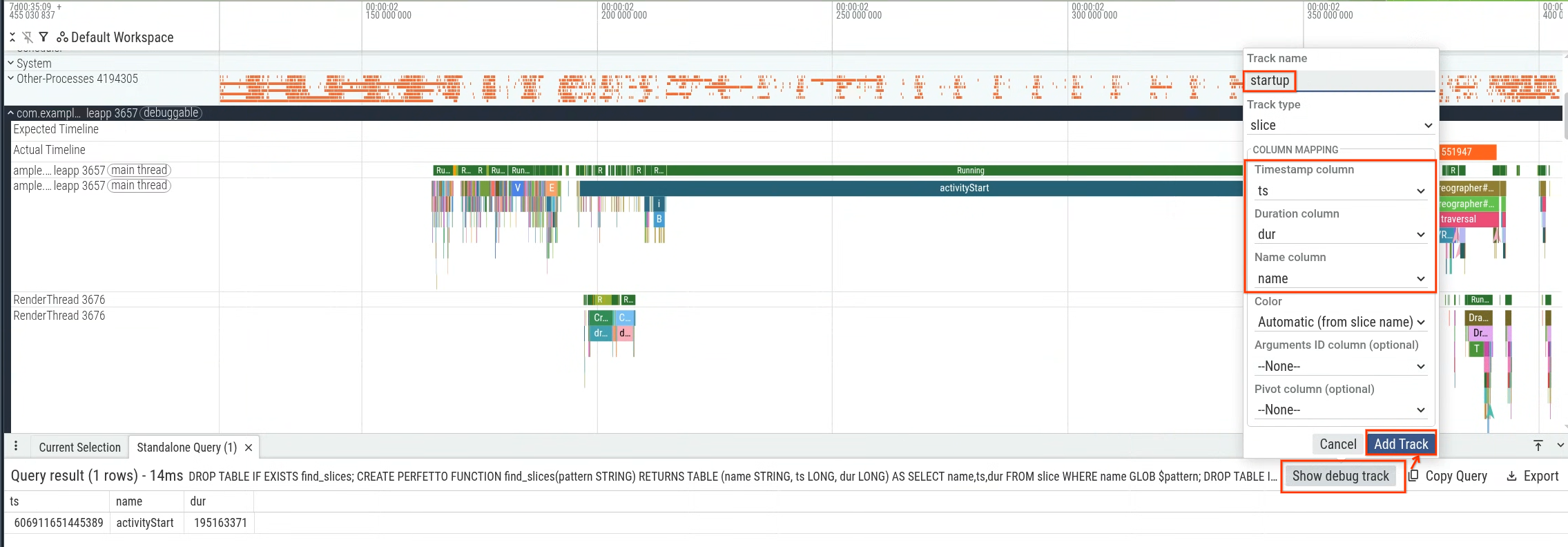
खास तौर पर, activityStart से लेकर जनरेट किए गए पहले फ़्रेम (Choreographer#doFrame स्लाइस का पहला उदाहरण) तक की अवधि को मेज़र किया जा सकता है. इससे ऐप्लिकेशन के चालू होने में लगने वाले समय को मेज़र किया जा सकता है, जिसे ऐप्लिकेशन कंट्रोल करता है. पहली इमेज में, क्वेरी करने के लिए सेक्शन दिखाया गया है.

CREATE OR REPLACE PERFETTO FUNCTION find_slices(pattern STRING) RETURNS
TABLE (name STRING, ts LONG, dur LONG) AS
SELECT name,ts,dur FROM slice WHERE name GLOB $pattern;
CREATE OR REPLACE PERFETTO FUNCTION generate_start_to_end_slices(startSlicePattern STRING, endSlicePattern STRING, inclusive BOOL) RETURNS
TABLE(name STRING, ts LONG, dur LONG) AS
SELECT name, ts, MIN(startToEndDur) as dur
FROM
(SELECT S.name as name, S.ts as ts, E.ts + IIF($inclusive, E.dur, 0) - S.ts as startToEndDur
FROM find_slices($startSlicePattern) as S CROSS JOIN find_slices($endSlicePattern) as E
WHERE startToEndDur > 0)
GROUP BY name, ts;
SELECT ts,name,dur from generate_start_to_end_slices('activityStart','*Choreographer#doFrame [0-9]*', true)
क्वेरी को Perfetto यूज़र इंटरफ़ेस (यूआई) में चलाया जा सकता है. इसके बाद, क्वेरी के नतीजों का इस्तेमाल करके डीबग ट्रैक (दूसरी इमेज) जनरेट किया जा सकता है. साथ ही, इसे टाइमलाइन (तीसरी इमेज) में देखा जा सकता है.

Python एनवायरमेंट सेट अप करना
अपने कंप्यूटर पर Python इंस्टॉल करें और इसकी ज़रूरी लाइब्रेरी:
pip install perfetto pandas plotly
एक साथ कई ट्रेस का विश्लेषण करने वाली स्क्रिप्ट बनाना
यहां दी गई स्क्रिप्ट के उदाहरण में, Perfetto के Python BatchTraceProcessor का इस्तेमाल करके, कई ट्रेस में क्वेरी को एक्ज़ीक्यूट किया गया है.
from perfetto.batch_trace_processor import BatchTraceProcessor
import glob
import plotly.express as px
# Collect all trace files in the local directory
traces = glob.glob('*.perfetto-trace')
if not traces:
print("No .perfetto-trace files found in the current directory.")
exit(1)
if __name__ == '__main__':
# Process all traces in parallel to aggregate metrics across runs
with BatchTraceProcessor(traces) as btp:
query = """
CREATE OR REPLACE PERFETTO FUNCTION find_slices(pattern STRING) RETURNS
TABLE (name STRING, ts LONG, dur LONG) AS
SELECT name,ts,dur FROM slice WHERE name GLOB $pattern;
CREATE OR REPLACE PERFETTO FUNCTION generate_start_to_end_slices(startSlicePattern STRING, endSlicePattern STRING, inclusive BOOL) RETURNS
TABLE(name STRING, ts LONG, dur LONG) AS
SELECT name, ts, MIN(startToEndDur) as dur
FROM
(SELECT S.name as name, S.ts as ts, E.ts + IIF($inclusive, E.dur, 0) - S.ts as startToEndDur
FROM find_slices($startSlicePattern) as S CROSS JOIN find_slices($endSlicePattern) as E
WHERE startToEndDur > 0)
GROUP BY name, ts;
SELECT ts,name,dur / 1000000 as dur_ms from generate_start_to_end_slices('activityStart','*Choreographer#doFrame [0-9]*', true)
"""
df = btp.query_and_flatten(query)
# Plot the distribution of startup times, tracking trace file paths on
# hover
violin = px.violin(df, x='dur_ms', hover_data='_path', title='startup time', points='all')
violin.show()
स्क्रिप्ट को समझना
Python स्क्रिप्ट चलाने पर, ये कार्रवाइयां होती हैं:
- यह स्क्रिप्ट, आपकी लोकल डायरेक्ट्री में
.perfetto-traceसे सफ़िक्स किए गए सभी Perfetto ट्रेस खोजती है. साथ ही, उनका इस्तेमाल विश्लेषण के लिए सोर्स ट्रेस के तौर पर करती है. - यह एक साथ कई ट्रेस क्वेरी चलाता है. इससे, ऐप्लिकेशन चालू होने में लगने वाले समय के सबसेट का हिसाब लगाया जाता है. यह सबसेट,
activityStartट्रेस स्लाइस से लेकर आपके ऐप्लिकेशन से जनरेट होने वाले पहले फ़्रेम तक के समय के हिसाब से होता है. - यह स्टार्टअप के समय के डिस्ट्रिब्यूशन को विज़ुअलाइज़ करने के लिए, वायलिन प्लॉट का इस्तेमाल करके मिलीसेकंड में लेटेन्सी को प्लॉट करता है.
नतीजों को समझना

स्क्रिप्ट चलाने के बाद, स्क्रिप्ट एक प्लॉट जनरेट करती है. इस मामले में, प्लॉट में दो मोड वाला डिस्ट्रिब्यूशन दिखाया गया है. इसमें दो अलग-अलग पीक हैं (आंकड़ा 4).
इसके बाद, दोनों पापुलेशन के बीच का अंतर पता करें. इससे आपको हर ट्रेस की ज़्यादा जानकारी देखने में मदद मिलती है. इस उदाहरण में, प्लॉट को इस तरह से सेट अप किया गया है कि जब डेटा पॉइंट (लेटेंसी) पर कर्सर घुमाया जाता है, तो ट्रेस फ़ाइल के नाम की पहचान की जा सकती है. इसके बाद, ज़्यादा इंतज़ार के समय वाले ग्रुप में शामिल किसी एक ट्रेस को खोला जा सकता है.
ज़्यादा समय लेने वाले ग्रुप से किसी ट्रेस को खोलने पर (पांचवीं इमेज), आपको एक अतिरिक्त स्लाइस दिखेगा. इसका नाम MyFlaggedFeature है और यह स्टार्टअप के दौरान चल रहा है (छठी इमेज).
इसके उलट, कम समय में डेटा प्रोसेस करने वाले ग्रुप (सबसे बाईं ओर वाला पीक) से किसी ट्रेस को चुनने पर, यह पुष्टि होती है कि उस स्लाइस का डेटा मौजूद नहीं है (आंकड़ा 7). इस तुलना से पता चलता है कि उपयोगकर्ताओं के किसी सबसेट के लिए चालू किया गया कोई खास फ़ीचर फ़्लैग, रिग्रेशन को ट्रिगर करता है.



इस उदाहरण में, एक साथ कई ट्रेस का विश्लेषण करने के कई तरीकों में से एक तरीका दिखाया गया है. इसके अलावा, इस सुविधा का इस्तेमाल कई अन्य कामों के लिए भी किया जा सकता है. जैसे, फ़ील्ड से आंकड़े निकालकर असर का आकलन करना, रिग्रेशन का पता लगाना वगैरह.