
CPU 性能分析器中的轨迹视图提供了多种方法查看来自所记录的轨迹的信息。
对于方法轨迹和函数轨迹,您可以直接在 Threads 时间轴中查看 Call Chart,并从 Analysis 窗格中查看 Flame Chart、Top Down、Bottom Up 和 Events 标签页。对于调用堆栈帧,您可以查看已执行的代码部分以及调用这些代码的原因。对于系统轨迹,您可以直接在 Threads 时间轴中查看 Trace Events,并从 Analysis 窗格中查看 Flame Chart、Top Down、Bottom Up 和 Events 标签页。
您可以使用鼠标和键盘快捷键更轻松地浏览 Call Charts 或 Trace Events。
使用调用图表检查跟踪数据
调用图表以图形方式来呈现方法轨迹或函数轨迹,其中调用的时间段和时间在横轴上表示,而其被调用方则在纵轴上显示。对系统 API 的调用显示为橙色,对应用自有方法的调用显示为绿色,对第三方 API(包括 Java 语言 API)的调用显示为蓝色。图 4 显示了一个调用图表示例,说明了给定方法或函数的 Self 时间、Children 时间和 Total 时间的概念。如需详细了解这些概念,请参阅关于如何使用“Top Down”和“Bottom Up”检查轨迹的部分。
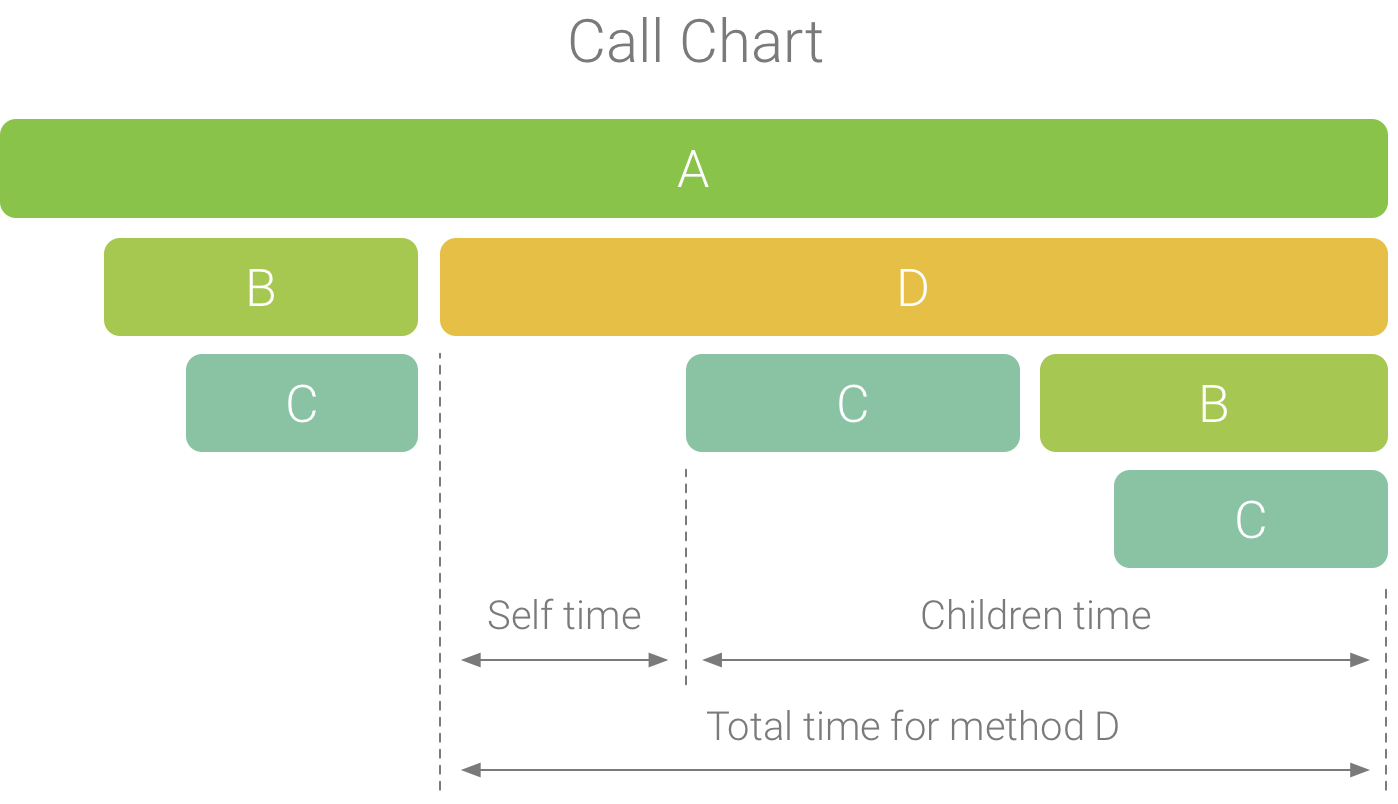
图 1. 一个调用图表示例,展示了方法 D 的 Self 时间、Children 时间和 Total 时间。
提示:如需跳转到某个方法或函数的源代码,请右键点击该方法或函数,然后选择 Jump to Source。在“分析”窗格的任意标签页中都可以执行此操作。
使用“Flame Chart”标签检查跟踪数据
Flame Chart 标签页提供一个倒置的调用图表,用来汇总完全相同的调用堆栈。也就是说,将具有相同调用方顺序的完全相同的方法或函数收集起来,并在火焰图中将它们表示为一个较长的横条(而不是将它们显示为多个较短的横条,如调用图表中所示)。这样更方便您查看哪些方法或函数消耗的时间最多。不过,这也意味着,横轴不代表时间轴,而是表示执行每个方法或函数所需的相对时间。
为帮助说明此概念,不妨考虑图 2 中的调用图表。请注意,方法 D 多次调用 B(B1、B2 和 B3),其中一些对 B 的调用也调用了 C(C1 和 C3)。
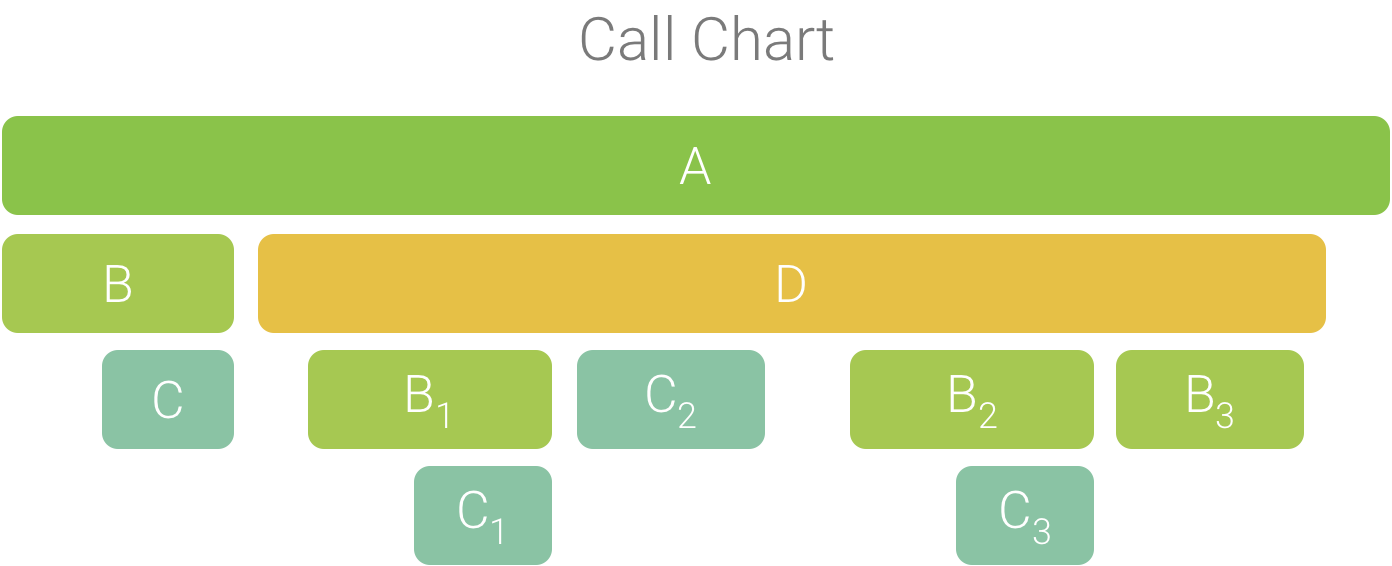
图 2. 一个调用图表,其中的多个方法调用具有相同的调用方顺序。
由于 B1、B2 和 B3 具有相同的调用方顺序 (A → D → B),因此系统将它们汇总在一起,如图 3 所示。同样,C1 和 C3 也汇总在一起,因为它们也具有相同的调用方顺序 (A → D → B → C)。请注意,C2 不包括在内,因为它具有不同的调用方顺序 (A → D → C)。
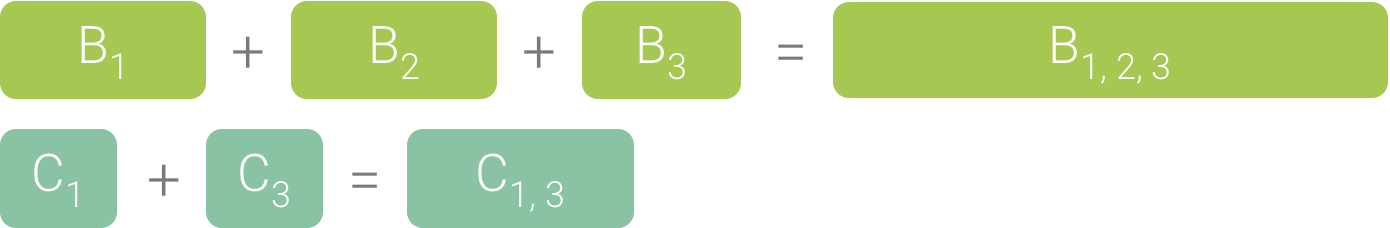
图 3. 汇总具有相同调用堆栈的相同方法。
汇总的调用用于创建火焰图,如图 4 所示。 请注意,对于火焰图中的任何给定调用,占用最多 CPU 时间的被调用方会最先显示。
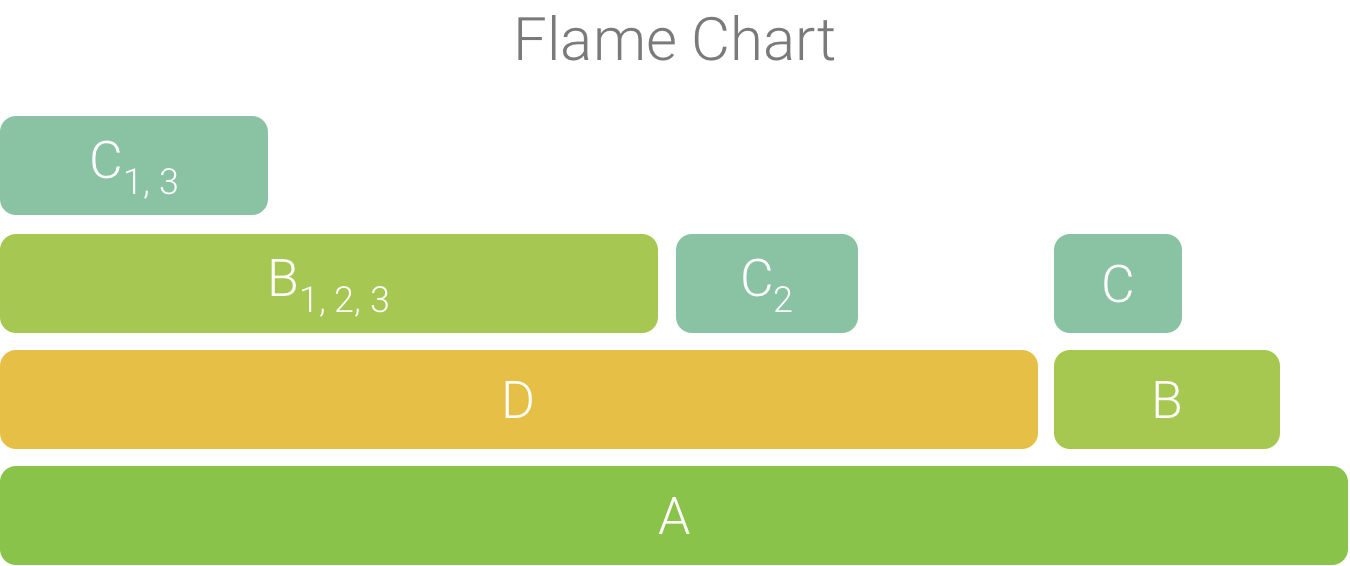
图 4. 图 5 中所示调用图表的火焰图表示形式。
使用“Top Down”和“Bottom Up”检查跟踪数据
Top Down 标签页显示一个调用列表,在该列表中展开方法或函数节点会显示它的被调用方。图 5 显示了图 1 中调用图表的 Top Down 图。图中的每个箭头都从调用方指向被调用方。
如图 5 所示,在 Top Down 标签页中展开方法 A 的节点会显示它的被调用方,即方法 B 和 D。在此之后,展开方法 D 的节点会显示它的被调用方,即方法 B 和 C,依此类推。与 Flame chart 标签页类似,“Top Down”树也汇总了具有相同调用堆栈的完全相同的方法的跟踪信息。也就是说,Flame chart 标签页提供了 Top down 标签页的图形表示方式。
Top Down 标签页提供以下信息来帮助说明在每个调用上所花的 CPU 时间(时间也可表示为在选定范围内占线程总时间的百分比):
- Self:方法或函数调用在执行自己的代码(而非被调用方的代码)上所花的时间,如图 1 中的方法 D 所示。
- Children:方法或函数调用在执行它的被调用方(而非自己的代码)上所花的时间,如图 1 中的方法 D 所示。
- Total:方法的 Self 时间和 Children 时间的总和。这表示应用在执行调用时所用的总时间,如图 1 中的方法 D 所示。
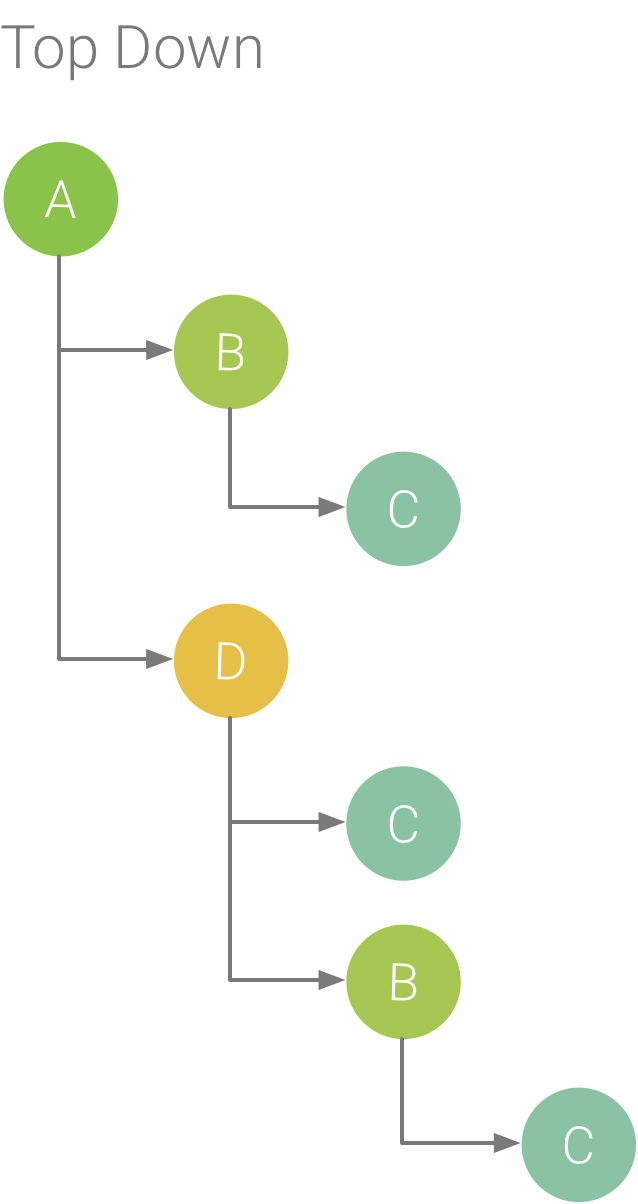
图 5. 一个 Top Down 树。
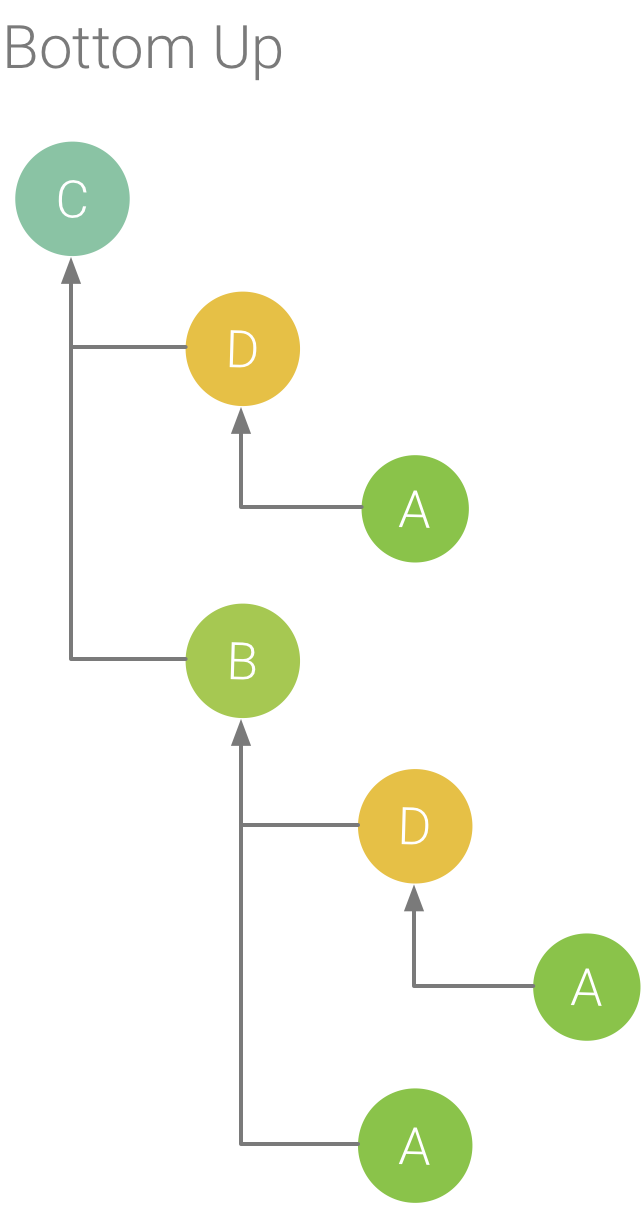
图 6. 图 5 中方法 C 的 Bottom Up 树。
Bottom Up 标签页显示一个调用列表,在该列表中展开函数或方法的节点会显示它的调用方。沿用图 5 中所示的轨迹示例,图 6 提供了方法 C 的 Bottom Up 树。在该 Bottom Up 树中打开方法 C 的节点会显示它独有的两个调用方,即方法 B 和 D。请注意,尽管 B 调用 C 两次,但在“Bottom Up”树中展开方法 C 的节点时,B 仅显示一次。在此之后,展开 B 的节点会显示它的调用方,即方法 A 和 D。
Bottom Up 标签页用于按照占用的 CPU 时间由多到少(或由少到多)的顺序对方法或函数排序。您可以检查每个节点以确定哪些调用方在调用这些方法或函数上所花的 CPU 时间最多。与“Top Down”树相比,“Bottom Up”树中每个方法或函数的时间信息参照的是每个树顶部的方法(顶部节点)。CPU 时间也可表示为在该记录期间占线程总时间的百分比。下表说明了如何解读顶部节点及其调用方(子节点)的时间信息。
| Self | Children | 总计 | |
|---|---|---|---|
| “Bottom Up”树顶部的方法或函数(顶部节点) | 表示方法或函数在执行自己的代码(而非被调用方的代码)上所花的总时间。与“Top Down”树相比,此时间信息表示在记录的持续时间内对此方法或函数的所有调用时间的总和。 | 表示方法或函数在执行它的被调用方(而非自己的代码)上所花的总时间。与“Top Down”树相比,此时间信息表示在记录的持续时间内对此方法或函数的被调用方的所有调用时间的总和。 | Self 时间和 Children 时间的总和。 |
| 调用方(子节点) | 表示被调用方在由调用方调用时的总 Self 时间。以图 6 中的 Bottom Up 树为例,方法 B 的 Self 时间将等于每次执行由方法 B 调用的方法 C 所用的 Self 时间的总和。 | 表示被调用方在由调用方调用时的总 Children 时间。以图 6 中的 Bottom Up 树为例,方法 B 的 Children 时间将等于每次执行由方法 B 调用的方法 C 所用的 Children 时间的总和。 | Self 时间和 Children 时间的总和。 |
注意:对于给定的记录,当分析器达到文件大小限制时,Android Studio 会停止收集新数据(不过,不会停止记录)。在执行检测轨迹时,这种情况通常发生得更快,因为与采样轨迹相比,此类轨迹会在更短的时间内收集更多的数据。如果您将检查时间范围延长至达到限制后的记录时段,则轨迹窗格中的时间数据不会发生变化(因为没有新数据可用)。此外,当您仅选择没有可用数据的那部分记录时,对于时间信息,轨迹窗格将显示 NaN。
使用“Events”表格检查轨迹
“Events”表格列出了当前所选线程中的所有调用。您可以点击列标题对它们进行排序。通过选择表格中的某一行,您可以在时间轴上导航到所选调用的开始时间和结束时间。这样,您就可以在时间轴上准确定位事件。
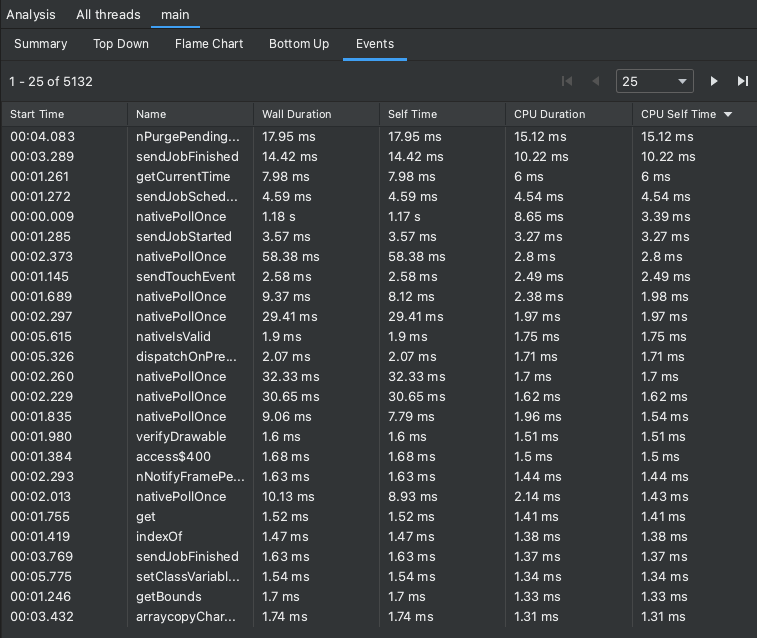
图 7. 查看“Analysis”窗格中的“Events”标签页。
检查调用堆栈帧
调用堆栈有助于了解已执行代码的哪个部分,以及调用这些代码的原因。如果为 Java/Kotlin 程序收集调用堆栈示例记录,调用堆栈通常不仅包含 Java/Kotlin 代码,还包含 JNI 原生代码、Java 虚拟机(例如,android::AndroidRuntime::start)和系统内核 ([kernel.kallsyms]+offset) 中的帧。这是因为 Java/Kotlin 程序通常通过 Java 虚拟机执行。无论是运行程序本身,还是程序同系统和硬件通信,都必须使用原生代码。性能分析器呈现这些帧是为了确保精确;不过,这些额外的调用帧对您来说可能有用,也可能没用,具体取决于您进行的调查。性能分析器提供了一种方法来收起您不感兴趣的帧,以便您可以隐藏与您的调查无关的信息。
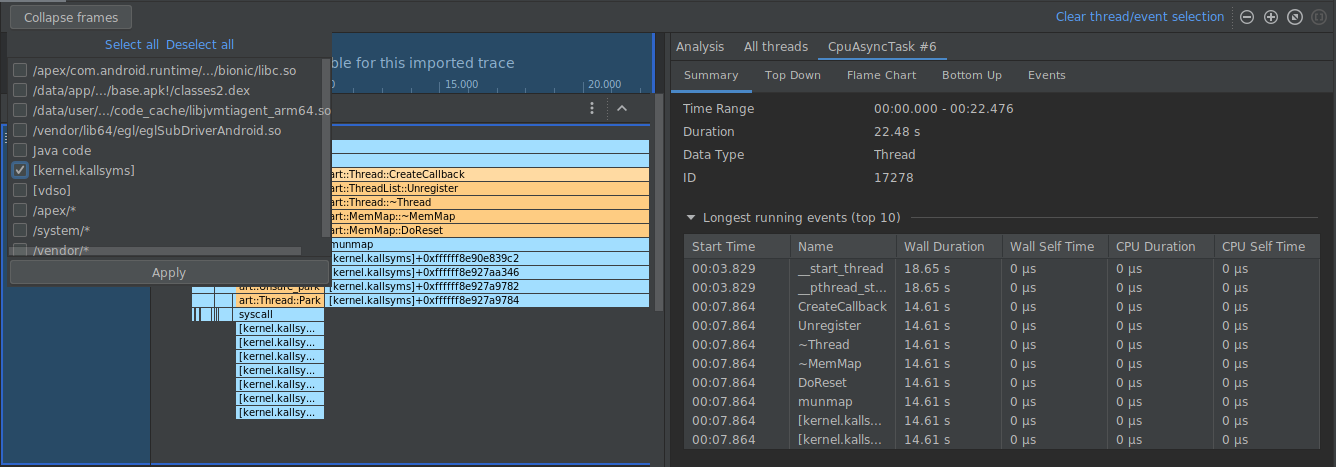
在以下示例中,以下轨迹具有许多标记为 [kernel.kallsyms]+offset 的帧,这些帧目前对开发没有帮助。
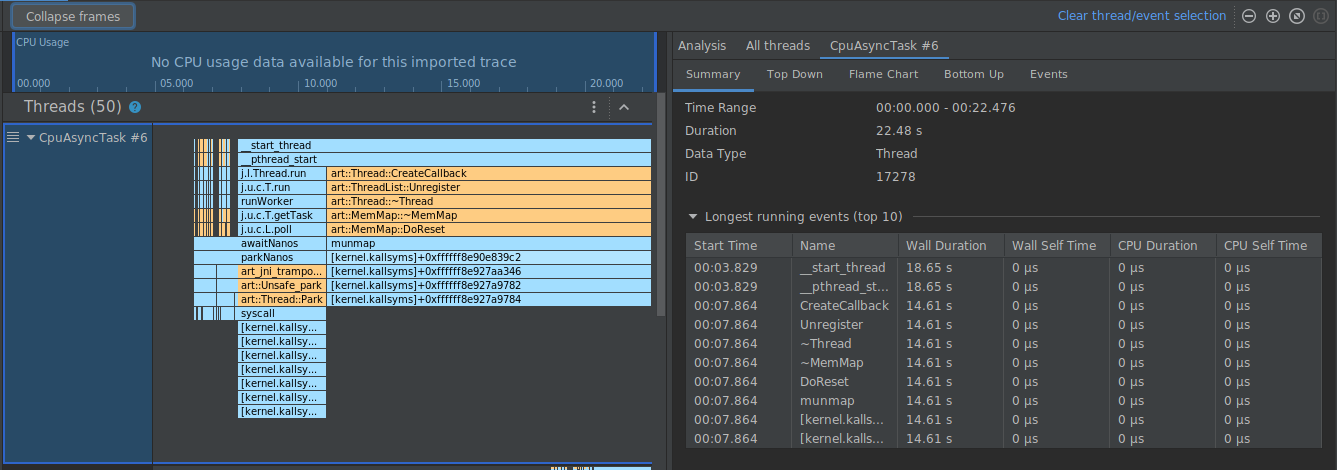
如需将这些帧收拢为一个帧,请从工具栏中选择 Collapse frames 按钮,然后选择收起路径,接着选择 Apply 按钮以应用您所做的更改。在此示例中,路径为 [kernel.kallsyms]。
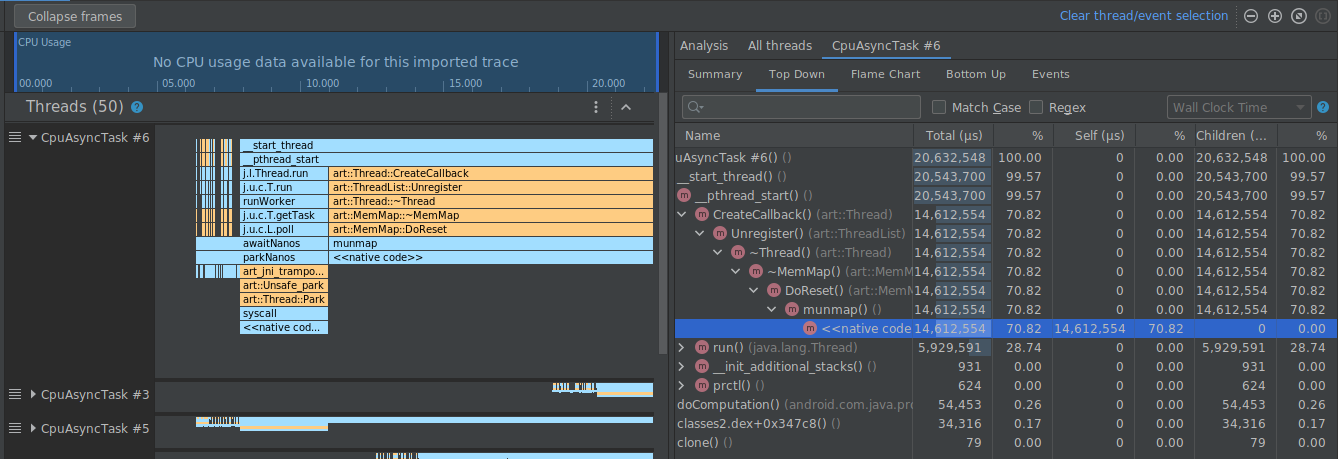
这样做可以收起左侧面板和右侧面板上与所选路径对应的帧,如下所示。
检查系统轨迹
检查系统跟踪数据时,您可以在 Threads 时间轴中检查 Trace Events,以查看每个线程上所发生事件的详细信息。将鼠标指针悬停在某个事件上,可查看该事件的名称以及在每种状态下所花费的时间。点击事件可在 Analysis 窗格中查看详情。
检查系统轨迹:CPU 核心
除了 CPU 调度数据外,系统轨迹还包括按核心记录的 CPU 频率。该图表会显示每个核心上的活动量,让您可以了解哪些是现代移动处理器中的“大”核心或“小”核心。

图 8. 查看渲染线程的 CPU 活动和跟踪事件。
CPU Cores 窗格(如图 8 所示)显示每个核心上安排的线程活动。将鼠标指针悬停在某个线程活动上,可查看该核心在此特定时间在哪个线程上运行。
如需详细了解如何检查系统跟踪信息,请参阅 systrace 文档的调查界面性能问题部分。
检查系统轨迹:帧渲染时间轴
您可以检查应用在主线程和 RenderThread 上渲染每个帧所用的时间,以调查造成界面卡顿和帧速率低的瓶颈。如需了解如何使用系统轨迹来调查并帮助减少界面卡顿,请参阅界面卡顿检测。
检查系统轨迹:进程内存 (RSS)
对于部署到搭载 Android 9 或更高版本的设备的应用,Process Memory (RSS) 部分会显示应用当前使用的物理内存量。

图 9. 在性能分析器中查看物理内存。
Total
这是您的进程当前使用的物理内存总量。在基于 Unix 的系统上,这被称为“驻留集大小”,是匿名分配、文件映射和共享内存分配所使用的所有内存的组合。
对于 Windows 开发者,驻留集大小类似于工作集大小。
Allocated
此计数器跟踪进程的正常内存分配目前占用了多少物理内存。这些分配均匿名(不由特定文件支持)且不公开(不共享)。在大多数应用中,这由堆分配量(使用 malloc 或 new)和堆栈内存组成。从物理内存中换出时,这些分配会写入系统交换文件。
File Mappings
此计数器会跟踪进程用于文件映射的物理内存量,也就是说,通过内存管理器从文件映射至内存区域的内存。
Shared
此计数器跟踪在此进程和系统中其他进程之间共享的内存所用的物理内存量。