
Gdy zbierzesz wiele śladów za pomocą ProfilingManager, indywidualne sprawdzanie ich w celu znalezienia problemów z wydajnością staje się niepraktyczne. Analiza zbiorcza logów czasu umożliwia jednoczesne wysyłanie zapytań do zbioru danych logów czasu w celu:
- identyfikować typowe regresje wydajności;
- Obliczanie rozkładów statystycznych (np. czas oczekiwania w 50, 90 i 99 centylu).
- Znajdowanie wzorców w kilku śladach.
- Wyszukuj nietypowe ślady, aby zrozumieć i debugować problemy z wydajnością.
W tej sekcji pokazujemy, jak za pomocą procesora śledzenia wsadowego Perfetto w Pythonie analizować dane dotyczące uruchamiania w zbiorze lokalnie przechowywanych śladów i lokalizować ślady odstające w celu przeprowadzenia bardziej szczegółowej analizy.
Projektowanie zapytania
Pierwszym krokiem do przeprowadzenia analizy zbiorczej jest utworzenie zapytania PerfettoSQL.
W tej sekcji przedstawiamy przykładowe zapytanie, które mierzy opóźnienie uruchamiania aplikacji.
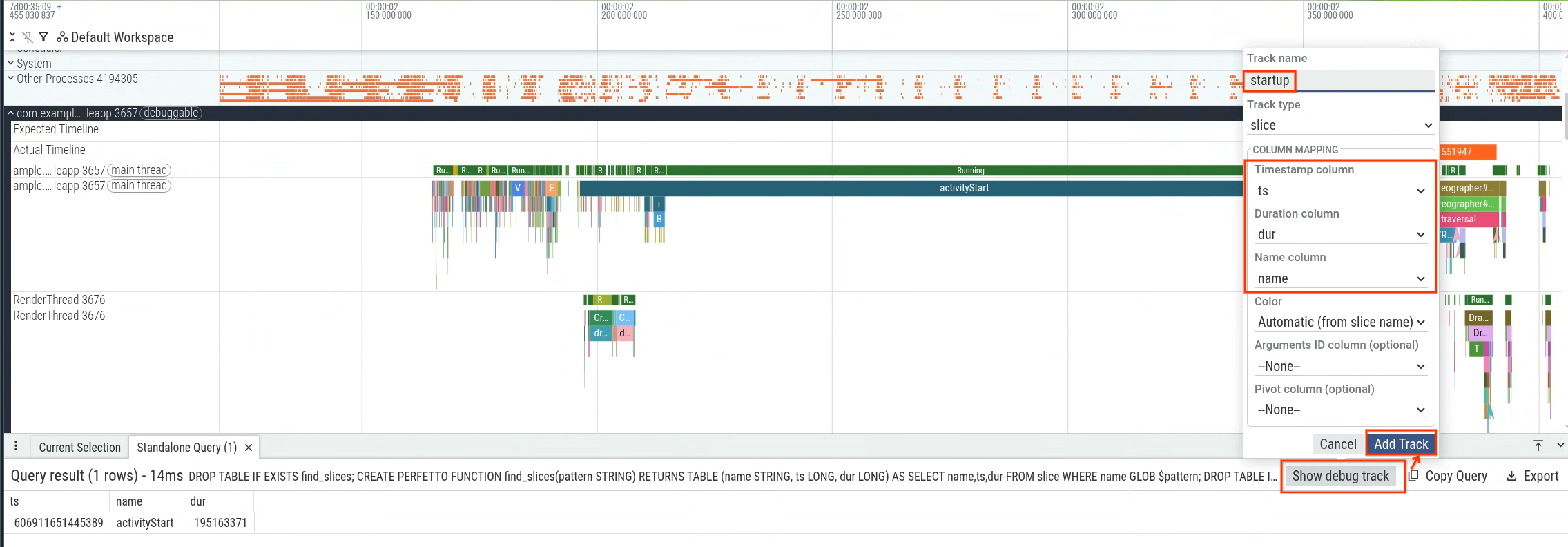
Możesz mierzyć czas od activityStart do wygenerowania pierwszej klatki (pierwsze wystąpienie wycinka Choreographer#doFrame), aby mierzyć czas rozpoczęcia aplikacji, który jest pod Twoją kontrolą. Rysunek 1 przedstawia sekcję, w której można wysłać zapytanie.

CREATE OR REPLACE PERFETTO FUNCTION find_slices(pattern STRING) RETURNS
TABLE (name STRING, ts LONG, dur LONG) AS
SELECT name,ts,dur FROM slice WHERE name GLOB $pattern;
CREATE OR REPLACE PERFETTO FUNCTION generate_start_to_end_slices(startSlicePattern STRING, endSlicePattern STRING, inclusive BOOL) RETURNS
TABLE(name STRING, ts LONG, dur LONG) AS
SELECT name, ts, MIN(startToEndDur) as dur
FROM
(SELECT S.name as name, S.ts as ts, E.ts + IIF($inclusive, E.dur, 0) - S.ts as startToEndDur
FROM find_slices($startSlicePattern) as S CROSS JOIN find_slices($endSlicePattern) as E
WHERE startToEndDur > 0)
GROUP BY name, ts;
SELECT ts,name,dur from generate_start_to_end_slices('activityStart','*Choreographer#doFrame [0-9]*', true)
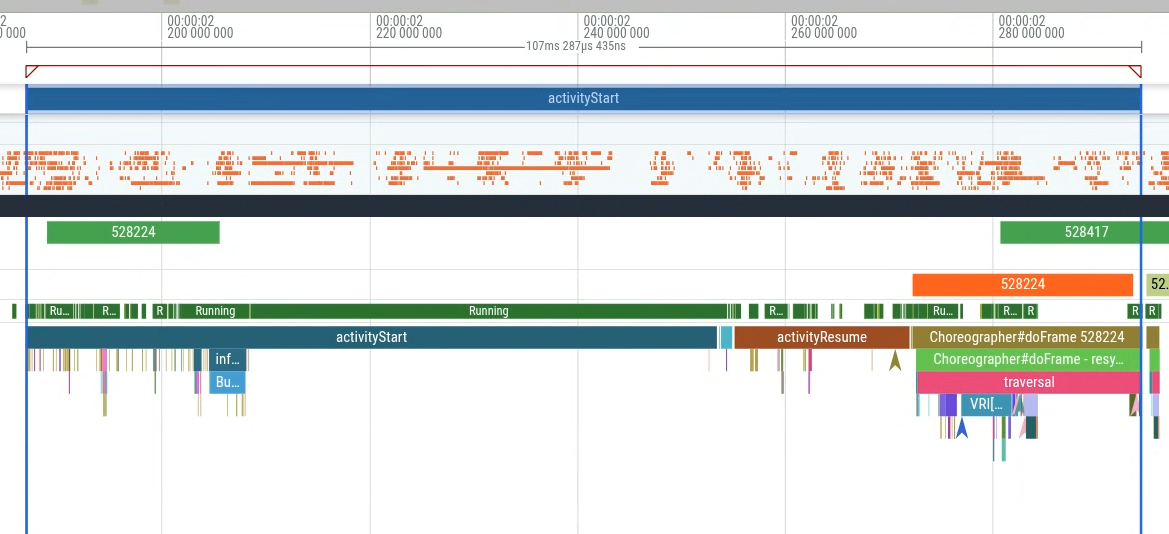
Możesz wykonać zapytanie w interfejsie Perfetto, a następnie użyć wyników zapytania do wygenerowania ścieżki debugowania (rysunek 2) i wyświetlenia jej na osi czasu (rysunek 3).

Konfigurowanie środowiska Pythona
Zainstaluj Pythona na komputerze lokalnym i wymagane biblioteki:
pip install perfetto pandas plotly
Tworzenie skryptu analizy zbiorczej logów czasu
Ten przykładowy skrypt wykonuje zapytanie w wielu śladach za pomocą Pythona Perfetto.BatchTraceProcessor
from perfetto.batch_trace_processor import BatchTraceProcessor
import glob
import plotly.express as px
# Collect all trace files in the local directory
traces = glob.glob('*.perfetto-trace')
if not traces:
print("No .perfetto-trace files found in the current directory.")
exit(1)
if __name__ == '__main__':
# Process all traces in parallel to aggregate metrics across runs
with BatchTraceProcessor(traces) as btp:
query = """
CREATE OR REPLACE PERFETTO FUNCTION find_slices(pattern STRING) RETURNS
TABLE (name STRING, ts LONG, dur LONG) AS
SELECT name,ts,dur FROM slice WHERE name GLOB $pattern;
CREATE OR REPLACE PERFETTO FUNCTION generate_start_to_end_slices(startSlicePattern STRING, endSlicePattern STRING, inclusive BOOL) RETURNS
TABLE(name STRING, ts LONG, dur LONG) AS
SELECT name, ts, MIN(startToEndDur) as dur
FROM
(SELECT S.name as name, S.ts as ts, E.ts + IIF($inclusive, E.dur, 0) - S.ts as startToEndDur
FROM find_slices($startSlicePattern) as S CROSS JOIN find_slices($endSlicePattern) as E
WHERE startToEndDur > 0)
GROUP BY name, ts;
SELECT ts,name,dur / 1000000 as dur_ms from generate_start_to_end_slices('activityStart','*Choreographer#doFrame [0-9]*', true)
"""
df = btp.query_and_flatten(query)
# Plot the distribution of startup times, tracking trace file paths on
# hover
violin = px.violin(df, x='dur_ms', hover_data='_path', title='startup time', points='all')
violin.show()
Interpretowanie skryptu
Po uruchomieniu skryptu w Pythonie wykonane zostaną te działania:
- Skrypt wyszukuje w lokalnym katalogu wszystkie ślady Perfetto z sufiksem
.perfetto-tracei używa ich jako śladów źródłowych do analizy. - Uruchamia zbiorcze zapytanie śledzenia, które oblicza podzbiór czasu uruchamiania odpowiadający czasowi od wycinka śledzenia
activityStartdo pierwszej klatki wygenerowanej przez aplikację. - Wykreśla czas oczekiwania w milisekundach za pomocą wykresu skrzypcowego, aby wizualizować rozkład czasu uruchamiania.
Interpretowanie wyników

Po uruchomieniu skryptu wygeneruje on wykres. W tym przypadku wykres przedstawia rozkład dwumodalny z 2 wyraźnymi pikami (rysunek 4).
Następnie znajdź różnicę między tymi dwiema populacjami. Ułatwi to dokładniejsze analizowanie poszczególnych śladów. W tym przykładzie wykres jest skonfigurowany tak, że po najechaniu kursorem na punkty danych (opóźnienia) można zidentyfikować nazwy plików śledzenia. Następnie możesz otworzyć jeden z trace’ów należących do grupy o dużym opóźnieniu.
Gdy otworzysz ślad z grupy o dużym opóźnieniu (rysunek 5), zobaczysz dodatkowy wycinek o nazwie MyFlaggedFeature, który jest uruchamiany podczas uruchamiania (rysunek 6).
Z kolei wybranie śladu z populacji o mniejszych opóźnieniach (najbardziej na lewo) potwierdza brak tego samego wycinka (rysunek 7). To porównanie
wskazuje, że określony flaga funkcji, włączona dla podzbioru użytkowników, powoduje
regresję.


Ten przykład pokazuje jeden z wielu sposobów korzystania z analizy śledzenia zbiorczego. Inne przypadki użycia to m.in. wyodrębnianie statystyk z pola w celu oceny wpływu, wykrywanie regresji i inne.