
La vista de seguimiento del Generador de perfiles de CPU ofrece varias formas de ver la información de los seguimientos registrados.
En el caso de los seguimientos de métodos y funciones, puedes ver el gráfico de llamadas directamente en el cronograma de Threads, o bien en las pestañas Flame Chart, Top Down, Bottom Up y Events desde el panel Analysis. En el caso de los marcos de pila de llamadas, puedes ver la parte del código que se ejecutó y el motivo de su invocación. En el caso de los registros del sistema, puedes examinar los eventos de seguimiento directamente en el cronograma de Threads, o bien en las pestañas Flame Chart, Top Down, Bottom Up y Events desde el panel Analysis.
Puedes usar las combinaciones de teclas del mouse y del teclado para facilitar la navegación por los gráficos de llamada o los eventos de seguimiento.
Cómo inspeccionar registros con el gráfico de llamadas
El gráfico de llamadas proporciona una representación visual de un seguimiento de método o función, en la que el período y el tiempo de una llamada están representados en el eje horizontal, y sus destinatarios, a lo largo del eje vertical. Las llamadas a las API del sistema se muestran en naranja, las que se realizan a los métodos de tu app se muestran en verde y las llamadas a API de terceros (incluidas las de lenguaje Java) se muestran en azul. En la figura 4, se muestra un gráfico de llamadas de ejemplo y se ilustra el concepto de los tipos de tiempo self, children y total para un método determinado. Puedes obtener más información sobre estos conceptos en la sección Cómo inspeccionar seguimientos mediante Top Down y Bottom Up.

Figura 1: Ejemplo de gráfico de llamadas en el que se muestran los tiempos self, children y total para el método D
Sugerencia: Para saltar al código fuente de un método o función, haz clic con el botón derecho en ese elemento y selecciona Jump to Source. Esto funciona desde todas las pestañas del panel Analysis.
Cómo inspeccionar seguimientos con la pestaña Flame Chart
La pestaña Flame Chart provee un gráfico de llamadas invertido que agrega pilas de llamadas idénticas. Es decir, las funciones o los métodos idénticos que comparten la misma secuencia de emisores se agrupan en una sola barra más larga, en un gráfico tipo llama (en lugar de mostrarse como varias barras más cortas, como se ve en un gráfico de llamadas). De esta forma, es más fácil ver qué métodos o funciones consumen más tiempo. Sin embargo, esto también significa que el eje horizontal no representa un cronograma; en su lugar, indica la cantidad relativa de tiempo que tarda en ejecutarse cada método o función.
Para ilustrar mejor este concepto, observa el gráfico de llamadas de la Figura 2. Ten en cuenta que el método D hace varias llamadas a B (B1, B2 y B3) y algunas de esas llamadas a B hacen una llamada a C (C1 y C3).

Figura 2: Gráfico de llamadas con varias llamadas a métodos que comparten una misma secuencia de emisores
Debido a que B1, B2 y B3 comparten la misma secuencia de emisores (A → D → B), se agrupan como se muestra en la Figura 3. De manera similar, C1 y C3 se agrupan porque comparten la misma secuencia de emisores (A → D → B → C). Ten en cuenta que no se incluye C2 porque tiene una secuencia de emisores diferente (A → D → C).

Figura 3: Agregación de métodos idénticos que comparten la misma pila de llamadas
Con las llamadas agregadas, se crea el gráfico tipo llama, como se muestra en la Figura 4. Ten en cuenta que, para cualquier llamada en un gráfico tipo llama, aparecen primero los destinatarios que consumen la mayor cantidad de tiempo de CPU.
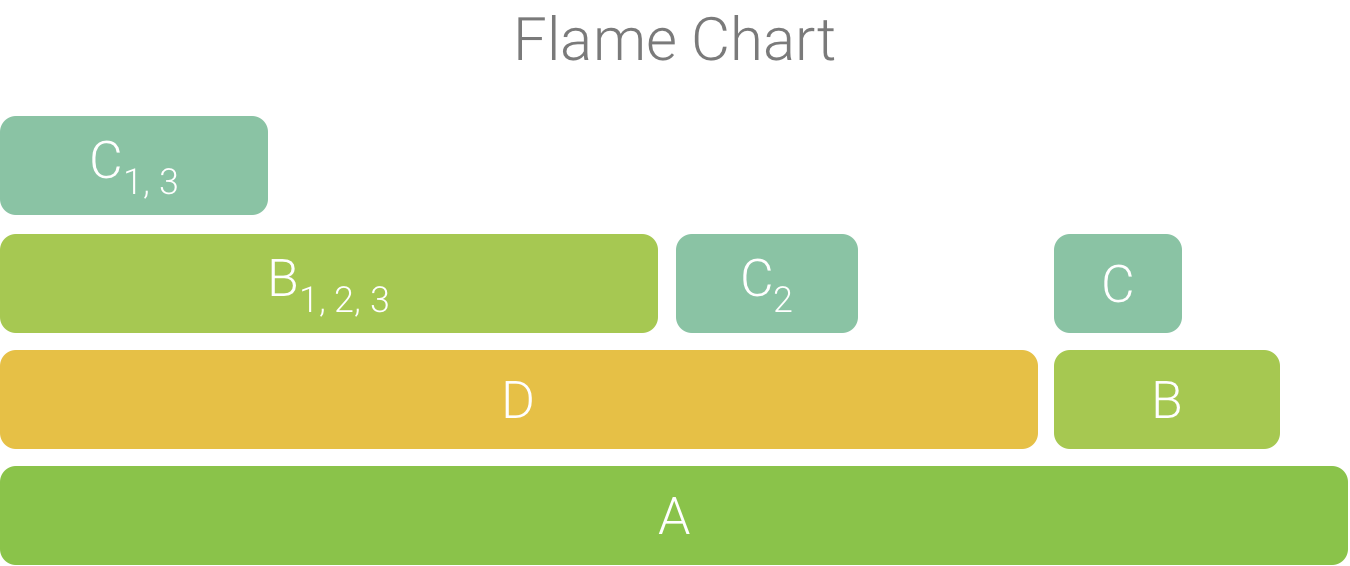
Figura 4: Representación en un gráfico tipo llama del gráfico de llamadas que se muestra en la Figura 5
Cómo inspeccionar seguimientos mediante Top Down y Bottom Up
La pestaña Top Down muestra una lista de llamadas en las que la expansión de un nodo de función o método muestra sus destinatarios. En la Figura 5, se muestra un gráfico de Top Down correspondiente al gráfico de llamadas de la Figura 1. Cada flecha del gráfico apunta de un emisor a un destinatario.
Como se muestra en la Figura 5, cuando se expande el nodo para el método A en la pestaña Top Down, se muestran sus destinatarios, los métodos B y D. Luego, cuando se expande el nodo para el método D, se muestran sus destinatarios, los métodos B y C, y así sucesivamente. Como sucede con la pestaña Flame chart, en el árbol de Top Down, se agrega la información de seguimiento de métodos idénticos que comparten la misma pila de llamadas. Es decir, en la pestaña Flame chart, se proporciona una representación gráfica de la pestaña Top down.
La pestaña Top Down proporciona la siguiente información para ayudar a describir el tiempo de CPU invertido en cada llamada (los tiempos también se representan como un porcentaje del tiempo total del subproceso en el rango seleccionado):
- Self: Es la cantidad de tiempo que tardó la llamada al método o la función en ejecutar su propio código y no el de sus destinatarios, como se muestra en la Figura 1 para el método D.
- Children: Es la cantidad de tiempo que la llamada al método o la función tardó en ejecutar el código de sus destinatarios y no el suyo propio, como se muestra en la Figura 1 para el método D.
- Total: Es la suma de los tiempos Self y Children del método (representa el tiempo total que la app tardó en ejecutar una llamada, como se ilustra en la Figura 1 para el método D).
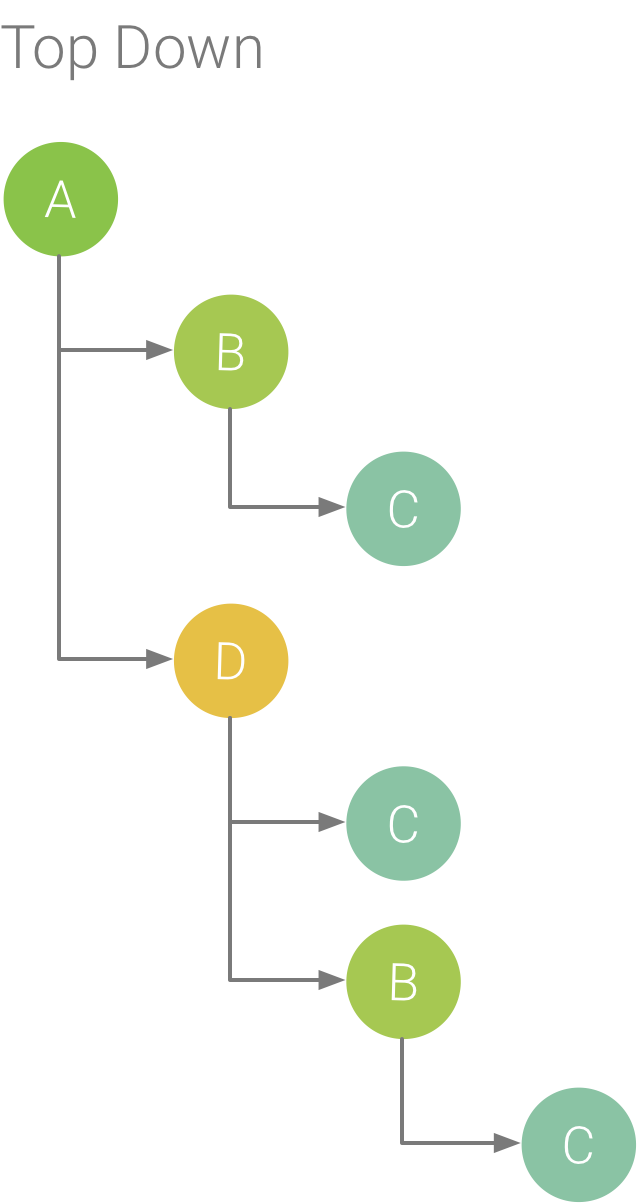
Figura 5: Árbol de Top Down
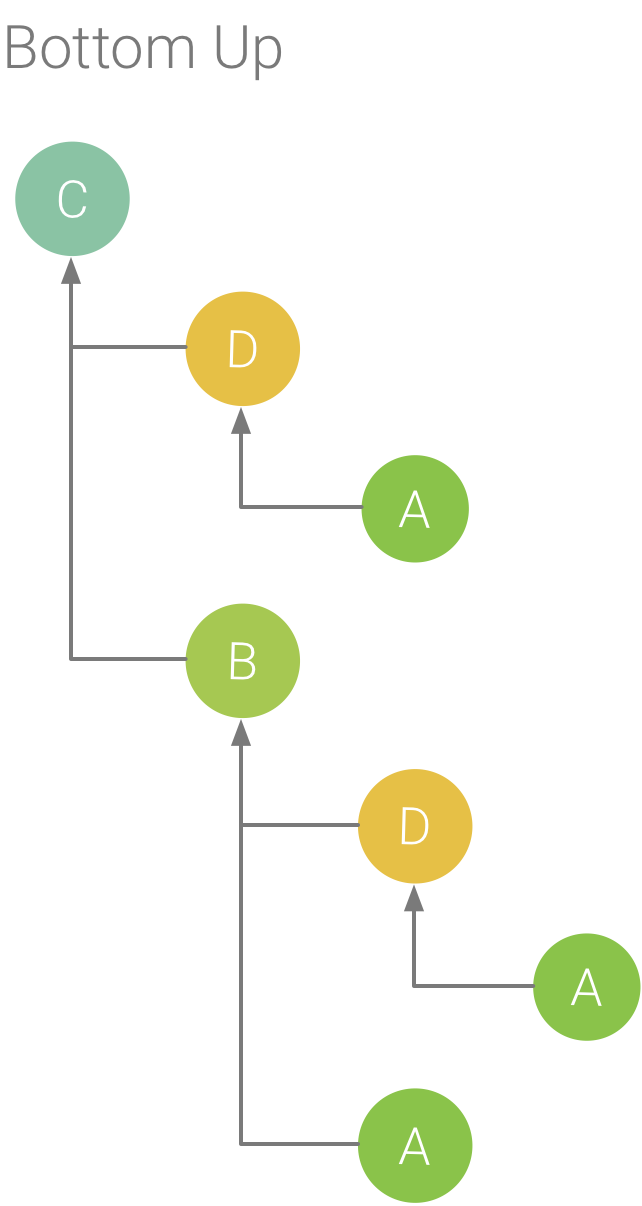
Figura 6: Árbol de Bottom Up para el método C de la Figura 5
La pestaña Bottom Up muestra una lista de llamadas en las que la expansión de un nodo o método de función muestra sus emisores. En la Figura 5, con el seguimiento de ejemplo que se muestra en la Figura 6, se proporciona un árbol Bottom Up para el método C. Al abrirse el nodo para el método C en el árbol Bottom Up, se muestra cada uno de sus emisores únicos, los métodos B y D. Ten en cuenta que, aunque B llama a C dos veces, B aparece una sola vez cuando se expande el nodo para el método C en el árbol Bottom Up. Luego, al expandirse el nodo para B, se muestran sus emisores, los métodos A y D.
La pestaña Bottom Up es útil para ordenar los métodos o funciones según los que más (o menos) tiempo de CPU consumen. Además, puedes inspeccionar cada nodo para determinar qué emisores pasan la mayor cantidad de tiempo de CPU invocando esos métodos o funciones. En comparación con el árbol de Top Down, la información de sincronización para cada método o función en un árbol de Bottom Up tiene que ver con el método que está en la parte superior de cada árbol (nodo superior). El tiempo de CPU también se representa como un porcentaje del tiempo total del subproceso durante ese registro. La siguiente tabla ayuda a comprender la manera en que debe interpretarse la información de sincronización para el nodo superior y sus emisores (subnodos).
| Self | Children | Total | |
|---|---|---|---|
| Método o función en la parte superior del árbol Bottom Up (nodo superior) | Representa el tiempo total que el método o la función tardó en ejecutar su propio código y no el de sus destinatarios. En comparación con el árbol de Top Down, esta información de tiempo representa una suma de todas las llamadas a este método o esta función durante el registro. | Representa el tiempo total que el método o la función tardó en ejecutar sus destinatarios y no su propio código. En comparación con el árbol de Top Down, esta información de tiempo representa la suma de todas las llamadas a los destinatarios de este método o función durante el registro. | La suma de los tiempos "self" y "children" |
| Emisores (subnodos) | Representa el tiempo total del destinatario cuando lo llama el emisor. Al usar el árbol de Bottom Up de la Figura 6 como ejemplo, el tiempo self para el método B sería igual a la suma de los tiempos self de cada ejecución del método C cuando lo llama B. | Representa el tiempo children total del destinatario cuando lo invoca el emisor. Al usar el árbol de Bottom Up de la Figura 6 como ejemplo, el tiempo children del método B sería igual a la suma de los tiempos children de cada ejecución del método C cuando lo llama B. | La suma de los tiempos "self" y "children" |
Nota: Para un registro en particular, Android Studio deja de recopilar datos nuevos cuando el generador de perfiles alcanza el límite de tamaño de archivo (esto, sin embargo, no detiene el registro). Normalmente, esto sucede mucho más rápido cuando se llevan a cabo seguimientos instrumentados, ya que este tipo de seguimiento recopila más datos en un período más corto, en comparación con un seguimiento muestreado. Si extiendes el tiempo de inspección a un período del registro que se produjo luego de alcanzar el límite, no cambiarán los datos de sincronización del panel de seguimiento (ya que no habrá nuevos datos disponibles). Además, en el panel de seguimiento, se muestra NaN para la información de sincronización cuando seleccionas solo la parte de un registro que no tiene datos disponibles.
Cómo inspeccionar seguimientos con la tabla de eventos
En la tabla de eventos, se enumeran todas las llamadas en el subproceso seleccionado actualmente. Para ordenar los eventos, haz clic en los encabezados de las columnas. Si seleccionas una fila de la tabla, puedes navegar por el cronograma a la hora de inicio y finalización de la llamada seleccionada. Esto te permite ubicar con precisión los eventos en el cronograma.

Figura 7: Cómo ver la pestaña de eventos en el panel de análisis
Cómo inspeccionar fotogramas de pila de llamadas
Las pilas de llamadas son útiles para comprender qué parte del código se ejecutó y el motivo de la invocación. Si se recopila un registro de muestra de pila de llamadas para un programa Java/Kotlin, la pila de llamadas generalmente incluye no solo el código Java/Kotlin, sino también los fotogramas del código nativo de JNI, la máquina virtual de Java. (p. ej.,
android::AndroidRuntime::start) y el kernel del sistema ([kernel.kallsyms]+offset). Esto se debe a que un programa Java o Kotlin generalmente se ejecuta a través de una máquina virtual de Java. Se requiere código nativo para ejecutar el programa en sí y para que el programa se comunique con el sistema y el hardware. El generador de perfiles presenta estos fotogramas para su precisión. Sin embargo, según tu investigación, podrías considerar que esos fotogramas de llamada adicionales podrían ser útiles o no. El generador de perfiles proporciona una forma de contraer fotogramas que no te interesan, de manera que puedas ocultar la información irrelevante para tu investigación.
En el siguiente ejemplo, el seguimiento de la imagen tiene muchos fotogramas con la etiqueta [kernel.kallsyms]+offset, que por el momento no son útiles para el desarrollo.
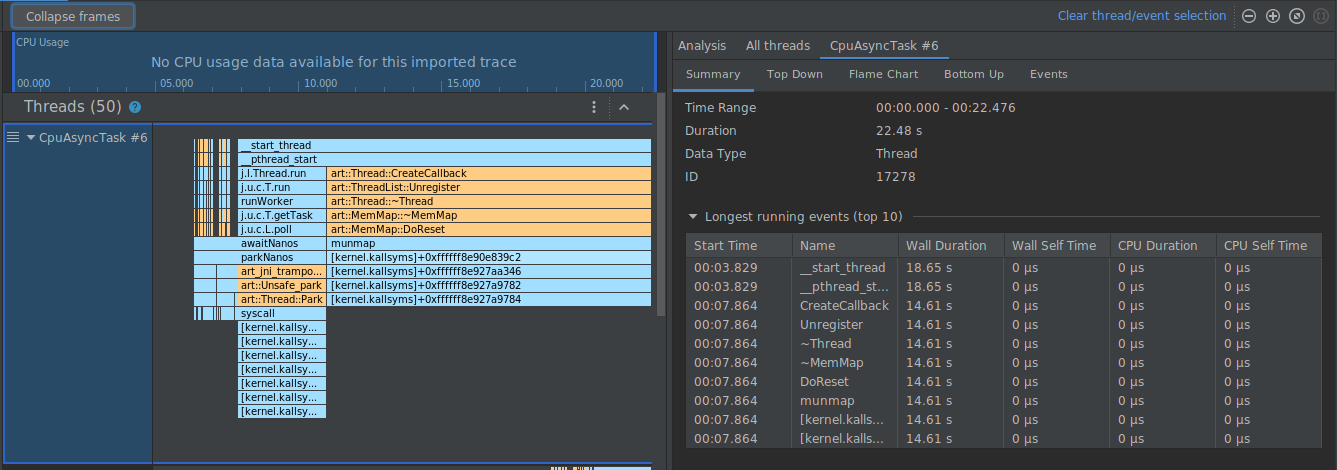
Para contraer estos fotogramas en uno, debes seleccionar el botón Collapse frames en la barra de herramientas, elegir las rutas que quieres contraer y seleccionar el botón Apply para aplicar los cambios. En este ejemplo, la ruta es [kernel.kallsyms].
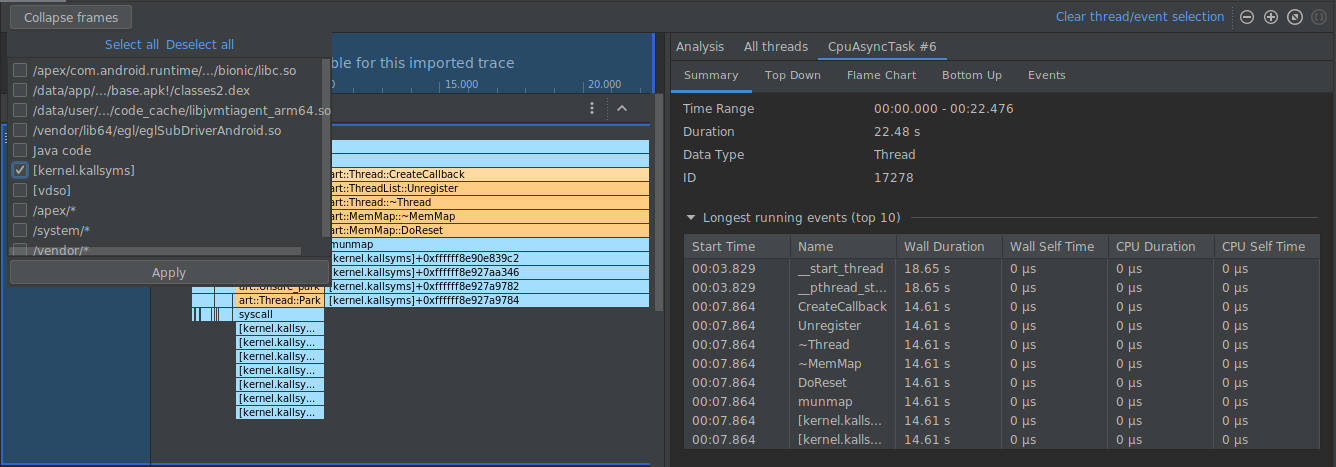
Si lo haces, se contraerán los fotogramas correspondientes a la ruta seleccionada tanto en el panel izquierdo como en el derecho, como se muestra a continuación.
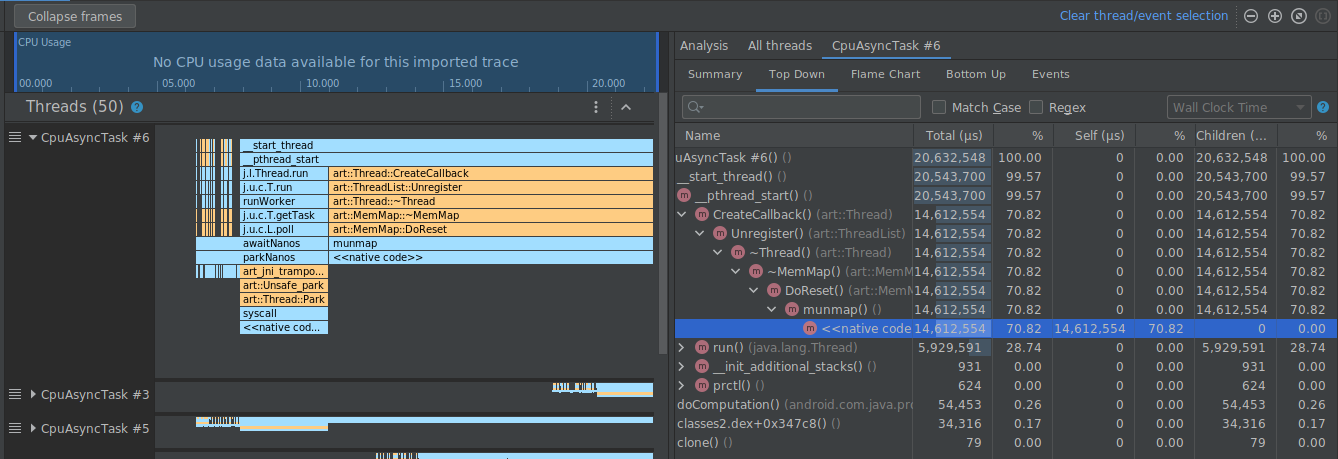
Cómo inspeccionar registros del sistema
Al inspeccionar un registro del sistema, puedes examinar los eventos de seguimiento en el cronograma Threads para ver los detalles de los eventos que se producen en cada subproceso. Coloca el cursor del mouse sobre un evento para ver su nombre y el tiempo empleado en cada estado. Haz clic en un evento para ver más información en el panel Analysis.
Cómo inspeccionar los registros del sistema: núcleos de la CPU
Además de los datos de programación de CPU, los registros del sistema también incluyen la frecuencia de CPU de cada núcleo. Esto muestra la cantidad de actividad en cada núcleo y puede darte una idea de qué núcleos son "grandes" o "pequeños" en los procesadores móviles modernos.

Figura 8: Visualización de la actividad de la CPU y eventos de seguimiento correspondientes al subproceso de procesamiento
En el panel CPU Cores, se muestra la actividad de los subprocesos que se programó en cada núcleo, como se muestra en la Figura 8. Coloca el puntero del mouse sobre una actividad para ver el subproceso que está ejecutando el núcleo en ese determinado momento.
Para obtener información adicional sobre la inspección de la información de registros del sistema, consulta la sección Cómo investigar problemas de rendimiento de IU de la documentación de systrace.
Cómo inspeccionar registros del sistema: cronograma de renderización de fotogramas
Puedes inspeccionar cuánto tiempo le toma a tu app procesar cada fotograma del subproceso principal y RenderThread para examinar los cuellos de botella que causan el bloqueo de la IU y una baja velocidad de fotogramas. A fin de descubrir cómo usar los registros del sistema para investigar y ayudar a reducir los bloqueos de la IU, consulta Detección de bloqueos de IU.
Cómo inspeccionar registros del sistema: memoria de proceso (RSS)
En el caso de las apps implementadas en dispositivos con Android 9 o versiones posteriores, en la sección de memoria de proceso (RSS), se muestra la cantidad de memoria física que la app usa en ese momento.

Figura 9: Visualización de memoria física en el generador de perfiles
Total
Esta es la cantidad total de memoria física que está usando tu proceso en ese momento. En los sistemas basados en Unix, esto se conoce como "tamaño del conjunto residente". Es la suma de toda la memoria que usan las asignaciones anónimas, las asignaciones de archivos y las asignaciones de memoria compartida.
Para los desarrolladores de Windows, el tamaño del conjunto residente es similar al tamaño del conjunto de trabajo.
Asignada
Este contador realiza un seguimiento de cuánta memoria física usan las asignaciones de memoria normal del proceso en el momento. Estas asignaciones son anónimas (no las respalda ningún archivo específico) y privadas (no se comparten). En la mayoría de las apps, estas consisten en asignaciones de montón (con malloc o new) y memoria de pila. Cuando se intercambia desde la memoria física, estas asignaciones se escriben en el archivo de intercambio del sistema.
Mapeos de archivos
En este contador, se hace un seguimiento de la cantidad de memoria física que el proceso usa para las asignaciones de archivos, es decir, la memoria que el administrador asigna desde archivos a una región de la memoria.
Compartida
Este contador realiza un seguimiento de cuánta memoria física se usa para compartir memoria entre este y otros procesos del sistema.