
UI レイヤには UI 関連の状態と UI ロジックが含まれていますが、データレイヤにはアプリデータとビジネス ロジックが含まれています。ビジネス ロジックは、アプリデータの作成、保存、変更方法を決定する実際のビジネスルールで構成されており、アプリに価値を提供するものです。
データレイヤでこのように関心の分離を行うことで、複数画面での使用、アプリの各要素間での情報共有ができるほか、単体テスト用に UI の外部でビジネス ロジックを再現することも可能になります。データレイヤのメリットについて詳しくは、アーキテクチャの概要ページをご覧ください。
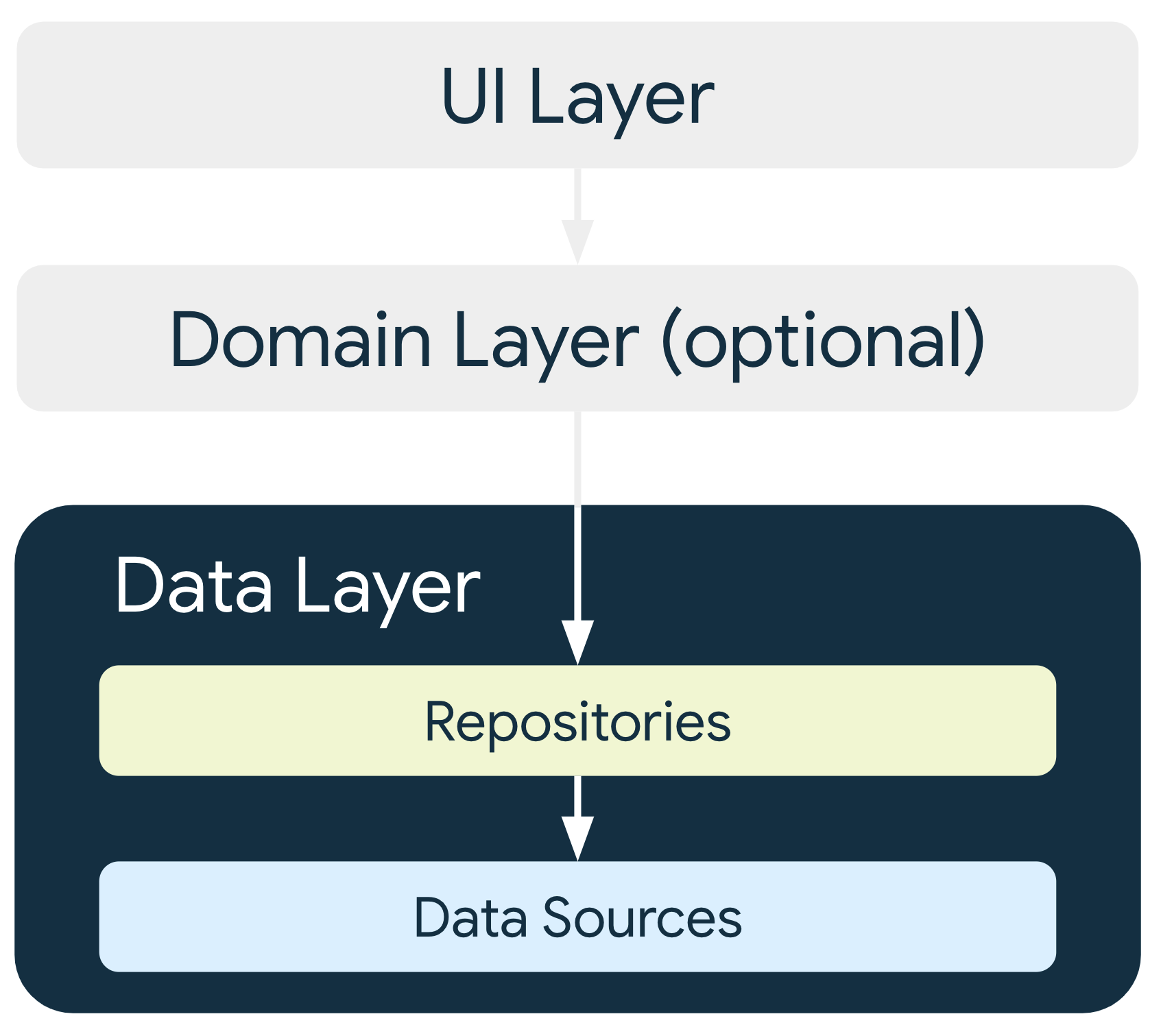
データレイヤのアーキテクチャ
データレイヤは、それぞれが 0 から多数のデータソースを含むことができるリポジトリで構成されています。アプリで処理するデータの種類ごとにリポジトリ クラスを作成する必要があります。たとえば、映画に関するデータであれば MoviesRepository クラス、支払いに関するデータであれば PaymentsRepository クラスを作成します。
リポジトリ クラスは、次のタスクを行います。
- アプリの他の部分にデータを公開する。
- データの変更を一元管理する。
- 複数のデータソース間の競合を解決する。
- アプリの他の部分からデータソースを抽象化する。
- ビジネス ロジックを格納する。
各データソース クラスは、ファイル、ネットワーク ソース、ローカル データベースなど、1 つのデータソースのみを処理する役割を担う必要があります。データソース クラスは、データ オペレーションのためにアプリとシステムの橋渡しをします。
必ずリポジトリ クラスをデータレイヤのエントリ ポイントとして使用し、階層内の他のレイヤがデータソースに直接アクセスしないようにしてください。状態ホルダーのクラス(UI レイヤのガイドを参照)またはユースケースのクラス(ドメインレイヤのガイドを参照)には、データソースを直接的な依存関係として含めることはできません。リポジトリ クラスをエントリ ポイントとして使用すると、アーキテクチャのさまざまなレイヤを個別にスケーリングできます。
このレイヤで公開されるデータは不変である必要があります。これにより、他のクラスによってデータが改ざんされ、値に不整合が発生するリスクをなくすことができます。不変のデータは、複数のスレッドによって安全に処理することもできます。詳しくは、スレッド化のセクションをご覧ください。
依存関係注入のベスト プラクティスに従い、リポジトリはコンストラクタの依存関係をデータソースとして使用します。
class ExampleRepository(
private val exampleRemoteDataSource: ExampleRemoteDataSource, // network
private val exampleLocalDataSource: ExampleLocalDataSource // database
) { /* ... */ }
API を公開する
通常、データレイヤのクラスは、ワンショットの作成、読み取り、更新、削除(CRUD)呼び出しを実行する関数や、時間の経過に伴うデータの変更について通知を受け取る関数を公開します。データレイヤは、各ケースで次の項目を公開する必要があります。
- ワンショット オペレーションの場合は、suspend 関数を公開します。
- 時間の経過に伴うデータ変更について通知を受け取るには、フローを公開します。
class ExampleRepository(
private val exampleRemoteDataSource: ExampleRemoteDataSource, // network
private val exampleLocalDataSource: ExampleLocalDataSource // database
) {
val data: Flow<Example> = ...
suspend fun modifyData(example: Example) { ... }
}
このガイドにおける命名規則
このガイドでは、リポジトリ クラスは担当するデータに基づいて命名されます。規則は次のとおりです。
データの種類 + Repository
たとえば、NewsRepository、MoviesRepository、PaymentsRepository などです。
データソース クラスには、担当するデータと使用するソースに基づいて名前が付けられます。規則は次のとおりです。
データの種類 + ソースの種類 + DataSource
データの種類については、実装が変わる可能性があるため、Remote や Local を使用すると汎用性が高くなります。たとえば、NewsRemoteDataSource や NewsLocalDataSource などです。ソースが重要な場合、より具体的な名前になるようにソースの種類を使用します。たとえば、NewsNetworkDataSource や NewsDiskDataSource などです。
データソースを使用するリポジトリはデータの保存方法を認識しないため、実装の詳細に基づく名前は付けないでください(例: UserSharedPreferencesDataSource)。このルールに従うと、そのソースを呼び出すレイヤに影響を与えることなくデータソースの実装を変更できます(例: SharedPreferences から DataStore への移行)。
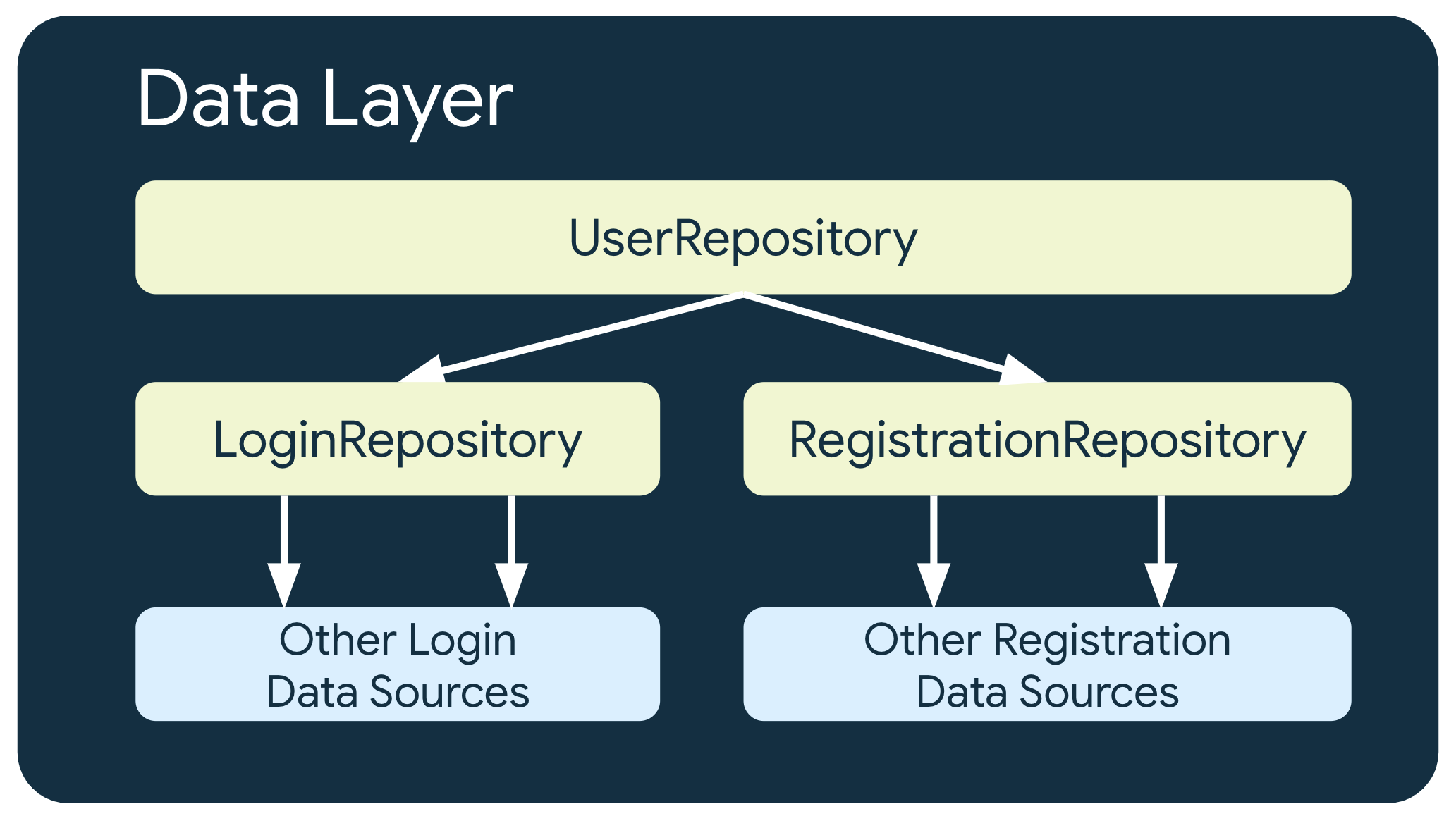
複数レベルのリポジトリ
より複雑なビジネス要件が含まれる場合は、リポジトリが他のリポジトリに依存しなければならないことがあります。具体的には、関連データが複数のデータソースから集約されたものである場合や、役割を別のリポジトリ クラスにカプセル化する必要がある場合などです。
たとえば、ユーザー認証データを処理するリポジトリ UserRepository は、その要件を満たすために LoginRepository や RegistrationRepository などの他のリポジトリに依存することがあります。
信頼できる情報源
各リポジトリで信頼できる唯一の情報源を定義することが重要です。信頼できる情報源には、常に正確で一貫性のある最新データが含まれています。実際、リポジトリから公開されるデータは、常に信頼できる情報源から直接取得されたデータでなければなりません。
信頼できる情報源は、データソース(データベースなど)の場合もあれば、リポジトリに含まれるメモリ内キャッシュの場合もあります。リポジトリはさまざまなデータソースを組み合わせて、データソース間の潜在的な競合を解決し、定期的に、またはユーザー入力イベントによって信頼できる唯一の情報源を更新します。
アプリのリポジトリによって、信頼できる情報源が異なる場合があります。たとえば、LoginRepository クラスはそのキャッシュを、PaymentsRepository クラスはネットワーク データソースを、それぞれ信頼できる情報源として使用している場合などです。
オフライン ファーストのサポートを提供するため、信頼できる情報源としてローカル データソース(データベースなど)を使用することをおすすめします。
スレッド化
データソースとリポジトリの呼び出しは、メインセーフ(メインスレッドから安全に呼び出せること)である必要があります。これらのクラスは、長時間実行ブロック オペレーションを実行する際に、ロジックの実行を適切なスレッドに移動する役割を担います。たとえば、データソースがファイルから読み取る場合、またはリポジトリが大きなリストで高コストなフィルタリングを実行する場合に、メインセーフである必要があります。
ほとんどのデータソースには、Room、Retrofit、Ktor が提供する suspend メソッド呼び出しなどのメインセーフな API がすでに用意されています。これらの API が利用可能な場合は、リポジトリで活用できます。
スレッド化について詳しくは、バックグラウンド処理ガイドをご覧ください。Kotlin ではコルーチンを使用することをおすすめします。
ライフサイクル
データレイヤ内のクラスのインスタンスは、ガベージ コレクション ルートから到達可能である限り、メモリ内に保持されます(通常はアプリの他のオブジェクトから参照されます)。
クラスにメモリ内データ(キャッシュなど)が含まれている場合、そのクラスの同じインスタンスを一定期間再利用することをおすすめします。これは、クラス インスタンスのライフサイクルとも呼ばれます。
クラスの役割がアプリ全体で重要な場合は、そのクラスのインスタンスのスコープを Application クラスに設定できます。これにより、インスタンスがアプリのライフサイクルに従うようになります。一方、アプリの特定のフロー(登録フローやログインフローなど)で同じインスタンスを再利用するだけであれば、そのフローのライフサイクルを持つクラスにインスタンスのスコープを設定する必要があります。たとえば、メモリ内データを含む RegistrationRepository のスコープを、RegistrationActivity または NavEntryDecorator を使用してバックスタックに設定します。
各インスタンスのライフサイクルは、アプリ内で依存関係を提供する方法を決定するための重要な要素です。依存関係を管理し、スコープを依存関係コンテナに設定できる依存関係注入のベスト プラクティスに従うことをおすすめします。Android でのスコープ設定について詳しくは、Android と Hilt でのスコープ設定に関するブログ投稿をご覧ください。
ビジネスモデルを表す
データレイヤから公開するデータモデルは、さまざまなデータソースから取得した情報のサブセットである場合があります。ネットワーク データソースもローカル データソースも、アプリが必要とする情報のみを返すのが理想的ですが、実際そうなるとは限りません。
たとえば、記事情報だけでなく、編集履歴、ユーザー コメント、一部のメタデータも返す News API サーバーがあるとします。
data class ArticleApiModel(
val id: Long,
val title: String,
val content: String,
val publicationDate: Date,
val modifications: Array<ArticleApiModel>,
val comments: Array<CommentApiModel>,
val lastModificationDate: Date,
val authorId: Long,
val authorName: String,
val authorDateOfBirth: Date,
val readTimeMin: Int
)
アプリの画面には記事のコンテンツと執筆者の基本情報しか表示されないため、記事に関する情報はそれほど必要ありません。そのため、モデルクラスを分離し、リポジトリで階層の他のレイヤに必要なデータのみを公開することをおすすめします。たとえば、Article モデルクラスをドメインレイヤと UI レイヤに公開するために、ネットワークから ArticleApiModel をカットする方法は次のとおりです。
data class Article(
val id: Long,
val title: String,
val content: String,
val publicationDate: Date,
val authorName: String,
val readTimeMin: Int
)
モデルクラスを分離すると、次のようなメリットがあります。
- データを必要最小限まで削減することで、アプリのメモリを節約できます。
- 外部のデータ型をアプリで使用されているデータ型に適応させることができます。たとえば、アプリで日付を表すために別のデータ型が使用されている場合があります。
- 関心の分離を適切に行うことができます。たとえば、モデルクラスが事前に定義されている場合、大規模なチームのメンバーは機能のネットワーク レイヤと UI レイヤに個別に取り組むことができます。
この手法を拡張し、アプリ アーキテクチャの他の部分(データソース クラス、ViewModel など)で個別のモデルクラスを定義することもできます。ただし、この場合はドキュメント作成とテストを適切に行えるように、追加のクラスとロジックを定義する必要があります。少なくとも、アプリの他の部分で想定されているデータとは異なるデータをデータソースが受信する場合は、新しいモデルを作成することをおすすめします。
データ オペレーションの種類
データレイヤは、重要度によって異なるオペレーションの種類に対応できます。これには UI 指向、アプリ指向、ビジネス指向のオペレーションがあります。
UI 指向のオペレーション
UI 指向のオペレーションは、ユーザーが特定の画面にいる場合にのみ重要であり、ユーザーがその画面から移動するとキャンセルされます。たとえば、データベースから取得したデータを表示する場合です。
UI 指向のオペレーションは通常、UI レイヤによってトリガーされ、呼び出し元のライフサイクル(ViewModel のライフサイクルなど)に従います。UI 指向のオペレーションの例については、ネットワーク リクエストを行うのセクションをご覧ください。
アプリ指向のオペレーション
アプリ指向のオペレーションは、アプリが開いている間だけ重要となります。アプリが終了されるか、プロセスが強制終了されると、これらのオペレーションはキャンセルされます。たとえば、ネットワーク リクエストの結果をキャッシュに保存し、後で必要に応じて使用できるようにする場合です。詳細については、メモリ内データのキャッシュ保存の実装のセクションをご覧ください。
通常、これらのオペレーションは Application クラスまたはデータレイヤのライフサイクルに従います。例については、オペレーションを画面より長く存続させるセクションをご覧ください。
ビジネス指向のオペレーション
ビジネス指向のオペレーションはキャンセルできません。これらはプロセス終了後も存続する必要があります。たとえば、ユーザーがプロフィールに投稿する写真のアップロードを完了する場合です。
ビジネス指向のオペレーションでは、WorkManager を使用することをおすすめします。詳しくは、WorkManager を使用したタスクのスケジュール設定をご覧ください。
エラーを公開する
リポジトリとデータソースとのインタラクションは、成功するか、失敗したときに例外をスローします。コルーチンと Flow の場合は、Kotlin の組み込みのエラー処理メカニズムを使用してください。suspend 関数によってトリガーされる可能性があるエラーの場合は、必要に応じて try/catch ブロックを使用します。Flow の場合は、catch 演算子を使用します。このアプローチでは、UI レイヤはデータレイヤを呼び出すときに例外を処理することが想定されています。
データレイヤでは、さまざまな種類のエラーを理解して処理し、カスタム例外(UserNotAuthenticatedException など)を使用して公開できます。
コルーチンのエラーについて詳しくは、コルーチンの例外に関するブログ投稿をご覧ください。
一般的なタスク
次のセクションでは、データレイヤを使用および設計して、Android アプリで一般的なタスクを実行する方法について説明します。下記の例は、ガイドの前半で説明した典型的なニュースアプリに基づいています。
ネットワーク リクエストを行う
ネットワーク リクエストは、Android アプリでよく行われるタスクの 1 つです。ニュースアプリは、ネットワークから取得した最新ニュースをユーザーに表示する必要があります。そのため、このアプリにはネットワーク オペレーションを管理するデータソース クラス NewsRemoteDataSource が必要になります。情報をアプリの他の部分に公開するために、ニュースデータに対するオペレーションを処理する新しいリポジトリ NewsRepository が作成されます。
要件としては、ユーザーが画面を開いたときに、常に最新ニュースが更新されるようにする必要があります。したがって、これは UI 指向のオペレーションになります。
データソースを作成する
データソースは、最新ニュース(ArticleHeadline インスタンスのリスト)を返す関数を公開するとともに、ネットワークから最新ニュースを取得するメインセーフな方法を提供します。そのためには、CoroutineDispatcher または Executor に依存してタスクを実行する必要があります。
ネットワーク リクエストの実行は、新しい fetchLatestNews() メソッドで処理されるワンショットの呼び出しです。
class NewsRemoteDataSource(
private val newsApi: NewsApi,
private val ioDispatcher: CoroutineDispatcher
) {
/**
* Fetches the latest news from the network and returns the result.
* This executes on an IO-optimized thread pool, the function is main-safe.
*/
suspend fun fetchLatestNews(): List<ArticleHeadline> =
// Move the execution to an IO-optimized thread since the ApiService
// doesn't support coroutines and makes synchronous requests.
withContext(ioDispatcher) {
newsApi.fetchLatestNews()
}
}
// Makes news-related network synchronous requests.
interface NewsApi {
fun fetchLatestNews(): List<ArticleHeadline>
}
NewsApi インターフェースは、ネットワーク API クライアントの実装を隠蔽します。インターフェースをサポートするのが Retrofit と HttpURLConnection のどちらであっても違いはありません。インターフェースに依存すると、アプリ内で API の実装を切り替えられるようになります。
リポジトリを作成する
このタスクのリポジトリ クラスに追加のロジックは不要であるため、NewsRepository はネットワーク データソースのプロキシとして機能します。この抽象化レイヤを追加するメリットについては、メモリ内でのキャッシュ保存のセクションをご覧ください。
// NewsRepository is consumed from other layers of the hierarchy.
class NewsRepository(
private val newsRemoteDataSource: NewsRemoteDataSource
) {
suspend fun fetchLatestNews(): List<ArticleHeadline> =
newsRemoteDataSource.fetchLatestNews()
}
UI レイヤからリポジトリ クラスを直接使用する方法については、UI レイヤのガイドをご覧ください。
データのメモリ内キャッシュ保存を実装する
ニュースアプリに新しい要件が導入されたとします。この要件は、前にリクエストが行われていた場合、ユーザーが画面を開いたときにキャッシュに保存されたニュースを表示するというものです。それ以外の場合、アプリはネットワーク リクエストを行って最新ニュースを取得します。
新しい要件に基づき、ユーザーがアプリを開いている間、最新ニュースをメモリに保持する必要があります。したがって、これはアプリ指向のオペレーションになります。
キャッシュ
データのメモリ内キャッシュ保存を追加するとユーザーがアプリを開いている間データを保持できます。キャッシュは、一定の期間(ここではユーザーがアプリを開いている間)メモリに情報を保存することを目的としています。キャッシュの実装にはさまざまな形式があり、単純な可変変数から、複数のスレッドでの読み取り/書き込みオペレーションから保護する高度なクラスに至るまで、多岐にわたります。ユースケースに応じて、リポジトリまたはデータソース クラスにキャッシュ保存を実装できます。
ネットワーク リクエストの結果をキャッシュに保存する
シンプルにするために、NewsRepository では可変変数を使用して最新ニュースをキャッシュに保存します。別のスレッドからの読み取りと書き込みから保護するために、Mutex を使用します。共有可能な可変状態と同時実行の詳細については、Kotlin ドキュメントをご覧ください。
次の実装では、Mutex で書き込み保護されたリポジトリ内の変数に最新ニュースの情報をキャッシュします。ネットワーク リクエストが成功した場合、データは latestNews 変数に割り当てられます。
class NewsRepository(
private val newsRemoteDataSource: NewsRemoteDataSource
) {
// Mutex to make writes to cached values thread-safe.
private val latestNewsMutex = Mutex()
// Cache of the latest news got from the network.
private var latestNews: List<ArticleHeadline> = emptyList()
suspend fun getLatestNews(refresh: Boolean = false): List<ArticleHeadline> {
if (refresh || latestNews.isEmpty()) {
val networkResult = newsRemoteDataSource.fetchLatestNews()
// Thread-safe write to latestNews
latestNewsMutex.withLock {
this.latestNews = networkResult
}
}
return latestNewsMutex.withLock { this.latestNews }
}
}
オペレーションを画面より長く存続させる
ネットワーク リクエストの処理中にユーザーが画面から移動した場合、リクエストはキャンセルされ、結果はキャッシュに保存されません。NewsRepository は、このロジックの実行に呼び出し元の CoroutineScope を使用しません。NewsRepository は代わりに、ライフサイクルにアタッチされた CoroutineScope を使用します。最新ニュースの取得は、アプリ指向のオペレーションにする必要があります。
依存関係注入のベスト プラクティスに従うために、NewsRepository は独自の CoroutineScope を作成する代わりに、コンストラクタのパラメータとしてスコープを受け取ります。リポジトリは作業のほとんどをバックグラウンド スレッドで行うため、CoroutineScope は Dispatchers.Default または独自のスレッドプールで構成する必要があります。
class NewsRepository(
...,
// This could be CoroutineScope(SupervisorJob() + Dispatchers.Default).
private val externalScope: CoroutineScope
) { ... }
NewsRepository は外部 CoroutineScope を使用してアプリ指向のオペレーションを実行する準備ができているため、データソースの呼び出しを実行して、そのスコープによって開始された新規コルーチンでその結果を保存する必要があります。
class NewsRepository(
private val newsRemoteDataSource: NewsRemoteDataSource,
private val externalScope: CoroutineScope
) {
/* ... */
suspend fun getLatestNews(refresh: Boolean = false): List<ArticleHeadline> {
return if (refresh) {
externalScope.async {
newsRemoteDataSource.fetchLatestNews().also { networkResult ->
// Thread-safe write to latestNews.
latestNewsMutex.withLock {
latestNews = networkResult
}
}
}.await()
} else {
return latestNewsMutex.withLock { this.latestNews }
}
}
}
async は、外部スコープでコルーチンを開始するために使用されます。ネットワーク リクエストが戻り、結果がキャッシュに保存されるまで、一時停止するための新しいコルーチンで await が呼び出されます。その時点でユーザーがまだ画面にいた場合は、最新ニュースが表示されます。ユーザーが画面から離れた場合は、await はキャンセルされますが、async 内のロジックは引き続き実行されます。
CoroutineScope のパターンの詳細を確認する。
ディスクのデータを保存して取得する
ブックマークしたニュースやユーザー設定などのデータを保存するとします。 このタイプのデータは、プロセスが終了しても存続し、ユーザーがネットワークに接続されていなくてもアクセスできるように必要があります。
作業対象のデータがプロセスの終了後も存続する必要がある場合、次のいずれかの方法でデータをディスクに保存します。
- クエリの実行、参照整合性、部分更新が必要な大規模なデータセットの場合、Room データベースにデータを保存します。ニュースアプリの例では、ニュース記事や執筆者をデータベースに保存できます。
- 取得と設定のみが必要(クエリの実行や部分更新は不要)な小さなデータセットの場合、Datastore を使用します。ニュースアプリの例では、ユーザーの好みの日付形式やその他の表示設定を DataStore に保存できます。
- JSON オブジェクトのようなデータチャンクにはファイルを使用します。
信頼できる情報源のセクションで説明したように、各データソースは 1 つのソースのみを処理し、特定のデータ型(News、Authors、NewsAndAuthors、UserPreferences など)に対応しています。データソースを使用するクラスは、データの保存方法(データベースやファイルなど)を認識しません。
データソースとしての Room
各データソースが特定の種類のデータに関して 1 つのソースのみを処理する役割を担う必要があるため、Room データソースはデータアクセス オブジェクト(DAO)またはデータベース自体をパラメータとして受け取ります。たとえば、NewsLocalDataSource は NewsDao のインスタンスを、AuthorsLocalDataSource は AuthorsDao のインスタンスを、それぞれパラメータとして受け取ります。
追加のロジックが不要な場合は、DAO をリポジトリに直接挿入できることがあります。これは、DAO がテストで簡単に置換できるインターフェースであるためです。
Room API の操作について詳しくは、Room ガイドをご覧ください。
データソースとしての DataStore
DataStore は、ユーザー設定などの Key-Value ペアを格納するのに最適です。たとえば、時刻の形式、通知設定、既読のニュース記事を表示するかどうかなどを設定できます。DataStore では、プロトコル バッファを使用して型付きオブジェクトを保存することもできます。
他のオブジェクトと同様に、DataStore でサポートされるデータソースには、特定の型やアプリの特定の部分に対応するデータを含める必要があります。DataStore の読み取りは、値が更新されるたびに出力される Flow として公開されるので、これは DataStore では特に重要です。このため、関連する設定は同じ DataStore に保存する必要があります。
たとえば、NotificationsDataStore では通知関連の設定のみを処理し、NewsPreferencesDataStore ではニュース画面の設定のみを処理するようにします。これにより、newsScreenPreferencesDataStore.data フローはその画面に関連する設定が変更された場合にのみ出力されるため、更新のスコープを適切に設定できます。また、オブジェクトのライフサイクルはニュース画面が表示されている間だけ存続するため、オブジェクトのライフサイクルを短くすることもできます。
DataStore API の操作について詳しくは、DataStore ガイドをご覧ください。
データソースとしてのファイル
JSON オブジェクトやビットマップなどの大きなオブジェクトを処理する場合は、File オブジェクトを操作してスレッドの切り替えを処理する必要があります。
ファイル ストレージの操作の詳細については、ストレージの概要のページをご覧ください。
WorkManager を使用してタスクのスケジュールを設定する
ニュースアプリに別の新しい要件が導入されたとします。この要件は、デバイスが充電中で定額制ネットワークに接続されている場合にのみ、最新ニュースを定期的かつ自動的に取得するオプションをユーザーに提供するというものです。そのため、これはビジネス指向のオペレーションになります。この要件により、ユーザーがアプリを開いたときにデバイスが接続されていない場合でも、最新ニュースを表示できるようになります。
WorkManager を使用すると、信頼性の高い非同期処理を簡単にスケジュールできるほか、制約の管理を行うことも可能です。このライブラリは永続的な処理に向いています。上記で定義されたタスクを実行するために、Worker クラス(RefreshLatestNewsWorker)が作成されます。このクラスは、最新ニュースを取得してディスクにキャッシュするために、依存関係として NewsRepository を使用します。
class RefreshLatestNewsWorker(
private val newsRepository: NewsRepository,
context: Context,
params: WorkerParameters
) : CoroutineWorker(context, params) {
override suspend fun doWork(): Result = try {
newsRepository.refreshLatestNews()
Result.success()
} catch (error: Throwable) {
Result.failure()
}
}
このタイプのタスクのビジネス ロジックは、独自のクラスにカプセル化し、別のデータソースとして扱う必要があります。これにより、WorkManager は、すべての制約が満たされたときに、バックグラウンド スレッドで処理が実行されるようにする役割のみを担うようになります。このパターンに従うことで、必要に応じてさまざまな環境で実装をすばやく入れ替えることができます。
この例では、このニュース関連のタスクを NewsRepository から呼び出す必要があり、新しいデータソース(NewsTasksDataSource)を依存関係として使用します。実装は次のようになります。
private const val REFRESH_RATE_HOURS = 4L
private const val FETCH_LATEST_NEWS_TASK = "FetchLatestNewsTask"
private const val TAG_FETCH_LATEST_NEWS = "FetchLatestNewsTaskTag"
class NewsTasksDataSource(
private val workManager: WorkManager
) {
fun fetchNewsPeriodically() {
val fetchNewsRequest = PeriodicWorkRequestBuilder<RefreshLatestNewsWorker>(
REFRESH_RATE_HOURS, TimeUnit.HOURS
).setConstraints(
Constraints.Builder()
.setRequiredNetworkType(NetworkType.TEMPORARILY_UNMETERED)
.setRequiresCharging(true)
.build()
)
.addTag(TAG_FETCH_LATEST_NEWS)
workManager.enqueueUniquePeriodicWork(
FETCH_LATEST_NEWS_TASK,
ExistingPeriodicWorkPolicy.KEEP,
fetchNewsRequest.build()
)
}
fun cancelFetchingNewsPeriodically() {
workManager.cancelAllWorkByTag(TAG_FETCH_LATEST_NEWS)
}
}
これらの種類のクラスには、担当するデータ(NewsTasksDataSource、PaymentsTasksDataSource など)に基づく名前が付けられます。特定のデータ型に関連するすべてのタスクは、同じクラスにカプセル化する必要があります。
アプリの起動時にタスクをトリガーする必要がある場合は、Initializer からリポジトリを呼び出す App Startup ライブラリを使用して WorkManager リクエストをトリガーすることをおすすめします。
WorkManager API の操作の詳細については、WorkManager ガイドをご覧ください。
テスト
依存関係注入のベスト プラクティスは、アプリをテストする際に役立ちます。また、外部リソースと通信するクラスにインターフェースを利用することも有用です。単体テストの際に、その依存関係の疑似バージョンを注入して、テストの確定性と信頼性を確保できます。
単体テスト
データレイヤをテストする際は、一般的なテスト ガイダンスが適用されます。単体テストでは、必要に応じて実際のオブジェクトを使用し、ファイルからの読み取りやネットワークからの読み取りなど、外部ソースにアクセスする依存関係を模倣します。
統合テスト
外部ソースにアクセスする統合テストは、実際のデバイスで実施する必要があるため、確定性が低くなりがちです。統合テストの信頼性を高めるため、これらのテストは管理された環境で実施することをおすすめします。
データベースの場合、Room を使用することで、テストで完全に制御できるインメモリ データベースを作成できます。詳細については、データベースのテストとデバッグをご覧ください。
ネットワークの場合、WireMock や MockWebServer などの一般的なライブラリを使用して、HTTP および HTTPS 呼び出しを模倣し、想定どおりリクエストが行われることを確認できます。
参考情報
サンプル
あなたへのおすすめ
- 注: JavaScript がオフになっている場合はリンクテキストが表示されます
- ドメインレイヤ
- オフラインファースト アプリの作成
- UI 状態生成