
אפליקציה שפועלת אופליין היא אפליקציה שיכולה לבצע את כל הפונקציונליות העיקרית שלה או חלק קריטי מהן בלי גישה לאינטרנט. כלומר, הוא יכול לבצע חלק מהלוגיקה העסקית שלו או את כולה במצב אופליין.
השיקולים לבניית אפליקציה שפועלת אופליין מתחילים בשכבת הנתונים, שמאפשרת גישה לנתוני האפליקציה וללוגיקה העסקית. יכול להיות שמעת לעת האפליקציה תצטרך לרענן את הנתונים האלה ממקורות חיצוניים למכשיר. לשם כך, יכול להיות שהיא תצטרך להשתמש במשאבי רשת כדי להישאר מעודכנת.
הזמינות של הרשת לא תמיד מובטחת. בדרך כלל, יש תקופות שבהן החיבור של המכשירים לרשת לא יציב או איטי. יכול להיות שהמשתמשים יחוו את הבעיות הבאות:
- רוחב פס מוגבל באינטרנט
- הפרעות זמניות בחיבור, למשל כשנמצאים במעלית או במנהרה
- גישה לנתונים מדי פעם – לדוגמה, טאבלטים עם Wi-Fi בלבד
ללא קשר לסיבה, ברוב המקרים אפליקציה יכולה לפעול בצורה מספקת בנסיבות האלה. כדי לוודא שהאפליקציה פועלת בצורה תקינה במצב אופליין, היא צריכה להיות מסוגלת לבצע את הפעולות הבאות:
- להישאר שמיש גם ללא חיבור רשת מהימן
- הצגת נתונים מחנויות מקומיות למשתמשים באופן מיידי במקום להמתין להשלמה או לכישלון של הקריאה הראשונה לרשת
- אחזור נתונים באופן שמתחשב בסטטוס הסוללה ובנתונים – לדוגמה, על ידי שליחת בקשות לאחזור נתונים רק בתנאים אופטימליים, כמו בזמן טעינה או כשיש חיבור ל-Wi-Fi
אפליקציה שעומדת בקריטריונים האלה נקראת לעיתים קרובות אפליקציה שפועלת אופליין קודם.
עיצוב אפליקציה שפועלת קודם אופליין
כשמתכננים אפליקציה שפועלת אופליין, מתחילים בשכבת הנתונים ובשתי הפעולות העיקריות שאפשר לבצע בנתוני האפליקציה:
- קריאה: אחזור נתונים לשימוש בחלקים אחרים של האפליקציה, כמו הצגת מידע למשתמש. בדרך כלל, כדי לעשות את זה ב-Compose, צריך להתבונן במצב. כשממשק המשתמש מתייחס למקור הנתונים המקומי כאל מצב, המסך משקף את הנתונים המקומיים האחרונים באופן אוטומטי.
- פעולות כתיבה: שמירת קלט של משתמשים לאחזור מאוחר יותר. ב-Compose, בדרך כלל עושים את זה באמצעות אירועים ופעולות שנשלחים מממשק המשתמש אל ViewModel.
מאגרי מידע בשכבת הנתונים אחראים לשילוב מקורות נתונים כדי לספק נתונים לאפליקציה. באפליקציה שפועלת אופליין קודם, צריך להיות לפחות מקור נתונים אחד שלא דורש גישה לרשת כדי לבצע את המשימות הקריטיות ביותר שלו. אחת מהמשימות הקריטיות האלה היא קריאת נתונים.
נתוני מודל באפליקציה שפועלת קודם במצב אופליין
לאפליקציה במודל אופליין-פירסט יש לפחות 2 מקורות נתונים לכל מאגר שמשתמש במשאבי רשת:
- מקור הנתונים של המוצרים בחנויות המקומיות
- מקור הנתונים של הרשת
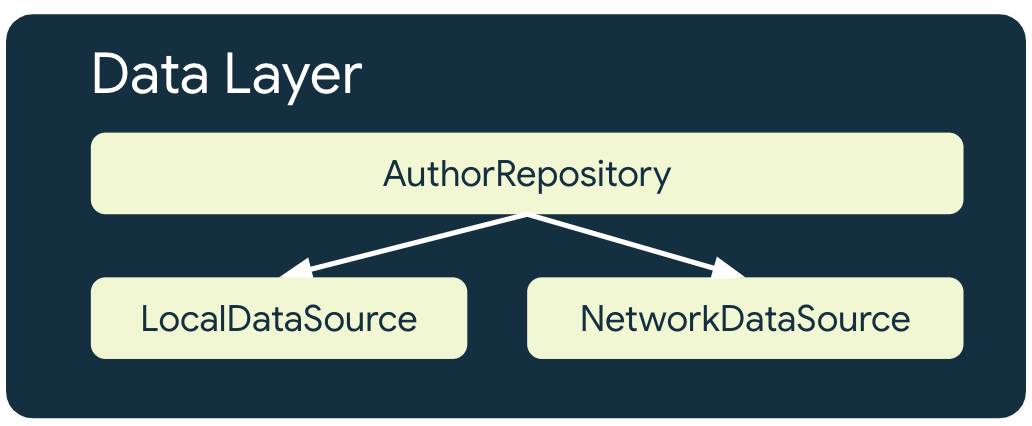
מקור הנתונים של המוצרים בחנויות המקומיות
מקור הנתונים המקומי הוא מקור המידע האמין של האפליקציה. הוא צריך להיות המקור הבלעדי של כל הנתונים ששכבות גבוהות יותר של האפליקציה קוראות. כך מובטחת עקביות הנתונים בין מצבי החיבור. מקור הנתונים המקומי מגובה בדרך כלל באחסון שמועבר לדיסק. אלה כמה דרכים נפוצות לשמירת נתונים בדיסק:
- מקורות נתונים מובְנים, כמו מסדי נתונים רלציוניים כמו Room
- מקורות נתונים לא מובְנים – לדוגמה, מאגרי אחסון לפרוטוקולים עם DataStore
- קבצים פשוטים
מקור הנתונים של הרשת
מקור הנתונים של הרשת הוא המצב בפועל של האפליקציה. במקרה הטוב, מקור הנתונים המקומי מסונכרן עם מקור הנתונים ברשת. יכול להיות גם שהנתונים מחנויות מקומיות לא יהיו עדכניים כמו הנתונים במקור הנתונים ברשת. במקרה כזה, צריך לעדכן את האפליקציה כשמתחברים שוב לאינטרנט. לעומת זאת, יכול להיות שיהיה פער בין מקור הנתונים ברשת לבין מקור הנתונים המקומי עד שהאפליקציה תוכל לעדכן אותו כשהקישוריות תחזור. שכבות הדומיין וממשק המשתמש של האפליקציה לא יכולות לתקשר ישירות עם שכבת הרשת. האחריות של מארח repository היא לתקשר עם מקור הנתונים המקומי ולהשתמש בו כדי לעדכן אותו.
חשיפת משאבים
יכול להיות הבדל מהותי בין מקורות הנתונים המקומיים לבין מקורות הנתונים ברשת, באופן שבו האפליקציה יכולה לקרוא ולכתוב נתונים במקורות האלה. הפעלת שאילתות על מקור נתונים מקומי יכולה להיות מהירה וגמישה, למשל כשמשתמשים בשאילתות SQL. לעומת זאת, מקורות נתונים ברשת יכולים להיות איטיים ומוגבלים, למשל כשניגשים למשאבי RESTful באופן מצטבר לפי מזהה. כתוצאה מכך, לכל מקור נתונים לרוב נדרשת ייצוג משלו של הנתונים שהוא מספק. לכן, יכול להיות שלמקור הנתונים מחנויות מקומיות ולמקור הנתונים של הרשת יהיו מודלים משלהם.
מבנה הספריות הבא ממחיש את הרעיון הזה. התווית
AuthorEntity מייצגת מחבר שנקרא ממסד הנתונים המקומי של האפליקציה, והתווית
NetworkAuthor מייצגת מחבר שעבר סריאליזציה ברשת:
data/
├─ local/
│ ├─ entities/
│ │ ├─ AuthorEntity
│ ├─ dao/
│ ├─ NiADatabase
├─ network/
│ ├─ NiANetwork
│ ├─ models/
│ │ ├─ NetworkAuthor
├─ model/
│ ├─ Author
├─ repository/
הפרטים של AuthorEntity ושל NetworkAuthor:
/**
* Network representation of [Author]
*/
@Serializable
data class NetworkAuthor(
val id: String,
val name: String,
val imageUrl: String,
val twitter: String,
val mediumPage: String,
val bio: String,
)
/**
* Defines an author for either an [EpisodeEntity] or [NewsResourceEntity].
* It has a many-to-many relationship with both entities
*/
@Entity(tableName = "authors")
data class AuthorEntity(
@PrimaryKey
val id: String,
val name: String,
@ColumnInfo(name = "image_url")
val imageUrl: String,
@ColumnInfo(defaultValue = "")
val twitter: String,
@ColumnInfo(name = "medium_page", defaultValue = "")
val mediumPage: String,
@ColumnInfo(defaultValue = "")
val bio: String,
)
מומלץ לשמור את AuthorEntity ואת NetworkAuthor
הפונקציות הפנימיות בשכבת הנתונים, ולחשוף סוג שלישי של פונקציות לשכבות חיצוניות. ההגנה הזו מיועדת לשכבות חיצוניות מפני שינויים קלים במקורות הנתונים המקומיים והרשתיים, שלא משנים באופן מהותי את ההתנהגות של האפליקציה. דוגמה לכך מופיעה בקטע הקוד הבא:
/**
* External data layer representation of a "Now in Android" Author
*/
data class Author(
val id: String,
val name: String,
val imageUrl: String,
val twitter: String,
val mediumPage: String,
val bio: String,
)
לאחר מכן, מודל הרשת יכול להגדיר שיטת הרחבה כדי להמיר אותו למודל המקומי, ובאופן דומה, למודל המקומי יש שיטה להמרה שלו לייצוג החיצוני, כמו שמוצג בקטע הקוד הבא:
/**
* Converts the network model to the local model for persisting
* by the local data source
*/
fun NetworkAuthor.asEntity() = AuthorEntity(
id = id,
name = name,
imageUrl = imageUrl,
twitter = twitter,
mediumPage = mediumPage,
bio = bio,
)
/**
* Converts the local model to the external model for use
* by layers external to the data layer
*/
fun AuthorEntity.asExternalModel() = Author(
id = id,
name = name,
imageUrl = imageUrl,
twitter = twitter,
mediumPage = mediumPage,
bio = bio,
)
קריאות
פעולות קריאה הן הפעולה הבסיסית בנתוני האפליקציה באפליקציה שפועלת במצב אופליין. לכן, צריך לוודא שהאפליקציה יכולה לקרוא את הנתונים, וברגע שנתונים חדשים זמינים, האפליקציה יכולה להציג אותם. אפליקציה שיכולה לעשות את זה היא אפליקציה ריאקטיבית כי היא חושפת ממשקי API לקריאה עם סוגים שניתנים לצפייה.
בקטע הקוד הבא, הפונקציה OfflineFirstTopicRepository מחזירה Flows לכל ממשקי ה-API לקריאה. כך הוא יכול לעדכן את הקוראים שלו כשהוא מקבל עדכונים ממקור הנתונים של הרשת. במילים אחרות, הוא מאפשר ל-OfflineFirstTopicRepository לדחוף שינויים כשמקור הנתונים המקומי שלו לא תקף. לכן, כל קורא של OfflineFirstTopicRepository צריך להיות מוכן לטפל בשינויים בנתונים שיכולים להתרחש כשחיבור הרשת משוחזר באפליקציה. בנוסף, OfflineFirstTopicRepository קורא נתונים ישירות ממקור הנתונים המקומי. הוא יכול לעדכן את הקוראים על שינויים בנתונים רק אחרי שהוא מעדכן קודם את מקור הנתונים המקומי שלו.
class TopicsViewModel(
offlineFirstTopicsRepository: OfflineFirstTopicsRepository
) : ViewModel() {
val topics: StateFlow<List<Topic>> = offlineFirstTopicsRepository.getTopicsStream()
.stateIn(
scope = viewModelScope,
started = SharingStarted.WhileSubscribed(5_000),
initialValue = emptyList()
)
}
באפליקציית Jetpack פיתוח נייטיב, משתמשים ב-ViewModel כדי לגשר בין שכבת הנתונים לממשק המשתמש.
ב-ViewModel, ממירים את Flow ל-StateFlow באמצעות האופרטור stateIn. לאחר מכן, רכיבי ה-Composable אוספים את המצבים האלה באמצעות collectAsStateWithLifecycle() ומנהלים אוטומטית את המינויים באופן שמודע למחזור החיים.
מידע נוסף על collectAsStateWithLifecycle() זמין במאמר בנושא מצב ו-Jetpack פיתוח נייטיב.
אסטרטגיות לטיפול בשגיאות
יש דרכים ייחודיות לטפל בשגיאות באפליקציות שפועלות במצב אופליין, בהתאם למקורות הנתונים שבהם הן עשויות להתרחש. בקטעי המשנה הבאים מפורטות האסטרטגיות האלה.
מקור נתונים מחנויות מקומיות
כדאי לנסות לצמצם את השגיאות בקריאה ממקור הנתונים המקומי. כדי להגן על הקוראים מפני שגיאות, צריך להשתמש באופרטור catch ב-Flow שמהם הקורא אוסף נתונים.
אפשר להשתמש באופרטור catch ב-ViewModel באופן הבא:
class AuthorViewModel(
authorsRepository: AuthorsRepository,
...
) : ViewModel() {
private val authorId: String = ...
// Observe author information
private val authorStream: Flow<Author> =
authorsRepository.getAuthorStream(
id = authorId
)
.catch { emit(Author.empty()) }
}
כדי להשתמש בגישה עמידה יותר, כדאי לשקול פתרון LCE (שגיאה בטעינת תוכן). ב-LCE, אם יש כשל בקריאה, מוצג מצב שגיאה. בדרך כלל, כדי להשיג LCE, יוצרים מודלים של מצבי ממשק המשתמש כמחלקות אטומות של Kotlin.
// Define the LCE UI state
sealed interface AuthorUiState {
data object Loading : AuthorUiState
data class Success(val author: Author) : AuthorUiState
data object Error : AuthorUiState
}
class AuthorViewModel(
authorsRepository: AuthorsRepository,
...
) : ViewModel() {
private val authorId: String = ...
// Observe author information and map to LCE state
val authorUiState: StateFlow<AuthorUiState> =
authorsRepository.getAuthorStream(id = authorId)
.map<Author, AuthorUiState> { author ->
AuthorUiState.Success(author)
}
.catch { emit(AuthorUiState.Error) }
.stateIn(
scope = viewModelScope,
started = SharingStarted.WhileSubscribed(5_000),
initialValue = AuthorUiState.Loading
)
}
מקור נתונים של רשת
אם מתרחשות שגיאות בקריאת נתונים ממקור נתונים ברשת, האפליקציה צריכה להשתמש בהיוריסטיקה כדי לנסות שוב לאחזר נתונים. דוגמאות להיוריסטיקות נפוצות:
השהיה מעריכית לפני ניסיון חוזר (exponential backoff)
בהשהיה מעריכית לפני ניסיון חוזר, האפליקציה ממשיכה לנסות לקרוא ממקור נתוני הרשת במרווחי זמן הולכים וגדלים עד שהיא מצליחה, או עד שתנאים אחרים קובעים שהיא צריכה להפסיק.
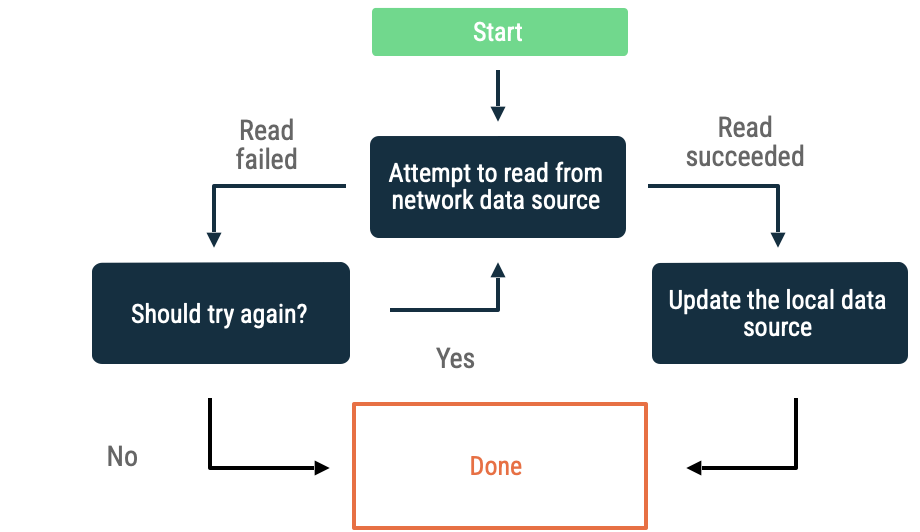
הקריטריונים להערכה אם האפליקציה ממשיכה להשהות את הפעולה כוללים את הדברים הבאים:
- סוג השגיאה שמקור הנתונים של הרשת ציין. לדוגמה, כדאי לנסות שוב לבצע קריאות לרשת שמחזירות שגיאה שמציינת חוסר קישוריות. אל תנסו שוב לשלוח בקשות HTTP שלא אושרו עד שיהיו פרטי כניסה מתאימים.
- מספר הניסיונות החוזרים המקסימלי המותר.
מעקב אחרי החיבור לרשת
בגישה הזו, בקשות קריאה מתווספות לתור עד שהאפליקציה מוודאת שהיא יכולה להתחבר למקור הנתונים ברשת. אחרי שנוצר חיבור, בקשת הקריאה מוצאת מהתור, הנתונים נקראים ומקור הנתונים המקומי מתעדכן. ב-Android, יכול להיות שהתור הזה ינוהל באמצעות מסד נתונים של Room, והוא יתרוקן כעבודה מתמשכת באמצעות WorkManager.
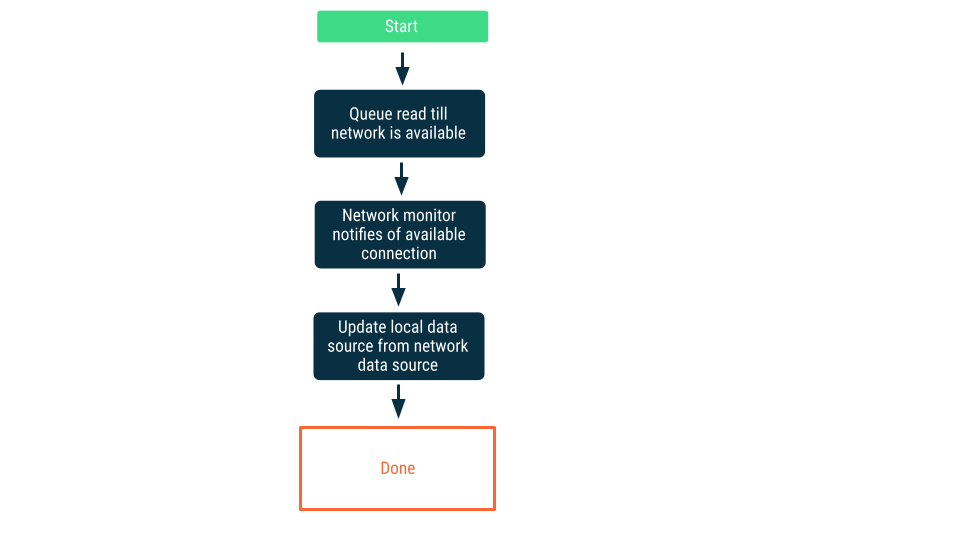
כותב
הדרך המומלצת לקרוא נתונים באפליקציה שפועלת אופליין היא באמצעות סוגים שניתנים לצפייה, אבל המקבילה לממשקי API לכתיבה היא ממשקי API אסינכרוניים כמו פונקציות השהיה. כך נמנעת חסימה של שרשור ה-UI, וקל יותר לטפל בשגיאות כי פעולות כתיבה באפליקציות שפועלות במצב אופליין עלולות להיכשל כשעוברים בין גבולות רשת.
interface UserDataRepository {
/**
* Updates the bookmarked status for a news resource
*/
suspend fun updateNewsResourceBookmark(newsResourceId: String, bookmarked: Boolean)
}
בקטע הקוד הקודם, ה-API האסינכרוני שנבחר הוא Coroutines כי השיטה מושהית.
כתיבת אסטרטגיות
כשכותבים נתונים באפליקציות שפועלות במצב אופליין, יש שלוש אסטרטגיות שכדאי לקחת בחשבון. הבחירה תלויה בסוג הנתונים שנכתבים ובדרישות של האפליקציה:
כתיבה באינטרנט בלבד
ניסיון לכתוב את הנתונים מעבר לגבולות הרשת. אם הפעולה מצליחה, מעדכנים את מקור הנתונים מחנויות מקומיות. אחרת, מעלים חריגה ומאפשרים למתקשר להגיב בהתאם.
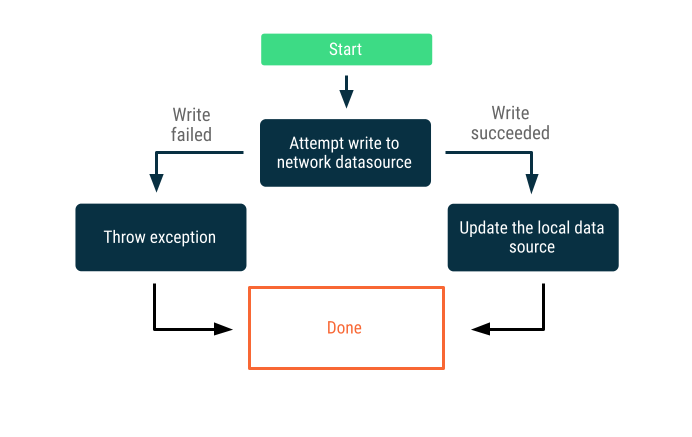
האסטרטגיה הזו משמשת לעיתים קרובות לטרנזקציות כתיבה שצריכות להתבצע אונליין כמעט בזמן אמת – לדוגמה, העברה בנקאית. יכול להיות שפעולות כתיבה ייכשלו, ולכן לעיתים קרובות צריך להודיע למשתמש על הכישלון או למנוע מהמשתמש לנסות לכתוב נתונים מלכתחילה. ריכזנו כאן כמה אסטרטגיות שאפשר להשתמש בהן בתרחישים האלה:
- אם אפליקציה דורשת גישה לאינטרנט כדי לכתוב נתונים, אתם יכולים לבחור שלא להציג למשתמש ממשק משתמש שמאפשר לו לכתוב נתונים, או לפחות להשבית אותו.
- אתם יכולים להשתמש ב
AlertDialogשהמשתמש לא יכול לסגור, או בSnackbar, כדי להודיע למשתמש שהוא במצב אופליין.
כתיבה בתור
כשרוצים לכתוב על אובייקט, מוסיפים אותו לתור. כשהאפליקציה חוזרת למצב אונליין, צריך לרוקן את התור עם השהיה מעריכית לפני ניסיון חוזר. ב-Android, ניקוי תור אופליין הוא עבודה מתמשכת שלרוב מוקצית ל-WorkManager.
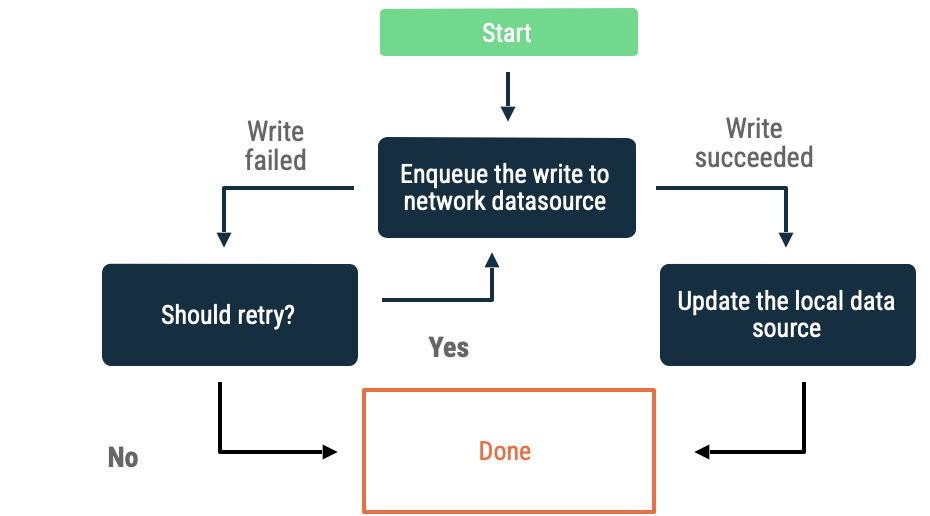
הגישה הזו מתאימה במקרים הבאים:
- לא חובה שהנתונים ייכתבו לרשת.
- העסקה לא רגישה לזמן.
- לא חובה ליידע את המשתמש אם הפעולה נכשלת.
תרחישים לדוגמה לשימוש בגישה הזו כוללים אירועים של ניתוח נתונים ורישום ביומן.
כתיבה מדורגת
קודם כותבים למקור הנתונים המקומי, ואז מוסיפים את הכתיבה לתור כדי להודיע לרשת בהזדמנות הראשונה. זה לא פשוט כי יכולות להיות סתירות בין מקורות הנתונים ברשת לבין מקורות הנתונים המקומיים כשהאפליקציה חוזרת למצב אונליין. בקטע הבא מוסבר על גישור ויישוב סכסוכים.
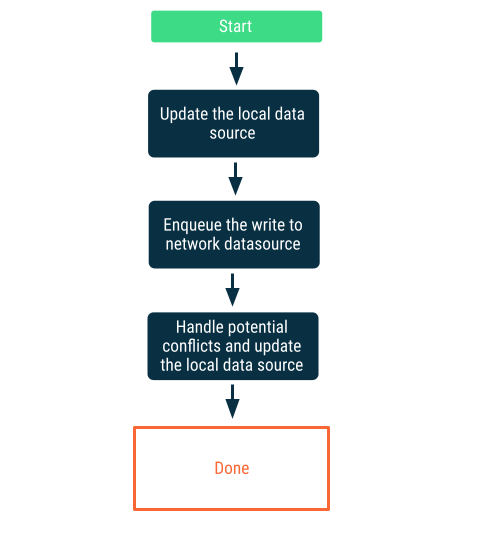
הגישה הזו מתאימה כשמדובר בנתונים שחיוניים לאפליקציה. לדוגמה, באפליקציה של רשימת מטלות שפועלת קודם במצב אופליין, חיוני שכל המטלות שהמשתמש מוסיף במצב אופליין יישמרו באופן מקומי כדי למנוע את הסיכון לאובדן נתונים.
סנכרון ופתרון בעיות שנובעות מסנכרון
כשחיבור הרשת של אפליקציה שפועלת במצב אופליין משוחזר, צריך לסנכרן את הנתונים במקור הנתונים המקומי עם הנתונים במקור הנתונים ברשת. התהליך הזה נקרא סנכרון. יש שתי דרכים עיקריות שבהן אפליקציה יכולה לבצע סנכרון עם מקור נתונים ברשת:
- סנכרון מבוסס-משיכה
- סנכרון מבוסס-דחיפה
סנכרון מבוסס-משיכה
בסנכרון מבוסס-משיכה, האפליקציה פונה לרשת כדי לקרוא את הנתונים העדכניים ביותר של האפליקציה על פי דרישה. היוריסטיקה הנפוצה בגישה הזו היא ניווט מבוסס, שבו האפליקציה מאחזרת נתונים רק לפני שהיא מציגה אותם למשתמש.
הגישה הזו מתאימה במיוחד לאפליקציות שצפויות להפסיק להתחבר לרשת לפרקי זמן קצרים עד בינוניים. הסיבה לכך היא שרענון הנתונים מתבצע באופן אקראי, ותקופות ארוכות ללא קישוריות מגדילות את הסיכוי שהמשתמש ינסה להיכנס ליעדים באפליקציה עם מטמון לא עדכני או ריק.
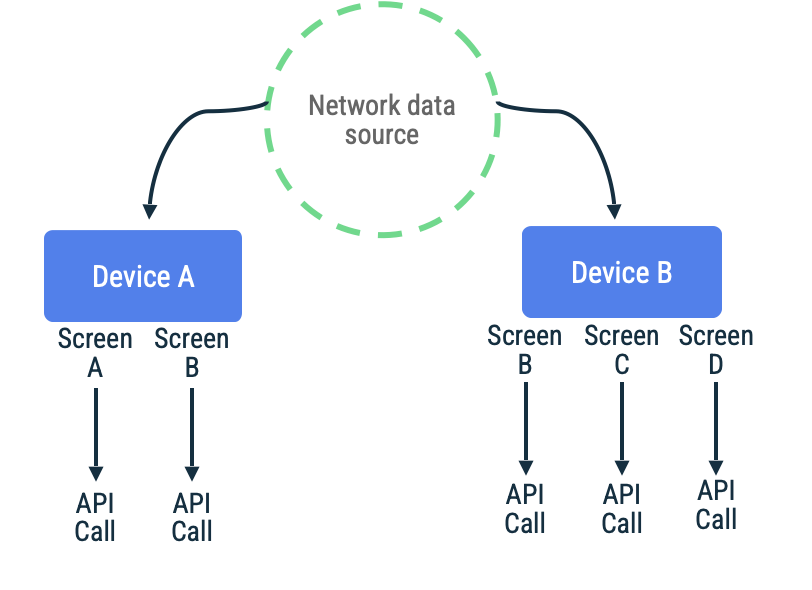
נניח שיש אפליקציה שבה נעשה שימוש בטוקנים של דפים כדי לאחזר פריטים ברשימה עם גלילה אינסופית במסך מסוים. יכול להיות שההטמעה תפנה לרשת באופן עצלני, תשמור את הנתונים במקור הנתונים המקומי ואז תקרא ממקור הנתונים המקומי כדי להציג את המידע למשתמש. במקרה שאין קישוריות לרשת, יכול להיות שהמאגר יבקש נתונים רק ממקור הנתונים המקומי. זהו הדפוס שבו נעשה שימוש ב-Jetpack Paging Library עם ה-API RemoteMediator.
class FeedRepository(...) {
fun feedPagingSource(): PagingSource<FeedItem> { ... }
}
class FeedViewModel(
private val repository: FeedRepository
) : ViewModel() {
private val pager = Pager(
config = PagingConfig(
pageSize = NETWORK_PAGE_SIZE,
enablePlaceholders = false
),
remoteMediator = FeedRemoteMediator(...),
pagingSourceFactory = feedRepository::feedPagingSource
)
val feedPagingData = pager.flow
}
בטבלה הבאה מפורטים היתרונות והחסרונות של סנכרון מבוסס-משיכה:
| יתרונות | חסרונות |
|---|---|
| קל יחסית להטמעה. | נוטה לשימוש רב בנתונים. הסיבה לכך היא שביקורים חוזרים ביעד ניווט מפעילים אחזור חוזר מיותר של מידע שלא השתנה. אפשר לצמצם את הבעיה באמצעות שמירה במטמון. אפשר לעשות את זה בשכבת ממשק המשתמש באמצעות האופרטור cachedIn, או בשכבת הרשת באמצעות מטמון HTTP. |
| נתונים שלא נדרשים אף פעם לא מאוחזרים. | המודל לא מתאים לנתונים יחסיים כי הוא צריך להיות עצמאי. אם המודל שמסונכרן תלוי במודלים אחרים שצריך לאחזר כדי לאכלס אותו, בעיית השימוש הכבד בנתונים שצוינה קודם הופכת למשמעותית עוד יותר. בנוסף, היא יכולה לגרום לתלות בין מאגרי המידע של מודל האב לבין מאגרי המידע של המודל המקונן. |
סנכרון מבוסס-דחיפה
בסנכרון מבוסס-דחיפה, מקור הנתונים המקומי מנסה לחקות קבוצת רפליקות של מקור הנתונים ברשת, ככל האפשר. הוא מאחזר באופן יזום כמות מתאימה של נתונים בהפעלה הראשונה כדי להגדיר בסיס. אחרי כן, הוא מסתמך על התראות מהשרת כדי לקבל התראה כשהנתונים האלה לא עדכניים.
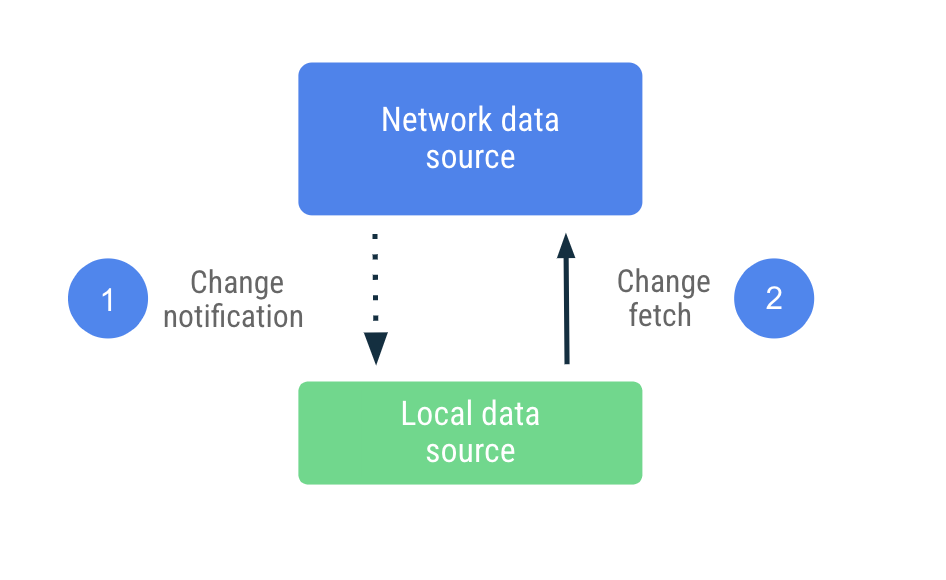
כשמתקבלת התראה על נתונים לא עדכניים, האפליקציה פונה לרשת כדי לעדכן רק את הנתונים שסומנו כלא עדכניים. העבודה הזו מוקצית ל-Repository, שמתחבר למקור הנתונים ברשת ושומר את הנתונים שנשלפו במקור הנתונים המקומי. מכיוון שהמאגר חושף את הנתונים שלו באמצעות סוגים שניתנים לצפייה, הקוראים מקבלים הודעה על כל שינוי.
class UserDataRepository(...) {
suspend fun synchronize() {
val userData = networkDataSource.fetchUserData()
localDataSource.saveUserData(userData)
}
}
בגישה הזו, האפליקציה תלויה הרבה פחות במקור נתוני הרשת, והיא יכולה לפעול בלעדיו למשך תקופות ארוכות. הוא מציע גישת קריאה וכתיבה במצב אופליין כי הוא מניח שיש לו את המידע העדכני ממקור הנתונים ברשת באופן מקומי.
בטבלה הבאה מפורטים היתרונות והחסרונות של סנכרון מבוסס-דחיפה:
| יתרונות | חסרונות |
|---|---|
| האפליקציה יכולה להישאר במצב אופליין ללא הגבלת זמן. | נתוני ניהול הגרסאות לפתרון קונפליקטים הם משמעותיים. |
| שימוש מינימלי בנתונים. האפליקציה מאחזרת רק נתונים שהשתנו. | צריך לקחת בחשבון את בעיות הכתיבה במהלך הסנכרון. |
| מתאים במיוחד לנתונים רלציוניים. כל מאגר אחראי לאחזור נתונים רק עבור המודל שהוא תומך בו. | מקור הנתונים של הרשת צריך לתמוך בסנכרון. |
סנכרון היברידי
חלק מהאפליקציות משתמשות בגישה היברידית שמבוססת על משיכה או על דחיפה, בהתאם לנתונים. לדוגמה, אפליקציה של מדיה חברתית עשויה להשתמש בסנכרון מבוסס-משיכה כדי לאחזר את פיד העוקבים של המשתמש לפי דרישה, בגלל התדירות הגבוהה של עדכוני הפיד. אותה אפליקציה יכולה לבחור להשתמש בסנכרון מבוסס-push לנתונים על המשתמש שמחובר לחשבון, כולל שם המשתמש, תמונת הפרופיל וכו'.
בסופו של דבר, הבחירה בסנכרון במצב אופליין תלויה בדרישות המוצר ובתשתית הטכנית הזמינה.
יישוב סכסוכים
אם האפליקציה כותבת נתונים באופן מקומי כשהיא במצב אופליין, והנתונים האלה לא תואמים למקור הנתונים ברשת, צריך לפתור את הקונפליקט לפני שהסנכרון יתבצע.
לרוב, כדי לפתור התנגשויות צריך להשתמש בניהול גרסאות. האפליקציה צריכה לבצע פעולות מסוימות כדי לעקוב אחרי מועדי השינויים, כדי שתוכל להעביר את המטא-נתונים למקור הנתונים של הרשת. מקור הנתונים של הרשת אחראי לספק את המקור המהימן המוחלט. יש הרבה אסטרטגיות לפתרון בעיות שצריך לקחת בחשבון, בהתאם לצרכים של האפליקציה. באפליקציות לנייד, גישה נפוצה היא 'העדכון האחרון קובע'.
העדכון האחרון קובע
בגישה הזו, המכשירים מצרפים מטא-נתונים של חותמת זמן לנתונים שהם כותבים ברשת. כשמקור הנתונים של הרשת מקבל אותם, הוא משליך את כל הנתונים שקודמים למצב הנוכחי שלו, ומקבל את הנתונים החדשים יותר.
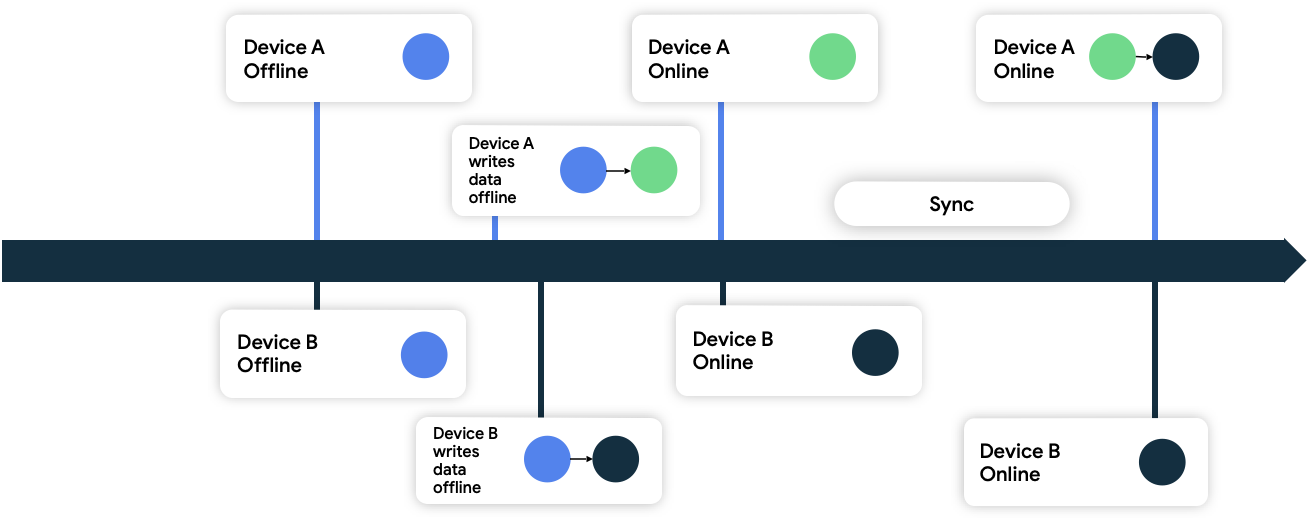
באיור 9, שני המכשירים במצב אופליין ומסונכרנים בהתחלה עם מקור הנתונים של הרשת. במצב אופליין, שניהם כותבים נתונים באופן מקומי ועוקבים אחרי הזמן שבו הם כתבו את הנתונים. כששני המכשירים יחזרו למצב אונליין ויסונכרנו עם מקור הנתונים ברשת, הרשת תפתור את הסתירה על ידי שמירת הנתונים ממכשיר ב' כי הוא כתב את הנתונים שלו מאוחר יותר.
WorkManager באפליקציות שפועלות קודם במצב אופליין
בשתי האסטרטגיות של קריאה וכתיבה שצוינו קודם, יש שני כלי עזר נפוצים:
- תורים
- קריאה: משמש לדחיית קריאות עד שזמינה קישוריות לרשת.
- Writes: משמש לדחיית פעולות כתיבה עד שזמינה קישוריות לרשת, ולשינוי סדר פעולות הכתיבה כדי לנסות שוב.
- ניטור קישוריות לרשת
- קריאות: משמשות כאות לניקוי תור הקריאה כשהאפליקציה מחוברת, ולסנכרון.
- פעולות כתיבה: משמשות כאות לניקוי תור הכתיבה כשהאפליקציה מחוברת, ולסנכרון.
שתי הדוגמאות האלה ממחישות את העבודה המתמשכת ש-WorkManager מצטיין בה. לדוגמה, באפליקציית הדוגמה Now in Android, WorkManager משמש גם כתור קריאה וגם ככלי למעקב אחרי הרשת כשמסנכרנים את מקור הנתונים המקומי. בזמן ההפעלה, האפליקציה מבצעת את הפעולות הבאות:
- הפעולה מוסיפה לעומס העבודה סנכרון קריאה כדי לוודא שיש שוויון בין מקור הנתונים המקומי למקור הנתונים ברשת.
- מרוקן את תור הסנכרון של הקריאה ומתחיל לסנכרן כשהאפליקציה מחוברת לאינטרנט.
- מבצע קריאה ממקור נתוני הרשת באמצעות השהיה מעריכית לפני ניסיון חוזר (exponential backoff).
- התוצאות של הקריאה נשמרות במקור הנתונים המקומי, וכל התנגשויות שמתרחשות נפתרות.
- חושפת את הנתונים ממקור הנתונים המקומי לשכבות אחרות באפליקציה כדי שיוכלו להשתמש בהם.
הפעולות האלה מודגמות בתרשים הבא:
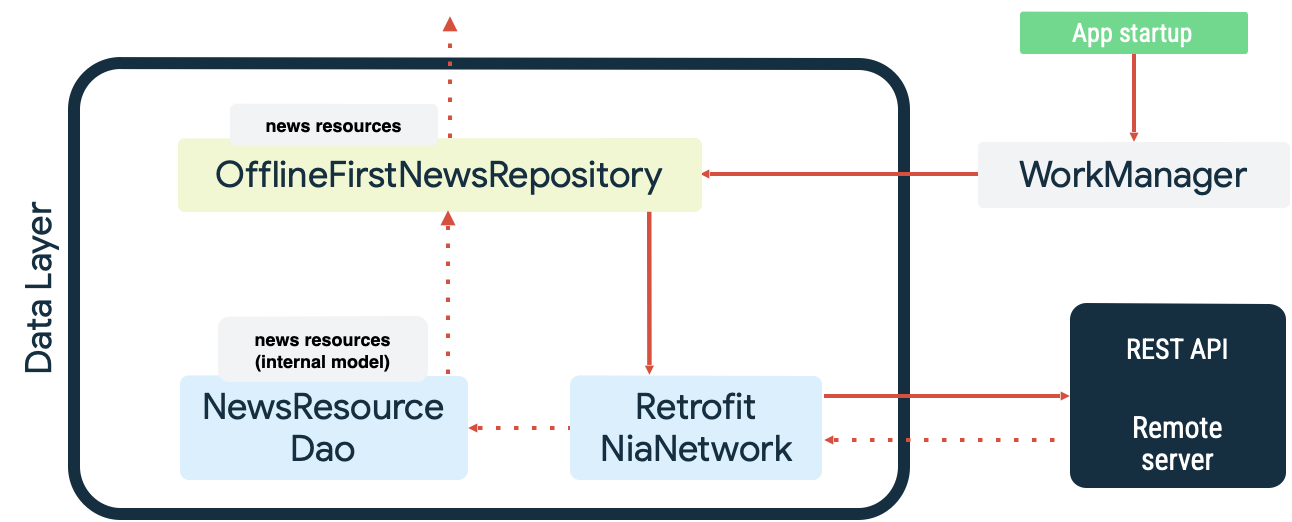
הוספת עבודת הסנכרון לתור באמצעות WorkManager מתבצעת על ידי הגדרתה כעבודה ייחודית באמצעות KEEP ExistingWorkPolicy:
class SyncInitializer : Initializer<Sync> {
override fun create(context: Context): Sync {
WorkManager.getInstance(context).apply {
// Queue sync on app startup and ensure only one
// sync worker runs at any time
enqueueUniqueWork(
SyncWorkName,
ExistingWorkPolicy.KEEP,
SyncWorker.startUpSyncWork()
)
}
return Sync
}
}
ההגדרה של SyncWorker.startupSyncWork() היא:
/**
Create a WorkRequest to call the SyncWorker using a DelegatingWorker.
This allows for dependency injection into the SyncWorker in a different
module than the app module without having to create a custom WorkManager
configuration.
*/
fun startUpSyncWork() = OneTimeWorkRequestBuilder<DelegatingWorker>()
// Run sync as expedited work if the app is able to.
// If not, it runs as regular work.
.setExpedited(OutOfQuotaPolicy.RUN_AS_NON_EXPEDITED_WORK_REQUEST)
.setConstraints(SyncConstraints)
// Delegate to the SyncWorker.
.setInputData(SyncWorker::class.delegatedData())
.build()
val SyncConstraints
get() = Constraints.Builder()
.setRequiredNetworkType(NetworkType.CONNECTED)
.build()
באופן ספציפי, Constraints שמוגדר על ידי SyncConstraints דורש שNetworkType יהיה NetworkType.CONNECTED. כלומר, הוא ממתין עד שהרשת תהיה זמינה לפני שהוא מופעל.
כשהרשת זמינה, העובד מרוקן את תור העבודה הייחודי שצוין על ידי SyncWorkName על ידי הקצאה למופעי Repository המתאימים. אם הסנכרון נכשל, השיטה doWork() מחזירה את הערך Result.retry(). WorkManager ינסה לסנכרן שוב באופן אוטומטי עם השהיה מעריכית לפני ניסיון חוזר (exponential backoff). אחרת, הפונקציה מחזירה Result.success() ומסיימת את הסנכרון.
class SyncWorker(...) : CoroutineWorker(appContext, workerParams), Synchronizer {
override suspend fun doWork(): Result = withContext(ioDispatcher) {
// First sync the repositories in parallel
val syncedSuccessfully = awaitAll(
async { topicRepository.sync() },
async { authorsRepository.sync() },
async { newsRepository.sync() },
).all { it }
if (syncedSuccessfully) Result.success()
else Result.retry()
}
}
דוגמאות
בדוגמאות הבאות של Google מוצגות אפליקציות שפועלות במצב אופליין. כדאי לעיין בהם כדי לראות איך ההנחיות האלה באות לידי ביטוי בפועל:
מומלץ בשבילך
- הערה: טקסט הקישור מוצג כש-JavaScript מושבת
- ייצור מצבים לממשקי משתמש
- שכבת ממשק המשתמש
- שכבת נתונים