
Si bien la capa de IU contiene estados relacionados y lógica de la IU, la capa de datos contiene datos de la aplicación y lógica empresarial. La lógica empresarial es la que aporta valor a la app: está compuesta por reglas empresariales reales que determinan cómo se deben crear, almacenar y cambiar los datos de la aplicación.
Esta separación de problemas permite que la capa de datos se use en varias pantallas, comparta información entre diferentes partes de la app y reproduzca la lógica empresarial fuera de la IU a fin de realizar pruebas de unidades. Para obtener más información sobre los beneficios de la capa de datos, consulta la página Descripción general de la arquitectura.
Arquitectura de capa de datos
La capa de datos está formada por repositorios que pueden contener de cero a muchas fuentes de datos. Debes crear una clase de repositorio para cada tipo de datos diferente que administres en tu app. Por ejemplo, puedes crear una clase MoviesRepository para datos relacionados con películas o una clase PaymentsRepository para datos relacionados con pagos.
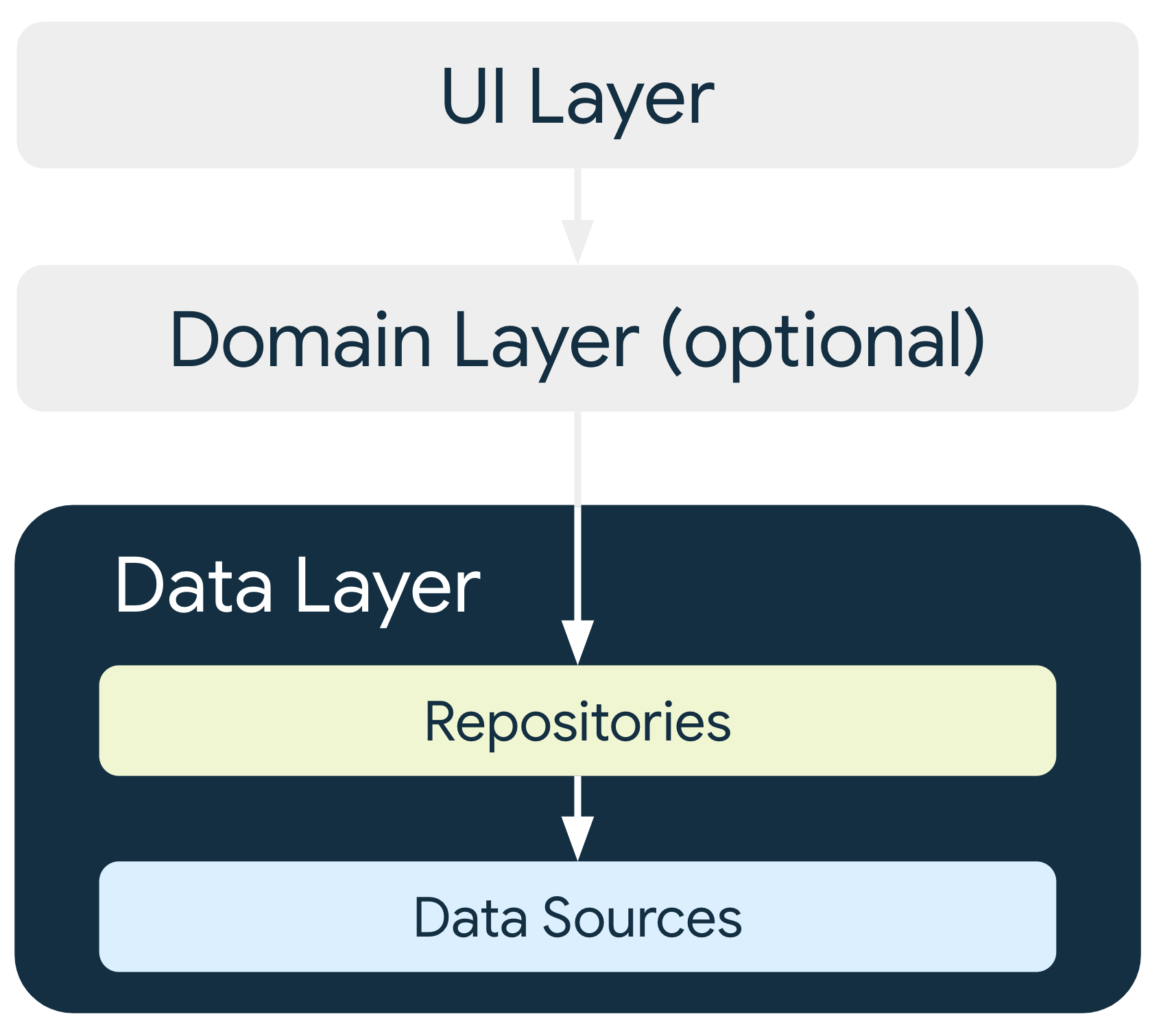
Las clases de repositorio son responsables de las siguientes tareas:
- Exponer datos al resto de la app
- Centralizar los cambios en los datos
- Resolver conflictos entre múltiples fuentes de datos
- Abstraer fuentes de datos del resto de la app
- Contener la lógica empresarial
Cada clase de fuente de datos debe tener la responsabilidad de trabajar con una sola fuente de datos, que puede ser un archivo, una fuente de red o una base de datos local. Las clases de fuente de datos son el puente entre la aplicación y el sistema para las operaciones de datos.
Las demás capas de la jerarquía nunca deberían acceder a las fuentes de datos directamente. Los puntos de entrada a la capa de datos son siempre las clases del repositorio. Las clases de contenedores de estado (consulta la guía de capas de IU) o las clases de casos de uso (consulta la guía de capas de dominio) nunca deben tener una fuente de datos como dependencia directa. El uso de clases de repositorio como puntos de entrada permite que las diferentes capas de la arquitectura escalen de forma independiente.
Los datos que expone esta capa deben ser inmutables para que otras clases no puedan manipularlos, lo que podría poner en riesgo sus valores en un estado incoherente. Los datos inmutables también se pueden controlar de forma segura mediante varios subprocesos. Consulta la sección de subprocesos para obtener más detalles.
Si sigues las prácticas recomendadas de la inyección de dependencias, el repositorio toma fuentes de datos como dependencias en su constructor:
class ExampleRepository(
private val exampleRemoteDataSource: ExampleRemoteDataSource, // network
private val exampleLocalDataSource: ExampleLocalDataSource // database
) { /* ... */ }
Cómo exponer las APIs
Por lo general, las clases de la capa de datos exponen funciones a fin de realizar llamadas únicas de creación, lectura, actualización y eliminación (CRUD) o recibir notificaciones de cambios en los datos a lo largo del tiempo. La capa de datos debería exponer lo siguiente para cada uno de estos casos:
- Para las operaciones únicas, expón funciones de suspensión.
- Para recibir notificaciones de cambios en los datos a lo largo del tiempo, expón flujos.
class ExampleRepository(
private val exampleRemoteDataSource: ExampleRemoteDataSource, // network
private val exampleLocalDataSource: ExampleLocalDataSource // database
) {
val data: Flow<Example> = ...
suspend fun modifyData(example: Example) { ... }
}
Convenciones de nombres en esta guía
En esta guía, las clases de repositorio se nombran según los datos de los que son responsables. La convención es la siguiente:
tipo de datos + Repositorio.
Por ejemplo, NewsRepository, MoviesRepository o PaymentsRepository.
Las clases de fuente de datos se nombran según los datos de los que son responsables y la fuente que usan. La convención es la siguiente:
tipo de datos + tipo de fuente + DataSource.
Para el tipo de datos, usa Remote o Local a fin de que sean más genéricos, ya que las implementaciones pueden cambiar. Por ejemplo, NewsRemoteDataSource o NewsLocalDataSource. Para ser más específicos en caso de que la fuente sea importante, usa el tipo de la fuente. Por ejemplo, NewsNetworkDataSource o NewsDiskDataSource.
No uses un nombre para la fuente de datos según los detalles de la implementación (por ejemplo, UserSharedPreferencesDataSource), ya que los repositorios que usan esa fuente de datos no deberían saber cómo se guardan los datos. Si sigues esta regla, puedes cambiar la implementación de la fuente de datos (por ejemplo, migrar de SharedPreferences a DataStore) sin afectar la capa que llama a esa fuente.
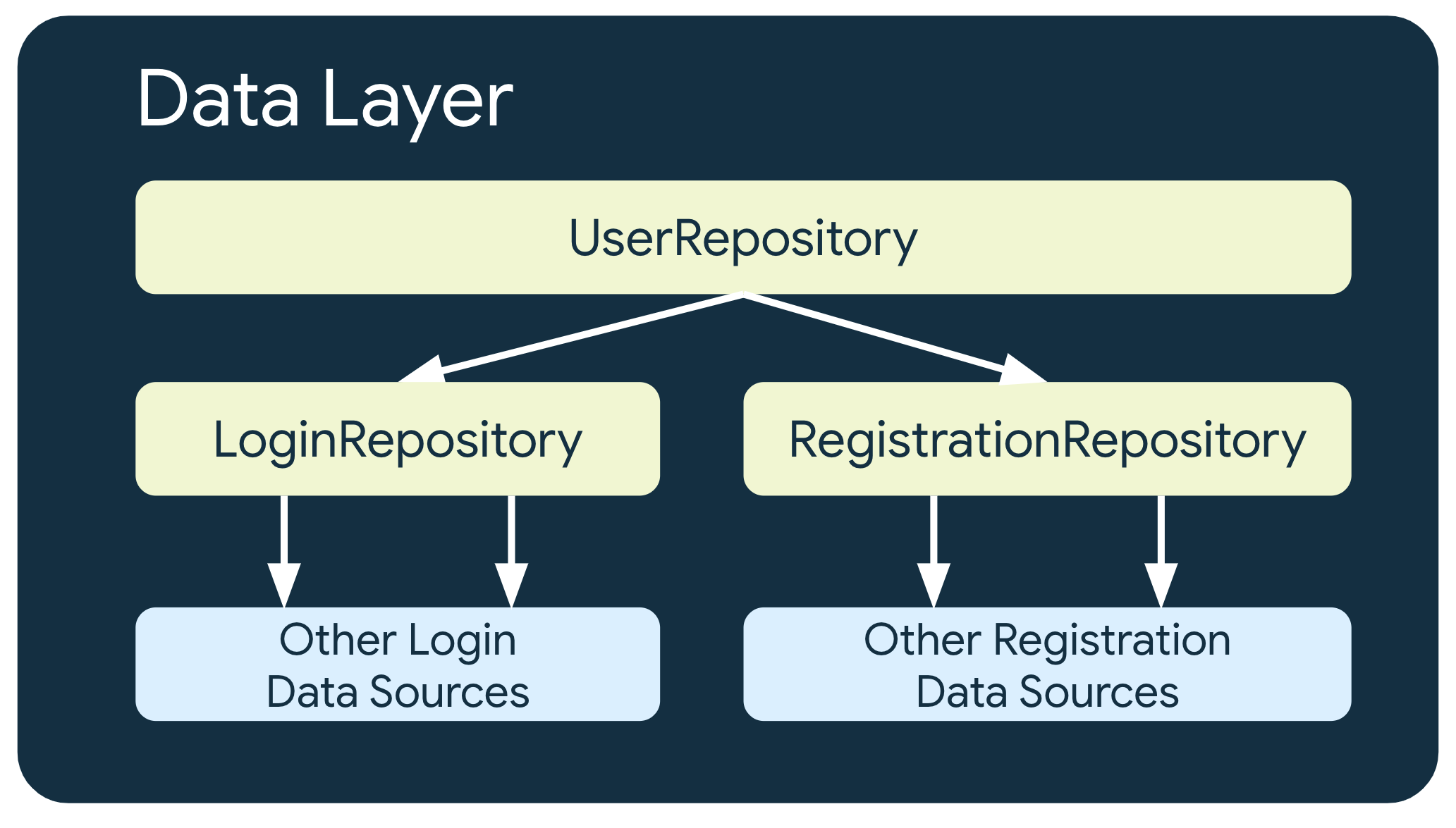
Varios niveles de repositorios
En algunos casos con requisitos empresariales más complejos, es posible que un repositorio deba depender de otros repositorios. Esto podría deberse a que los datos involucrados son una agregación de varias fuentes de datos o a que la responsabilidad debe encapsularse en otra clase de repositorio.
Por ejemplo, un repositorio que controla los datos de autenticación del usuario, UserRepository, podría depender de otros repositorios, como LoginRepository y RegistrationRepository, para cumplir con sus requisitos.
Fuente de información
Es importante que cada repositorio defina una única fuente de información. Esta siempre contiene datos que son coherentes y correctos, y están actualizados. De hecho, los datos expuestos del repositorio siempre deben ser los que provienen directamente de la fuente de información.
La fuente de información puede ser una fuente de datos (por ejemplo, la base de datos) o incluso una caché en la memoria que podría contener el repositorio. Los repositorios combinan diferentes fuentes de datos y resuelven cualquier posible conflicto entre las fuentes de datos para actualizar la fuente de información única con regularidad o debido a un evento de entrada del usuario.
Los distintos repositorios de tu app pueden tener fuentes de información diferentes. Por ejemplo, la clase LoginRepository podría usar su caché como fuente de información y la clase PaymentsRepository podría usar la fuente de datos de red.
Para proporcionar asistencia sin conexión, la fuente de información recomendada es una fuente de datos local (como una base de datos).
Subprocesos
Llamar a fuentes de datos y los repositorios debe ser seguro para el subproceso principal; es seguro llamarlos desde el subproceso principal. Estas clases son responsables de mover la ejecución de su lógica al subproceso correspondiente cuando se realizan operaciones de bloqueo de larga duración. Por ejemplo, debe ser seguro para el subproceso principal que una fuente de datos lea desde un archivo, o que un repositorio realice un filtrado costoso en una lista grande.
Ten en cuenta que la mayoría de las fuentes de datos ya proporcionan APIs seguras para el subproceso principal, como las llamadas de método de suspensión que proporcionan Room, Retrofit o Ktor. Tu repositorio puede aprovechar estas APIs cuando estén disponibles.
Si quieres obtener más información sobre los subprocesos, consulta la Guía para el procesamiento en segundo plano. Para los usuarios de Kotlin, se recomiendan las corrutinas.
Ciclo de vida
Las instancias de clases en la capa de datos permanecen en la memoria siempre que se pueda acceder a ellas desde una raíz de recolección de elementos no utilizados; por lo general, se hace referencia a ellas desde otros objetos de la app.
Si una clase contiene datos en la memoria, por ejemplo, una caché, es posible que quieras reutilizar la misma instancia de esa clase durante un período específico. Esto también se conoce como el ciclo de vida de la instancia de clase.
Si la responsabilidad de la clase es fundamental para toda la aplicación, puedes limitar una instancia de esa clase en la clase Application. Así, la instancia sigue el ciclo de vida de la aplicación. Como alternativa, si solo necesitas volver a usar la misma instancia en un flujo particular de tu app (por ejemplo, el flujo de registro o acceso), debes limitar la instancia a la clase que posee el ciclo de vida de ese flujo. Por ejemplo, puedes definir el alcance de un RegistrationRepository que contenga datos en la memoria en el RegistrationActivity o en una pila de historial con un NavEntryDecorator.
El ciclo de vida de cada instancia es un factor fundamental para decidir cómo proporcionar dependencias dentro de tu app. Se recomienda seguir las prácticas recomendadas para la inyección de dependencias en las que las dependencias se administran y pueden tener como alcance contenedores de dependencias. Para obtener más información sobre los alcances en Android, consulta la entrada de blog Alcance en Android y Hilt.
Cómo representar modelos de negocios
Los modelos de datos que deseas exponer desde la capa de datos pueden ser un subconjunto de la información que obtienes de las diferentes fuentes de datos. Lo ideal sería que las diferentes fuentes de datos (de red y locales) muestren solo la información que necesita la aplicación, pero no suele ser el caso.
Por ejemplo, imagina un servidor de la API de Google Noticias que muestra no solo la información del artículo, sino también el historial de cambios, los comentarios de los usuarios y algunos metadatos:
data class ArticleApiModel(
val id: Long,
val title: String,
val content: String,
val publicationDate: Date,
val modifications: Array<ArticleApiModel>,
val comments: Array<CommentApiModel>,
val lastModificationDate: Date,
val authorId: Long,
val authorName: String,
val authorDateOfBirth: Date,
val readTimeMin: Int
)
La app no necesita tanta información sobre el artículo porque solo muestra el contenido del artículo en la pantalla junto con información básica sobre su autor. Se recomienda separar las clases de modelo y hacer que tus repositorios expongan solo los datos que requieren las otras capas de la jerarquía. Por ejemplo, a continuación se muestra cómo puedes cortar el ArticleApiModel de la red para exponer una clase de modelo Article ante las capas de IU y de dominio:
data class Article(
val id: Long,
val title: String,
val content: String,
val publicationDate: Date,
val authorName: String,
val readTimeMin: Int
)
Separar las clases de modelo es beneficioso por lo siguiente:
- Ahorra memoria de la app porque reduce los datos solo a los necesarios.
- Adapta los tipos de datos externos a los tipos de datos que usa tu app; por ejemplo, esta podría usar un tipo de datos diferente para representar fechas.
- Proporciona una mejor separación de problemas; por ejemplo, los miembros de un equipo grande podrían trabajar de forma individual en las capas de red e IU de una función si la clase de modelo se define de antemano.
Puedes ampliar esta práctica y definir también clases de modelo separadas en otras partes de la arquitectura de tu app; por ejemplo, en clases de fuente de datos y ViewModels. Sin embargo, esto requiere que definas clases y lógica adicionales que debes documentar y probar de forma adecuada. Como mínimo, se recomienda que crees modelos nuevos en cualquier caso en el que una fuente de datos reciba datos que no coincidan con lo que espera el resto de tu app.
Tipos de operaciones de datos
La capa de datos puede lidiar con tipos de operaciones que varían según su importancia: las operaciones orientadas a la IU, a la app y a la empresa.
Operaciones orientadas a la IU
Las operaciones orientadas a la IU solo son relevantes cuando el usuario se encuentra en una pantalla específica y se cancelan cuando el usuario abandona esa pantalla. Un ejemplo es que muestren algunos datos obtenidos de la base de datos.
Por lo general, las operaciones orientadas a la IU se activan mediante la capa de IU y siguen el ciclo de vida del llamador; por ejemplo, el ciclo de vida del ViewModel. Consulta la sección Cómo realizar una solicitud de red para ver un ejemplo de una operación orientada a la IU.
Operaciones orientadas a apps
Las operaciones orientadas a la app son relevantes siempre que la app esté abierta. Si se cierra la app o se finaliza el proceso, se cancelan estas operaciones. Un ejemplo es almacenar en caché el resultado de una solicitud de red para que pueda usarse más adelante si es necesario. Consulta la sección Cómo implementar el almacenamiento en caché de datos en memoria para obtener más información.
Estas operaciones suelen seguir el ciclo de vida de la clase Application o la capa de datos. Para ver un ejemplo, consulta la sección Cómo hacer que una operación dure más que la pantalla.
Operaciones orientadas a la empresa
No se pueden cancelar las operaciones orientadas a la empresa. Deberían permanecer activas tras el cierre del proceso. Un ejemplo es finalizar la carga de una foto que el usuario desea publicar en su perfil.
Para las operaciones orientadas a la empresa, se recomienda usar WorkManager. Consulta la sección Cómo programar tareas con WorkManager para obtener más información.
Cómo exponer errores
Las interacciones con repositorios y fuentes de datos pueden tener éxito o arrojar una excepción cuando se produce una falla. Para las corrutinas y los flujos, debes usar el mecanismo integrado de manejo de errores de Kotlin. Para los errores que podrían activarse con funciones de suspensión, usa bloques try/catch cuando corresponda y, en flujos, usa el operador catch. Con este enfoque, se espera que la capa de IU maneje las excepciones cuando se llama a la capa de datos.
La capa de datos puede comprender y controlar diferentes tipos de errores y exponerlos mediante excepciones personalizadas; por ejemplo, con UserNotAuthenticatedException.
Para obtener más información sobre los errores en las corrutinas, consulta la entrada de blog Excepciones en corrutinas.
Tareas comunes
En las siguientes secciones, se presentan ejemplos de cómo usar y diseñar la capa de datos para realizar ciertas tareas comunes en las apps para Android. Los ejemplos se basan en la app de Google Noticias que se mencionó antes en la guía, pues tiene características típicas.
Cómo realizar una solicitud de red
Realizar una solicitud de red es una de las tareas más comunes que puede realizar una app para Android. La app de Google Noticias debe mostrar al usuario las noticias más recientes que se obtienen de la red. Por lo tanto, la app necesita una clase de fuente de datos para administrar las operaciones de red: NewsRemoteDataSource. Para exponer la información al resto de la app, se crea un repositorio nuevo que maneja las operaciones en los datos de noticias: NewsRepository.
El requisito es que las noticias más recientes siempre deben actualizarse cuando el usuario abre la pantalla. Por lo tanto, esta es una operación orientada a la IU.
Cómo crear la fuente de datos
La fuente de datos debe exponer una función que muestre las últimas noticias: una lista de instancias de ArticleHeadline. La fuente de datos debe proporcionar al subproceso principal una forma segura de obtener las noticias más recientes de la red. Para ello, toma una dependencia de CoroutineDispatcher o Executor en la que ejecutará la tarea.
Hacer una solicitud de red representa una llamada única que controla un método fetchLatestNews() nuevo:
class NewsRemoteDataSource(
private val newsApi: NewsApi,
private val ioDispatcher: CoroutineDispatcher
) {
/**
* Fetches the latest news from the network and returns the result.
* This executes on an IO-optimized thread pool, the function is main-safe.
*/
suspend fun fetchLatestNews(): List<ArticleHeadline> =
// Move the execution to an IO-optimized thread since the ApiService
// doesn't support coroutines and makes synchronous requests.
withContext(ioDispatcher) {
newsApi.fetchLatestNews()
}
}
// Makes news-related network synchronous requests.
interface NewsApi {
fun fetchLatestNews(): List<ArticleHeadline>
}
La interfaz NewsApi oculta la implementación del cliente de API de red. No importa si la interfaz está respaldada por Retrofit o HttpURLConnection. Si se utilizan las interfaces, las implementaciones de la API son intercambiables en tu app.
Cómo crear el repositorio
Debido a que no se necesita lógica adicional en la clase de repositorio para esta tarea, NewsRepository actúa como un proxy para la fuente de datos de red. Los beneficios de agregar esta capa adicional de abstracción se explican en la sección de almacenamiento en caché en memoria.
// NewsRepository is consumed from other layers of the hierarchy.
class NewsRepository(
private val newsRemoteDataSource: NewsRemoteDataSource
) {
suspend fun fetchLatestNews(): List<ArticleHeadline> =
newsRemoteDataSource.fetchLatestNews()
}
Si quieres obtener información para consumir la clase de repositorio directamente desde la capa de IU, consulta la guía Capa de IU.
Cómo implementar el almacenamiento en caché de datos en memoria
Supongamos que se presenta un nuevo requisito para la app de Google Noticias: cuando el usuario abre la pantalla, deben aparecer las noticias almacenadas en caché si antes se realizó una solicitud. De lo contrario, la app deberá realizar una solicitud de red para recuperar las noticias más recientes.
Dado el nuevo requisito, la app debe conservar las últimas noticias en la memoria mientras el usuario tiene la app abierta. Por lo tanto, esta es una operación orientada a la app.
Memorias caché
Puedes conservar datos mientras el usuario está en tu app si agregas almacenamiento en caché de datos en memoria. Las memorias caché tienen el fin de guardar información en la memoria durante un período específico (en este caso, mientras el usuario esté en la app). Las implementaciones de caché pueden tener formas diferentes. Pueden variar desde variables mutables simples hasta clases más sofisticadas que protegen de las operaciones de lectura y escritura en varios subprocesos. Según el caso de uso, el almacenamiento en caché se puede implementar en las clases de repositorio o de fuente de datos.
Cómo almacenar en caché el resultado de la solicitud de red
Por cuestiones de simplicidad, NewsRepository usa una variable mutable para almacenar en caché las noticias más recientes. Para proteger las lecturas y escrituras de diferentes subprocesos, se usa Mutex. Para obtener más información sobre el estado mutable y la simultaneidad compartidos, consulta la documentación de Kotlin.
En la siguiente implementación, se almacena en caché la información de las noticias más reciente en una variable del repositorio protegida contra escritura con Mutex. Si el resultado de la solicitud de red se realiza de forma correcta, los datos se asignan a la variable latestNews.
class NewsRepository(
private val newsRemoteDataSource: NewsRemoteDataSource
) {
// Mutex to make writes to cached values thread-safe.
private val latestNewsMutex = Mutex()
// Cache of the latest news got from the network.
private var latestNews: List<ArticleHeadline> = emptyList()
suspend fun getLatestNews(refresh: Boolean = false): List<ArticleHeadline> {
if (refresh || latestNews.isEmpty()) {
val networkResult = newsRemoteDataSource.fetchLatestNews()
// Thread-safe write to latestNews
latestNewsMutex.withLock {
this.latestNews = networkResult
}
}
return latestNewsMutex.withLock { this.latestNews }
}
}
Cómo hacer que una operación dure más que la pantalla
Si el usuario sale de la pantalla mientras la solicitud de red está en curso, esta se cancelará y el resultado no se almacenará en caché. NewsRepository no debería usar el CoroutineScope del llamador para realizar esta lógica. En su lugar, NewsRepository debe usar un CoroutineScope que esté conectado a su ciclo de vida.
La recuperación de las noticias más recientes debe ser una operación orientada a la app.
Para seguir las prácticas recomendadas de inserción de dependencias, NewsRepository debe recibir un alcance como parámetro en su constructor en lugar de crear su propio CoroutineScope. Debido a que los repositorios deben realizar la mayor parte de su trabajo en los subprocesos en segundo plano, debes configurar CoroutineScope con Dispatchers.Default o con tu propio conjunto de subprocesos.
class NewsRepository(
...,
// This could be CoroutineScope(SupervisorJob() + Dispatchers.Default).
private val externalScope: CoroutineScope
) { ... }
Debido a que NewsRepository está listo para realizar operaciones orientadas a la app con el CoroutineScope externo, debe realizar la llamada a la fuente de datos y guardar su resultado con una corrutina nueva que inicie ese alcance:
class NewsRepository(
private val newsRemoteDataSource: NewsRemoteDataSource,
private val externalScope: CoroutineScope
) {
/* ... */
suspend fun getLatestNews(refresh: Boolean = false): List<ArticleHeadline> {
return if (refresh) {
externalScope.async {
newsRemoteDataSource.fetchLatestNews().also { networkResult ->
// Thread-safe write to latestNews.
latestNewsMutex.withLock {
latestNews = networkResult
}
}
}.await()
} else {
return latestNewsMutex.withLock { this.latestNews }
}
}
}
Se usa async para iniciar la corrutina en el alcance externo. Se llama a await en la corrutina nueva para suspenderse hasta que regrese la solicitud de red y se guarde el resultado en la caché. Si en ese momento el usuario aún está en la pantalla, verá las noticias más recientes. Si abandona la pantalla, se cancela await, pero la lógica dentro de async se sigue ejecutando.
Obtén más información sobre los patrones para CoroutineScope.
Cómo guardar y recuperar datos del disco
Supongamos que quieres guardar datos, como noticias que agregaste a favoritos y preferencias del usuario. Este tipo de datos necesita sobrevivir al cierre del proceso y ser accesible incluso si el usuario no está conectado a la red.
Si los datos con los que trabajas necesitan sobrevivir al cierre del proceso, debes almacenarlos en el disco de una de las siguientes maneras:
- Guarda los datos en una base de datos de Room en el caso de los conjuntos de datos grandes que necesiten consultas, integridad referencial o actualizaciones parciales. En el ejemplo de la app de Google Noticias, los artículos o los autores podrían guardarse en la base de datos.
- Para conjuntos de datos pequeños que solo deben recuperarse y configurarse (no consultarse ni actualizarse de forma parcial), usa DataStore. En el ejemplo de la app de Google Noticias, el formato de fecha preferido del usuario y otras preferencias de visualización podrían guardarse en Datastore.
- Para los fragmentos de datos, como un objeto JSON, usa un archivo.
Como se mencionó en la sección Fuente de información, cada fuente de datos funciona con una sola fuente y corresponde a un tipo de datos específico (por ejemplo, News, Authors, NewsAndAuthors o UserPreferences). Las clases que usan la fuente de datos no deberían saber cómo se guardan los datos (por ejemplo, en una base de datos o en un archivo).
Room como fuente de datos
Dado que cada fuente de datos debe encargarse de trabajar con una sola fuente para un tipo específico de datos, una fuente de datos de Room recibirá un objeto de acceso a datos (DAO) o la base de datos en sí como parámetro. Por ejemplo, NewsLocalDataSource podría tomar una instancia de NewsDao como parámetro, y AuthorsLocalDataSource, una instancia de AuthorsDao.
En algunos casos, si no se necesita lógica adicional, podrías incorporar el DAO directamente al repositorio, ya que es una interfaz que puedes reemplazar con facilidad en las pruebas.
Para obtener más información sobre cómo trabajar con las APIs de Room, consulta las guías de Room.
DataStore como fuente de datos
DataStore es perfecto para almacenar pares clave-valor, como la configuración del usuario. Algunos ejemplos pueden incluir el formato de hora, las preferencias de notificación y la opción de ocultar o mostrar artículos de noticias después de que el usuario los haya leído. Datastore también puede almacenar objetos escritos con búferes de protocolo.
Al igual que con cualquier otro objeto, una fuente de datos respaldada por DataStore debe contener datos correspondientes a un tipo determinado o a una parte determinada de la app. Esto es aún más cierto con DataStore, ya que sus lecturas se exponen como un flujo que se emite cada vez que se actualiza un valor. Por este motivo, debes almacenar las preferencias relacionadas en el mismo DataStore.
Por ejemplo, podrías tener un NotificationsDataStore que solo controle las preferencias relacionadas con notificaciones y un NewsPreferencesDataStore que solo controle las preferencias relacionadas con la pantalla de noticias. De esa manera, podrás determinar mejor el alcance de las actualizaciones, ya que el flujo newsScreenPreferencesDataStore.data solo se emite cuando se modifica una preferencia relacionada con esa pantalla. También significa que el ciclo de vida del objeto puede ser más corto, ya que solo puede existir mientras se muestre la pantalla de noticias.
Para obtener más información sobre cómo trabajar con las APIs de DataStore, consulta las guías de DataStore.
Un archivo como fuente de datos
Cuando uses objetos grandes, como un objeto JSON o un mapa de bits, deberás trabajar con un objeto File y controlar los subprocesos de cambio.
Para obtener más información sobre cómo trabajar con el almacenamiento de archivos, consulta la página de Descripción general del almacenamiento.
Cómo programar tareas con WorkManager
Supongamos que se presenta otro requisito nuevo para la app de Google Noticias: la app debe darle al usuario la opción de recuperar las últimas noticias de forma periódica y automáticamente siempre que el dispositivo se esté cargando y esté conectado a una red no medida. Por tal motivo, esta es una operación orientada a la empresa. Con este requisito, el usuario podrá ver las noticias recientes incluso aunque el dispositivo no tenga conectividad cuando abra la app.
WorkManager facilita la programación de trabajo asíncrono y confiable, y puede manejar la administración de restricciones. Es la biblioteca recomendada para trabajos persistentes. Para realizar la tarea definida anteriormente, se crea una clase Worker: RefreshLatestNewsWorker. Esta clase toma a NewsRepository como una dependencia para recuperar las últimas noticias y almacenarlas en caché, en el disco.
class RefreshLatestNewsWorker(
private val newsRepository: NewsRepository,
context: Context,
params: WorkerParameters
) : CoroutineWorker(context, params) {
override suspend fun doWork(): Result = try {
newsRepository.refreshLatestNews()
Result.success()
} catch (error: Throwable) {
Result.failure()
}
}
La lógica empresarial para este tipo de tarea se debe encapsular en su propia clase y tratar como una fuente de datos independiente. WorkManager solo será responsable de garantizar que el trabajo se ejecute en un subproceso en segundo plano cuando se cumplan todas las restricciones. Si cumples con este patrón, puedes intercambiar implementaciones con rapidez en diferentes entornos según sea necesario.
En este ejemplo, se debe llamar a esta tarea relacionada con noticias desde NewsRepository, que tomaría una nueva fuente de datos como una dependencia, NewsTasksDataSource, implementada de la siguiente manera:
private const val REFRESH_RATE_HOURS = 4L
private const val FETCH_LATEST_NEWS_TASK = "FetchLatestNewsTask"
private const val TAG_FETCH_LATEST_NEWS = "FetchLatestNewsTaskTag"
class NewsTasksDataSource(
private val workManager: WorkManager
) {
fun fetchNewsPeriodically() {
val fetchNewsRequest = PeriodicWorkRequestBuilder<RefreshLatestNewsWorker>(
REFRESH_RATE_HOURS, TimeUnit.HOURS
).setConstraints(
Constraints.Builder()
.setRequiredNetworkType(NetworkType.TEMPORARILY_UNMETERED)
.setRequiresCharging(true)
.build()
)
.addTag(TAG_FETCH_LATEST_NEWS)
workManager.enqueueUniquePeriodicWork(
FETCH_LATEST_NEWS_TASK,
ExistingPeriodicWorkPolicy.KEEP,
fetchNewsRequest.build()
)
}
fun cancelFetchingNewsPeriodically() {
workManager.cancelAllWorkByTag(TAG_FETCH_LATEST_NEWS)
}
}
Estos tipos de clases se nombran según los datos de los que son responsables; por ejemplo, NewsTasksDataSource o PaymentsTasksDataSource. Todas las tareas relacionadas con un tipo particular de datos se deben encapsular en la misma clase.
Si la tarea se debe activar al inicio de la app, se recomienda activar la solicitud de WorkManager con la biblioteca de App Startup que llama al repositorio desde un elemento Initializer.
Si quieres obtener más información para trabajar con las APIs de WorkManager, consulta las guías de WorkManager.
Prueba
Las prácticas recomendadas de la inserción de dependencias ayudan cuando pruebas tu app. También es útil utilizar interfaces para clases que se comunican con recursos externos. Cuando pruebas una unidad, puedes insertar versiones falsas de sus dependencias para que la prueba sea determinista y confiable.
Pruebas de unidades
Se aplica la guía de pruebas generales para probar la capa de datos. Para las pruebas de unidades, usa objetos reales cuando sea necesario y falsifica las dependencias que se comuniquen con fuentes externas, como leer desde un archivo o leer desde la red.
Pruebas de integración
Las pruebas de integración que acceden a fuentes externas tienden a ser menos deterministas porque se deben ejecutar en un dispositivo real. Se recomienda que ejecutes esas pruebas en un entorno controlado para que las pruebas de integración sean más confiables.
Para las bases de datos, Room permite crear una base de datos en la memoria que puedes controlar por completo en tus pruebas. Para obtener más información, consulta la página Cómo probar y depurar tu base de datos.
Para las herramientas de redes, existen bibliotecas populares, como WireMock o MockWebServer, que te permiten simular llamadas HTTP y HTTPS y verificar que se hayan realizado las solicitudes como se esperaba.
Recursos adicionales
Ejemplos
- Jetcaster
- Plantilla de inicio de arquitectura (multimódulo)
- Arquitectura
- Plantilla de inicio de arquitectura (módulo único)
- App de Now in Android
Recomendaciones para ti
- Nota: El texto del vínculo se muestra cuando JavaScript está desactivado
- Capa de dominio
- Cómo compilar una app que prioriza el uso sin conexión
- Producción del estado de la IU