
AppSearch to wydajne rozwiązanie do wyszukiwania na urządzeniu, które umożliwia zarządzanie lokalnie przechowywanymi uporządkowanymi danymi. Zawiera interfejsy API do indeksowania danych i ich pobierania za pomocą wyszukiwania pełnotekstowego. Aplikacje mogą używać AppSearch, aby oferować w swoim wnętrzu niestandardowe funkcje wyszukiwania, które umożliwiają użytkownikom wyszukiwanie treści nawet w trybie offline.
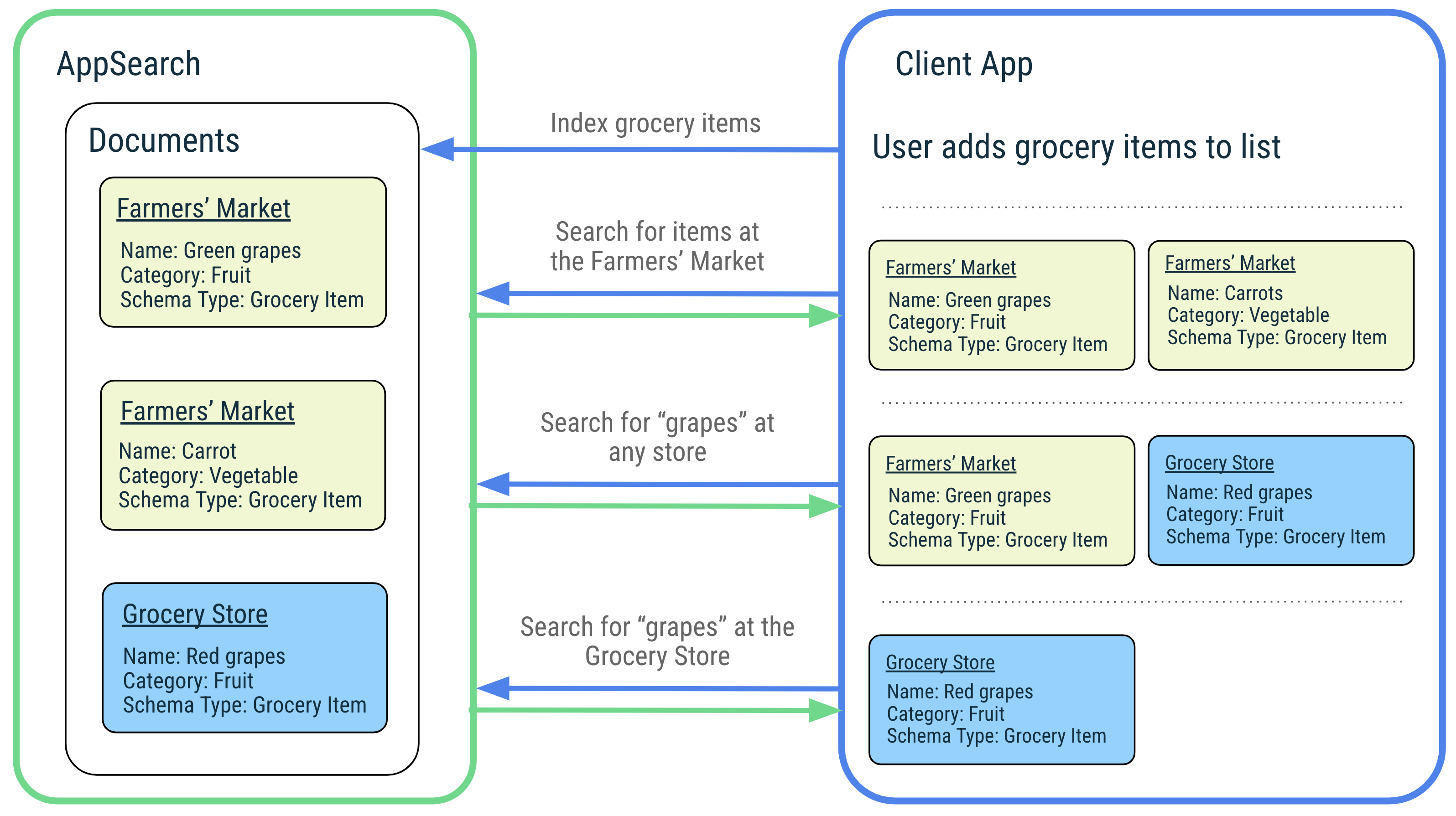
AppSearch udostępnia te funkcje:
- Szybka implementacja pamięci z optymalizacją pod kątem urządzeń mobilnych i małą liczbą operacji wejścia/wyjścia
- Bardzo wydajne indeksowanie i wybieranie dużych zbiorów danych
- obsługa wielu języków, np. angielskiego i hiszpańskiego;
- Ranking trafności i ocena wykorzystania
Ze względu na mniejsze wykorzystanie wejść i wyjść AppSearch zapewnia mniejsze opóźnienie w indeksowaniu i przeszukiwaniu dużych zbiorów danych niż SQLite. AppSearch upraszcza zapytania krzyżowe, obsługując pojedyncze zapytania, podczas gdy SQLite scala wyniki z wielu tabel.
Aby zilustrować funkcje AppSearch, weźmiemy pod uwagę przykład aplikacji muzycznej, która zarządza ulubionymi utworami użytkowników i umożliwia im łatwe wyszukiwanie ich. Użytkownicy słuchają muzyki z całego świata, a nazwy utworów są w różnych językach. AppSearch obsługuje indeksowanie i wyszukiwanie w takich przypadkach. Gdy użytkownik wyszukuje utwór według tytułu lub nazwy wykonawcy, aplikacja przekazuje żądanie do AppSearch, aby szybko i skutecznie pobrać pasujące utwory. Aplikacja wyświetla wyniki, dzięki czemu użytkownicy mogą szybko odtwarzać ulubione utwory.
Konfiguracja
Aby używać AppSearch w aplikacji, dodaj do pliku build.gradle aplikacji te zależności:
Groovy
dependencies { def appsearch_version = "1.1.0" implementation "androidx.appsearch:appsearch:$appsearch_version" // Use kapt instead of annotationProcessor if writing Kotlin classes annotationProcessor "androidx.appsearch:appsearch-compiler:$appsearch_version" implementation "androidx.appsearch:appsearch-local-storage:$appsearch_version" // PlatformStorage is compatible with Android 12+ devices, and offers additional features // to LocalStorage. implementation "androidx.appsearch:appsearch-platform-storage:$appsearch_version" // PlayServicesStorage is compatible with all devices that support Google Play Services on // all API levels. It offers the same features as PlatformStorage and is the recommended // solution for lower API levels on which PlatformStorage is not supported. implementation "androidx.appsearch:appsearch-play-services-storage:$appsearch_version" }
Kotlin
dependencies { val appsearch_version = "1.1.0" implementation("androidx.appsearch:appsearch:$appsearch_version") // Use annotationProcessor instead of kapt if writing Java classes kapt("androidx.appsearch:appsearch-compiler:$appsearch_version") implementation("androidx.appsearch:appsearch-local-storage:$appsearch_version") // PlatformStorage is compatible with Android 12+ devices, and offers additional features // to LocalStorage. implementation("androidx.appsearch:appsearch-platform-storage:$appsearch_version") // PlayServicesStorage is compatible with all devices that support Google Play Services on // all API levels. It offers the same features as PlatformStorage and is the recommended // solution for lower API levels on which PlatformStorage is not supported. implementation("androidx.appsearch:appsearch-play-services-storage:$appsearch_version") }
Pojęcia związane z wyszukiwaniem w aplikacjach
Na poniższym diagramie przedstawiono pojęcia związane z AppSearch i ich wzajemne oddziaływanie.
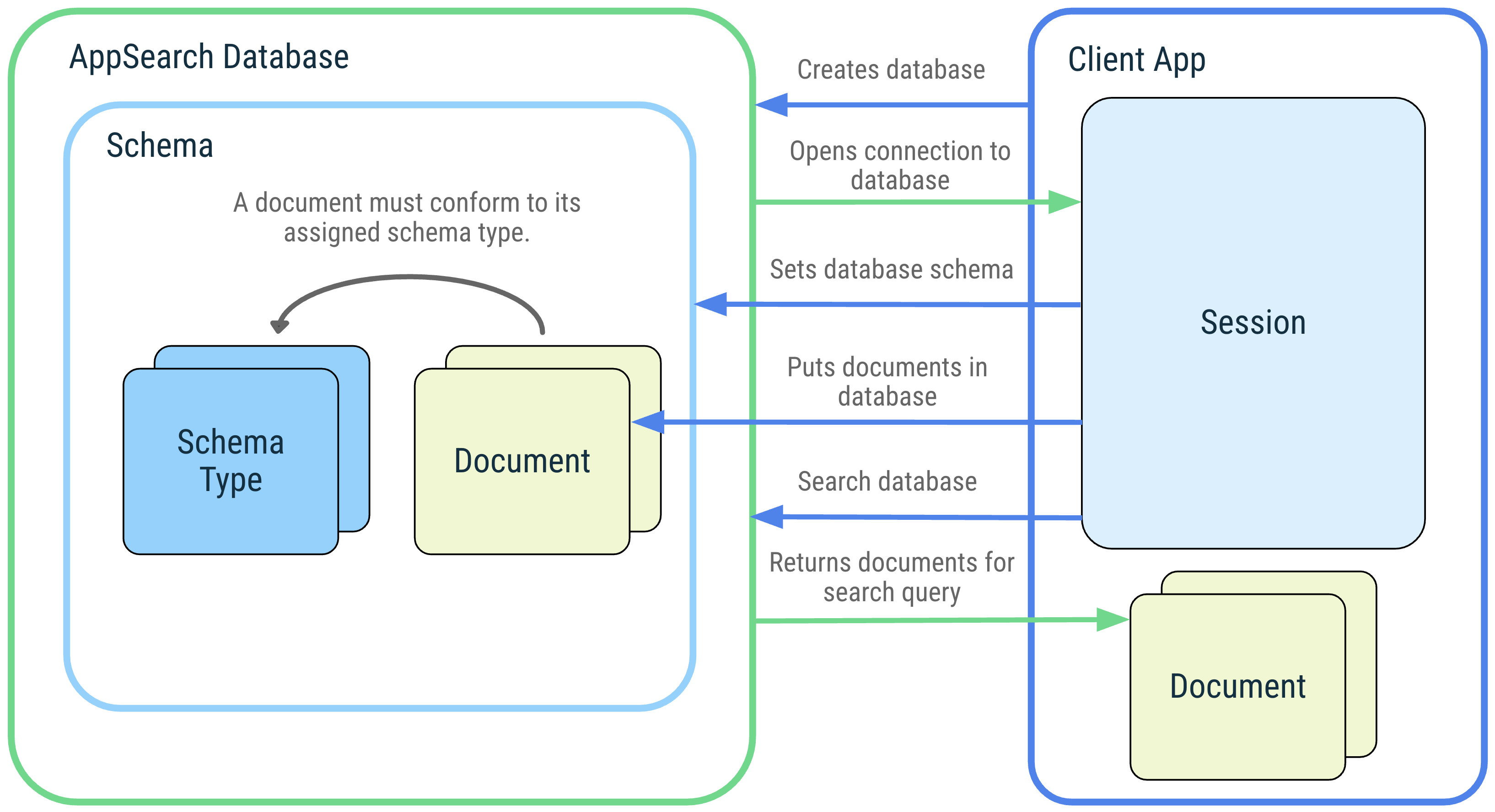 Rysunek 1. Diagram z pojęciami AppSearch: baza danych AppSearch, schemat, typy schematów, dokumenty, sesja i wyszukiwanie
Rysunek 1. Diagram z pojęciami AppSearch: baza danych AppSearch, schemat, typy schematów, dokumenty, sesja i wyszukiwanie
Baza danych i sesja
Baza danych AppSearch to zbiór dokumentów zgodny ze schematem bazy danych. Aplikacje klienckie tworzą bazę danych, podając kontekst aplikacji i jej nazwę. Bazy danych mogą być otwierane tylko przez aplikację, która je utworzyła. Gdy otwierasz bazę danych, zwracana jest sesja, która umożliwia jej używanie. Sesja jest punktem wejścia do wywoływania interfejsów AppSearch API i pozostaje otwarta, dopóki nie zostanie zamknięta przez aplikację klienta.
Schematy i ich typy
Schemat reprezentuje strukturę organizacyjną danych w bazie danych AppSearch.
Schemat składa się z typów schematów, które reprezentują unikalne typy danych. Typy schematów składają się z właściwości, które zawierają nazwę, typ danych i liczebność. Po dodaniu typu schematu do schematu bazy danych można tworzyć dokumenty tego typu schematu i dodawać je do bazy danych.
Dokumenty
W AppSearch jednostka danych jest reprezentowana jako dokument. Każdy dokument w bazie danych AppSearch jest jednoznacznie identyfikowany za pomocą swojej przestrzeni nazw i identyfikatora. Nazwy przestrzeni są używane do oddzielania danych z różnych źródeł, gdy należy przesłać zapytanie tylko do jednego źródła, np. do kont użytkowników.
Dokumenty zawierają sygnaturę czasową utworzenia, czas życia i wynik, który może być używany do ich porządkowania podczas pobierania. Dokumentowi przypisuje się też typ schematu, który opisuje dodatkowe właściwości danych, które musi on zawierać.
Klasa dokumentu to abstrakcja dokumentu. Zawiera pola z adnotacjami, które reprezentują zawartość dokumentu. Domyślnie nazwa klasy dokumentu określa nazwę typu schematu.
Szukaj
Dokumenty są indeksowane i można je wyszukiwać, podając zapytanie. Dokument jest dopasowywany i uwzględniany w wynikach wyszukiwania, jeśli zawiera terminy z zapytania lub pasuje do innej specyfikacji wyszukiwania. Wyniki są uporządkowane na podstawie ich wyniku i strategii rankingu. Wyniki wyszukiwania są reprezentowane przez strony, które możesz pobierać sekwencyjnie.
AppSearch oferuje dostosowywanie wyszukiwania, np. filtrów, konfiguracji rozmiaru strony i fragmentowania.
Pamięć platformy, pamięć lokalna lub pamięć Usług Google Play
AppSearch oferuje 3 rozwiązania dotyczące miejsca na dane: LocalStorage, PlatformStorage i PlayServicesStorage. Dzięki LocalStorage Twoja aplikacja może zarządzać indeksem dotyczącym aplikacji, który znajduje się w katalogu danych aplikacji. W przypadku zarówno PlatformStorage, jak i PlayServicesStorage Twoja aplikacja przyczynia się do tworzenia centralnego indeksu całego systemu. Indeks PlatformStorage jest hostowany na serwerze systemu, a indeks PlayServicesStorage – w magazynie Usług Google Play. Dostęp do danych w tych centralnych indeksach jest ograniczony do danych dostarczonych przez Twoją aplikację oraz danych, które zostały wyraźnie udostępnione przez inną aplikację. Wszystkie te opcje mają ten sam interfejs API i można je zamieniać w zależności od wersji urządzenia:
Kotlin
if (BuildCompat.isAtLeastS()) { appSearchSessionFuture.setFuture( PlatformStorage.createSearchSession( PlatformStorage.SearchContext.Builder(mContext, DATABASE_NAME) .build() ) ) } else { if (usePlayServicesStorageBelowS) { appSearchSessionFuture.setFuture( PlayServicesStorage.createSearchSession( PlayServicesStorage.SearchContext.Builder(mContext, DATABASE_NAME) .build() ) ) } else { appSearchSessionFuture.setFuture( LocalStorage.createSearchSession( LocalStorage.SearchContext.Builder(mContext, DATABASE_NAME) .build() ) ) } }
Java
if (BuildCompat.isAtLeastS()) { mAppSearchSessionFuture.setFuture(PlatformStorage.createSearchSession( new PlatformStorage.SearchContext.Builder(mContext, DATABASE_NAME) .build())); } else { if (usePlayServicesStorageBelowS) { mAppSearchSessionFuture.setFuture(PlayServicesStorage.createSearchSession( new PlayServicesStorage.SearchContext.Builder(mContext, DATABASE_NAME) .build())); } else { mAppSearchSessionFuture.setFuture(LocalStorage.createSearchSession( new LocalStorage.SearchContext.Builder(mContext, DATABASE_NAME) .build())); } }
Dzięki PlatformStorage i PlayServicesStorage Twoja aplikacja może bezpiecznie udostępniać dane innym aplikacjom, aby umożliwić im wyszukiwanie w danych aplikacji. Udostępnianie danych aplikacji tylko do odczytu odbywa się za pomocą certyfikatu, aby mieć pewność, że druga aplikacja ma uprawnienia do odczytu danych. Więcej informacji o tym interfejsie API znajdziesz w dokumentacji setSchemaTypeVisibilityForPackage().
Dodatkowo dzięki PlatformStorage dane, które są indeksowane, mogą być wyświetlane w interfejsach systemu. Aplikacje mogą zrezygnować z wyświetlania niektórych lub wszystkich danych na interfejsach systemu. Więcej informacji o tym interfejsie API znajdziesz w dokumentacji setSchemaTypeDisplayedBySystem().
| Funkcje | LocalStorage (zgodna z Androidem 5.0 lub nowszym) |
PlatformStorage (obsługa Androida 12 i nowszych) |
PlayServicesStorage (zgodna z Androidem 5.0 lub nowszym) |
|---|---|---|---|
| wydajne wyszukiwanie pełnotekstowe, | |||
| Obsługa wielu języków | |||
| Zmniejszony rozmiar pliku binarnego | |||
| Udostępnianie danych z aplikacji do aplikacji | |||
| Umiejętność wyświetlania danych w interfejsie systemu | |||
| indeksowanie dokumentów o nieograniczonym rozmiarze i liczbie; | |||
| Szybsze operacje bez dodatkowego opóźnienia związanego z zapisem |
Wybierając między LocalStorage a PlatformStorage, należy wziąć pod uwagę dodatkowe kompromisy. Ponieważ PlatformStorage owija interfejsy Jetpack API za pomocą usługi systemowej AppSearch, wpływ na rozmiar pliku APK jest minimalny w porównaniu z korzystaniem z LocalStorage. Oznacza to jednak, że operacje AppSearch powodują dodatkowy czas oczekiwania na wywołanie usługi systemowej AppSearch. Dzięki temu AppSearch może ograniczać liczbę i rozmiar dokumentów, które aplikacja może zindeksować, aby zapewnić wydajny indeks centralny.PlatformStorage PlayServicesStorage ma te same ograniczenia co PlatformStorage i jest obsługiwana tylko na urządzeniach z Usługami Google Play.
Pierwsze kroki z AppSearch
Przykład w tej sekcji pokazuje, jak używać interfejsów AppSearch API do integracji z hipotetyczną aplikacją do tworzenia notatek.
Tworzenie klasy dokumentu
Pierwszym krokiem do integracji z AppSearch jest napisanie klasy dokumentu, która opisuje dane do wstawienia w bazie danych. Oznacz klasę jako klasę dokumentu, używając adnotacji @Document.Możesz używać instancji klasy dokumentu do umieszczania dokumentów w bazie danych i pobierania ich z niej.
Poniższy kod definiuje klasę dokumentu Note z polami @Document.StringProperty opatrzonymi adnotacjami na potrzeby indeksowania tekstu obiektu Note.
Kotlin
@Document public data class Note( // Required field for a document class. All documents MUST have a namespace. @Document.Namespace val namespace: String, // Required field for a document class. All documents MUST have an Id. @Document.Id val id: String, // Optional field for a document class, used to set the score of the // document. If this is not included in a document class, the score is set // to a default of 0. @Document.Score val score: Int, // Optional field for a document class, used to index a note's text for this // document class. @Document.StringProperty(indexingType = AppSearchSchema.StringPropertyConfig.INDEXING_TYPE_PREFIXES) val text: String )
Java
@Document public class Note { // Required field for a document class. All documents MUST have a namespace. @Document.Namespace private final String namespace; // Required field for a document class. All documents MUST have an Id. @Document.Id private final String id; // Optional field for a document class, used to set the score of the // document. If this is not included in a document class, the score is set // to a default of 0. @Document.Score private final int score; // Optional field for a document class, used to index a note's text for this // document class. @Document.StringProperty(indexingType = StringPropertyConfig.INDEXING_TYPE_PREFIXES) private final String text; Note(@NonNull String id, @NonNull String namespace, int score, @NonNull String text) { this.id = Objects.requireNonNull(id); this.namespace = Objects.requireNonNull(namespace); this.score = score; this.text = Objects.requireNonNull(text); } @NonNull public String getNamespace() { return namespace; } @NonNull public String getId() { return id; } public int getScore() { return score; } @NonNull public String getText() { return text; } }
Otwieranie bazy danych
Zanim zaczniesz pracować z dokumentami, musisz utworzyć bazę danych. Podany niżej kod tworzy nową bazę danych o nazwie notes_app i pobiera ListenableFuture dla AppSearchSession, która reprezentuje połączenie z bazą danych i zapewnia interfejsy API do operacji na bazie danych.
Kotlin
val context: Context = getApplicationContext() val sessionFuture = LocalStorage.createSearchSession( LocalStorage.SearchContext.Builder(context, /*databaseName=*/"notes_app") .build() )
Java
Context context = getApplicationContext(); ListenableFuture<AppSearchSession> sessionFuture = LocalStorage.createSearchSession( new LocalStorage.SearchContext.Builder(context, /*databaseName=*/ "notes_app") .build() );
Ustawianie schematu
Zanim zaczniesz umieszczać dokumenty w bazie danych i zwracać je z niej, musisz ustawić schemat. Schemat bazy danych składa się z różnych typów danych uporządkowanych, zwanych „typami schematu”. Poniższy kod ustawia schemat, podając klasę dokumentu jako typ schematu.
Kotlin
val setSchemaRequest = SetSchemaRequest.Builder().addDocumentClasses(Note::class.java) .build() val setSchemaFuture = Futures.transformAsync( sessionFuture, { session -> session?.setSchema(setSchemaRequest) }, mExecutor )
Java
SetSchemaRequest setSchemaRequest = new SetSchemaRequest.Builder().addDocumentClasses(Note.class) .build(); ListenableFuture<SetSchemaResponse> setSchemaFuture = Futures.transformAsync(sessionFuture, session -> session.setSchema(setSchemaRequest), mExecutor);
Przechowywanie dokumentu w bazie danych
Po dodaniu typu schematu możesz dodawać do bazy danych dokumenty tego typu.
Poniższy kod tworzy dokument typu schematu Note za pomocą kreatora klasy dokumentu Note. Ustawia przestrzeń nazw dokumentu user1, aby reprezentowała dowolnego użytkownika tej próbki. Następnie dokument jest wstawiany do bazy danych, a dodawany jest do niego odbiornik, który przetwarza wynik operacji put.
Kotlin
val note = Note( namespace="user1", id="noteId", score=10, text="Buy fresh fruit" ) val putRequest = PutDocumentsRequest.Builder().addDocuments(note).build() val putFuture = Futures.transformAsync( sessionFuture, { session -> session?.put(putRequest) }, mExecutor ) Futures.addCallback( putFuture, object : FutureCallback<AppSearchBatchResult<String, Void>?> { override fun onSuccess(result: AppSearchBatchResult<String, Void>?) { // Gets map of successful results from Id to Void val successfulResults = result?.successes // Gets map of failed results from Id to AppSearchResult val failedResults = result?.failures } override fun onFailure(t: Throwable) { Log.e(TAG, "Failed to put documents.", t) } }, mExecutor )
Java
Note note = new Note(/*namespace=*/"user1", /*id=*/ "noteId", /*score=*/ 10, /*text=*/ "Buy fresh fruit!"); PutDocumentsRequest putRequest = new PutDocumentsRequest.Builder().addDocuments(note) .build(); ListenableFuture<AppSearchBatchResult<String, Void>> putFuture = Futures.transformAsync(sessionFuture, session -> session.put(putRequest), mExecutor); Futures.addCallback(putFuture, new FutureCallback<AppSearchBatchResult<String, Void>>() { @Override public void onSuccess(@Nullable AppSearchBatchResult<String, Void> result) { // Gets map of successful results from Id to Void Map<String, Void> successfulResults = result.getSuccesses(); // Gets map of failed results from Id to AppSearchResult Map<String, AppSearchResult<Void>> failedResults = result.getFailures(); } @Override public void onFailure(@NonNull Throwable t) { Log.e(TAG, "Failed to put documents.", t); } }, mExecutor);
Szukaj
Możesz wyszukiwać w dokumentach, które zostały zindeksowane, korzystając z operacji wyszukiwania opisanych w tej sekcji. Podany niżej kod wykonuje zapytania dotyczące terminu „owoc” w bazie danych w przypadku dokumentów należących do przestrzeni nazw user1.
Kotlin
val searchSpec = SearchSpec.Builder() .addFilterNamespaces("user1") .build(); val searchFuture = Futures.transform( sessionFuture, { session -> session?.search("fruit", searchSpec) }, mExecutor ) Futures.addCallback( searchFuture, object : FutureCallback<SearchResults> { override fun onSuccess(searchResults: SearchResults?) { iterateSearchResults(searchResults) } override fun onFailure(t: Throwable?) { Log.e("TAG", "Failed to search notes in AppSearch.", t) } }, mExecutor )
Java
SearchSpec searchSpec = new SearchSpec.Builder() .addFilterNamespaces("user1") .build(); ListenableFuture<SearchResults> searchFuture = Futures.transform(sessionFuture, session -> session.search("fruit", searchSpec), mExecutor); Futures.addCallback(searchFuture, new FutureCallback<SearchResults>() { @Override public void onSuccess(@Nullable SearchResults searchResults) { iterateSearchResults(searchResults); } @Override public void onFailure(@NonNull Throwable t) { Log.e(TAG, "Failed to search notes in AppSearch.", t); } }, mExecutor);
Przechodzenie przez SearchResults
Wyszukiwania zwracają wystąpienie SearchResults, które zapewnia dostęp do stron obiektów SearchResult. Każdy element SearchResult
zawiera dopasowany element GenericDocument, czyli ogólny format dokumentu, do którego są konwertowane wszystkie dokumenty. Ten kod pobiera pierwszą stronę wyników wyszukiwania i przekształca je w dokument Note.
Kotlin
Futures.transform( searchResults?.nextPage, { page: List<SearchResult>? -> // Gets GenericDocument from SearchResult. val genericDocument: GenericDocument = page!![0].genericDocument val schemaType = genericDocument.schemaType val note: Note? = try { if (schemaType == "Note") { // Converts GenericDocument object to Note object. genericDocument.toDocumentClass(Note::class.java) } else null } catch (e: AppSearchException) { Log.e( TAG, "Failed to convert GenericDocument to Note", e ) null } note }, mExecutor )
Java
Futures.transform(searchResults.getNextPage(), page -> { // Gets GenericDocument from SearchResult. GenericDocument genericDocument = page.get(0).getGenericDocument(); String schemaType = genericDocument.getSchemaType(); Note note = null; if (schemaType.equals("Note")) { try { // Converts GenericDocument object to Note object. note = genericDocument.toDocumentClass(Note.class); } catch (AppSearchException e) { Log.e(TAG, "Failed to convert GenericDocument to Note", e); } } return note; }, mExecutor);
Usuwanie dokumentu
Gdy użytkownik usunie notatkę, aplikacja usunie z bazy danych odpowiedni dokument Note. Dzięki temu notatka nie będzie już wyświetlana w zapytaniach. Podany niżej kod wysyła wyraźne żądanie usunięcia dokumentu Note z bazy danych na podstawie identyfikatora.
Kotlin
val removeRequest = RemoveByDocumentIdRequest.Builder("user1") .addIds("noteId") .build() val removeFuture = Futures.transformAsync( sessionFuture, { session -> session?.remove(removeRequest) }, mExecutor )
Java
RemoveByDocumentIdRequest removeRequest = new RemoveByDocumentIdRequest.Builder("user1") .addIds("noteId") .build(); ListenableFuture<AppSearchBatchResult<String, Void>> removeFuture = Futures.transformAsync(sessionFuture, session -> session.remove(removeRequest), mExecutor);
Zapisz na dysku
Aktualizacje bazy danych powinny być okresowo zapisywane na dysku przez wywołanie funkcji requestFlush(). Poniższy kod wywołuje funkcję requestFlush() z detektorem, aby określić, czy wywołanie było udane.
Kotlin
val requestFlushFuture = Futures.transformAsync( sessionFuture, { session -> session?.requestFlush() }, mExecutor ) Futures.addCallback(requestFlushFuture, object : FutureCallback<Void?> { override fun onSuccess(result: Void?) { // Success! Database updates have been persisted to disk. } override fun onFailure(t: Throwable) { Log.e(TAG, "Failed to flush database updates.", t) } }, mExecutor)
Java
ListenableFuture<Void> requestFlushFuture = Futures.transformAsync(sessionFuture, session -> session.requestFlush(), mExecutor); Futures.addCallback(requestFlushFuture, new FutureCallback<Void>() { @Override public void onSuccess(@Nullable Void result) { // Success! Database updates have been persisted to disk. } @Override public void onFailure(@NonNull Throwable t) { Log.e(TAG, "Failed to flush database updates.", t); } }, mExecutor);
Zamknij sesję
Blokada AppSearchSession
należy zamknąć, gdy aplikacja nie będzie już wywoływać żadnych operacji na bazie danych. Ten kod zamyka wcześniej otwartą sesję AppSearch i zapisuje wszystkie aktualizacje na dysku.
Kotlin
val closeFuture = Futures.transform<AppSearchSession, Unit>(sessionFuture, { session -> session?.close() Unit }, mExecutor )
Java
ListenableFuture<Void> closeFuture = Futures.transform(sessionFuture, session -> { session.close(); return null; }, mExecutor);
Dodatkowe materiały
Więcej informacji o AppSearch znajdziesz w tych materiałach:
Próbki
- Android AppSearch Sample (Kotlin), aplikacja do robienia notatek, która korzysta z AppSearch do indeksowania notatek użytkownika i umożliwia wyszukiwanie w nich.
Prześlij opinię
Udostępniaj nam swoje opinie i propozycje, korzystając z tych narzędzi:
Narzędzie do śledzenia problemów
zgłaszać błędy, abyśmy mogli je naprawić;