
A AppSearch é uma solução de pesquisa no dispositivo de alto desempenho para gerenciar dados estruturados armazenados localmente. Ela contém APIs para indexar e extrair dados usando a pesquisa de texto completo. Os aplicativos podem usar o AppSearch para oferecer recursos de pesquisa personalizados no app, permitindo que os usuários pesquisem conteúdo mesmo off-line.
O AppSearch oferece os seguintes recursos:
- Uma implementação de armazenamento rápida e com foco em dispositivos móveis com uso de E/S baixo
- Indexação e consulta altamente eficientes em grandes conjuntos de dados
- Suporte a vários idiomas, como inglês e espanhol
- Classificação de relevância e pontuação de uso
Devido ao uso menor de E/S, o AppSearch oferece latência menor para indexação e pesquisa em grandes conjuntos de dados em comparação com o SQLite. O AppSearch simplifica as consultas entre tipos com suporte a consultas únicas, enquanto o SQLite mescla resultados de várias tabelas.
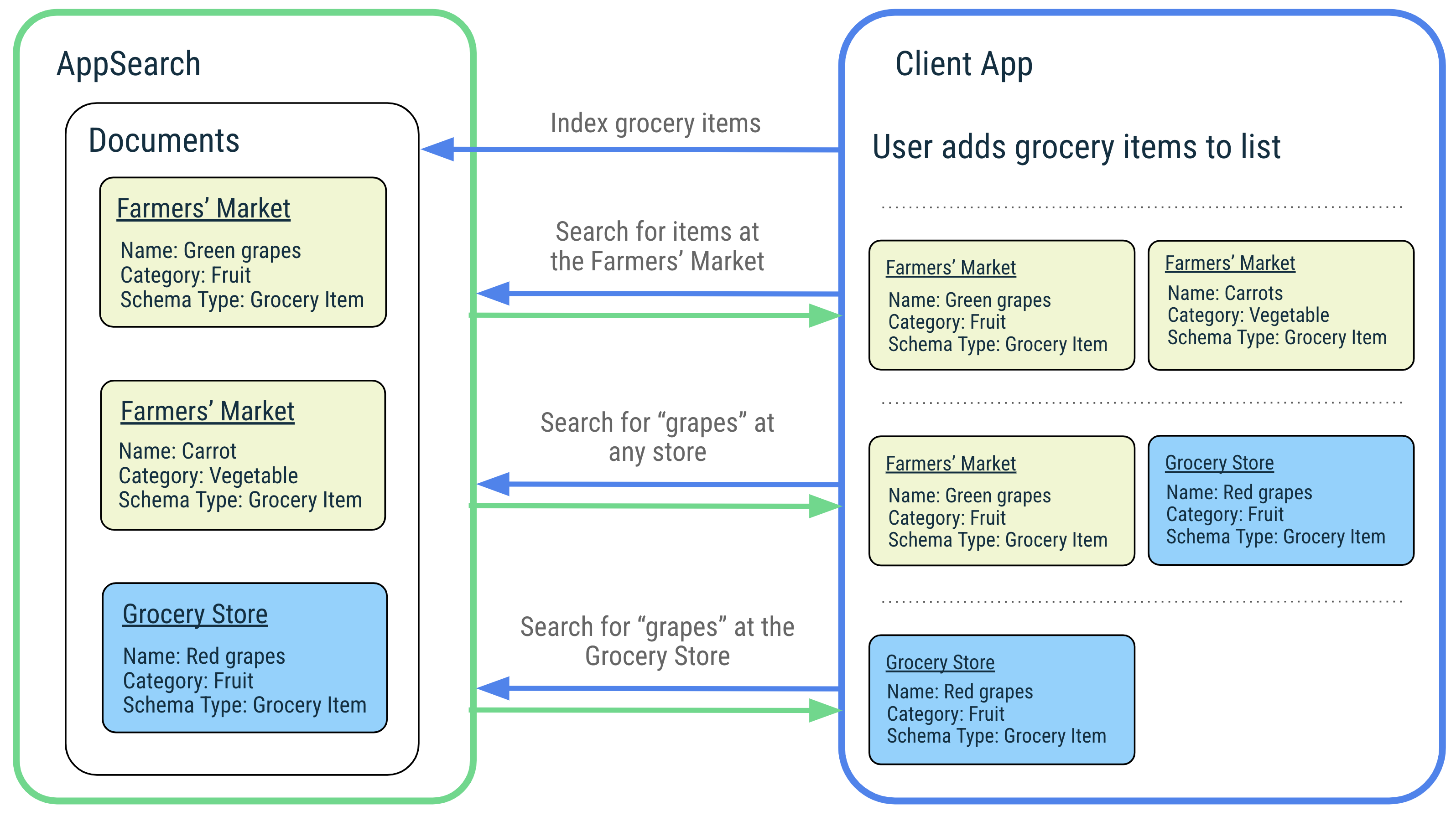
Para ilustrar os recursos do AppSearch, vamos usar o exemplo de um aplicativo de música que gerencia as músicas favoritas dos usuários e permite que eles as pesquisem com facilidade. Os usuários podem curtir músicas do mundo todo com títulos em diferentes idiomas, que o AppSearch oferece suporte nativo para indexação e consulta. Quando o usuário pesquisa uma música pelo título ou nome do artista, o aplicativo simplesmente transmite a solicitação ao AppSearch para recuperar músicas correspondentes de maneira rápida e eficiente. O app mostra os resultados, permitindo que os usuários comecem a tocar as músicas favoritas rapidamente.
Configurar
Para usar o AppSearch no app, adicione as seguintes dependências ao
arquivo build.gradle do app:
Groovy
dependencies { def appsearch_version = "1.1.0" implementation "androidx.appsearch:appsearch:$appsearch_version" // Use kapt instead of annotationProcessor if writing Kotlin classes annotationProcessor "androidx.appsearch:appsearch-compiler:$appsearch_version" implementation "androidx.appsearch:appsearch-local-storage:$appsearch_version" // PlatformStorage is compatible with Android 12+ devices, and offers additional features // to LocalStorage. implementation "androidx.appsearch:appsearch-platform-storage:$appsearch_version" // PlayServicesStorage is compatible with all devices that support Google Play Services on // all API levels. It offers the same features as PlatformStorage and is the recommended // solution for lower API levels on which PlatformStorage is not supported. implementation "androidx.appsearch:appsearch-play-services-storage:$appsearch_version" }
Kotlin
dependencies { val appsearch_version = "1.1.0" implementation("androidx.appsearch:appsearch:$appsearch_version") // Use annotationProcessor instead of kapt if writing Java classes kapt("androidx.appsearch:appsearch-compiler:$appsearch_version") implementation("androidx.appsearch:appsearch-local-storage:$appsearch_version") // PlatformStorage is compatible with Android 12+ devices, and offers additional features // to LocalStorage. implementation("androidx.appsearch:appsearch-platform-storage:$appsearch_version") // PlayServicesStorage is compatible with all devices that support Google Play Services on // all API levels. It offers the same features as PlatformStorage and is the recommended // solution for lower API levels on which PlatformStorage is not supported. implementation("androidx.appsearch:appsearch-play-services-storage:$appsearch_version") }
Conceitos do AppSearch
O diagrama a seguir ilustra os conceitos do AppSearch e as interações deles.
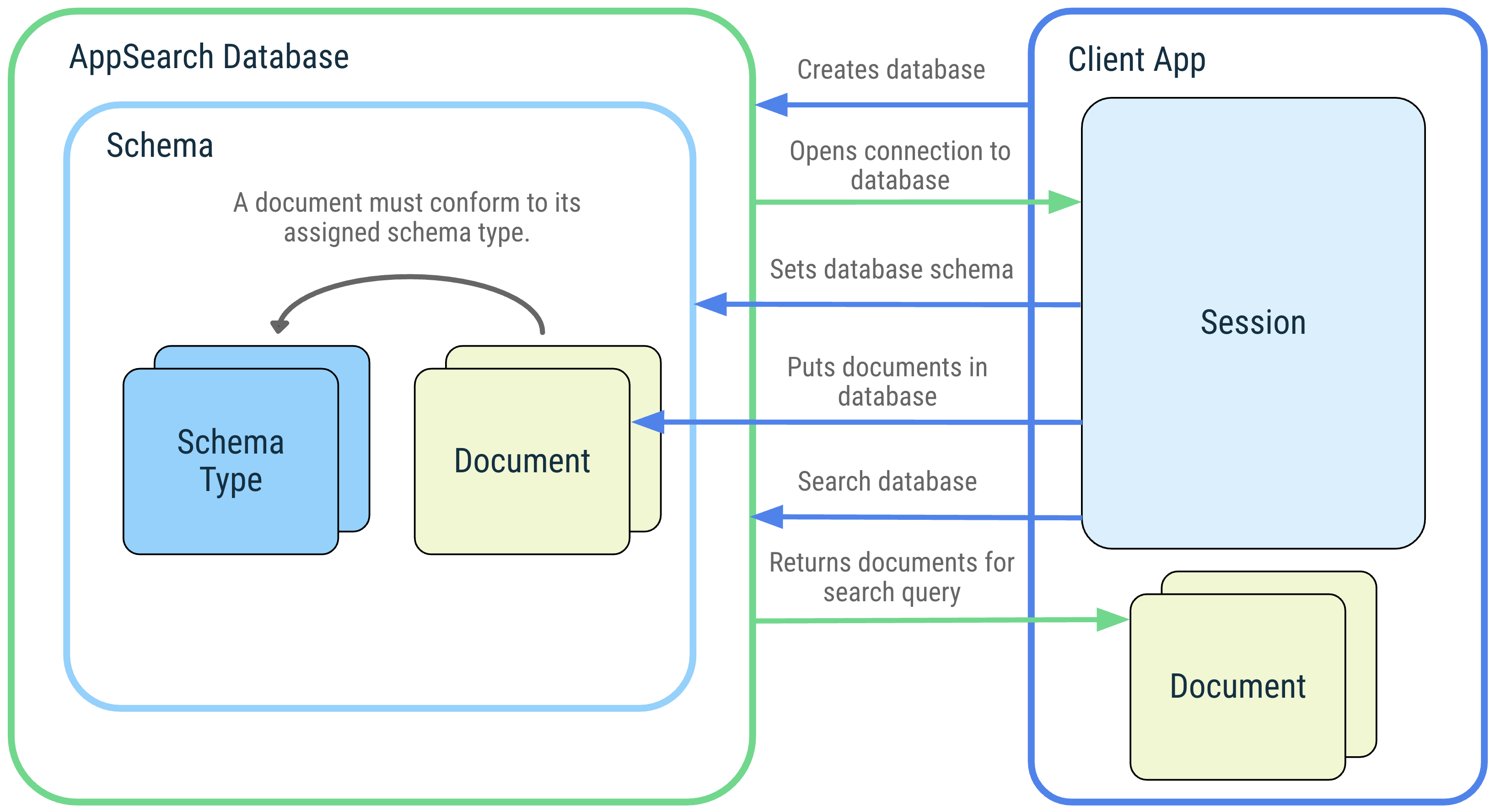 Figura 1. Diagrama dos conceitos do AppSearch: banco de dados, esquema,
tipos de esquema, documentos, sessão e pesquisa.
Figura 1. Diagrama dos conceitos do AppSearch: banco de dados, esquema,
tipos de esquema, documentos, sessão e pesquisa.
Banco de dados e sessão
Um banco de dados do AppSearch é uma coleção de documentos que está em conformidade com o esquema do banco de dados. Os aplicativos clientes criam um banco de dados fornecendo o contexto do aplicativo e um nome de banco de dados. Os bancos de dados só podem ser abertos pelo aplicativo que os criou. Quando um banco de dados é aberto, uma sessão é retornada para interagir com ele. A sessão é o ponto de entrada para chamar as APIs do AppSearch e permanece aberta até ser fechada pelo aplicativo cliente.
Esquema e tipos de esquema
Um esquema representa a estrutura organizacional dos dados em um banco de dados do AppSearch.
O esquema é composto por tipos que representam tipos exclusivos de dados. Os tipos de esquema consistem em propriedades que contêm um nome, tipo de dados e cardinalidade. Depois que um tipo de esquema é adicionado ao esquema do banco de dados, é possível criar e adicionar documentos desse tipo ao banco de dados.
Documentos
No AppSearch, uma unidade de dados é representada como um documento. Cada documento em um banco de dados do AppSearch é identificado de maneira exclusiva pelo namespace e ID. Os namespaces são usados para separar dados de diferentes origens quando apenas uma origem precisa ser consultada, como contas de usuário.
Os documentos contêm um carimbo de data/hora de criação, um tempo de vida (TTL, na sigla em inglês) e uma pontuação que pode ser usada para classificação durante a recuperação. Um documento também recebe um tipo de esquema que descreve outras propriedades de dados que ele precisa ter.
Uma classe de documento é uma abstração de um documento. Ele contém campos anotados que representam o conteúdo de um documento. Por padrão, o nome da classe de documento define o nome do tipo de esquema.
Pesquisar
Os documentos são indexados e podem ser pesquisados com uma consulta. Um documento é correspondido e incluído nos resultados da pesquisa se ele contém os termos da consulta ou corresponde a outra especificação de pesquisa. Os resultados são ordenados com base na pontuação e na estratégia de classificação. Os resultados da pesquisa são representados por páginas que podem ser recuperadas sequencialmente.
O AppSearch oferece personalizações para a pesquisa, como filtros, configuração do tamanho da página e snippeting.
Armazenamento da plataforma, armazenamento local ou armazenamento do Google Play Services
O AppSearch oferece três soluções de armazenamento: LocalStorage, PlatformStorage e
PlayServicesStorage. Com LocalStorage, seu aplicativo gerencia um
índice específico do app que fica no diretório de dados do aplicativo. Com
PlatformStorage e PlayServicesStorage, seu app contribui para um
índice central em todo o sistema. O índice de PlatformStorage é hospedado no servidor
do sistema, e o índice de PlayServicesStorage é hospedado no armazenamento
do Google Play Services. O acesso a dados nesses índices centrais é restrito aos dados que
o aplicativo contribuiu e aos dados que foram compartilhados explicitamente com você
por outro aplicativo. Todas essas opções de armazenamento compartilham a mesma API e podem ser
trocadas com base na versão de um dispositivo:
Kotlin
if (BuildCompat.isAtLeastS()) { appSearchSessionFuture.setFuture( PlatformStorage.createSearchSession( PlatformStorage.SearchContext.Builder(mContext, DATABASE_NAME) .build() ) ) } else { if (usePlayServicesStorageBelowS) { appSearchSessionFuture.setFuture( PlayServicesStorage.createSearchSession( PlayServicesStorage.SearchContext.Builder(mContext, DATABASE_NAME) .build() ) ) } else { appSearchSessionFuture.setFuture( LocalStorage.createSearchSession( LocalStorage.SearchContext.Builder(mContext, DATABASE_NAME) .build() ) ) } }
Java
if (BuildCompat.isAtLeastS()) { mAppSearchSessionFuture.setFuture(PlatformStorage.createSearchSession( new PlatformStorage.SearchContext.Builder(mContext, DATABASE_NAME) .build())); } else { if (usePlayServicesStorageBelowS) { mAppSearchSessionFuture.setFuture(PlayServicesStorage.createSearchSession( new PlayServicesStorage.SearchContext.Builder(mContext, DATABASE_NAME) .build())); } else { mAppSearchSessionFuture.setFuture(LocalStorage.createSearchSession( new LocalStorage.SearchContext.Builder(mContext, DATABASE_NAME) .build())); } }
Usando PlatformStorage e PlayServicesStorage, seu app pode
compartilhar dados com segurança com outros apps para que eles também possam pesquisar
os dados do seu app. O compartilhamento de dados de aplicativos somente leitura é concedido
usando uma negociação de certificado para garantir que o outro aplicativo tenha
permissão para ler os dados. Leia mais sobre essa API na documentação
para setSchemaTypeVisibilityForPackage().
Além disso, com PlatformStorage, os dados indexados podem ser mostrados
nas plataformas da interface do sistema. Os aplicativos podem desativar a exibição de alguns ou todos os dados
nas plataformas da interface do sistema. Leia mais sobre essa API na
documentação de setSchemaTypeDisplayedBySystem().
| Recursos | LocalStorage (compatível com o Android 5.0 e versões mais recentes) |
PlatformStorage (compatível com o Android 12 e versões mais recentes) |
PlayServicesStorage (compatível com o Android 5.0 e versões mais recentes) |
|---|---|---|---|
| Pesquisa de texto completo eficiente | |||
| Suporte a vários idiomas | |||
| Tamanho binário reduzido | |||
| Compartilhamento de dados entre aplicativos | |||
| Capacidade de mostrar dados nas plataformas da interface do sistema | |||
| O tamanho e a contagem de documentos podem ser ilimitados | |||
| Operações mais rápidas sem latência adicional do vinculador |
Há outras vantagens e desvantagens a serem consideradas ao escolher entre LocalStorage
e PlatformStorage. Como PlatformStorage envolve APIs do Jetpack no
serviço de sistema do AppSearch, o impacto no tamanho do APK é mínimo em comparação com o uso do
LocalStorage. No entanto, isso também significa que as operações do AppSearch têm latência
adicional de vinculação ao chamar o serviço do sistema do AppSearch. Com PlatformStorage,
o AppSearch limita o número e o tamanho dos documentos que um aplicativo
pode indexar para garantir um índice central eficiente. O PlayServicesStorage também tem
as mesmas limitações que o PlatformStorage e só tem suporte em dispositivos com
o Google Play Services.
Começar a usar o AppSearch
O exemplo desta seção mostra como usar as APIs AppSearch para fazer a integração com um aplicativo hipotético de anotações.
Escrever uma classe de documento
A primeira etapa para integrar o AppSearch é escrever uma classe de documento para
descrever os dados a serem inseridos no banco de dados. Marque uma classe como uma classe de documento
usando a anotação
@Document.É possível usar instâncias da classe de documento para inserir e
extrair documentos do banco de dados.
O código abaixo define uma classe de documento de nota com um campo
anexado @Document.StringProperty
para indexar o texto de um objeto de nota.
Kotlin
@Document public data class Note( // Required field for a document class. All documents MUST have a namespace. @Document.Namespace val namespace: String, // Required field for a document class. All documents MUST have an Id. @Document.Id val id: String, // Optional field for a document class, used to set the score of the // document. If this is not included in a document class, the score is set // to a default of 0. @Document.Score val score: Int, // Optional field for a document class, used to index a note's text for this // document class. @Document.StringProperty(indexingType = AppSearchSchema.StringPropertyConfig.INDEXING_TYPE_PREFIXES) val text: String )
Java
@Document public class Note { // Required field for a document class. All documents MUST have a namespace. @Document.Namespace private final String namespace; // Required field for a document class. All documents MUST have an Id. @Document.Id private final String id; // Optional field for a document class, used to set the score of the // document. If this is not included in a document class, the score is set // to a default of 0. @Document.Score private final int score; // Optional field for a document class, used to index a note's text for this // document class. @Document.StringProperty(indexingType = StringPropertyConfig.INDEXING_TYPE_PREFIXES) private final String text; Note(@NonNull String id, @NonNull String namespace, int score, @NonNull String text) { this.id = Objects.requireNonNull(id); this.namespace = Objects.requireNonNull(namespace); this.score = score; this.text = Objects.requireNonNull(text); } @NonNull public String getNamespace() { return namespace; } @NonNull public String getId() { return id; } public int getScore() { return score; } @NonNull public String getText() { return text; } }
Abrir um banco de dados
Você precisa criar um banco de dados antes de trabalhar com documentos. O código abaixo
cria um novo banco de dados com o nome notes_app e recebe um ListenableFuture
para um AppSearchSession,
que representa a conexão com o banco de dados e fornece as APIs para
operações de banco de dados.
Kotlin
val context: Context = getApplicationContext() val sessionFuture = LocalStorage.createSearchSession( LocalStorage.SearchContext.Builder(context, /*databaseName=*/"notes_app") .build() )
Java
Context context = getApplicationContext(); ListenableFuture<AppSearchSession> sessionFuture = LocalStorage.createSearchSession( new LocalStorage.SearchContext.Builder(context, /*databaseName=*/ "notes_app") .build() );
Definir um esquema
É necessário definir um esquema antes de inserir e recuperar documentos do banco de dados. O esquema do banco de dados consiste em diferentes tipos de dados estruturados, chamados de "tipos de esquema". O código abaixo define o esquema fornecendo a classe de documento como um tipo de esquema.
Kotlin
val setSchemaRequest = SetSchemaRequest.Builder().addDocumentClasses(Note::class.java) .build() val setSchemaFuture = Futures.transformAsync( sessionFuture, { session -> session?.setSchema(setSchemaRequest) }, mExecutor )
Java
SetSchemaRequest setSchemaRequest = new SetSchemaRequest.Builder().addDocumentClasses(Note.class) .build(); ListenableFuture<SetSchemaResponse> setSchemaFuture = Futures.transformAsync(sessionFuture, session -> session.setSchema(setSchemaRequest), mExecutor);
Colocar um documento no banco de dados
Depois que um tipo de esquema é adicionado, você pode adicionar documentos desse tipo ao banco de dados.
O código a seguir cria um documento do tipo de esquema Note usando o builder de classe de documento Note. Ele define o namespace do documento user1 para representar um
usuário arbitrário desse exemplo. O documento é inserido no banco de dados
e um listener é anexado para processar o resultado da operação put.
Kotlin
val note = Note( namespace="user1", id="noteId", score=10, text="Buy fresh fruit" ) val putRequest = PutDocumentsRequest.Builder().addDocuments(note).build() val putFuture = Futures.transformAsync( sessionFuture, { session -> session?.put(putRequest) }, mExecutor ) Futures.addCallback( putFuture, object : FutureCallback<AppSearchBatchResult<String, Void>?> { override fun onSuccess(result: AppSearchBatchResult<String, Void>?) { // Gets map of successful results from Id to Void val successfulResults = result?.successes // Gets map of failed results from Id to AppSearchResult val failedResults = result?.failures } override fun onFailure(t: Throwable) { Log.e(TAG, "Failed to put documents.", t) } }, mExecutor )
Java
Note note = new Note(/*namespace=*/"user1", /*id=*/ "noteId", /*score=*/ 10, /*text=*/ "Buy fresh fruit!"); PutDocumentsRequest putRequest = new PutDocumentsRequest.Builder().addDocuments(note) .build(); ListenableFuture<AppSearchBatchResult<String, Void>> putFuture = Futures.transformAsync(sessionFuture, session -> session.put(putRequest), mExecutor); Futures.addCallback(putFuture, new FutureCallback<AppSearchBatchResult<String, Void>>() { @Override public void onSuccess(@Nullable AppSearchBatchResult<String, Void> result) { // Gets map of successful results from Id to Void Map<String, Void> successfulResults = result.getSuccesses(); // Gets map of failed results from Id to AppSearchResult Map<String, AppSearchResult<Void>> failedResults = result.getFailures(); } @Override public void onFailure(@NonNull Throwable t) { Log.e(TAG, "Failed to put documents.", t); } }, mExecutor);
Pesquisar
É possível pesquisar documentos indexados usando as operações de pesquisa abordadas
nesta seção. O código a seguir executa consultas do termo "fruit" no
banco de dados para documentos que pertencem ao namespace user1.
Kotlin
val searchSpec = SearchSpec.Builder() .addFilterNamespaces("user1") .build(); val searchFuture = Futures.transform( sessionFuture, { session -> session?.search("fruit", searchSpec) }, mExecutor ) Futures.addCallback( searchFuture, object : FutureCallback<SearchResults> { override fun onSuccess(searchResults: SearchResults?) { iterateSearchResults(searchResults) } override fun onFailure(t: Throwable?) { Log.e("TAG", "Failed to search notes in AppSearch.", t) } }, mExecutor )
Java
SearchSpec searchSpec = new SearchSpec.Builder() .addFilterNamespaces("user1") .build(); ListenableFuture<SearchResults> searchFuture = Futures.transform(sessionFuture, session -> session.search("fruit", searchSpec), mExecutor); Futures.addCallback(searchFuture, new FutureCallback<SearchResults>() { @Override public void onSuccess(@Nullable SearchResults searchResults) { iterateSearchResults(searchResults); } @Override public void onFailure(@NonNull Throwable t) { Log.e(TAG, "Failed to search notes in AppSearch.", t); } }, mExecutor);
Iterar por SearchResults
As pesquisas retornam uma instância de SearchResults, que dá acesso às páginas de objetos SearchResult. Cada SearchResult
contém o GenericDocument correspondente, a forma geral de um
documento para o qual todos os documentos são convertidos. O código a seguir recebe a primeira
página de resultados da pesquisa e converte o resultado de volta em um documento Note.
Kotlin
Futures.transform( searchResults?.nextPage, { page: List<SearchResult>? -> // Gets GenericDocument from SearchResult. val genericDocument: GenericDocument = page!![0].genericDocument val schemaType = genericDocument.schemaType val note: Note? = try { if (schemaType == "Note") { // Converts GenericDocument object to Note object. genericDocument.toDocumentClass(Note::class.java) } else null } catch (e: AppSearchException) { Log.e( TAG, "Failed to convert GenericDocument to Note", e ) null } note }, mExecutor )
Java
Futures.transform(searchResults.getNextPage(), page -> { // Gets GenericDocument from SearchResult. GenericDocument genericDocument = page.get(0).getGenericDocument(); String schemaType = genericDocument.getSchemaType(); Note note = null; if (schemaType.equals("Note")) { try { // Converts GenericDocument object to Note object. note = genericDocument.toDocumentClass(Note.class); } catch (AppSearchException e) { Log.e(TAG, "Failed to convert GenericDocument to Note", e); } } return note; }, mExecutor);
Remover um documento
Quando o usuário exclui uma nota, o aplicativo exclui o documento Note
correspondente do banco de dados. Isso garante que a nota não seja mais exibida nas
consultas. O código abaixo faz uma solicitação explícita para remover o documento Note
do banco de dados por ID.
Kotlin
val removeRequest = RemoveByDocumentIdRequest.Builder("user1") .addIds("noteId") .build() val removeFuture = Futures.transformAsync( sessionFuture, { session -> session?.remove(removeRequest) }, mExecutor )
Java
RemoveByDocumentIdRequest removeRequest = new RemoveByDocumentIdRequest.Builder("user1") .addIds("noteId") .build(); ListenableFuture<AppSearchBatchResult<String, Void>> removeFuture = Futures.transformAsync(sessionFuture, session -> session.remove(removeRequest), mExecutor);
Persistência no disco
As atualizações de um banco de dados precisam ser mantidas periodicamente no disco chamando
requestFlush(). O
código a seguir chama requestFlush() com um listener para determinar se a chamada
foi bem-sucedida.
Kotlin
val requestFlushFuture = Futures.transformAsync( sessionFuture, { session -> session?.requestFlush() }, mExecutor ) Futures.addCallback(requestFlushFuture, object : FutureCallback<Void?> { override fun onSuccess(result: Void?) { // Success! Database updates have been persisted to disk. } override fun onFailure(t: Throwable) { Log.e(TAG, "Failed to flush database updates.", t) } }, mExecutor)
Java
ListenableFuture<Void> requestFlushFuture = Futures.transformAsync(sessionFuture, session -> session.requestFlush(), mExecutor); Futures.addCallback(requestFlushFuture, new FutureCallback<Void>() { @Override public void onSuccess(@Nullable Void result) { // Success! Database updates have been persisted to disk. } @Override public void onFailure(@NonNull Throwable t) { Log.e(TAG, "Failed to flush database updates.", t); } }, mExecutor);
Encerrar uma sessão
Uma AppSearchSession
precisa ser fechada quando um aplicativo não chamar mais nenhuma operação
do banco de dados. O código abaixo fecha a sessão do AppSearch que foi aberta
anteriormente e persiste todas as atualizações no disco.
Kotlin
val closeFuture = Futures.transform<AppSearchSession, Unit>(sessionFuture, { session -> session?.close() Unit }, mExecutor )
Java
ListenableFuture<Void> closeFuture = Futures.transform(sessionFuture, session -> { session.close(); return null; }, mExecutor);
Outros recursos
Para saber mais sobre o AppSearch, consulte estes recursos:
Amostras
- Amostra do AppSearch para Android (Kotlin), um app de anotações que usa o AppSearch para indexar as anotações de um usuário e permite que os usuários pesquisem entre elas.
Enviar feedback
Envie comentários e ideias usando os recursos abaixo:
Informe bugs para que possamos corrigi-los.