
Öncelikle çevrimdışı uygulamalar, internet erişimi olmadan temel işlevlerinin tamamını veya kritik bir alt kümesini gerçekleştirebilen uygulamalardır. Yani, işletme mantığının bir kısmını veya tamamını çevrimdışı olarak gerçekleştirebilir.
Öncelikle çevrimdışı uygulamalar oluşturmayla ilgili hususlar veri katmanında başlar. Bu katman, uygulama verilerine ve iş mantığına erişim sunar. Uygulama, zaman zaman bu verileri cihaz dışındaki kaynaklardan yenilemesi gerekebilir. Bunu yaparken güncel kalmak için ağ kaynaklarını kullanması gerekebilir.
Ağın kullanılabilirliği her zaman garanti edilmez. Cihazlarda genellikle düzensiz veya yavaş ağ bağlantısı dönemleri olur. Kullanıcılar aşağıdaki sorunlarla karşılaşabilir:
- Sınırlı internet bant genişliği
- Asansörde veya tüneldeyken olduğu gibi geçici bağlantı kesintileri
- Ara sıra veri erişimi (ör. yalnızca kablosuz bağlantı özellikli tabletler)
Nedeni ne olursa olsun, uygulamaların bu durumlarda yeterli şekilde çalışması genellikle mümkündür. Uygulamanızın çevrimdışı olarak doğru şekilde çalışmasını sağlamak için uygulamanızın aşağıdakileri yapabilmesi gerekir:
- Güvenilir bir ağ bağlantısı olmadan kullanılabilir kalma
- İlk ağ çağrısının tamamlanmasını veya başarısız olmasını beklemek yerine kullanıcılara yerel verileri hemen sunma
- Verileri, pil ve veri durumunu dikkate alarak getirme (ör. yalnızca şarj olurken veya kablosuz bağlantı üzerinden veri getirme isteğinde bulunma)
Bu ölçütleri karşılayan uygulamalara genellikle "önce çevrimdışı" uygulamalar denir.
Önceliği çevrimdışı kullanıma veren bir uygulama tasarlama
Çevrimdışı öncelikli bir uygulama tasarlarken veri katmanından ve uygulama verileri üzerinde gerçekleştirebileceğiniz iki ana işlemden başlayın:
- Okuma: Verileri, uygulamanın diğer bölümlerinde (ör. kullanıcıya bilgi gösterme) kullanılmak üzere alma. Oluşturma işleminde bu genellikle durumun gözlemlenmesiyle yapılır. Kullanıcı arayüzünüz yerel veri kaynağını durum olarak gözlemlediğinde ekran, en son yerel verileri otomatik olarak yansıtır.
- Yazma: Kullanıcı girişini daha sonra almak üzere kalıcı hale getirme. Compose'da bunu genellikle kullanıcı arayüzünden ViewModel'e gönderilen etkinlikler ve işlemlerle yaparsınız.
Veri katmanındaki depolar, uygulama verilerini sağlamak için veri kaynaklarını birleştirmekten sorumludur. Öncelikle çevrimdışı uygulamalarda, en kritik görevlerini gerçekleştirmek için ağ erişimi gerektirmeyen en az bir veri kaynağı olmalıdır. Bu kritik görevlerden biri verileri okumaktır.
Çevrimdışı öncelikli bir uygulamada verileri modelleme
Çevrimdışı öncelikli bir uygulamada, ağ kaynaklarını kullanan her depo için en az 2 veri kaynağı bulunur:
- Yerel veri kaynağı
- Ağ veri kaynağı
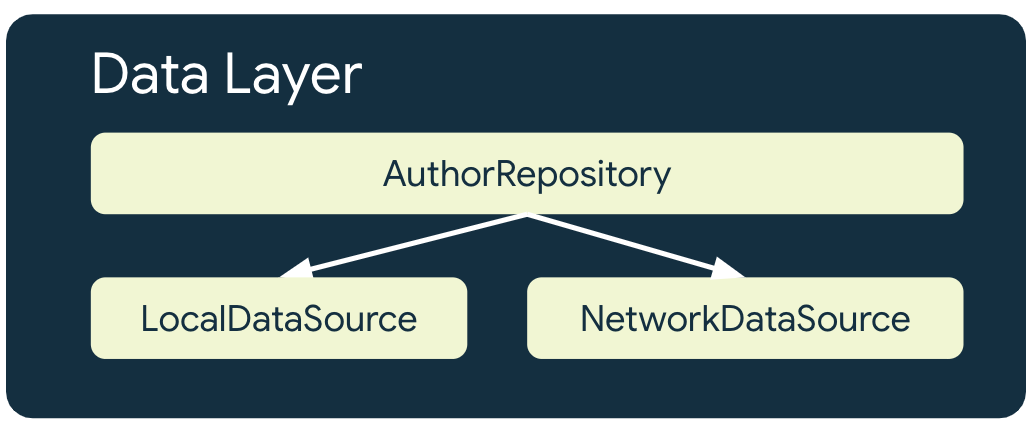
Yerel veri kaynağı
Yerel veri kaynağı, uygulama için standart doğruluk kaynağıdır. Uygulamanın üst katmanlarının okuduğu tüm verilerin tek kaynağı olmalıdır. Bu sayede bağlantı durumları arasında veri tutarlılığı sağlanır. Yerel veri kaynağı genellikle diske kalıcı olarak kaydedilen depolama alanı tarafından desteklenir. Verileri diske kalıcı olarak kaydetmek için kullanılan yaygın yöntemlerden bazıları şunlardır:
- Room gibi ilişkisel veritabanları gibi yapılandırılmış veri kaynakları
- Yapılandırılmamış veri kaynakları (ör. DataStore ile protokol arabellekleri)
- Basit dosyalar
Ağ veri kaynağı
Ağ veri kaynağı, uygulamanın gerçek durumudur. En iyi durumda, yerel veri kaynağı ağ veri kaynağıyla senkronize edilir. Yerel veri kaynağı, ağ veri kaynağının gerisinde de kalabilir. Bu durumda, uygulama tekrar çevrimiçi olduğunda güncellenmesi gerekir. Aynı şekilde, bağlantı tekrar sağlandığında uygulama güncelleyene kadar ağ veri kaynağı yerel veri kaynağının gerisinde kalabilir. Uygulamanın alan ve kullanıcı arayüzü katmanları hiçbir zaman ağ katmanıyla doğrudan iletişim kurmamalıdır. Barındırma repository, bu kaynakla iletişim kurmak ve yerel veri kaynağını güncellemek için kullanmakla sorumludur.
Kaynakları kullanıma sunma
Yerel ve ağ veri kaynakları, uygulamanızın bu kaynaklara okuma ve yazma şekli açısından temel olarak farklılık gösterebilir. Yerel bir veri kaynağını sorgulamak, SQL sorguları kullanırken olduğu gibi hızlı ve esnek olabilir. Buna karşılık, ağ veri kaynakları yavaş ve kısıtlı olabilir. Örneğin, RESTful kaynaklara kimliğe göre artımlı olarak erişildiğinde bu durum yaşanır. Bu nedenle, her veri kaynağının sağladığı verilerin kendi gösterimine ihtiyacı vardır. Bu nedenle, yerel veri kaynağı ve ağ veri kaynağının kendi modelleri olabilir.
Aşağıdaki dizin yapısı bu kavramın görselleştirilmesine yardımcı olur. AuthorEntity, uygulamanın yerel veritabanından okunan bir yazarı, NetworkAuthor ise ağ üzerinden serileştirilmiş bir yazarı temsil eder:
data/
├─ local/
│ ├─ entities/
│ │ ├─ AuthorEntity
│ ├─ dao/
│ ├─ NiADatabase
├─ network/
│ ├─ NiANetwork
│ ├─ models/
│ │ ├─ NetworkAuthor
├─ model/
│ ├─ Author
├─ repository/
AuthorEntity ve NetworkAuthor ile ilgili ayrıntılar aşağıda verilmiştir:
/**
* Network representation of [Author]
*/
@Serializable
data class NetworkAuthor(
val id: String,
val name: String,
val imageUrl: String,
val twitter: String,
val mediumPage: String,
val bio: String,
)
/**
* Defines an author for either an [EpisodeEntity] or [NewsResourceEntity].
* It has a many-to-many relationship with both entities
*/
@Entity(tableName = "authors")
data class AuthorEntity(
@PrimaryKey
val id: String,
val name: String,
@ColumnInfo(name = "image_url")
val imageUrl: String,
@ColumnInfo(defaultValue = "")
val twitter: String,
@ColumnInfo(name = "medium_page", defaultValue = "")
val mediumPage: String,
@ColumnInfo(defaultValue = "")
val bio: String,
)
Hem AuthorEntity hem de NetworkAuthor öğesini veri katmanında tutmak ve harici katmanların kullanması için üçüncü bir türü kullanıma sunmak iyi bir uygulamadır. Bu, harici katmanları yerel ve ağ veri kaynaklarındaki, uygulamanın davranışını temelden değiştirmeyen küçük değişikliklerden korur. Bu durum aşağıdaki snippet'te gösterilmektedir:
/**
* External data layer representation of a "Now in Android" Author
*/
data class Author(
val id: String,
val name: String,
val imageUrl: String,
val twitter: String,
val mediumPage: String,
val bio: String,
)
Ağ modeli daha sonra bunu yerel modele dönüştürmek için bir uzantı yöntemi tanımlayabilir ve yerel model de benzer şekilde aşağıdaki snippet'te gösterildiği gibi bunu harici temsile dönüştürmek için bir yönteme sahiptir:
/**
* Converts the network model to the local model for persisting
* by the local data source
*/
fun NetworkAuthor.asEntity() = AuthorEntity(
id = id,
name = name,
imageUrl = imageUrl,
twitter = twitter,
mediumPage = mediumPage,
bio = bio,
)
/**
* Converts the local model to the external model for use
* by layers external to the data layer
*/
fun AuthorEntity.asExternalModel() = Author(
id = id,
name = name,
imageUrl = imageUrl,
twitter = twitter,
mediumPage = mediumPage,
bio = bio,
)
Okumalar
Okuma işlemleri, öncelikle çevrimdışı uygulamalarda uygulama verileriyle ilgili temel işlemlerdir. Bu nedenle, uygulamanızın verileri okuyabildiğinden ve yeni veriler kullanılabilir hale gelir gelmez bunları görüntüleyebildiğinden emin olmanız gerekir. Bunu yapabilen uygulamalar, gözlemlenebilir türlerle okuma API'leri sundukları için reaktif uygulamalardır.
Aşağıdaki snippet'te, OfflineFirstTopicRepository tüm okuma API'leri için Flow döndürür. Bu sayede, ağ veri kaynağından güncellemeler aldığında okuyucularını güncelleyebilir. Diğer bir deyişle, yerel veri kaynağı geçersiz kılındığında OfflineFirstTopicRepository değişiklikleri gönderebilir. Bu nedenle, OfflineFirstTopicRepository'nın her okuyucusu, ağ bağlantısı uygulamaya geri yüklendiğinde tetiklenebilecek veri değişikliklerini işlemeye hazır olmalıdır. Ayrıca, OfflineFirstTopicRepository verileri doğrudan yerel veri kaynağından okur. Okuyucularını veri değişiklikleri konusunda yalnızca önce yerel veri kaynağını güncelleyerek bilgilendirebilir.
class TopicsViewModel(
offlineFirstTopicsRepository: OfflineFirstTopicsRepository
) : ViewModel() {
val topics: StateFlow<List<Topic>> = offlineFirstTopicsRepository.getTopicsStream()
.stateIn(
scope = viewModelScope,
started = SharingStarted.WhileSubscribed(5_000),
initialValue = emptyList()
)
}
Jetpack Compose uygulamasında, veri katmanı ile kullanıcı arayüzü arasında köprü oluşturmak için ViewModel kullanın.
ViewModel'de Flow öğesini stateIn operatörünü kullanarak StateFlow öğesine dönüştürün. Daha sonra composable'lar, collectAsStateWithLifecycle() kullanarak bu durumları toplar ve abonelikleri yaşam döngüsüne duyarlı bir şekilde otomatik olarak yönetir.
collectAsStateWithLifecycle() hakkında daha fazla bilgi için Durum ve Jetpack Compose başlıklı makaleyi inceleyin.
Hata işleme stratejileri
Çevrimdışı öncelikli uygulamalarda hataları işlemek için, hataların oluşabileceği veri kaynaklarına bağlı olarak benzersiz yöntemler vardır. Aşağıdaki alt bölümlerde bu stratejiler özetlenmektedir.
Yerel veri kaynağı
Yerel veri kaynağından okuma yaparken hataları en aza indirmeye çalışın. Okuyucuları hatalardan korumak için okuyucunun veri topladığı Flow'lerde catch operatörünü kullanın.
catch operatörünü ViewModel içinde aşağıdaki gibi kullanabilirsiniz:
class AuthorViewModel(
authorsRepository: AuthorsRepository,
...
) : ViewModel() {
private val authorId: String = ...
// Observe author information
private val authorStream: Flow<Author> =
authorsRepository.getAuthorStream(
id = authorId
)
.catch { emit(Author.empty()) }
}
Daha esnek bir yaklaşım için LCE (Loading Content Error) çözümünü kullanabilirsiniz. LCE'de okuma sırasında bir hata oluştuğunda hata durumu gösterilir. Genellikle, kullanıcı arayüzü durumlarını Kotlin sealed class olarak modelleyerek LCE'ye ulaşırsınız.
// Define the LCE UI state
sealed interface AuthorUiState {
data object Loading : AuthorUiState
data class Success(val author: Author) : AuthorUiState
data object Error : AuthorUiState
}
class AuthorViewModel(
authorsRepository: AuthorsRepository,
...
) : ViewModel() {
private val authorId: String = ...
// Observe author information and map to LCE state
val authorUiState: StateFlow<AuthorUiState> =
authorsRepository.getAuthorStream(id = authorId)
.map<Author, AuthorUiState> { author ->
AuthorUiState.Success(author)
}
.catch { emit(AuthorUiState.Error) }
.stateIn(
scope = viewModelScope,
started = SharingStarted.WhileSubscribed(5_000),
initialValue = AuthorUiState.Loading
)
}
Ağ veri kaynağı
Bir ağ veri kaynağından veri okunurken hata oluşursa uygulamanın, verileri getirme işlemini yeniden denemek için bir sezgisel yöntem kullanması gerekir. Sık kullanılan sezgisel yöntemler şunlardır:
Eksponansiyel geri yükleme
Eksponansiyel geri yükleme işleminde uygulama, başarılı olana veya başka koşullar durdurulması gerektiğini belirleyene kadar artan zaman aralıklarıyla ağ veri kaynağından okumaya çalışmaya devam eder.
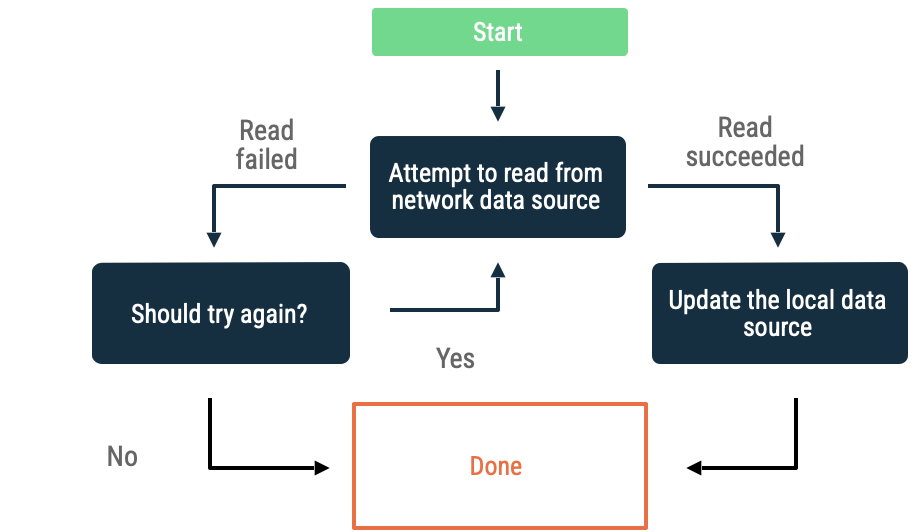
Uygulamanın geri çekilmeye devam edip etmediğini değerlendirmek için kullanılan ölçütler şunlardır:
- Ağ veri kaynağının belirttiği hata türü. Örneğin, bağlantı eksikliğini gösteren bir hata döndüren ağ çağrılarını yeniden deneyin. Uygun kimlik bilgileri kullanılabilir olana kadar yetkilendirilmemiş HTTP isteklerini yeniden denemeyin.
- İzin verilen maksimum yeniden deneme sayısı.
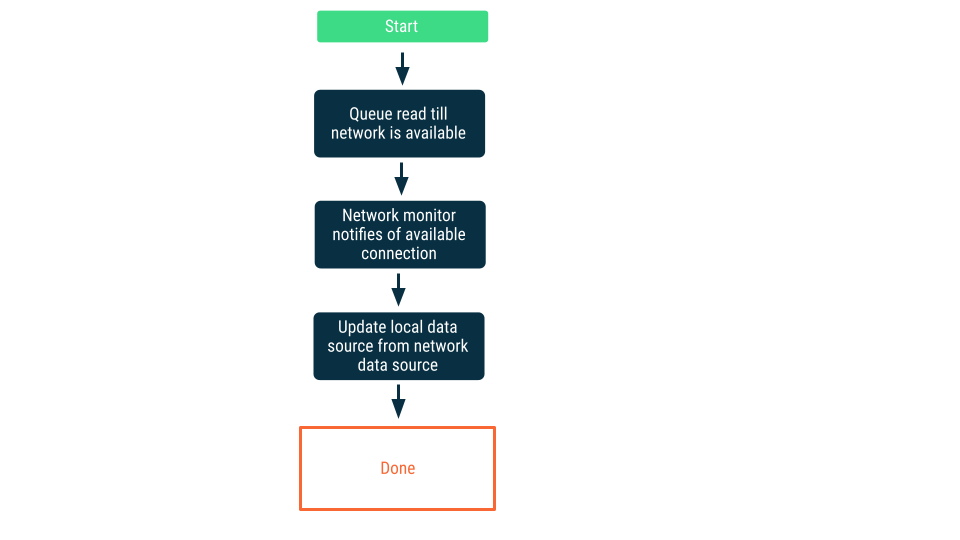
Ağ bağlantısı izleme
Bu yaklaşımda, uygulama ağ veri kaynağına bağlanabileceğinden emin olana kadar okuma istekleri kuyruğa alınır. Bağlantı kurulduktan sonra okuma isteği kuyruktan çıkarılır, veriler okunur ve yerel veri kaynağı güncellenir. Android'de bu sıra, Room veritabanı ile korunabilir ve WorkManager kullanılarak kalıcı iş olarak boşaltılabilir.
Yazma işlemleri
Çevrimdışı öncelikli bir uygulamada verileri okumak için önerilen yöntem gözlemlenebilir türleri kullanmaktır. Yazma API'leri için eşdeğer olanlar ise askıya alma işlevleri gibi eşzamansız API'lerdir. Bu, kullanıcı arayüzü iş parçacığının engellenmesini önler ve çevrimdışı öncelikli uygulamalarda ağ sınırını aşarken yazma işlemleri başarısız olabileceğinden hata işlemeye yardımcı olur.
interface UserDataRepository {
/**
* Updates the bookmarked status for a news resource
*/
suspend fun updateNewsResourceBookmark(newsResourceId: String, bookmarked: Boolean)
}
Önceki snippet'te, yöntem askıya alındığı için tercih edilen asenkron API Coroutines'tir.
Yazma stratejileri
Çevrimdışı öncelikli uygulamalara veri yazarken göz önünde bulundurulması gereken üç strateji vardır. Hangi türü seçeceğiniz, yazılan verilerin türüne ve uygulamanın gereksinimlerine bağlıdır:
Yalnızca online yazma işlemleri
Verileri ağ sınırı boyunca yazmaya çalışmak İşlem başarılı olursa yerel veri kaynağını güncelleyin. Aksi takdirde bir istisna oluşturun ve uygun şekilde yanıt vermeyi arayana bırakın.
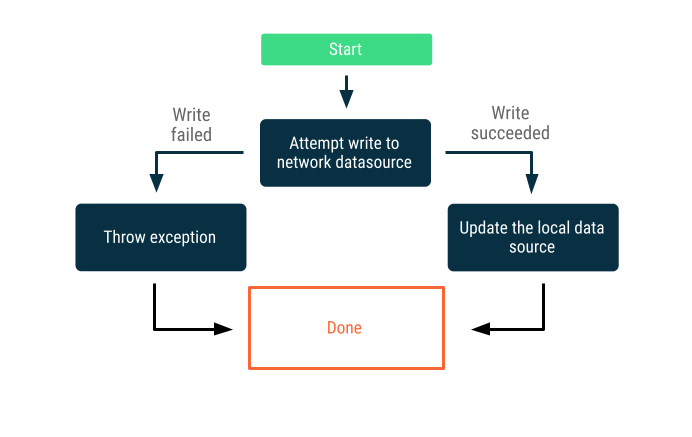
Bu strateji genellikle neredeyse gerçek zamanlı olarak internette gerçekleşmesi gereken yazma işlemleri (ör. banka havalesi) için kullanılır. Yazma işlemleri başarısız olabileceğinden, genellikle kullanıcıya yazma işleminin başarısız olduğunu bildirmek veya kullanıcının veri yazma girişiminde bulunmasını engellemek gerekir. Bu senaryolarda kullanabileceğiniz bazı stratejiler şunlardır:
- Bir uygulama, veri yazmak için internet erişimi gerektiriyorsa kullanıcıya veri yazmasına izin veren bir kullanıcı arayüzü göstermemeyi veya en azından bu arayüzü devre dışı bırakmayı tercih edebilirsiniz.
- Kullanıcıya çevrimdışı olduğunu bildirmek için kullanıcının kapatamayacağı bir
AlertDialogveya birSnackbarkullanabilirsiniz.
Kuyruğa alınan yazma işlemleri
Yazmak istediğiniz bir nesne olduğunda bunu bir sıraya ekleyin. Uygulama tekrar internete bağlandığında, eksponansiyel geri yükleme ile sırayı boşaltın. Android'de, çevrimdışı kuyruğu boşaltmak, genellikle WorkManager'ye devredilen sürekli bir iştir.
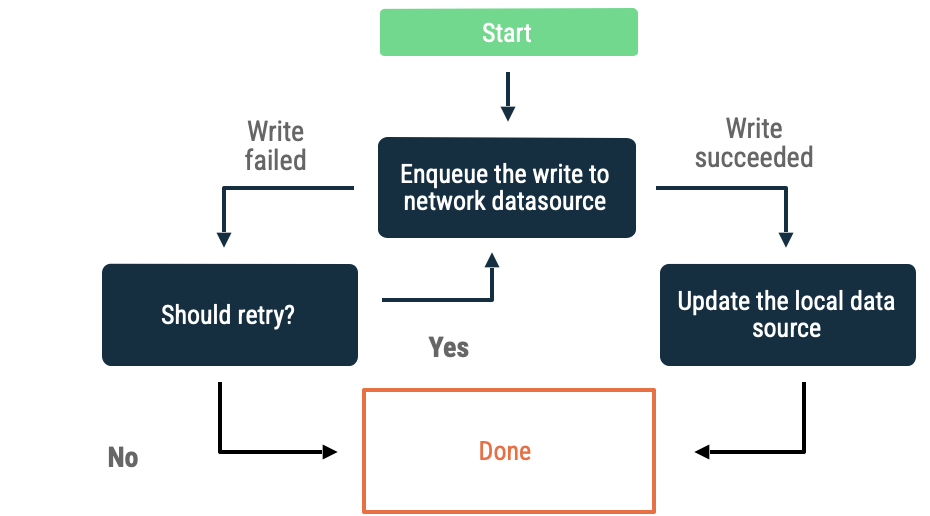
Bu yaklaşım aşağıdaki senaryolarda iyi bir seçimdir:
- Verilerin ağa yazılması gerekmez.
- İşlem zamana duyarlı değildir.
- İşlem başarısız olursa kullanıcının bilgilendirilmesi zorunlu değildir.
Bu yaklaşımla ilgili kullanım alanları arasında analiz etkinlikleri ve günlük kaydı yer alır.
Geç yazma işlemleri
Önce yerel veri kaynağına yazın, ardından ağa en kısa sürede bildirim göndermek için yazma işlemini sıraya alın. Uygulama tekrar internete bağlandığında ağ ve yerel veri kaynakları arasında çakışmalar olabileceğinden bu işlem önemlidir. Çakışma çözümüyle ilgili sonraki bölümde daha ayrıntılı bilgi verilmektedir.
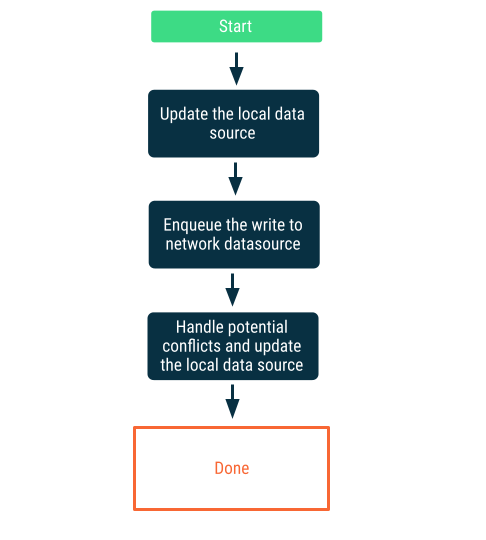
Bu yaklaşım, verilerin uygulama için kritik olduğu durumlarda doğru seçimdir. Örneğin, öncelikle çevrimdışı çalışan bir yapılacaklar listesi uygulamasında, kullanıcının çevrimdışıyken eklediği görevlerin veri kaybı riskini önlemek için yerel olarak depolanması gerekir.
Senkronizasyon ve çakışma çözümü
Çevrimdışı öncelikli bir uygulama bağlantısını geri yüklediğinde yerel veri kaynağındaki verileri ağ veri kaynağındaki verilerle uzlaştırması gerekir. Bu sürece senkronizasyon denir. Bir uygulamanın ağ veri kaynağıyla senkronize olmasının iki ana yolu vardır:
- Çekmeye dayalı senkronizasyon
- Push tabanlı senkronizasyon
Çekmeye dayalı senkronizasyon
Çekmeye dayalı senkronizasyonda uygulama, talep üzerine en son uygulama verilerini okumak için ağa ulaşır. Bu yaklaşımla ilgili yaygın bir sezgisel yöntem, uygulamaların verileri yalnızca kullanıcıya sunmadan hemen önce getirdiği, gezinmeye dayalı yöntemdir.
Bu yaklaşım, uygulamanın kısa veya orta süreli ağ bağlantısı kesintileri beklemesi durumunda en iyi sonucu verir. Bunun nedeni, veri yenilemenin fırsatçı olması ve uzun süreli bağlantı olmaması durumunda kullanıcının, eski veya boş bir önbelleğe sahip uygulama hedeflerini ziyaret etme olasılığının artmasıdır.
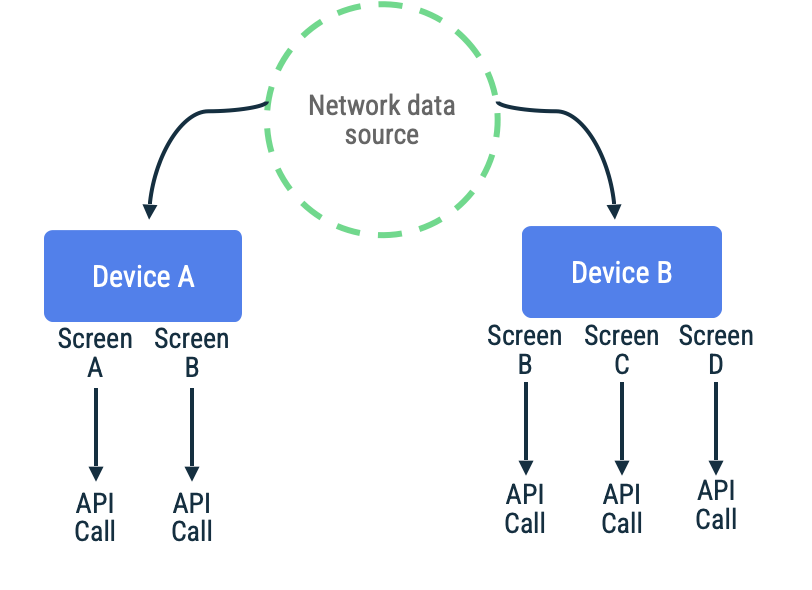
Belirli bir ekranda sonsuz kaydırma listesindeki öğeleri getirmek için sayfa jetonlarının kullanıldığı bir uygulamayı ele alalım. Uygulama, ağa geç erişebilir, verileri yerel veri kaynağında kalıcı hale getirebilir ve ardından bilgileri kullanıcıya geri sunmak için yerel veri kaynağından okuyabilir. Ağ bağlantısı olmadığında, depo yalnızca yerel veri kaynağından veri isteyebilir. Bu, RemoteMediator API'siyle birlikte Jetpack Paging Library tarafından kullanılan kalıptır.
class FeedRepository(...) {
fun feedPagingSource(): PagingSource<FeedItem> { ... }
}
class FeedViewModel(
private val repository: FeedRepository
) : ViewModel() {
private val pager = Pager(
config = PagingConfig(
pageSize = NETWORK_PAGE_SIZE,
enablePlaceholders = false
),
remoteMediator = FeedRemoteMediator(...),
pagingSourceFactory = feedRepository::feedPagingSource
)
val feedPagingData = pager.flow
}
Çekmeye dayalı senkronizasyonun avantajları ve dezavantajları aşağıdaki tabloda özetlenmiştir:
| Avantajları | Dezavantajları |
|---|---|
| Uygulaması nispeten kolaydır. | Yoğun veri kullanımına yatkın. Bunun nedeni, bir gezinme hedefine yapılan tekrarlı ziyaretlerin, değişmeyen bilgilerin gereksiz yere yeniden getirilmesini tetiklemesidir. Uygun önbelleğe alma işlemiyle bu durumu hafifletebilirsiniz. Bu işlem, kullanıcı arayüzü katmanında cachedIn operatörüyle veya ağ katmanında HTTP önbelleğiyle yapılabilir. |
| Gerekmeyen veriler hiçbir zaman getirilmez. | Modelin kendi kendine yeterli olması gerektiğinden ilişkisel verilerle iyi ölçeklenmez. Senkronize edilen modelin kendisini doldurmak için getirilmesi gereken başka modeller varsa daha önce bahsedilen yoğun veri kullanımı sorunu daha da önemli hale gelir. Ayrıca, üst modelin depoları ile iç içe yerleştirilmiş modelin depoları arasında bağımlılıklara neden olabilir. |
Push tabanlı senkronizasyon
Push tabanlı senkronizasyonda, yerel veri kaynağı, ağ veri kaynağının bir kopyasını olabildiğince taklit etmeye çalışır. Temel oluşturmak için ilk başlangıçta uygun miktarda veriyi proaktif olarak getirir. Bundan sonra, bu veriler eski olduğunda uyarı vermek için sunucudan gelen bildirimlere güvenir.
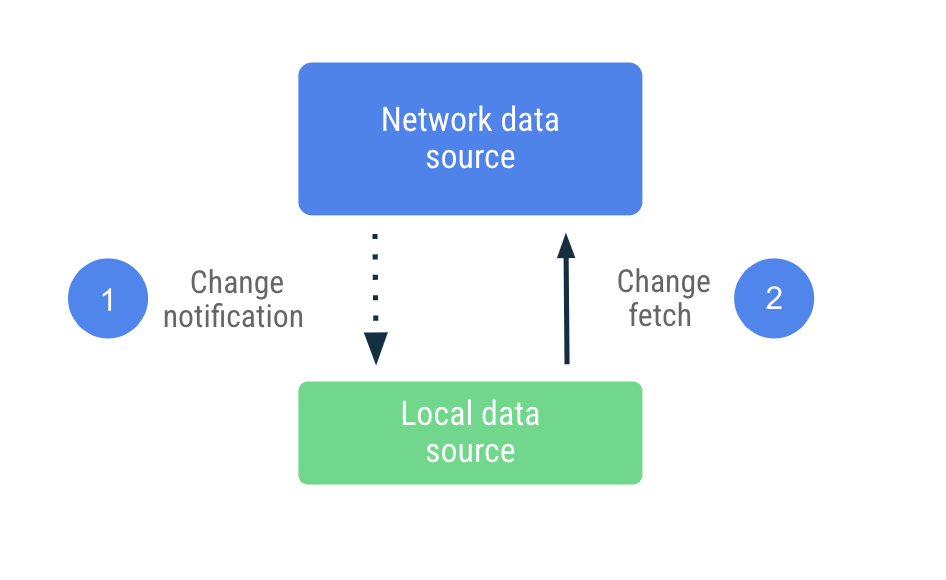
Uygulama, eski bildirim alındığında yalnızca eski olarak işaretlenen verileri güncellemek için ağa ulaşır. Bu görev, ağ veri kaynağına ulaşan ve getirilen verileri yerel veri kaynağında kalıcı hale getiren Repository'ya devredilir. Depo, verilerini gözlemlenebilir türlerle sunduğundan okuyucular değişikliklerden haberdar edilir.
class UserDataRepository(...) {
suspend fun synchronize() {
val userData = networkDataSource.fetchUserData()
localDataSource.saveUserData(userData)
}
}
Bu yaklaşımda uygulama, ağ veri kaynağına çok daha az bağımlıdır ve uzun süreler boyunca bu kaynak olmadan çalışabilir. Ağ veri kaynağındaki en son bilgilerin yerel olarak bulunduğunu varsaydığı için çevrimdışıyken hem okuma hem de yazma erişimi sunar.
Anında senkronizasyonun avantajları ve dezavantajları aşağıdaki tabloda özetlenmiştir:
| Avantajları | Dezavantajları |
|---|---|
| Uygulama süresiz olarak çevrimdışı kalabilir. | Çakışma çözümü için sürüm oluşturma verileri kolay bir işlem değildir. |
| Minimum veri kullanımı. Uygulama yalnızca değişen verileri getirir. | Senkronizasyon sırasında yazma sorunlarını dikkate almanız gerekir. |
| İlişkisel veriler için uygundur. Her depo, yalnızca desteklediği modelin verilerini getirmekle sorumludur. | Ağ veri kaynağının senkronizasyonu desteklemesi gerekir. |
Karma senkronizasyon
Bazı uygulamalar, verilere bağlı olarak çekme veya gönderme tabanlı hibrit bir yaklaşım kullanır. Örneğin, bir sosyal medya uygulaması, feed güncellemelerinin sıklığı nedeniyle kullanıcının takip ettiği feed'i isteğe bağlı olarak getirmek için çekmeye dayalı senkronizasyonu kullanabilir. Aynı uygulama, oturum açmış kullanıcıyla ilgili veriler (kullanıcı adı, profil resmi vb.) için push tabanlı senkronizasyonu kullanmayı tercih edebilir.
Sonuç olarak, öncelikle çevrimdışı senkronizasyon seçimi ürün gereksinimlerine ve mevcut teknik altyapıya bağlıdır.
Çakışma çözümü
Uygulama, çevrimdışı durumdayken ağ veri kaynağıyla uyumlu olmayan verileri yerel olarak yazarsa senkronizasyonun gerçekleşebilmesi için çakışmayı çözmeniz gerekir.
Çakışma çözümü genellikle sürüm oluşturmayı gerektirir. Uygulamanın, değişikliklerin ne zaman gerçekleştiğini takip edebilmesi ve böylece meta verileri ağ veri kaynağına aktarabilmesi için bazı kayıt işlemleri yapması gerekir. Ağ veri kaynağı, mutlak doğru kaynağı sağlamakla yükümlüdür. Uygulamanın ihtiyaçlarına bağlı olarak, anlaşmazlık çözümü için göz önünde bulundurulması gereken birçok strateji vardır. Mobil uygulamalarda yaygın bir yaklaşım "son yazma kazanır"dır.
Son yazma işlemi kazanır
Bu yaklaşımda cihazlar, ağa yazdıkları verilere zaman damgası meta verileri ekler. Ağ veri kaynağı bu verileri aldığında mevcut durumundan daha eski olan verileri atar, mevcut durumundan daha yeni olanları ise kabul eder.
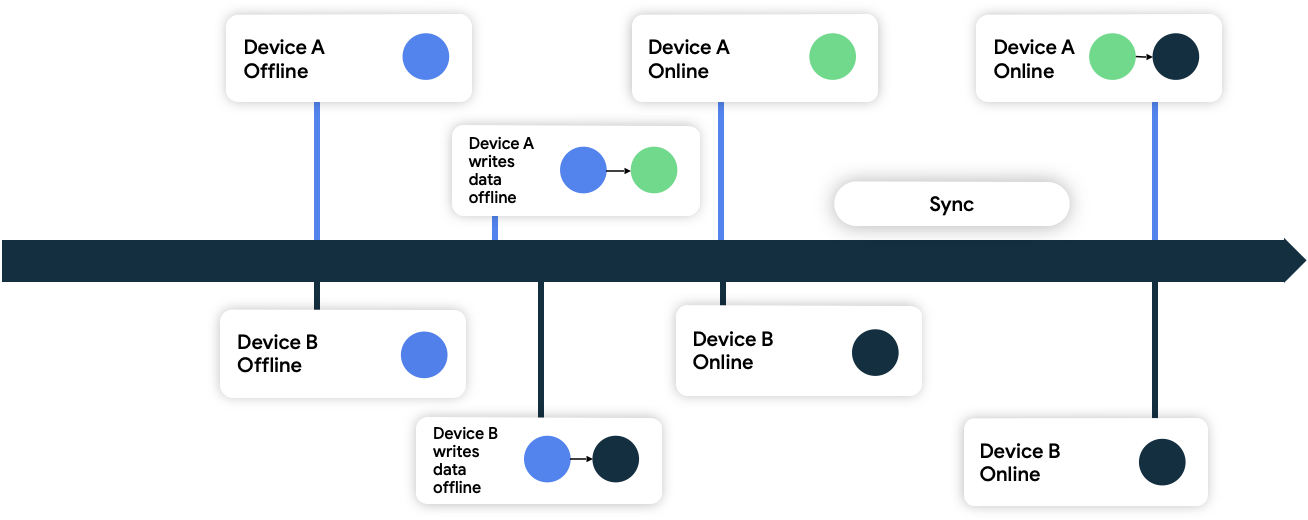
Şekil 9'da her iki cihaz da çevrimdışı ve başlangıçta ağ veri kaynağıyla senkronize durumdadır. Çevrimdışıyken hem verileri yerel olarak yazar hem de verilerini yazdıkları zamanı takip ederler. Her ikisi de tekrar internete bağlandığında ve ağ veri kaynağıyla senkronize olduğunda ağ, verilerini daha sonra yazdığı için B cihazındaki verileri kalıcı hale getirerek çakışmayı giderir.
Çevrimdışı öncelikli uygulamalarda WorkManager
Daha önce ele alınan hem okuma hem de yazma stratejilerinde iki yaygın yardımcı program bulunur:
- Sıralar
- Okuma: Ağ bağlantısı kullanılabilir olana kadar okuma işlemlerini ertelemek için kullanılır.
- Yazma: Ağ bağlantısı kullanılabilir olana kadar yazma işlemlerini ertelemek ve yeniden denemek için yazma işlemlerini yeniden sıraya almak üzere kullanılır.
- Ağ bağlantısı monitörleri
- Okuma: Uygulama bağlandığında ve senkronizasyon için okuma sırasını boşaltmak üzere sinyal olarak kullanılır.
- Yazma: Uygulama bağlandığında yazma sırasını boşaltmak ve senkronizasyon için sinyal olarak kullanılır.
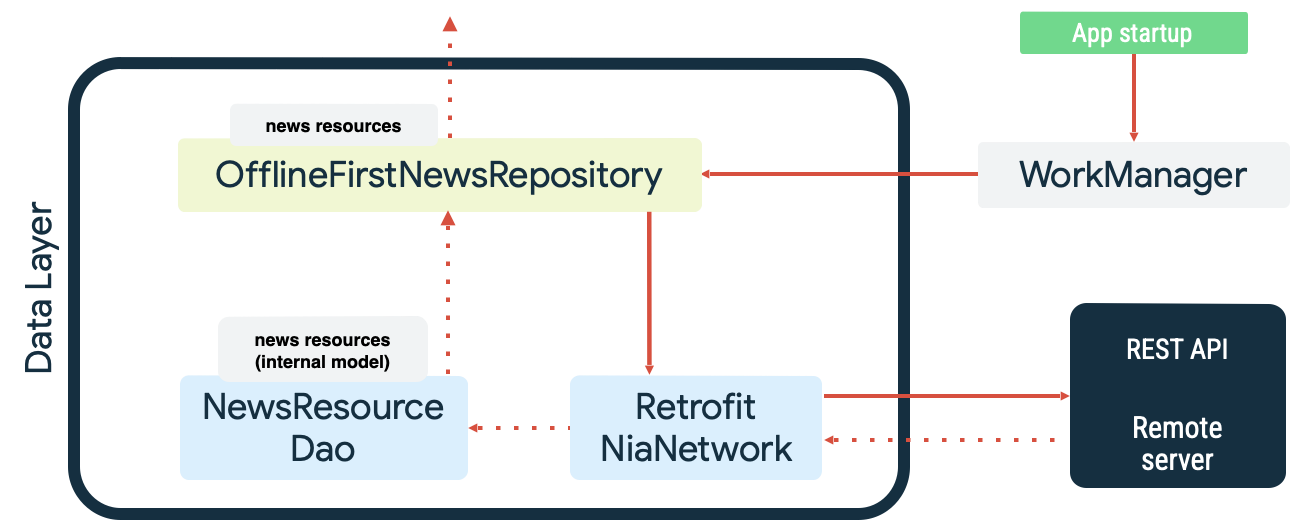
Her iki durum da WorkManager'ın uzmanlaştığı kalıcı işlere örnektir. Örneğin, Now in Android örnek uygulamasında, yerel veri kaynağı senkronize edilirken WorkManager hem okuma sırası hem de ağ izleyici olarak kullanılır. Uygulama başlatıldığında şunları yapar:
- Yerel veri kaynağı ile ağ veri kaynağı arasında eşitlik olmasını sağlamak için okuma senkronizasyonu işini sıraya alır.
- Okuma senkronizasyonu kuyruğunu boşaltır ve uygulama internete bağlandığında senkronizasyonu başlatır.
- Eksponansiyel geri yükleme kullanarak ağ veri kaynağından okuma işlemi gerçekleştirir.
- Okuma sonuçlarını yerel veri kaynağında kalıcı hale getirir ve oluşan çakışmaları giderir.
- Uygulamanın diğer katmanlarının kullanabilmesi için yerel veri kaynağındaki verileri kullanıma sunar.
Bu işlemler aşağıdaki diyagramda gösterilmektedir:
Senkronizasyon işinin WorkManager ile sıraya alınması, KEEP ExistingWorkPolicy ile unique work (benzersiz iş) olarak belirtilerek yapılır:
class SyncInitializer : Initializer<Sync> {
override fun create(context: Context): Sync {
WorkManager.getInstance(context).apply {
// Queue sync on app startup and ensure only one
// sync worker runs at any time
enqueueUniqueWork(
SyncWorkName,
ExistingWorkPolicy.KEEP,
SyncWorker.startUpSyncWork()
)
}
return Sync
}
}
SyncWorker.startupSyncWork() aşağıdaki şekilde tanımlanır:
/**
Create a WorkRequest to call the SyncWorker using a DelegatingWorker.
This allows for dependency injection into the SyncWorker in a different
module than the app module without having to create a custom WorkManager
configuration.
*/
fun startUpSyncWork() = OneTimeWorkRequestBuilder<DelegatingWorker>()
// Run sync as expedited work if the app is able to.
// If not, it runs as regular work.
.setExpedited(OutOfQuotaPolicy.RUN_AS_NON_EXPEDITED_WORK_REQUEST)
.setConstraints(SyncConstraints)
// Delegate to the SyncWorker.
.setInputData(SyncWorker::class.delegatedData())
.build()
val SyncConstraints
get() = Constraints.Builder()
.setRequiredNetworkType(NetworkType.CONNECTED)
.build()
Özellikle, SyncConstraints tarafından tanımlanan Constraints, NetworkType'nin NetworkType.CONNECTED olmasını gerektirir. Yani, çalıştırılmadan önce ağın kullanılabilir olmasını bekler.
Ağ kullanılabilir olduğunda Worker, uygun Repository örneklerine yetki vererek SyncWorkName tarafından belirtilen benzersiz iş sırasını boşaltır. Senkronizasyon başarısız olursa doWork() yöntemi Result.retry() ile birlikte döndürülür. WorkManager, eksponansiyel geri yüklemeyle senkronizasyonu otomatik olarak yeniden dener. Aksi takdirde, senkronizasyonu tamamlayarak Result.success() değerini döndürür.
class SyncWorker(...) : CoroutineWorker(appContext, workerParams), Synchronizer {
override suspend fun doWork(): Result = withContext(ioDispatcher) {
// First sync the repositories in parallel
val syncedSuccessfully = awaitAll(
async { topicRepository.sync() },
async { authorsRepository.sync() },
async { newsRepository.sync() },
).all { it }
if (syncedSuccessfully) Result.success()
else Result.retry()
}
}
Örnekler
Aşağıdaki Google örnekleri, öncelikle çevrimdışı uygulamaları gösterir. Bu kılavuzun nasıl uygulandığını görmek için aşağıdaki kaynakları inceleyin:
Sizin için önerilenler
- Not: JavaScript kapalıyken bağlantı metni gösterilir.
- Kullanıcı arayüzü durumu üretimi
- Kullanıcı arayüzü katmanı
- Veri katmanı