Профилировщик кадров AGI позволяет вам проверять отдельные проходы рендеринга, которые используются для составления одного кадра вашего приложения. Это достигается путем перехвата и записи всего состояния, необходимого для выполнения каждого вызова графического API. В Vulkan это делается с помощью системы слоев Vulkan. В OpenGL команды перехватываются с помощью ANGLE, который преобразует команды OpenGL в вызовы Vulkan, чтобы их можно было выполнить на оборудовании.
Адрено устройства
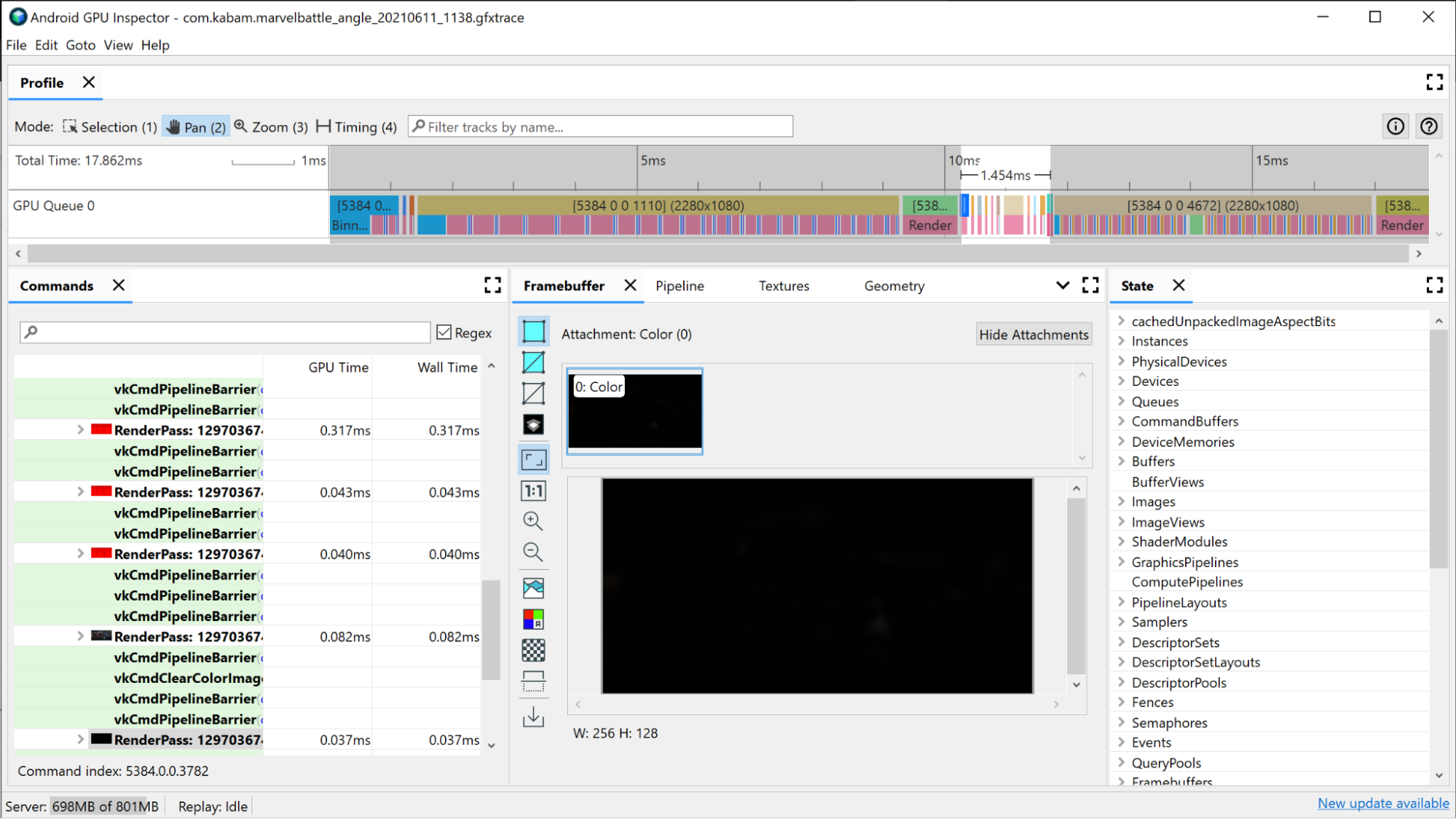
Чтобы определить ваши дорогостоящие проходы рендеринга, сначала посмотрите на временную шкалу AGI в верхней части окна. Здесь в хронологическом порядке отображаются все проходы рендеринга, составляющие композицию данного кадра. Это то же представление, которое вы бы увидели в средстве профилирования системы, если бы у вас была информация об очереди графического процессора. Он также предоставляет базовую информацию о этапе рендеринга, например разрешение кадровых буферов, в которых выполняется рендеринг, что может дать некоторое представление о том, что происходит на самом этапе рендеринга.
Первый критерий, который вы можете использовать для изучения ваших проходов рендеринга, — это сколько времени они занимают. Самый длинный проход рендеринга, скорее всего, будет иметь наибольший потенциал для улучшения, поэтому начните с его рассмотрения.
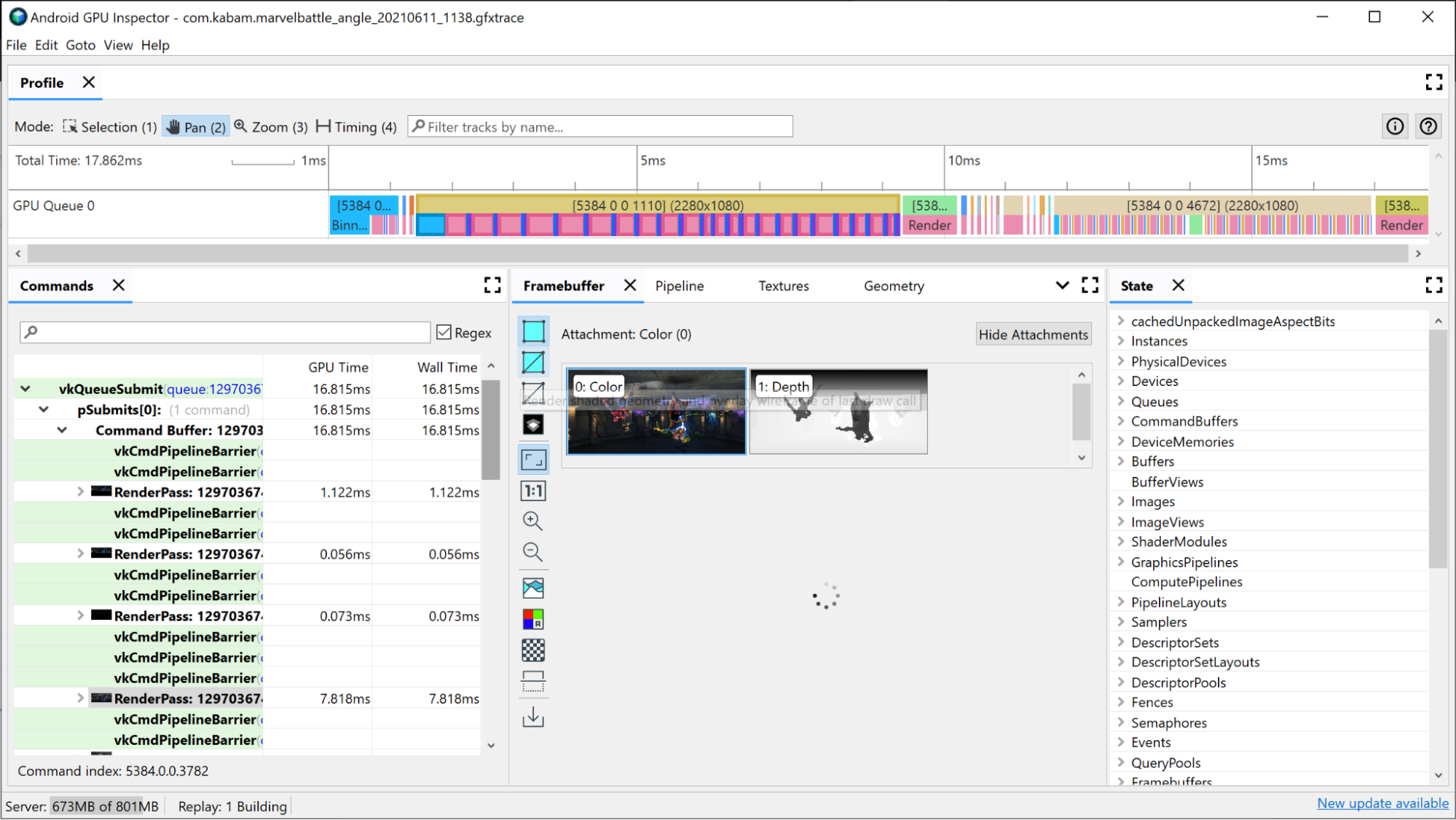
Срез графического процессора, относящийся к соответствующему проходу рендеринга, уже предоставит некоторую информацию о том, что происходит внутри прохода рендеринга:
- Биннинг: вершины помещаются в ячейки в зависимости от того, где они находятся на экране.
- Рендеринг: затенение пикселей или фрагментов.
- Загрузка/сохранение GMEM: когда содержимое кадрового буфера загружается или сохраняется из внутренней памяти графического процессора в основную память.
Вы можете получить хорошее представление о потенциальных узких местах, посмотрев, сколько времени каждое из них занимает в ходе рендеринга. Например:
- Если биннинг занимает большую часть времени, это указывает на наличие узкого места в данных вершин, которое предполагает слишком много вершин, большие вершины или другие проблемы, связанные с вершинами.
- Если рендеринг занимает большую часть времени, это означает, что узким местом является затенение. Возможными причинами могут быть сложные шейдеры, слишком большое количество выборок текстур, рендеринг в кадровом буфере высокого разрешения, когда в этом нет необходимости, или другие связанные проблемы.
Также следует помнить о загрузке и хранении GMEM. Перемещать данные из графической памяти в основную память дорого, поэтому минимизация количества операций загрузки или сохранения также поможет повысить производительность. Типичным примером этого является наличие хранилища глубины/трафарета GMEM, которое записывает буфер глубины/трафарета в основную память; если вы не будете использовать этот буфер в будущих проходах рендеринга, эту операцию сохранения можно исключить, и вы сэкономите время кадра и пропускную способность памяти.
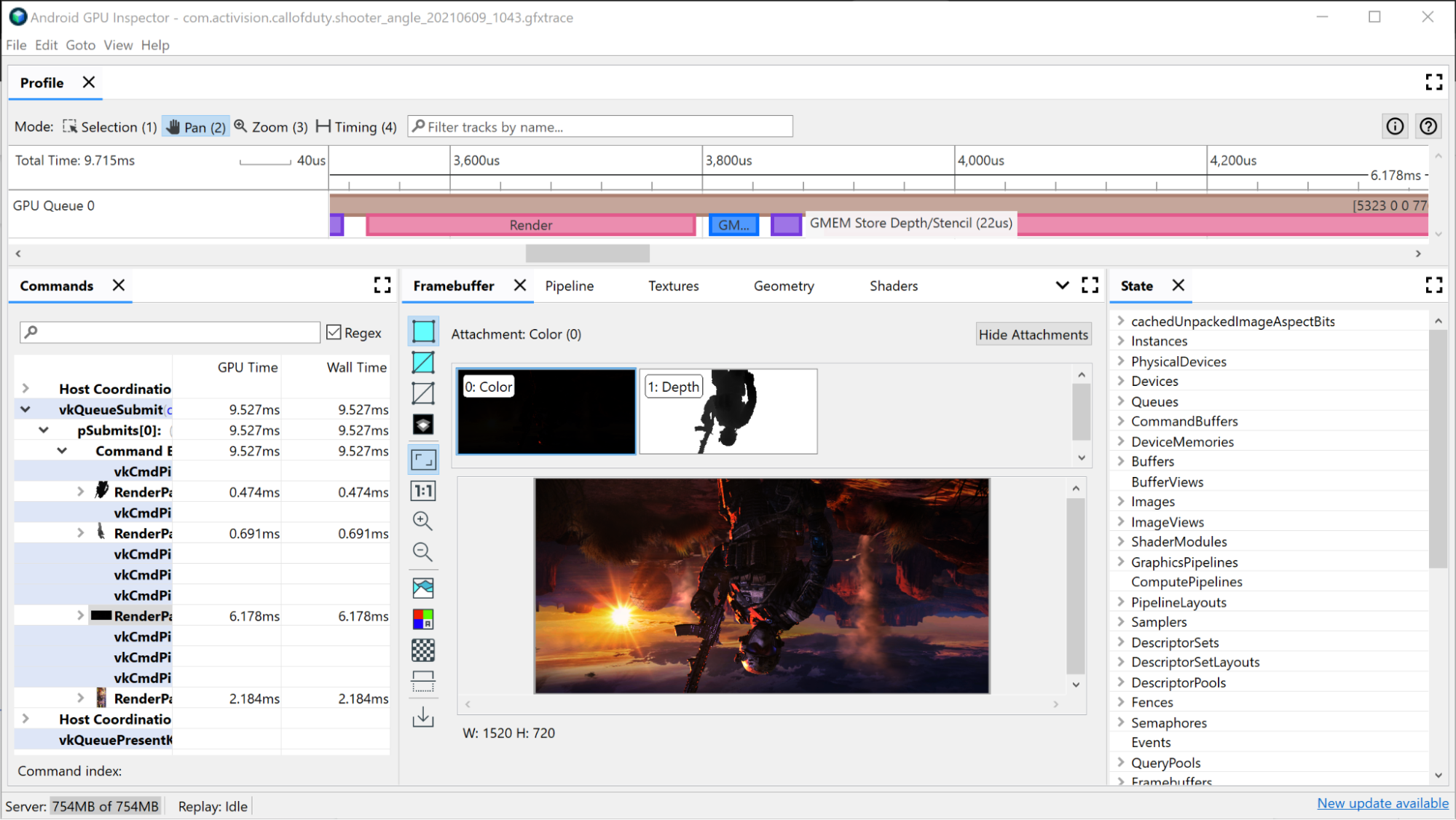
Большой рендеринг проходит расследование
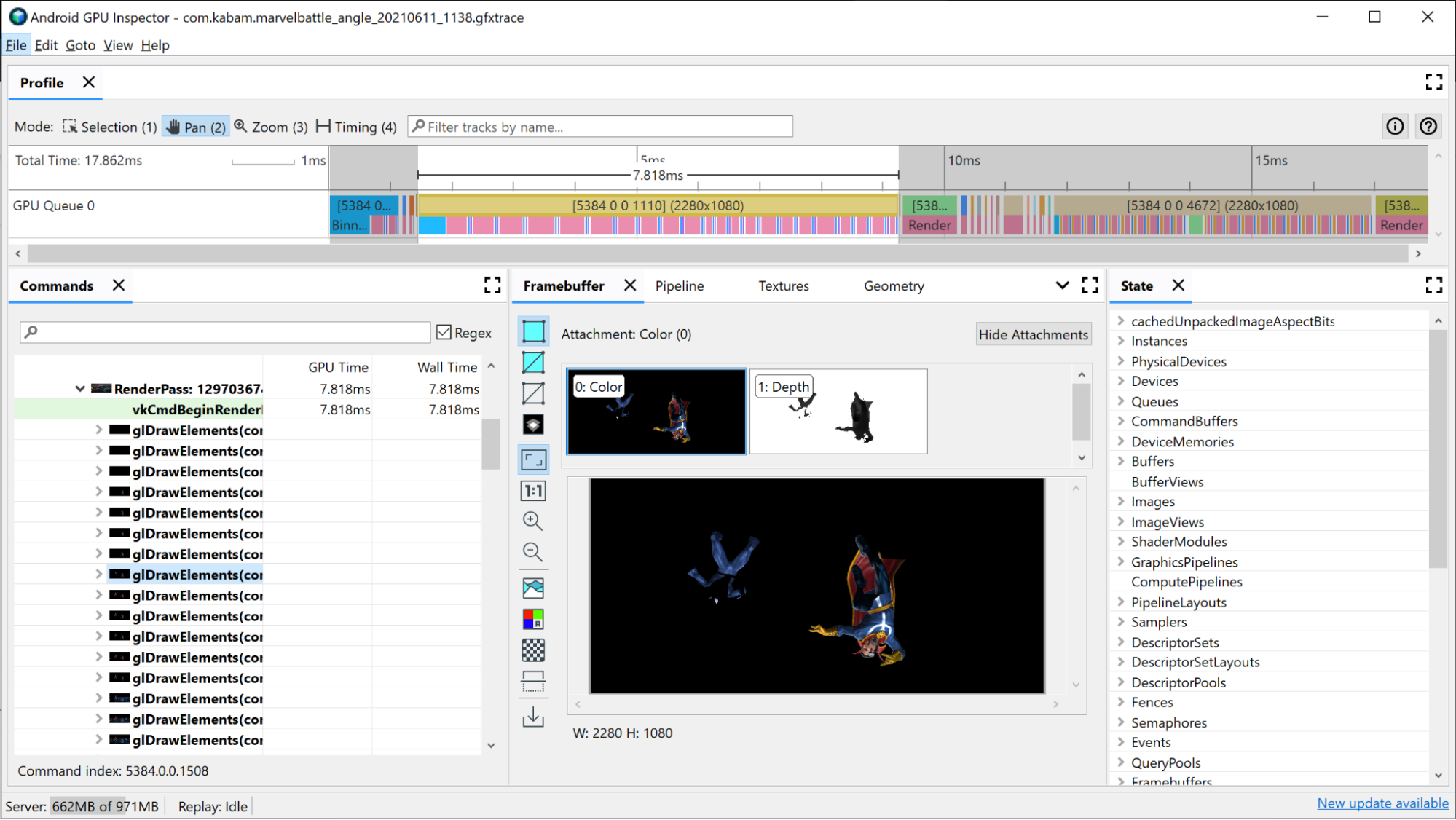
Чтобы просмотреть все отдельные команды рисования, выполненные во время этапа рендеринга:
Щелкните проход рендеринга на временной шкале. Это откроет этап рендеринга в иерархии, расположенной на панели «Команды» Frame Profiler .
Щелкните меню прохода рендеринга, в котором отображаются все отдельные команды рисования, выполненные во время прохода рендеринга. Если это приложение OpenGL, вы можете копнуть еще дальше и увидеть команды Vulkan, выдаваемые ANGLE.
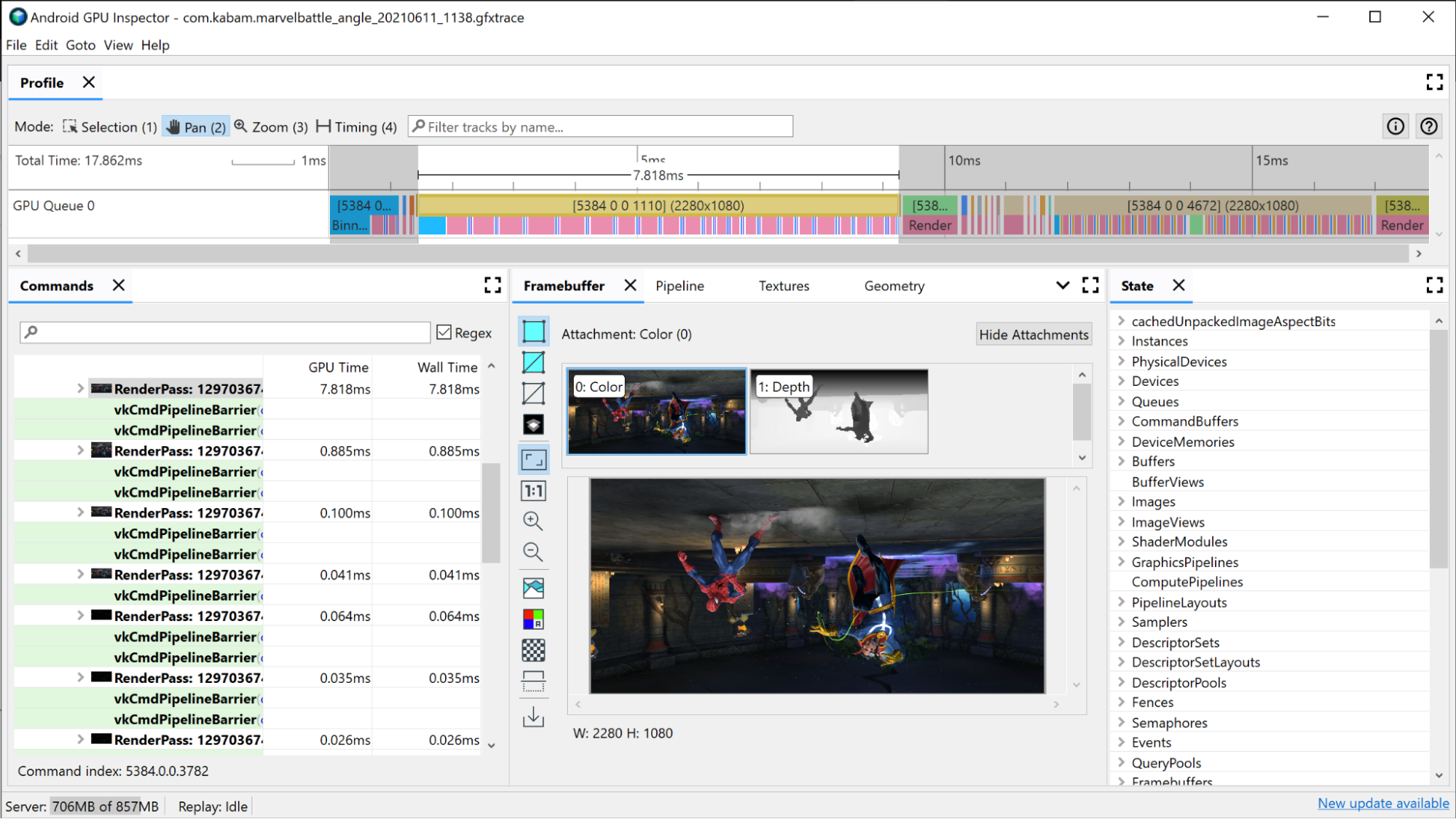
Выберите один из вызовов отрисовки. Откроется панель «Кадровый буфер» , на которой показаны все вложения кадрового буфера, которые были привязаны во время этой прорисовки, а также окончательный результат прорисовки прикрепленного кадрового буфера. Здесь вы также можете использовать AGI, чтобы открыть предыдущий и следующий вызовы отрисовки и сравнить разницу между ними. Если они визуально почти идентичны, это предполагает возможность исключить вызов отрисовки, который не влияет на окончательное изображение.
При открытии панели «Конвейер» для этого отрисовки отображается состояние, используемое графическим конвейером для выполнения этого вызова отрисовки.
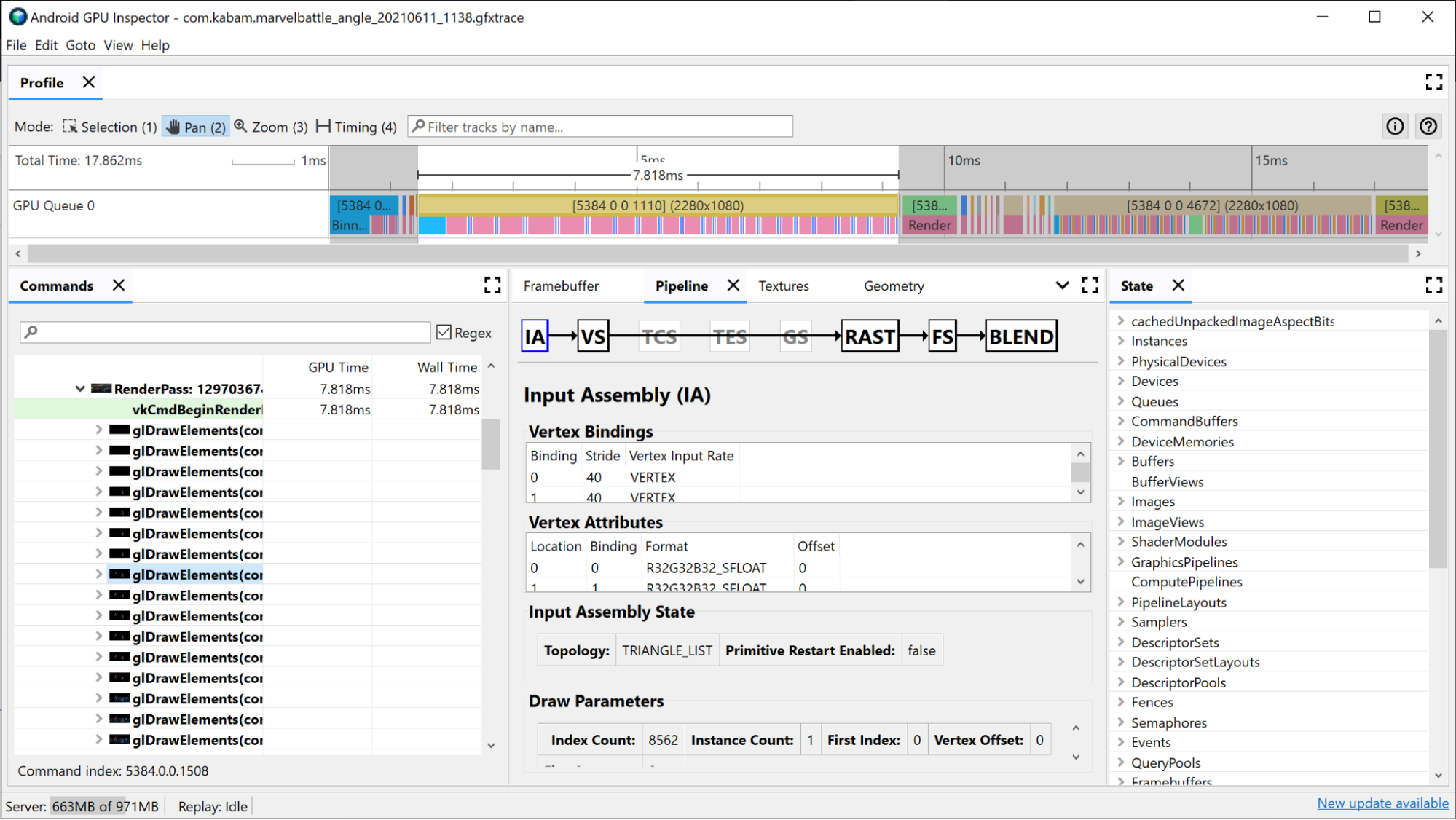
Ассемблер ввода предоставляет информацию о том, как данные вершин были привязаны к этому отрисовке. Это хорошая область для изучения, если вы заметили, что биннинг занимает большую часть времени вашего прохода рендеринга; здесь вы можете получить информацию о формате вершин, количестве нарисованных вершин и о том, как вершины располагаются в памяти. Дополнительные сведения об этом см. в разделе Анализ форматов вершин .
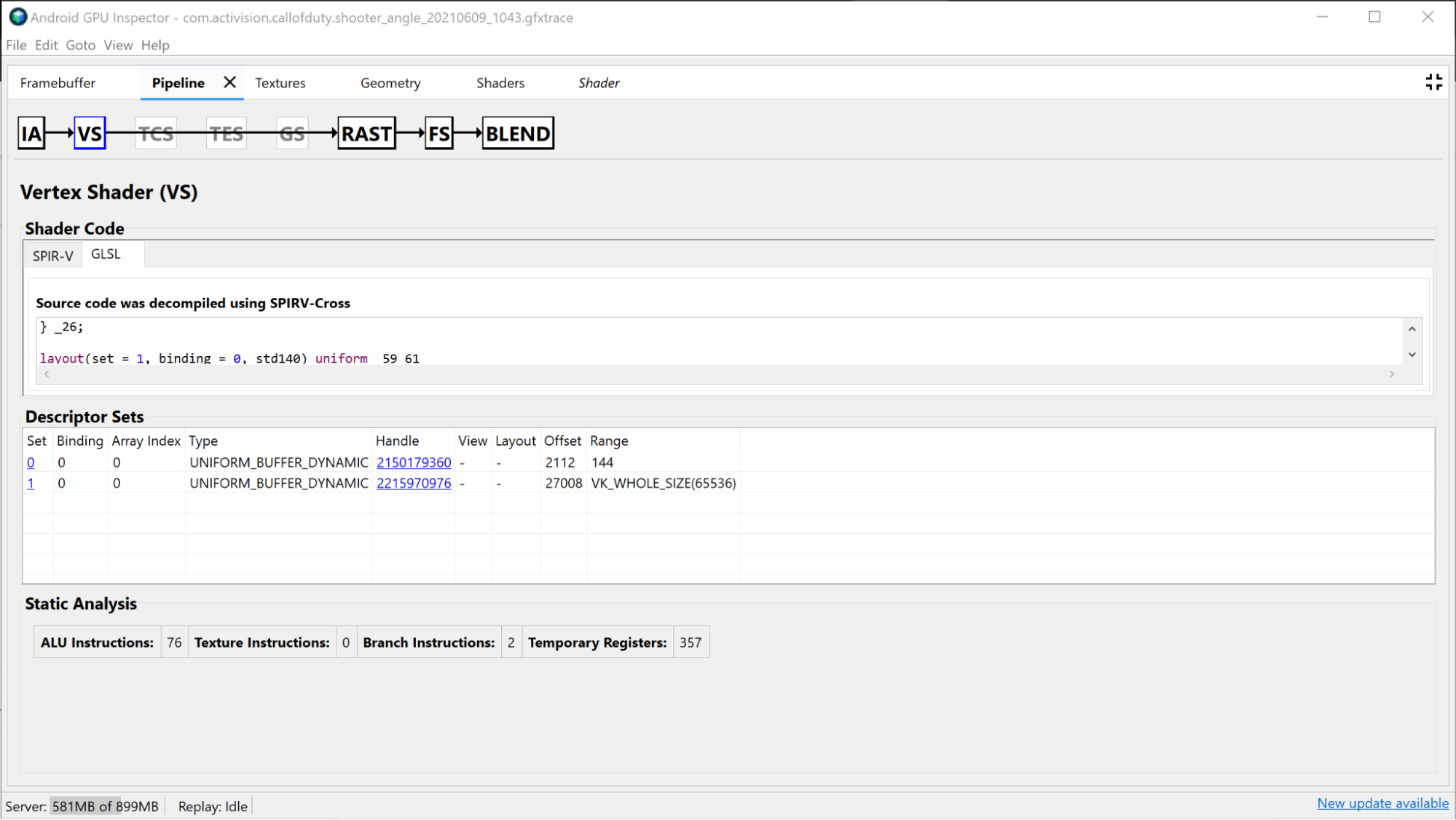
В разделе «Вершинный шейдер» представлена информация о вершинном шейдере, который вы использовали во время этого отрисовки, а также он может быть хорошим местом для проверки того, было ли биннинг обнаружено как проблема. Вы можете просмотреть SPIR-V и декомпилированный GLSL используемого шейдера, а также изучить связанные универсальные буферы для этого вызова. Дополнительные сведения см. в разделе Анализ производительности шейдеров .
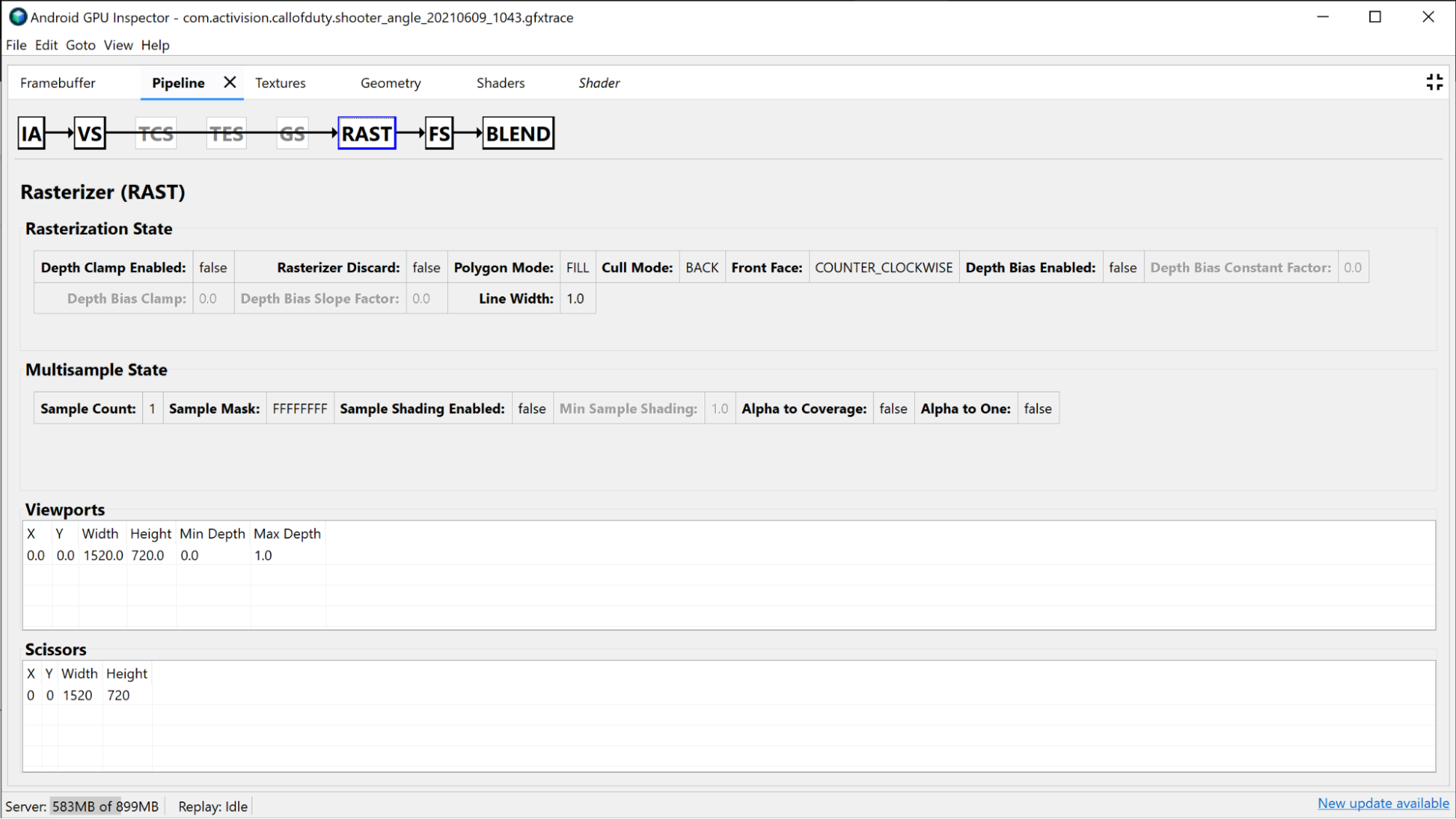
В разделе «Растеризатор» отображается информация о настройке конвейера с более фиксированными функциями, и его можно использовать в целях отладки состояний с фиксированными функциями, таких как область просмотра, ножницы, состояние глубины и режим многоугольника.
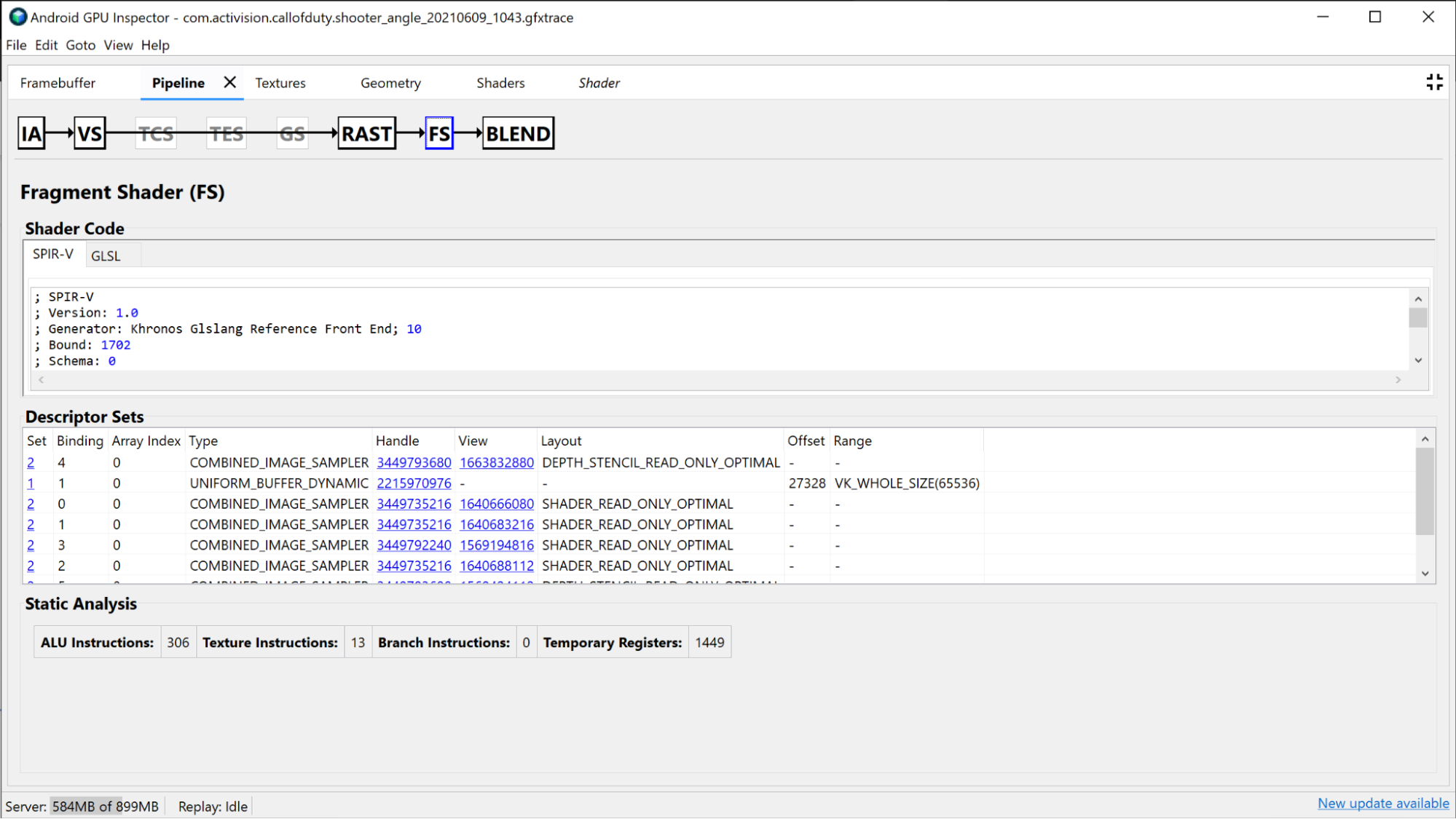
В разделе «Фрагментный шейдер» содержится много той же информации, что и в разделе «Вершинный шейдер» , но только для фрагментного шейдера . В этом случае вы действительно можете увидеть, какие текстуры привязываются, и изучить их, щелкнув маркер.
Меньший рендер прошел расследование
Еще один критерий, который вы можете использовать для повышения производительности вашего графического процессора, — это просмотр групп небольших проходов рендеринга. В общем, вы хотите максимально минимизировать количество проходов рендеринга, поскольку графическому процессору требуется время для обновления состояния от одного прохода рендеринга к другому. Эти меньшие проходы рендеринга обычно используются для создания карт теней, применения размытия по Гауссу, оценки яркости, эффектов постобработки или рендеринга пользовательского интерфейса. Некоторые из них потенциально можно объединить в один проход рендеринга или даже полностью исключить, если они не влияют на общее изображение настолько, чтобы оправдать затраты.