
يتيح لك أداة تحليل إطارات AGI إمكانية فحص أدوات التظليل من خلال تحديد استدعاء رسم من إحدى بطاقات العرض التي نقدمها، والانتقال إما إلى قسم Vertex Shader أو قسم Fragment Shader من لوحة Pipeline.
يمكنك الاطّلاع هنا على إحصاءات مفيدة تستند إلى التحليل الثابت لرمز أداة التظليل، بالإضافة إلى مجموعة التمثيل المتوسط المتنقل العادي (SPIR-V) التي تم تجميع GLSL إليها. هناك أيضًا علامة تبويب لعرض تمثيل GLSL الأصلي (مع أسماء تم إنشاؤها بواسطة برنامج التحويل للمتغيرات والدوال وغير ذلك) والتي تم فك تجميعها باستخدام SPIR-V Cross، لتوفير سياق إضافي لـ SPIR-V.
التحليل الثابت
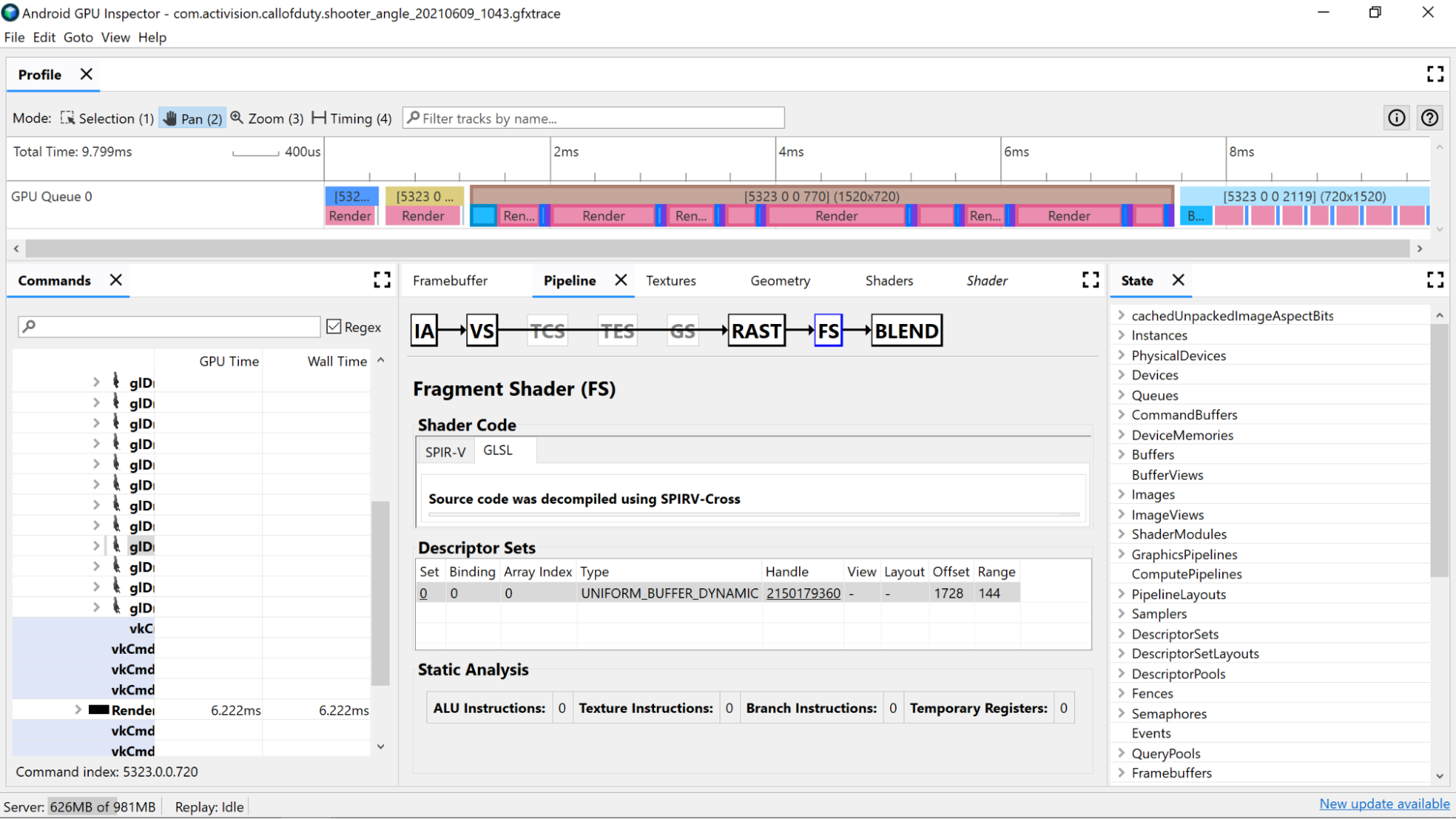
يمكنك استخدام عدّادات التحليل الثابتة لعرض العمليات المنخفضة المستوى في أداة التظليل.
تعليمات ALU: يوضّح هذا العدد عدد عمليات ALU (عمليات الجمع والضرب والقسمة وغيرها) التي يتم تنفيذها داخل التظليل، وهو يبيّن مدى تعقيد أداة التظليل. حاوِل تقليل هذه القيمة.
يمكن أن تساعد إعادة هيكلة عمليات الحوسبة الشائعة أو تبسيط العمليات الحسابية التي تتم في التظليل في تقليل عدد التعليمات اللازمة.
تعليمات الزخرفة: يعرض هذا العدد عدد مرات ظهور عيّنات من نسيج المستخدم في أداة التظليل.
- قد يكون أخذ عيّنات من الزخارف مكلفًا اعتمادًا على نوع الزخارف التي يتم أخذ عينات منها، لذا يمكن أن يوفر المقارنة بين رمز أداة التظليل والزخارف المرتبطة في القسم مجموعات الوصف مزيدًا من المعلومات عن أنواع الزخارف المستخدمة.
- تجنب الوصول العشوائي عند أخذ عينات من الزخارف، لأن هذا السلوك ليس مثاليًا للتخزين المؤقت للزخارف.
تعليمات الفرع: يعرض هذا العدد عدد عمليات الفروع في أداة التظليل. يُعد تقليل التشعّب أمرًا مثاليًا على المعالجات المتوازية مثل وحدة معالجة الرسومات، كما يمكن أن يساعد المحول البرمجي في العثور على تحسينات إضافية:
- استخدِم دوال مثل
minوmaxوclampلتجنب الاقتطاع من القيم الرقمية. - اختبار تكلفة الحساب على التشعّب. نظرًا لتنفيذ كلا مساري الفرع في العديد من البنى، هناك العديد من السيناريوهات التي يكون فيها إجراء العمليات الحسابية دائمًا أسرع من تخطي العملية الحسابية ذات الفرع.
- استخدِم دوال مثل
السجلات المؤقتة: هي سجلات سريعة وبسيطة تُستخدَم للاحتفاظ بنتائج العمليات الوسيطة التي تتطلبها العمليات الحسابية على وحدة معالجة الرسومات. هناك حد أقصى لعدد السجلات المتاحة للعمليات الحسابية قبل أن تنتقل وحدة معالجة الرسومات إلى استخدام ذاكرة أخرى خارج النواة لتخزين القيم الوسيطة، ما يقلل من الأداء العام. (يختلف هذا الحد بناءً على طراز وحدة معالجة الرسومات.)
قد يكون عدد السجلات المؤقتة المستخدمة أكبر من المتوقع في حالة تنفيذ المحول البرمجي لنقطة التظليل لعمليات مثل حل التكرارات الحلقية، لذا من الجيد إجراء تداخل بين هذه القيمة وSPIR-V أو فك تشفير GLSL لتعرف ما تفعله التعليمات البرمجية.
تحليل رموز التظليل
تحقَّق من رمز أداة التظليل الذي تم فك تشفيره لتحديد ما إذا كانت هناك أي تحسينات محتملة.
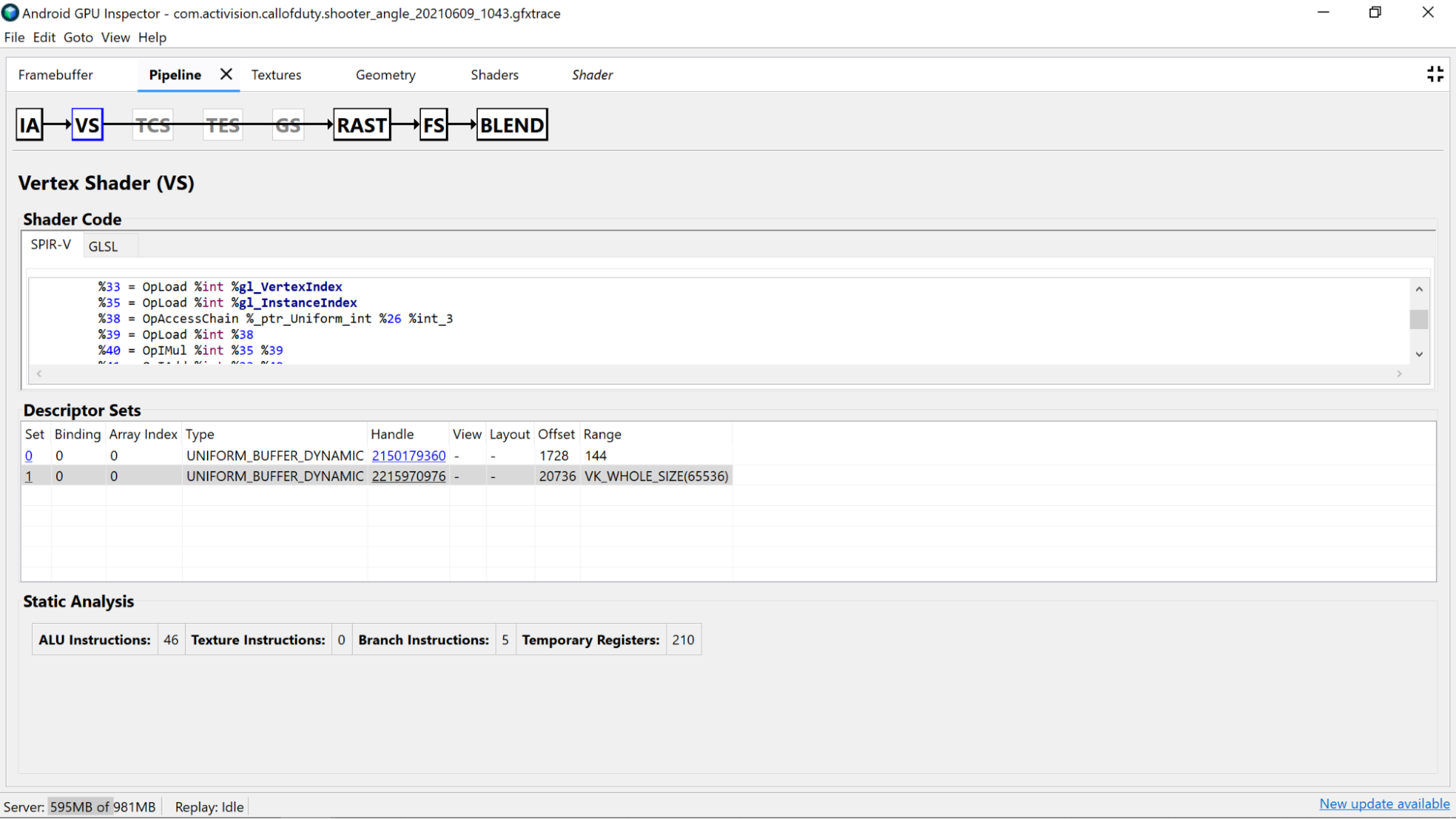
- الدقة: يمكن أن تؤثر دقة متغيرات أداة التظليل في أداء وحدة معالجة الرسومات في تطبيقك.
- حاوِل استخدام معدِّل الدقة
mediumpفي المتغيرات حيثما أمكن ذلك، لأن متغيّرات الدقة المتوسطة (mediump) تكون عادةً أسرع وأكثر كفاءة من حيث استهلاك الطاقة من متغيّرات الدقة الكاملة (highp) 32 بت. - إذا لم تظهر لك أي مؤهلات دقة في أداة التظليل في نماذج
التظليل أو لم تظهر في أعلى أداة التظليل مع
precision precision-qualifier type، يتم ضبط الإعدادات التلقائية على الدقة الكاملة (highp). احرص على الاطّلاع على التعريفات المتغيّرة أيضًا. - ويُفضّل أيضًا استخدام
mediumpلإخراج أداة تظليل الرأس للأسباب نفسها المذكورة أعلاه، ولتحقيق ذلك فائدة أيضًا في تقليل معدّل نقل البيانات للذاكرة وربما استخدام التسجيل المؤقت اللازم لإتمام الاستيفاء.
- حاوِل استخدام معدِّل الدقة
- الموارد الاحتياطية المنتظمة: حاوِل أن يظل حجم الموارد الاحتياطية المنتظمة صغيرًا قدر الإمكان (مع الحفاظ على قواعد المحاذاة). ويساعد ذلك في جعل العمليات الحسابية أكثر توافقًا مع التخزين المؤقت وقد يسمح بترقية البيانات الموحّدة إلى تسجيلات أساسية أسرع.
إزالة مخرجات Vertex Shader غير المستخدمة: في حال كانت مخرجات أداة تظليل الرأس غير مستخدَمة في أداة تظليل الأجزاء، يمكنك إزالتها من أداة التظليل لتوفير معدّل نقل بيانات الذاكرة والسجلات المؤقتة.
نقل العملية الحسابية من Fragment Shader إلى Vertex Shader: إذا كان رمز تظليل الجزء يُجري عمليات حسابية مستقلة عن الحالة المتعلقة بالجزء المظلّل (أو يمكن إدخاله بشكل صحيح)، فإن نقله إلى أداة تظليل الرأس يكون مثاليًا. ويرجع السبب في ذلك إلى أنه في معظم التطبيقات، يتم تشغيل أداة تظليل الأجزاء بشكل أقل تكرارًا مقارنةً بأداة تظليل الأجزاء.