
AGI Frame Profiler, oluşturma geçişlerimizin birinden bir çizim çağrısı seçip Vertex Shader (Vertex Gölgelendirici) bölümünden ya da Pipeline (Pipeline) bölmesinin Fragment Shader (Parça Gölgelendirici) bölümünden yararlanarak gölgelendiricilerinizi araştırmanıza olanak tanır.
Burada, gölgelendirici kodunun statik analizinden ve GLSL'mizin derlendiği Standart Taşınabilir Ara Gösterim (SPIR-V) derlemesinden elde edilen yararlı istatistikleri bulabilirsiniz. SPIR-V için ek bağlam sağlamak amacıyla SPIR-V Cross ile ayrıştırılan orijinal GLSL gösterimini (değişkenler, işlevler ve daha fazlası için derleyici tarafından oluşturulan adlarla) görüntülemek için de bir sekme bulunur.
Statik analiz
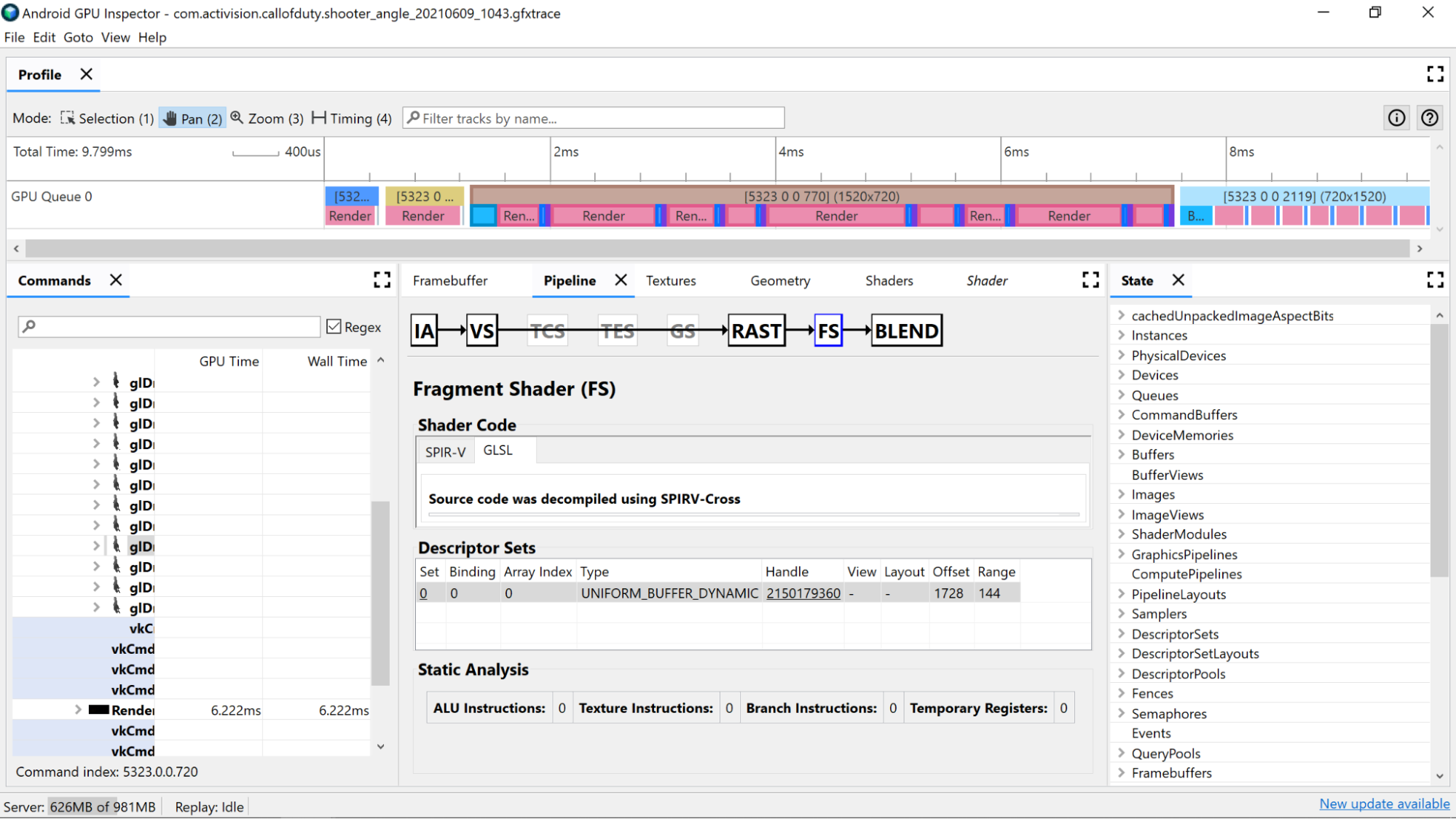
Gölgelendiricideki alt düzey işlemleri görüntülemek için statik analiz sayaçları kullanın.
ALU Talimatları: Bu sayı, gölgelendirici içinde yürütülmekte olan ALU işlemlerinin (ekleme, çarpma, bölme vb.) sayısını gösterir ve gölgelendiricinin ne kadar karmaşık olduğunu iyi bir şekilde gösterir. Bu değeri en aza indirmeye çalışın.
Yaygın hesaplamaları yeniden düzenlemek veya gölgelendiricide yapılan hesaplamaları basitleştirmek, gereken talimat sayısını azaltmaya yardımcı olabilir.
Doku Talimatları: Bu sayı, gölgelendiricide doku örneğinin kaç kez gerçekleştiğini gösterir.
- Doku örneklemesi, örneklenen dokuların türüne bağlı olarak pahalı olabilir. Bu nedenle, gölgelendirici kodu ile Açıklayıcı Kümeleri bölümündeki sınırlanmış dokulara çapraz referans alınması, kullanılan doku türleri hakkında daha fazla bilgi sağlayabilir.
- Doku önbelleğe alma için bu davranış ideal olmadığından, dokuları örnekleme sırasında rastgele erişimden kaçının.
Dal Talimatları: Bu sayı, gölgelendiricideki dal işlemlerinin sayısını gösterir. Dallandırmayı en aza indirmek, GPU gibi paralel işlemcilerde idealdir ve hatta derleyicinin ek optimizasyonlar bulmasına yardımcı olabilir:
- Sayısal değerleri kollara ayırma ihtiyacını ortadan kaldırmak için
min,maxveclampgibi işlevleri kullanın. - Kollara ayırma üzerinden hesaplama maliyetini test etme. Bir şubenin her iki yolu da birçok mimaride yürütüldüğünden her zaman hesaplamayı bir dal kullanarak atlamaktan daha hızlı olduğu birçok senaryo vardır.
- Sayısal değerleri kollara ayırma ihtiyacını ortadan kaldırmak için
Geçici Kayıtlar: GPU'daki hesaplamaların gerektirdiği ara işlemlerin sonuçlarını tutmak için kullanılan hızlı ve çekirdekli kayıtlardır. GPU'nun ara değerleri depolamak için diğer çekirdek dışı belleği kullanmanıza gerek kalmadan hesaplamalar için kullanılabilecek kayıt sayısının bir sınırı vardır. Bu da genel performansı düşürür. (Bu sınır, GPU modeline göre değişir.)
Gölgelendirici derleyicisi, döngüleri açma gibi işlemler gerçekleştiriyorsa kullanılan geçici kayıt sayısı beklenenden yüksek olabilir. Bu nedenle, kodun ne yaptığını görmek için bu değeri SPIR-V veya derlenmiş GLSL ile çapraz referans olarak yapmak iyi bir fikirdir.
Gölgelendirici kodu analizi
Olası iyileştirmelerin mümkün olup olmadığını belirlemek için derlenmiş gölgelendirici kodunun kendisini araştırın.
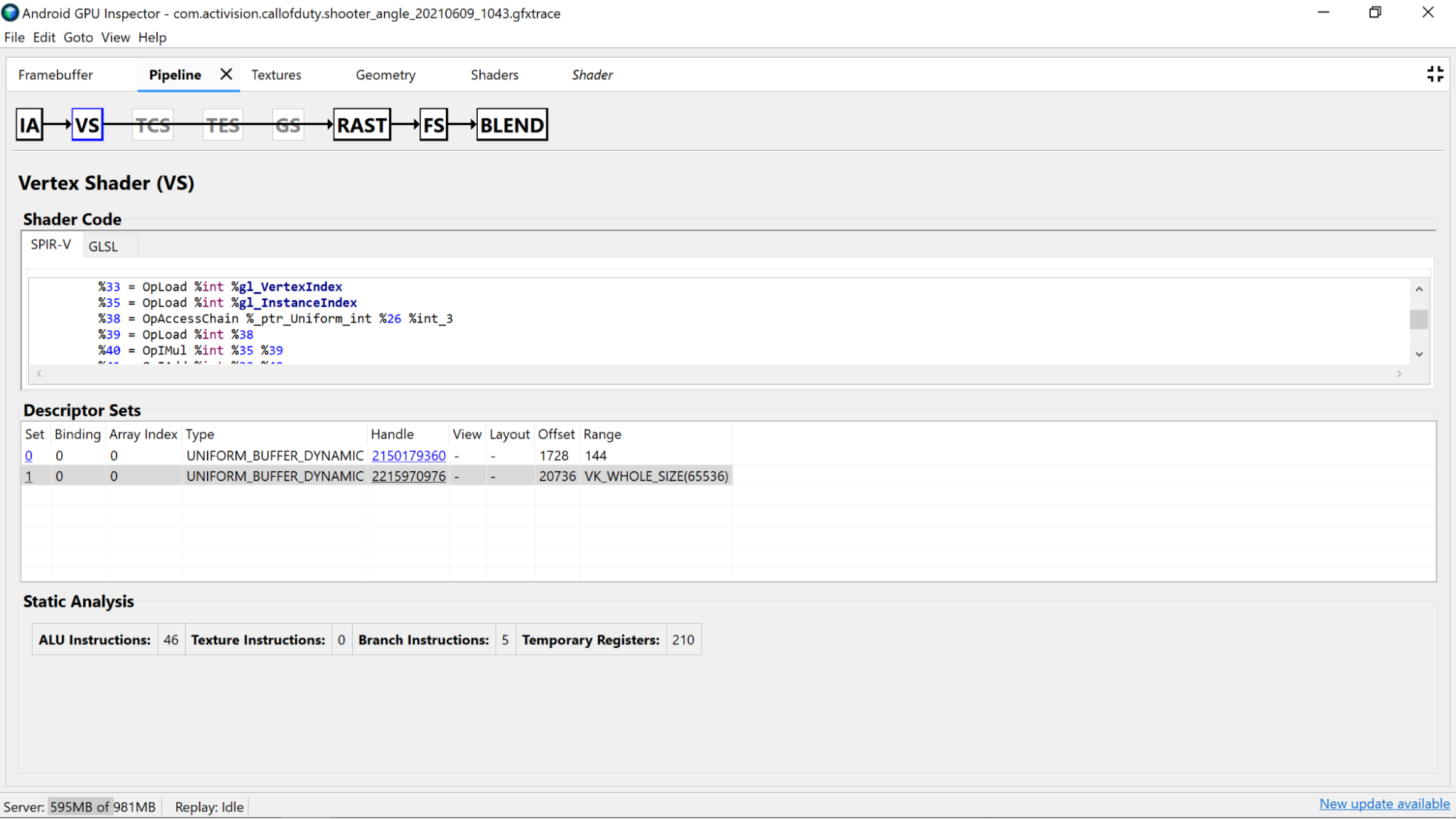
- Hassasiyet: Gölgelendirici değişkenlerinin hassasiyeti, uygulamanızın GPU performansını etkileyebilir.
- Orta hassasiyete sahip (
mediump) 16 bit değişkenler genellikle tam hassasiyete (highp) (highp) 32 bit değişkenlerden daha hızlı ve güç açısından daha verimli olduğundan, mümkün olduğunda değişkenlerdemediumphassasiyet değiştiricisini kullanmayı deneyin. - Değişken bildirimlerde gölgelendiricide veya gölgelendiricinin üst kısmında
precision precision-qualifier typeile birlikte herhangi bir hassasiyet niteleyici görmüyorsanız varsayılan olarak tam hassasiyet (highp) kullanılır. Değişken bildirimlerine de baktığınızdan emin olun. - Köşe gölgelendirici çıkışı için
mediumpkullanılması da yukarıda açıklanan nedenlerle tercih edilir. Bu ayrıca, interpolasyon yapmak için gereken bellek bant genişliğini ve geçici olarak kayıt kullanımını azaltma avantajına da sahiptir.
- Orta hassasiyete sahip (
- Tek Tip Arabellekler: Tek Tip Arabelleklerin boyutunu mümkün olduğunca küçük tutmaya çalışın (hizalama kurallarını koruyarak). Bu da hesaplamaları önbelleğe almayla daha uyumlu hale getirmeye yardımcı olur ve tek tip verilerin daha hızlı çekirdek üzerindeki kayıtlara tanıtılmasını sağlar.
Kullanılmayan Vertex Shader Çıkışlarını kaldırın: Köşe gölgelendirici çıkışlarının, parça gölgelendiricide kullanılmadığını fark ederseniz bellek bant genişliğinde yer açmak ve geçici kayıtlarda yer açmak için bunları gölgelendiriciden kaldırın.
İşlemi Parça Gölgelendirici'den Köşe Gölgelendirici'ye taşıma: Parça gölgelendirici kodu, gölgelenen parçaya özel durumdan bağımsız hesaplamalar yapıyorsa (veya düzgün bir şekilde interpolasyon yapabiliyorsa) tepe gölgelendiricisine taşımak en iyi seçenektir. Bunun nedeni, çoğu uygulamada tepe gölgelendiricisinin, parça gölgelendiriciye kıyasla çok daha az çalıştırılmasıdır.