
O AGI Frame Profiler permite investigar seus sombreadores selecionando uma chamada de desenho de uma das nossas transmissões de renderização e passando pela seção Vertex Shader ou Fragment Shader do painel Pipeline.
Aqui você encontrará estatísticas úteis provenientes da análise estática do código do sombreador, bem como do conjunto de Representação intermediária portátil padrão (SPIR-V, na sigla em inglês) em que nosso GLSL foi compilado. Há também uma guia para visualizar uma representação do GLSL original (com nomes gerados pelo compilador para variáveis, funções e mais) que foi descompilada com SPIR-V Cross, a fim de fornecer mais contexto para o SPIR-V.
Análise estática
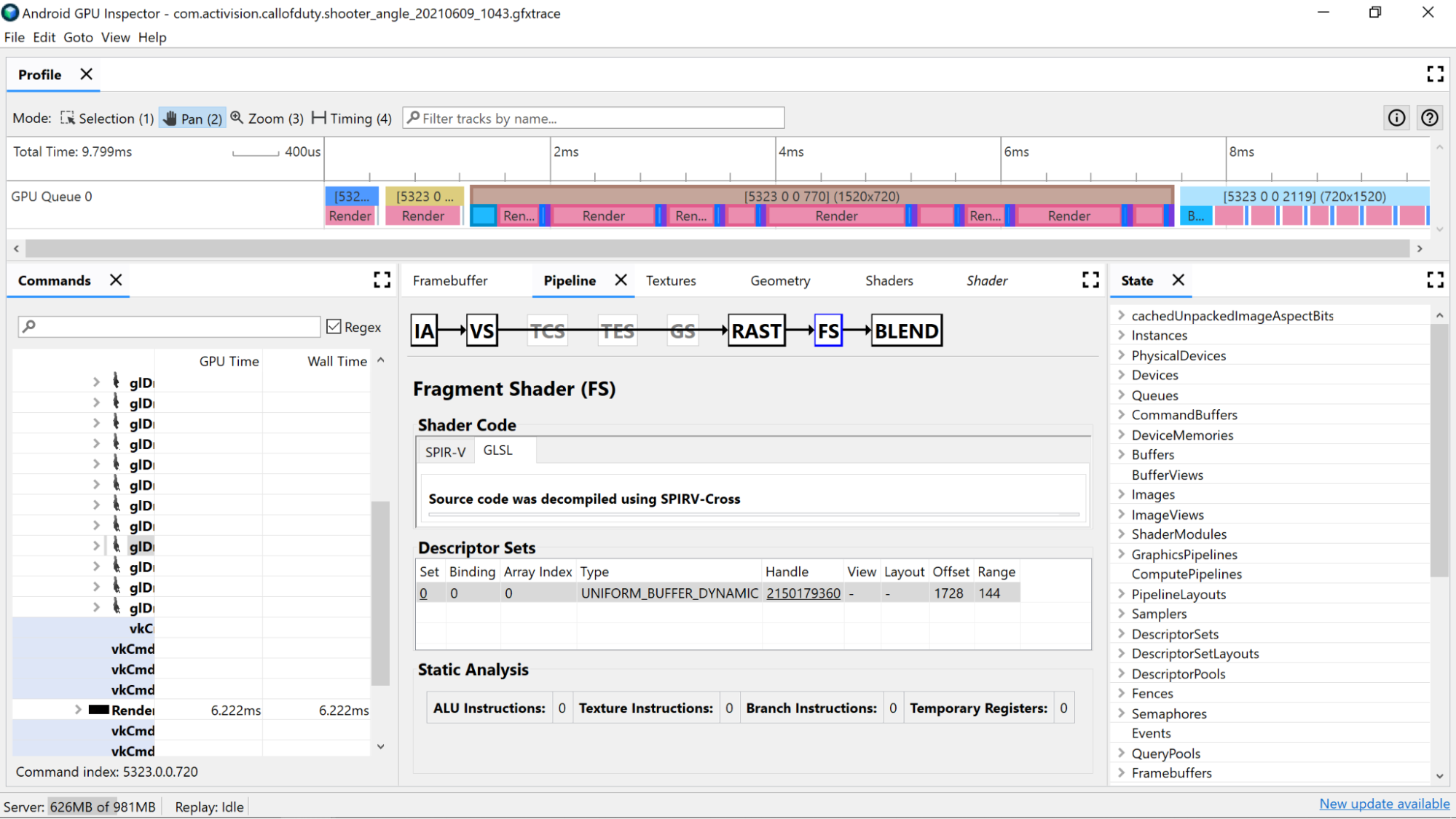
Usar contadores de análise estáticos para visualizar operações de baixo nível no sombreador.
Instruções de ALU: essa contagem mostra o número de operações de ALU (adição, multiplicação, divisão e muito mais) que estão sendo executadas no sombreador e é um bom indicador da complexidade do sombreador. Tente minimizar esse valor.
Refatorar cálculos comuns ou simplificar cálculos feitos no sombreador pode ajudar a reduzir o número de instruções necessárias.
Instruções de textura: essa contagem mostra o número de vezes que a amostragem de textura ocorre no sombreador.
- A amostragem de texturas pode ser cara dependendo do tipo de textura de amostra. Portanto, fazer a referência cruzada do código de sombreador com as texturas vinculadas encontradas na seção Conjuntos de descritores pode fornecer mais informações sobre os tipos de texturas usadas.
- Evite o acesso aleatório ao criar amostras de texturas, porque esse comportamento não é ideal para armazenamento em cache de textura.
Instruções para ramificação: essa contagem mostra o número de operações de ramificação no sombreador. Reduzir a ramificação é ideal em processadores paralelizados, como a GPU, e pode até ajudar o compilador a encontrar outras otimizações:
- Use funções como
min,maxeclamppara evitar a necessidade de ramificar valores numéricos. - Testar o custo de computação em ramificações. Como os dois caminhos de uma ramificação são executados em muitas arquiteturas, há muitos cenários em que sempre fazer o cálculo é mais rápido do que pular a computação com uma ramificação.
- Use funções como
Registros temporários: são registros rápidos no núcleo usados para manter os resultados de operações intermediárias exigidas por cálculos na GPU. Há um limite para o número de registros disponíveis para cálculos antes que a GPU precise passar a usar outra memória fora do núcleo para armazenar valores intermediários, reduzindo o desempenho geral. Esse limite varia de acordo com o modelo da GPU.
O número de registros temporários usados pode ser maior do que o esperado se o compilador de sombreador executar operações como desenrolar loops. Por isso, é bom cruzar esse valor com o SPIR-V ou o GLSL descompilado para ver o que o código está fazendo.
Análise de código do sombreador
Investigue o próprio código de sombreador descompilado para determinar se há melhorias em potencial.
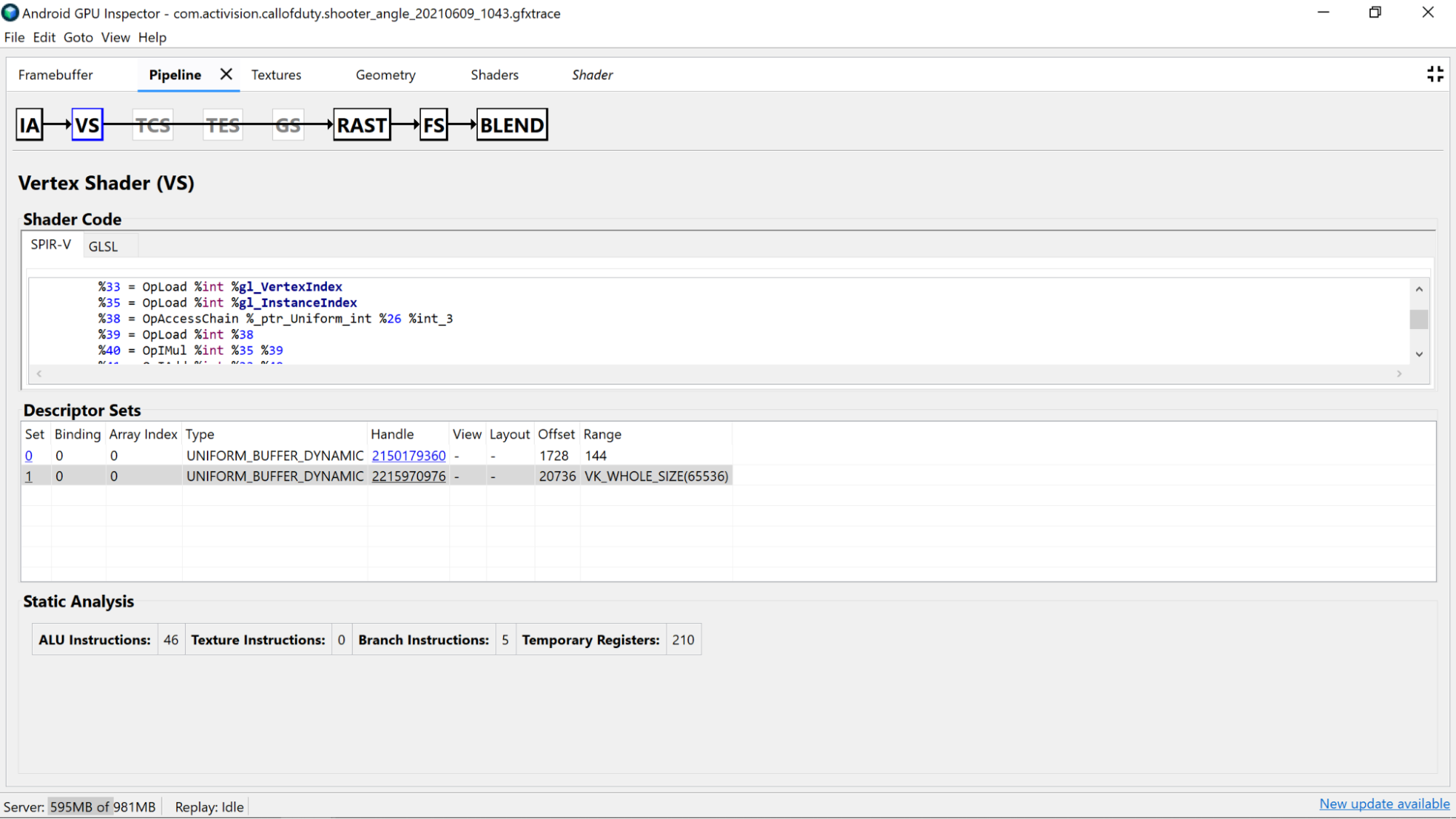
- Precisão: a precisão das variáveis do sombreador pode afetar o desempenho da
GPU do aplicativo.
- Tente usar o modificador de precisão
mediumpnas variáveis sempre que possível, já que as variáveis de 16 bits de precisão média (mediump) costumam ser mais rápidas e têm mais consumo de energia do que as variáveis de 32 bits de precisão total (highp). - Se você não encontrar qualificadores de precisão no sombreador em declarações
de variáveis ou na parte de cima do sombreador com um
precision precision-qualifier type, o padrão será a precisão total (highp). Confira também as declarações de variáveis. - O uso de
mediumppara a saída do sombreador de vértice também é preferível pelos mesmos motivos descritos acima, além de ter o benefício de reduzir a largura de banda de memória e o uso de registro possivelmente temporário necessário para fazer a interpolação.
- Tente usar o modificador de precisão
- Uniform Buffers: tente manter o tamanho dos Uniform Buffers o menor possível, mantendo as regras de alinhamento. Isso ajuda a tornar os cálculos mais compatíveis com o armazenamento em cache e permite que dados uniformes sejam promovidos a registros no núcleo mais rápidos.
Remova saídas do sombreador de vértices não usadas: se você achar que as saídas do sombreador de vértice não são usadas no sombreador de fragmento, remova-as do sombreador para liberar largura de banda da memória e registros temporários.
Mover a computação do sombreador de fragmentos para o sombreador de vértice: se o código do sombreador de fragmentos executa cálculos independentes do estado específico do fragmento que está sendo sombreado (ou pode ser interpolado corretamente), o ideal é movê-lo para o sombreador de vértice. O motivo disso é que, na maioria dos apps, o sombreador de vértice é executado com muito menos frequência em comparação com o sombreador de fragmentos.