
يمكنك تشخيص عدد قليل من مشكلات الأداء المحتملة المتعلقة بالرأس من خلال استخدام تحديد ملامح الإطار. استخدم جزء الأوامر لعرض جميع استدعاءات السحب التي تنفذها لعبتك في إطار معين وأعداد العناصر الأولية المرسومة لكل استدعاء للرسم. بهذه الطريقة، يمكن أن يكون لديك عدد تقريبي للعدد الإجمالي للرؤوس التي يتم إرسالها في إطار واحد.
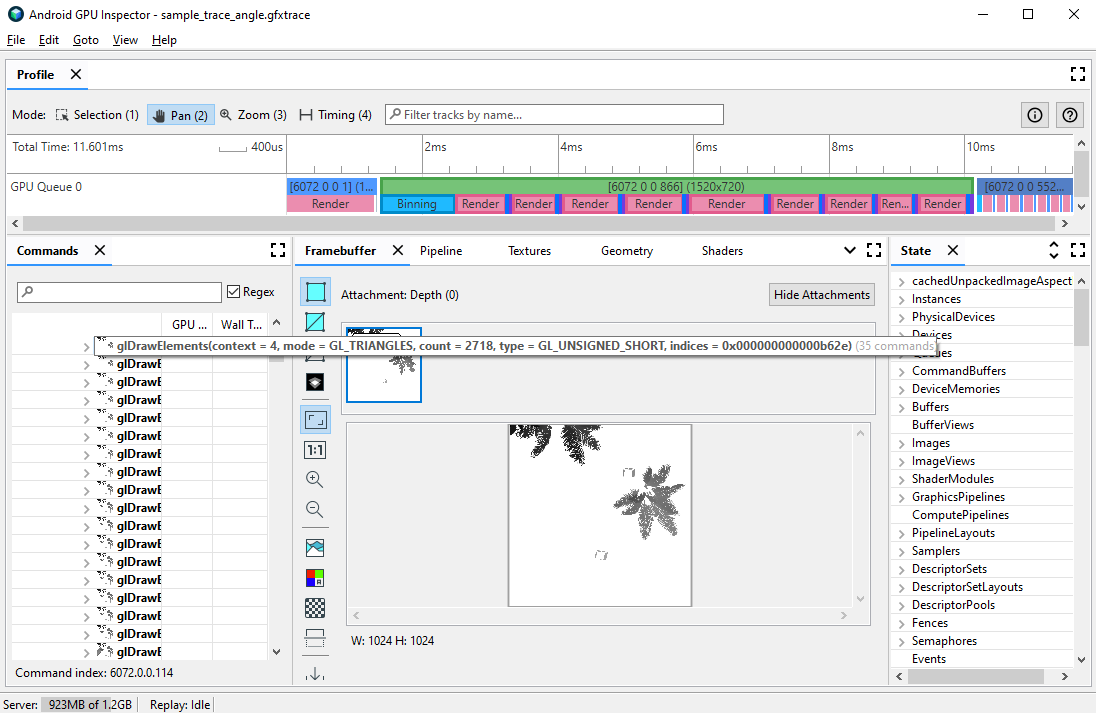
glDrawElements واحدة، يظهر 2,718 قاعدة مثلثية مرسومةضغط سمة Vertex
من المشاكل الشائعة التي قد تواجهها لعبتك هي متوسط حجم رأس المال الكبير. عند إرسال عدد كبير من الرؤوس ذات متوسط حجم رأس مرتفع، يتم عرض معدل نقل بيانات قراءة الرأس الكبير للذاكرة عند قراءتها بواسطة وحدة معالجة الرسومات.
لمراقبة تنسيق الرأس لاستدعاء رسم معين، أكمل الخطوات التالية:
اختَر إحدى استدعاءات الرسم التي تهمّك.
قد تكون استدعاء رسم نموذجي للمشهد، أو استدعاء رسم بعدد كبير من الرؤوس، أو طلب رسم لنموذج معقد لشخصيات، أو نوعًا آخر من استدعاءات الرسم.
انتقِل إلى جزء Pipeline، ثم انقر على IA لتجميع الإدخال. يحدد هذا تنسيق الرأس للرؤوس التي تأتي في وحدة معالجة الرسومات.
راقِب سلسلة من السمات وتنسيقاتها. على سبيل المثال،
R32G32B32_SFLOATهو عمود عائم يتضمّن 32 بت يتضمّن 3 مكونات.
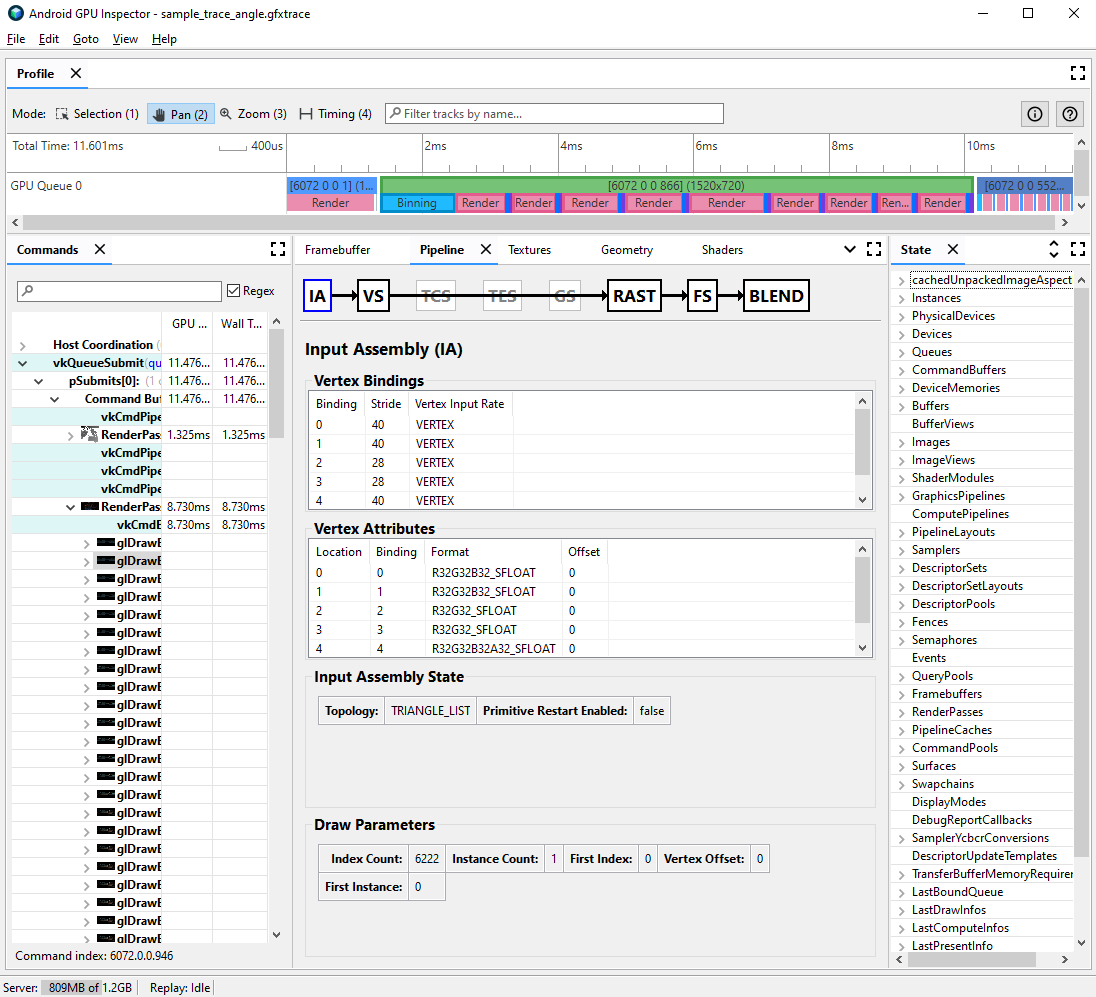
غالبًا ما يمكن ضغط سمات الرأس بأقل تخفيض في جودة النماذج المرسومة. وننصح على وجه الخصوص بما يلي:
- ضغط موضع الرأس إلى رموز عائمة بحجم 16 بت بنصف الدقة
- ضغط إحداثيات نسيج الأشعة فوق البنفسجية إلى ushorts بعدد صحيح 16 بت غير موقَّع
- ضغط مساحة المماس بترميز المتجهات العادية والمماسية والثنائية الطبيعة باستخدام الرباعيات
ويمكن أيضًا مراعاة السمات المتنوعة الأخرى للأنواع منخفضة الدقة على أساس كل حالة على حدة.
تقسيم بث Vertex
يمكنك أيضًا التحقّق ممّا إذا كانت ساحات مشاركات سمات الرأس مقسّمة بشكل مناسب. في بُنى العرض المتجانب، مثل وحدات معالجة الرسومات للأجهزة الجوّالة، يتم استخدام مواضع الرأس لأول مرة في تمريرة شاملة لإنشاء سلال من العناصر الأولية التي تمت معالجتها في كل مربّع. إذا كانت سمات الرأس متداخلة في مورد احتياطي واحد، تتم قراءة جميع بيانات الرأس في ذاكرة التخزين المؤقت للدمج، على الرغم من استخدام مواضع الرأس فقط.
لتقليل معدّل نقل بيانات الذاكرة المستخدمة بالرأس وتحسين كفاءة ذاكرة التخزين المؤقت، وبالتالي تقليل الوقت المستغرَق في تمرير البيانات، يجب تقسيم بيانات الرأس إلى مصدرَين منفصلَين، أحدهما لموضع الرأس والآخر لجميع سمات الرأس الأخرى.
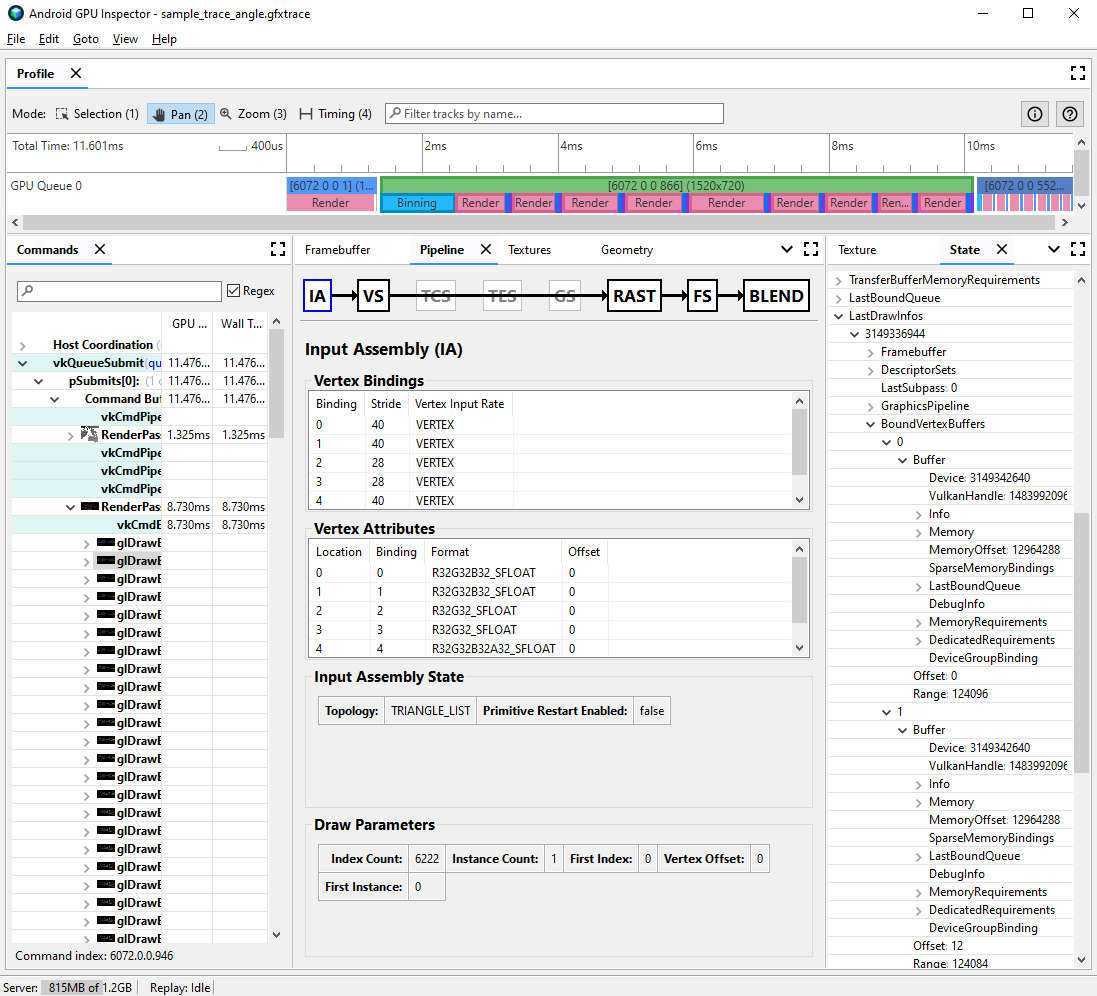
للتحقّق ممّا إذا كانت سمات الرأس مقسّمة بشكل مناسب:
اختر مكالمة الرسم التي تهمك، ولاحظ رقم مكالمة الرسم.
قد تكون استدعاء رسم نموذجي للمشهد، أو استدعاء رسم بعدد كبير من الرؤوس، أو طلب رسم لنموذج معقد لشخصيات، أو نوعًا آخر من استدعاءات الرسم.
انتقِل إلى جزء Pipeline، ثم انقر على IA لتجميع الإدخال. يحدد هذا تنسيق الرأس للرؤوس التي تأتي إلى وحدة معالجة الرسومات.
لاحِظ ارتباطات سمات الرأس، فقد تزداد عادةً هذه الروابط خطيًا (0، 1، 2، 3، إلخ)، ولكن هذا لا يحدث دائمًا. موضع الرأس هو عادةً سمة الرأس الأولى المدرجة.
في لوحة State (الولاية)، ابحث عن
LastDrawInfosووسِّع رقم طلب الرسم المطابق. بعد ذلك، قم بتوسيعBoundVertexBuffersلاستدعاء الرسم هذا.لاحظ الموارد الاحتياطية للرأس المحصورة أثناء استدعاء السحب المحدد، مع الفهارس التي تطابق ارتباطات سمة الرأس السابقة.
وسّع الروابط الخاصة بسمات رأس استدعاء الرسم، وقم بتوسيع الموارد الاحتياطية.
راقِب
VulkanHandleلمعرفة الموارد الاحتياطية التي تمثّل الذاكرة الأساسية التي تصدر منها البيانات الرأسية. وإذا كانت السمةVulkanHandleمختلفة، يعني ذلك أنّ السمات تنشأ من مخازن احتياطية أساسية مختلفة. إذا كانتVulkanHandleهي نفسها لكن عمليات الإزاحة كبيرة (على سبيل المثال، أكبر من 100)، قد تنشأ السمات من مخازن فرعية مختلفة، ولكن هذا يتطلّب مزيدًا من التحقيق.
للحصول على مزيد من التفاصيل حول تقسيم ساحة مشاركات الرأس وكيفية حلها على محركات الألعاب المختلفة، يمكنك الاطلاع على مشاركة المدونة حول هذا الموضوع.