
شما ممکن است چند مشکل احتمالی عملکرد مرتبط با راس را از طریق استفاده از پروفایل قاب تشخیص دهید. برای مشاهده تمام فراخوان های قرعه کشی که بازی شما در یک فریم معین انجام می دهد و تعداد موارد اولیه ترسیم شده در هر تماس قرعه کشی، از پنجره فرمان ها استفاده کنید. این می تواند تقریبی از تعداد کلی رئوس ارسال شده در یک فریم را ارائه دهد.
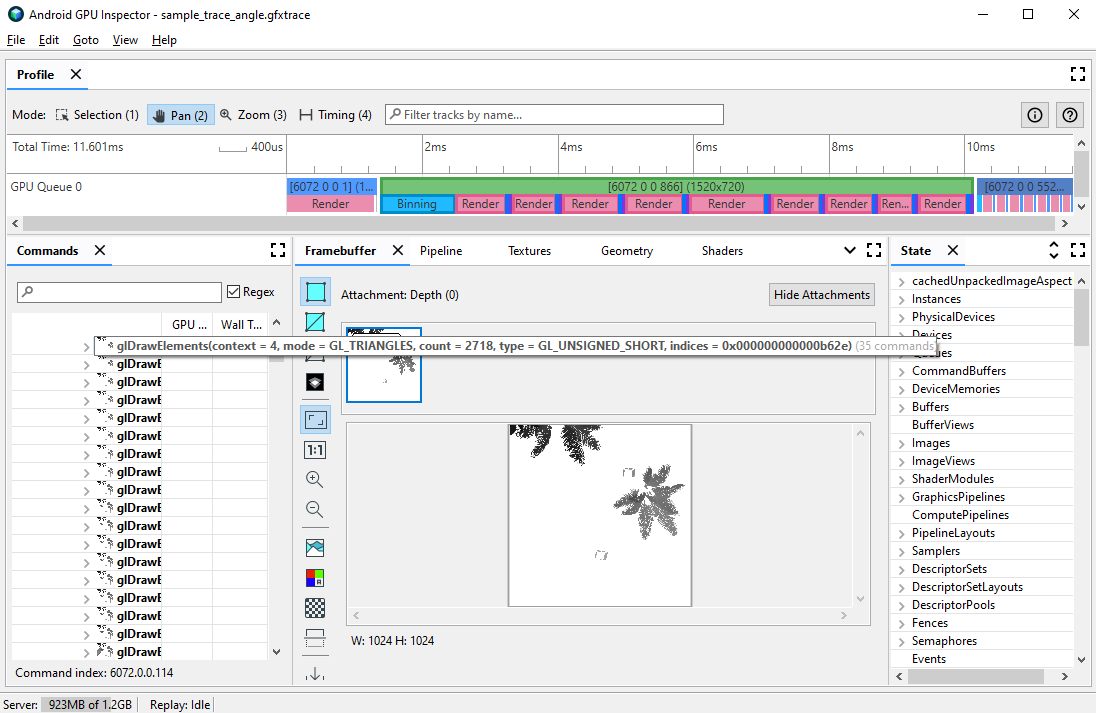
glDrawElements ، که 2718 مثلث اولیه ترسیم شده را نشان می دهد. فشرده سازی ویژگی Vertex
یکی از مشکلات رایجی که بازی شما ممکن است با آن روبرو شود، اندازه متوسط بزرگ راس است. تعداد زیادی از رئوس ارسال شده با اندازه متوسط بالای راس منجر به پهنای باند خواندن حافظه رئوس زیادی در هنگام خواندن توسط GPU می شود.
برای مشاهده فرمت راس برای یک فراخوانی مشخص، مراحل زیر را انجام دهید:
یک فراخوان مورد علاقه قرعه کشی را انتخاب کنید.
این می تواند یک فراخوان ترسیم معمولی برای صحنه، یک فراخوانی قرعه کشی با تعداد زیادی رئوس، یک فراخوان ترسیم برای یک مدل کاراکتر پیچیده، یا نوع دیگری از فراخوانی قرعه کشی باشد.
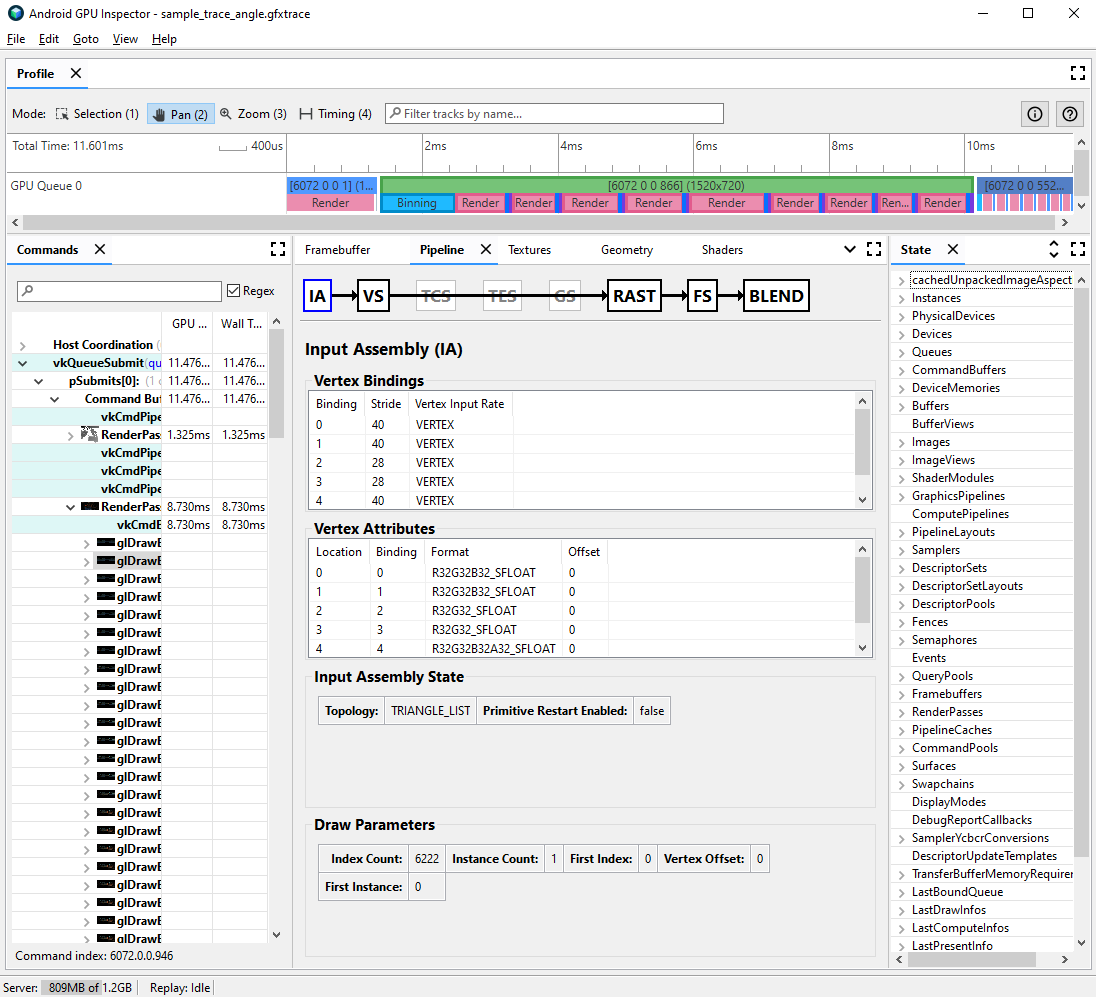
به صفحه Pipeline بروید و برای اسمبلی ورودی روی IA کلیک کنید. این فرمت راس را برای رئوس هایی که به GPU می آیند تعریف می کند.
یک سری صفات و قالب آنها را رعایت کنید. به عنوان مثال،
R32G32B32_SFLOATیک شناور 3 جزء 32 بیتی است.
اغلب، ویژگی های راس را می توان با حداقل کاهش در کیفیت مدل های ترسیم شده فشرده کرد. به ویژه توصیه می کنیم:
- فشرده سازی موقعیت راس به شناورهای نیمه دقیق 16 بیتی
- فشرده سازی بافت UV مختصات به یوشورت های اعداد صحیح بدون علامت 16 بیتی
- فشرده سازی فضای مماس با رمزگذاری بردارهای عادی، مماس و دونرمال با استفاده از کواترنیون ها
سایر ویژگی های متفرقه نیز ممکن است برای انواع با دقت کمتر به صورت موردی در نظر گرفته شوند.
تقسیم جریان راس
همچنین میتوانید بررسی کنید که آیا جریانهای ویژگی راس بهطور مناسب تقسیم شدهاند یا خیر. در معماریهای رندر کاشیشده مانند پردازندههای گرافیکی موبایل، موقعیتهای راس ابتدا در یک گذرگاه برای ایجاد سطلهای اولیه پردازششده در هر کاشی استفاده میشوند. اگر ویژگیهای راس در یک بافر منفرد قرار بگیرند، تمام دادههای راس برای binning در حافظه پنهان خوانده میشوند، حتی اگر فقط از موقعیتهای راس استفاده شود.
برای کاهش پهنای باند حافظه خوانده شده از راس و بهبود کارایی حافظه نهان، و در نتیجه کاهش زمان صرف شده در عبور باینینگ، دادههای راس باید به دو جریان جداگانه تقسیم شوند، یکی برای موقعیتهای راس، و دیگری برای تمام ویژگیهای راس دیگر.
برای بررسی اینکه آیا ویژگی های راس به درستی تقسیم شده اند یا خیر:
یک تماس قرعه کشی مورد علاقه را انتخاب کنید و شماره تماس قرعه کشی را یادداشت کنید.
این می تواند یک فراخوان ترسیم معمولی برای صحنه، یک فراخوانی قرعه کشی با تعداد زیادی رئوس، یک فراخوان ترسیم برای یک مدل کاراکتر پیچیده، یا نوع دیگری از فراخوانی قرعه کشی باشد.
به صفحه Pipeline بروید و برای اسمبلی ورودی روی IA کلیک کنید. این فرمت راس را برای رئوس هایی که به GPU می آیند تعریف می کند.
اتصالات صفات راس خود را مشاهده کنید. معمولاً اینها ممکن است به صورت خطی افزایش یابد (0، 1، 2، 3، و غیره)، اما همیشه اینطور نیست. موقعیت راس معمولاً اولین ویژگی رأس لیست شده است.
در قسمت State ،
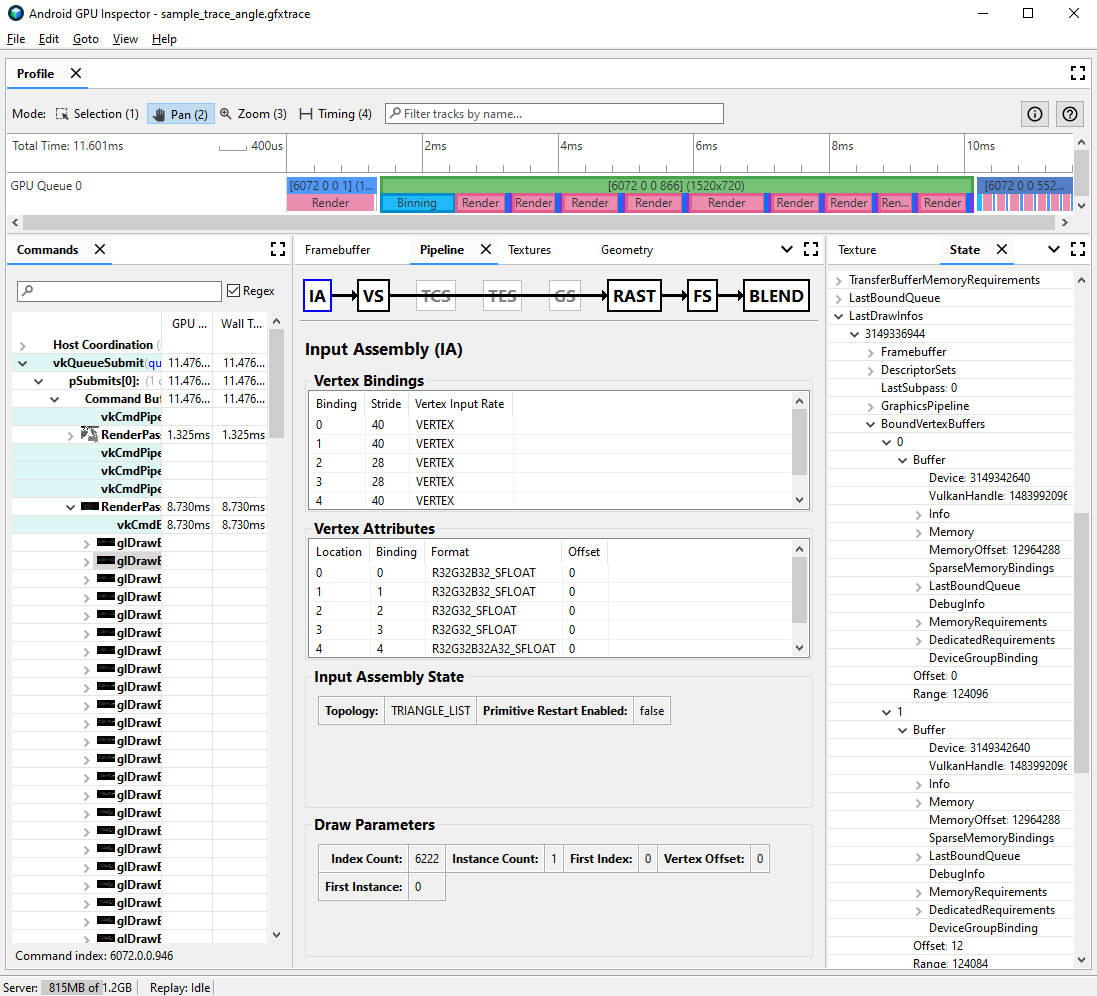
LastDrawInfosرا پیدا کنید و شماره تماس قرعه کشی منطبق را گسترش دهید. سپس،BoundVertexBuffersرا برای این فراخوانی قرعه کشی گسترش دهید.بافرهای رأس محدود شده در طول فراخوانی قرعه کشی داده شده را با شاخص هایی که با اتصالات ویژگی راس قبلی مطابقت دارند، مشاهده کنید.
اتصالات را برای ویژگی های راس فراخوانی قرعه کشی خود گسترش دهید و بافرها را گسترش دهید.
VulkanHandleرا برای بافرها مشاهده کنید، که نشاندهنده حافظه زیربنایی است که دادههای راس از آن منبع میشوند. اگر s هایVulkanHandleمتفاوت باشند، این بدان معناست که ویژگی ها از بافرهای زیرین مختلف نشات می گیرند. اگر s هایVulkanHandleیکسان باشند اما افست ها بزرگ باشند (مثلاً بزرگتر از 100)، ویژگی ها ممکن است همچنان از بافرهای فرعی متفاوتی منشأ بگیرند، اما این نیاز به بررسی بیشتر دارد.
برای جزئیات بیشتر در مورد تقسیم جریان ورتکس و نحوه حل آن در موتورهای بازی مختلف، به پست وبلاگ ما در مورد این موضوع مراجعه کنید.