
您可以通过使用帧性能分析来诊断一些可能与顶点相关的性能问题。您可以使用 Commands 窗格查看游戏在给定帧中执行的所有绘制调用,以及每次绘制调用绘制的基元计数。它可以估算在单个帧中提交的顶点总数。
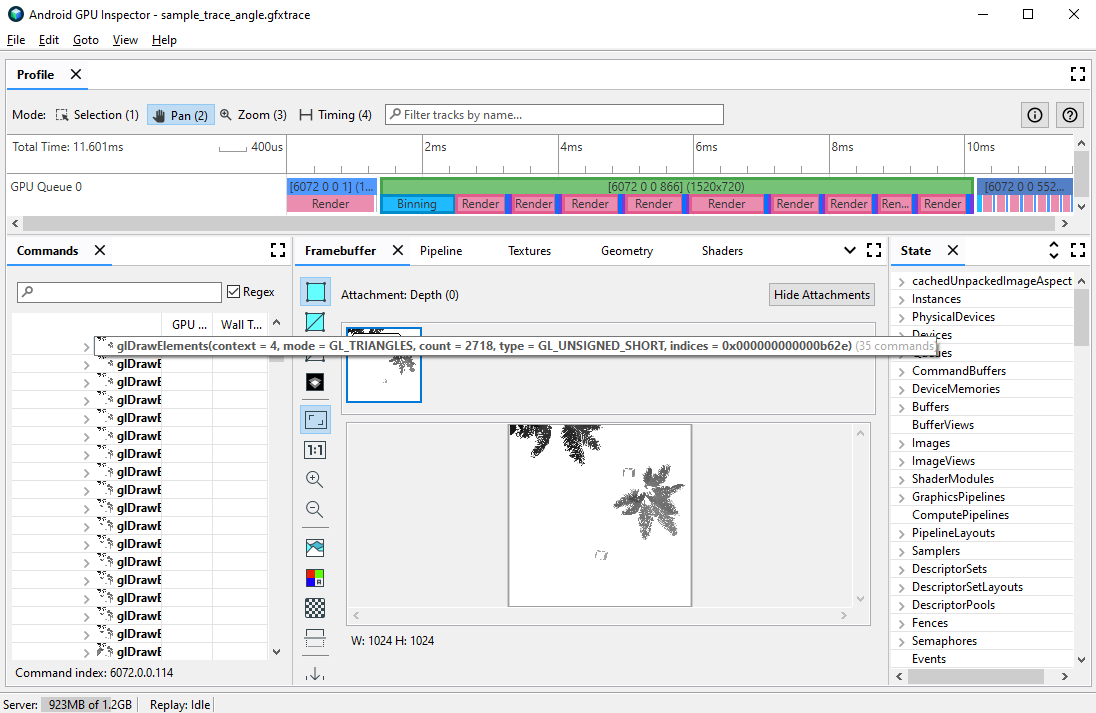
glDrawElements 调用的帧性能分析视图,显示已绘制 2,718 个三角形基元顶点属性压缩
您的游戏可能会面临的一个常见问题是平均顶点过大。如果提交的大量顶点具有较高的平均顶点大小,会导致 GPU 在读取时占用较大的顶点内存读取带宽。
如需观察给定绘制调用的顶点格式,请完成以下步骤:
选择感兴趣的绘制调用。
该调用可以是场景的典型绘制调用、具有大量顶点的绘制调用、复杂角色模型的绘制调用,也可以是其他类型的绘制调用。
前往 Pipeline 窗格,然后点击 IA 以进行输入组装。 这定义了进入 GPU 的顶点的顶点格式。
观察一系列属性及其格式;例如,
R32G32B32_SFLOAT是一个 3 分量 32 位有符号浮点数。
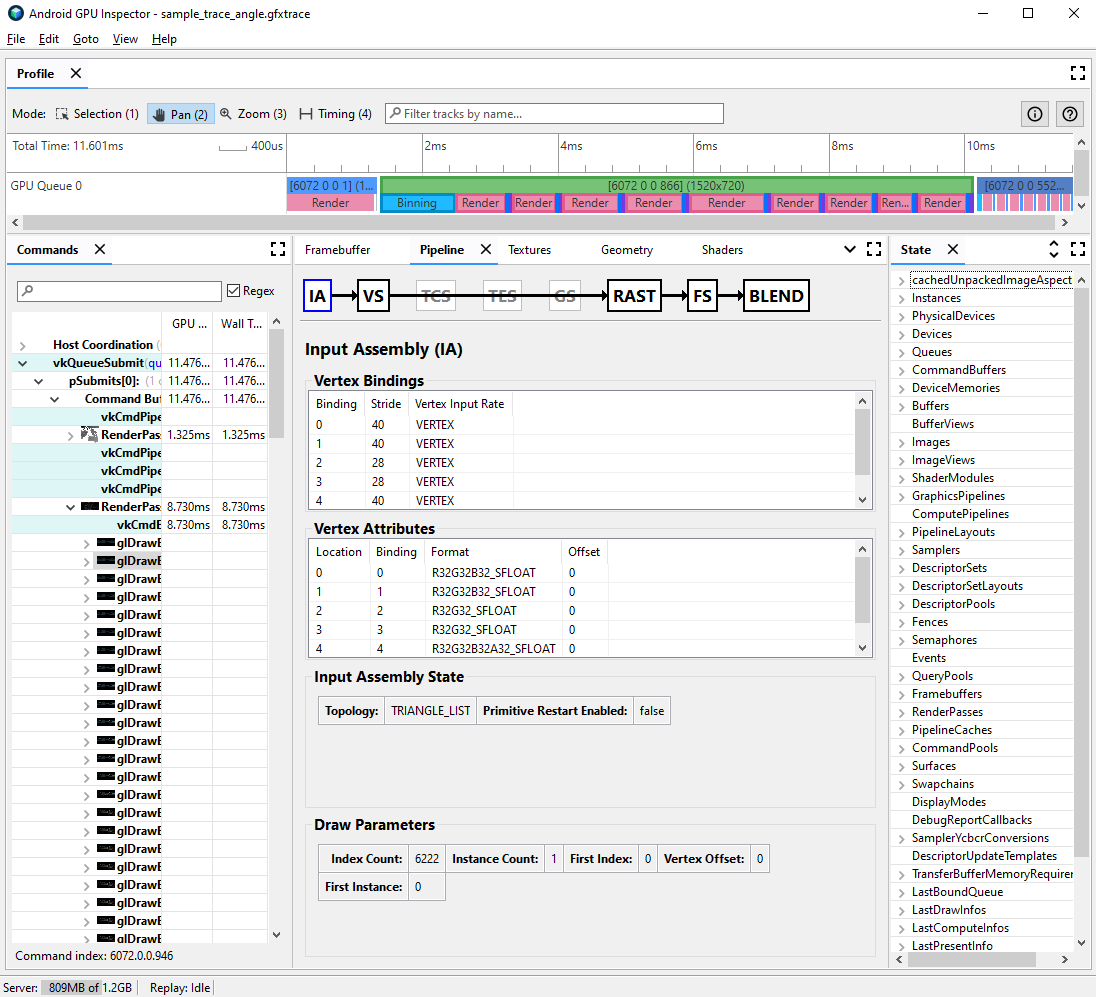
通常,可以压缩顶点属性,同时最大限度地降低所绘制模型的质量。具体来说,我们建议您:
- 将顶点位置压缩为半精度 16 位浮点数
- 将 UV 纹理坐标压缩为 16 位无符号整数 ushort
- 通过使用四元数对法线、正切和双法线向量进行编码来压缩切线空间
对于低精度类型,可能还要根据具体情况考虑其他属性。
顶点流拆分
您还可以调查顶点属性流是否进行了适当的拆分。在移动 GPU 等平铺渲染架构中,首先在分箱传递中使用顶点位置,以创建在每个图块中处理的基元的分箱。如果顶点属性交错到单个缓冲区中,则所有顶点数据都会被读入缓存以进行分箱,即使只使用了顶点位置也是如此。
为了减少顶点读取内存带宽并提高缓存效率,从而缩短分箱传递所花费的时间,顶点数据应拆分为两个单独的流,一个用于顶点位置,另一个用于所有其他顶点属性。
如需调查是否适当拆分顶点属性,请执行以下操作:
选择感兴趣的绘制调用,并记下绘制调用编号。
该调用可以是场景的典型绘制调用、具有大量顶点的绘制调用、复杂角色模型的绘制调用,也可以是其他类型的绘制调用。
转到 Pipeline 窗格,然后点击 IA 以进行输入组装。这定义了进入 GPU 的顶点的顶点格式。
观察顶点属性的绑定;这些绑定通常可能会线性增加(0、1、2、3 等),但也并非总是如此。顶点位置通常是列出的第一个顶点属性。
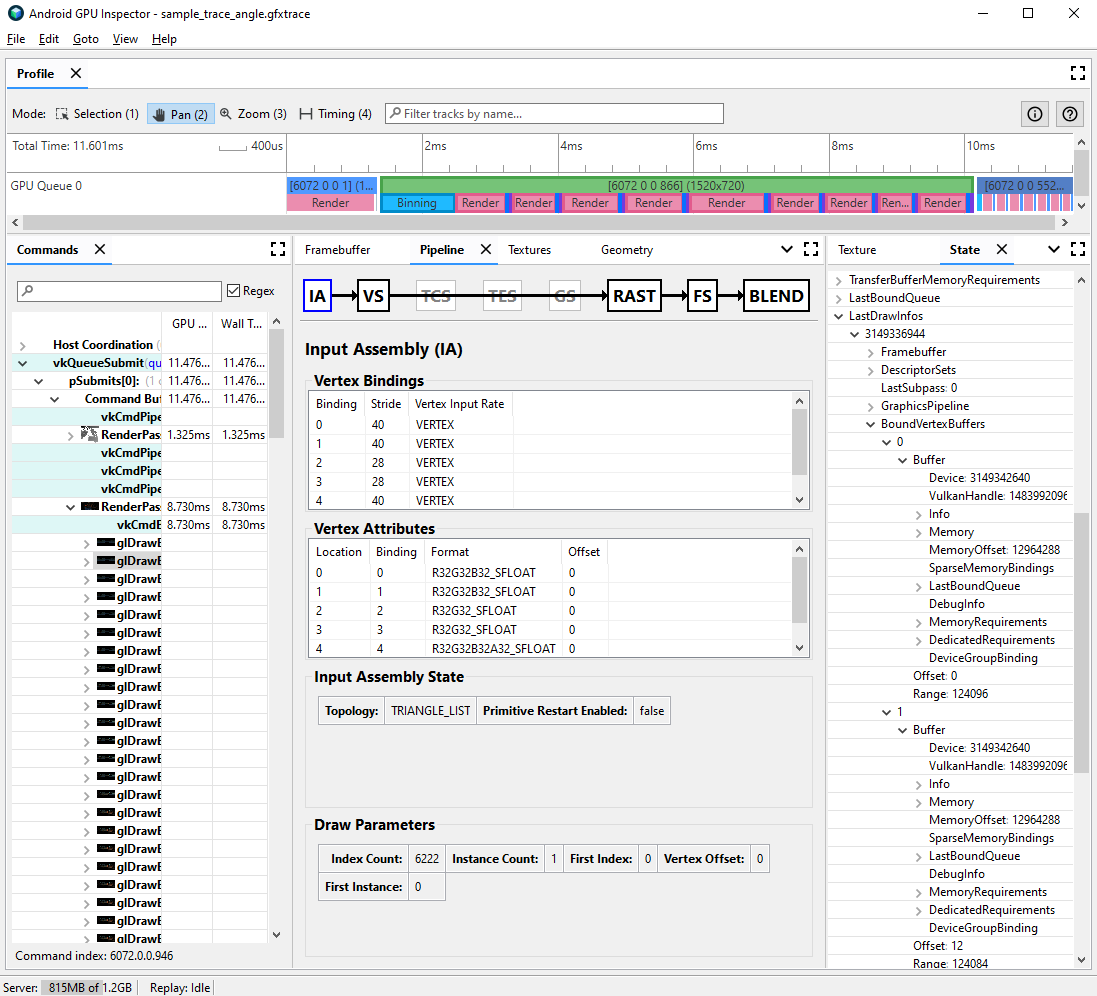
在 State 窗格中,找到
LastDrawInfos并展开匹配的绘制调用编号。然后,展开此绘制调用的BoundVertexBuffers。观察给定绘制调用期间绑定的顶点缓冲区,其中索引与之前的顶点属性绑定匹配。
扩展绘制调用的顶点属性的绑定,并扩展缓冲区。
观察缓冲区的
VulkanHandle,缓冲区表示顶点数据源所在的底层内存。如果VulkanHandle不同,则表示属性来自不同的底层缓冲区。如果VulkanHandle相同但偏移量较大(例如,大于 100),则这些属性可能仍然来自不同的子缓冲区,但这需要进一步调查。
如需详细了解顶点流拆分以及如何在各种游戏引擎上对其进行解析,请参阅有关该主题的博文。