AGI Frame Profiler 可讓您檢查用於組合應用程式的單一影格的個別算繪通道,方法是攔截和記錄執行每個圖形 API 呼叫所需的所有狀態。在 Vulkan 上,系統會使用 Vulkan 的分層系統原生完成這項操作。在 OpenGL 中,指令會透過 ANGLE 攔截,進而將 OpenGL 指令轉換為 Vulkan 呼叫,以便在硬體上執行。
Adreno 裝置
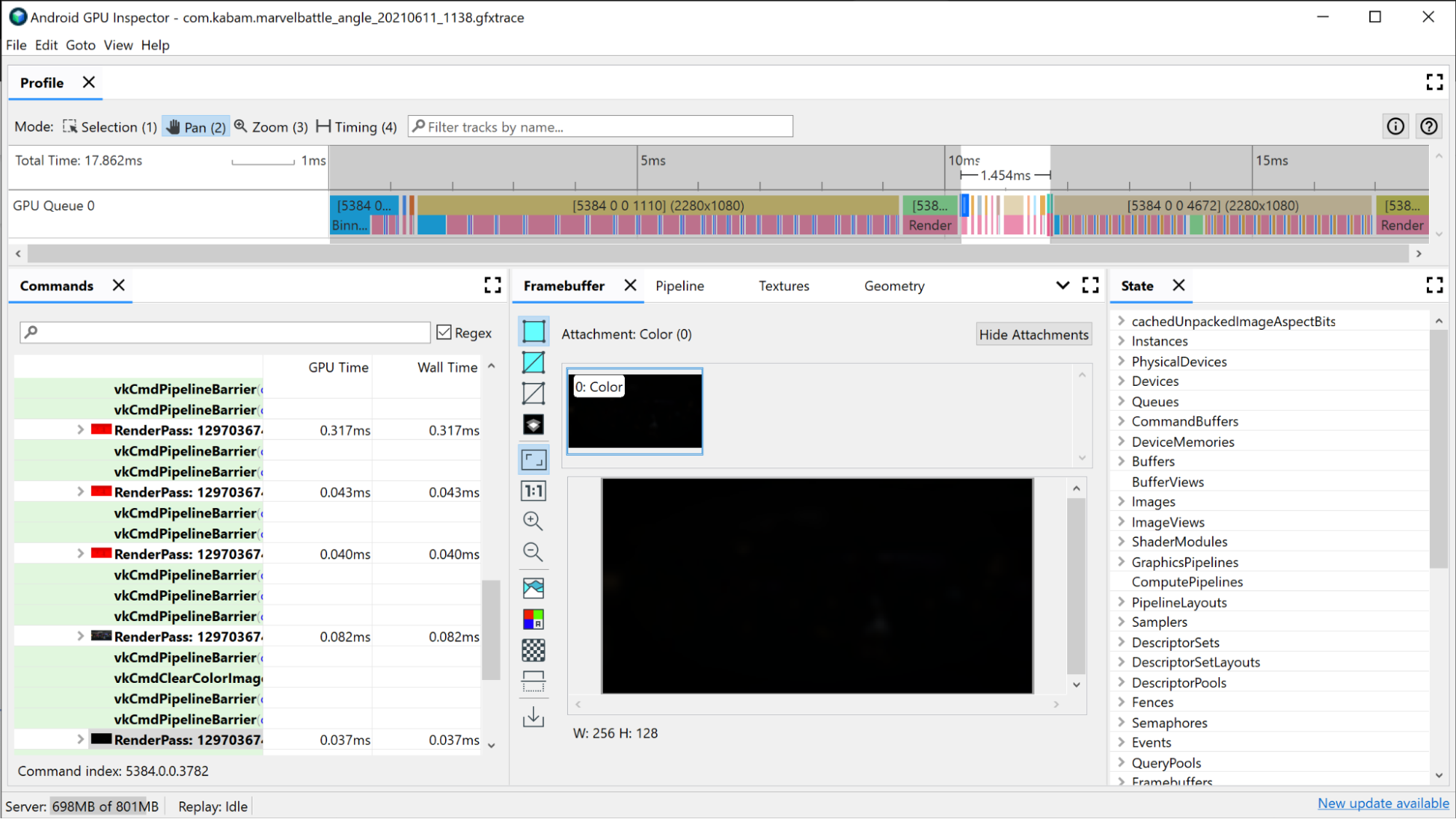
如要找出昂貴的算繪通道,請先查看視窗頂端的 AGI 時間軸檢視畫面。這會顯示構成指定影格組成的所有轉譯通道 (按照時間順序排列)。如果您有 GPU 佇列資訊,那麼您在系統分析器中看到的檢視畫面就會相同。也會呈現轉譯傳遞的基本資訊,例如轉譯後的影格緩衝區解析度,藉此深入分析轉譯傳遞本身時發生的情況。
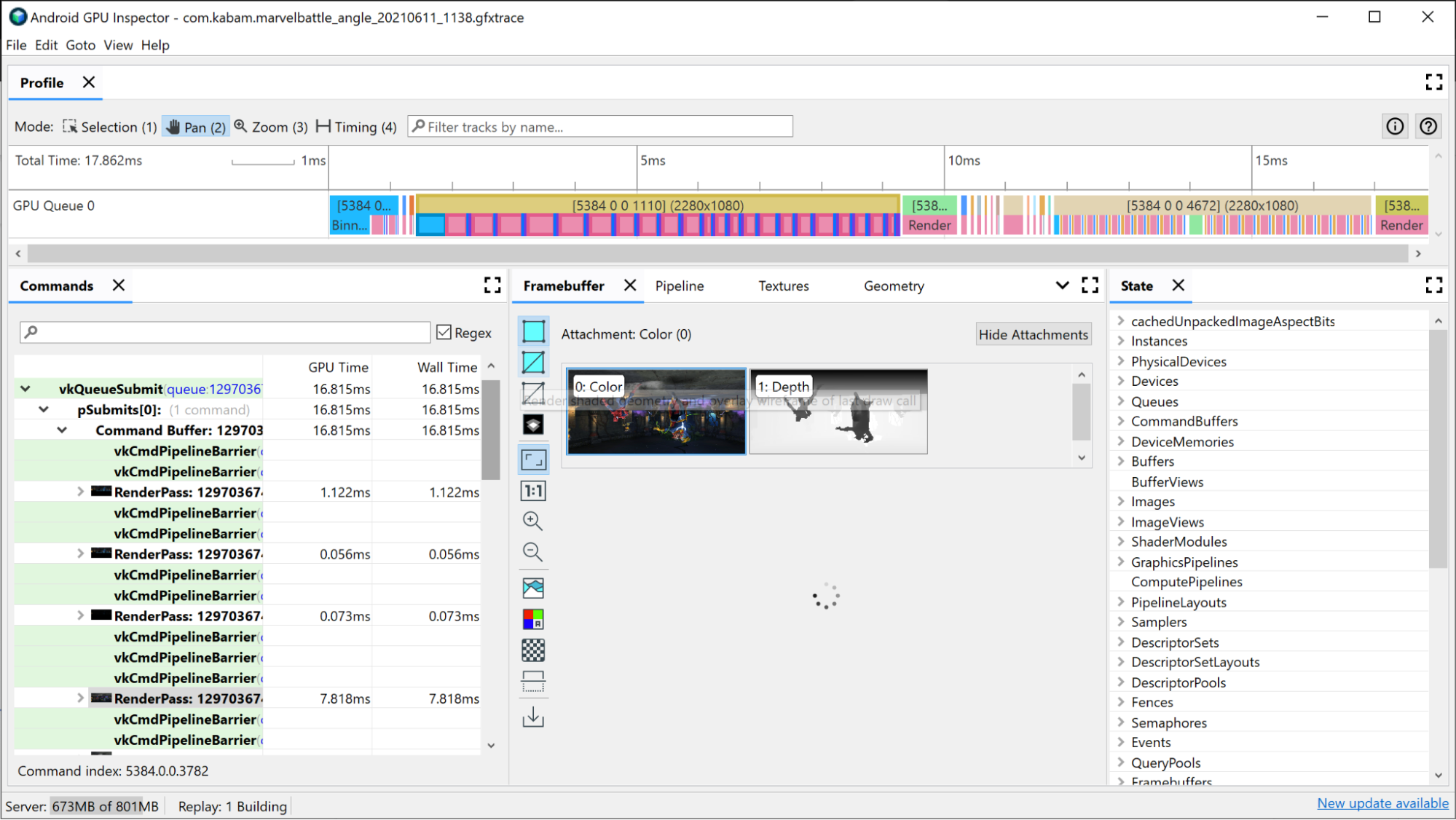
可用於調查算繪通道的第一項條件是載入時間。最長的算繪通道很可能是最有助於改善的轉譯通道,因此請先瞭解此情況。
與相關轉譯票證相關的 GPU 切片,已列出算繪通道中情況的相關資訊:
- 特徵分塊:端點根據螢幕上的位置放置至特徵分塊
- 算繪:像素或片段為陰影的位置
- GMEM 載入/儲存:載入 framebuffer 的內容,或從內部 GPU 記憶體將內容儲存至主要記憶體時
如要瞭解潛在瓶頸,請查看每項動作在轉譯傳遞中花費的時間。例如:
- 如果 Binning 佔據了大部分時間,這會建議包含頂點資料的瓶頸,這表示頂點有太多頂點、大型頂點,或其他與頂點相關的問題。
- 如果轉譯作業花費太多時間,就表示瓶頸是瓶頸。可能的原因包括複雜的著色器、紋理擷取過多、在不需要時算繪至高解析度的影格緩衝區,或其他相關問題。
GMEM 載入和儲存也是必須留意的事項。從圖像記憶體移到主記憶體是很昂貴的,因此,若能減少負載或商店作業量,也對效能有幫助。常見的例子是 GMEM 儲存庫深度/模板,這類緩衝區將深度/模板緩衝區寫入主記憶體。如果您未在日後的算繪傳遞中使用該緩衝區,系統會排除這類儲存作業,節省影格時間和記憶體頻寬。
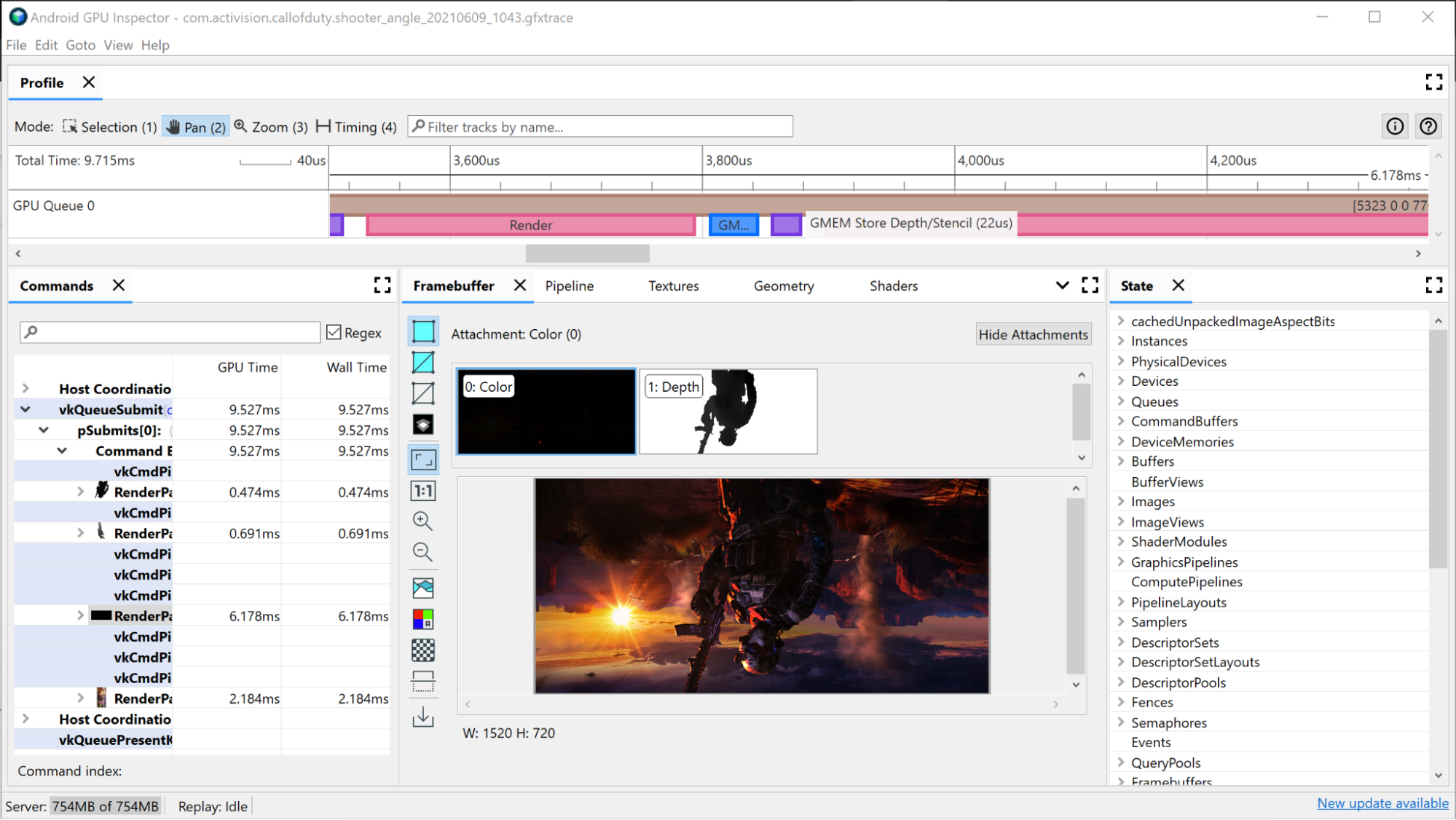
大型算繪通道調查
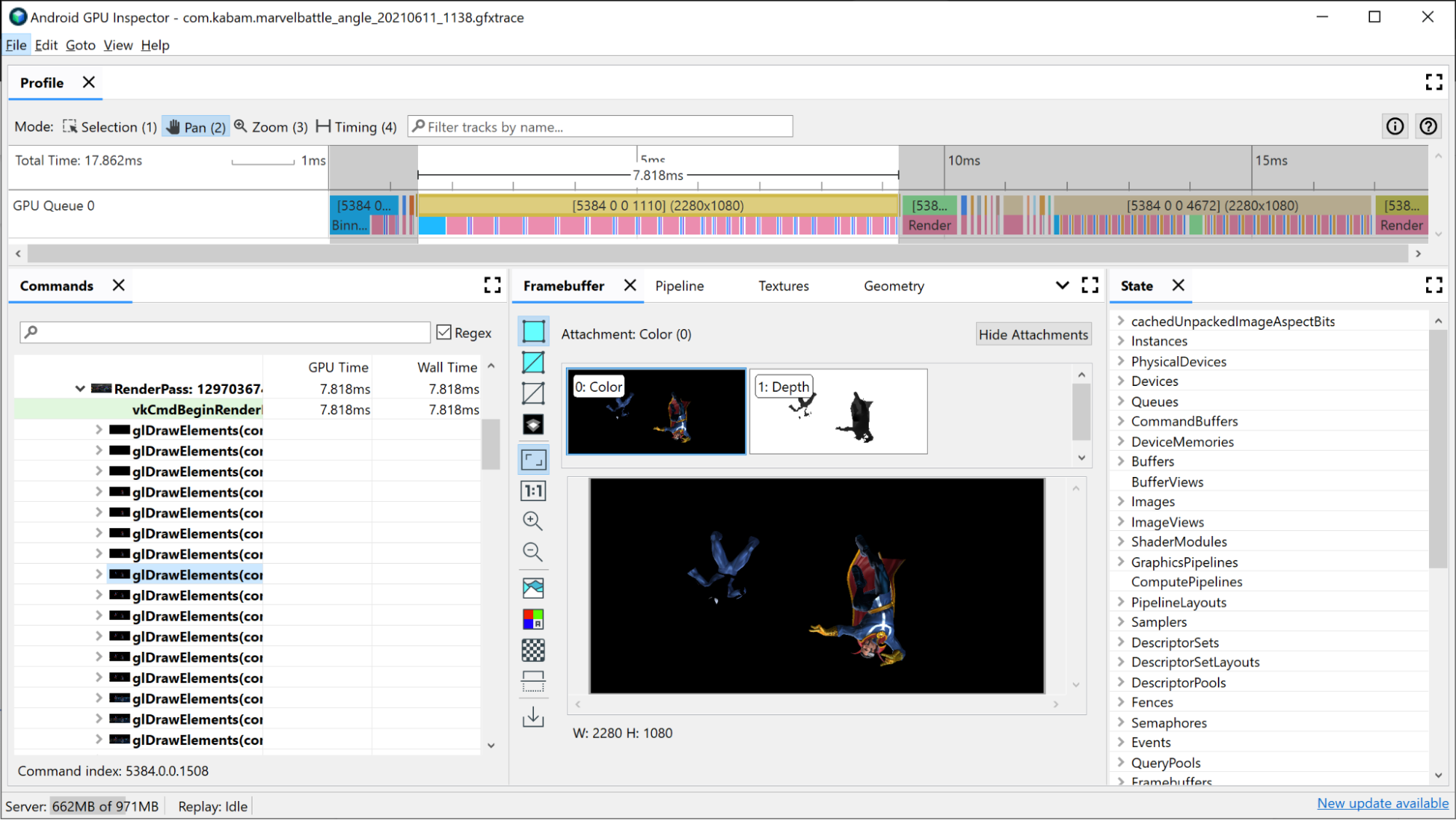
查看轉譯過程中發出的所有個別繪圖指令:
按一下時間軸中的轉譯通道。這個動作會在「Frame Profiler」(指令分析器) 窗格中的「Commands」(指令) 窗格中開啟算繪通道。
按一下算繪通道的選單,隨即顯示在算繪傳遞期間發出的所有個別繪圖指令。如果這是 OpenGL 應用程式,您可以進一步瞭解詳情並查看 ANGLE 發出的 Vulkan 指令。
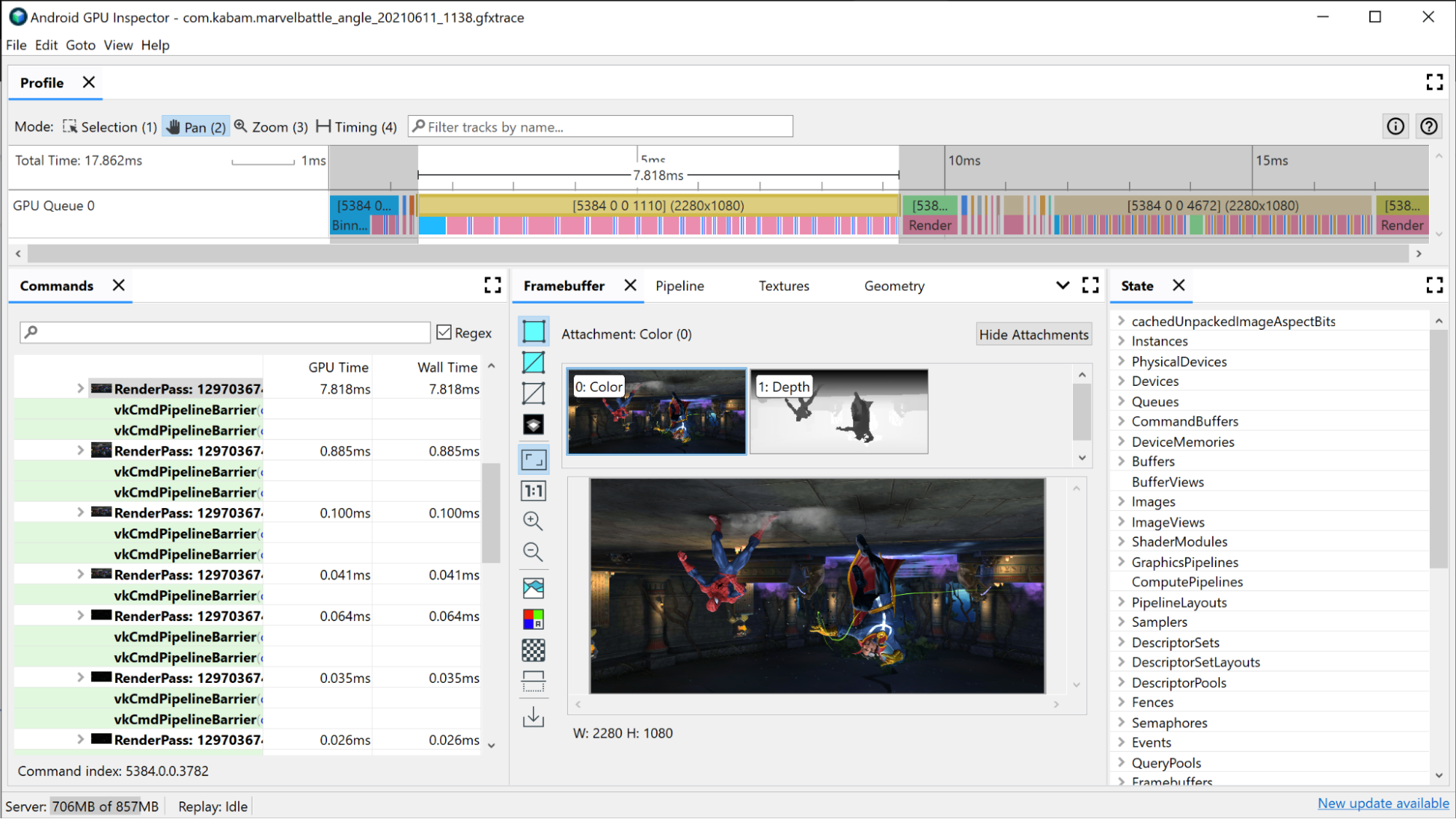
選取其中一個繪製呼叫。這個動作會開啟「Framebuffer」窗格,其中顯示此繪圖期間繫結的所有 framebuffer 附件,以及連接的 framebuffer 的最終繪製結果。您也可以在這裡使用 AGI 開啟上一個和下一個繪圖呼叫,然後比較兩者之間的差異。如果兩者看起來幾乎相同,就表示可以試著排除不會影響最終圖片的繪圖呼叫。
開啟這個繪圖的「Pipeline」窗格,會顯示圖形管道執行此繪製呼叫所用的狀態。
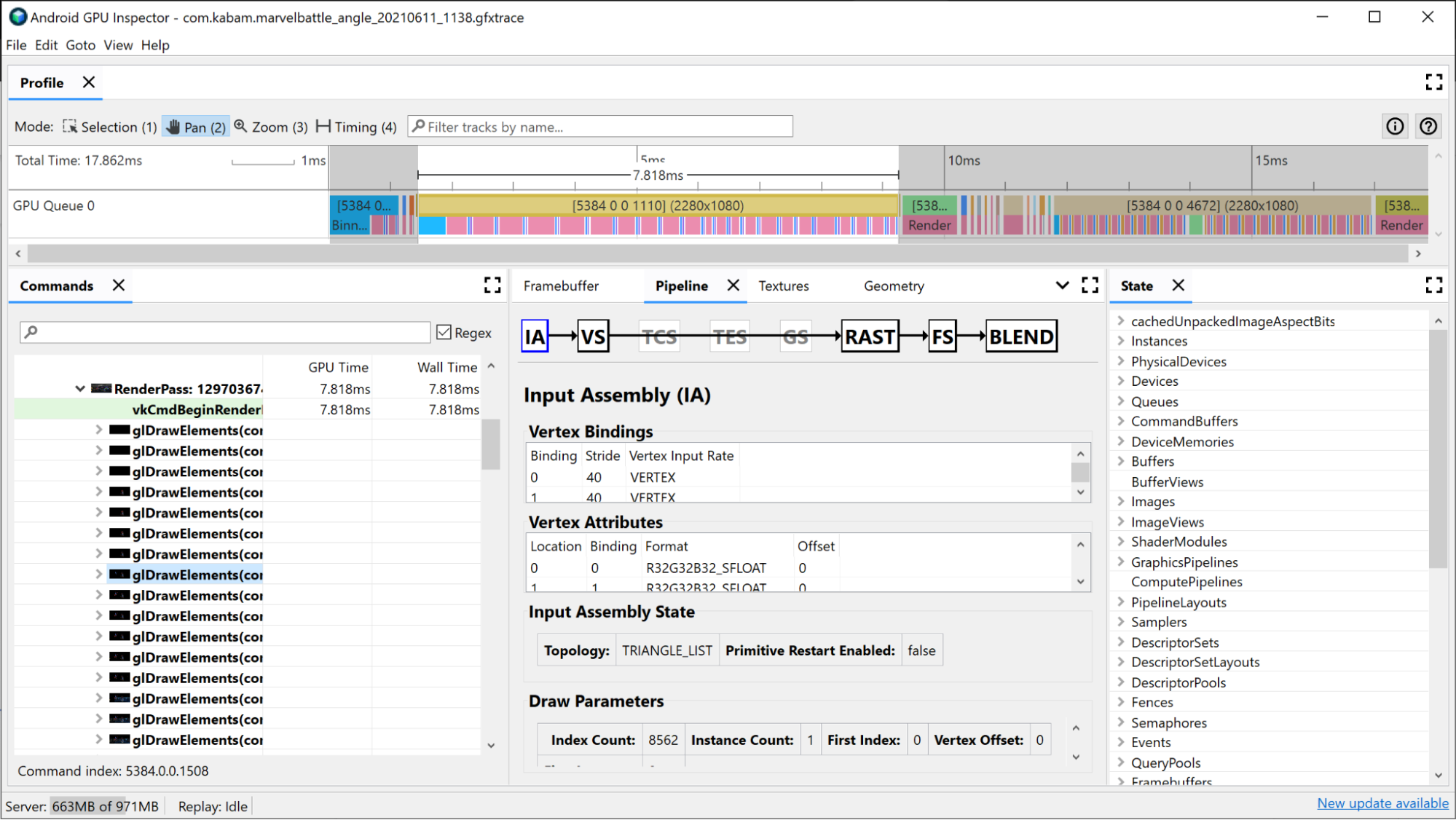
輸入組合器提供頂點資料與此繪圖繫結的相關資訊。如果您發現 Binning 佔據了轉譯通行證的大部分時間,建議您瞭解此情況。您可以在這裡查看頂點格式、已繪製的頂點數量,以及頂點在記憶體中的配置方式等相關資訊。詳情請參閱「分析頂點格式」一文。
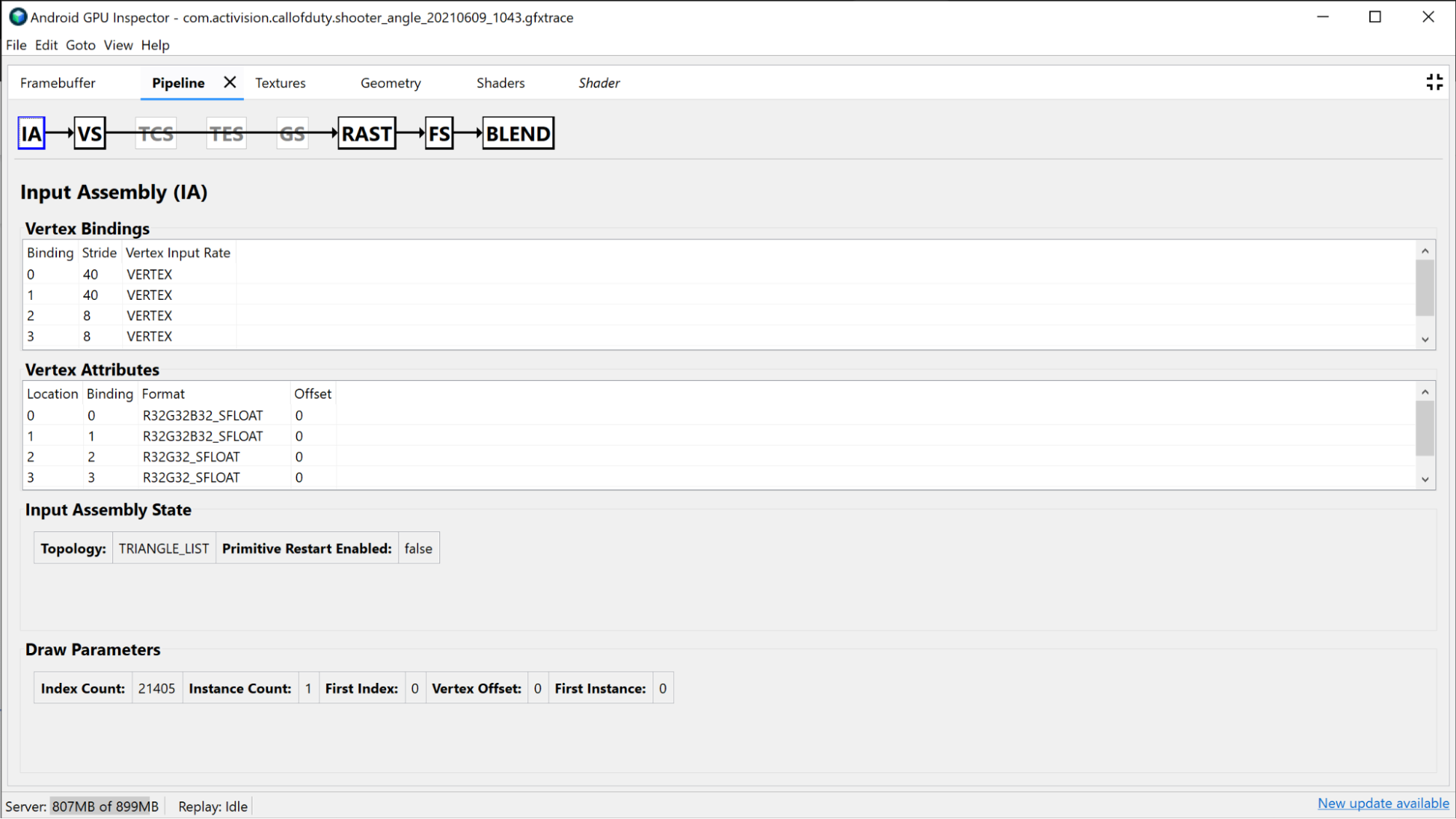
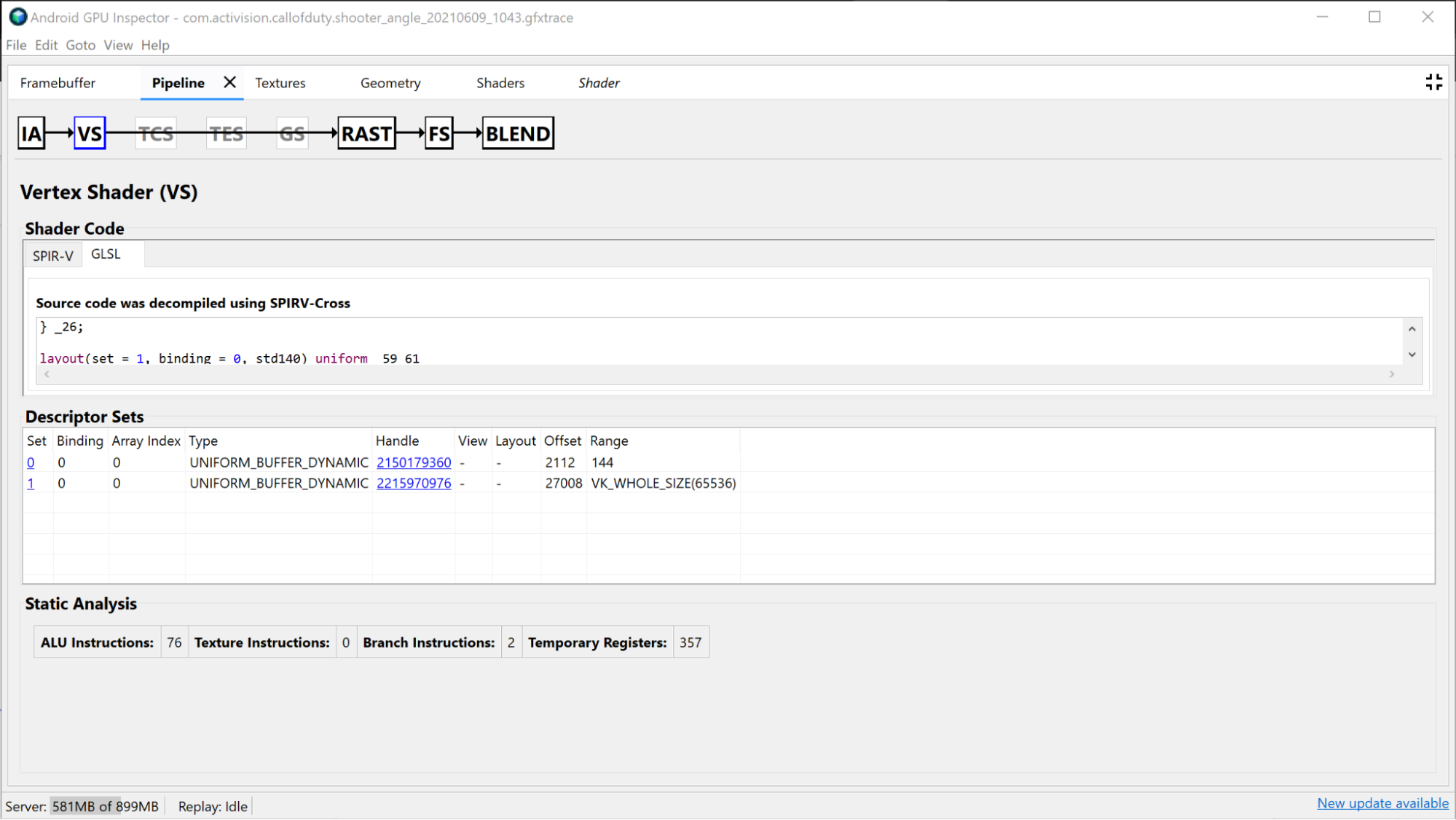
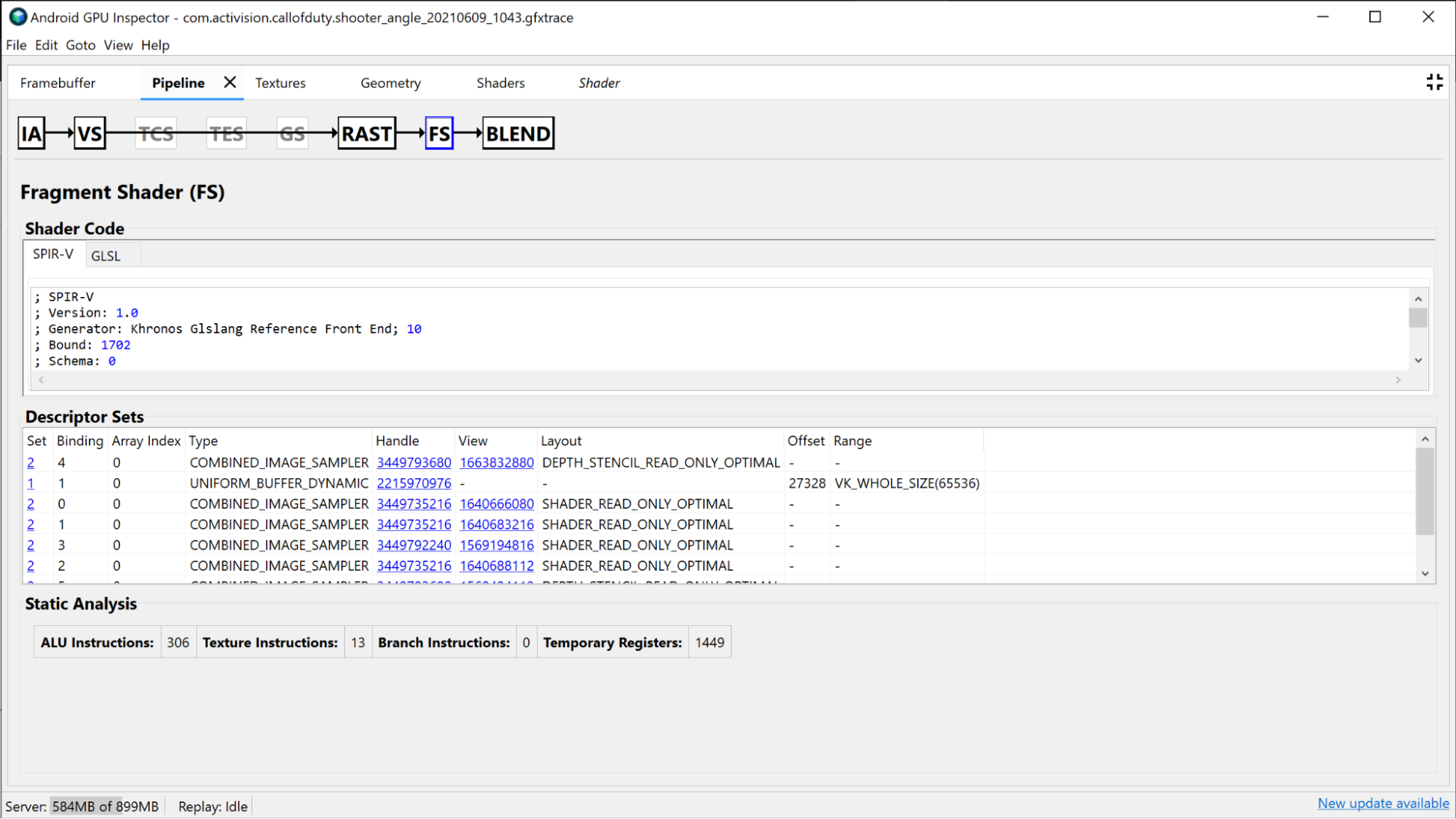
「Vertex 著色器」部分提供此繪製期間使用的頂點著色器相關資訊,如果識別繫結是問題,您也可以調查此情況。您可以查看使用的著色器 SPIR-V 和反編譯 GLSL,並調查這個呼叫的繫結「統一緩衝區」。詳情請參閱「分析著色器效能」。
光柵化部分會顯示管道更固定函式設定的相關資訊,並可用於更多用於固定功能狀態 (例如可視區域、剪刀、深度狀態和多邊形模式) 的偵錯用途。
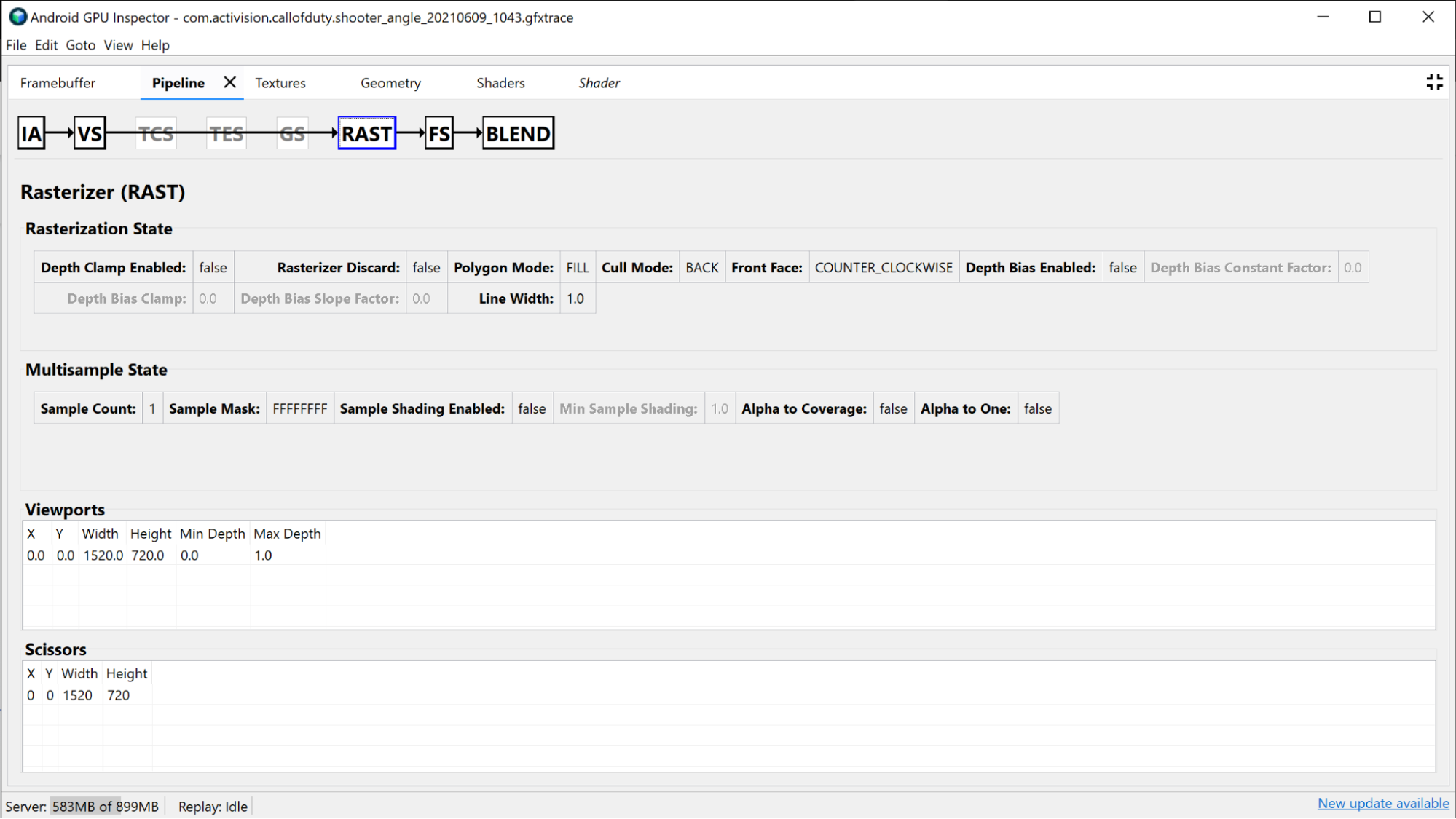
「Fragment Shader」區段提供許多與「Vertex Shader」區段相同的資訊,但僅限 Fragment Shader。 在這種情況下,您可以查看哪些紋理受到繫結,然後按一下控點來調查紋理。
較小型的算繪通道調查
您還可以採用另一項條件來改善 GPU 效能。一般而言,請盡量減少轉譯傳遞的數量,因為 GPU 需要一段時間才能更新狀態,這類較小的算繪通道通常用於產生陰影地圖、套用高斯模糊、估算亮度、進行後續處理,或是算繪 UI 等作業。其中有些可能可以合併為單一算繪通道,即使對整體圖片的影響不大,也不會對圖片產生合理影響,甚至能完全排除。