
このドキュメントでは、ツールを使用して CPU と GPU のボトルネックを特定し、解決することで、ゲームのパフォーマンスを最適化する方法について説明します。
CPU の最適化
分析の結果、ゲームが CPU 基準であることが判明した場合は、さらなる調査が不可欠です。そのためには、ボトルネックの原因となり FPS を低下させている特定のスレッドや API を特定する必要があります。
CPU の最適化には、一般的に万能のソリューションは有効ではありません。代わりに、ゲームやシーンに基づいて最も負荷の高いワークロードを特定し、関連するロジックと関数を最適化する必要があります。
ゲームエンジンのタイミング トレースツール
この分析には、次のツールが役立ちます。
Unreal Insights
Unreal Engine プロジェクトでは、Unreal Insight Tool を使用して、フレームを構成する個々のスレッドのタイミング トレース情報を分析できます。
たとえば、GameThread は通常、CPU 時間の大部分を使用します。これは主に Tick Time が原因です。さらに、Tick Time の大部分は FActorComponentTickFunction に関連付けられたタスクによって消費されます。
FActorComponentTick を最適化するには、カメラの視野外に配置されたキャラクターやオブジェクトの計算を除外し、カリングを実装することが不可欠です。また、LOD(詳細レベル)ベースのアニメーションを活用することで、パフォーマンスをさらに向上させることができます。

Unity Profiler(Unity)
Unity Profiler を使用した分析により、メインスレッドが 45 ミリ秒以上を消費し、PostLateUpdate.FinishFrameRendering が 16.23 ミリ秒を占有していることが明らかになりました。これにより、この処理が最も時間のかかるオペレーションであることがわかりました。この中で、Inl_RenderCameraStack の複数の呼び出しが確認されています。有効になっているカメラの必要性を確認し、それに応じて最適化することをおすすめします。

システムレベルのプロファイリング ツール
次のプロファイリング ツールを使用します。
perfetto
Perfetto トレースを使用すると、Android 搭載デバイスの各スレッドの CPU コアの割り当てと実行の詳細を確認できます。これにより、スレッド実行データを分析してパフォーマンスのボトルネックを特定できます。
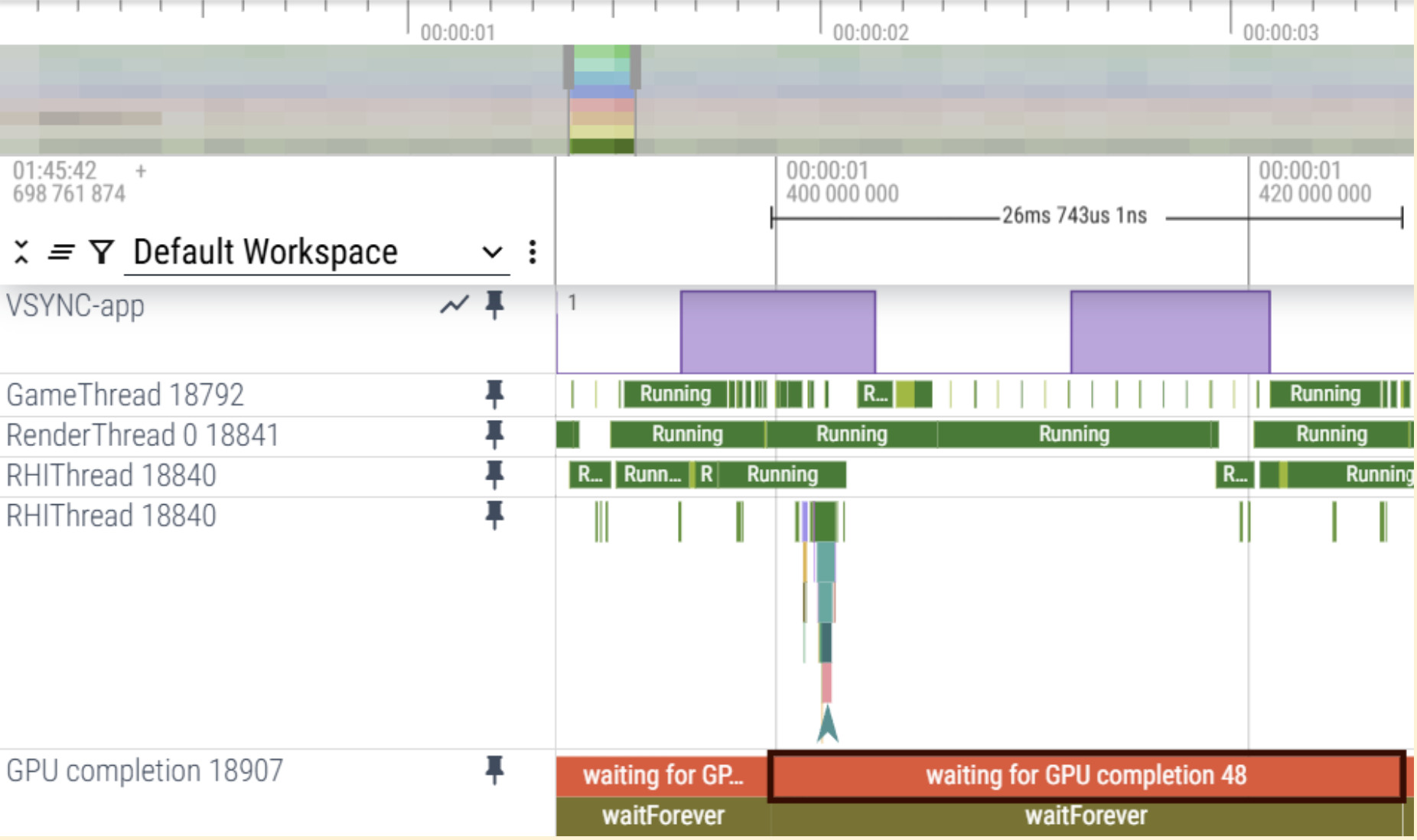
CPU オーバーヘッドのケース
トレースは、GameThread と RenderThread のワークロードが RHI Thread の QueuePresent の遅延を引き起こし、VSync に基づく CPU バウンドのシナリオにつながっていることを示しています。

GPU オーバーヘッドのケース
トレースは、GPU の完了自体が 25 ミリ秒を超えていることを示しています。これは、GPU バウンドのシナリオであることを意味します。
Simpleperf
現在の CPU 使用率が最も高い関数を特定するには、simpleperf を使用できます。最適な結果を得るには、これらの関数を並べ替えて、使用率が最も高い関数を優先的に処理することをおすすめします。

Simpleperf を使用すると、最も多くの CPU 時間を使用する関数に関するデータを調べることができます。CPU 使用率を最適化するには、CPU を最も多く使用する関数から始めます。この例では、ActorComponentTickFunctions のアニメーションに関連付けられている USkeletalMeshComponent が最も CPU を使用しています。
GPU の最適化
分析の結果、ゲームが GPU バウンドであることが判明した場合は、さらに調査することが不可欠です。これには、GPU の最適化と分析にさまざまなツールと手法を使用する必要があります。
GPU を最適化するには、フレーム デバッガを使用して、各シーンのレンダリング パイプラインとドローコールを分析します。また、不要なオペレーションや最適化する領域を特定するには、GPU アーキテクチャとパイプラインの動作を十分に理解する必要があります。
以降のセクションでは、GPU の最適化方法とツールについて説明します。
不要な RenderPass を排除する
レンダリングのパフォーマンスを向上させ、GPU のワークロードを減らすには、不要なレンダリング パスを削除します。これには、ドローコールがないレンダリング パスや、出力が最終フレームで使用されないレンダリング パスが含まれます。
RenderDoc などの GPU デバッガを使用して、レンダリング パイプラインを分析し、最適化の機会を特定します。
ドローコールなし: レンダリング パスにドローコールが含まれているかどうかを確認します。ドローコールがない場合は、パスを削除します。
未使用の出力: 後続のパスでレンダーパスの出力(色や深度など)にアクセスしたり、表示したりするかどうかを確認します。そうでない場合は、パスを削除します。
マージ可能なパス: マージ可能なパスを特定します。
- 同じフレームバッファまたはアタッチメント
- 互換性のある読み込みまたはストア オペレーション
- 依存関係のバリアが間にない

読み込みまたは保存オペレーションを最小限に抑える
読み込みまたは保存のオペレーションは、大量のメモリを使用するため、リソースを大量に消費します。不要なロードストア オペレーションを最小限に抑えます。これらのアクションは、RenderPass 内の添付ファイルが必要な場合にのみ実行します。それ以外の場合は、Clear または Don't care オペレーションに置き換えてオーバーヘッドを削減します。
最適化の方法
RenderDoc などの GPU デバッガを使用して、レンダリング パイプラインを分析し、次の最適化の機会を特定します。
読み込み: レンダリング パスのアタッチメントが前のパスまたはアタッチメントのデータを使用しない場合、読み込みオペレーションは不要です。このような場合、
Don't careまたはClearを使用するとオーバーヘッドを削減できます。ストア: 現在のレンダーパスの後にレンダーパス アタッチメントが使用されない場合、ストア オペレーションは不要です。このような場合は、
Don't careまたはClearを使用します。Replace: 最終フレームに影響を与えることなく、現在の読み込みまたは保存の設定を
ClearまたはDon't Careに置き換えることができるかどうかを判断します。

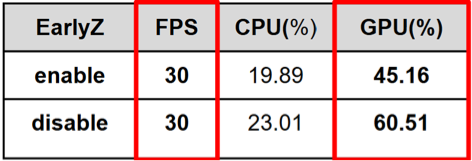
破棄を回避して Early-Z を有効にする
Early-Z はモバイル プラットフォームのパフォーマンスを向上させます。ただし、シェーダー内の discard 命令は Early-Z を自動的に無効にします。discard 命令が不可欠でない場合は、削除します。
Early-Z アクセラレーション
この最適化により、フラグメント シェーダー オペレーションが大幅に削減され、GPU パフォーマンスが向上します。
最適化の方法
RenderDoc などの GPU デバッガを使用して、レンダリング パイプラインを分析し、次の最適化の機会を特定します。
フラグメント シェーダーでの
discardの使用:discardキーワードは、フラグメントの可視性が事前にわからないため、GPU が早期の深度テストを実行するのを防ぎます。gl_FragDepthの変更:gl_FragDepthを動的に変更すると、フラグメントの深度が変更されます。フラグメント処理の前に最終的な深度が不明になるため、Early-Z 最適化が無効になります。アルファからカバレッジへの変換が有効: アルファからカバレッジへの変換が有効になっている場合(MSAA レンダリングでよく使用されます)、フラグメント カバレッジはアルファ値に依存します。これにより、深度テストが遅延し、Early-Z が無効になる可能性があります。

テクスチャ形式を最適化する
最適なテクスチャ形式を選択すると、メモリ消費量が減少し、帯域幅の効率が向上し、レンダリング パフォーマンスが向上します。精度が高すぎる形式を使用すると、視覚的なメリットが得られないまま GPU リソースが無駄になる可能性があります。
最適化の方法
RenderDoc などの GPU デバッガを使用して、レンダリング パイプラインを分析し、次の最適化の機会を特定します。
- 深度ステンシル バッファに
D32S8ではなくD24S8を使用: 深度ステンシル バッファにD24S8を使用すると、ほとんどのアプリで画質に目立った違いはほとんどないか、まったくありませんが、D32S8と比較してメモリ消費量が 20% 削減されます。 - カラー テクスチャに
ASTC圧縮を使用する:ASTC圧縮を使用すると、非圧縮形式と比較してテクスチャ メモリの使用量を最大 8 分の 1 に大幅に削減しながら、高い画質を維持できます。 - フルフロートの代わりにハーフフロート形式を使用する:
R16FまたはRG16Fを使用して、メモリ帯域幅とストレージ消費量を削減します。これらの形式は、後処理バッファに適しています。
ジオメトリの複雑さを最適化する
ジオメトリの複雑さを最小限に抑えると、特に GPU 機能が制限されているモバイル デバイスで、レンダリング パフォーマンスが向上します。これには、頂点と三角形の数を減らし、オブジェクトを統合してドローコールを減らし、レンダリングされない、または不要なジオメトリを削除することが含まれます。メッシュの簡略化、詳細レベル(LOD)、フラスタムまたはオクルージョン カリングなどの手法を使用すると、GPU のワークロードを大幅に削減し、フレームレートを向上させることができます。
最適化の方法
RenderDoc、Android GPU Inspector、その他のパフォーマンス アナライザなどのプロファイリング ツールと GPU デバッガを使用して、ジオメトリ関連のパフォーマンス ボトルネックを特定します。
三角形の数を減らす: 特に小さくて遠いオブジェクトについては、ポリゴンの使用を最小限に抑えます。
詳細レベル(LOD)を使用: カメラの距離に基づいて、よりシンプルなメッシュが自動的に使用されます。
小さなメッシュを統合: 静的オブジェクトを統合して、ドローコールと CPU オーバーヘッドを削減します。
フラスタム カリングとオクルージョン カリング: 視野外にあるオブジェクトや、他の要素によって隠されているオブジェクトのレンダリングを回避します。
不要な添付ファイルを削除する
レンダーパス アタッチメント(色、深度、ステンシルなど)は、使用されていなくてもメモリ帯域幅と GPU リソースを消費します。不要な添付ファイルや冗長な添付ファイルを削除すると、特にモバイル プラットフォームでパフォーマンスが向上し、電力消費量が削減されます。
最適化の方法
プロファイリング ツールや GPU デバッガ(RenderDoc、Android GPU Inspector、その他のパフォーマンス アナライザなど)を使用して、ジオメトリ関連のパフォーマンス ボトルネックを特定します。
- 実際の使用状況を確認する: アタッチメントに書き込みまたはアタッチメントから読み取りを行うドローコールまたはシェーダーはありますか?
- フレーム出力の分析:
RenderDocまたは同等のユーティリティを使用して、添付ファイルが最終的な画像に貢献しているかどうかを判断します。 - 一時的なアタッチメントまたはダミーのアタッチメントを検討する: 永続ストレージを必要としない一時データには、一時的なアタッチメントまたは「Don't Care」ストア オペレーションを使用する必要があります。
シェーダーの精度を最適化する
シェーダー内で過度に高い精度(mediump や lowp ではなく highp など)を使用すると、特にモバイル GPU で GPU ワークロード、消費電力、レジスタ圧力が上昇します。変数(位置、色、UV など)に適切な最小精度を使用することで、視覚的な影響を認識することなくパフォーマンスを改善できます。

最適化の方法
RenderDoc、Android GPU Inspector などのプロファイリング ツールや GPU デバッガ、その他のパフォーマンス アナライザを使用して、ジオメトリ関連のパフォーマンス ボトルネックを特定します。
シェーダー コードを確認する: シェーダー変数を評価し、高精度が使用されているのは、深度やスクリーンスペースの計算など、必要な場合に限られていることを確認します。高精度を必要としない色、UV 座標、値には、中精度または低精度を使用します。
GPU デバッガを使用する: RenderDoc やモバイル GPU プロファイラ(AGI、Mali/GPU Inspector など)などの診断ユーティリティは、精度に関する問題に関連するレジスタ使用量の増加やシェーダーの停止を特定します。

背面カリングを有効にする
カメラから遠ざかる三角形(背面)のレンダリングは、ソリッド オブジェクトでは不要なことがよくあります。
最適化の方法
VK_CULL_MODE_NONE を使用すると、GPU が前面と背面の両方をレンダリングする必要があるため、レンダリングのワークロードが増加し、パフォーマンスに悪影響を及ぼす可能性があります。
UI シーンのオーバードローを最小限に抑える
特に UI シーンで、不要なドローコールとレンダーパスを排除して、レンダリング パフォーマンスを向上させ、GPU のワークロードを削減します。たとえば、UI シーンで、世界全体がレンダリングされてから UI が画面全体にオーバーレイされる場合、世界のレンダリングは冗長になります。
最適化の方法
RenderDoc などの GPU デバッガを使用して、レンダリング パイプラインを分析し、次の最適化の機会を特定します。
- 余分なオーバードローがないことを確認します。画面全体がレンダリングされる可能性のあるユーザー インターフェースのコンテキストでは、前のレンダリング パスが不必要にオーバー ドローされていないことを確認します。
- パフォーマンスを最適化するために、深度テストとカリングを有効にします。
- レンダリングの順序を前面から背面にすることを検討してください。
